BigQuery
使用 BigQuery 连接器对 Google BigQuery 数据执行插入、删除、更新和读取操作。您还可以针对 BigQuery 数据执行自定义 SQL 查询。您可以使用 BigQuery 连接器集成来自多个 Google Cloud 服务或其他第三方服务(例如 Cloud Storage 或 Amazon S3)的数据。
准备工作
在 Google Cloud 项目中,执行以下任务:
- 确保已设置网络连接。如需了解网络模式,请参阅网络连接。
- 向配置连接器的用户授予 roles/connectors.admin IAM 角色。
- 向您要用于连接器的服务账号授予
roles/bigquery.dataEditorIAM 角色。如果您没有服务账号,则必须创建一个服务账号。连接器和服务账号必须属于同一项目。 - 启用以下服务:
secretmanager.googleapis.com(Secret Manager API)connectors.googleapis.com(Connectors API)
如需了解如何启用服务,请参阅启用服务。如果之前没有为您的项目启用这些服务或权限,则在您配置连接器时,系统会提示您启用。
创建 BigQuery 连接
一个连接需专用于一个数据源。这意味着,如果您有许多数据源,则必须为每个数据源创建单独的连接。如需创建连接,请执行以下操作:
- 在 Cloud 控制台 中,进入 Integration Connectors > 连接页面,然后选择或创建一个 Google Cloud 项目。
- 点击 + 新建以打开创建连接页面。
- 在位置部分中,从区域列表中选择一个位置,然后点击下一步。
如需查看所有受支持区域的列表,请参阅位置。
- 在连接详情部分中,执行以下操作:
- 从连接器列表中选择 BigQuery。
- 从连接器版本列表中选择一个连接器版本。
- 在连接名称字段中,输入连接实例的名称。连接名称可以包含小写字母、数字或连字符。名称必须以字母开头,以字母或数字结尾,且不得超过 49 个字符。
- 您可以选择启用 Cloud Logging,然后选择日志级别。默认情况下,日志级别设置为
Error。 - 服务账号:选择具有所需角色的服务账号。
- (可选)配置连接节点设置。
- 节点数下限:输入连接节点数下限。
- 节点数上限:输入连接节点数上限。
- 项目 ID:数据所在的 Google Cloud 项目的 ID。
- 数据集 ID:BigQuery 数据集的 ID。
- 如需支持 BigQuery Array 数据类型,请选择支持原生数据类型。支持以下数组类型:Varchar、Int64、Float64、Long、Double、Bool 和 Timestamp。不支持嵌套数组。
- (可选)如要为连接配置代理服务器,请选择使用代理,然后输入代理详细信息。
-
代理身份验证方案:选择要通过代理服务器进行身份验证的身份验证类型。支持以下身份验证类型:
- 基本:基本 HTTP 身份验证。
