Oracle 数据库(版本 2)
借助 Oracle DB 连接器,您可以连接到 Oracle 数据库实例并执行受支持的数据库操作。
支持的版本
此连接器支持的最低版本为 Oracle 数据库版本 11.2。
准备工作
在使用 Oracle DB 连接器之前,请先完成以下任务:
- 在您的 Google Cloud 项目中:
- 确保已设置网络连接。如需了解网络模式,请参阅网络连接。
- 向配置连接器的用户授予 roles/connectors.admin IAM 角色。
- 将以下 IAM 角色授予您要用其来使用连接器的服务账号:
roles/secretmanager.viewerroles/secretmanager.secretAccessor
服务账号是一种特殊类型的 Google 账号,用于表示需要验证身份并获得授权以访问 Google API 数据的非人类用户。如果您没有服务账号,则必须创建一个服务账号。连接器和服务账号必须属于同一项目。如需了解详情,请参阅创建服务账号。
- 启用以下服务:
secretmanager.googleapis.com(Secret Manager API)connectors.googleapis.com(Connectors API)
如需了解如何启用服务,请参阅启用服务。
如果之前没有为您的项目启用这些服务或权限,则在您配置连接器时,系统会提示您启用。
配置连接器
一个连接需专用于一个数据源。这意味着,如果您有许多数据源,则必须为每个数据源创建单独的连接。如需创建连接,请执行以下操作:
- 在 Cloud 控制台 中,进入 Integration Connectors > 连接页面,然后选择或创建一个 Google Cloud 项目。
- 点击 + 新建以打开创建连接页面。
- 在位置部分中,选择连接的位置。
- 区域:从下拉列表中选择一个位置。
如需查看所有受支持区域的列表,请参阅位置。
- 点击下一步。
- 区域:从下拉列表中选择一个位置。
- 在连接详情部分中,完成以下操作:
- 连接器:从可用连接器的下拉列表中选择 Oracle 数据库。
- 连接器版本:从可用版本的下拉列表中选择版本 2。
- 在连接名称字段中,输入连接实例的名称。
连接名称必须符合以下条件:
- 连接名称可以使用字母、数字或连字符。
- 字母必须小写。
- 连接名称必须以字母开头,以字母或数字结尾。
- 连接名称不能超过 49 个字符。
- (可选)输入连接实例的说明。
- 您可以选择启用 Cloud Logging,然后选择日志级别。默认情况下,日志级别设置为
Error。 - 您可以选择启用 Cloud Logging 以启用 Cloud Logging。
- 服务账号:选择具有所需角色的服务账号。
