Teradata
Mit dem Teradata-Connector können Sie Vorgänge zum Einfügen, Löschen, Aktualisieren und Lesen in einer Teradata-Datenbank ausführen.
Hinweis
Führen Sie vor der Verwendung des Teradata-Connectors die folgenden Aufgaben aus:
- In Ihrem Google Cloud-Projekt:
- Prüfen Sie, ob eine Netzwerkverbindung eingerichtet ist. Informationen zu Netzwerkmustern finden Sie unter Netzwerkkonnektivität.
- Weisen Sie dem Nutzer, der den Connector konfiguriert, die IAM-Rolle roles/connectors.admin zu.
- Weisen Sie dem Dienstkonto, das Sie für den Connector verwenden möchten, die folgenden IAM-Rollen zu:
roles/secretmanager.viewerroles/secretmanager.secretAccessor
Ein Dienstkonto ist eine spezielle Art von Google-Konto, das einen nicht menschlichen Nutzer repräsentiert. Es muss authentifiziert und autorisiert werden, um Zugriff auf Daten in Google APIs zu erhalten. Wenn Sie kein Dienstkonto haben, müssen Sie eins erstellen. Der Connector und das Dienstkonto müssen zum selben Projekt gehören. Weitere Informationen finden Sie unter Dienstkonto erstellen.
- Aktivieren Sie die folgenden Dienste:
secretmanager.googleapis.com(Secret Manager API)connectors.googleapis.com(Connectors API)
Informationen zum Aktivieren von Diensten finden Sie unter Dienste aktivieren.
Wenn diese Dienste oder Berechtigungen für Ihr Projekt zuvor nicht aktiviert wurden, werden Sie aufgefordert, sie beim Konfigurieren des Connectors zu aktivieren.
Teradata-Konfiguration
Informationen zum Erstellen einer Teradata Vantage Express-Instanz auf einer Google Cloud-VM finden Sie unter Teradata auf einer Google Cloud-VM installieren. Wenn diese VM öffentlich zugänglich ist, kann die externe IP-Adresse dieser VM als Hostadresse verwendet werden, wenn Sie eine Verbindung herstellen. Wenn die VM nicht öffentlich zugänglich ist, erstellen Sie eine Private Service Connect-Verbindung und verwenden Sie die IP-Adresse des Netzwerkendpunktanhangs, wenn Sie eine Verbindung erstellen.
Connector konfigurieren
Eine Verbindung ist für eine Datenquelle spezifisch. Wenn Sie also viele Datenquellen haben, müssen Sie für jede Datenquelle eine separate Verbindung erstellen. So erstellen Sie eine Verbindung:
- Rufen Sie in der Cloud Console die Seite Integration Connectors > Verbindungen auf und wählen Sie ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Klicken Sie auf + NEU ERSTELLEN, um die Seite Verbindung erstellen zu öffnen.
- Wählen Sie im Abschnitt Standort den Standort für die Verbindung aus.
- Region: Wählen Sie einen Standort aus der Drop-down-Liste aus.
Eine Liste aller unterstützten Regionen finden Sie unter Standorte.
- Klicken Sie auf Weiter.
- Region: Wählen Sie einen Standort aus der Drop-down-Liste aus.
- Führen Sie im Abschnitt Verbindungsdetails folgende Schritte aus:
- Connector: Wählen Sie Teradata aus der Drop-down-Liste der verfügbaren Connectors aus.
- Connector-Version: Wählen Sie die Connector-Version aus der Drop-down-Liste der verfügbaren Versionen aus.
- Geben Sie im Feld Verbindungsname einen Namen für die Verbindungsinstanz ein.
Verbindungsnamen müssen die folgenden Kriterien erfüllen:
- Verbindungsnamen können Buchstaben, Ziffern oder Bindestriche enthalten.
- Buchstaben müssen Kleinbuchstaben sein.
- Verbindungsnamen müssen mit einem Buchstaben beginnen und mit einem Buchstaben oder einer Ziffer enden.
- Verbindungsnamen dürfen maximal 49 Zeichen haben.
- Geben Sie optional unter Beschreibung eine Beschreibung für die Verbindungsinstanz ein.
- Optional können Sie Cloud Logging aktivieren und dann eine Logebene auswählen. Die Logebene ist standardmäßig auf
Errorfestgelegt. - Dienstkonto: Wählen Sie ein Dienstkonto, das über die erforderlichen Rollen verfügt.
- Konfigurieren Sie optional die Verbindungsknoteneinstellungen:
- Mindestanzahl von Knoten: Geben Sie die Mindestanzahl von Verbindungsknoten ein.
- Maximale Anzahl von Knoten: Geben Sie die maximale Anzahl von Verbindungsknoten ein.
Ein Knoten ist eine Einheit (oder ein Replikat) einer Verbindung, die Transaktionen verarbeitet. Zur Verarbeitung von mehr Transaktionen für eine Verbindung sind mehr Knoten erforderlich. Umgekehrt sind weniger Knoten erforderlich, um weniger Transaktionen zu verarbeiten. Informationen zu den Auswirkungen der Knoten auf Ihre Connector-Preise finden Sie unter Preise für Verbindungsknoten. Wenn Sie keine Werte eingeben, ist die Mindestanzahl von Knoten standardmäßig auf 2 (für eine bessere Verfügbarkeit) und die maximale Knotenzahl auf 50 gesetzt.
- Datenbank: Die Datenbank, die als Standarddatenbank ausgewählt wird, wenn eine Teradata-Verbindung geöffnet wird.