- 摘要:摘要 HTTP 身份验证。
- 代理用户:用于向代理服务器进行身份验证的用户名。
- 代理密码:用户密码的 Secret Manager 密文。
-
代理 SSL 类型:连接到代理服务器时使用的 SSL 类型。支持以下身份验证类型:
- 自动:默认设置。如果网址是 HTTPS 网址,则使用“隧道”选项。如果网址是 HTTP 网址,则使用“永不”选项。
- 始终:连接始终启用 SSL。
- 永不:连接未启用 SSL。
- 隧道:连接通过隧道代理建立。代理服务器会打开与远程主机的连接,并且流量会流经该代理。
- 在代理服务器部分中,输入代理服务器的详细信息。
- 点击下一步。
节点是处理事务的连接单元(或副本)。 连接处理越多事务就需要越多节点,相反,处理越少事务需要越少节点。 如需了解节点如何影响连接器价格,请参阅 连接节点的价格。如果未输入任何值,则默认情况下,节点数下限设置为 2(以便提高可用性),节点数上限设置为 50。
-
在身份验证部分中,输入身份验证详细信息。
- 选择是否使用 OAuth 2.0 - 授权代码进行身份验证,或者不进行身份验证直接继续。
如需了解如何配置身份验证,请参阅配置身份验证。
- 点击下一步。
- 选择是否使用 OAuth 2.0 - 授权代码进行身份验证,或者不进行身份验证直接继续。
- 查看您的连接和身份验证详细信息,然后点击创建。
配置身份验证
根据您要使用的身份验证输入详细信息。
- 无身份验证:如果您不需要进行身份验证,请选择此选项。
- OAuth 2.0 - 授权代码:选择此选项可使用基于网页的用户登录流程进行身份验证。请指定以下详细信息:
- 客户端 ID: 连接到后端 Google 服务所需的客户端 ID。
- 范围: 以英文逗号分隔的所需范围列表。如需查看所需 Google 服务的所有受支持的 OAuth 2.0 范围,请参阅适用于 Google API 的 OAuth 2.0 范围页面中的相关部分。
- 客户端密钥:选择 Secret Manager 密钥。您必须先创建 Secret Manager 密钥,然后再配置此授权。
- 密钥版本:客户端密钥的 Secret Manager 密钥版本。
对于 Authorization code 身份验证类型,创建连接后,您必须授权该连接。
授权关联
如果您使用 OAuth 2.0(授权代码)来验证连接,请在创建连接后完成以下任务。
- 在“连接”页面中,找到新创建的连接。
请注意,新连接器的状态将为需要授权。
- 点击需要授权。
系统会显示修改授权窗格。
- 将重定向 URI 值复制到外部应用。
- 验证授权详细信息。
- 点击授权。
如果授权成功,系统会在“连接”页面中将连接状态设置为有效。
授权代码的重新授权
如果您使用的是 Authorization code 身份验证类型,并且在 BigQuery 中进行了任何配置更改,则必须重新授权您的 BigQuery 连接。如需重新授权连接,请执行以下步骤:
在集成中使用 BigQuery 连接
创建连接后,该连接将在 Apigee Integration 和 Application Integration 中可用。您可以通过连接器任务在集成中使用该连接。
- 如需了解如何在 Apigee Integration 中创建和使用连接器任务,请参阅连接器任务。
- 如需了解如何在 Application Integration 中创建和使用连接器任务,请参阅连接器任务。
操作
本部分介绍了 BigQuery 连接器中可用的操作。
运行集成后,所有实体操作和操作的结果将以 JSON 响应的形式在 Connectors 任务的 connectorOutputPayload 响应参数中提供。
CancelJob 操作
此操作可让您取消正在运行的 BigQuery 作业。
下表介绍了 CancelJob 操作的输入参数。
| 参数名称 | 数据类型 | 说明 |
|---|---|---|
| JobId | 字符串 | 要取消的作业的 ID。这是必填字段。 |
| 区域 | 字符串 | 作业当前正在执行的区域。如果职位位于美国或欧盟区域,则无需提供此信息。 |
GetJob 操作
此操作可让您检索现有作业的配置信息和执行状态。
下表介绍了 GetJob 操作的输入参数。
| 参数名称 | 数据类型 | 说明 |
|---|---|---|
| JobId | 字符串 | 您要检索配置的作业的 ID。这是必填字段。 |
| 区域 | 字符串 | 作业当前正在执行的区域。如果职位位于美国或欧盟区域,则无需提供此信息。 |
InsertJob 操作
此操作可让您插入 BigQuery 作业,然后稍后选择该作业来检索查询结果。
下表介绍了 InsertJob 操作的输入参数。
| 参数名称 | 数据类型 | 说明 |
|---|---|---|
| 查询 | 字符串 | 要提交给 BigQuery 的查询。这是必填字段。 |
| IsDML | 字符串 | 如果查询是 DML 语句,则应设置为 true;否则应设置为 false。默认值为 false。 |
| DestinationTable | 字符串 | 查询的目标表,采用 DestProjectId:DestDatasetId.DestTable 格式。 |
| WriteDisposition | 字符串 | 指定如何将数据写入目标表;例如,截断现有结果、附加现有结果,或仅当表为空时才写入。支持的值如下:
|
| DryRun | 字符串 | 指定作业的执行是否为试运行。 |
| MaximumBytesBilled | 字符串 | 指定作业可处理的最大字节数。如果作业尝试处理的字节数超过指定值,BigQuery 会取消该作业。 |
| 区域 | 字符串 | 指定作业应执行的区域。 |
InsertLoadJob 操作
此操作可让您插入 BigQuery 加载作业,从而将 Google Cloud Storage 中的数据添加到现有表中。
