Oracle DB(버전 2)
Oracle DB 커넥터를 사용하면 Oracle 데이터베이스 인스턴스에 연결하고 지원되는 데이터베이스 작업을 수행할 수 있습니다.
지원되는 버전
이 커넥터에 지원되는 최소 버전은 Oracle 데이터베이스 버전 11.2입니다.
시작하기 전에
Oracle DB 커넥터를 사용하기 전에 다음 태스크를 수행합니다.
- Google Cloud 프로젝트에서:
- 네트워크 연결이 설정되어 있는지 확인합니다. 네트워크 패턴에 대한 자세한 내용은 네트워크 연결을 참조하세요.
- 커넥터를 구성하는 사용자에게 roles/connectors.admin IAM 역할을 부여합니다.
- 커넥터에 사용할 서비스 계정에 다음 IAM 역할을 부여합니다.
roles/secretmanager.viewerroles/secretmanager.secretAccessor
서비스 계정은 인증을 거쳐야 하며 Google API의 데이터에 액세스할 수 있는 승인을 받은 사람이 아닌 사용자를 나타내는 특별한 유형의 Google 계정입니다. 서비스 계정이 없으면 서비스 계정을 만들어야 합니다. 커넥터와 서비스 계정은 동일한 프로젝트에 속해야 합니다. 자세한 내용은 서비스 계정 만들기를 참조하세요.
- 다음 서비스를 사용 설정합니다.
secretmanager.googleapis.com(Secret Manager API)connectors.googleapis.com(Connectors API)
서비스 사용 설정 방법은 서비스 사용 설정을 참조하세요.
이러한 서비스나 권한이 이전 프로젝트에서 사용 설정되지 않았으면 커넥터를 구성할 때 서비스나 권한을 사용 설정하라는 메시지가 표시됩니다.
커넥터 구성
연결은 데이터 소스와 관련이 있습니다. 즉, 데이터 소스가 많으면 데이터 소스마다 별도의 연결을 만들어야 합니다. 연결을 만들려면 다음 단계를 따르세요.
- Cloud 콘솔에서 Integration Connectors > 연결 페이지로 이동한 다음 Google Cloud 프로젝트를 선택하거나 만듭니다.
- + 새로 만들기를 클릭하여 연결 만들기 페이지를 엽니다.
- 위치 섹션에서 연결 위치를 선택합니다.
- 리전: 드롭다운 목록에서 위치를 선택합니다.
지원되는 모든 리전 목록은 위치를 참조하세요.
- 다음을 클릭합니다.
- 리전: 드롭다운 목록에서 위치를 선택합니다.
- 연결 세부정보 섹션에서 다음을 완료합니다.
- 커넥터: 사용 가능한 커넥터 드롭다운 목록에서 Oracle DB를 선택합니다.
- 커넥터 버전: 사용 가능한 버전의 드롭다운 목록에서 버전 2를 선택합니다.
- 연결 이름 필드에서 연결 인스턴스의 이름을 입력합니다.
연결 이름은 다음 기준을 충족해야 합니다.
- 연결 이름에 문자, 숫자, 하이픈을 사용할 수 있습니다.
- 문자는 소문자여야 합니다.
- 연결 이름은 문자로 시작하고 문자 또는 숫자로 끝나야 합니다.
- 연결 이름은 49자(영문 기준)를 초과할 수 없습니다.
- 선택적으로 연결 인스턴스에 대한 설명을 입력합니다.
- 필요한 경우 Cloud Logging을 사용 설정한 다음 로그 수준을 선택합니다. 기본적으로 로그 수준은
Error로 설정됩니다. - 선택적으로 Cloud Logging 사용 설정을 선택하여 Cloud Logging을 사용 설정합니다.
- 서비스 계정: 필수 역할이 있는 서비스 계정을 선택합니다.
- 필요한 경우 연결 노드 설정을 구성합니다.
- 최소 노드 수: 최소 연결 노드 수를 입력합니다.
- 최대 노드 수: 최대 연결 노드 수를 입력합니다.
노드는 트랜잭션을 처리하는 연결의 단위(또는 복제본)입니다. 연결에 대해 더 많은 트랜잭션을 처리하려면 더 많은 노드가 필요합니다. 이와 반대로 더 적은 트랜잭션을 처리하기 위해서는 더 적은 노드가 필요합니다. 노드가 커넥터 가격 책정에 미치는 영향을 파악하려면 연결 노드 가격 책정을 참조하세요. 값을 입력하지 않으면 기본적으로 최소 노드가 (높은 가용성을 위해) 2로 설정되고 최대 노드는 50으로 설정됩니다.
