ベアメタル用 Google Distributed Cloud(ソフトウェアのみ)では、クラウドベースのマネージド サービス、オープンソース ツール、サードパーティの商用ソリューションとの互換性の検証など、クラスタのロギングとモニタリングに関して複数のオプションが用意されています。このページでは、これらのオプションについて説明し、環境に適したソリューションを選択するための基本的なガイダンスを示します。
このページは、サービスレベル目標(SLO)の遵守など、デプロイされたアプリケーションやサービスの状態をモニタリングする管理者、アーキテクト、オペレーターを対象としています。 Google Cloud のコンテンツで使用されている一般的なロールとタスクの例の詳細については、一般的な GKE ユーザーのロールとタスクをご覧ください。
Google Distributed Cloud のオプション
クラスタのロギングとモニタリングには、いくつかのオプションがあります。
- Cloud Logging と Cloud Monitoring。ベアメタル システム コンポーネントでデフォルトで有効になっています。
- Prometheus と Grafana は Cloud Marketplace から入手できます。
- サードパーティ ソリューションによる検証済みの構成。
Cloud Logging と Cloud Monitoring
Google Cloud Observability は、Google Cloudの組み込みオブザーバビリティ ソリューションです。フルマネージドのロギング ソリューション、指標の収集、モニタリング、ダッシュボード、アラートが提供されます。Cloud Monitoring は、クラウドベースの GKE クラスタと同様の方法で、Google Distributed Cloud クラスタをモニタリングします。
必要なサービス アカウントと Identity and Access Management(IAM)ロールを使用してクラスタを作成すると、Cloud Logging と Cloud Monitoring がデフォルトで有効になります。Cloud Logging と Cloud Monitoring を無効にすることはできません。サービス アカウントと必要なロールの詳細については、サービス アカウントを構成するをご覧ください。
エージェントは、次の変更を行うように構成できます。
- ロギングとモニタリングのスコープ。システム コンポーネントのみ(デフォルト)からシステム コンポーネントとアプリケーションの両方まで。
- 収集される指標のレベル。最適化された指標のセット(デフォルト)のみからすべての指標まで。
詳細については、このドキュメントの Google Distributed Cloud の Stackdriver エージェントの構成をご覧ください。
Logging と Monitoring は、簡単に構成でき、強力な、たった一つのクラウドベースのオブザーバビリティ ソリューションを提供します。Google Distributed Cloud でワークロードを実行する場合は、Logging と Monitoring の使用を強くおすすめします。Google Distributed Cloud と標準のオンプレミス インフラストラクチャで実行されるコンポーネントがあるアプリケーションの場合は、アプリケーションのエンドツーエンドのビューのために、その他のソリューションも検討できます。
アーキテクチャ、構成、 Google Cloud プロジェクトにデフォルトで複製されるデータの詳細については、Google Distributed Cloud のロギングとモニタリングの仕組みをご覧ください。
Logging の詳細については、Cloud Logging のドキュメントをご覧ください。
Monitoring の詳細については、Cloud Monitoring のドキュメントをご覧ください。
フリートレベルで Google Distributed Cloud から Cloud Monitoring リソース使用率の指標を表示して使用する方法については、Google Kubernetes Engine の概要をご覧ください。
Prometheus と Grafana
Prometheus と Grafana は、Cloud Marketplace で入手可能な人気の高いオープンソース モニタリング サービスです。
Prometheus は、アプリケーションとシステムの指標を収集します。
Alertmanager は、複数の異なるアラート メカニズムを使用してアラートの送信を行います。
Grafana はダッシュボード ツールです。
すべてのモニタリング ニーズに、Cloud Monitoring をベースとする Google Cloud Managed Service for Prometheus を使用することをおすすめします。Google Cloud Managed Service for Prometheus では、無料でシステム コンポーネントをモニタリングできます。Google Cloud Managed Service for Prometheus には Grafana との互換性もあります。ただし、純粋なローカル モニタリング システムが必要な場合は、クラスタに Prometheus と Grafana をインストールすることもできます。
