Divisor personalizado
O divisor personalizado foi projetado para ser usado para dividir documentos compostos (documentos compostos de várias classes) em vários documentos de classe única, identificando cada documento lógico. Por exemplo, um pacote de hipoteca contém várias classes, como inscrição, verificação de renda e documento de identificação com foto. Os processadores de divisor personalizados, para serem usados, são treinados desde o início usando seus próprios documentos e classes personalizadas.
Descrição e uso do divisor
Crie divisores personalizados que são especificamente adequados para seus documentos e treinados e avaliados com seus dados. Este processador identifica classes de documentos de um conjunto de classes definido pelo usuário. Você pode usar o processador treinado em documentos de produção. Normalmente, você usaria um divisor personalizado em arquivos compostos por diferentes tipos de documentos lógicos e, em seguida, usaria a identificação de classe de cada um para transmitir os documentos a um processador de extração apropriado para extrair as entidades.
Como os modelos de ML não são perfeitos e têm uma certa taxa de erro, e como erros de divisão costumam ser muito problemáticos (uma divisão incorreta compõe dois documentos errados e causa erros de extração), uma prática recomendada é a etapa de revisão humana após a previsão de divisão, mas antes da divisão de arquivo real. Com base nos requisitos da empresa, existem alternativas para sempre fazer a revisão humana:
- Use as pontuações de confiança na previsão para decidir se deve ignorar a revisão humana (se for alta o suficiente). Esse limite de pontuação de confiança precisa ser determinado com base em dados históricos sobre taxas de erro com pontuações de confiança determinadas. Essa deve ser uma decisão de negócios com base na tolerância do processo de negócios a erros e no requisito de ignorar a revisão humana.
- Em alguns casos de uso, os documentos divididos podem ser roteados diretamente para o extrator apropriado, de acordo com a classe prevista. Em seguida, se a extração estiver incompleta ou tiver pontuações de confiança baixas, isole os documentos divididos e acione o documento composto original e a decisão de divisão a serem analisados. Isso tem requisitos de fluxo de trabalho bastante complexos.
Criar um divisor personalizado no console do Google Cloud
Neste guia de início rápido, descrevemos como usar a Document AI para criar e treinar um divisor personalizado que divide e classifica documentos de compras. A maior parte da preparação do documento já foi feita para que você possa se concentrar na criação de um divisor personalizado.
Um fluxo de trabalho típico para criar e usar um divisor personalizado é o seguinte:
- Criar um divisor personalizado na Document AI.
- Criar um conjunto de dados usando um bucket vazio do Cloud Storage.
- Definir e criar o esquema do processador (classes).
- Importar documentos.
- Atribuir documentos aos conjuntos de treinamento e teste.
- Anotar documentos manualmente no Document AI Workbench ou com tarefas de rotulagem.
- Treinar o processador.
- Avaliar o processador.
- Implantar o processador.
- Testar o processador.
- Usar o processador nos seus documentos.
Se você tiver seus documentos em pastas separadas por classe, poderá pular a etapa 6 especificando a classe no momento da importação.
Para seguir as instruções passo a passo desta tarefa diretamente no console do Google Cloud, clique em Orientação:
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Criar um processador
No console do Google Cloud, na seção do Document AI, acesse a página Workbench.
Em Divisor de documentos personalizado, selecione
Criar processador .
No menu Criar processador, insira um nome para o processador, como
my-custom-document-splitter.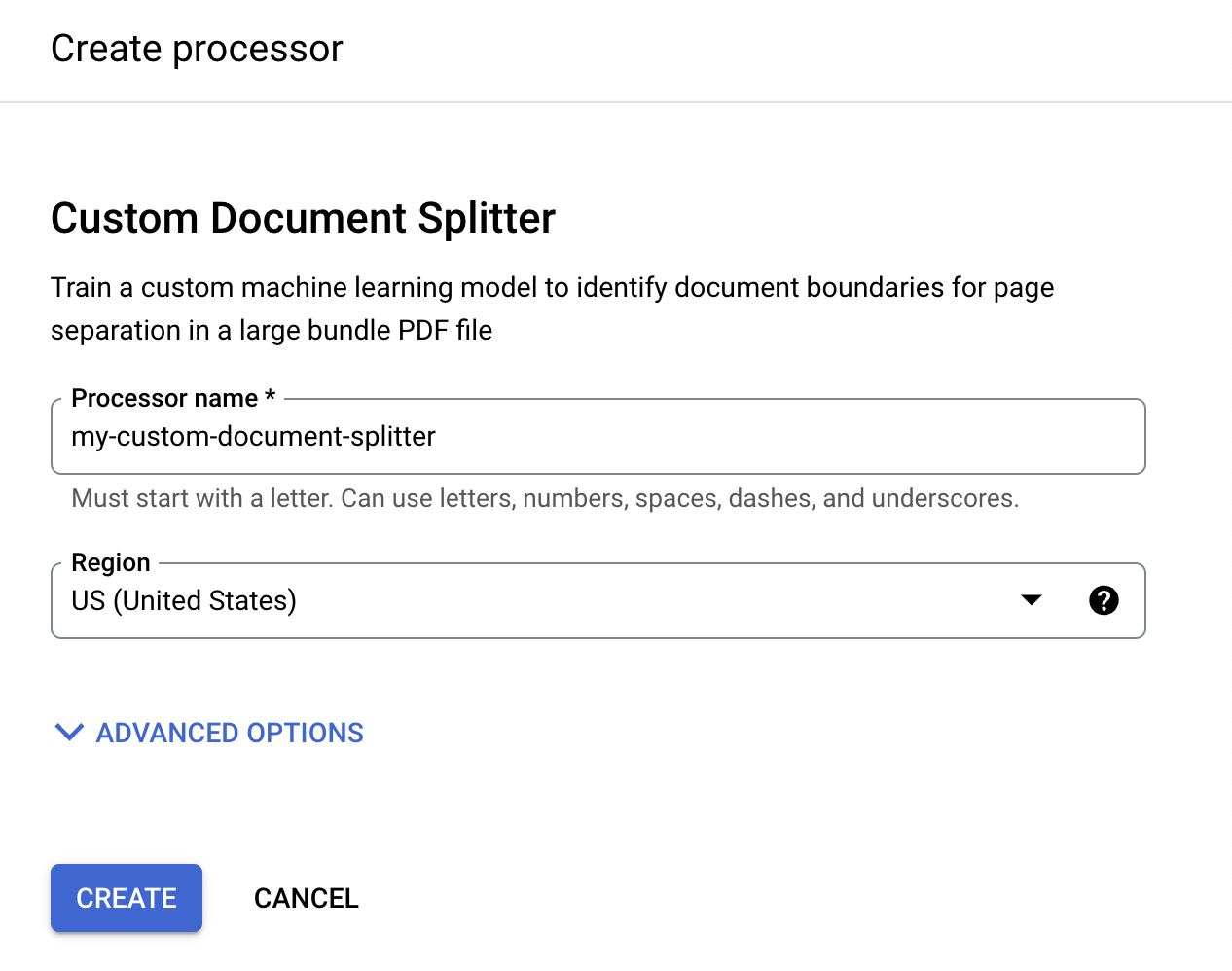
Selecione a região mais próxima de você.