- Oracle DB 연결에서 서버 기반 연결 또는 TNS 연결을 사용하는지에 따라 ServiceName 또는 DataSource(TNS 연결 문자열)을 지정합니다. 둘 다 지정하면 DataSource가 사용됩니다.
- ServiceName: 서버 기반 인증을 사용하는 경우 대상 세부정보와 함께 서비스 이름을 지정합니다.
-
DataSource: TNS 연결을 사용하는 경우 Oracle Net Services Name, Connect Descriptor(TNS 연결 문자열이라고도 함) 또는 연결할 데이터베이스를 식별하는 쉬운 연결 이름을 지정합니다. TNS 연결 문자열을 지정하려면
(DESCRIPTION=(ADDRESS=(protocol_address_information))(CONNECT_DATA= (SERVICE_NAME=service_name)))형식을 사용합니다. 데이터 소스를 지정하는 경우 대상 섹션에서 대상 세부정보를 다시 지정하면 안 됩니다.
- 필요한 경우 동의어 포함을 선택합니다.
- 폐기된 연결 제한 시간: 대여한 연결이 폐기된 것으로 간주되기까지 사용되지 않을 수 있는 시간을 지정하는 제한 시간 값(초)을 입력합니다.
- 비활성 연결 제한 시간: 연결 제한 시간 값(초)을 입력합니다.
- 최대 연결 재사용 시간: 연결 재사용 시간(초)을 입력합니다.
- TTL 연결 시간 초과: 연결이 사용 중일 수 있는 최대 시간(초)을 입력합니다.
- 검색 가능한 스키마: 항목 및 작업을 가져올 때 사용할 스키마 이름을 쉼표로 구분하여 입력합니다. 예를 들면
schemaA, schemaB, schemaC입니다. - 선택적으로 + 라벨 추가를 클릭하여 키/값 쌍의 형식으로 연결에 라벨을 추가합니다.
- 다음을 클릭합니다.
- 대상 섹션에서 연결하려는 원격 호스트(백엔드 시스템)의 세부정보를 입력합니다.
- 대상 유형: 대상 유형을 선택합니다.
- 대상 호스트 이름 또는 IP 주소를 지정하려면 호스트 주소를 선택하고 호스트 1 필드에 주소를 입력합니다.
- 비공개 연결을 설정하려면 엔드포인트 연결을 선택하고 엔드포인트 연결 목록에서 필요한 연결을 선택합니다.
추가 보안을 사용하여 백엔드 시스템에 공개 연결을 설정하려면 연결의 고정 아웃바운드 IP 주소를 구성한 후 방화벽 규칙을 구성하여 특정 고정 IP 주소만 허용 목록에 추가합니다.
추가 대상을 입력하려면 +대상 추가를 클릭합니다.
- 다음을 클릭합니다.
- 대상 유형: 대상 유형을 선택합니다.
-
인증 섹션에서 인증 세부정보를 입력합니다.
- 인증 유형을 선택하고 관련 세부정보를 입력합니다.
Oracle DB 연결에서 지원되는 인증 유형은 다음과 같습니다.
- 사용자 이름 및 비밀번호
- 다음을 클릭합니다.
이러한 인증 유형을 구성하는 방법은 인증 구성을 참조하세요.
- 인증 유형을 선택하고 관련 세부정보를 입력합니다.
- 검토: 연결 및 인증 세부정보를 검토합니다.
- 만들기를 클릭합니다.
인증 구성
사용할 인증을 기반으로 세부정보를 입력합니다.
-
사용자 이름 및 비밀번호
- 사용자 이름: 인증에 사용되는 Oracle 계정의 사용자 이름
- 비밀번호: Oracle 계정 사용자 이름과 연결된 비밀번호가 포함된 Secret Manager 보안 비밀
Oracle DB 기본 인증 연결 유형
다음 표에서는 Oracle DB 기본 인증 연결 유형에 대해 구성할 수 있는 필드를 설명합니다.
| 필드 이름 | 세부정보 |
|---|---|
| 위치 | us-central1 |
| 커넥터 | Oracle DB |
| 커넥터 버전 | 2 |
| 연결 이름 | google-oracledb-plsql-new |
| Cloud Logging 사용 설정 | 예 |
| 서비스 계정 | SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com |
| 서비스 이름 | pdb1 |
| 최소 노드 수 | 2 |
| 최대 노드 수 | 50 |
| 호스트 주소 | 198.51.100.0 |
| 포트 | 1521 |
| 사용자 이름 | USERNAME |
| 비밀번호 | PASSWORD |
| 보안 비밀 버전 | 1 |
Oracle DB TNS 연결 유형
다음 표에서는 Oracle DB TNS 연결 유형에 대해 구성할 수 있는 필드를 설명합니다.