- Charset: Gibt den Sitzungszeichensatz für die Codierung und Decodierung von Zeichendaten an, die zur und von der Teradata-Datenbank übertragen werden. Der Standardwert ist ASCII.
- Klicken Sie optional auf + Label hinzufügen, um der Verbindung ein Label in Form eines Schlüssel/Wert-Paars hinzuzufügen.
- Klicken Sie auf Weiter.
- Geben Sie im Abschnitt Ziele die Details zum Remote-Host (Backend-System) ein, zu dem Sie eine Verbindung herstellen möchten.
- Zieltyp: Wählen Sie einen Zieltyp aus.
- Wenn Sie den Zielhostnamen oder die Ziel-IP-Adresse angeben möchten, wählen Sie Hostadresse aus und geben Sie die Adresse in das Feld Host 1 ein.
- Wenn Sie eine private Verbindung herstellen möchten, wählen Sie Endpunktanhang aus und wählen Sie den erforderlichen Anhang aus der Liste Endpunktanhang aus.
Wenn Sie eine öffentliche Verbindung zu Ihren Back-End-Systemen mit zusätzlicher Sicherheit herstellen möchten, können Sie statische ausgehende IP-Adressen für Ihre Verbindungen konfigurieren und dann Ihre Firewallregeln konfigurieren, um nur bestimmte statische IP-Adressen zuzulassen.
Wenn Sie weitere Ziele eingeben möchten, klicken Sie auf + Ziel hinzufügen.
- Klicken Sie auf Weiter.
- Zieltyp: Wählen Sie einen Zieltyp aus.
-
Geben Sie im Abschnitt Authentifizierung die Authentifizierungsdetails ein.
- Wählen Sie einen Authentifizierungstyp aus und geben Sie die relevanten Details ein.
Die folgenden Authentifizierungstypen werden von der Teradata-Verbindung unterstützt:
- Nutzername und Passwort
- Klicken Sie auf Next (Weiter).
Informationen zum Konfigurieren dieser Authentifizierungstypen finden Sie unter Authentifizierung konfigurieren.
- Wählen Sie einen Authentifizierungstyp aus und geben Sie die relevanten Details ein.
- Überprüfen: Prüfen Sie Ihre Verbindungs- und Authentifizierungsdetails.
- Klicken Sie auf Erstellen.
Authentifizierung konfigurieren
Geben Sie die Details basierend auf der zu verwendenden Authentifizierung ein.
-
Nutzername und Passwort
- Nutzername: Nutzername für den Connector
- Passwort: Secret Manager-Secret mit dem Passwort, das mit dem Connector verknüpft ist.
Beispiele für Verbindungskonfigurationen
In diesem Abschnitt finden Sie Beispielwerte für die verschiedenen Felder, die Sie beim Erstellen eines Teradata-Connectors konfigurieren.
Basisauthentifizierung – Verbindungstyp
| Feldname | Details |
|---|---|
| Standort | us-central1 |
| Connector | Teradata |
| Connector-Version | 1 |
| Verbindungsname | teradata-vm-connection |
| Cloud Logging aktivieren | Ja |
| Dienstkonto | SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com |
| Datenbank | TERADATA_TESTDB |
| Zeichensatz | ASCII |
| Mindestanzahl von Knoten | 2 |
| Maximale Anzahl von Knoten | 2 |
| Zieltyp | Hostadresse |
| Host 1 | 203.0.113.255 |
| Port 1 | 1025 |
| Nutzername | NUTZERNAME |
| Passwort | PASSWORT |
| Secret-Version | 1 |
Entitäten, Vorgänge und Aktionen
Alle Integration Connectors bieten eine Abstraktionsebene für die Objekte der verbundenen Anwendung. Sie können nur über diese Abstraktion auf die Objekte einer Anwendung zugreifen. Die Abstraktion wird Ihnen als Entitäten, Vorgänge und Aktionen zur Verfügung gestellt.
- Entität: Eine Entität kann als Objekt oder Sammlung von Attributen in der verbundenen Anwendung oder im verbundenen Dienst verstanden werden. Die Definition einer Entität unterscheidet sich von Connector zu Connector. Beispiel: In einem Datenbank-Connector sind Tabellen die Entitäten, in einem Dateiserver-Connector sind Ordner die Entitäten und in einem Nachrichtensystem-Connector sind Warteschlangen die Entitäten.
Es ist jedoch möglich, dass ein Connector keine Entitäten unterstützt oder keine Entitäten enthält. In diesem Fall ist die Liste
Entitiesleer. - Vorgang: Ein Vorgang ist die Aktivität, die Sie für eine Entität ausführen können. Sie können einen der folgenden Vorgänge für eine Entität ausführen:
Durch Auswahl einer Entität aus der verfügbaren Liste wird eine Liste der Vorgänge generiert, die für die Entität verfügbar sind. Eine detaillierte Beschreibung der Vorgänge finden Sie in den Entitätsvorgängen der Connectors-Aufgabe. Wenn ein Connector jedoch keine der Entitätsvorgänge unterstützt, werden solche nicht unterstützten Vorgänge nicht in der
Operations-Liste aufgeführt. - Aktion: Eine Aktion ist eine Funktion erster Klasse, die über die Connector-Benutzeroberfläche für die Integration verfügbar gemacht wird. Mit einer Aktion können Sie Änderungen an einer oder mehreren Entitäten vornehmen, die von Connector zu Connector unterschiedlich sind. Normalerweise hat eine Aktion einige Eingabeparameter und einen Ausgabeparameter. Es ist jedoch möglich, dass ein Connector keine Aktionen unterstützt. In diesem Fall ist die
Actions-Liste leer.
