Document AI lets you train new processor versions using your own training data and evaluate the quality of your processor version against your own test data.
This is useful when you want to use a custom processor. There is a Document AI processor for your document type, but you can up-train a custom version of it to meet your needs.
Training and evaluation are typically performed in tandem to iterate towards a high quality, usable processor version.
Document AI
Document AI lets you build your own custom extractor, which extracts entities from documents of a particular type, for example, the items in a menu or the name and contact information from a resume.
Unlike other processors, custom processors don't come with any pretrained processor versions and thus, cannot process any documents until you train a version from scratch.
To get started with Document AI, see Build your own custom processor.
Uptraining a processor
You can uptrain new processor versions to improve accuracy on your data, extract additional custom fields from your documents, and add support for new languages.
Up training works by applying transfer learning on Google pretrained processor versions and generally requires less data than training from scratch.
To get started, see Uptrain a pretrained processor.
Supported processors
Not all specialized processors support up training. These are the processors that support up training.
Data considerations and recommendations
The quality and the amount of your data determines the quality of the training, uptraining, and evaluation.
Obtaining a set of representative, real-world documents and providing enough high-quality labels are often the most time-consuming and resource-intensive part of the process.
Number of documents
If your documents all have a similar format (for example, a fixed form with very low variation), then fewer documents are required to achieve accuracy. The higher the variation, the more documents are required.
The following charts provide a rough estimate of the number of documents that are required for a Custom Document Extractor to achieve a particular quality score.
| Low variation | High variation |
|---|---|
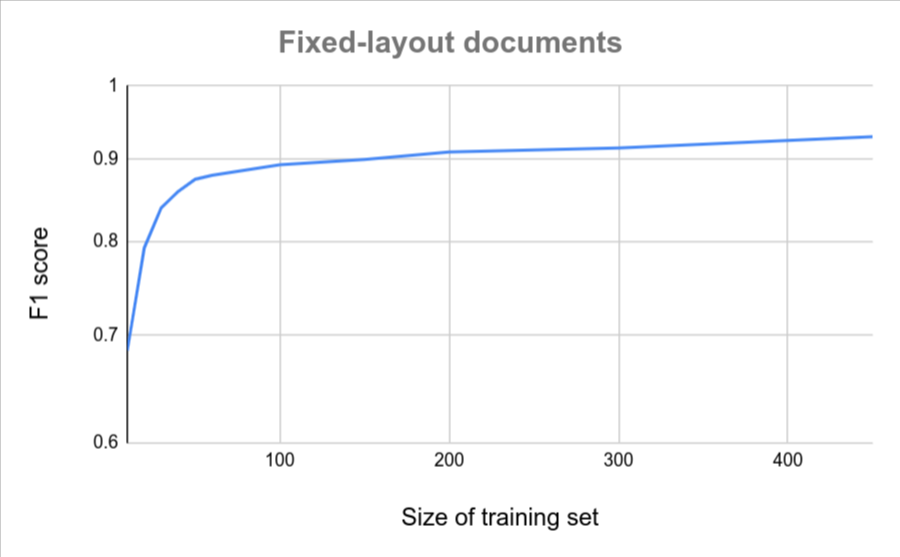 |
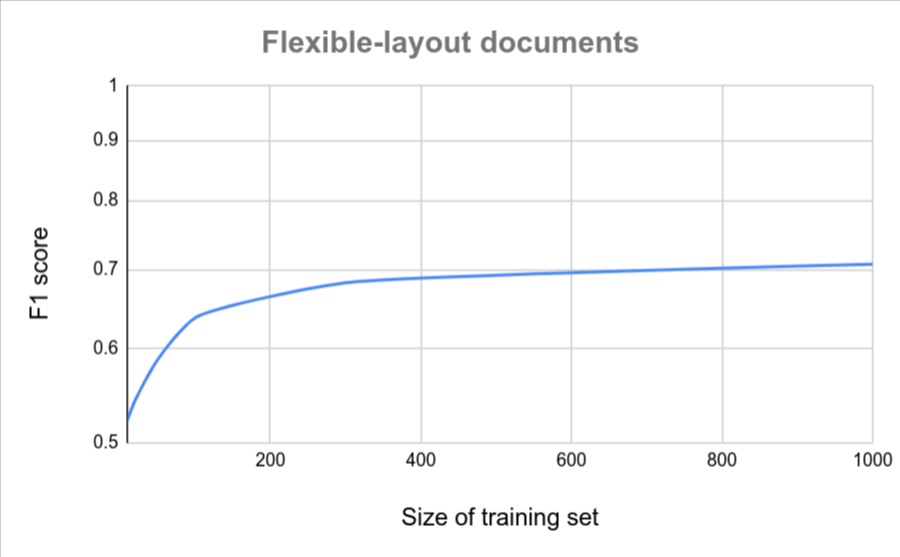 |
Data labeling
Consider your options for labeling documents and make sure you have enough resources to annotate the documents in your dataset.
Training models
Custom extractor processors can use different model types depending on the specific use case and available training data.
- Custom model: model using labeled training data.
- Template-based: documents with a fixed layout.
- Model-based: documents with some layout variation.
- Generative AI model: based on pretrained foundation models that require minimal additional training.
The following table illustrates which use cases correspond to each model type.
| Custom model | Generative AI | ||
|---|---|---|---|
| Template-based | Model-based | ||
| Layout variation | None | Low to medium | High |
| Amount of free-form text (for example, paragraphs in a contract) | Low | Low | High |
| Amount of training data required | Low | High | Low |
| Accuracy with limited training data | Higher | Lower | Higher |
Learn to Fine-tune a processor with property descriptions.