| 필드 이름 | 세부정보 |
|---|---|
| 위치 | us-central1 |
| 커넥터 | Oracle DB |
| 커넥터 버전 | 2 |
| 연결 이름 | google-oracledb-plsql-tns |
| Cloud Logging 사용 설정 | 예 |
| 서비스 계정 | SERVICE_ACCOUNT_NAME@PROJECT_ID.iam.gserviceaccount.com |
| 데이터 소스 | (DESCRIPTION=(ADDRESS=(PROTOCOL_ADDRESS_INFORMATION))(CONNECT_DATA= (SERVICE_NAME=service_name))) |
| 최소 노드 수 | 2 |
| 최대 노드 수 | 50 |
| 사용자 이름 | USERNAME |
| 비밀번호 | PASSWORD |
| 보안 비밀 버전 | 1 |
항목, 작업, 조치
모든 Integration Connectors는 연결된 애플리케이션의 객체에 대한 추상화 레이어를 제공합니다. 이 추상화를 통해서만 애플리케이션의 객체에 액세스할 수 있습니다. 추상화는 항목, 작업, 조치로 노출됩니다.
- 항목: 연결된 애플리케이션 또는 서비스에서 항목은 객체 또는 속성 모음으로 간주될 수 있습니다. 항목의 정의는 커넥터마다 다릅니다. 예를 들어 데이터베이스 커넥터에서는 테이블이 항목이고, 파일 서버 커넥터에서는 폴더가 항목이며 메시징 시스템 커넥터에서는 큐가 항목입니다.
그러나 커넥터가 항목을 지원하지 않거나 항목을 포함하지 않을 수 있으며, 이 경우
Entities목록이 비어 있습니다. - 작업: 작업은 항목에 대해 수행할 수 있는 활동입니다. 항목에서 다음 작업을 수행할 수 있습니다.
사용 가능한 목록에서 항목을 선택하면 항목에 사용 가능한 작업 목록이 생성됩니다. 작업에 대한 자세한 설명은 커넥터 태스크의 항목 작업을 참조하세요. 그러나 커넥터가 항목 작업을 지원하지 않으면 이렇게 지원되지 않는 작업은
Operations목록에 나열되지 않습니다. - 조치: 커넥터 인터페이스를 통해 통합에 제공되는 첫 번째 클래스 함수입니다. 조치를 사용하면 항목을 변경할 수 있습니다. 조치는 커넥터마다 다릅니다. 일반적으로 조치에는 입력 매개변수와 출력 매개변수가 있습니다. 하지만 커넥터가 조치를 지원하지 않을 수 있으며 이 경우
Actions목록이 비어 있습니다.
시스템 제한사항
Oracle DB 커넥터는 노드당 1초에 최대 70개의 트랜잭션을 처리할 수 있으며, 이 한도를 초과하는 모든 트랜잭션을 제한합니다. 기본적으로 Integration Connectors는 가용성을 높이기 위해 연결에 2개의 노드를 할당합니다.
Integration Connectors에 적용되는 한도에 대한 자세한 내용은 한도를 참조하세요.
지원되는 데이터 유형
이 커넥터에 지원되는 데이터 유형은 다음과 같습니다.
- BIGINT
- 바이너리
- BIT
- 부울
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- 정수
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- TIME
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
작업
Oracle DB 커넥터를 사용하면 Oracle 데이터베이스에서 지원되는 형식으로 저장 프로시저, 함수, 커스텀 SQL 쿼리를 실행할 수 있습니다. 커스텀 SQL 쿼리가 실행되도록 커넥터에서 커스텀 쿼리 실행 작업을 제공합니다.
커스텀 쿼리를 만들려면 다음 단계를 수행합니다.
- 자세한 안내에 따라 커넥터 태스크를 추가합니다.
- 커넥터 태스크를 구성할 때 수행할 작업 유형에서 작업을 선택합니다.
- 작업 목록에서 커스텀 쿼리 실행을 선택한 후 완료를 클릭합니다.
