BigQuery
Use the BigQuery connector to perform insert, delete, update, and read operations on Google BigQuery data. You can also execute custom SQL queries against BigQuery data. You can use BigQuery connector to integrate data from multiple Google Cloud services or other third-party services, such as Cloud Storage or Amazon S3.
Before you begin
In your Google Cloud project, do the following tasks:
- Ensure that network connectivity is set up. For information about network patterns, see Network connectivity.
- Grant the roles/connectors.admin IAM role to the user configuring the connector.
- Grant the
roles/bigquery.dataEditorIAM role to the service account that you want to use for the connector. If you don't have a service account, you must create a service account. The connector and the service account must belong to the same project. - Enable the following services:
secretmanager.googleapis.com(Secret Manager API)connectors.googleapis.com(Connectors API)
To understand how to enable services, see Enabling services. If these services or permissions have not been enabled for your project previously, you are prompted to enable them when you configure the connector.
Create a BigQuery connection
A connection is specific to a data source. It means that if you have many data sources, you must create a separate connection for each data source. To create a connection, do the following:
- In the Cloud console, go to the Integration Connectors > Connections page and then select or create a Google Cloud project.
- Click + CREATE NEW to open the Create Connection page.
- In the Location section, select a location from the Region list and then click NEXT.
For the list of all the supported regions, see Locations.
- In the Connection Details section, do the following:
- Select BigQuery from the Connector list.
- Select a connector version from the Connector version list.
- In the Connection Name field, enter a name for the connection instance. The connection name can contain lower-case letters, numbers, or hyphens. The name must begin with a letter and end with a letter or number and the name must not exceed 49 characters.
- Optionally, enable Cloud logging,
and then select a log level. By default, the log level is set to
Error. - Service Account: Select a service account that has the required roles.
- (Optional) Configure the Connection node settings.
- Minimum number of nodes: Enter the minimum number of connection nodes.
- Maximum number of nodes: Enter the maximum number of connection nodes.
- Project ID: The ID of the Google Cloud project where the data resides.
- Dataset ID: The ID of the BigQuery Dataset.
- To support BigQuery Array data type, select Support Native Data Types. The following array types are supported: Varchar, Int64, Float64, Long, Double, Bool, and Timestamp. Nested arrays are not supported.
- (Optional) To configure a proxy server for the connection, select Use proxy and enter the proxy details.
-
Proxy Auth Scheme: Select the authentication type to authenticate with the proxy server. The following authentication types are supported:
- Basic: Basic HTTP authentication.
- Digest: Digest HTTP authentication.
- Proxy User: A user name to be used to authenticate with the proxy server.
- Proxy Password: The Secret manager secret of the user's password.
-
Proxy SSL Type: The SSL type to use when connecting to the proxy server. The following authentication types are supported:
- Auto: Default setting. If the URL is an HTTPS URL, then the Tunnel option is used. If the URL is an HTTP URL, then the NEVER option is used.
- Always: The connection is always SSL enabled.
- Never: The connection is not SSL enabled.
- Tunnel: The connection is through a tunneling proxy. The proxy server opens a connection to the remote host and traffic flows back and forth through the proxy.
- In the Proxy Server section, enter details of the proxy server.
- Click + Add destination.
- Select a Destination Type.
- Host address: Specify the hostname or IP address of the destination.
If you want to establish a private connection to your backend system, do the following:
- Create a PSC service attachment.
- Create an endpoint attachment and then enter the details of the endpoint attachment in the Host address field.
- Host address: Specify the hostname or IP address of the destination.
- Click NEXT.
A node is a unit (or replica) of a connection that processes transactions. More nodes are required to process more transactions for a connection and conversely, fewer nodes are required to process fewer transactions. To understand how the nodes affect your connector pricing, see Pricing for connection nodes. If you don't enter any values, by default the minimum nodes are set to 2 (for better availability) and the maximum nodes are set to 50.
-
In the Authentication section, enter the authentication details.
- Select whether to authenticate with OAuth 2.0 - Authorization code or to proceed without authentication.
To understand how to configure authentication, see Configure authentication.
- Click NEXT.
- Select whether to authenticate with OAuth 2.0 - Authorization code or to proceed without authentication.
- Review your connection and authentication details, and then click Create.
