Konektor mendapatkan data dari sumber data Google dan pihak ketiga ke Gemini Enterprise, lalu menyimpannya di penyimpanan data khusus. Dokumen ini memberikan ringkasan tentang konektor ini. Memusatkan data Anda di Gemini Enterprise akan meningkatkan aksesibilitas data, fungsi penelusuran, dan kemampuan analisis.
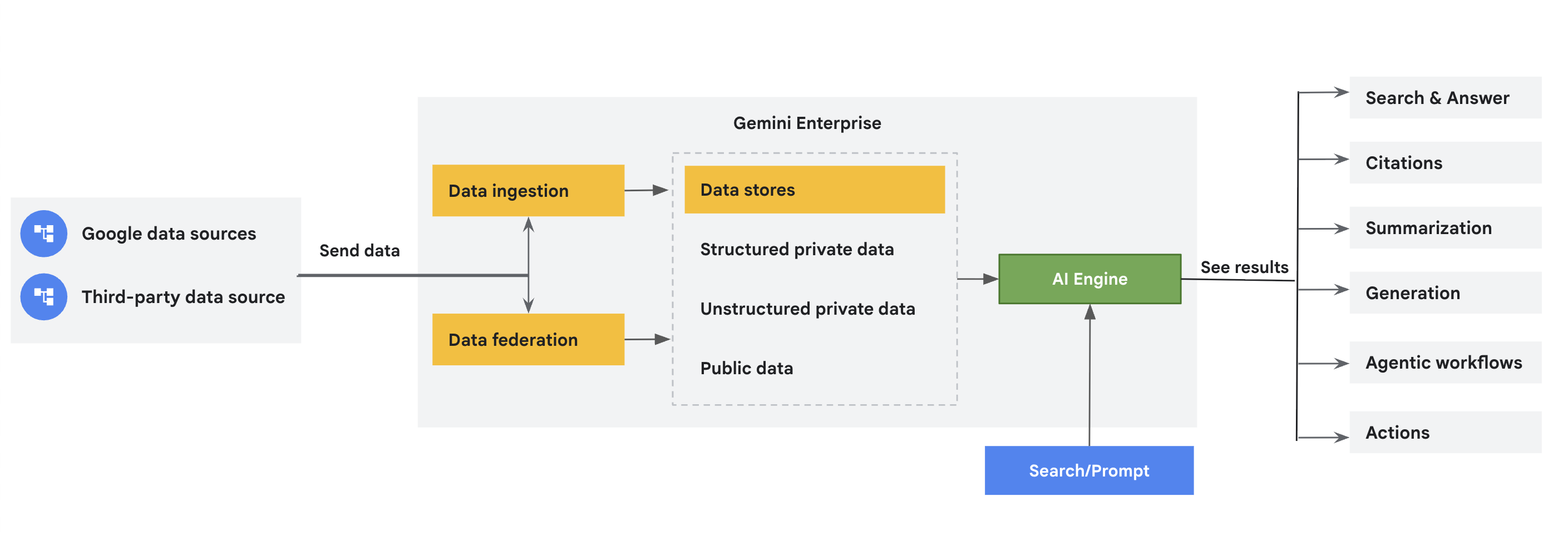
Konsep konektor dan penyimpanan data
Penyimpanan data |
| Setiap sumber data mendukung serangkaian jenis entity. Misalnya, Jira Cloud memiliki entitas seperti masalah, lampiran, komentar, dan log aktivitas, yang unik untuk sumber data. Gemini Enterprise membuat penyimpanan data terpisah untuk setiap entitas. Oleh karena itu, saat Anda membuat penyimpanan data menggunakan konsol Google Cloud , Anda akan mendapatkan kumpulan penyimpanan data yang merepresentasikan entitas data yang di-ingest ini. |
Penggabungan data versus penyerapan (pengindeksan) |
| Federasi data secara langsung mengambil informasi dari sumber data yang ditentukan. Karena data tidak disalin ke indeks Vertex AI Search, Anda tidak perlu khawatir tentang penyimpanan data. Namun, karena data tidak diindeks, kualitas penelusuran mungkin lebih rendah. Penyerapan data (pengindeksan) menyalin data ke indeks Vertex AI Search. Hal ini dapat meningkatkan kualitas penelusuran. Namun, proses ini menggunakan lebih banyak penyimpanan dan waktu. |
Data tidak terstruktur |
| Format data yang didukung khusus untuk sumber data dan jenis entity. Jika konten dalam entitas disimpan dalam format tidak terstruktur — seperti HTML, PDF, TXT, PPTX, atau DOCX — penyimpanan data tidak terstruktur dibuat oleh Vertex AI Search. Untuk mengetahui informasi selengkapnya dan jenis file yang didukung, lihat Penelusuran tidak terstruktur. |
Data terstruktur |
| Format data yang didukung khusus untuk sumber data dan jenis entity. Jika konten dalam entitas disimpan dalam format terstruktur, penyimpanan data terstruktur akan dibuat oleh Vertex AI Search. Untuk mengetahui informasi selengkapnya, lihat Penelusuran terstruktur. |
Skema data |
| Skema data menentukan struktur data. Saat Anda mengimpor data terstruktur menggunakan Gemini Enterprise, sistem akan otomatis mendeteksi skema. Anda dapat menggunakan skema yang terdeteksi otomatis atau menentukan skema menggunakan API. Untuk mengetahui informasi selengkapnya, lihat Menyediakan atau mendeteksi skema secara otomatis. |
Region penyimpanan data |
| Saat memproses data, Anda perlu memilih region tempat Anda ingin menyimpan data, seperti global, AS, atau Uni Eropa. Untuk mengetahui informasi selengkapnya, lihat Lokasi Gemini Enterprise. Data yang disimpan di wilayah AS atau Uni Eropa memerlukan enkripsi data. Enkripsi default adalah dengan Google-owned and Google-managed encryption key, tetapi sebagai alternatif, Anda dapat menggunakan kunci enkripsi yang dikelola pelanggan. |
Sinkronisasi data |
Sinkronisasi data menarik dan memperbarui data identitas (seperti peran, izin, dan pengguna) serta data entitas (seperti data yang terkait dengan sumber data tertentu) dari sumber data asli. Untuk mengetahui informasi selengkapnya, lihat Jenis dan jadwal sinkronisasi data. |