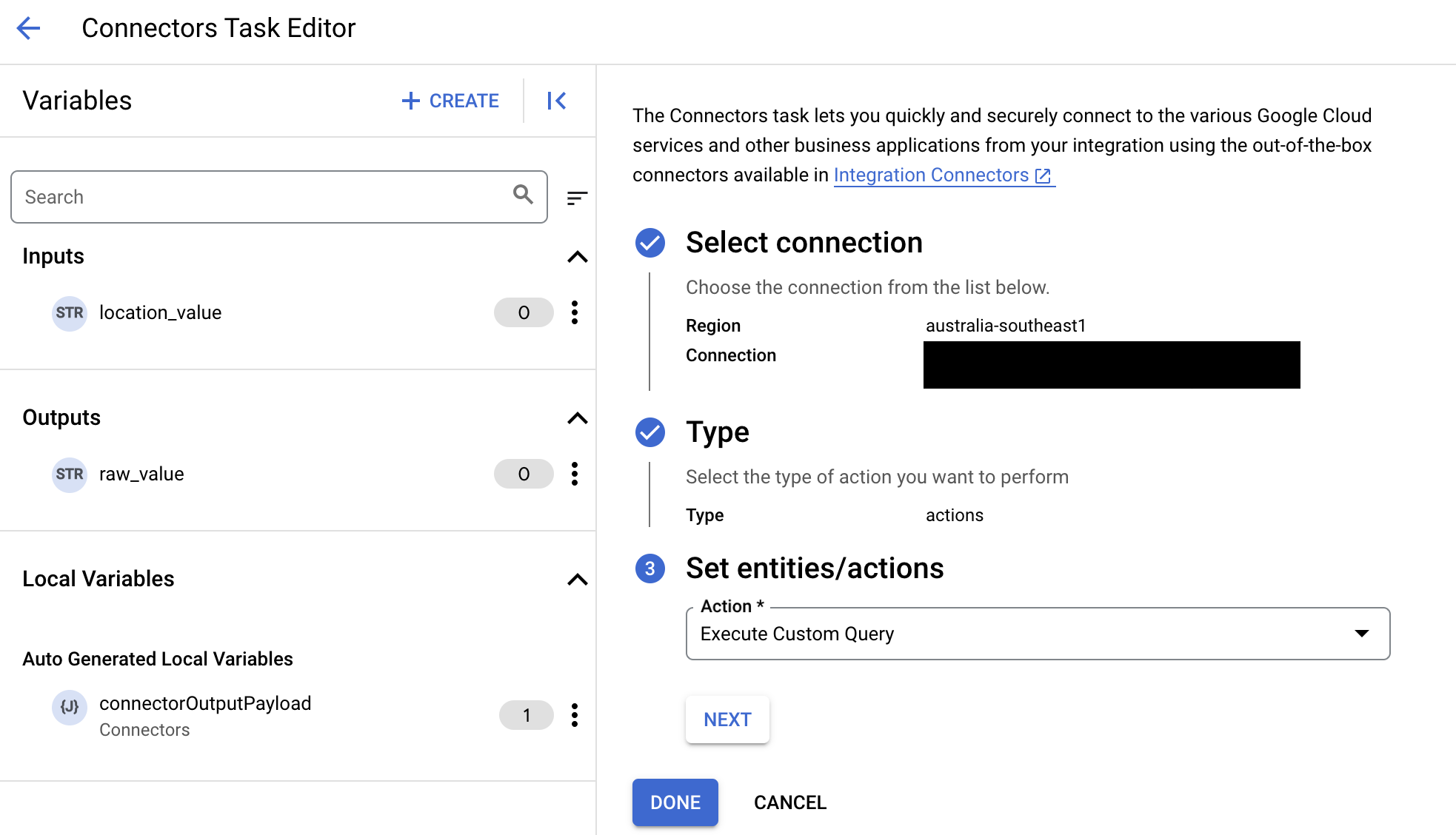
- 태스크 입력 섹션을 펼친 후 다음을 수행합니다.
- 다음 이후 시간 초과 필드에 쿼리가 실행될 때까지 대기할 시간(초)을 입력합니다.
기본값:
180초 - 최대 행 수 필드에 데이터베이스에서 반환될 최대 행 수를 입력합니다.
기본값은
25입니다. - 커스텀 쿼리를 업데이트하려면 커스텀 스크립트 수정을 클릭합니다. 스크립트 편집기 대화상자가 열립니다.
