BigQuery
Usa el conector de BigQuery para realizar operaciones de inserción, eliminación, actualización y lectura en los datos de Google BigQuery. También puedes ejecutar consultas de SQL personalizadas en los datos de BigQuery. Puedes usar el conector de BigQuery para integrar datos de varios servicios de Google Cloud o de otros servicios de terceros, como Cloud Storage o Amazon S3.
Antes de comenzar
En tu proyecto de Google Cloud, realiza las siguientes tareas:
- Asegúrate de que la conectividad de red esté configurada. Para obtener información sobre los patrones de red, consulta Conectividad de red.
- Otorga el rol de IAM roles/connectors.admin al usuario que configura el conector.
- Otorga el rol de IAM
roles/bigquery.dataEditora la cuenta de servicio que deseas usar para el conector. Si no tienes una cuenta de servicio, debes crear una. El conector y la cuenta de servicio deben pertenecer al mismo proyecto. - Habilita los siguientes servicios:
secretmanager.googleapis.com(API de Secret Manager)connectors.googleapis.com(API de conectores)
Para comprender cómo habilitar servicios, consulta Habilita servicios. Si estos servicios o permisos no se habilitaron antes para tu proyecto, se te solicitará que los habilites cuando configures el conector.
Crea una conexión de BigQuery
Una conexión es específica de una fuente de datos. Significa que, si tienes muchas fuentes de datos, debes crear una conexión independiente para cada fuente. Para crear una conexión, haz lo siguiente:
- En la consola de Cloud, ve a la página Conectores de Integration > Conexiones y, luego, selecciona o crea un proyecto de Google Cloud.
- Haz clic en + CREAR NUEVO para abrir la página Crear conexión.
- En la sección Ubicación, selecciona una ubicación de la lista Región y, luego, haz clic en SIGUIENTE.
Para obtener la lista de todas las regiones compatibles, consulta Ubicaciones.
- En la sección Detalles de la conexión, haz lo siguiente:
- Selecciona BigQuery en la lista Conector.
- Selecciona una versión del conector en la lista Versión del conector.
- En el campo Nombre de la conexión, ingresa un nombre para la instancia de conexión. El nombre de la conexión puede contener letras minúsculas, números o guiones. El nombre debe comenzar con una letra y terminar con una letra o un número, y no debe exceder los 49 caracteres.
- De manera opcional, habilita Cloud Logging y, luego, selecciona un nivel de registro. De forma predeterminada, el nivel de registro se establece en
Error. - Cuenta de servicio: Selecciona una cuenta de servicio que tenga los roles necesarios.
- (Opcional) Configura los parámetros de nodo de conexión.
- Cantidad mínima de nodos: Ingresa la cantidad mínima de nodos de conexión.
- Cantidad máxima de nodos: Ingresa la cantidad máxima de nodos de conexión.
- ID del proyecto: Ingresa el ID del proyecto de Google Cloud en el que residen los datos.
- ID del conjunto de datos: Ingresa el ID del conjunto de datos de BigQuery.
- Para admitir el tipo de datos Array de BigQuery, selecciona Support Native Data Types. Se admiten los siguientes tipos de arrays: Varchar, Int64, Float64, Long, Double, Bool y Timestamp. No se admiten los arrays anidados.
- (Opcional) Para configurar un servidor proxy para la conexión, selecciona Usar proxy y, luego, ingresa los detalles del proxy.
-
Esquema de autenticación del proxy: Selecciona el tipo de autenticación para autenticar con el servidor proxy. Se admiten los siguientes tipos de autenticación:
- Básico: Autenticación HTTP básica.
- Resumen: Autenticación de HTTP de resumen.
- Usuario de proxy: Un nombre de usuario que se usará para autenticarse con el servidor proxy.
- Contraseña de proxy: el secreto de Secret Manager de la contraseña del usuario.