Jenis dan jadwal sinkronisasi data
Sinkronisasi data mengambil data entitas, data identitas, atau keduanya, dan memperbarui isi penyimpanan data di Gemini Enterprise.
Jenis sinkronisasi
Penyimpanan data di Gemini Enterprise menggunakan dua jenis sinkronisasi data penting:
Sinkronisasi penuh merekam seluruh status aplikasi atau layanan pihak ketiga. Hal ini mencakup penambahan, pembaruan, dan penghapusan. Sinkronisasi penuh menggantikan isi penyimpanan data yang ada.
Sinkronisasi inkremental secara berkala mengambil data entitas yang telah ditambahkan atau diperbarui sejak sinkronisasi terakhir. Tindakan ini tidak menyinkronkan data identitas atau penghapusan data entitas.
Anda dapat menjadwalkan sinkronisasi penuh secara terpisah untuk jenis data berikut:
Sinkronisasi entity mengambil data khusus untuk sumber data pihak ketiga. Misalnya, penyimpanan data untuk sistem seperti Jira dapat menyinkronkan masalah, log aktivitas, komentar, dan lampiran. Sinkronisasi entitas tidak menyertakan informasi identitas.
Sinkronisasi identitas merekam data tentang akun pengguna yang terkait dengan grup ACL.
Interaksi antara sinkronisasi identitas dan sinkronisasi penuh
Untuk memahami cara kerja proses sinkronisasi identitas individual dengan proses sinkronisasi penuh,
pertimbangkan contoh skenario yang mencakup dua halaman: page_1, yang ditautkan ke grup
ACL group_1; dan page_2, yang ditautkan ke grup ACL group_2.
Sinkronisasi identitas awal berjalan, dan mengambil informasi tentang grup
group_1dangroup_2.Asumsikan bahwa
group_1berisi penggunauser_1.Asumsikan bahwa
group_2berisi penggunauser_2.
Sinkronisasi identitas ini membuat pemetaan berikut:
user_1dipetakan kegroup_1.user_2dipetakan kegroup_2.
Selain sinkronisasi identitas, sinkronisasi penuh akan berjalan, mengambil
page_1danpage_2.Sinkronisasi penuh ini menetapkan pemetaan berikut:
user_1memiliki akses kepage_1(melaluigroup_1).user_2memiliki akses kepage_2(melaluigroup_2).
Jadwal sinkronisasi
Untuk setiap penyimpanan data, Anda dapat memilih frekuensi untuk berbagai jenis sinkronisasi:
Sinkronisasi penuh semua data identitas dan data entitas dapat dijadwalkan secara bersamaan setiap 3 jam, 6 jam, 12 jam, 1 hari, atau 3 hari.
Sinkronisasi penuh independen dari semua data identitas, dan sinkronisasi penuh independen dari semua data entitas, dapat dijadwalkan secara terpisah menggunakan salah satu frekuensi sinkronisasi kustom berikut:
Data entitas: Setiap 3 jam, 6 jam, 12 jam, 1 hari, 3 hari, 5 hari, dan setiap 7 hari.
Data identitas: Setiap 30 menit, 1 jam, 3 jam, 6 jam, 12 jam, 1 hari, 3 hari, 5 hari, dan setiap 7 hari.
Sinkronisasi inkremental data entitas yang diperbarui atau ditambahkan dapat dijadwalkan setiap 3 jam, 6 jam, 12 jam, 1 hari, 3 hari, 5 hari, atau setiap 7 hari. Secara default, sinkronisasi inkremental dilakukan setiap 3 jam.
Rekomendasi frekuensi
Pilih frekuensi sinkronisasi data yang sesuai dengan volume data yang diambil dan kueri per detik (QPS) yang direkomendasikan.
