大規模な読み取りと書き込みについて
このドキュメントでは、優れたパフォーマンスと高い信頼性を備えたアプリケーションを設計する際に役立つ情報を提供します。このドキュメントでは、Firestore の高度なトピックについて説明します。Firestore を使い始めたばかりの方は、クイックスタート ガイドをご覧ください。
データベースのサイズとトラフィックが増加してもアプリケーションのパフォーマンスが維持されるようにするには、Firestore バックエンドでの読み取りと書き込みの仕組みを理解する必要があります。また、読み取り / 書き込みでのストレージ レイヤとのやり取りや、パフォーマンスに影響を与える可能性がある基本的な制約についても理解する必要があります。
アプリケーションを設計する前に、以降のセクションでベスト プラクティスをご確認ください。
コンポーネントの概要
次の図は、Firestore API リクエストに関連するコンポーネントの概要を示しています。
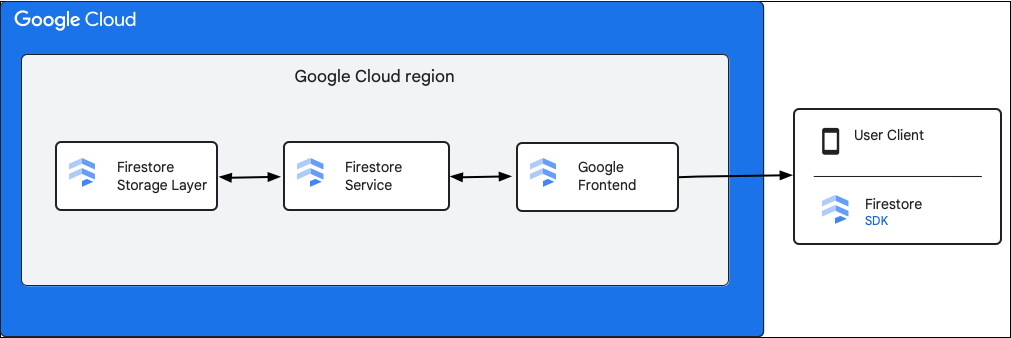
SDK、クライアント ライブラリ、ドライバ
Firestore は、さまざまなプラットフォームの SDK、クライアント ライブラリ、ドライバをサポートしています。
Google Front End(GFE)
これは、すべての Google Cloud サービスに共通のインフラストラクチャ サービスです。GFE は受信リクエストを受け入れ、適切な Google サービス(ここでは Firestore サービス)に転送します。
Firestore サービス
Firestore サービスは、認証、認可、割り当てチェックなど、API リクエストに対するチェックを実行し、トランザクションを管理します。この Firestore サービスには、データ読み取りと書き込みのためにストレージ レイヤとやり取りするストレージ クライアントが含まれています。
Firestore ストレージ レイヤ
Firestore ストレージ レイヤは、データとメタデータの保存や、Firestore から提供される関連するデータベース機能を処理します。以降のセクションでは、Firestore ストレージ レイヤでデータがどのように編成され、システムがスケーリングされるかについて説明します。データの編成方法を知ることで、スケーラブルなデータモデルを設計し、Firestore のベスト プラクティスをより深く理解できるようになります。
キー範囲とスプリット
Firestore は NoSQL ドキュメント指向データベースです。データはドキュメントに格納され、ドキュメントはコレクションにまとめられます。コレクション名とドキュメント ID は、ドキュメントの一意のキーを形成します。同じコレクション内のドキュメントは、キースペースにまとめて保存されます。そのキースペース内でドキュメント ID がハッシュ化されます。「キー範囲」とは、ストレージ内の連続したキーの範囲を指します。
Firestore は、コレクション内のデータを複数のストレージ サーバーに自動的にパーティショニングします。これらのパーティションは分割と呼ばれます。
ドキュメントは、辞書順に並べ替えられ、ドキュメント データと同じ種類の分割と配置に参加するインデックス エントリを生成できます。
同期レプリケーション