下表介绍了 InsertLoadJob 操作的输入参数。
| 参数名称 | 数据类型 | 说明 |
|---|---|---|
| SourceURIs | 字符串 | 以空格分隔的 Google Cloud Storage URI 列表。 |
| SourceFormat | 字符串 | 文件的源格式。支持的值如下:
|
| DestinationTable | 字符串 | 查询的目标表,采用 DestProjectId.DestDatasetId.DestTable 格式。 |
| DestinationTableProperties | 字符串 | 一个 JSON 对象,用于指定表的别名、说明和标签列表。 |
| DestinationTableSchema | 字符串 | 一个 JSON 列表,用于指定创建表时使用的字段。 |
| DestinationEncryptionConfiguration | 字符串 | 一个 JSON 对象,用于指定表的 KMS 加密设置。 |
| SchemaUpdateOptions | 字符串 | 一个 JSON 列表,用于指定在更新目标表架构时要应用的选项。 |
| TimePartitioning | 字符串 | 一个 JSON 对象,用于指定时间分区类型和字段。 |
| RangePartitioning | 字符串 | 一个 JSON 对象,用于指定范围分区字段和分桶。 |
| 聚簇 | 字符串 | 一个 JSON 对象,用于指定要用于聚类的字段。 |
| 自动检测 | 字符串 | 指定是否应自动确定 JSON 和 CSV 文件的选项和架构。 |
| CreateDisposition | 字符串 | 指定是否需要在目标表尚不存在时创建该表。支持的值如下:
|
| WriteDisposition | 字符串 | 指定如何将数据写入目标表,例如:截断现有结果、附加现有结果,或仅在表为空时写入。支持的值如下:
|
| 区域 | 字符串 | 指定作业应执行的区域。Google Cloud Storage 资源和 BigQuery 数据集必须位于同一区域。 |
| DryRun | 字符串 | 指定作业的执行是否为试运行。默认值为 false。 |
| MaximumBadRecords | 字符串 | 指定在取消整个作业之前可以有多少条无效记录。默认情况下,所有记录都必须有效。默认值为 0。 |
| IgnoreUnknownValues | 字符串 | 指定是否必须忽略输入文件中的未知字段,或者将这些字段视为错误。默认情况下,它们会被视为错误。默认值为 false。 |
| AvroUseLogicalTypes | 字符串 | 指定是否必须使用 AVRO 逻辑类型将 AVRO 数据转换为 BigQuery 类型。默认值为 true。 |
| CSVSkipLeadingRows | 字符串 | 指定在 CSV 文件开头要跳过的行数。此参数通常用于跳过标题行。 |