Prometheus をローカルにインストールし、システム コンポーネントから指標を収集する場合は、システム コンポーネントの指標エンドポイントにアクセスする権限をローカルの Prometheus インスタンスに付与する必要があります。
Prometheus インスタンスのサービス アカウントを事前定義された
gke-metrics-agentClusterRole にバインドし、サービス アカウント トークンを認証情報として使用して、次のシステム コンポーネントから指標をスクレイピングします。kube-apiserverkube-schedulerkube-controller-managerkubeletnode-exporter
kube-system/stackdriver-prometheus-etcd-scrapeシークレットに保存されているクライアント キーと証明書を使用して、etcd からの指標スクレイピングを認証します。名前空間から kube-state-metrics へのアクセスを許可する NetworkPolicy を作成します。
サードパーティのソリューション
Google は、サードパーティのロギングおよびモニタリング ソリューション プロバイダと協力して、Google Distributed Cloud とサードパーティの製品が適切に連動するよう支援しています。Datadog、Elastic、Splunk などの製品があります。今後もサードパーティの製品が検証され、追加される予定です。
Google Distributed Cloud でサードパーティのソリューションを使用する場合は、次のソリューション ガイドをご覧ください。
- Elastic Stack による Google Distributed Cloud のモニタリング
- Splunk Connect を使用して Google Distributed Cloud でログを収集する
Google Distributed Cloud のロギングとモニタリングの仕組み
Cloud Logging と Cloud Monitoring は、新しい管理クラスタまたはユーザー クラスタの作成時に、各クラスタにインストールされ、起動されます。
Stackdriver エージェントには、クラスタごとに次のコンポーネントが含まれています。
Stackdriver Operator(
stackdriver-operator-*)。クラスタにデプロイされた他のすべての Stackdriver エージェントのライフサイクルを管理します。Stackdriver のカスタム リソース。 Google Distributed Cloud インストール プロセスで自動的に作成されるリソース。
GKE Metrics Agent(
gke-metrics-agent-*)。各ノードから Cloud Monitoring に指標をスクレイピングする OpenTelemetry Collector ベースの DaemonSet。クラスタに関するより多くの指標を提供するために、node-exporterDaemonSet とkube-state-metricsデプロイメントも含まれています。Stackdriver Log Forwarder(
stackdriver-log-forwarder-*)。各マシンから Cloud Logging にログを転送する Fluent Bit DeamonSet。Log Forwarder は、ログエントリをノードにローカルでバッファリングして、最大 4 時間再送信します。バッファがいっぱいになるか、Log Forwarder が Cloud Logging API に 4 時間以上アクセスできない場合、ログは削除されます。メタデータ エージェント(
stackdriver-metadata-agent-)。Pod、Deployment、ノードなどの Kubernetes リソースのメタデータを Ops API の構成モニタリングに送信する Deployment。このメタデータの追加により、Deployment 名、ノード名、Kubernetes Service 名で指標データをクエリできます。
Stackdriver によってインストールされたエージェントは、次のコマンドを実行して確認できます。
kubectl -n kube-system get pods -l "managed-by=stackdriver"
このコマンドの出力は、次のようになります。