- (可选)配置连接节点设置:
- 节点数下限:输入连接节点数下限。
- 节点数上限:输入连接节点数上限。
节点是处理事务的连接单元(或副本)。 连接处理越多事务就需要越多节点,相反,处理越少事务需要越少节点。 如需了解节点如何影响连接器价格,请参阅连接节点的价格。如果未输入任何值,则默认情况下,节点数下限设置为 2(以便提高可用性),节点数上限设置为 50。
- 根据 Oracle 数据库连接是使用基于服务器的连接还是 TNS 连接,指定 ServiceName 或 DataSource (TNS 连接字符串)。如果同时指定这两个参数,则使用 DataSource。
- ServiceName:如果您使用基于服务器的身份验证,请指定服务名称以及目标详细信息。
-
DataSource:如果您使用 TNS 连接,请指定 Oracle 网络服务名称、连接描述符(也称为 TNS 连接字符串)或标识要连接的数据库的简单连接命名。请使用以下格式指定 TNS 连接字符串:
(DESCRIPTION=(ADDRESS=(protocol_address_information))(CONNECT_DATA= (SERVICE_NAME=service_name)))。如果您指定了数据源,则不得在目标部分再次指定目标详细信息。
- (可选)选择包含同义词。
- 废弃连接超时时间:输入超时值(以秒为单位),用于指定借用的连接在被视为废弃之前可以保持未使用的时长。
- 非活动连接超时时间:输入连接超时时间值(以秒为单位)。
- 连接重复使用时间上限:输入连接重复使用时间(以秒为单位)。
- TTL 连接超时:输入连接可保持使用状态的最长时间(以秒为单位)。
- 可浏览的架构:输入以英文逗号分隔的架构名称,用于提取实体和操作。例如
schemaA, schemaB, schemaC。 - (可选)点击 + 添加标签,以键值对的形式向连接添加标签。
- 点击下一步。
- 在目标部分中,输入要连接到的远程主机(后端系统)的详细信息。
- 目标类型:选择目标类型。
- 如需指定目标主机名或 IP 地址,请选择主机地址,然后在主机 1 字段中输入相应地址。
- 如需建立专用连接,请选择端点连接,然后从端点连接列表中选择所需的连接。
如果要与后端系统建立公共连接以提高安全性,您可以考虑为连接配置静态出站 IP 地址,然后将防火墙规则配置为仅将特定静态 IP 地址列入许可名单。
要输入其他目标,请点击 + 添加目标。
- 点击下一步。
- 目标类型:选择目标类型。
-
在身份验证部分中,输入身份验证详细信息。
- 选择身份验证类型,然后输入相关详细信息。
Oracle 数据库连接支持以下身份验证类型:
- 用户名和密码
- 点击下一步。