すべての書き込みは、Paxos を使用してレプリカの過半数に同期的に複製されます。スプリットごとに 1 つのレプリカがリーダーと見なされ、レプリケーション プロセスを調整します。リーダーに障害が発生した場合、新しいリーダーが選出されます。レプリカは、潜在的なゾーン障害に対する復元力を備えるために、異なるゾーンに配置されます。その結果、スケーラビリティと可用性が高くなり、負荷の高いワークロードや非常に大規模な環境間で読み取りと書き込みのレイテンシを抑えることができます。
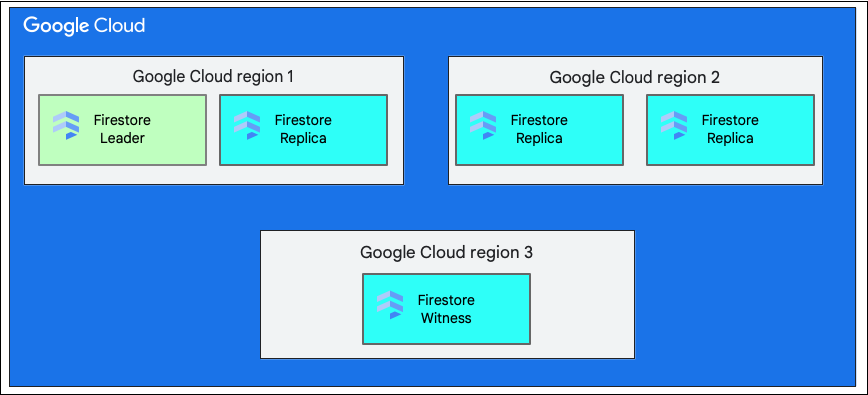
シングル リージョンとマルチリージョン
データベースを作成する場合は、単一リージョン ロケーションまたはマルチリージョン ロケーションを選択する必要があります。
シングル リージョンのロケーションは、us-west1 などの特定の地理的なロケーションです。前述のように、Firestore データベースのスプリットには、選択したリージョン内の異なるゾーンにレプリカが存在します。
マルチリージョン ロケーションは定義済みのリージョンのセットで構成され、これらの複数のリージョンに Firestore がデータベースのレプリカを保存します。Firestore のマルチリージョン デプロイでは、2 つのリージョンにデータベースのデータ全体の完全なレプリカが存在します。3 番目のリージョンには、完全なデータセットは維持されず、レプリケーションに参加する監視レプリカが存在します。Firestore は複数のリージョン間でデータを複製するため、1 つのリージョン全体が失われてもデータの書き込みと読み取りを行うことができます。
リージョンのロケーションの詳細については、Firestore のロケーションをご覧ください。
書き込みのライフサイクルについて
ドライバは、単一のドキュメントを作成、更新、削除することでデータを書き込むことができます。単一ドキュメントへの書き込みでは、ストレージ レイヤでそのドキュメントとそれに関連付けられたインデックス エントリの両方をアトミックに更新する必要があります。Firestore は、複数のドキュメントに対する複数の読み取り / 書き込みで構成されるアトミック オペレーションもサポートしています。
Firestore は、あらゆる種類の書き込みに対してリレーショナル データベースの ACID 特性(アトミック性、整合性、独立性、永続性)を備えています。Firestore は直列化可能性も備えています。これは、すべてのトランザクションが順次実行されているかのように見えることを意味します。
書き込みトランザクションの概要
ドライバが前述のいずれかの方法でトランザクションの書き込みまたは commit を行うと、この処理はデータベースの読み取り / 書き込みトランザクションとしてストレージ レイヤで実行されます。このトランザクションにより、Firestore は前述の ACID 特性を提供しています。
トランザクションの最初のステップとして、Firestore は既存のドキュメントを読み取り、ドキュメントのデータに行うミューテーションを決定します。
また、関連するインデックスの更新も行います。
- ドキュメントに追加するインデックス付きフィールドには、インデックスへの対応する挿入が必要です。
- ドキュメントから削除されるインデックス付きフィールドは、インデックスで対応する削除を行う必要があります。
- ドキュメント内で変更されるインデックス付きフィールドでは、インデックスでの削除(古い値)と挿入(新しい値)の両方が必要です。
前述のミューテーションを計算するために、Firestore はプロジェクトのインデックス構成を読み取ります。インデックス構成には、プロジェクトのインデックスに関する情報が保存されています。