-
Tipo de SSL del proxy: el tipo de SSL que se usará para conectarse al servidor del proxy. Se admiten los siguientes tipos de autenticación:
- Automático: Configuración predeterminada. Si la URL es HTTPS, se usa la opción Túnel. Si la URL es una URL HTTP, se usa la opción NUNCA.
- Siempre: La conexión siempre está habilitada para SSL.
- Nunca: La conexión no está habilitada para SSL.
- Túnel: La conexión se realiza a través de un proxy de túnel. El servidor proxy abre una conexión con el host remoto y el tráfico fluye de un lado a otro a través del proxy.
- En la sección Proxy Server, ingresa los detalles del servidor proxy.
- Haz clic en Agregar destino.
- Selecciona un Tipo de destino.
- Dirección del host: Especifica el nombre de host o la dirección IP del destino.
Si deseas establecer una conexión privada a tu sistema de backend, haz lo siguiente:
- Crea un adjunto de servicio de PSC.
- Crea un adjunto de extremo y, luego, ingresa los detalles del adjunto del extremo en el campo Dirección del host.
- Dirección del host: Especifica el nombre de host o la dirección IP del destino.
- Haz clic en SIGUIENTE.
Un nodo es una unidad (o réplica) de una conexión que procesa transacciones. Se requieren más nodos para procesar más transacciones para una conexión y, del mismo modo, se requieren menos para procesar menos transacciones. Para comprender cómo los nodos afectan el precio del conector, consulta Precios de nodos de conexión. Si no ingresas ningún valor, de forma predeterminada, los nodos mínimos se establecen en 2 (para una mejor disponibilidad) y los nodos máximos se establecen en 50.
-
En la sección Autenticación, ingresa los detalles de autenticación.
- Selecciona si deseas autenticarte con el código de autorización de OAuth 2.0 o continuar sin autenticación.
Para comprender cómo configurar la autenticación, consulta Configura la autenticación.
- Haz clic en SIGUIENTE.
- Selecciona si deseas autenticarte con el código de autorización de OAuth 2.0 o continuar sin autenticación.
- Revisa los detalles de conexión y autenticación, y, luego, haz clic en Crear.
Configura la autenticación
Ingresa los detalles según la autenticación que desees usar.
- Sin autenticación: Selecciona esta opción si no necesitas autenticación.
- OAuth 2.0 - Código de autorización: Selecciona esta opción para autenticarte con un flujo de acceso de usuario basado en la Web. Especifica los siguientes detalles:
- ID de cliente: Es el ID de cliente necesario para conectarse a tu servicio de backend de Google.
- Permisos: Es una lista separada por comas de los permisos deseados. Para ver todos los permisos de OAuth 2.0 admitidos para el servicio de Google que necesitas, consulta la sección correspondiente en la página Permisos de OAuth 2.0 para las APIs de Google.
- Secreto del cliente: Selecciona el secreto de Secret Manager. Debes crear el secreto de Secret Manager antes de configurar esta autorización.
- Versión del secreto: La versión del secreto de Secret Manager para el secreto del cliente.
Para el tipo de autenticación Authorization code, después de crear la conexión, debes autorizar la conexión.
Autoriza la conexión
Si usas el código de autorización de OAuth 2.0 para autenticar la conexión, completa las siguientes tareas después de crear la conexión.
- En la página Connections, busca la conexión recién creada.
Observa que el Estado del conector nuevo será Se requiere autorización.
- Haz clic en Se requiere autorización.
Se mostrará el panel Editar autorización.
- Copia el valor del URI de redireccionamiento en tu aplicación externa.
- Verifica los detalles de la autorización.
- Haz clic en Autorizar.
Si la autorización se realiza correctamente, el estado de la conexión se establecerá en Activa en la página Conexiones.
Cómo volver a autorizar el código de autorización
Si usas el tipo de autenticación Authorization code y realizaste cambios de configuración en BigQuery,
debes volver a autorizar tu conexión de BigQuery. Para volver a autorizar una conexión, sigue estos pasos:
- Haz clic en la conexión requerida en la página Conexiones.
Se abrirá la página de detalles de la conexión.