kube-system gke-metrics-agent-4th8r 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-8lt4s 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-dhxld 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-lbkl2 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-pblfk 1/1 Running 1 (40h ago) 40h
kube-system gke-metrics-agent-qfwft 1/1 Running 1 (40h ago) 40h
kube-system kube-state-metrics-9948b86dd-6chhh 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-5s4pg 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-d9gwv 1/1 Running 2 (40h ago) 40h
kube-system node-exporter-fhbql 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-gzf8t 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-tsrpp 1/1 Running 1 (40h ago) 40h
kube-system node-exporter-xzww7 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-8lwxh 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-f7cgf 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-fl5gf 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-q5lq8 1/1 Running 2 (40h ago) 40h
kube-system stackdriver-log-forwarder-www4b 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-log-forwarder-xqgjc 1/1 Running 1 (40h ago) 40h
kube-system stackdriver-metadata-agent-cluster-level-5bb5b6d6bc-z9rx7 1/1 Running 1 (40h ago) 40h
Cloud Monitoring の指標
Cloud Monitoring によって収集される指標のリストについては、Google Distributed Cloud の指標を表示するをご覧ください。
Google Distributed Cloud 用の Stackdriver エージェントの構成
Google Distributed Cloud にインストールされた Stackdriver エージェントは、クラスタの問題の管理とトラブルシューティングを目的として、システム コンポーネントに関するデータを収集します。以降のセクションでは、Stackdriver の構成とオペレーティング モードについて説明します。
システム コンポーネントのみ(デフォルト モード)
Stackdriver エージェントはインストール時に、デフォルトでログと指標を収集するように構成されます。Google 提供のシステム コンポーネントのパフォーマンス詳細(CPU やメモリ使用率など)などのメタデータを収集します。管理クラスタ内のすべてのワークロード、およびユーザー クラスタでは、コンポーネントに kube-system、gke-system、gke-connect、istio-system、config-management-system 名前空間のワークロードが含まれます。
システム コンポーネントとアプリケーション
デフォルト モードでアプリケーションのロギングとモニタリングを有効にするには、アプリケーションのロギングとモニタリングを有効にするの手順に沿って行います。
最適化された指標(デフォルト指標)
デフォルトでは、クラスタで実行される kube-state-metrics Deployment は、最適化された一連の kube 指標を収集して Google Cloud Observability(旧称 Stackdriver)に報告します。
この最適化された一連の指標を収集するために必要なリソースは少ないため、全体的なパフォーマンスとスケーラビリティを向上させることができます。
最適化された指標を無効にする(推奨しません)には、Stackdriver カスタム リソースのデフォルト設定をオーバーライドします。
選択したシステム コンポーネントに Google Cloud Managed Service for Prometheus を使用する