Selecione Criar. A guia Detalhes do processador é exibida.
Configurar conjunto de dados
Para treinar esse novo processador, você precisa criar um conjunto de dados com informações de treinamento e teste para ajudar o processador a identificar os documentos que você quer dividir e classificar.
Este conjunto de dados requer um novo local para ele. Pode ser um bucket do Cloud Storage ou uma pasta vazia, ou você pode permitir um local gerenciado pelo Google (interno).
- Se você quiser usar o armazenamento gerenciado pelo Google, selecione essa opção.
- Se você quiser usar seu próprio armazenamento para utilizar as chaves de criptografia gerenciadas pelo cliente (CMEK), selecione Vou especificar meu próprio local de armazenamento e siga o procedimento posterior.

Crie um bucket do Cloud Storage para o conjunto de dados
Acesse a guia
Treinar do processador.Selecione Definir local do conjunto de dados. Você precisa selecionar ou criar um bucket do Cloud Storage ou pasta vazios.
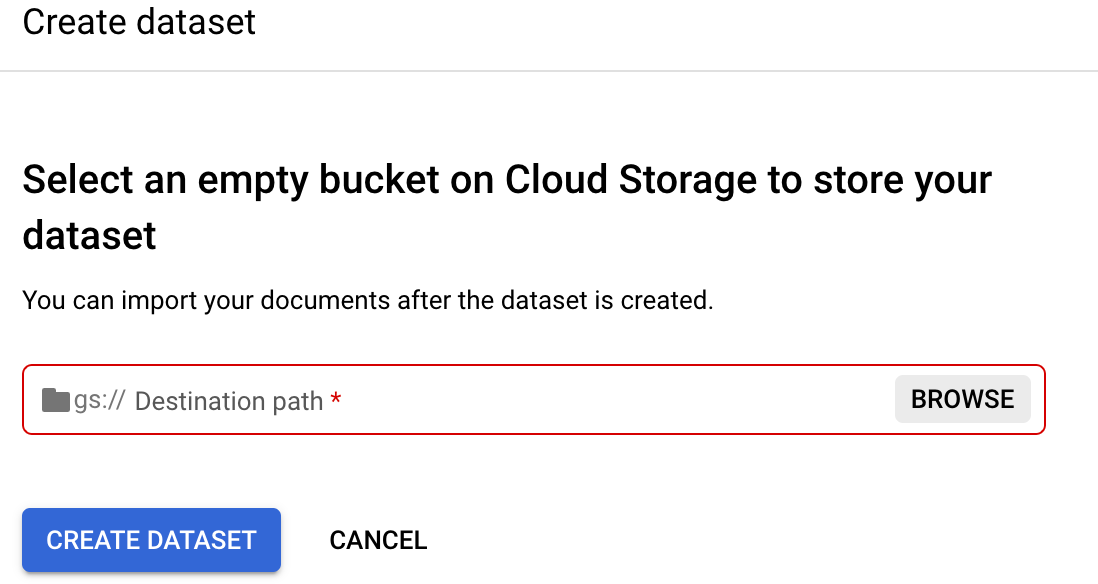
Selecione Procurar para abrir Selecionar pasta.
Clique no ícone Criar um novo bucket e siga as instruções para criar um novo bucket. Depois de criar o bucket, a página Selecionar pasta será exibida. Saiba mais sobre como criar um bucket do Cloud Storage em Buckets do Cloud Storage.
Na página Selecionar pasta do bucket, escolha o botão de seleção na parte inferior da caixa de diálogo.
Verifique se o caminho de destino está preenchido com o nome do bucket que você selecionou. Selecione Criar conjunto de dados. A criação do conjunto de dados pode levar vários minutos.
Definir esquema do processado
É possível criar o esquema do processador antes ou depois de importar documentos para o conjunto de dados. O esquema fornece rótulos que serão usados para anotar documentos.
Na guia Treinar, selecione
Editar esquema no canto inferior esquerdo. A página Gerenciar marcadores é aberta.Selecione
Criar rótulo .Digite o nome do marcador. Selecione Criar. Consulte Definir esquema de processador para instruções detalhadas sobre como criar e editar um esquema.