- Haz clic en Editar para editar los detalles de la conexión.
- Verifica los detalles de OAuth 2.0 - Código de autorización en la sección Autenticación.
Si es necesario, realiza los cambios necesarios.
- Haz clic en Guardar. Esto te llevará a la página de detalles de la conexión.
- Haz clic en Editar autorización en la sección Autenticación. Se mostrará el panel Autorizar.
- Haz clic en Autorizar.
Si la autorización se realiza correctamente, el estado de la conexión se establecerá como Activa en la página Conexiones.
Usa la conexión de BigQuery en una integración
Después de crear la conexión, estará disponible en Apigee Integration y Application Integration. Puedes usar la conexión en una integración a través de la tarea Connectors.
- Para comprender cómo crear y usar la tarea Connectors en Apigee Integration, consulta Tarea Connectors.
- Para comprender cómo crear y usar la tarea Connectors en Application Integration, consulta Tarea Connectors.
Acciones
En esta sección, se describen las acciones disponibles en el conector de BigQuery.
Los resultados de todas las operaciones y acciones de entidades estarán disponibles como una respuesta JSON en el parámetro de respuesta connectorOutputPayload de la tarea Connectors después de ejecutar la integración.
Acción CancelJob
Esta acción te permite cancelar un trabajo de BigQuery en ejecución.
En la siguiente tabla, se describen los parámetros de entrada de la acción CancelJob.
| Nombre del parámetro | Tipo de dato | Descripción |
|---|---|---|
| JobId | String | ID del trabajo que deseas cancelar. Este campo es obligatorio. |
| Región | String | Es la región en la que se está ejecutando el trabajo actualmente. Esto no es necesario si el trabajo se encuentra en una región de EE.UU. o la UE. |
Acción GetJob
Esta acción te permite recuperar la información de configuración y el estado de ejecución de un trabajo existente.
En la siguiente tabla, se describen los parámetros de entrada de la acción GetJob.
| Nombre del parámetro | Tipo de dato | Descripción |
|---|---|---|
| JobId | String | Es el ID del trabajo para el que deseas recuperar la configuración. Este campo es obligatorio. |
| Región | String | Es la región en la que se está ejecutando el trabajo actualmente. Esto no es necesario si el trabajo se encuentra en una región de EE.UU. o la UE. |
Acción de InsertJob
Esta acción te permite insertar un trabajo de BigQuery, que luego se puede seleccionar para recuperar los resultados de la consulta.
En la siguiente tabla, se describen los parámetros de entrada de la acción InsertJob.
| Nombre del parámetro | Tipo de dato | Descripción |
|---|---|---|
| Consulta | String | Es la consulta que se enviará a BigQuery. Este campo es obligatorio. |
| IsDML | String | Debe establecerse en true si la consulta es una declaración DML o false en cualquier otro caso. El valor predeterminado es false. |
| DestinationTable | String | Tabla de destino de la consulta, en formato DestProjectId:DestDatasetId.DestTable. |
| WriteDisposition | String | Especifica cómo escribir datos en la tabla de destino, por ejemplo, truncar los resultados existentes, anexar los resultados existentes o escribir solo cuando la tabla esté vacía. A continuación, se indican los valores admitidos:
|
| DryRun | String | Especifica si la ejecución del trabajo es una prueba de validación. |
| MaximumBytesBilled | String | Especifica la cantidad máxima de bytes que puede procesar el trabajo. BigQuery cancela el trabajo si este intenta procesar más bytes que el valor especificado. |
| Región | String | Especifica la región en la que se debe ejecutar el trabajo. |
Acción InsertLoadJob
Esta acción te permite insertar un trabajo de carga de BigQuery, que agrega datos de Google Cloud Storage a una tabla existente.