Configure authentication
Enter the details based on the authentication you want to use.
- No Authentication: Select this option if you don't require authentication.
- OAuth 2.0 - Authorization code: Select this option to authenticate using a web-based user login flow. Specify the following details:
- Client ID: The client ID required to connect to your backend Google service.
- Scopes: A comma-separated list of desired scopes. To view all the supported OAuth 2.0 scopes for your required Google service, see the relevant section in the OAuth 2.0 Scopes for Google APIs page.
- Client secret: Select the Secret Manager secret. You must have created the Secret Manager secret prior configuring this authorization.
- Secret version: Secret Manager secret version for client secret.
For the Authorization code authentication type, after creating the connection, you must authorize the connection.
Authorize the connection
If you use OAuth 2.0 - authorization code to authenticate the connection, complete the following tasks after you create the connection.
- In the Connections page,
locate the newly created connection.
Notice that the Status for the new connector will be Authorization required.
- Click Authorization required.
This shows the Edit authorization pane.
- Copy the Redirect URI value to your external application.
- Verify the authorization details.
- Click Authorize.
If the authorization is successful, the connection status will be set to Active in the Connections page.
Re-authorization for authorization code
If you are using Authorization code authentication type and have made any configuration changes in BigQuery,
you must re-authorize your BigQuery connection. To re-authorize a connection, perform the following steps:
- Click on the required connection in the Connections page.
This opens the connection details page.
- Click Edit to edit the connection details.
- Verify the OAuth 2.0 - Authorization code details in the Authentication section.
If required, make the necessary changes.
- Click Save. This takes you to the connection details page.
- Click Edit authorization in the Authentication section. This shows the Authorize pane.
- Click Authorize.
If the authorization is successful, the connection status will be set to Active in the Connections page.
Use the BigQuery connection in an integration
After you create the connection, it becomes available in both Apigee Integration and Application Integration. You can use the connection in an integration through the Connectors task.
- To understand how to create and use the Connectors task in Apigee Integration, see Connectors task.
- To understand how to create and use the Connectors task in Application Integration, see Connectors task.
Actions
This section describes the actions available in the BigQuery connector.
The results of all the entity operations
and actions will be available as a JSON response in the Connectors task's connectorOutputPayload
response parameter after you run your integration.
CancelJob action
This action lets you cancel a running BigQuery job.
The following table describes the input parameters of the CancelJob action.
| Parameter name | Data type | Description |
|---|---|---|
| JobId | String | The ID of the job you want to cancel. This is a mandatory field. |
| Region | String | The region where the job is currently executing. This is not required if the job is a US or EU region. |
GetJob action
This action lets you retrieve the configuration information and execution state of an existing job.
The following table describes the input parameters of the GetJob action.
| Parameter name | Data type | Description |
|---|---|---|
| JobId | String | The ID of the job for which you want to retrieve the configuration. This is a mandatory field. |
| Region | String | The region where the job is currently executing. This is not required if the job is a US or EU region. |
InsertJob action
This action lets you insert a BigQuery job, which can then be selected later to retrieve the query results.
The following table describes the input parameters of the InsertJob action.
| Parameter name | Data type | Description |
|---|---|---|
| Query | String | The query to submit to BigQuery. This is a mandatory field. |
| IsDML | String | Should be set to true if the query is a DML statement or false
otherwise. The default value is false. |
| DestinationTable | String | The destination table for the query, in the DestProjectId:DestDatasetId.DestTable format. |
| WriteDisposition | String | Specifies how to write data to the destination table; such as truncate existing results,
append existing results, or write only when the table is empty. Following are the supported
values:
|
| DryRun | String | Specifies if the job's execution is a dry run. |
| MaximumBytesBilled | String | Specifies the maximum bytes that can be processed by the job. BigQuery cancels the job if the job attempts to process more bytes than the specified value. |
| Region | String | Specifies the region where the job should execute. |
InsertLoadJob action
This action lets you insert a BigQuery load job, which adds data from Google Cloud Storage into an existing table.