Crie cada um dos rótulos a seguir para o esquema do processador.
bank_statementform_1040form_w2form_w9paystub
Selecione
Salvar quando os rótulos estiverem completos.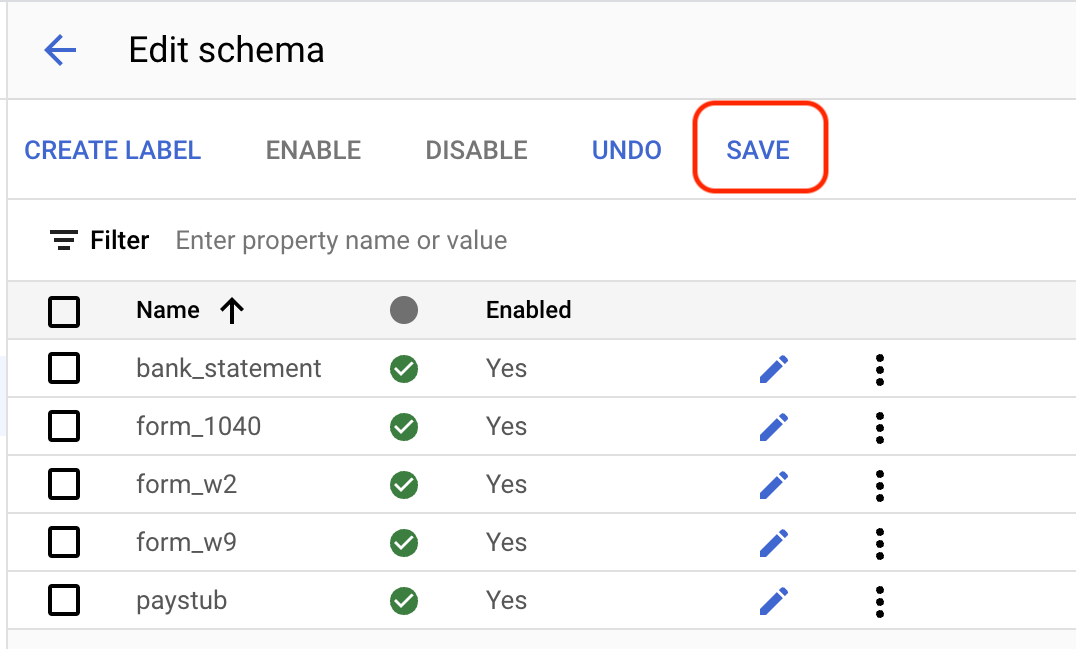
Importar um documento não identificado para um conjunto de dados
A próxima etapa é começar a importar documentos não rotulados para seu conjunto de dados e rotulá-los. Uma alternativa recomendada é importar documentos organizados em pastas por classe, se disponíveis.
Se estiver trabalhando no seu próprio projeto, você determinará como rotular os dados. Consulte Opções de rotulagem.
Os processadores personalizados da Document AI exigem no mínimo 10 documentos nos conjuntos de treinamento e teste, além de 10 instâncias de cada rótulo em cada conjunto. Recomendamos pelo menos 50 documentos em cada conjunto, com 50 instâncias de cada rótulo para melhor desempenho. Em geral, mais dados de treinamento produzem maior precisão.
Na guia Treinar, selecione
Importar documentos .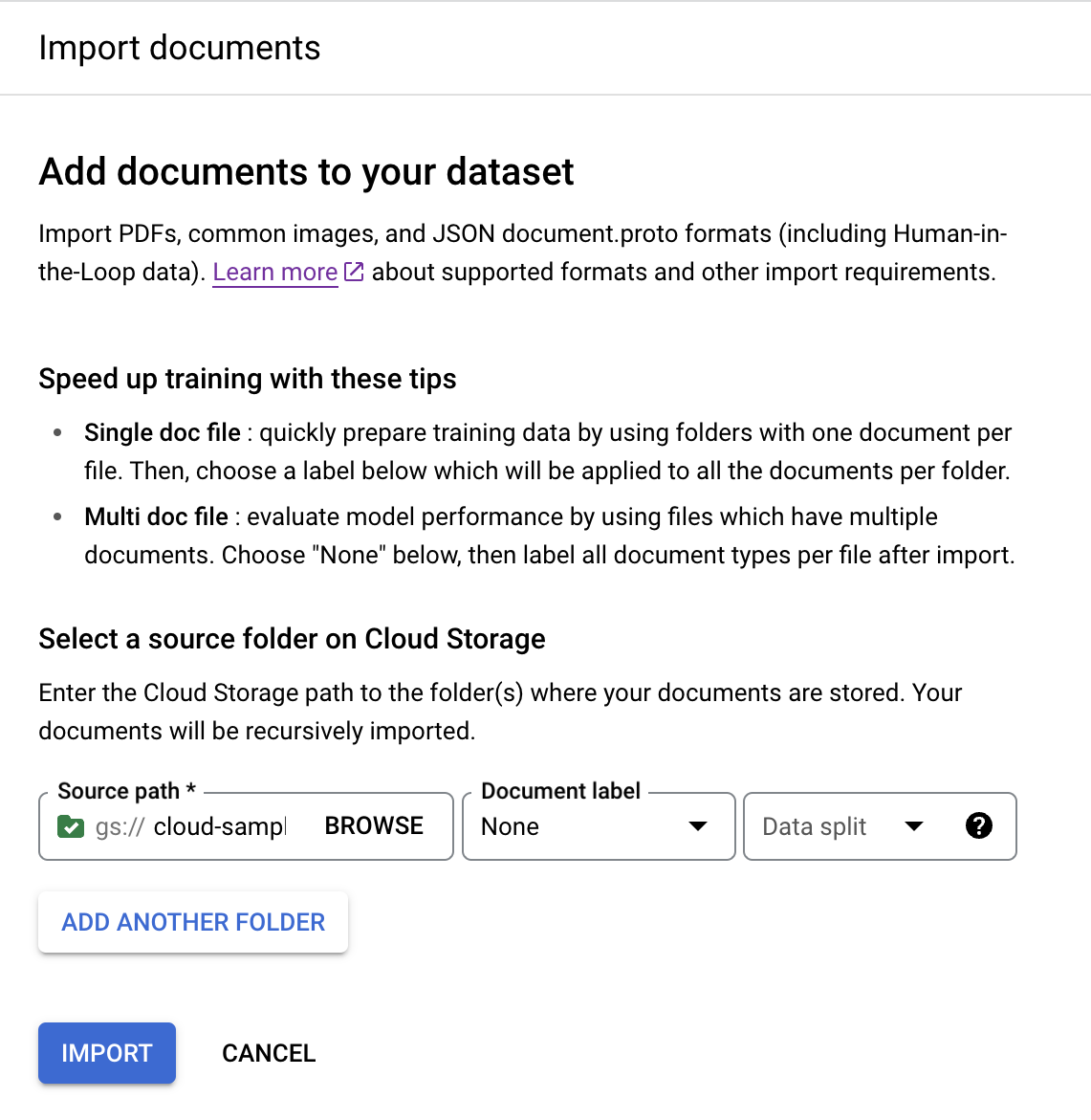
Neste exemplo, insira esse caminho em
Caminho de origem . Ele contém um documento PDF.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-UnlabeledDefina o
Rótulo do documento como Nenhum.Defina o menu suspenso
Divisão de conjuntos de dados como Não atribuída.O documento nessa pasta não recebe um rótulo ou é atribuído por padrão ao conjunto de teste ou treinamento.