Aktionen
Dieser Connector unterstützt die Ausführung der folgenden Aktionen:
- Benutzerdefinierte gespeicherte Prozeduren und Funktionen: Wenn Sie gespeicherte Prozeduren und Funktionen in Ihrem Backend haben, werden diese in der Spalte
Actionsdes DialogfeldsConfigure connector taskaufgeführt. - Benutzerdefinierte SQL-Abfragen: Zum Ausführen benutzerdefinierter SQL-Abfragen bietet der Connector die Aktion Benutzerdefinierte Abfrage ausführen.
So erstellen Sie eine benutzerdefinierte Abfrage:
- Folgen Sie der detaillierten Anleitung zum Hinzufügen einer Connectors-Aufgabe.
- Wenn Sie die Connector-Aufgabe konfigurieren, wählen Sie unter „Art der auszuführenden Aktion“ die Option Aktionen aus.
- Wählen Sie in der Liste Aktion die Option Benutzerdefinierte Abfrage ausführen aus und klicken Sie dann auf Fertig.

- Maximieren Sie den Abschnitt Aufgabeneingabe und gehen Sie dann so vor:
- Geben Sie im Feld Zeitlimit nach die Anzahl der Sekunden ein, die gewartet werden soll, bis die Abfrage ausgeführt wird.
Standardwert:
180Sekunden. - Geben Sie im Feld Maximale Zeilenanzahl die maximale Anzahl der Zeilen ein, die aus der Datenbank zurückgegeben werden sollen.
Standardwert:
25. - Wenn Sie die benutzerdefinierte Abfrage aktualisieren möchten, klicken Sie auf Benutzerdefiniertes Skript bearbeiten. Das Dialogfeld Skripteditor wird geöffnet.
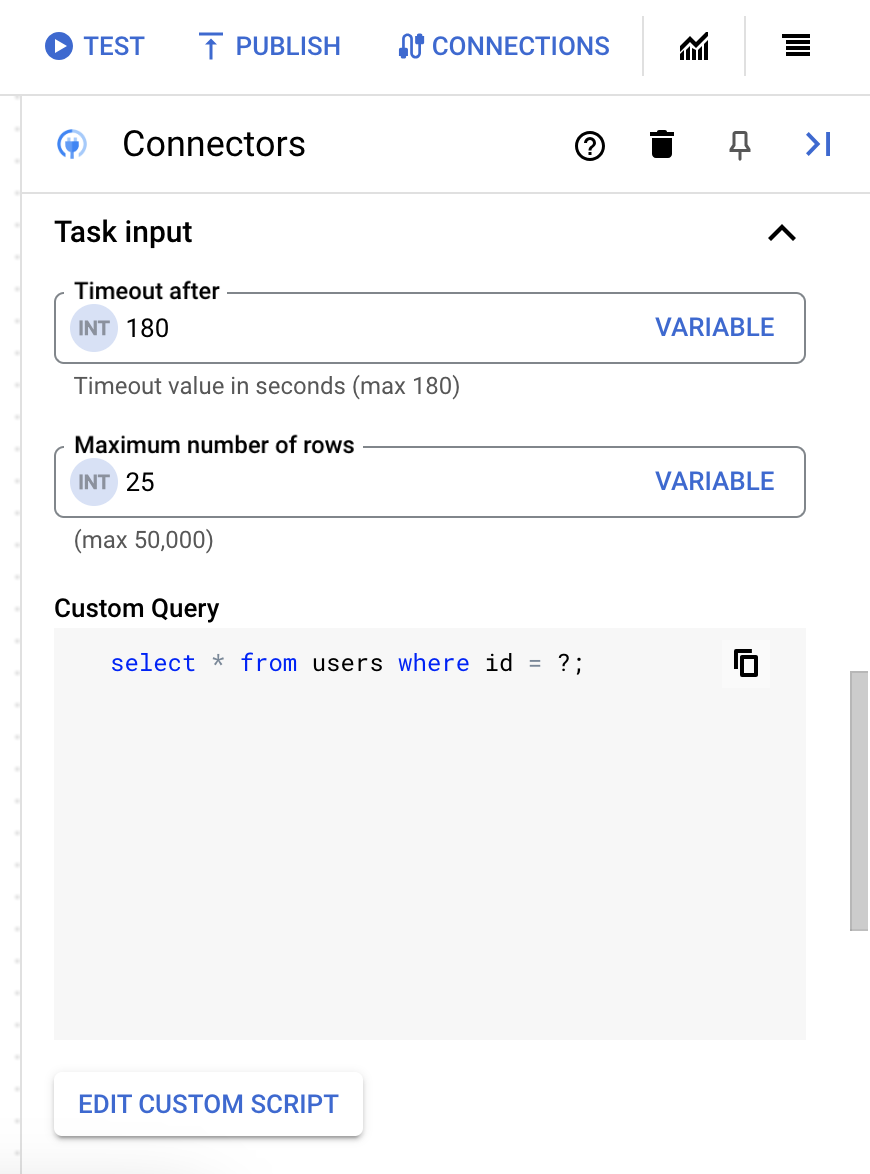
- Geben Sie im Dialogfeld Skripteditor die SQL-Abfrage ein und klicken Sie auf Speichern.