En la siguiente tabla, se describen los parámetros de entrada de la acción InsertLoadJob.
| Nombre del parámetro | Tipo de dato | Descripción |
|---|---|---|
| SourceURIs | String | Es una lista de URIs de Google Cloud Storage separados por espacios. |
| SourceFormat | String | Es el formato de origen de los archivos. A continuación, se indican los valores admitidos:
|
| DestinationTable | String | Tabla de destino de la consulta, en formato DestProjectId.DestDatasetId.DestTable. |
| DestinationTableProperties | String | Es un objeto JSON que especifica el nombre descriptivo, la descripción y la lista de etiquetas de la tabla. |
| DestinationTableSchema | String | Es una lista JSON que especifica los campos que se usan para crear la tabla. |
| DestinationEncryptionConfiguration | String | Es un objeto JSON que especifica la configuración de encriptación de KMS para la tabla. |
| SchemaUpdateOptions | String | Es una lista en formato JSON que especifica las opciones que se aplicarán cuando se actualice el esquema de la tabla de destino. |
| TimePartitioning | String | Es un objeto JSON que especifica el tipo y el campo de la partición por tiempo. |
| RangePartitioning | String | Es un objeto JSON que especifica el campo y buckets de la partición por rango. |
| Agrupamiento en clústeres | String | Es un objeto JSON que especifica los campos que se usarán para el agrupamiento en clústeres. |
| Detección automática | String | Especifica si las opciones y el esquema se deben determinar automáticamente para los archivos JSON y CSV. |
| CreateDisposition | String | Especifica si se debe crear la tabla de destino si aún no existe. A continuación, se indican los valores admitidos:
|
| WriteDisposition | String | Especifica cómo escribir datos en la tabla de destino, por ejemplo, truncar los resultados existentes, anexar los resultados existentes o escribir solo cuando la tabla esté vacía. A continuación, se indican los valores admitidos:
|
| Región | String | Especifica la región en la que se debe ejecutar el trabajo. Tanto los recursos de Google Cloud Storage como el conjunto de datos de BigQuery deben estar en la misma región. |
| DryRun | String | Especifica si la ejecución del trabajo es una prueba de validación. El valor predeterminado es false. |
| MaximumBadRecords | String | Especifica la cantidad de registros que pueden ser no válidos antes de que se cancele todo el trabajo. De forma predeterminada, todos los registros deben ser válidos. El valor predeterminado es 0. |
| IgnoreUnknownValues | String | Especifica si se deben ignorar los campos desconocidos en el archivo de entrada o si se deben tratar como errores. De forma predeterminada, se tratan como errores. El valor predeterminado es false. |
| AvroUseLogicalTypes | String | Especifica si se deben usar tipos lógicos de AVRO para convertir datos de AVRO en tipos de BigQuery. El valor predeterminado es true. |
| CSVSkipLeadingRows | String | Especifica cuántas filas se deben omitir al comienzo de los archivos CSV. Por lo general, se usa para omitir filas de encabezado. |
| CSVEncoding | String | Es el tipo de codificación de los archivos CSV. A continuación, se indican los valores admitidos:
|
| CSVNullMarker | String | Si se proporciona, esta cadena se usa para los valores NULL en los archivos CSV. De forma predeterminada, los archivos CSV no pueden usar NULL. |
| CSVFieldDelimiter | String | Es el carácter que se usa para separar las columnas en los archivos CSV. El valor predeterminado es una coma (,). |
| CSVQuote | String | Es el carácter que se usa para los campos entre comillas en los archivos CSV. Se puede establecer como vacío para inhabilitar las comillas. El valor predeterminado son comillas dobles ("). |
| CSVAllowQuotedNewlines | String | Especifica si los archivos CSV pueden contener saltos de línea dentro de los campos entre comillas. El valor predeterminado es false. |
| CSVAllowJaggedRows | String | Especifica si los archivos CSV pueden contener campos faltantes. El valor predeterminado es false. |
| DSBackupProjectionFields | String | Es una lista en formato JSON de los campos que se cargarán desde una copia de seguridad de Cloud Datastore. |
| ParquetOptions | String | Es un objeto JSON que especifica las opciones de importación específicas de Parquet. |
| DecimalTargetTypes | String | Es una lista JSON que indica el orden de preferencia aplicado a los tipos numéricos. |
| HivePartitioningOptions | String | Es un objeto JSON que especifica las opciones de partición del lado de la fuente. |
Ejecuta una consulta en SQL personalizada
Para crear una consulta personalizada, sigue estos pasos:
- Sigue las instrucciones detalladas para agregar una tarea de conectores.