The following table describes the input parameters of the InsertLoadJob action.
| Parameter name | Data type | Description |
|---|---|---|
| SourceURIs | String | A space-separated list of Google Cloud Storage URIs. |
| SourceFormat | String | The source format of the files. Following are the supported values:
|
| DestinationTable | String | The destination table for the query, in the DestProjectId.DestDatasetId.DestTable format. |
| DestinationTableProperties | String | A JSON object specifying the table friendly name, description, and list of labels. |
| DestinationTableSchema | String | A JSON list specifying the fields used to create the table. |
| DestinationEncryptionConfiguration | String | A JSON object specifying the KMS encryption settings for the table. |
| SchemaUpdateOptions | String | A JSON list specifying the options to apply when updating the destination table schema. |
| TimePartitioning | String | A JSON object specifying the time partitioning type and field. |
| RangePartitioning | String | A JSON object specifying the range partitioning field and buckets. |
| Clustering | String | A JSON object specifying the fields to be used for clustering. |
| Autodetect | String | Specifies if options and schema should be automatically determined for JSON and CSV files. |
| CreateDisposition | String | Specifies if the destination table needs to be created if it doesn't already exist. Following
are the supported values:
|
| WriteDisposition | String | Specifies how to write data to the destination table, such as; truncate existing results,
appending existing results, or writing only when the table is empty. Following are the
supported values:
|
| Region | String | Specifies the region where the job should execute. Both the Google Cloud Storage resources and the BigQuery dataset must be in the same region. |
| DryRun | String | Specifies if the job's execution is a dry run. The default value is false. |
| MaximumBadRecords | String | Specifies the number of records that can be invalid before the entire job is canceled. By default all records must be valid. The default value is 0. |
| IgnoreUnknownValues | String | Specifies if the unknown fields must be ignored in the input file or treat them as errors. By default they are treated as errors. The default value is false. |