Google Cloud Managed Service for Prometheus は Cloud Monitoring の一部であり、システム コンポーネントのオプションとして使用できます。Google Cloud Managed Service for Prometheus のメリットは次のとおりです。
アラートや Grafana ダッシュボードを変更することなく、既存の Prometheus ベースのモニタリングを引き続き使用できます。
GKE と Google Distributed Cloud の両方を使用する場合、すべてのクラスタで同じ Prometheus Query Language(PromQL)を指標として使用できます。 Google Cloud コンソールの Metrics Explorer で、[PromQL] タブを使用することもできます。
Google Cloud Managed Service for Prometheus の有効化と無効化
Google Distributed Cloud リリース 1.30.0-gke.1930 以降では、Google Cloud Managed Service for Prometheus は常に有効になっています。以前のバージョンでは、Stackdriver リソース stackdriver を編集して、Google Cloud Managed Service for Prometheus を有効または無効にできます。1.30.0-gke.1930 より前のクラスタ バージョンで Google Cloud Managed Service for Prometheus を無効にするには、stackdriver リソースの spec.featureGates.enableGMPForSystemMetrics を false に設定します。
指標データを表示する
enableGMPForSystemMetrics を true に設定すると、以下のコンポーネントの指標は、Cloud Monitoring での保存方法とクエリの方法が異なる形式になります。
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- kubelet と cadvisor
- kube-state-metrics
- node-exporter
新しい形式では、Prometheus Query Language(PromQL)を使用して、前述の指標をクエリできます。
次に PromQL クエリの例を示します。
histogram_quantile(0.95, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))
Google Cloud Managed Service for Prometheus を使用した Grafana ダッシュボードの構成
Google Cloud Managed Service for Prometheus の指標データで Grafana を使用するには、まず Grafana データソースを構成して認証する必要があります。データソースを構成して認証するには、データソース同期ツール(datasource-syncer)を使用して OAuth2 認証情報を生成し、Grafana データソース API を介して Grafana に同期します。データソース同期ツールは、Grafana のデータソースで Cloud Monitoring API を Prometheus サーバー URL(URL 値は https://monitoring.googleapis.com で始まる)として設定します。
Grafana を使用したクエリの手順に沿って、Google Cloud Managed Service for Prometheus からデータをクエリするように Grafana データソースを認証し、構成します。
サンプルの Grafana ダッシュボードは、GitHub の anthos-samples リポジトリで提供されています。サンプル ダッシュボードをインストールする手順は次のとおりです。
サンプル JSON ファイルをダウンロードします。
git clone https://github.com/GoogleCloudPlatform/anthos-samples.git cd anthos-samples/gmp-grafana-dashboards
Grafana データソースを
Managed Service for Prometheusと異なる名前で作成している場合は、すべての JSON ファイルのdatasourceフィールドを変更します。sed -i "s/Managed Service for Prometheus/[DATASOURCE_NAME]/g" ./*.json
[DATASOURCE_NAME] は、Prometheus
frontendサービスを指す Grafana のデータソースの名前に置き換えます。ブラウザから Grafana UI にアクセスし、[Dashboards] メニューの [+ Import] を選択します。