Selecione
Importar . A Document AI lê os documentos do bucket no conjunto de dados. Ele não modifica o bucket de importação ou faz uma leitura a partir do bucket após a conclusão da importação.
Quando você importa documentos, é possível atribuir os documentos ao conjunto de Treinamento ou Teste na importação ou esperar mais tarde.
Se quiser excluir um ou mais documentos importados, selecione-os na guia Treinar e clique em Excluir.
Para mais informações sobre como preparar os dados para importação, consulte o guia de preparação de dados.
Opcional: identificador em lote de documentos na importação
É possível rotular todos os documentos que estão em um diretório específico na importação para economizar tempo com a rotulagem. Se os documentos de treinamento estiverem organizados por classe em pastas, será possível usar o campo Rótulo do documento para especificar a classe desses documentos e evitar a identificação manual de cada documento.
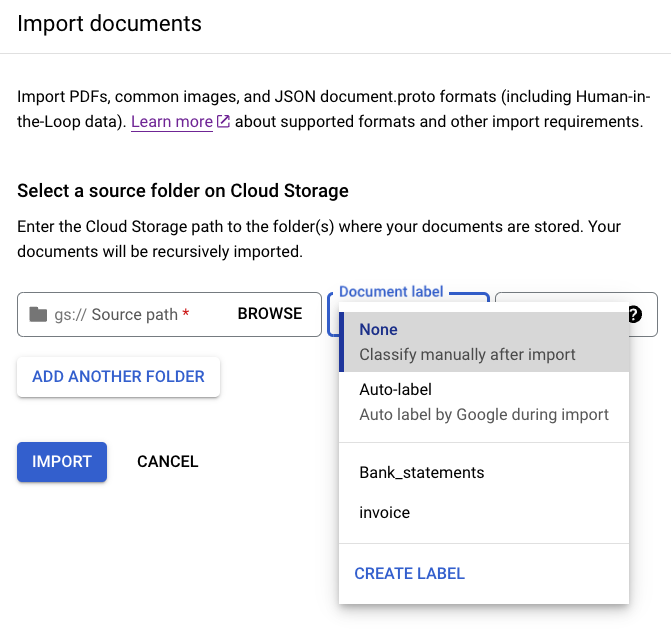
Na imagem Bank_statements e Fatura estão disponíveis rótulos definidos (classes de documento) que podem ser selecionados. Ou você pode usar CREATE LABEL e definir uma nova
classe.
- Clique em Importar documentos.
Insira o caminho a seguir em Caminho de origem. Este bucket contém documentos sem rótulo em formato PDF.
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabelNa lista Divisão de dados, selecione Dividir automaticamente. Isso divide automaticamente os documentos para que tenham 80% no conjunto de treinamento e 20% no conjunto de teste.
Na seção Aplicar marcadores, selecione Escolher marcador.
Para estes documentos de exemplo, selecione "Outros".
Clique em Importar e aguarde os documentos. Você pode sair desta página e continuar mais tarde.
Rotular um documento
O processo de aplicar rótulos a um documento é conhecido como anotação.