ミューテーションが計算されると、Firestore はトランザクション内でミューテーションを収集し、commit します。
ストレージ レイヤでの書き込みトランザクションについて
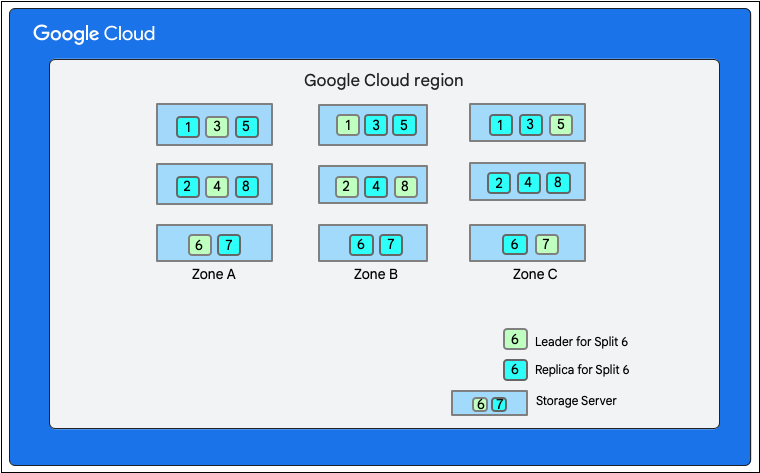
前述のように、Firestore に書き込みを行うと、ストレージ レイヤで読み取り / 書き込みトランザクションが実行されます。データのレイアウトによっては、書き込みに 1 つ以上のスプリットが関係します。
次の図では、Firestore データベースに 8 つのスプリット(1 ~ 8 のマーク)が 1 つのゾーンの 3 つの異なるストレージ サーバーでホストされています。また、各スプリットは 3 つ以上のゾーンで複製されています。各スプリットには Paxos リーダーがあり、リーダーは他のスプリットと異なるゾーンに存在しています。
次のような Restaurants コレクションを含む Firestore データベースを考えてみましょう。
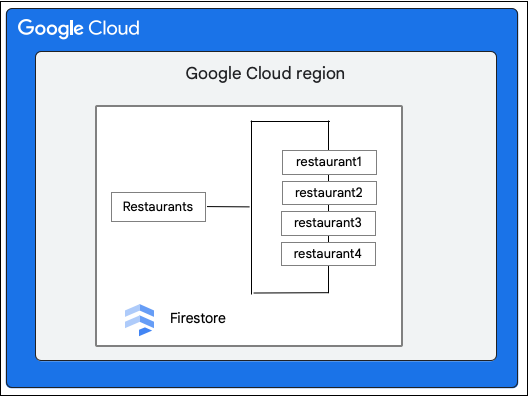
ドライバは、priceCategory フィールドの値を更新して、Restaurant コレクション内のドキュメントに対する次の変更をリクエストします。
書き込みの大まかな流れは次のとおりです。
- 読み取り / 書き込みトランザクションを作成します。
Restaurantsコレクションのrestaurant1ドキュメントを読み取ります。- ドキュメントのインデックスを読み取ります。
- データに対して行われるミューテーションを計算します。この場合、5 つのミューテーションがあります。
- M1:
restaurant1の行を更新して、priceCategoryフィールドの値の変更を反映します。 - M2 と M3:
priceCategoryの古いインデックス エントリを削除します。 - M4 と M5:
priceCategoryの新しいインデックス エントリを追加します。
- M1:
- これらのミューテーションを commit します。
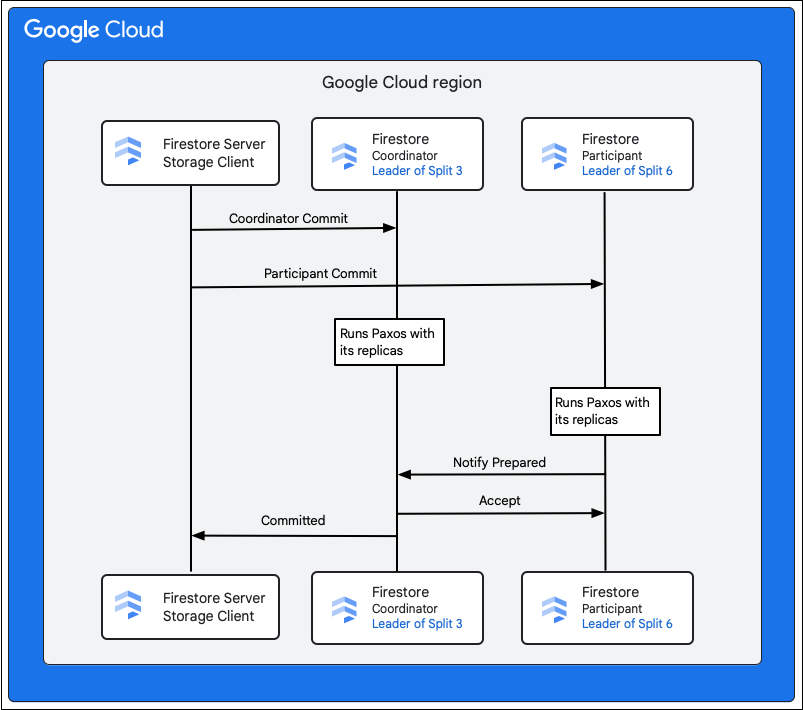
Firestore サービスのストレージ クライアントは、変更される行のキーを所有しているスプリットを検索します。スプリット 3 が M1 に、スプリット 6 が M2 から M5 にサービスを提供する場合について考えてみましょう。分散トランザクションがあり、これらのスプリットはすべて参加者として関係しています。参加者スプリットには、読み取り / 書き込みトランザクションの一部として、先にデータが読み取られたスプリットも含まれる場合があります。
この commit の流れは次のとおりです。
- ストレージ クライアントが commit を発行します。commit にはミューテーション M1~M5 が含まれています。
- スプリット 3 とスプリット 6 がこのトランザクションの参加者です。参加者の 1 つ(スプリット 3 など)がコーディネーターとして選択されます。コーディネーターは、すべての参加者の間でトランザクションがアトミックに commit または中止されるように調整します。
- これらのスプリットのリーダー レプリカは参加者とコーディネーターが行う処理を管理します。
- 各参加者とコーディネーターは、それぞれのレプリカで Paxos アルゴリズムを実行します。
- リーダーは、レプリカで Paxos アルゴリズムを実行します。レプリカのほとんどがリーダーに