| CSVEncoding | 字符串 | CSV 文件的编码类型。支持的值如下:
|
| CSVNullMarker | 字符串 | 如果提供,此字符串将用于 CSV 文件中的 NULL 值。默认情况下,CSV 文件不能使用 NULL。 |
| CSVFieldDelimiter | 字符串 | 用于分隔 CSV 文件中各列的字符。默认值为英文逗号 (,)。 |
| CSVQuote | 字符串 | 用于 CSV 文件中带引号字段的字符。可设置为空以停用引用。默认值为英文双引号 (")。 |
| CSVAllowQuotedNewlines | 字符串 | 指定 CSV 文件是否可以在带英文引号的字段中包含换行符。默认值为 false。 |
| CSVAllowJaggedRows | 字符串 | 指定 CSV 文件是否可以包含缺失的字段。默认值为 false。 |
| DSBackupProjectionFields | 字符串 | 要从 Cloud Datastore 备份加载的字段的 JSON 列表。 |
| ParquetOptions | 字符串 | 一个 JSON 对象,用于指定 Parquet 特有的导入选项。 |
| DecimalTargetTypes | 字符串 | 一个 JSON 列表,用于指定应用于数值类型的偏好顺序。 |
| HivePartitioningOptions | 字符串 | 一个 JSON 对象,用于指定源端分区选项。 |
执行自定义 SQL 查询
如需创建自定义查询,请按照下列步骤操作:
- 按照详细说明添加连接器任务。
- 配置连接器任务时,在要执行的动作类型中选择动作。
- 在动作列表中,选择执行自定义查询,然后点击完成。
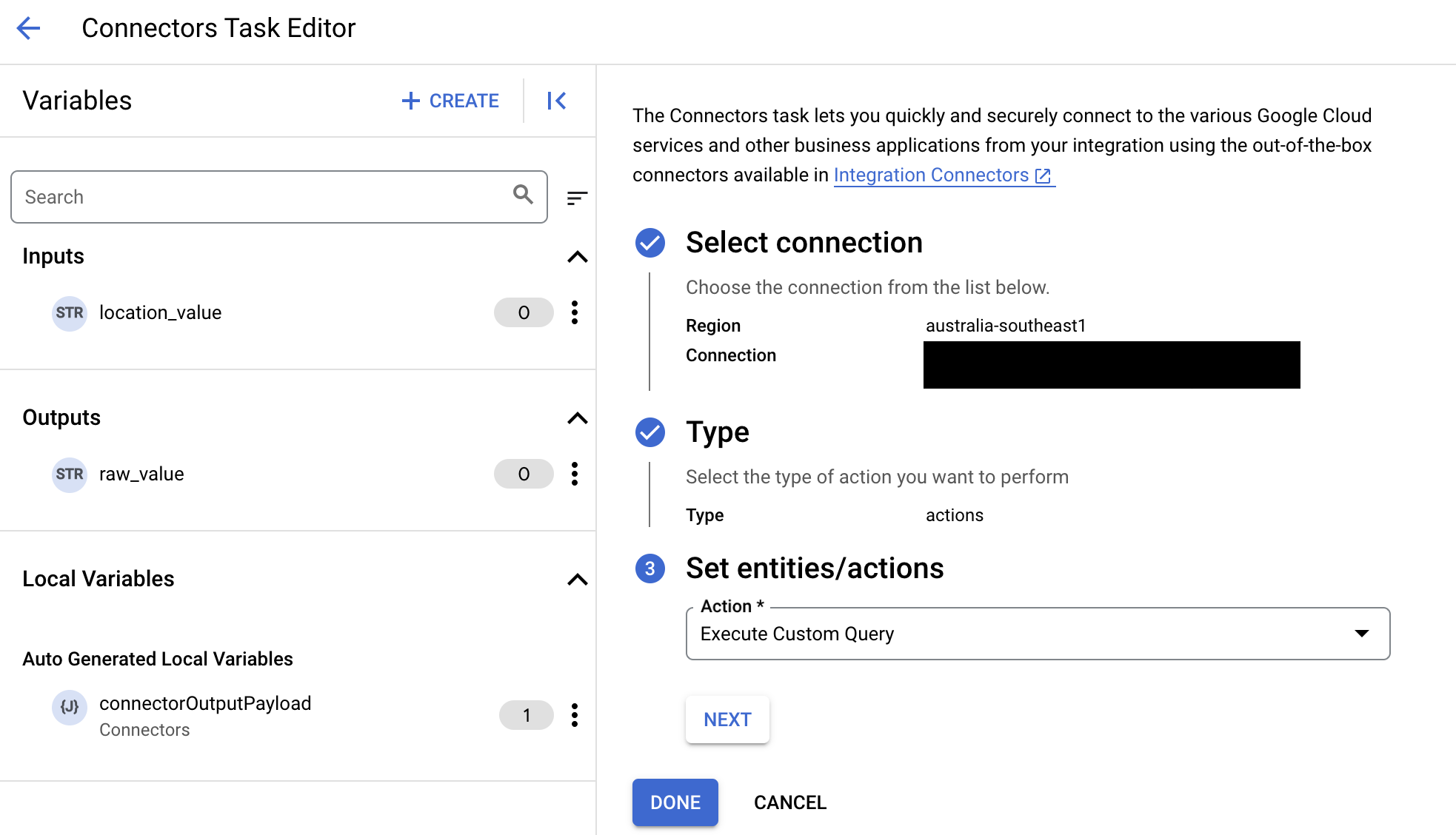
- 展开任务输入部分,然后执行以下操作:
- 在在以下时间后超时字段中,输入查询执行前要等待的秒数。
默认值:
180秒。 - 在最大行数字段中,输入要从数据库返回的最大行数。
默认值:
25。 - 要更新自定义查询,请点击修改自定义脚本。系统随即会打开脚本编辑器对话框。
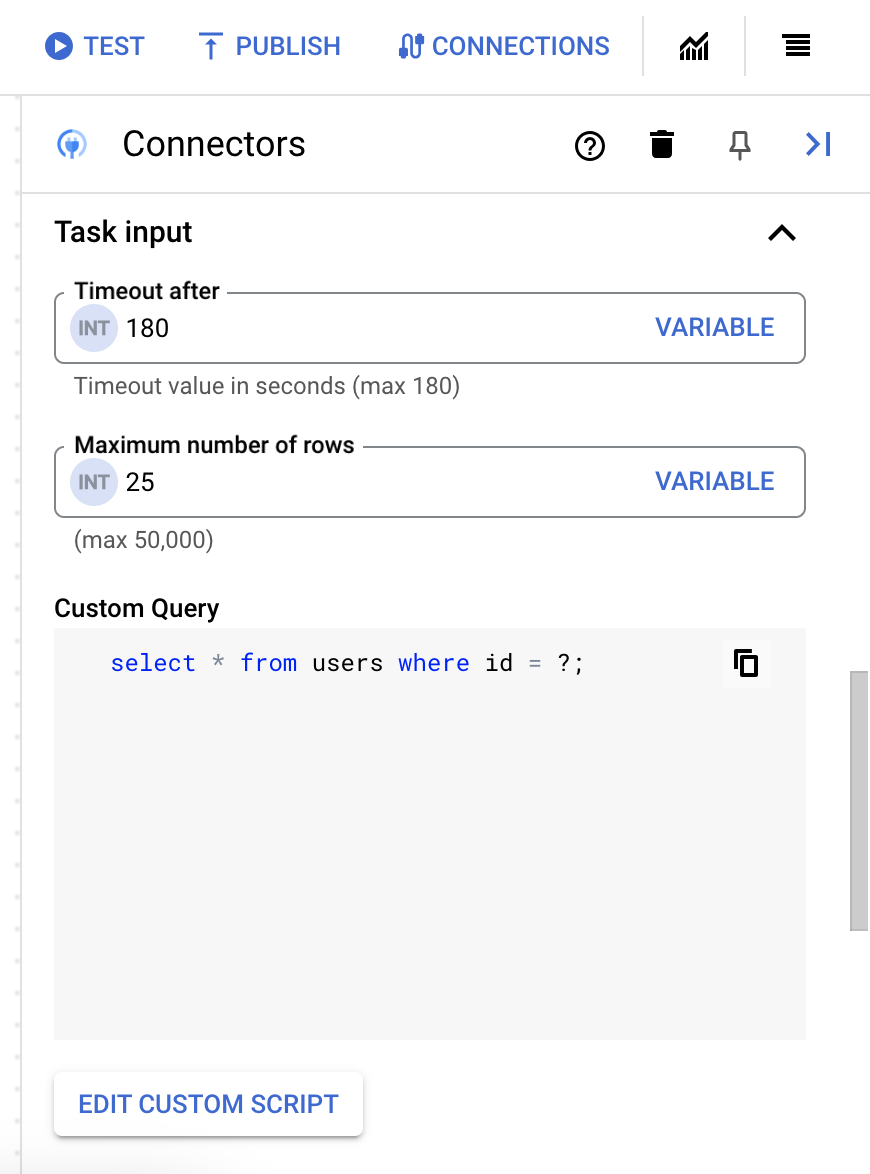
- 在脚本编辑器对话框中,输入 SQL 查询,然后点击保存。
您可以在 SQL 语句中使用问号 (?) 表示必须在查询参数列表中指定的单个参数。例如,以下 SQL 查询会从
Employees表中选择与为LastName列指定的值匹配的所有行:SELECT * FROM Employees where LastName=?
- 如果您在 SQL 查询中使用了问号,则必须点击 + 添加参数名称,针对每个问号添加参数。执行集成时,这些参数按顺序替换 SQL 查询中的问号 (?)。例如,如果您添加了三个问号 (?),那么必须按顺序添加三个参数。
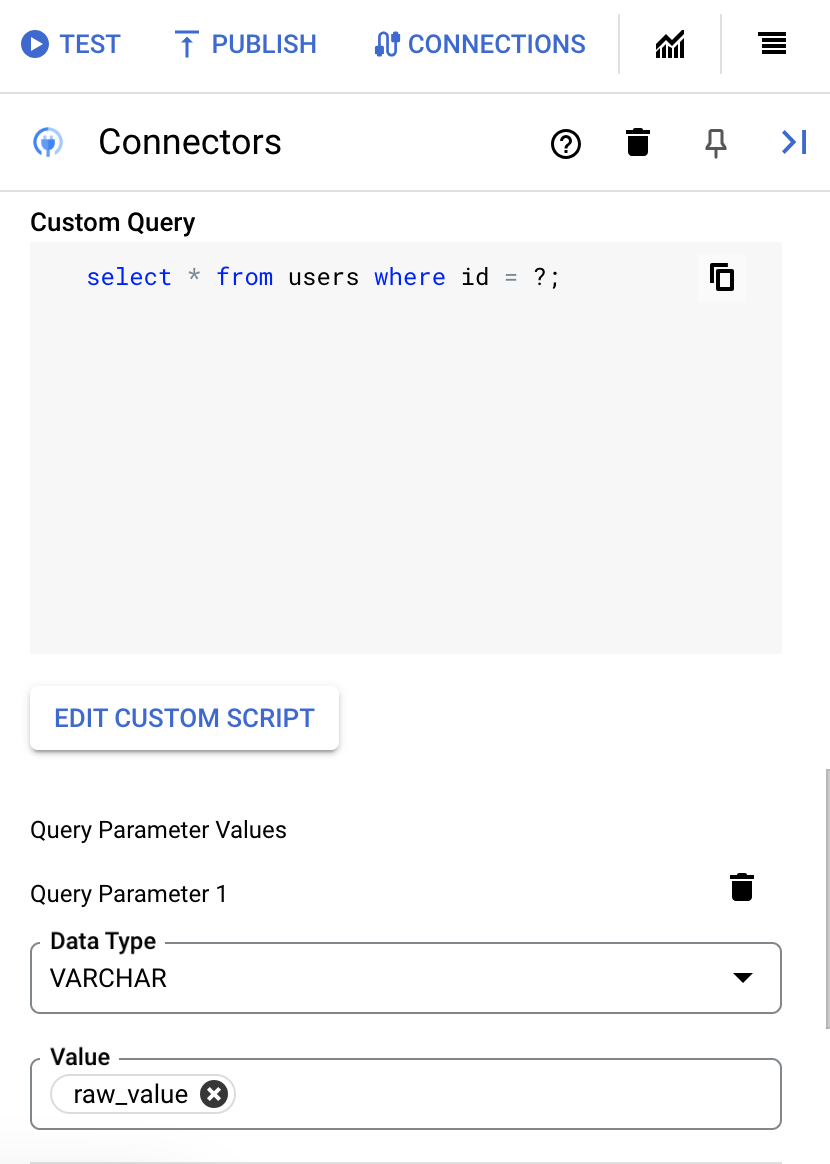
如需添加查询参数,请执行以下操作:
- 从类型列表中,选择参数的数据类型。