Volte para a guia Treinar e selecione
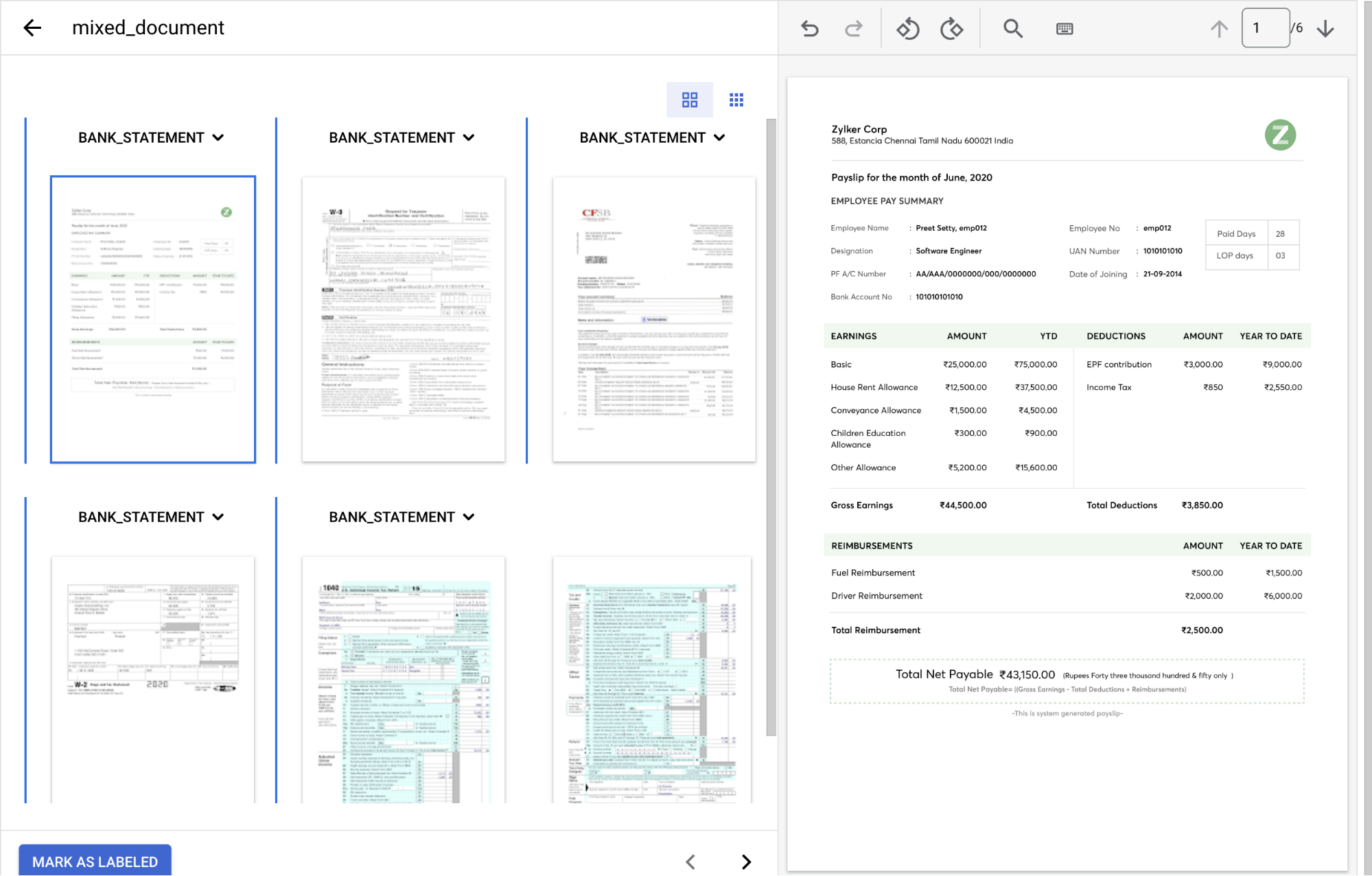
um documento para abrir o console de Gerenciamento de rótulos.Este documento contém vários grupos de páginas que precisam ser identificados e rotulados. Primeiro, você precisa identificar os pontos de divisão. Mova o mouse entre as páginas 1 e 2 na visualização de imagem e clique no símbolo de
+ .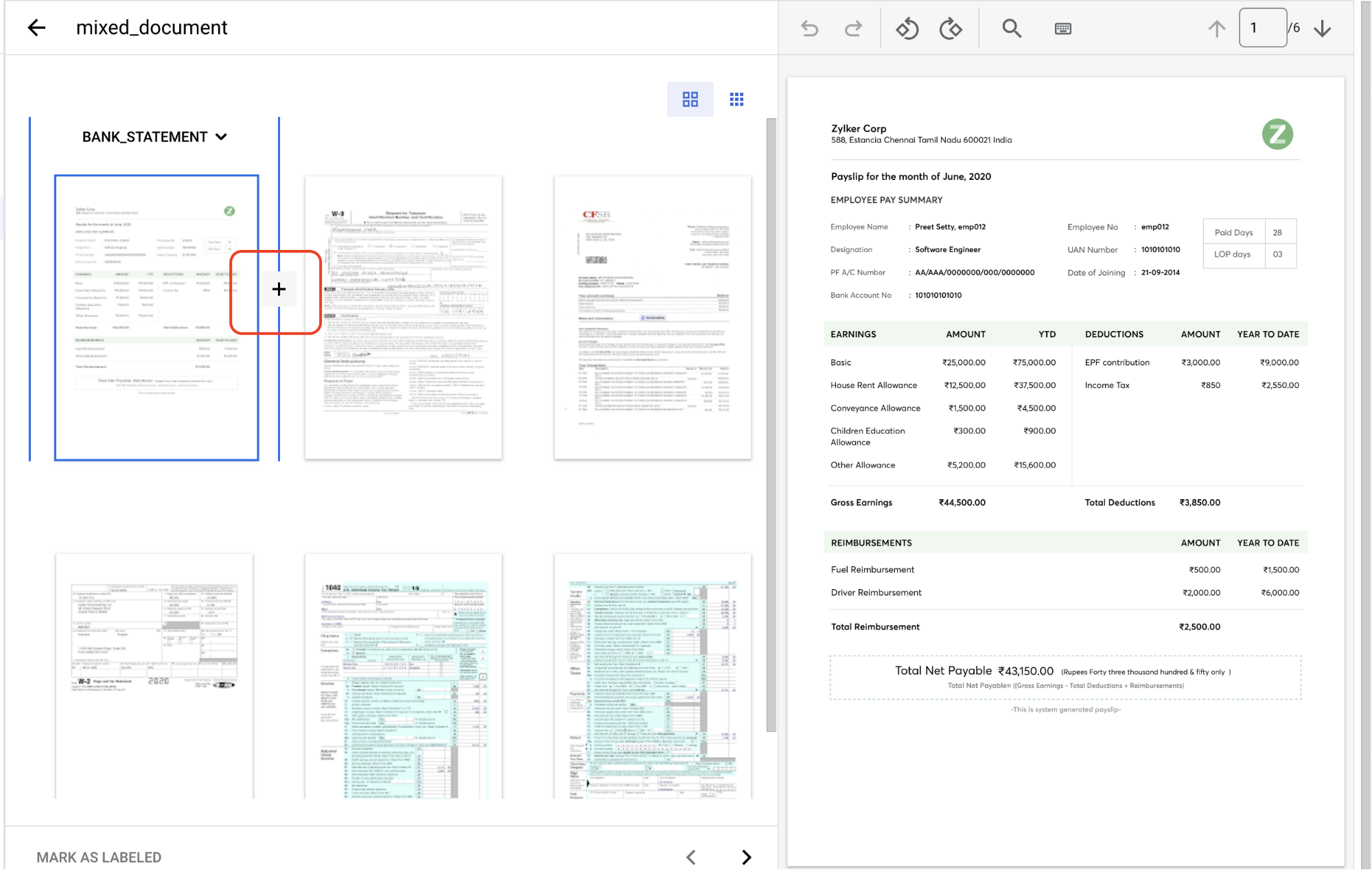
Crie pontos de divisão antes dos seguintes números de página: 2, 3, 4, 5.