- Cuando configures la tarea del conector, en el tipo de acción que deseas realizar, selecciona Acciones.
- En la lista Acción, selecciona Ejecutar consulta personalizada y, luego, haz clic en Listo.
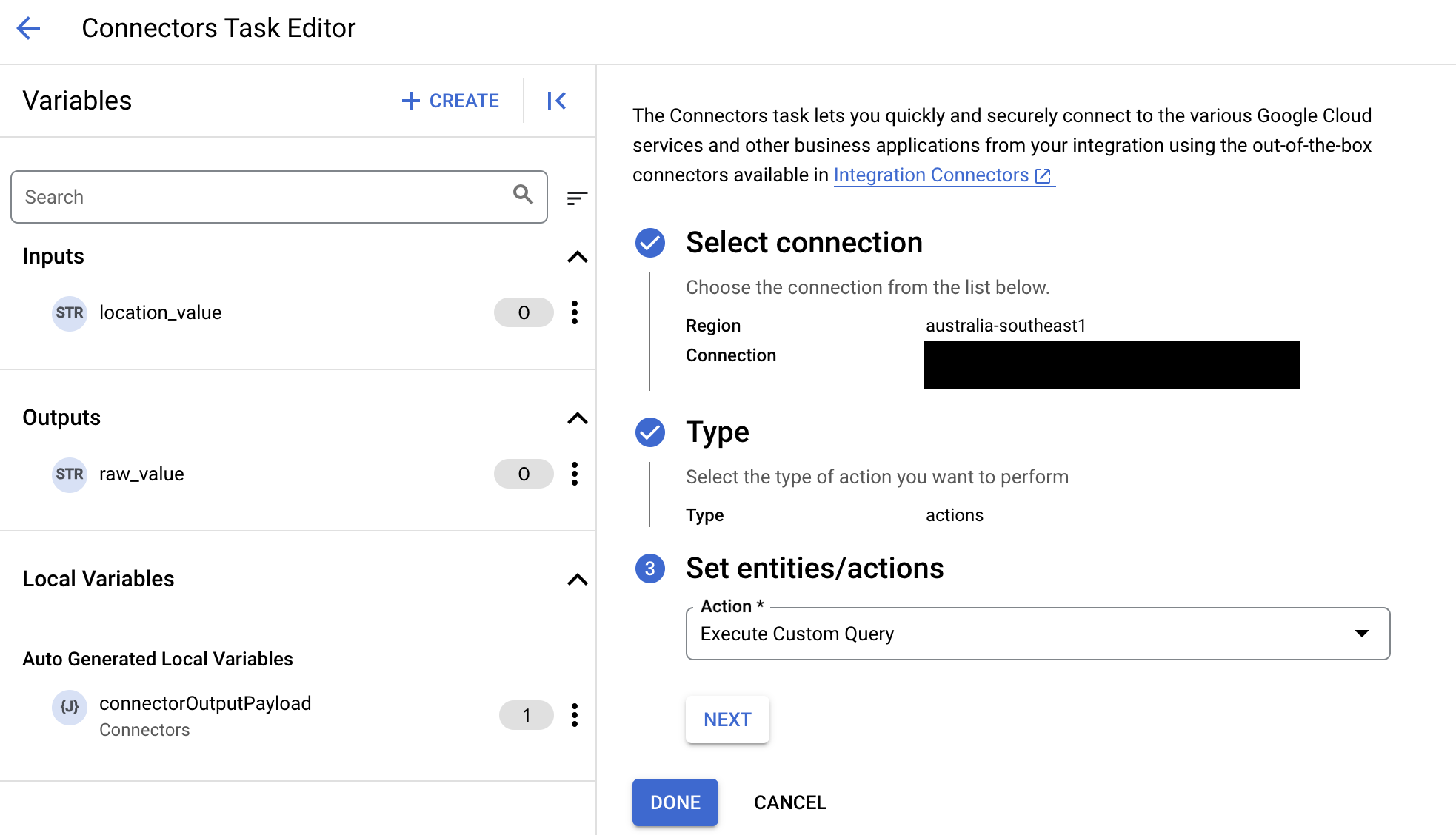
- Expande la sección Task input y, luego, haz lo siguiente:
- En el campo Tiempo de espera después de, ingresa la cantidad de segundos que se debe esperar hasta que se ejecute la consulta.