如需了解如何配置这些身份验证类型,请参阅配置身份验证。
- 选择身份验证类型,然后输入相关详细信息。
- 查看:查看您的连接和身份验证详细信息。
- 点击创建。
配置身份验证
根据您要使用的身份验证输入详细信息。
-
用户名和密码
- 用户名:用于身份验证的 Oracle 账号的用户名
- 密码:包含与 Oracle 账号用户名关联的密码的 Secret Manager Secret。
Oracle 数据库基本身份验证连接类型
下表介绍了您可以为 Oracle 数据库基本身份验证连接类型配置的字段。
| 字段名称 | 详细信息 |
|---|---|
| 位置 | us-central1 |
| 连接器 | Oracle 数据库 |
| 连接器版本 | 2 |
| 连接名称 | google-oracledb-plsql-new |
| 启用 Cloud Logging | 是 |
| 服务账号 | SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com |
| 服务名称 | pdb1 |
| 节点数下限 | 2 |
| 节点数上限 | 50 |
| 主机地址 | 198.51.100.0 |
| 端口 | 1521 |
| 用户名 | 用户名 |
| 密码 | PASSWORD |
| Secret 版本 | 1 |
Oracle 数据库 TNS 连接类型
下表介绍了您可以为 Oracle DB TNS 连接类型配置的字段。
| 字段名称 | 详细信息 |
|---|---|
| 位置 | us-central1 |
| 连接器 | Oracle 数据库 |
| 连接器版本 | 2 |
| 连接名称 | google-oracledb-plsql-tns |
| 启用 Cloud Logging | 是 |
| 服务账号 | SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com |
| 数据源 | (DESCRIPTION=(ADDRESS=(PROTOCOL_ADDRESS_INFORMATION))(CONNECT_DATA= (SERVICE_NAME=service_name))) |
| 节点数下限 | 2 |
| 节点数上限 | 50 |
| 用户名 | 用户名 |
| 密码 | PASSWORD |
| Secret 版本 | 1 |
实体、操作和动作
所有集成连接器都会为所连接应用的对象提供抽象层。您只能通过此抽象访问应用的对象。抽象作为实体、操作和动作向您展示。
- 实体:实体可以被视为连接的应用或服务中的对象或属性集合。不同连接器的实体定义也会有所不同。例如,在数据库连接器中,表是实体;在文件服务器连接器中,文件夹是实体;在消息传递系统连接器中,队列是实体。