O console vai ficar assim quando terminar.
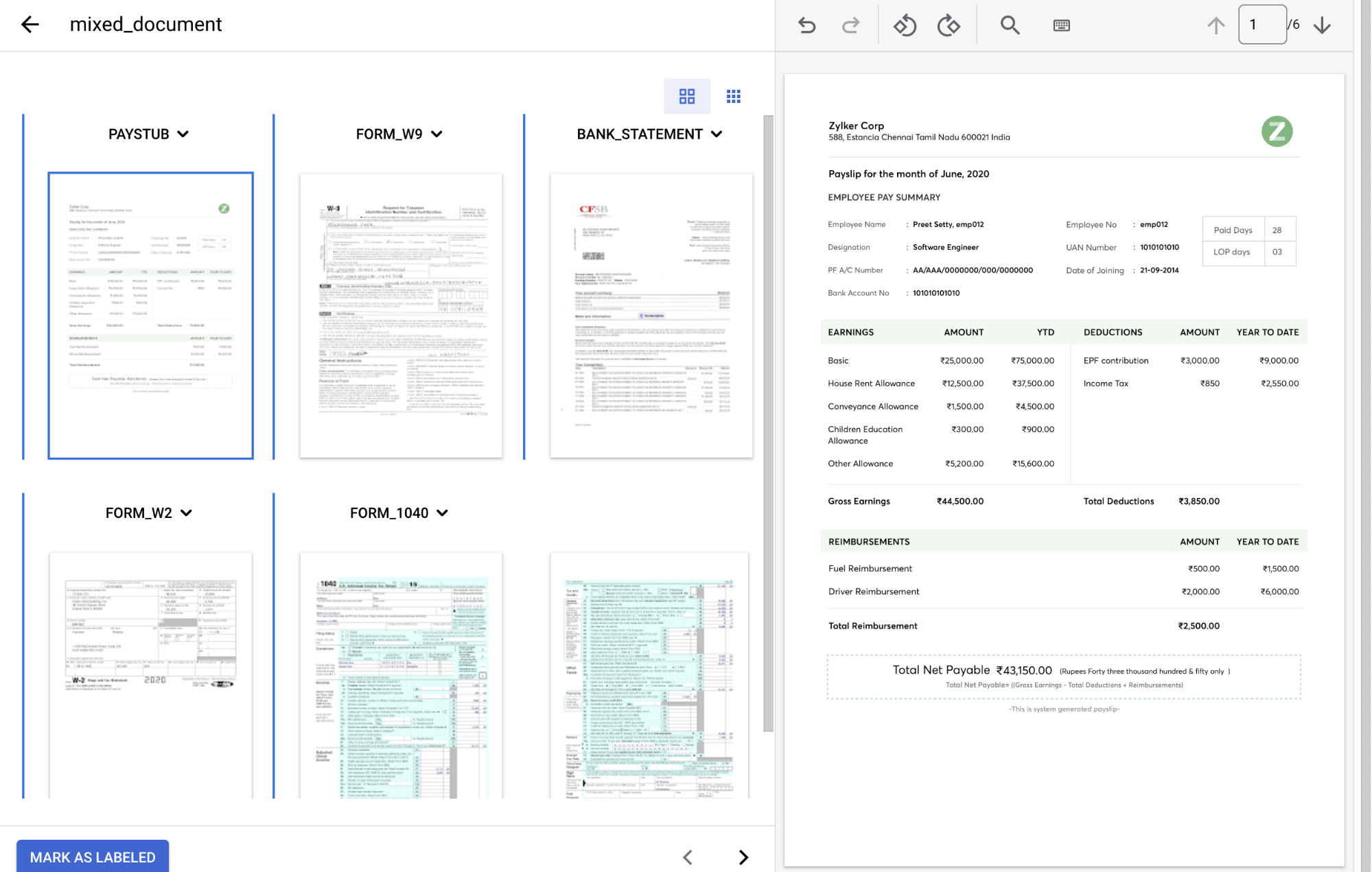
No
menu suspenso Tipo de documento , selecione o rótulo apropriado para cada grupo de páginas.Páginas Tipo de documento 1 paystub2 form_w93 bank_statement4 form_w25 e 6 form_1040Quando concluído, o documento rotulado deve ficar assim:
Selecione
Marcar como rotulado quando terminar de anotar o documento.Na guia Treinar, o painel à esquerda mostra que um documento foi rotulado.