El valor predeterminado es
180segundos. - En el campo Cantidad máxima de filas, ingresa la cantidad máxima de filas que se devolverán de la base de datos.
Valor predeterminado:
25. - Para actualizar la consulta personalizada, haz clic en Editar secuencia de comandos personalizada. Se abrirá el diálogo Editor de secuencias de comandos.
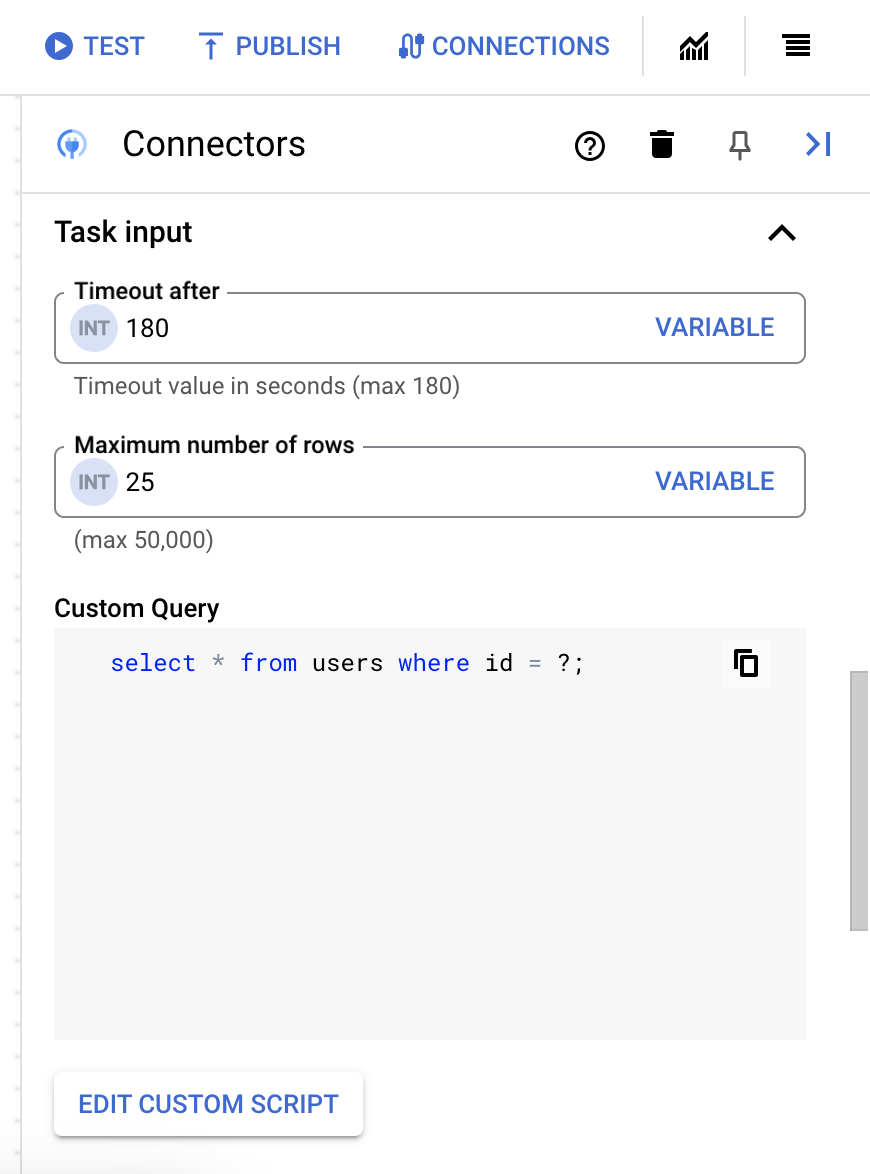
- En el diálogo Editor de secuencias de comandos, ingresa la consulta en SQL y haz clic en Guardar.