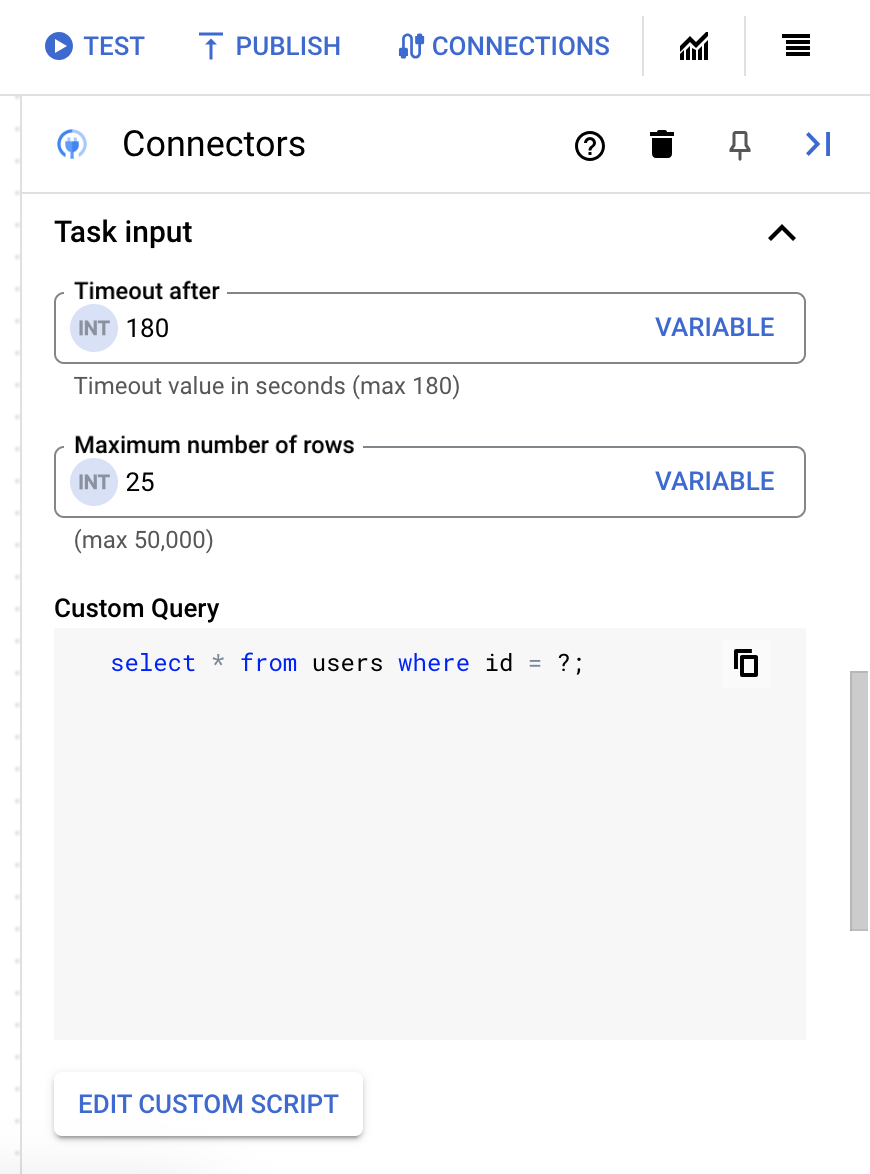
- 스크립트 편집기 대화상자에서 SQL 쿼리를 입력하고 저장을 클릭합니다.
SQL 문에서 물음표(?)를 사용하여 쿼리 매개변수 목록에 지정해야 하는 단일 매개변수를 나타낼 수 있습니다. 예를 들어 다음 SQL 쿼리는
Employees테이블에서LastName열에 지정된 값과 일치하는 모든 행을 선택합니다.SELECT * FROM Employees where LastName=?
- SQL 쿼리에 물음표를 사용한 경우에는 물음표마다 + 매개변수 이름 추가를 클릭하여 매개변수를 추가해야 합니다. 통합을 실행하는 동안 이 매개변수는 SQL 쿼리의 물음표(?)를 순차적으로 대체합니다. 예를 들어 물음표(?) 3개를 추가한 경우 매개변수 3개를 순서대로 추가해야 합니다.