| AvroUseLogicalTypes | String | Specifies if AVRO logical types must be used to convert AVRO data to BigQuery types. The default
value is true. |
| CSVSkipLeadingRows | String | Specifies how many rows to skip at the start of CSV files. This is usually used to skip header rows. |
| CSVEncoding | String | Encoding type of the CSV files. Following are the supported values:
|
| CSVNullMarker | String | If provided, this string is used for NULL values within CSV files. By default, CSV files cannot use NULL. |
| CSVFieldDelimiter | String | The character used to separate columns within CSV files. The default value is a comma (,). |
| CSVQuote | String | The character used for quoted fields in CSV files. May be set to empty to disable quoting. The
default value is double quotes ("). |
| CSVAllowQuotedNewlines | String | Specifies if the CSV files can contain newlines within quoted fields. The default value is false. |
| CSVAllowJaggedRows | String | Specifies if the CSV files can contain missing fields. The default value is false. |
| DSBackupProjectionFields | String | A JSON list of fields to load from a Cloud datastore backup. |
| ParquetOptions | String | A JSON object specifying the Parquet-specific import options. |
| DecimalTargetTypes | String | A JSON list giving the preference order applied to numeric types. |
| HivePartitioningOptions | String | A JSON object specifying the source-side partitioning options. |
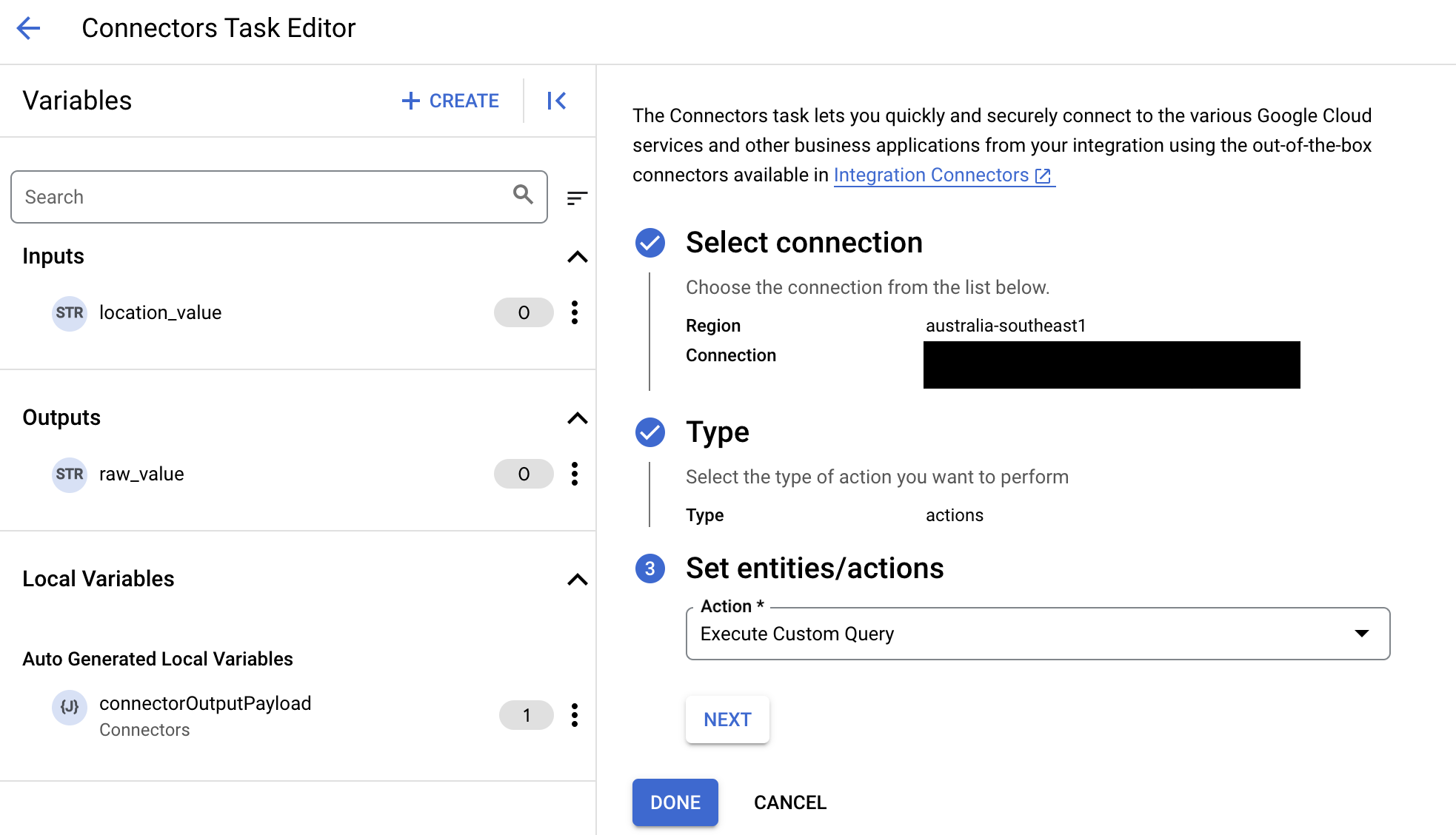
Execute custom SQL query
To create a custom query, follow these steps:
- Follow the detailed instructions to add a connectors task.
- When you configure the connector task, in the type of action you want to perform, select Actions.
- In the Action list, select Execute custom query, and then click Done.
- Expand the Task input section, and then do the following:
- In the Timeout after field, enter the number of seconds to wait till the query executes.
Default value:
180seconds. - In the Maximum number of rows field, enter the maximum number of rows to be returned from the database.
Default value:
25. - To update the custom query, click Edit Custom Script. The Script editor dialog opens.