Puedes usar un signo de interrogación (?) en una instrucción de SQL para representar un solo parámetro que se debe especificar en la lista de parámetros de la consulta. Por ejemplo, la siguiente consulta en SQL selecciona todas las filas de la tabla
Employeesque coinciden con los valores especificados para la columnaLastName:SELECT * FROM Employees where LastName=?
- Si usaste signos de interrogación en tu consulta en SQL, debes agregar el parámetro haciendo clic en + Agregar nombre de parámetro para cada signo de interrogación. Mientras se ejecuta la integración, estos parámetros reemplazan los signos de interrogación (?) en la consulta en SQL de forma secuencial. Por ejemplo, si agregaste tres signos de interrogación (?), debes agregar tres parámetros en orden de secuencia.
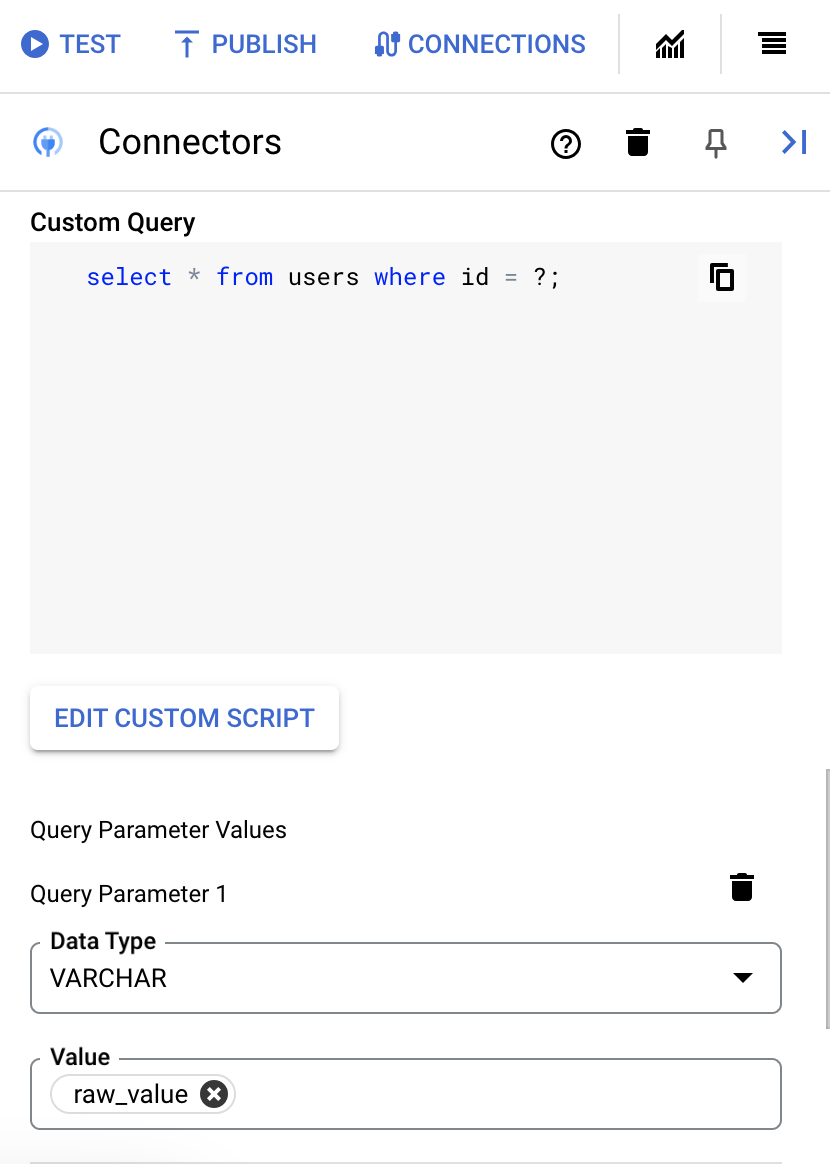
Para agregar parámetros de búsqueda, haz lo siguiente:
- En la lista Tipo, selecciona el tipo de datos del parámetro.