JSON ファイルをアップロードするか、ファイルの内容をコピーして貼り付けて、[読み込む] を選択します。ファイルの内容が正常に読み込まれたら、[インポートする] を選択します。必要に応じて、インポートする前にダッシュボード名と UID を変更することもできます。
Google Distributed Cloud とデータソースが正しく構成されていれば、インポートされたダッシュボードは正常に読み込まれます。たとえば、次のスクリーンショットでは、
cluster-capacity.jsonによって構成されたダッシュボードを示します。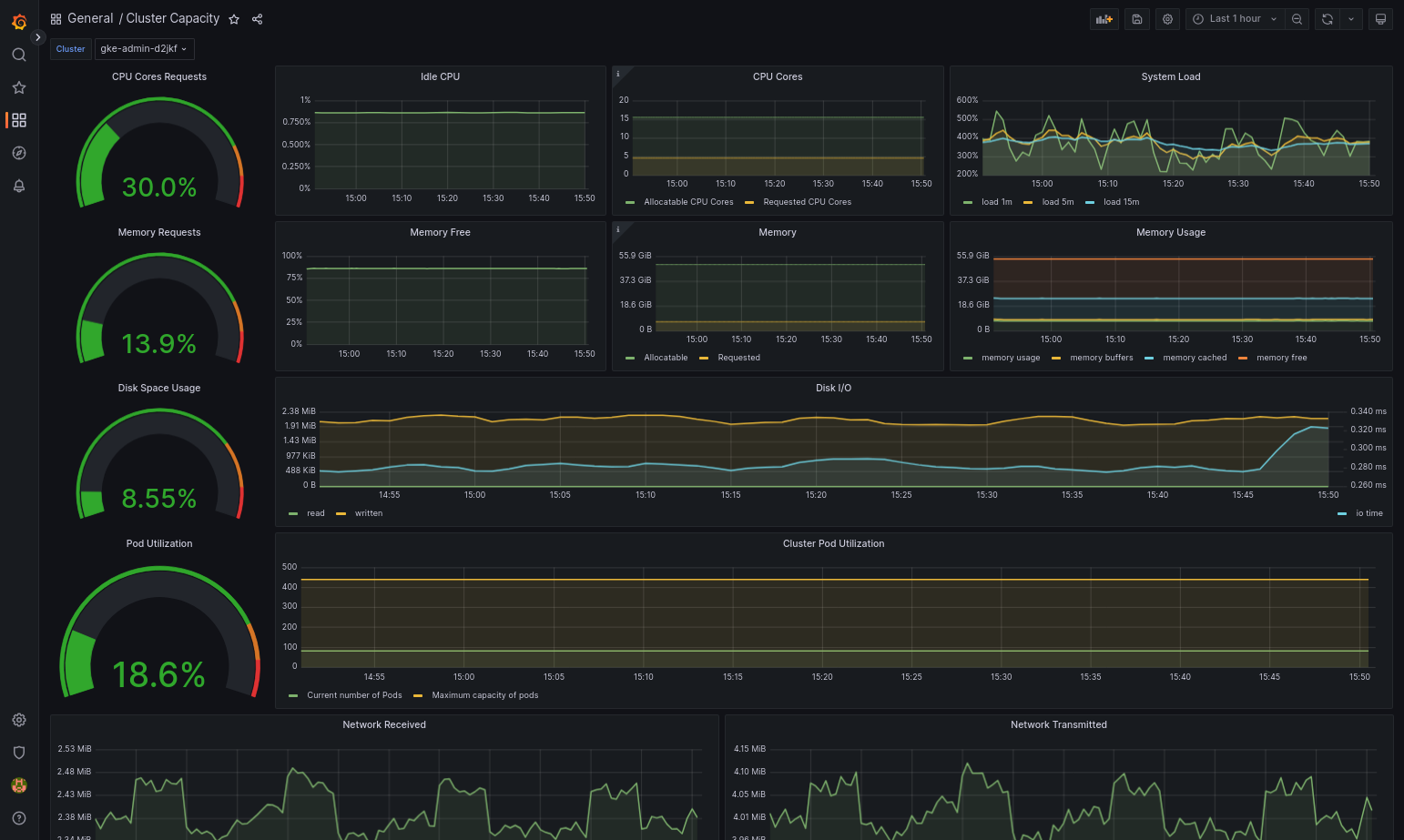
参考情報
Google Cloud Managed Service for Prometheus の詳細については、以下をご覧ください。
Stackdriver コンポーネント リソースの構成
クラスタを作成すると、Google Distributed Cloud が Stackdriver カスタム リソースを自動的に作成します。カスタム リソースの仕様を編集して、Stackdriver コンポーネントの CPU リクエストとメモリ リクエストのデフォルト値と上限をオーバーライドできます。また、デフォルトの最適化された指標の設定を個別にオーバーライドすることもできます。
Stackdriver コンポーネントのデフォルトの CPU およびメモリのリクエストと上限をオーバーライドする
Pod 密度が高いクラスタでは、ロギングとモニタリングのオーバーヘッドが増加します。極端な場合、Stackdriver コンポーネントにより、CPU とメモリの使用率が上限に近いことが報告されるか、リソースの上限が原因の再起動が繰り返し発生することがあります。この場合、Stackdriver コンポーネントの CPU とメモリのリクエストおよび制限のデフォルト値をオーバーライドするには、次の手順を行います。
次のコマンドを実行して、コマンドライン エディタで Stackdriver カスタム リソースを開きます。
kubectl -n kube-system edit stackdriver stackdriver
Stackdriver カスタム リソースで、
specフィールドの下にresourceAttrOverrideセクションを追加します。resourceAttrOverride: DAEMONSET_OR_DEPLOYMENT_NAME/CONTAINER_NAME: LIMITS_OR_REQUESTS: RESOURCE: RESOURCE_QUANTITYresourceAttrOverrideセクションは、指定したコンポーネントの既存のデフォルトの制限とリクエストをすべてオーバーライドします。次のコンポーネントは、resourceAttrOverrideによってサポートされています。gke-metrics-agent/gke-metrics-agentstackdriver-log-forwarder/stackdriver-log-forwarderstackdriver-metadata-agent-cluster-level/metadata-agentnode-exporter/node-exporterkube-state-metrics/kube-state-metrics
サンプル ファイルは次のようになります。
apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a resourceAttrOverride: gke-metrics-agent/gke-metrics-agent: requests: cpu: 110m memory: 240Mi limits: cpu: 200m memory: 4.5GiStackdriver カスタム リソースに対する変更を保存するには、保存してコマンドライン エディタを終了します。
Pod のヘルスチェックを行います。
kubectl -n kube-system get pods -l "managed-by=stackdriver"
正常な Pod のレスポンスは次のようになります。
gke-metrics-agent-4th8r 1/1 Running 1 40h
コンポーネントの Pod 仕様を確認して、リソースが正しく設定されていることを確認します。
kubectl -n kube-system describe pod POD_NAME
POD_NAMEは、変更した Pod の名前に置き換えます。例:gke-metrics-agent-4th8rレスポンスは次のようになります。
Name: gke-metrics-agent-4th8r Namespace: kube-system ... Containers: gke-metrics-agent: Limits: cpu: 200m memory: 4.5Gi Requests: cpu: 110m memory: 240Mi ...