Tabel berikut menunjukkan jumlah kumpulan data yang biasanya diambil untuk sinkronisasi satu, tiga, lima, dan tujuh hari. Jumlah sebenarnya data yang ditampilkan dapat bervariasi, bergantung pada sumber data dan konfigurasinya.
| QPS | Volume rekaman untuk sinkronisasi 1 hari | Volume rekaman untuk sinkronisasi 3 hari | Volume rekaman untuk sinkronisasi 5 hari | Volume rekaman untuk sinkronisasi 7 hari |
|---|---|---|---|---|
| 5 | 432 ribu | 1,296 jt | 2,16 JT | 3M |
| 10 | 864 ribu | 2.592M | 4,32 JT | 6M |
| 20 | 1,7 JT | 5,1 JT | 8,5 JT | 11,9 JT |
| 50 | 4,3 JT | 12,9 JT | 21,5 JT | 30,1 JT |
| 100 | 8,6 JT | 25,8 JT | 43 JT | 60,2 JT |
Menjeda dan melanjutkan sinkronisasi
Anda dapat menjeda dan melanjutkan sinkronisasi penuh dan sinkronisasi inkremental:
Saat Anda menjeda jenis sinkronisasi, penyimpanan data akan membatalkan sinkronisasi jenis tersebut yang sedang berlangsung dan berhenti menjadwalkan sinkronisasi jenis tersebut yang baru.
Saat Anda melanjutkan jenis sinkronisasi, penyimpanan data akan menjadwalkan sinkronisasi baru berdasarkan waktu sinkronisasi terjadwal terakhir, tetapi tidak melanjutkan sinkronisasi yang terganggu sebelumnya.
Misalnya, jika Anda menjeda sinkronisasi penuh saat sinkronisasi penuh sedang berlangsung, penyimpanan data akan membatalkan sinkronisasi tersebut. Jika Anda melanjutkan sinkronisasi penuh nanti, penyimpanan data akan otomatis menjadwalkan sinkronisasi penuh baru sesuai dengan jadwal sinkronisasi penuh.
Sumber data Google
Anda dapat terhubung ke sumber data Google, seperti BigQuery, Spanner, dan Google Drive.
Checklist untuk sumber data Google
Sebelum mengirim data ke Gemini Enterprise, periksa daftar berikut:
Siapkan kontrol akses untuk sumber data Anda. Untuk mengetahui informasi selengkapnya, lihat, Identitas dan izin.
Tentukan apakah data harus digabungkan atau diserap (diindeks).
Tentukan seberapa sering data harus disinkronkan.
Jika Anda menggunakan kunci enkripsi yang dikelola pelanggan (CMEK), buat kunci multi-region. Untuk mengetahui informasi selengkapnya, lihat Mendaftarkan kunci satu region untuk sumber data pihak ketiga.
Jika Anda memiliki informasi identitas pribadi (PII) dan ingin menggunakan pelengkapan otomatis untuk saran kueri, lihat melindungi dari kebocoran PII.
Sumber data Google yang didukung
| Google Drive | Gmail | Google Kalender | Penelusuran orang |

|

|

|

|
Sumber data pihak ketiga
Penyimpanan data pihak ketiga menyerap data aplikasi pihak ketiga ke dalam Gemini Enterprise.
Daftar periksa untuk sumber data pihak ketiga
Sebelum menghubungkan sumber data pihak ketiga ke Gemini Enterprise, tinjau checklist berikut:
Cakupan dan izin tertentu harus dikonfigurasi untuk sumber data tertentu. Administrator aplikasi pihak ketiga harus meninjau kredensial yang diperlukan untuk menghubungkan sumber data serta menyiapkan autentikasi dan izin. Untuk mengetahui informasi tentang cakupan dan izin tertentu, lihat dokumentasi sumber data pihak ketiga yang relevan.
Siapkan kontrol akses untuk penyimpanan data Anda. Untuk mengetahui informasi selengkapnya, lihat Identitas dan izin
Tentukan apakah data harus digabungkan atau diserap (diindeks).
Jika data dimasukkan, pastikan resource tidak dibatasi untuk kredensial pengguna yang Anda gunakan untuk memasukkan data ke sumber data.
Tentukan seberapa sering data harus disinkronkan.
Jika Anda menggunakan kunci enkripsi yang dikelola pelanggan (CMEK), buat kunci multi-region dan satu region. Untuk mengetahui informasi selengkapnya, lihat Mendaftarkan kunci satu region untuk penyimpanan data pihak ketiga.
Jika Anda memiliki informasi identitas pribadi (PII) dan ingin menggunakan pelengkapan otomatis untuk saran kueri, lihat melindungi dari kebocoran PII.
Sumber data pihak ketiga yang didukung
| Microsoft Entra ID | Microsoft OneDrive | Microsoft Outlook | Microsoft SharePoint |
|
|
|
|
|
| Jira Cloud | Confluence Cloud | ServiceNow | |
|
|
|
|