- En el campo Valor, ingresa el valor del parámetro.
- Para agregar varios parámetros, haz clic en + Agregar parámetro de consulta.
La acción Ejecutar consulta personalizada no admite variables de array.
- En el campo Tiempo de espera después de, ingresa la cantidad de segundos que se debe esperar hasta que se ejecute la consulta.
Usa Terraform para crear conexiones
Puedes usar el recurso de Terraform para crear una conexión nueva.
Si deseas obtener más información para aplicar o quitar una configuración de Terraform, consulta los comandos básicos de Terraform.
Para ver una plantilla de Terraform de ejemplo para la creación de conexiones, consulta la plantilla de ejemplo.
Cuando crees esta conexión con Terraform, debes establecer las siguientes variables en tu archivo de configuración de Terraform:
| Nombre del parámetro | Tipo de datos | Obligatorio | Descripción |
|---|---|---|---|
| project_id | STRING | Verdadero | Es el ID del proyecto que contiene el conjunto de datos de BigQuery, p. ej., myproject. |
| dataset_id | STRING | Falso | ID del conjunto de datos de BigQuery sin el nombre del proyecto, p. ej., mydataset. |
| proxy_enabled | BOOLEAN | Falso | Selecciona esta casilla de verificación para configurar un servidor proxy para la conexión. |
| proxy_auth_scheme | ENUM | Falso | Tipo de autenticación que se usará para autenticarse en el proxy de ProxyServer. Los valores admitidos son BASIC, DIGEST y NONE. |
| proxy_user | STRING | Falso | Nombre de usuario que se usará para autenticarse en el proxy de ProxyServer. |
| proxy_password | SECRET | Falso | Contraseña que se usará para la autenticación en el proxy de ProxyServer. |
| proxy_ssltype | ENUM | Falso | Es el tipo de SSL que se usará para conectarse al proxy de ProxyServer. Los valores admitidos son AUTO, ALWAYS, NEVER y TUNNEL. |
Limitaciones del sistema
El conector de BigQuery puede procesar un máximo de 8 transacciones por segundo, por nodo, y limita las transacciones que superen este límite. De forma predeterminada, Integration Connectors asigna 2 nodos (para una mejor disponibilidad) a una conexión.
Para obtener información sobre los límites aplicables a Integration Connectors, consulta Límites.
Tipos de datos admitidos
Los siguientes son los tipos de datos admitidos para este conector:
- ARRAY
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- TIME
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
Limitaciones conocidas
-
El conector de BigQuery no admite la clave primaria en una tabla de BigQuery. Esto significa que no puedes realizar las operaciones de entidades Get, Update y Delete con un
entityId. Como alternativa, puedes usar la cláusula de filtro para filtrar registros según un ID. -
Cuando recuperes datos por primera vez, es posible que experimentes una latencia inicial de alrededor de 6 segundos. Debido al almacenamiento en caché, no hay latencia en las solicitudes posteriores. Esta latencia puede volver a ocurrir cuando venza la caché.
Obtén ayuda de la Comunidad de Google Cloud
Puedes publicar tus preguntas y debatir sobre este conector en la comunidad de Google Cloud en Cloud Forums.
¿Qué sigue?
- Obtén información para suspender y reanudar una conexión.
- Obtén información para supervisar el uso del conector.
- Comprende cómo ver los registros del conector.