但可能的情况是,连接器不支持或不具有任何实体,在这种情况下,
Entities列表将为空。 - 操作:操作是指您可以对实体执行的操作。您可以对实体执行以下任一操作:
从可用列表中选择一个实体,系统会生成该实体可用的操作列表。如需了解操作的详细说明,请参阅连接器任务的实体操作。不过,如果连接器不支持任何实体操作,则不支持的操作不会列在
Operations列表中。 - 动作:动作是可通过连接器接口提供给集成的头等函数。动作可让您对一个或多个实体进行更改,并且动作因连接器而异。通常,操作会包含一些输入参数和一个输出参数。但可能的情况是,连接器不支持任何动作,在这种情况下,
Actions列表将为空。
系统限制
Oracle DB 连接器每个节点每秒最多可处理 70 笔交易,超出此限额的任何交易都会受到限制。默认情况下,Integration Connectors 会为连接分配 2 个节点(以提高可用性)。
如需了解适用于 Integration Connectors 的限制,请参阅限制。
支持的数据类型
此连接器支持以下数据类型:
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- 时间
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
操作
借助 Oracle DB 连接器,您可以执行 Oracle 数据库支持的格式的存储过程、函数和自定义 SQL 查询。如需执行自定义 SQL 查询,连接器提供了执行自定义查询操作。
如需创建自定义查询,请按照下列步骤操作:
- 按照详细说明添加连接器任务。
- 配置连接器任务时,在要执行的动作类型中选择动作。
- 在动作列表中,选择执行自定义查询,然后点击完成。
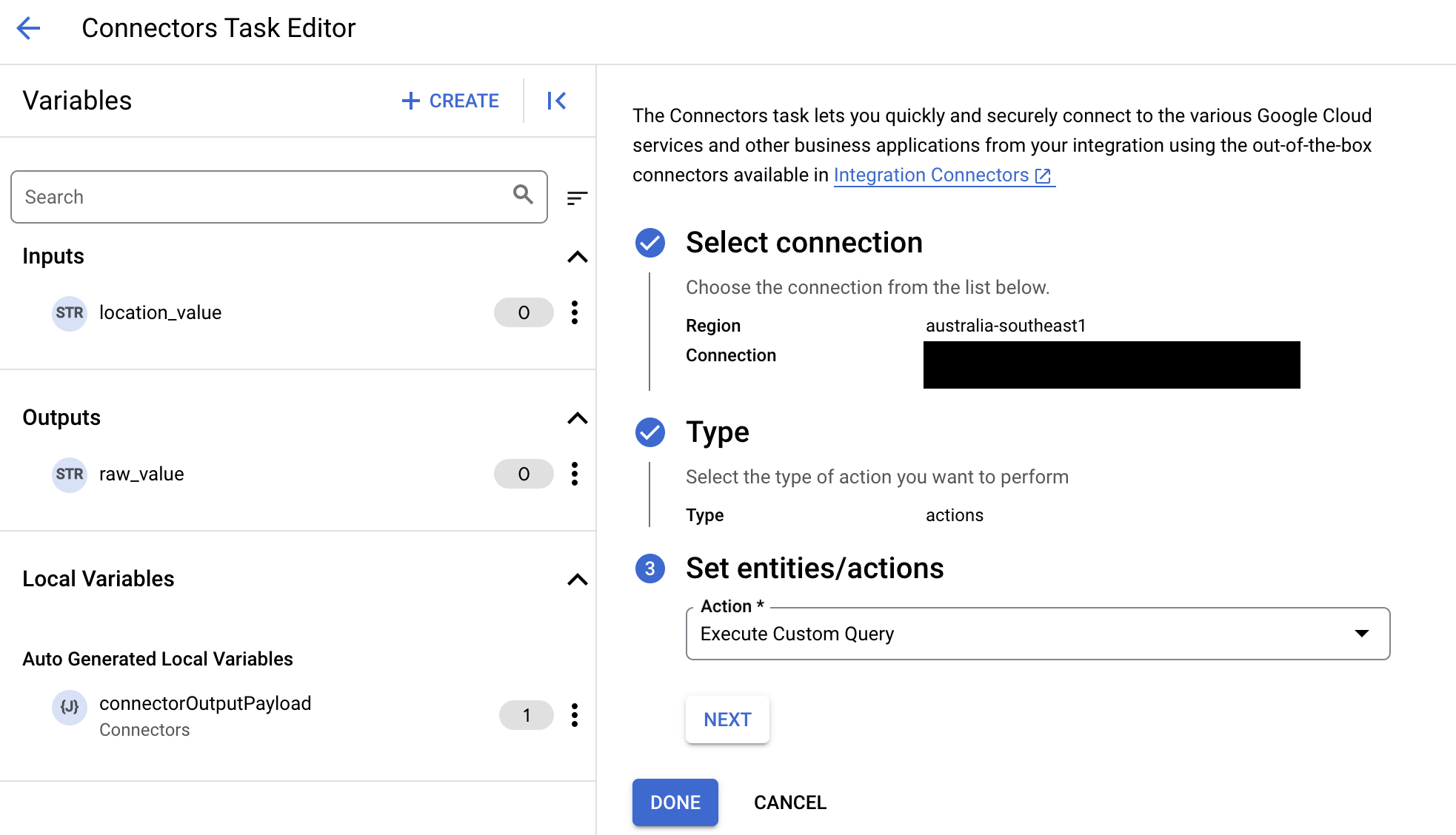
- 展开任务输入部分,然后执行以下操作:
- 在在以下时间后超时字段中,输入查询执行前要等待的秒数。
默认值:
180秒。 - 在最大行数字段中,输入要从数据库返回的最大行数。
默认值:
25。 - 要更新自定义查询,请点击修改自定义脚本。系统随即会打开脚本编辑器对话框。
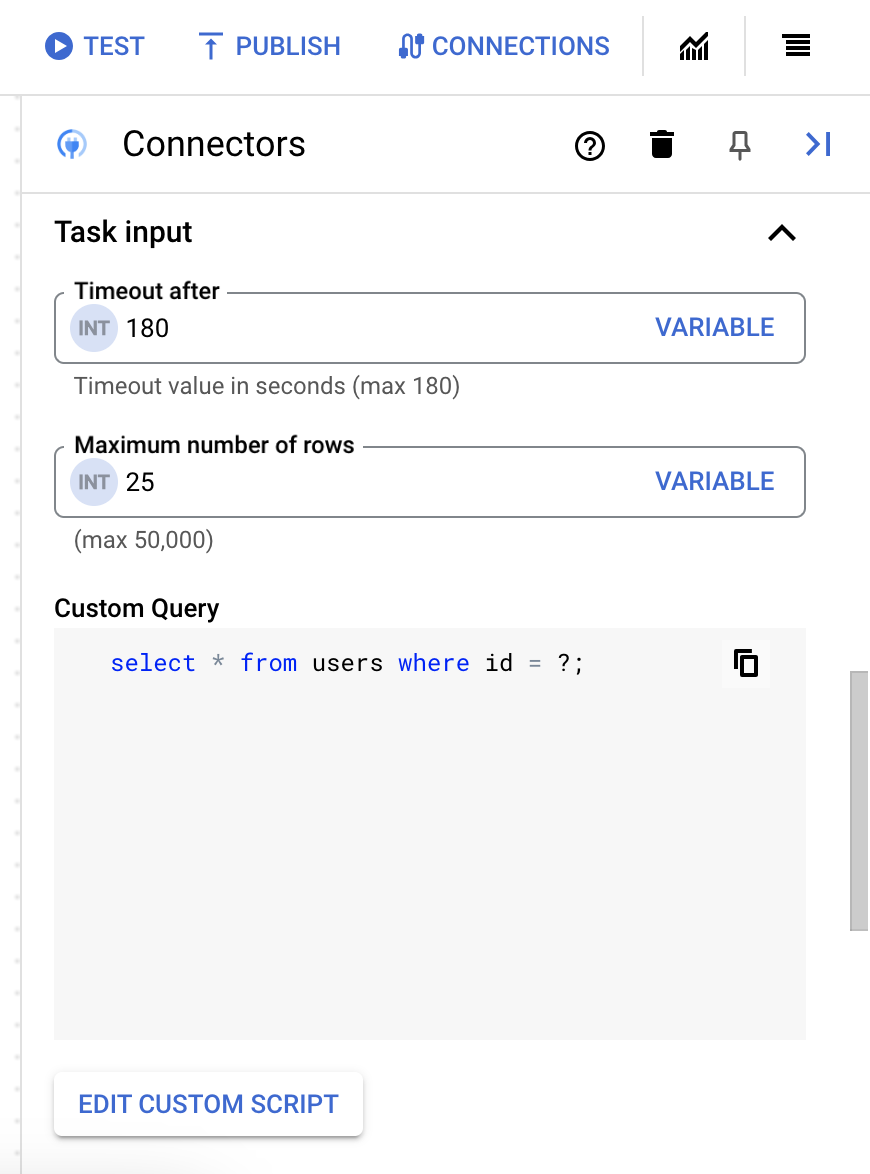
- 在脚本编辑器对话框中,输入 SQL 查询,然后点击保存。
您可以在 SQL 语句中使用问号 (?) 表示必须在查询参数列表中指定的单个参数。例如,以下 SQL 查询会从
Employees表中选择与为LastName列指定的值匹配的所有行:SELECT * FROM Employees where LastName=?