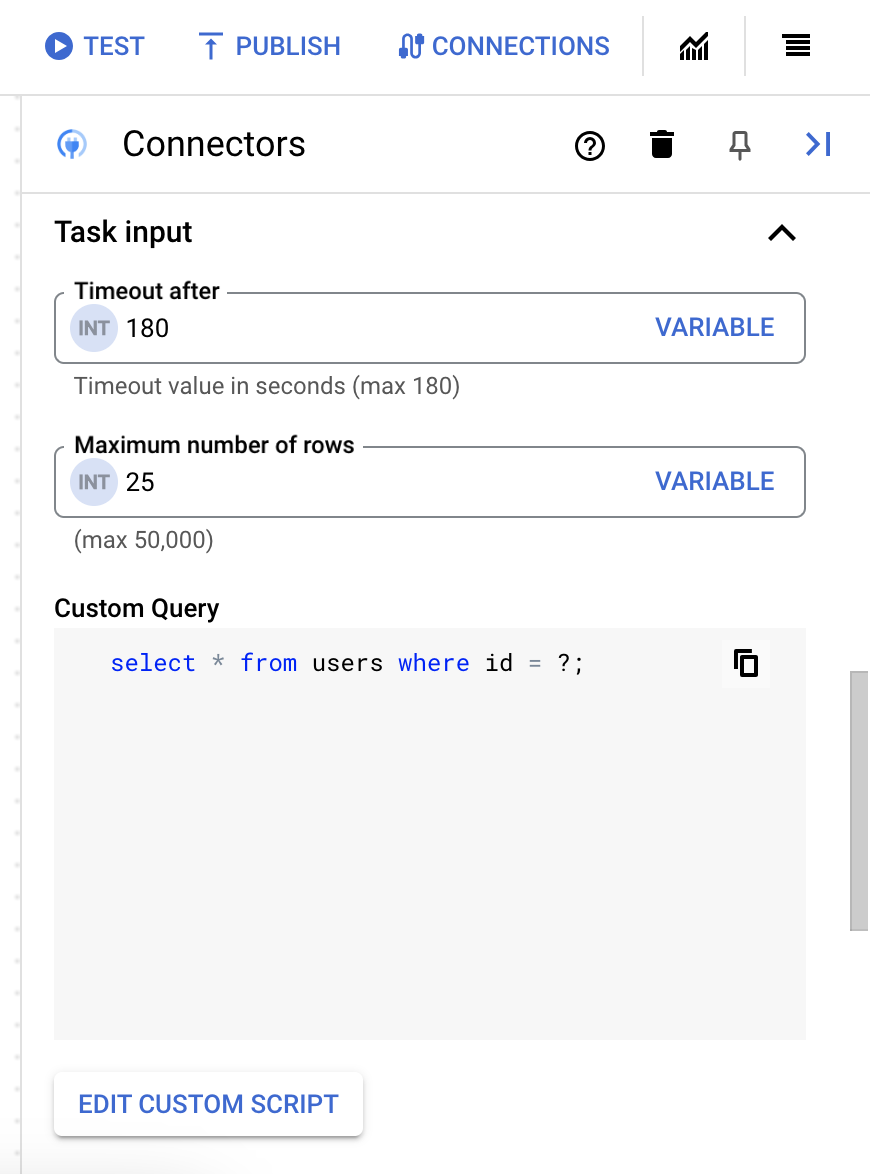
- In the Script editor dialog, enter the SQL query and click Save.
You can use a question mark (?) in a SQL statement to represent a single parameter that must be specified in the query parameters list. For example, the following SQL query selects all rows from the
Employeestable that matches the values specified for theLastNamecolumn:SELECT * FROM Employees where LastName=?
- If you've used question marks in your SQL query, you must add the parameter by clicking + Add Parameter Name for each question mark. While executing the integration, these parameters replace the question marks (?) in the SQL query sequentially. For example, if you have added three question marks (?), then you must add three parameters in order of sequence.
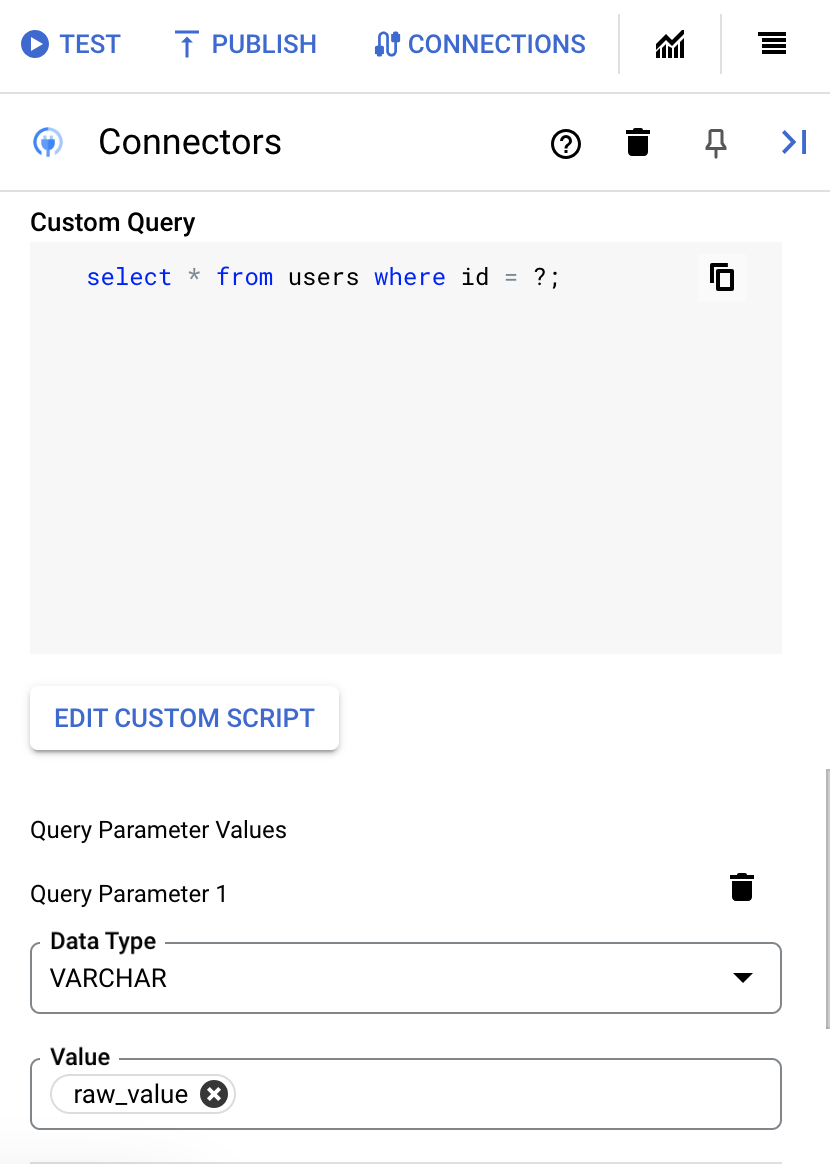
To add query parameters, do the following:
- From the Type list, select the data type of the parameter.
- In the Value field, enter the value of the parameter.
- To add multiple parameters, click + Add Query Parameter.
The Execute custom query action does not support array variables.
- In the Timeout after field, enter the number of seconds to wait till the query executes.
Use terraform to create connections
You can use the Terraform resource to create a new connection.
To learn how to apply or remove a Terraform configuration, see Basic Terraform commands.
To view a sample terraform template for connection creation, see sample template.
When creating this connection by using Terraform, you must set the following variables in your Terraform configuration file:
| Parameter name | Data type | Required | Description |
|---|---|---|---|
| project_id | STRING | True | The ID of the project containing BigQuery dataset. e.g. myproject. |
| dataset_id | STRING | False | Dataset ID of the BigQuery dataset without the project name. e.g. mydataset. |