Atribuir documentos anotados ao conjunto de treinamento
Agora que você rotulou este documento de exemplo, é possível atribuí-lo ao conjunto de treinamento.
Na guia Treinar, marque a caixa de seleção
Selecionar tudo .Na lista suspensa
Atribuir ao conjunto , selecione Treinamento.
No painel esquerdo, é possível conferir que um documento foi atribuído ao conjunto de treinamento.
Importar dados com rotulagem em lote
Em seguida, você importa arquivos PDF não rotulados que são classificados em diferentes pastas do Cloud Storage por tipo. A rotulagem em lote ajuda a economizar tempo na rotulagem atribuindo um rótulo no momento da importação com base no caminho.
Na guia Treinar, selecione
Importar documentos .Insira o caminho a seguir em
Caminho de origem . Esta pasta contém PDFs de extratos bancários.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/bank-statementDefina o
Rótulo do documento comobank_statement.Defina, no menu
Divisão do conjunto de dados , como Dividir automaticamente. Isso divide automaticamente os documentos para que tenham 80% no conjunto de treinamento e 20% no conjunto de teste.Selecione
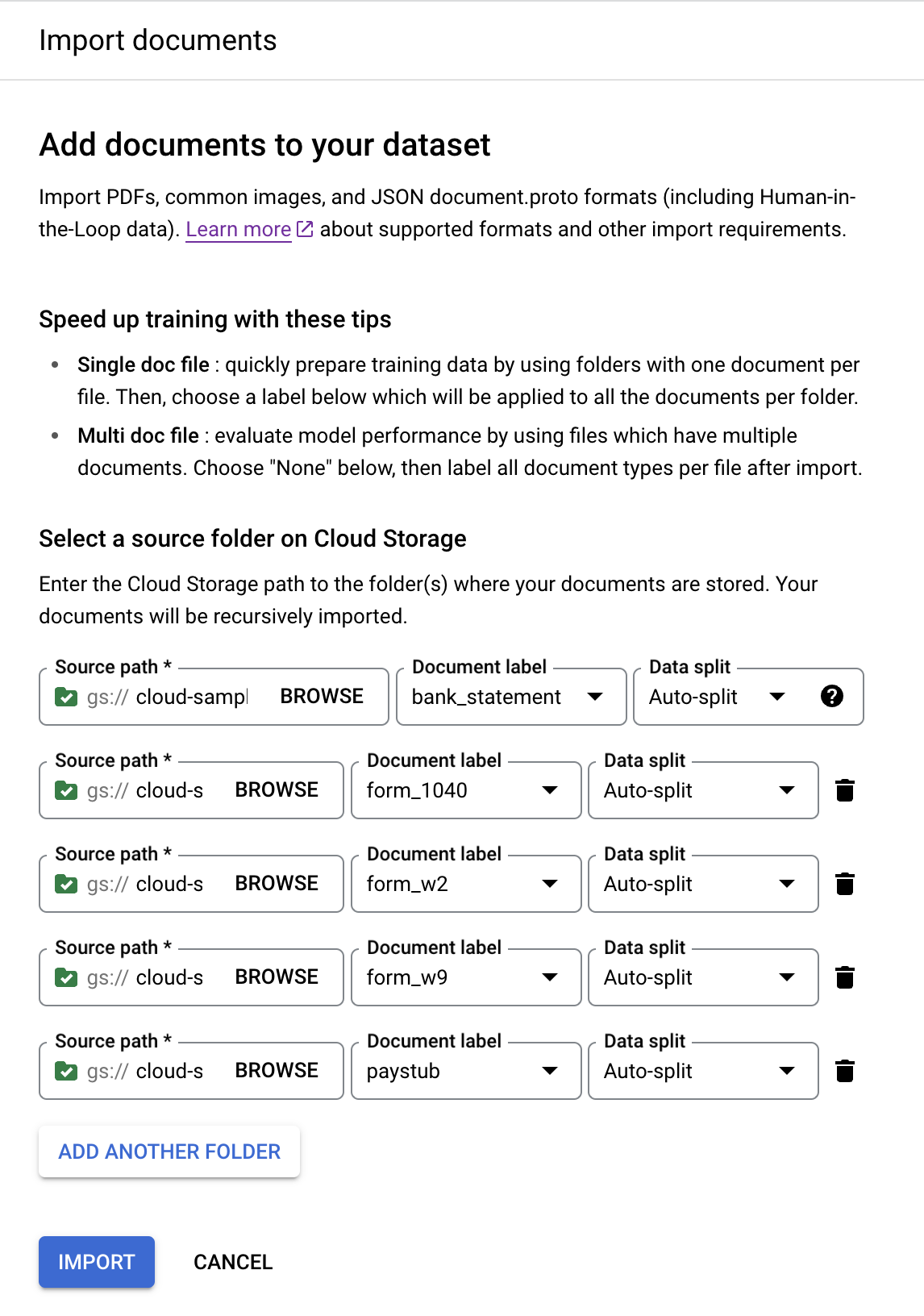
Adicionar outra pasta para adicionar mais pastas.Repita as etapas anteriores com os seguintes caminhos e rótulos de documentos:
Caminho do bucket Identificador do documento cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/1040form_1040cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w2form_w2cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w9form_w9cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/paystubpaystubO console vai ficar assim quando for concluído:
Selecione
Importar . A importação leva alguns minutos.
Quando a importação for concluída, encontre os documentos na guia Treinar.
Importar os dados pré-rotulados
Neste guia, fornecemos dados pré-rotulados no formato Document como arquivos JSON.
Esse é o mesmo formato que o Document AI gera ao processar um documento, rotular com human-in-the-loop ou exportar um conjunto de dados.