- 如果您在 SQL 查询中使用了问号,则必须点击 + 添加参数名称,针对每个问号添加参数。执行集成时,这些参数按顺序替换 SQL 查询中的问号 (?)。例如,如果您添加了三个问号 (?),那么必须按顺序添加三个参数。
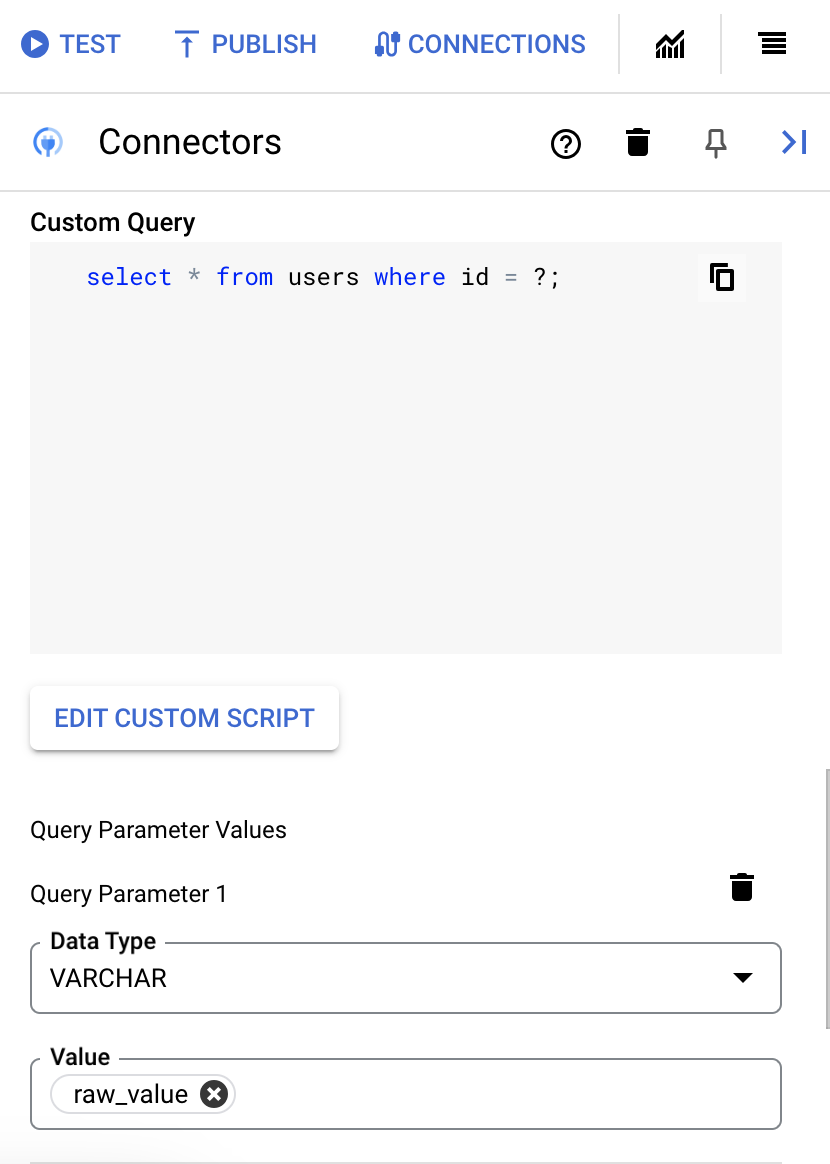
如需添加查询参数,请执行以下操作:
- 从类型列表中,选择参数的数据类型。
- 在值字段中,输入参数的值。
- 要添加多个参数,请点击 + 添加查询参数。
执行自定义查询操作不支持数组变量。
- 在在以下时间后超时字段中,输入查询执行前要等待的秒数。
如需了解如何使用自定义查询操作,请参阅操作示例。
操作示例
本部分介绍如何在此连接器中执行一些操作。
示例 - 执行分组查询
- 在配置连接器任务对话框中,选择操作。
- 选择执行自定义查询操作,然后点击完成。
- 在连接器任务的任务输入部分,点击修改自定义查询。系统会打开自定义查询对话框。
- 在自定义查询对话框中,输入以下 SQL 查询,然后点击保存:
Select E.EMPLOYEE_ID, E.EMPLOYEE_NAME, E.CITY FROM EMPLOYEES E LEFT JOIN EMPLOYEE_DEPARTMENT ED ON E.EMPLOYEE_ID=ED.ID WHERE E.EMPLOYEE_NAME = 'John' GROUP BY E.CITY,E.EMPLOYEE_ID,E.EMPLOYEE_NAME
此示例从
EMPLOYEES和EMPLOYEE_DEPARTMENT表中选择员工记录。如果操作成功,连接器任务的connectorOutputPayload响应参数将包含查询结果集。
示例 - 执行参数化查询
- 在配置连接器任务对话框中,选择操作。
- 选择执行自定义查询操作,然后点击完成。
- 在连接器任务的任务输入部分中,为相应字段设置以下值:
- 超时时间:
10 - 行数上限:
3
- 超时时间:
- 点击 + 添加参数名称,然后输入以下值:
- 类型:
VARCHAR - 值:
John
- 类型:
- 点击修改自定义查询。系统会打开自定义查询对话框。
- 在自定义查询对话框中,输入以下 SQL 查询,然后点击保存:
Select C.ID,C.NAME,C.CITY,C.O_DATE,E.EMPLOYEE_ID FROM customqueries C,Employees E WHERE C.ID=E.Employee_id and C.NAME=?
此示例选择员工姓名为 John 的员工记录。
请注意,员工的姓名已参数化。
如果操作成功,连接器任务的 connectorOutputPayload 响应参数将具有类似以下的值:
[{ "NAME": "John", "O_DATE": "2023-06-01 00:00:00.0", "EMPLOYEE_ID": 1.0 }, { "NAME": "John", "O_DATE": "2021-07-01 00:00:00.0", "EMPLOYEE_ID": 3.0 }, { "NAME": "John", "O_DATE": "2022-09-01 00:00:00.0", "EMPLOYEE_ID": 4.0 }]
示例 - 使用序列值插入记录
- 在配置连接器任务对话框中,选择操作。
- 选择执行自定义查询操作,然后点击完成。
- 在自定义查询对话框中,输入以下 SQL 查询,然后点击保存:
INSERT INTO AUTHOR(id,title) VALUES(author_table_id_seq.NEXTVAL,'Sample_book_title')
此示例使用现有的 author_table_id_seq 序列对象在 AUTHOR 表中插入一条记录。如果操作成功,连接器任务的 connectorOutputPayload 响应参数将具有类似以下的值:
[{ }]
示例 - 执行包含聚合函数的查询
- 在配置连接器任务对话框中,选择操作。
- 选择执行自定义查询操作,然后点击完成。
- 在自定义查询对话框中,输入以下 SQL 查询,然后点击保存:
SELECT SUM(SALARY) as Total FROM EMPLOYEES
此示例计算 EMPLOYEES 表中薪资的汇总值。如果操作成功,连接器任务的 connectorOutputPayload 响应参数将具有类似以下的值:
[{ "TOTAL": 13000.0 }]
示例 - 创建新表
- 在配置连接器任务对话框中,选择操作。
- 选择执行自定义查询操作,然后点击完成。
- 在自定义查询对话框中,输入以下 SQL 查询,然后点击保存:
CREATE TABLE TEST1 (ID INT, NAME VARCHAR(40),DEPT VARCHAR(20),CITY VARCHAR(10))
此示例创建了 TEST1 表。如果操作成功,连接器任务的 connectorOutputPayload 响应参数将具有类似以下的值:
[{ }]
实体操作示例
示例 - 列出所有员工
此示例列出了 Employee 实体中的所有员工。
- 在
Configure connector task对话框中,点击Entities。 - 从
Entity列表中选择Employee。 - 选择
List操作,然后点击完成。 - 或者,您可以在连接器任务的任务输入部分中,通过指定过滤条件子句来过滤结果集。
示例 - 获取员工详细信息
此示例从 Employee 实体中获取 ID 为 45 的员工的详细信息。
- 在
Configure connector task对话框中,点击Entities。 - 从
Entity列表中选择Employee。 - 选择
Get操作,然后点击完成。 - 在连接器任务的任务输入部分,点击 EntityId,然后在默认值字段中输入
45。其中,
45是Employee实体的键值。
示例 - 创建员工记录
此示例在 Employee 实体中添加了一条新的员工记录。
- 在
Configure connector task对话框中,点击Entities。 - 从
Entity列表中选择Employee。 - 选择
Create操作,然后点击完成。 - 在连接器任务的任务输入部分中,点击
connectorInputPayload,然后在Default Value字段中输入类似于以下内容的值:{ "EMPLOYEE_ID": 69.0, "EMPLOYEE_NAME": "John", "CITY": "Bangalore" }
如果集成成功,连接器任务的
connectorOutputPayload字段将具有类似以下的值:{ "ROWID": "AAAoU0AABAAAc3hAAF" }
示例 - 更新员工记录
此示例会更新 Employee 实体中 ID 为 69 的员工记录。
- 在
Configure connector task对话框中,点击Entities。 - 从
Entity列表中选择Employee。 - 选择
Update操作,然后点击完成。 - 在连接器任务的任务输入部分中,点击