最適化された指標を無効にする
デフォルトでは、クラスタで実行される kube-state-metrics Deployment は、最適化された一連の kube 指標を収集して Stackdriver に報告します。追加の指標が必要な場合は、Google Distributed Cloud の指標のリストから代替指標を見つけることをおすすめします。
使用可能な代替措置の例を以下に示します。
| 無効な指標 | 代替措置 |
|---|---|
kube_pod_start_time |
container/uptime |
kube_pod_container_resource_requests |
container/cpu/request_cores container/memory/request_bytes |
kube_pod_container_resource_limits |
container/cpu/limit_cores container/memory/limit_bytes |
最適化された指標のデフォルト設定を無効にする(おすすめしません)には、次の手順を行います。
コマンドライン エディタで Stackdriver カスタム リソースを開きます。
kubectl -n kube-system edit stackdriver stackdriver
optimizedMetricsフィールドをfalseに設定します。apiVersion: addons.gke.io/v1alpha1 kind: Stackdriver metadata: name: stackdriver namespace: kube-system spec: anthosDistribution: baremetal projectID: my-project clusterName: my-cluster clusterLocation: us-west-1a optimizedMetrics: false
変更を保存してコマンドライン エディタを終了します。
指標サーバー
Metrics Server は、さまざまな自動スケーリング パイプラインに対するコンテナ リソース指標のソースです。Metrics Server は、kubelets から指標を取得し、Kubernetes Metrics API を介して公開します。これらの指標は、HPA と VPA により自動スケーリング開始の判断に使われます。Metrics Server は、アドオンリサイザーを使用してスケーリングされます。
Pod 密度の高さが原因で、ロギングとモニタリングのオーバーヘッドが大きくなりすぎている場合は、リソースの上限により Metrics Server が停止、再起動されることがあります。この場合は、gke-managed-metrics-server Namespace の metrics-server-config ConfigMap を編集し、cpuPerNode と memoryPerNode の値を変更することで、指標サーバーにより多くのリソースを割り当てることができます。
kubectl edit cm metrics-server-config -n gke-managed-metrics-server
ConfigMap の内容の例:
apiVersion: v1
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
cpuPerNode: 3m
memoryPerNode: 20Mi
kind: ConfigMap
ConfigMap を更新したら、次のコマンドを使用して metrics-server Pod を再作成します。
kubectl delete pod -l k8s-app=metrics-server -n gke-managed-metrics-server
ログと指標のルーティング
Stackdriver Log Forwarder(stackdriver-log-forwarder)は、各ノードマシンから Cloud Logging にログを送信します。同様に、GKE 指標エージェント(gke-metrics-agent)は、各ノードマシンから Cloud Monitoring に指標を送信します。ログと指標が送信される前に、Stackdriver Operator(stackdriver-operator)は、stackdriver カスタム リソースの clusterLocation フィールドの値を各ログエントリと指標に関連付けてから Google Cloudに転送します。また、ログと指標は、stackdriver カスタム リソース仕様(spec.projectID)で指定された Google Cloud プロジェクトに関連付けられます。
stackdriver リソースは、クラスタの作成時に、クラスタ リソースの clusterOperations セクションの location フィールドと projectID フィールドから clusterLocation フィールドと projectID フィールドの値を取得します。