ok to commitレスポンスを返すとクォーラムが達成されます。 - 各参加者は、準備ができるとコーディネーターに通知します(2 フェーズ commit の第 1 フェーズ)。トランザクションを commit できない参加者がいる場合は、トランザクション全体が
aborts状態になります。
- リーダーは、レプリカで Paxos アルゴリズムを実行します。レプリカのほとんどがリーダーに
- コーディネーターが、自身を含むすべての参加者で準備が完了していることを確認すると、トランザクションの結果として参加者に
acceptを通知します(2 フェーズ commit の第 2 フェーズ)。このフェーズで、各参加者が commit の決定を安定したストレージに記録し、トランザクションが commit されます。 - コーディネーターは、トランザクションが commit されたことを Firestore のストレージ クライアントに応答します。同時に、コーディネーターとすべての参加者がデータにミューテーションを適用します。
Firestore データベースが小さい場合、1 つのスプリットがミューテーション M1~M5 のすべてのキーを所有していることがあります。その場合、トランザクションに参加するのは 1 つだけであり、前述の 2 フェーズでの commit は不要になり、書き込み時間が短縮されます。
マルチリージョンでの書き込み
マルチリージョン デプロイでは、レプリカを複数のリージョンに分散させると可用性が向上しますが、パフォーマンス コストが発生します。異なるリージョンのレプリカ間の通信はラウンドトリップ時間が長くなります。このため、Firestore オペレーションのベースライン レイテンシは、シングル リージョン デプロイよりも若干高くなります。
スプリットのリーダーが常にプライマリ リージョンに存在するようにレプリカが構成されています。プライマリ リージョンは、Firestore サーバーがトラフィックを受信するリージョンです。このようにリーダーを決定することで、Firestore のストレージ クライアントとレプリカリーダー(またはマルチスプリット トランザクションのコーディネーター)間の通信でのラウンドトリップの遅延が減少します。
読み取りのライフサイクルについて
このセクションでは、Firestore での読み取りについて説明します。特にクエリは、ドキュメントの読み取りとインデックス エントリの読み取りが混在しています。
ストレージ レイヤからのデータの読み取りは、読み取りの整合性を確保するため、内部的にはデータベース トランザクションを使用して実行されます。ただし、書き込みに使用されるトランザクションとは異なり、これらのトランザクションはロックされません。その代わりに、トランザクションはタイムスタンプを選択して、そのタイムスタンプですべての読み込みを行います。ロックを行わないため、トランザクションは同時読み書きトランザクションをブロックしません。このトランザクションを実行するために、Firestore のストレージ クライアントはタイムスタンプの範囲を指定し、ストレージ レイヤに読み取りタイムスタンプの選択方法を通知します。Firestore でストレージ クライアントによって選択されるタイムスタンプ範囲の種類は、読み取りリクエストの読み取りオプションによって決まります。
ストレージ レイヤでの読み取りトランザクションについて
このセクションでは、読み取りの種類と、Firestore のストレージ レイヤでの読み取り方法について説明します。
強力な読み込み