Sie können ein Fragezeichen (?) in einer SQL-Anweisung verwenden, um einen einzelnen Parameter darzustellen, der in der Liste der Abfrageparameter angegeben werden muss. Mit der folgenden SQL-Abfrage werden beispielsweise alle Zeilen aus der Tabelle
Employeesausgewählt, die den für die SpalteLastNameangegebenen Werten entsprechen:SELECT * FROM Employees where LastName=?
- Wenn Sie Fragezeichen in Ihrer SQL-Abfrage verwendet haben, müssen Sie den Parameter hinzufügen, indem Sie für jedes Fragezeichen auf + Parameternamen hinzufügen klicken. Bei der Ausführung der Integration werden diese Parameter sequenziell durch die Fragezeichen (?) in der SQL-Abfrage ersetzt. Wenn Sie beispielsweise drei Fragezeichen (?) hinzugefügt haben, müssen Sie drei Parameter in der richtigen Reihenfolge hinzufügen.
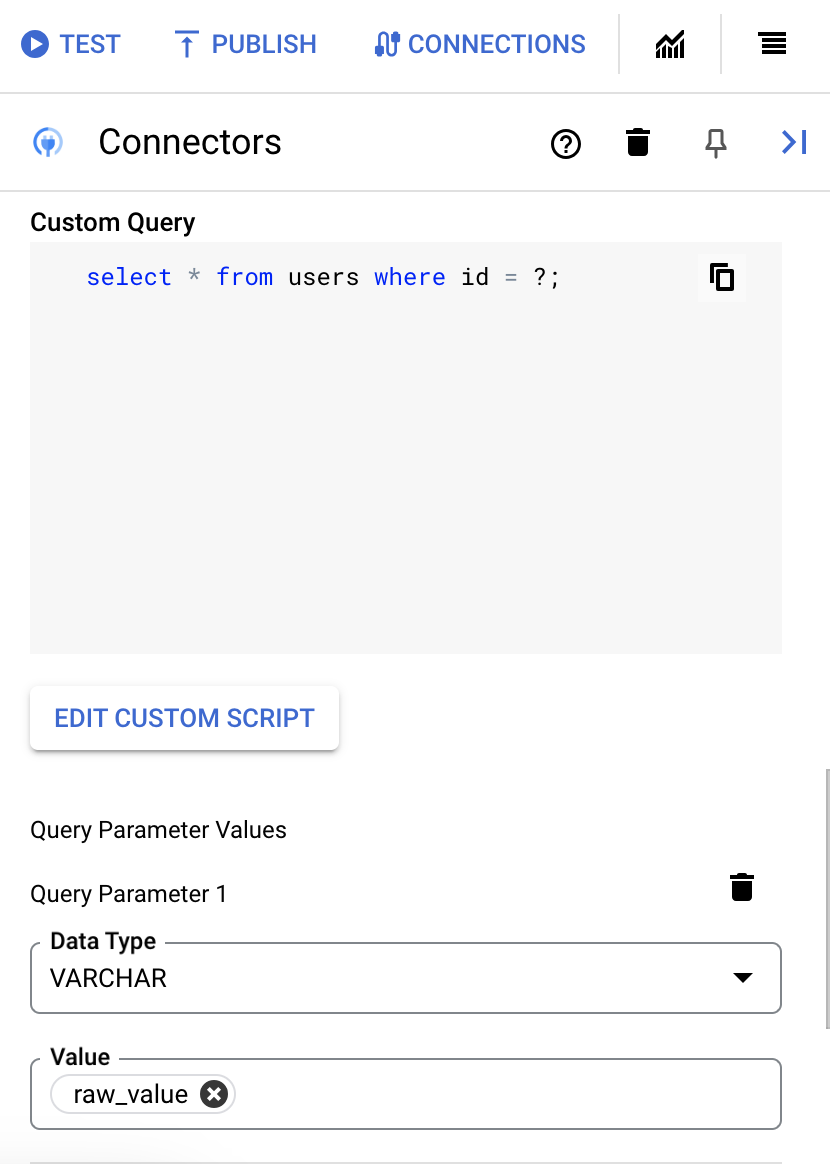
So fügen Sie Abfrageparameter hinzu:
- Wählen Sie in der Liste Typ den Datentyp des Parameters aus.
- Geben Sie im Feld Wert den Wert des Parameters ein.
- Wenn Sie mehrere Parameter hinzufügen möchten, klicken Sie auf + Abfrageparameter hinzufügen.
Die Aktion Benutzerdefinierte Abfrage ausführen unterstützt keine Array-Variablen.
- Geben Sie im Feld Zeitlimit nach die Anzahl der Sekunden ein, die gewartet werden soll, bis die Abfrage ausgeführt wird.
Systembeschränkungen
Der Teradata-Connector kann maximal 70 Transaktionen pro Sekunde und Knoten verarbeiten. Alle Transaktionen, die dieses Limit überschreiten, werden gedrosselt. Standardmäßig werden für eine Verbindung zwei Knoten (für eine bessere Verfügbarkeit) zugewiesen.
Informationen zu den für Integration Connectors geltenden Limits finden Sie unter Limits.
Unterstützte Datentypen
Die folgenden Datentypen werden für diesen Connector unterstützt:
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- UHRZEIT
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
Aktionen
Mit dem Oracle DB-Connector können Sie Ihre gespeicherten Prozeduren, Funktionen und benutzerdefinierten SQL-Abfragen in dem Format ausführen, das von Ihrer Oracle-Datenbank unterstützt wird. Zum Ausführen benutzerdefinierter SQL-Abfragen bietet der Connector die Aktion ExecuteCustomQuery.