connectorInputPayload,然后在Default Value字段中输入类似于以下内容的值:{ "EMPLOYEE_NAME": "John", "CITY": "Mumbai" }
- 点击 entityId,然后在默认值字段中输入
69。或者,您也可以将 filterClause 设置为
69,而不是指定 entityId。如果集成成功,连接器任务的
connectorOutputPayload字段将具有类似以下内容的值:{ }
示例 - 删除员工记录
此示例会删除 Employee 实体中 ID 为 35 的员工记录。
- 在
Configure connector task对话框中,点击Entities。 - 从
Entity列表中选择Employee。 - 选择
Delete操作,然后点击完成。 - 在连接器任务的任务输入部分,点击 entityId,然后在默认值字段中输入
35。
使用 Terraform 创建连接
您可以使用 Terraform 资源创建新连接。
如需了解如何应用或移除 Terraform 配置,请参阅基本 Terraform 命令。
如需查看用于创建连接的 Terraform 模板示例,请参阅模板示例。
使用 Terraform 创建此连接时,您必须在 Terraform 配置文件中设置以下变量:
| 参数名称 | 数据类型 | 必需 | 说明 |
|---|---|---|---|
| service_name | STRING | 错误 | Oracle 数据库的服务名称。 |
| data_source | STRING | 错误 | Oracle 网络服务名称、连接描述符(也称为 TNS 连接字符串)或标识要连接的数据库的简单连接命名。 |
| include_synonyms | BOOLEAN | 错误 | 查询同义词的元数据,并将其作为实体提供。将该属性设置为 false 可以提高元数据性能。 |
| abandoned_connection_timeout | INTEGER | 错误 | 废弃连接超时时间(以秒为单位)用于确定借用的连接在被视为废弃并由连接池回收之前可以保持未使用的时长。 |
| inactive_connection_timeout | INTEGER | 错误 | 非活动连接超时时间(以秒为单位)用于确定可用连接在从连接池中移除之前在连接池中保留的时长。 |
| max_connection_reuse_time | INTEGER | 错误 | 最长连接重用时间(以秒为单位)用于指定任何连接可重用的最长时间,超过此时间后,连接池会移除并关闭连接。 |
| ttl_connection_timeout | INTEGER | 错误 | 连接可保持使用状态的最长时间(以秒为单位)。 |
| browsable_schemas | STRING | 错误 | 以英文逗号分隔的架构(例如 SchemaA、SchemaB)以在提取连接的实体和操作时使用。默认使用用户的架构 |
在集成中使用 Oracle 数据库连接
创建连接后,该连接将在 Apigee Integration 和 Application Integration 中可用。您可以通过“连接器”任务在集成中使用该连接。
- 如需了解如何在 Apigee Integration 中创建和使用连接器任务,请参阅连接器任务。
- 如需了解如何在 Application Integration 中创建和使用连接器任务,请参阅连接器任务。