Stackdriver エージェントによって送信されたすべての指標とログエントリは、グローバル取り込みエンドポイントにルーティングされます。そこから、データ転送の信頼性を確保するために、最も近い到達可能なリージョン Google Cloud エンドポイントにデータが転送されます。
グローバル エンドポイントが指標またはログエントリを受信した後の処理は、サービスによって異なります。
ログの転送の構成方法: ロギング エンドポイントがログメッセージを受信すると、Cloud Logging はログルーターを介してメッセージを渡します。ログルーター構成のシンクとフィルタによって、メッセージの転送方法が決まります。ログエントリは、ログエントリを保存するリージョン Logging バケットなどの宛先や、Pub/Sub に転送できます。ログの転送の仕組みと構成方法の詳細については、転送とストレージの概要をご覧ください。
この転送プロセスでは、
stackdriverカスタム リソースのclusterLocationフィールドと Cluster 仕様のclusterOperations.locationフィールドは考慮されません。ログの場合、clusterLocationはログエントリのラベル付けにのみ使用されます。これは、ログ エクスプローラでのフィルタリングに役立ちます。指標のルーティングの構成方法: 指標エンドポイントが指標エントリを受信すると、エントリは自動的にルーティングされ、指標で指定されたロケーションに保存されます。指標のロケーションは、
stackdriverカスタム リソースのclusterLocationフィールドから取得されました。構成を計画する: Cloud Logging と Cloud Monitoring を構成するときに、ログルーターを構成し、ニーズに最適なロケーションで適切な
clusterOperations.locationを指定します。たとえば、ログと指標を同じロケーションに送信する場合は、clusterOperations.locationを、Log Router が Google Cloud プロジェクトに使用している同じ Google Cloud リージョンに設定します。必要に応じてログ構成を更新する: 障害復旧計画などのビジネス要件により、ログの宛先設定はいつでも変更できます。Google Cloud のログルーター構成の変更はすぐに有効になります。クラスタ リソースの
clusterOperationsセクションのlocationフィールドとprojectIDフィールドは変更不可であるため、クラスタの作成後に更新することはできません。stackdriverリソースの値を直接変更することはおすすめしません。このリソースは、アップグレードなどのクラスタ オペレーションによって調整がトリガーされるたびに、元のクラスタ作成状態に戻ります。
Logging と Monitoring の構成要件
Google Distributed Cloud で Cloud Logging と Cloud Monitoring を有効にするには、いくつかの構成要件があります。これらの手順は、Google サービスの有効化ページのLogging と Monitoring で使用するサービス アカウントの構成と、次のリストに含まれています。
- Cloud Monitoring ワークスペースは、Google Cloud プロジェクト内に作成する必要があります。これを行うには、Google Cloud コンソールで [モニタリング] をクリックし、ワークフローに従います。
次の Stackdriver API を有効にする必要があります。
Stackdriver エージェントが使用するサービス アカウントに次の IAM ロールを割り当てる必要があります。
logging.logWritermonitoring.metricWriterstackdriver.resourceMetadata.writermonitoring.dashboardEditoropsconfigmonitoring.resourceMetadata.writer
ログタグ
多くの Google Distributed Cloud ログには F タグが付いています。
logtag: "F"
このタグは、ログエントリが完了またはフルであることを示します。このタグの詳細については、GitHub の Kubernetes 設計プロポーザルのログ形式をご覧ください。
料金
Google Distributed Cloud クラスタでは、システムログと指標には次のものが含まれます。
- 管理クラスタ内のすべてのコンポーネントのログと指標。
- ユーザー クラスタ内の次の名前空間のコンポーネントのログと指標:
kube-system、gke-system、gke-connect、knative-serving、istio-system、monitoring-system、config-management-system、gatekeeper-system、cnrm-system。
詳細については、Google Cloud Observability の料金をご覧ください。
Cloud Logging の指標のクレジットについては、販売担当者にお問い合わせください。