Aktion „ExecuteCustomQuery“
Mit dieser Aktion können Sie benutzerdefinierte SQL-Abfragen ausführen.
Eingabeparameter der ExecuteCustomQuery-Aktion
| Parametername | Datentyp | Erforderlich | Beschreibung |
|---|---|---|---|
| Abfrage | String | Ja | Die auszuführende Abfrage. |
| queryParameters | JSON-Array im folgenden Format:[{"value": "VALUE", "dataType": "DATA_TYPE"}]
|
Nein | Suchparameter. |
| maxRows | Zahl | Nein | Maximale Anzahl der zurückzugebenden Zeilen. |
| Zeitüberschreitung | Zahl | Nein | Anzahl der Sekunden, die gewartet werden soll, bis die Abfrage ausgeführt wird. |
Ausgabeparameter der Aktion „ExecuteCustomQuery“
Bei erfolgreicher Ausführung gibt diese Aktion den Status 200 (OK) mit einem Antworttext zurück, der die Abfrageergebnisse enthält.
Beispiele für die Konfiguration der Aktion ExecuteCustomQuery finden Sie unter Beispiele.
Informationen zur Verwendung der Aktion ExecuteCustomQuery finden Sie unter Beispiele für Aktionen.
Beispiele für Aktionen
In diesem Abschnitt wird beschrieben, wie Sie einige der Aktionen in diesem Connector ausführen.
Beispiel: GROUP BY-Abfrage ausführen
- Klicken Sie im Dialogfeld
Configure connector taskaufActions. - Wählen Sie die Aktion
ExecuteCustomQueryaus und klicken Sie auf Fertig. - Klicken Sie im Bereich Aufgabeneingabe der Aufgabe Connectors auf
connectorInputPayloadund geben Sie dann einen Wert ähnlich dem folgenden in FeldDefault Valueein:{ "query": "select E.EMPLOYEE_ID,E.EMPLOYEE_NAME,E.CITY from EMPLOYEES E LEFT JOIN EMPLOYEE_DEPARTMENT ED ON E.EMPLOYEE_ID=ED.ID where E.EMPLOYEE_NAME = 'John' Group by E.CITY,E.EMPLOYEE_ID,E.EMPLOYEE_NAME" }
In diesem Beispiel werden die Mitarbeiterdatensätze aus den Tabellen EMPLOYEES und EMPLOYEE_DEPARTMENT ausgewählt. Wenn die Aktion erfolgreich ist, enthält der Antwortparameter connectorOutputPayload der Connector-Aufgabe das Abfrageergebnis.
Beispiel: Parametrisierte Abfrage ausführen
- Klicken Sie im Dialogfeld
Configure connector taskaufActions. - Wählen Sie die Aktion
ExecuteCustomQueryaus und klicken Sie auf Fertig. - Klicken Sie im Bereich Aufgabeneingabe der Aufgabe Connectors auf
connectorInputPayloadund geben Sie dann einen Wert ähnlich dem folgenden in FeldDefault Valueein:{ "query": "select C.ID,C.NAME,C.CITY,C.O_DATE,E.EMPLOYEE_ID from customqueries C,Employees E where C.ID=E.Employee_id and C.NAME=?", "queryParameters": [{ "value": "John", "dataType": "VARCHAR" }], "timeout":10, "maxRows":3 }
In diesem Beispiel werden Mitarbeiterdatensätze ausgewählt, in denen der Name des Mitarbeiters John ist.
Beachten Sie, dass der Name des Mitarbeiters mit dem Parameter queryParameters parametrisiert wird.
Wenn die Aktion erfolgreich ist, hat der Antwortparameter connectorOutputPayload der Connector-Aufgabe einen Wert, der dem folgenden ähnelt:
[{ "NAME": "John", "O_DATE": "2023-06-01 00:00:00.0", "EMPLOYEE_ID": 1.0 }, { "NAME": "John", "O_DATE": "2021-07-01 00:00:00.0", "EMPLOYEE_ID": 3.0 }, { "NAME": "John", "O_DATE": "2022-09-01 00:00:00.0", "EMPLOYEE_ID": 4.0 }]
Beispiel – Datensatz mit einem Sequenzwert einfügen
- Klicken Sie im Dialogfeld
Configure connector taskaufActions. - Wählen Sie die Aktion
ExecuteCustomQueryaus und klicken Sie auf Fertig. - Klicken Sie im Bereich Aufgabeneingabe der Aufgabe Connectors auf
connectorInputPayloadund geben Sie dann einen Wert ähnlich dem folgenden in FeldDefault Valueein:{ "query": "INSERT INTO AUTHOR(id,title) VALUES(author_table_id_seq.NEXTVAL,'Sample_book_title')" }
In diesem Beispiel wird ein Datensatz in die Tabelle AUTHOR eingefügt. Dazu wird ein vorhandenes author_table_id_seq-Sequenzobjekt verwendet. Wenn die Aktion erfolgreich ist, hat der Antwortparameter connectorOutputPayload der Connector-Aufgabe einen Wert, der dem folgenden ähnelt:
[{ }]
Beispiel: Abfrage mit einer Aggregatfunktion ausführen
- Klicken Sie im Dialogfeld
Configure connector taskaufActions. - Wählen Sie die Aktion
ExecuteCustomQueryaus und klicken Sie auf Fertig. - Klicken Sie im Bereich Aufgabeneingabe der Aufgabe Connectors auf
connectorInputPayloadund geben Sie dann einen Wert ähnlich dem folgenden in FeldDefault Valueein:{ "query": "SELECT SUM(SALARY) as Total FROM EMPLOYEES" }
In diesem Beispiel wird der aggregierte Wert der Gehälter in der Tabelle EMPLOYEES berechnet. Wenn die Aktion erfolgreich ist, hat der Antwortparameter connectorOutputPayload der Connector-Aufgabe einen Wert, der dem folgenden ähnelt:
[{ "TOTAL": 13000.0 }]
Beispiel: Neue Tabelle erstellen
- Klicken Sie im Dialogfeld
Configure connector taskaufActions. - Wählen Sie die Aktion
ExecuteCustomQueryaus und klicken Sie auf Fertig. - Klicken Sie im Bereich Aufgabeneingabe der Aufgabe Connectors auf
connectorInputPayloadund geben Sie dann einen Wert ähnlich dem folgenden in FeldDefault Valueein:{ "query": "CREATE TABLE TEST1 (ID INT, NAME VARCHAR(40),DEPT VARCHAR(20),CITY VARCHAR(10))" }
In diesem Beispiel wird die Tabelle TEST1 erstellt. Wenn die Aktion erfolgreich ist, hat der Antwortparameter connectorOutputPayload der Connector-Aufgabe einen Wert, der dem folgenden ähnelt:
[{ }]
Beispiele für Entitätsvorgänge
Beispiel: Alle Mitarbeiter auflisten
In diesem Beispiel werden alle Mitarbeiter in der Employee-Einheit aufgeführt.