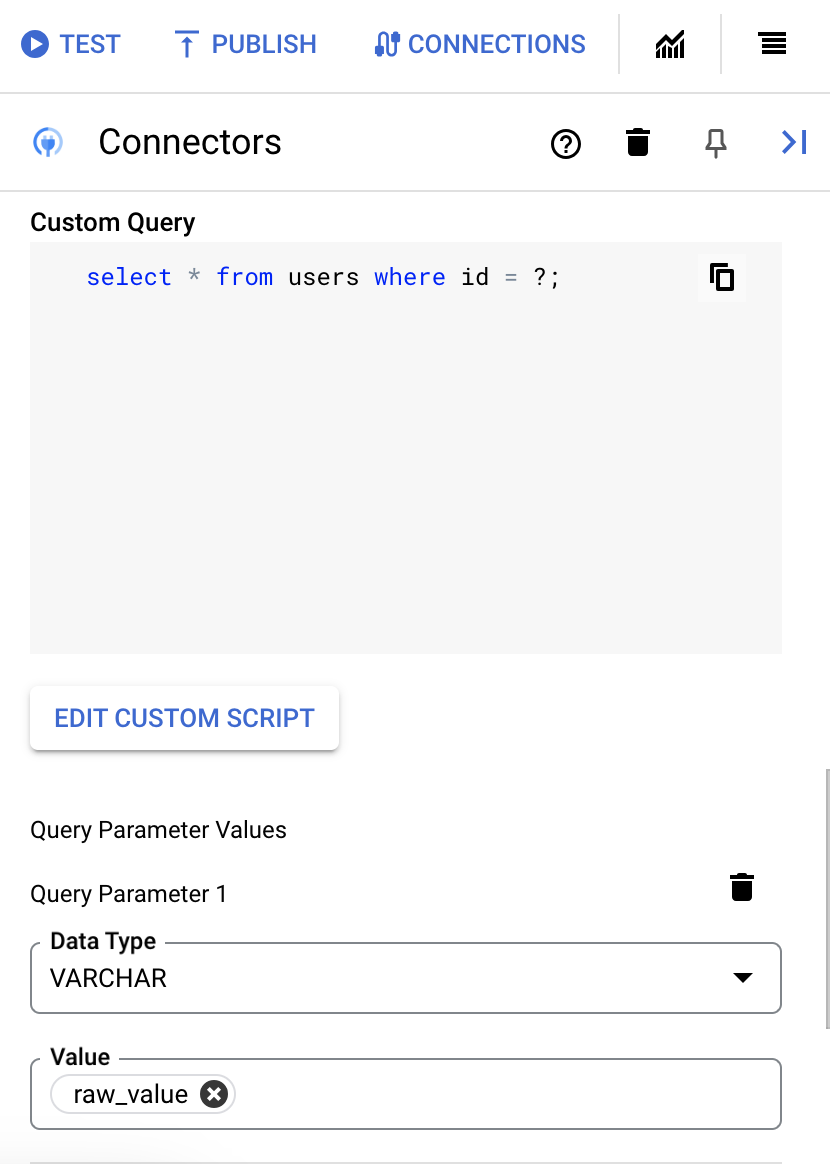
쿼리 매개변수를 추가하려면 다음을 수행합니다.
- 유형 목록에서 매개변수 데이터 유형을 선택합니다.
- 값 필드에 매개변수 값을 입력합니다.
- 여러 매개변수를 추가하려면 + 쿼리 매개변수 추가를 클릭합니다.
맞춤 쿼리 실행 작업은 배열 변수를 지원하지 않습니다.
- 다음 이후 시간 초과 필드에 쿼리가 실행될 때까지 대기할 시간(초)을 입력합니다.
커스텀 쿼리 작업을 사용하는 방법을 이해하려면 작업 예를 참고하세요.
작업 예시
이 섹션에서는 이 커넥터에서 일부 작업을 수행하는 방법을 설명합니다.
예시 - 쿼리로 그룹 실행
- 커넥터 태스크 구성 대화상자에서 작업을 선택합니다.
- 커스텀 쿼리 실행 작업을 선택한 다음 완료를 클릭합니다.
- 커넥터 작업의 태스크 입력 섹션에서 커스텀 쿼리 수정을 클릭합니다. 커스텀 쿼리 대화상자가 열립니다.
- 커스텀 쿼리 대화상자에 다음 SQL 쿼리를 입력하고 저장을 클릭합니다.
Select E.EMPLOYEE_ID, E.EMPLOYEE_NAME, E.CITY FROM EMPLOYEES E LEFT JOIN EMPLOYEE_DEPARTMENT ED ON E.EMPLOYEE_ID=ED.ID WHERE E.EMPLOYEE_NAME = 'John' GROUP BY E.CITY,E.EMPLOYEE_ID,E.EMPLOYEE_NAME
이 예시에서는
EMPLOYEES및EMPLOYEE_DEPARTMENT테이블에서 직원 레코드를 선택합니다. 작업이 성공하면 커넥터 태스크의connectorOutputPayload응답 매개변수에 쿼리 결과 집합이 포함됩니다.
예시 - 매개변수화된 쿼리 실행
- 커넥터 태스크 구성 대화상자에서 작업을 선택합니다.
- 커스텀 쿼리 실행 작업을 선택한 다음 완료를 클릭합니다.
- 커넥터 태스크의 태스크 입력 섹션에서 필드에 다음 값을 설정합니다.
- 다음 이후 시간 초과:
10 - 최대 행 수:
3
- 다음 이후 시간 초과:
- +매개변수 이름 추가를 클릭하여 다음 값을 입력합니다.
- 유형:
VARCHAR - 값:
John
- 유형:
- 커스텀 쿼리 수정을 클릭합니다. 커스텀 쿼리 대화상자가 열립니다.
- 커스텀 쿼리 대화상자에 다음 SQL 쿼리를 입력하고 저장을 클릭합니다.