- 在值字段中,输入参数的值。
- 要添加多个参数,请点击 + 添加查询参数。
执行自定义查询操作不支持数组变量。
- 在在以下时间后超时字段中,输入查询执行前要等待的秒数。
使用 Terraform 创建连接
您可以使用 Terraform 资源创建新连接。
如需了解如何应用或移除 Terraform 配置,请参阅基本 Terraform 命令。
如需查看用于创建连接的 Terraform 模板示例,请参阅模板示例。
使用 Terraform 创建此连接时,您必须在 Terraform 配置文件中设置以下变量:
| 参数名称 | 数据类型 | 必需 | 说明 |
|---|---|---|---|
| project_id | STRING | 正确 | 包含 BigQuery 数据集的项目的 ID。例如,myproject。 |
| dataset_id | STRING | 错误 | 不含项目名称的 BigQuery 数据集的数据集 ID。例如,mydataset。 |
| proxy_enabled | BOOLEAN | 错误 | 选中此复选框可为连接配置代理服务器。 |
| proxy_auth_scheme | ENUM | 错误 | 用于向 ProxyServer 代理进行身份验证的身份验证类型。支持的值包括:BASIC、DIGEST、NONE |
| proxy_user | STRING | 错误 | 用于向 ProxyServer 代理进行身份验证的用户名。 |
| proxy_password | SECRET | 错误 | 用于向 ProxyServer 代理进行身份验证的密码。 |
| proxy_ssltype | ENUM | 错误 | 连接到 ProxyServer 代理时使用的 SSL 类型。支持的值包括:AUTO、ALWAYS、NEVER、TUNNEL |
系统限制
BigQuery 连接器每秒最多可处理 8 个事务(每个节点),并且会限制超出此限制的任何事务。默认情况下,Integration Connectors 会为连接分配 2 个节点(以提高可用性)。
如需了解适用于 Integration Connectors 的限制,请参阅限制。
支持的数据类型
此连接器支持以下数据类型:
- ARRAY
- BIGINT
- BINARY
- BIT
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- FLOAT
- INTEGER
- LONGN VARCHAR
- LONG VARCHAR
- NCHAR
- NUMERIC
- NVARCHAR
- REAL
- SMALL INT
- 时间
- TIMESTAMP
- TINY INT
- VARBINARY
- VARCHAR
已知限制
向 Google Cloud 社区寻求帮助
您可以在 Google Cloud 社区的 Cloud 论坛中发布您的问题以及讨论此连接器。