- Klicken Sie im Dialogfeld
Configure connector taskaufEntities. - Wählen Sie
Employeeaus der ListeEntityaus. - Wählen Sie den Vorgang
Listaus und klicken Sie auf Fertig. - Optional können Sie im Bereich Aufgabeneingabe der Aufgabe Connectors das Ergebnisset filtern, indem Sie eine Filterklausel angeben.
Beispiel – Mitarbeiterdetails abrufen
In diesem Beispiel werden die Details des Mitarbeiters mit der angegebenen ID aus der Employee-Entität abgerufen.
- Klicken Sie im Dialogfeld
Configure connector taskaufEntities. - Wählen Sie
Employeeaus der ListeEntityaus. - Wählen Sie den Vorgang
Getaus und klicken Sie auf Fertig. - Klicken Sie im Bereich Aufgabeneingabe der Aufgabe Connectors auf EntityId und geben Sie dann
45in das Feld Standardwert ein.Dabei ist
45der Primärschlüsselwert der EntitätEmployee.
Beispiel: Mitarbeiterdatensatz erstellen
In diesem Beispiel wird der Entität Employee ein neuer Mitarbeiterdatensatz hinzugefügt.
- Klicken Sie im Dialogfeld
Configure connector taskaufEntities. - Wählen Sie
Employeeaus der ListeEntityaus. - Wählen Sie den Vorgang
Createaus und klicken Sie auf Fertig. - Klicken Sie im Bereich Aufgabeneingabe der Aufgabe Connectors auf
connectorInputPayloadund geben Sie dann einen Wert ähnlich dem folgenden in FeldDefault Valueein:{ "EMPLOYEE_ID": 69.0, "EMPLOYEE_NAME": "John", "CITY": "Bangalore" }
Wenn die Integration erfolgreich ist, hat das Feld
connectorOutputPayloadder Connector-Aufgabe einen Wert, der dem folgenden ähnelt:{ "ROWID": "AAAoU0AABAAAc3hAAF" }
Beispiel: Mitarbeiterdatensatz aktualisieren
In diesem Beispiel wird der Mitarbeiterdatensatz mit der ID 69 in der Entität Employee aktualisiert.
- Klicken Sie im Dialogfeld
Configure connector taskaufEntities. - Wählen Sie
Employeeaus der ListeEntityaus. - Wählen Sie den Vorgang
Updateaus und klicken Sie auf Fertig. - Klicken Sie im Bereich Aufgabeneingabe der Aufgabe Connectors auf
connectorInputPayloadund geben Sie dann einen Wert ähnlich dem folgenden in das FeldDefault Valueein:{ "EMPLOYEE_NAME": "John", "CITY": "Mumbai" }
- Klicken Sie auf entityId und geben Sie dann
69in das Feld Standardwert ein.Anstelle der entityId können Sie auch die filterClause auf
69festlegen.Wenn die Integration erfolgreich ist, hat das Feld
connectorOutputPayloadder Connector-Aufgabe einen Wert, der dem folgenden ähnelt:{ }
Beispiel: Mitarbeiterdatensatz löschen
In diesem Beispiel wird der Mitarbeiterdatensatz mit der angegebenen ID in der Entität Employee gelöscht.
- Klicken Sie im Dialogfeld
Configure connector taskaufEntities. - Wählen Sie
Employeeaus der ListeEntityaus. - Wählen Sie den Vorgang
Deleteaus und klicken Sie auf Fertig. - Klicken Sie im Bereich Aufgabeneingabe der Aufgabe Connectors auf entityId und geben Sie dann
35in das Feld Standardwert ein.
Verbindungen mit Terraform erstellen
Sie können die Terraform-Ressource verwenden, um eine neue Verbindung zu erstellen.
Informationen zum Anwenden oder Entfernen einer Terraform-Konfiguration finden Sie unter Grundlegende Terraform-Befehle.
Ein Beispiel für eine Terraform-Vorlage zum Erstellen einer Verbindung finden Sie hier.