When to use another processor
Here are some instances in which you might want to consider options besides Document AI Document AI Workbench, or adapt your workflow.
- Certain text-based input formats (.txt, .html, .docx, .md, and so forth) are not supported by Document AI Document AI Workbench. Consider other prebuilt or custom language processing offerings in Google Cloud, such as the Cloud Natural Language API.
- The Custom Document Extractor schema supports up to 150 entity labels. If your business logic requires more than 150 entities in the schema definition, consider training multiple processors, each targeting a subset of entities.
How to train a processor
Assuming that you have already created a processor that supports training or uptraining and labeled your dataset, you can train a new processor version from scratch. Or you can uptrain a new processor version based on an existing one.
Train processor version
Web UI
In the Google Cloud console, go to your processor's Train tab.
Click Edit Schema to open the Manage Labels page. Verify the processor's labels.
The labels that are enabled at the time of training determine the entities that your new processor version extracts. If a label is inactive in the schema, the processor version is not extracting that label, even if the documents are labeled.
On the Train tab, click View Label Stats and verify your test and training set. Documents that are auto-labeled, unlabeled, or unassigned are excluded from training and evaluation.
Click Train new version.
The Version Name defines the
namefield of theprocessorVersion.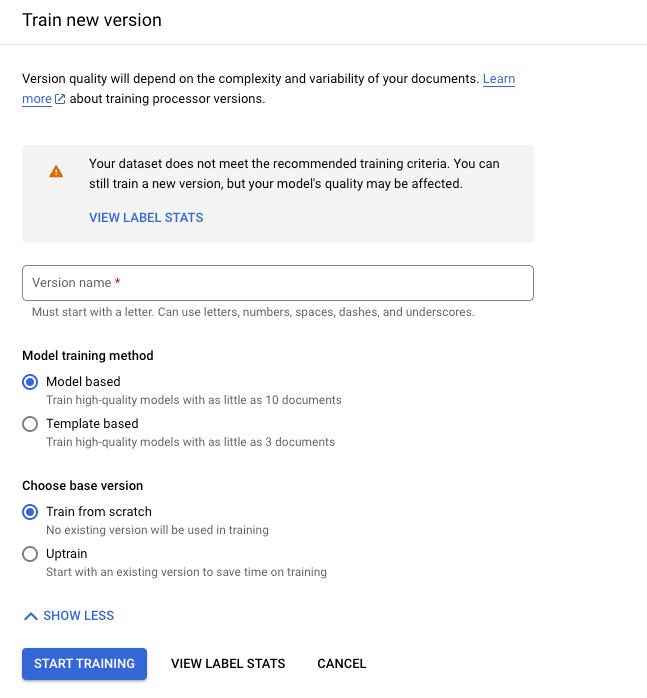
Click Start training and wait for your new processor version to be trained and evaluated.
You can monitor training progress on the Manage Versions tab:
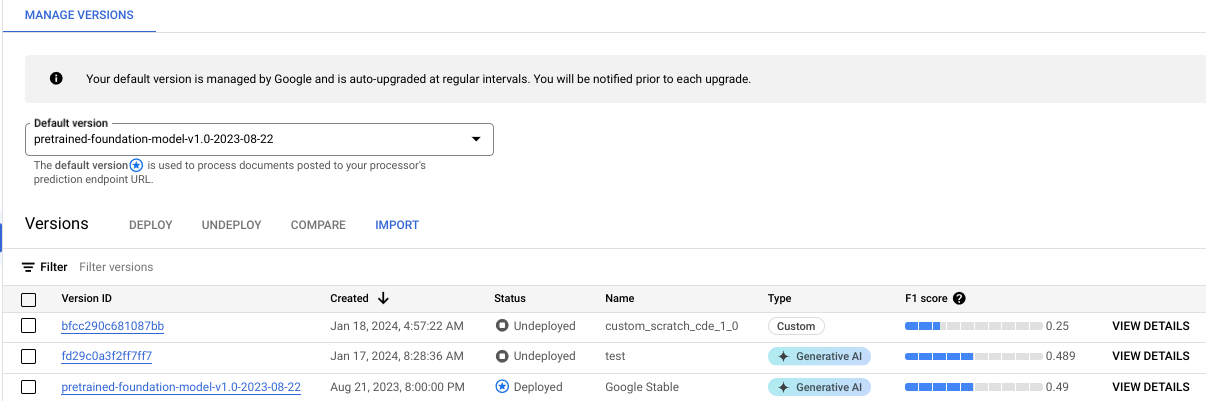
Click the Evaluate & Test tab to see how well your new processor version performed on the test set. For more information, see Evaluate processor version.
Python
For more information, see the Document AI Python API reference documentation.
To authenticate to Document AI, set up Application Default Credentials. For more information, see Set up authentication for a local development environment.
Deploy and use the processor version
You can deploy and manage your processor versions just like any other processor version. For more information, see Managing processor versions.
Once deployed, you can Send a processing request to your custom processor.
Disable or delete a processor
If you no longer want to use a processor, you can disable or delete it. If you disable a processor, you can re-enable it. If you delete a processor, you cannot recover it.
In the Document AI panel on the left, click My processors.
Click the vertical dots to the right of the processor name. Click Disable processor or Delete processor.
For more information, see Managing processor versions.
Encryption of training data
Document AI training data is saved in Cloud Storage and can be encrypted with Customer-managed encryption keys if required.
Deletion of training data
After a Document AI training job is completed, all training data saved in Cloud Storage expire after a two-day retention period. Subsequent data deletion activities respect the process described in Data deletion on Google Cloud.
Pricing
There is no cost for training or up-training. You pay for hosting and prediction. For more information, see Document AI Pricing.