| proxy_enabled | BOOLEAN | False | Select this checkbox to configure a proxy server for the connection. |
| proxy_auth_scheme | ENUM | False | The authentication type to use to authenticate to the ProxyServer proxy. Supported values are: BASIC, DIGEST, NONE |
| proxy_user | STRING | False | A user name to be used to authenticate to the ProxyServer proxy. |
| proxy_password | SECRET | False | A password to be used to authenticate to the ProxyServer proxy. |
| proxy_ssltype | ENUM | False | The SSL type to use when connecting to the ProxyServer proxy. Supported values are: AUTO, ALWAYS, NEVER, TUNNEL |
System limitations
The BigQuery connector can process a maximum of 8 transactions per second, per node, and throttles any transactions beyond this limit. By default, Integration Connectors allocates 2 nodes (for better availability) for a connection.
For information on the limits applicable to Integration Connectors, see Limits.
Supported data types
The following are the supported data types for this connector:
- ARRAY
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- TIME
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
Known limitations
-
The BigQuery connector doesn't support the primary key in a BigQuery table. It means that you can't perform the Get, Update, and Delete entity operations by using an
entityId. Alternately, you can use the filter clause to filter records based on an ID. -
When you fetch data for the first time, you might experience an initial latency of around 6 seconds. Due to caching, there is no latency for subsequent requests. This latency can recur upon cache expiry.
Get help from the Google Cloud community
You can post your questions and discuss this connector in the Google Cloud community at Cloud Forums.
What's next
- Understand how to suspend and resume a connection.
- Understand how to monitor connector usage.
- Understand how to view connector logs.