Wenn Sie diese Verbindung mit Terraform erstellen, müssen Sie die folgenden Variablen in Ihrer Terraform-Konfigurationsdatei festlegen:
| Parametername | Datentyp | Erforderlich | Beschreibung |
|---|---|---|---|
| client_charset | STRING | Wahr | Gibt den Java-Zeichensatz für die Codierung und Decodierung von Zeichendaten an, die zur und von der Teradata-Datenbank übertragen werden. |
| Datenbank | STRING | Wahr | Die Datenbank, die als Standarddatenbank ausgewählt wird, wenn eine Teradata-Verbindung geöffnet wird. |
| Konto | STRING | Falsch | Gibt einen Kontostring an, um den für den Teradata-Datenbanknutzer definierten Standardstring zu überschreiben. |
| charset | STRING | Wahr | Gibt den Sitzungszeichensatz für die Codierung und Decodierung von Zeichendaten an, die zur und von der Teradata-Datenbank übertragen werden. Der Standardwert ist ASCII. |
| column_name | INTEGER | Wahr | Steuert das Verhalten der Methoden „ResultSetMetaData getColumnName“ und „getColumnLabel“. |
| connect_failure_ttl | STRING | Falsch | Mit dieser Option kann sich der CData ADO.NET-Anbieter für Teradata den Zeitpunkt des letzten Verbindungsfehlers für jede Kombination aus IP-Adresse und Port merken. Darüber hinaus überspringt der CData ADO.NET-Anbieter für Teradata die Verbindungsversuche zu dieser IP-Adresse bzw. diesem Port bei nachfolgenden Anmeldungen für die durch den Wert CONNECTFAILURETTL (Connect Failure time-to-live) festgelegte Anzahl von Sekunden. |
| connect_function | STRING | Falsch | Gibt an, ob die Teradata-Datenbank eine Anmeldesequenznummer (LSN) für diese Sitzung zuweisen oder diese Sitzung einem vorhandenen LSN zuordnen soll. |
| Polizist | STRING | Falsch | Gibt an, ob die COP-Erkennung durchgeführt wird. |
| cop_last | STRING | Falsch | Gibt an, wie der letzte COP-Hostname ermittelt wird. |
| ddstats | ENUM | Falsch | Geben Sie den Wert für DDSTATS an. Unterstützte Werte: ON, OFF |
| disable_auto_commit_in_batch | BOOLEAN | Wahr | Gibt an, ob das Autocommit beim Ausführen des Batchvorgangs deaktiviert werden soll. |
| encrypt_data | ENUM | Falsch | Geben Sie den Wert für EncryptData an, ON oder OFF. Unterstützte Werte sind: ON, OFF |
| error_query_count | STRING | Falsch | Gibt an, wie oft JDBC FastLoad maximal versucht, die FastLoad-Fehlertabelle 1 nach einem JDBC-FastLoad-Vorgang abzufragen. |
| error_query_interval | STRING | Falsch | Gibt die Anzahl der Millisekunden an, die JDBC FastLoad zwischen den Versuchen der Abfrage von FastLoad-Fehlertabelle 1 nach einem JDBC-FastLoad-Vorgang wartet. |
| error_table1_suffix | STRING | Falsch | Gibt das Suffix für den Namen der FastLoad-Fehlertabelle 1 an, die von JDBC FastLoad und JDBC FastLoad CSV erstellt wird. |
| error_table2_suffix | STRING | Falsch | Gibt das Suffix für den Namen der FastLoad-Fehlertabelle 2 an, die von JDBC FastLoad und JDBC FastLoad CSV erstellt wird. |
| error_table_database | STRING | Falsch | Gibt den Datenbanknamen für die FastLoad-Fehlertabellen an, die von JDBC FastLoad und JDBC FastLoad CSV erstellt werden. |
| field_sep | STRING | Falsch | Gibt ein Feldtrennzeichen an, das nur mit der JDBC FastLoad CSV verwendet werden kann. Das Standardtrennzeichen ist ein Komma (,). |
| finalize_auto_close | STRING | Falsch | Geben Sie den Wert für FinalizeAutoClose an, ON oder OFF. |
| geturl_credentials | STRING | Falsch | Geben Sie den Wert für GeturlCredentials an (AN oder AUS). |
| regeln | STRING | Falsch | Geben Sie den Wert für GOVERN an, ON oder OFF. |
| literal_underscore | STRING | Falsch | Maskiert LIKE-Prädikatmuster in DatabaseMetaData-Aufrufen wie schemPattern und tableNamePattern automatisch. |
| lob_support | STRING | Falsch | Geben Sie den Wert für LobSupport an, ON oder OFF. |
| lob_temp_table | STRING | Falsch | Gibt den Namen einer Tabelle mit den folgenden Spalten an: id integer, bval blob, cval clob. |
| log | STRING | Falsch | Gibt die Logging-Ebene (Ausführlichkeit) für eine Verbindung an. Das Logging ist immer aktiviert. Die Loggingebenen werden in der Reihenfolge von kurz bis ausführlich aufgeführt. |
| log_data | STRING | Falsch | Gibt zusätzliche Daten an, die für die Anmeldung erforderlich sind, z. B. ein sicheres Token, ein Distinguished Name oder ein Domain-/Bereichsname. |
| log_mech | STRING | Falsch | Gibt den Anmeldemechanismus an, der die Authentifizierungs- und Verschlüsselungsfunktionen der Verbindung bestimmt. |
| logon_sequence_number | STRING | Falsch | Gibt eine vorhandene Anmeldesequenznummer (LSN) an, der diese Sitzung zugeordnet werden soll. |