デフォルトでは、Firestore の読み取りは強整合性を持ちます。強整合性とは、Firestore の読み取りが、読み取りの開始時までに commit されたすべての書き込みを反映した最新バージョンのデータを返すということです。
単一スプリット読み取り
Firestore のストレージ クライアントは、読み取る行のキーを所有しているスプリットを検索します。前のセクションのスプリット 3 からの読み取りを行う場合について考えてみましょう。クライアントは、ラウンドトリップ レイテンシを短縮するため、読み取りリクエストを最も近いレプリカに送信します。
この時点で、選択されたレプリカに応じて次のようなケースが考えられます。
- 読み取りリクエストがリーダー レプリカ(ゾーン A)に送信される。
- リーダーは常に最新の状態になっているため、読み取りがすぐに実行されます。
- 読み取りリクエストがリーダー以外のレプリカ(ゾーン B など)に送信される。
- スプリット 3 が、内部状態からそのスプリットに読み取りの実行に十分な情報があることを認識できた場合は、スプリットから読み取りを行います。
- スプリット 3 が最新のデータが存在することを認識できなかった場合は、リーダーにメッセージを送信して、読み取りの実行に必要な最新のトランザクションのタイムスタンプを取得します。トランザクションが適用されると、読み取りが実行されます。
Firestore がクライアントにレスポンスを返します。
マルチスプリット読み取り
複数のスプリットから読み取りを行う状況では、すべてのスプリットで同じメカニズムが発生します。すべてのスプリットからデータが返されると、Firestore のストレージ クライアントは結果を結合します。Firestore はこのデータを使用してクライアントにレスポンスを返します。
ホットスポットを回避する
Firestore のスプリットは、必要に応じて自動的に分割され、トラフィックをより多くのストレージ サーバーに配信したり、キースペースが拡張されたりするときにトラフィックを分散します。過剰なトラフィックの処理のために作成されたスプリットが、トラフィックがなくなっても約 24 時間ほど保持されます。そのため、トラフィックの急増が繰り返し発生する場合、スプリットは維持され、必要に応じて追加されます。このメカニズムにより、Firestore データベースは、トラフィック負荷またはデータベース サイズの増加に応じて自動スケーリングできます。ただし、いくつかの制限があります。
ストレージと負荷の分割に時間がかかり、トラフィックが急増すると、サービスの調整中に高レイテンシや期限超過エラー(一般的にはホットスポット)が発生する可能性があります。ベスト プラクティスは、データベース内のコレクションへのトラフィックを徐々に増やしながら、キー範囲全体にオペレーションを分散させることです。
スプリットは負荷が増加すると自動的に作成されますが、Firestore は、複製された専用のストレージ サーバーのセットを使用して単一ドキュメントを提供するまで、キー範囲を分割できます。結果として、単一ドキュメント上で同時実行するオペレーションの量が高いままで維持され、そのドキュメントでホットスポットが発生する場合があります。単一ドキュメントで高レイテンシが持続されるような場合は、複数のドキュメントにデータを分割または複製するようなデータモデルへの修正を検討しましょう。
競合エラーは、複数のオペレーションで同じドキュメントを同時に読み書きしようとした場合に発生します。
このページで説明するプラクティスに従うことで、Firestore は構成を調整しなくても、任意の大きなワークロードに合わせてスケーリングできます。