Select C.ID,C.NAME,C.CITY,C.O_DATE,E.EMPLOYEE_ID FROM customqueries C,Employees E WHERE C.ID=E.Employee_id and C.NAME=?
이 예시에서는 직원 이름이 John인 직원 레코드를 선택합니다.
직원 이름이 매개변수화되어 있습니다.
작업이 성공하면 커넥터 태스크의 connectorOutputPayload 응답 매개변수가 다음과 비슷한 값을 갖습니다.
[{ "NAME": "John", "O_DATE": "2023-06-01 00:00:00.0", "EMPLOYEE_ID": 1.0 }, { "NAME": "John", "O_DATE": "2021-07-01 00:00:00.0", "EMPLOYEE_ID": 3.0 }, { "NAME": "John", "O_DATE": "2022-09-01 00:00:00.0", "EMPLOYEE_ID": 4.0 }]
예시 - 시퀀스 값을 사용하여 레코드 삽입
- 커넥터 태스크 구성 대화상자에서 작업을 선택합니다.
- 커스텀 쿼리 실행 작업을 선택한 다음 완료를 클릭합니다.
- 커스텀 쿼리 대화상자에 다음 SQL 쿼리를 입력하고 저장을 클릭합니다.
INSERT INTO AUTHOR(id,title) VALUES(author_table_id_seq.NEXTVAL,'Sample_book_title')
이 예시에서는 기존 author_table_id_seq 시퀀스 객체를 사용하여 AUTHOR 테이블에 레코드를 삽입합니다. 작업이 성공하면 커넥터 태스크의 connectorOutputPayload 응답 매개변수가 다음과 비슷한 값을 갖습니다.
[{ }]
예시 - 집계 함수로 쿼리 실행
- 커넥터 태스크 구성 대화상자에서 작업을 선택합니다.
- 커스텀 쿼리 실행 작업을 선택한 다음 완료를 클릭합니다.
- 커스텀 쿼리 대화상자에 다음 SQL 쿼리를 입력하고 저장을 클릭합니다.
SELECT SUM(SALARY) as Total FROM EMPLOYEES
이 예시에서는 EMPLOYEES 테이블의 급여 총액을 계산합니다. 작업이 성공하면 커넥터 태스크의 connectorOutputPayload 응답 매개변수가 다음과 비슷한 값을 갖습니다.
[{ "TOTAL": 13000.0 }]
예시 - 새 테이블 만들기
- 커넥터 태스크 구성 대화상자에서 작업을 선택합니다.
- 커스텀 쿼리 실행 작업을 선택한 다음 완료를 클릭합니다.
- 커스텀 쿼리 대화상자에 다음 SQL 쿼리를 입력하고 저장을 클릭합니다.
CREATE TABLE TEST1 (ID INT, NAME VARCHAR(40),DEPT VARCHAR(20),CITY VARCHAR(10))
이 예시에서는 TEST1 테이블을 만듭니다. 작업이 성공하면 커넥터 태스크의 connectorOutputPayload 응답 매개변수가 다음과 비슷한 값을 갖습니다.
[{ }]
항목 작업 예시
예시 - 모든 직원 나열
이 예시에서는 Employee 항목의 모든 직원을 나열합니다.
Configure connector task대화상자에서Entities를 클릭합니다.Entity목록에서Employee를 선택합니다.List작업을 선택한 후 완료를 클릭합니다.- 원하는 경우 커넥터 태스크의 태스크 입력 섹션에서 필터 절을 지정하여 결과 집합을 필터링할 수 있습니다.
예시 - 직원 세부정보 가져오기
이 예시에서는 Employee 항목에서 ID가 45인 직원의 세부정보를 가져옵니다.
Configure connector task대화상자에서Entities를 클릭합니다.Entity목록에서Employee를 선택합니다.Get작업을 선택한 후 완료를 클릭합니다.- 커넥터 태스크의 태스크 입력 섹션에서 EntityId를 클릭한 후 기본값 필드에
45을 입력합니다.여기서
45는Employee항목의 기본 키 값입니다.
예시 - 직원 레코드 만들기
이 예시에서는 Employee 항목에 새 직원 레코드를 추가합니다.
Configure connector task대화상자에서Entities를 클릭합니다.Entity목록에서Employee를 선택합니다.Create작업을 선택한 후 완료를 클릭합니다.- 커넥터 태스크의 태스크 입력 섹션에서
connectorInputPayload를 클릭한 후Default Value필드에 다음과 유사한 값을 입력합니다.{ "EMPLOYEE_ID": 69.0, "EMPLOYEE_NAME": "John", "CITY": "Bangalore" }
통합이 성공하면 커넥터 태스크의
connectorOutputPayload필드에 다음과 유사한 값이 포함됩니다.{ "ROWID": "AAAoU0AABAAAc3hAAF" }
예시 - 직원 레코드 업데이트
이 예시에서는 Employee 항목에서 ID가 69인 직원 레코드를 업데이트합니다.