| max_message_body | STRING | Falsch | Gibt die maximale Antwort-Nachrichtengröße in Byte an. |
| maybe_null | STRING | Falsch | Steuert das Verhalten der Methode ResultSetMetaData.isNullable. |
| new_password | STRING | Falsch | Mit diesem Verbindungsparameter kann eine Anwendung ein abgelaufenes Passwort automatisch ändern. |
| Partition | STRING | Falsch | Gibt die Teradata-Datenbankpartition für die Verbindung an. |
| prep_support | STRING | Falsch | Gibt an, ob die Teradata-Datenbank einen Vorbereitungsvorgang ausführt, wenn eine PreparedStatement oder CallableStatement erstellt wird. |
| reconnect_count | STRING | Falsch | Aktiviert die erneute Verbindung mit Teradata-Sitzungen. Gibt die maximale Anzahl der Versuche an, die der Teradata JDBC-Treiber zum erneuten Verbinden der Sitzung unternimmt. |
| reconnect_interval | STRING | Falsch | Aktiviert die erneute Verbindung mit Teradata-Sitzungen. Gibt die Anzahl der Sekunden an, die der Teradata JDBC-Treiber zwischen Versuchen zum erneuten Verbinden der Sitzung wartet. |
| erneut fahren | STRING | Falsch | Aktiviert Teradata Session Reconnect und ermöglicht auch das automatische Entfernen von SQL-Anfragen, die durch den Neustart der Datenbank unterbrochen wurden. |
| run_startup | STRING | Falsch | Geben Sie den Wert für RunStartup an, ON oder OFF. |
| Sitzungen | STRING | Falsch | Gibt die Anzahl der FastLoad- oder FastExport-Verbindungen an, die erstellt werden sollen, wobei 1 <= Anzahl der FastLoad- oder FastExport-Verbindungen <= Anzahl der AMPs gilt. |
| sip_support | STRING | Falsch | Steuert, ob die Teradata-Datenbank und der Teradata JDBC-Treiber Metadaten vom StatementInfo Parcel (SIP) verwenden. |
| slob_receive_threshold | STRING | Falsch | Steuert, wie kleine LOB-Werte von der Teradata-Datenbank empfangen werden. Kleine LOB-Werte werden aus der Teradata-Datenbank abgerufen, bevor die Anwendung Daten explizit aus Blob-/Clob-Objekten liest. |
| slob_transmit_threshold | STRING | Falsch | Steuert, wie kleine LOB-Werte an die Teradata-Datenbank übertragen werden. |
| sp_spl | STRING | Falsch | Gibt das Verhalten zum Erstellen oder Ersetzen von gespeicherten Teradata-Prozeduren an. |
| strict_encode | STRING | Falsch | Gibt das Verhalten für die Codierung von Zeichendaten an, die an die Teradata-Datenbank übertragen werden sollen. |
| tmode | STRING | Falsch | Gibt den Transaktionsmodus für die Verbindung an. |
| tnano | STRING | Falsch | Gibt die Genauigkeit der Bruchteile von Sekunden für alle java.sql.Time-Werte an, die an ein PreparedStatement oder CallableStatement gebunden und als TIME- oder TIME WITH TIME ZONE-Werte an die Teradata-Datenbank übertragen werden. |
| tsnano | STRING | Falsch | Gibt die Genauigkeit der Sekundenbruchteile für alle java.sql.Timestamp-Werte an, die an ein PreparedStatement oder CallableStatement gebunden und als TIMESTAMP- oder TIMESTAMP WITH TIME ZONE-Werte an die Teradata-Datenbank übertragen werden. |
| tcp | STRING | Falsch | Gibt eine oder mehrere TCP-Socket-Einstellungen an, die durch Pluszeichen (+) getrennt sind. |
| trusted_sql | STRING | Falsch | Geben Sie den Wert für „TrustedSql“ an. |
| Typ | STRING | Falsch | Gibt den Protokolltyp an, der mit der Teradata-Datenbank für SQL-Anweisungen verwendet werden soll. |
| upper_case_identifiers | BOOLEAN | Falsch | Dieses Attribut meldet alle Kennungen in Großbuchstaben. Dies ist die Standardeinstellung für Oracle-Datenbanken und ermöglicht daher eine bessere Integration mit Oracle-Tools wie dem Oracle Database Gateway. |
| use_xviews | STRING | Falsch | Gibt an, welche Data Dictionary-Ansichten abgefragt werden sollen, um Ergebnismengen von DatabaseMetaData-Methoden zurückzugeben. |
Teradata-Verbindung in einer Integration verwenden
Nachdem Sie die Verbindung erstellt haben, ist sie sowohl in Apigee Integration als auch in Application Integration verfügbar. Sie können die Verbindung in einer Integration über die Aufgabe „Connectors“ verwenden.
- Informationen zum Erstellen und Verwenden der Connectors-Aufgabe in Apigee Integration finden Sie unter Connectors-Aufgabe.
- Informationen zum Erstellen und Verwenden der Connectors-Aufgabe in Application Integration finden Sie unter Connectors-Aufgabe.
Hilfe von der Google Cloud-Community erhalten
Sie können Ihre Fragen und Anregungen zu diesem Connector in der Google Cloud-Community unter Cloud-Foren posten.Nächste Schritte
- Verbindungen anhalten und fortsetzen
- Informationen zum Überwachen der Connector-Nutzung
- Connector-Logs ansehen