Configure connector task대화상자에서Entities를 클릭합니다.Entity목록에서Employee를 선택합니다.Update작업을 선택한 후 완료를 클릭합니다.- 커넥터 태스크의 태스크 입력 섹션에서
connectorInputPayload를 클릭한 후Default Value필드에 다음과 유사한 값을 입력합니다.{ "EMPLOYEE_NAME": "John", "CITY": "Mumbai" }
- entityId를 클릭한 후 기본값 필드에
69을 입력합니다.또는 entityId를 지정하는 대신 filterClause를
69로 설정할 수도 있습니다.통합이 성공하면 커넥터 태스크의
connectorOutputPayload필드에 다음과 유사한 값이 포함됩니다.{ }
예시 - 직원 레코드 삭제
이 예시에서는 Employee 항목에서 ID가 35인 직원 레코드를 삭제합니다.
Configure connector task대화상자에서Entities를 클릭합니다.Entity목록에서Employee를 선택합니다.Delete작업을 선택한 후 완료를 클릭합니다.- 커넥터 태스크의 태스크 입력 섹션에서 entityId를 클릭한 후 기본값 필드에
35을 입력합니다.
Terraform을 사용하여 연결 만들기
Terraform 리소스를 사용하여 새 연결을 만들 수 있습니다.
Terraform 구성을 적용하거나 삭제하는 방법은 기본 Terraform 명령어를 참조하세요.
연결 만들기를 위한 샘플 Terraform 템플릿을 보려면 샘플 템플릿을 참조하세요.
Terraform을 사용하여 이 연결을 만들 때는 Terraform 구성 파일에서 다음 변수를 설정해야 합니다.
| 매개변수 이름 | 데이터 유형 | 필수 | 설명 |
|---|---|---|---|
| service_name | STRING | 거짓 | Oracle 데이터베이스의 서비스 이름입니다. |
| data_source | STRING | 거짓 | Oracle Net Services Name, Connect Descriptor(TNS Connect String이라고도 함) 또는 연결할 데이터베이스를 식별하는 쉬운 연결을 이름합니다. |
| include_synonyms | 부울 | 거짓 | 동의어의 메타데이터를 쿼리하고 항목으로 사용할 수 있도록 합니다. 속성을 false로 설정하면 메타데이터 성능이 향상될 수 있습니다. |
| abandoned_connection_timeout | 정수 | 거짓 | 폐기된 연결 제한 시간(초)은 대여한 연결이 폐기된 것으로 간주되기까지 사용되지 않을 수 있는 시간을 지정하는 제한 시간 값을 결정합니다. |
| inactive_connection_timeout | 정수 | 거짓 | 비활성 연결 제한 시간(초)은 사용 가능한 연결이 풀에서 삭제되기 전에 연결 풀에 유지되는 시간을 결정합니다. |
| max_connection_reuse_time | 정수 | 거짓 | 최대 연결 재사용 시간(초)은 풀이 연결을 삭제하고 닫은 후 연결을 잠재적으로 재사용할 수 있는 최대 시간을 지정합니다. |
| ttl_connection_timeout | 정수 | 거짓 | 연결이 사용 중일 수 있는 최대 시간(초)입니다. |
| browsable_schemas | STRING | 거짓 | 쉼표로 구분된 스키마(예: SchemaA, SchemaB) 중에서 항목 및 작업을 가져올 때 사용할 것을 선택합니다. 기본적으로 사용자의 스키마를 사용합니다. |
통합에서 Oracle DB 연결 사용
연결을 만들면 Apigee Integration 및 Application Integration에서 사용할 수 있게 됩니다. 커넥터 태스크를 통해 통합에서 연결을 사용할 수 있습니다.
- Apigee Integration에서 커넥터 태스크를 만들고 사용하는 방법을 알아보려면 커넥터 태스크를 참조하세요.
- Application Integration에서 커넥터 태스크를 만들고 사용하는 방법을 이해하려면 커넥터 태스크를 참조하세요.
Google Cloud 커뮤니티에서 도움 받기
Google Cloud 커뮤니티에서 Cloud 포럼에 질문을 게시하고 이 커넥터에 대해 토론할 수 있습니다.다음 단계
- 연결 일시중지 및 재개 방법 알아보기
- 커넥터 사용량 모니터링 방법 알아보기
- 커넥터 로그 확인 방법 알아보기