Na guia Treinar, selecione
Importar documentos .Insira o caminho a seguir em
Caminho de origem .cloud-samples-data/documentai/Custom/Lending-Splitter/JSON-LabeledDefina o
Rótulo do documento como Nenhum.Defina o menu suspenso
Divisão de conjuntos de dados como Divisão automática.Selecione
Importar .
Quando a importação for concluída, encontre os documentos na guia Treinar.
Treinar o processador
Agora que você importou os dados de treinamento e teste, é possível treinar o processador. Como o treinamento pode levar várias horas, confirme se você configurou o processador com os dados e rótulos apropriados antes de começar o treinamento.
Selecione
Treinar nova versão .No campo
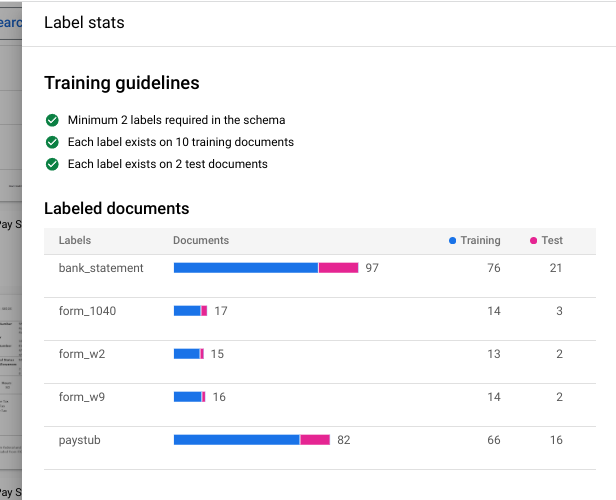
Nome da versão , insira um nome para essa versão do processador, comomy-cds-version-1.(Opcional) Selecione Ver estatísticas dos rótulos para conferir informações sobre os rótulos dos documentos. Isso pode ajudar a determinar a cobertura. Selecione Fechar para retornar à configuração de treinamento.
Selecione
Iniciar treinamento . É possível verificar o status no painel à direita.
Implantar a versão do processador
Após a conclusão do treinamento, navegue até a guia
Gerenciar versões . É possível ver detalhes sobre a versão que você acabou de treinar.Selecione os
três pontos verticais à direita da versão que você quer implantar e clique em Implantar versão.Selecione
Implantar na janela pop-up.A implantação leva alguns minutos para ser concluída.
Avaliar e testar o processador
Após a conclusão da implantação, navegue até a guia
Avaliar e testar .Nessa página, é possível encontrar as métricas de avaliação, incluindo a pontuação F1, precisão e recall para o documento completo e os rótulos individuais. Para mais informações sobre avaliação e estatísticas, consulte Avaliar processador.
Faça o download de um documento que não esteja envolvido em treinamentos ou testes anteriores para usá-lo na avaliação da versão do processador. Se você estiver usando seus próprios dados, use um documento reservado para essa finalidade.
Selecione
Fazer upload do documento de teste e selecione o documento que você acabou de fazer download.A página Análise do divisor personalizado é aberta. A saída da tela vai demonstrar como o documento foi dividido e classificado.
O console vai ficar assim quando for concluído:
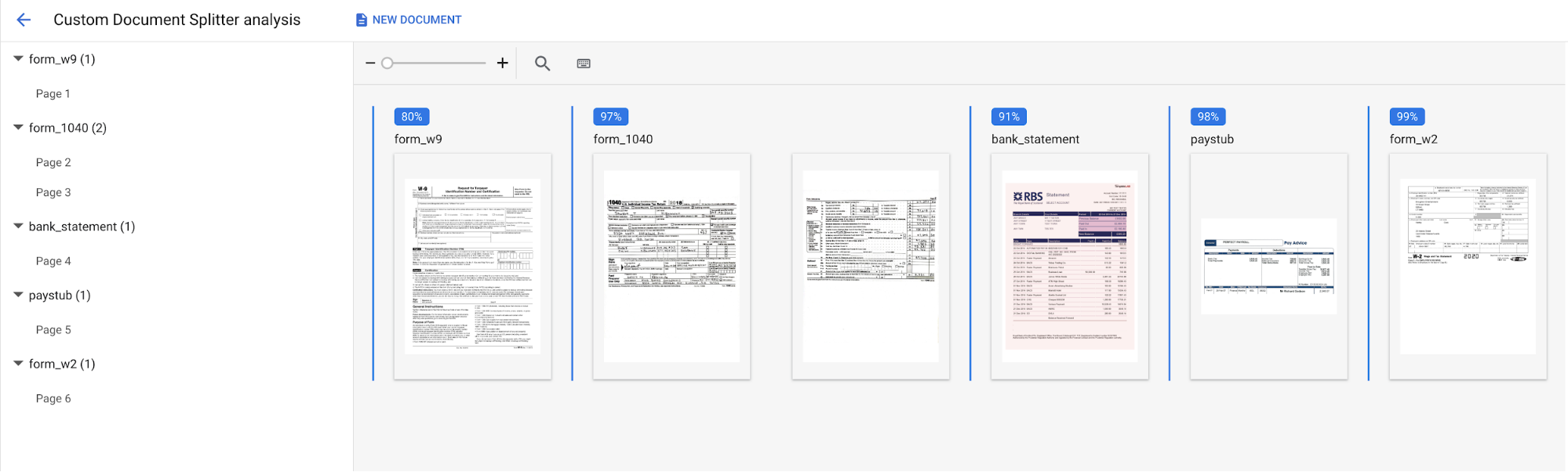
Também é possível executar novamente a avaliação em um conjunto de teste ou versão de processador diferente.
(Opcional) Importar dados com a rotulagem automática
Depois de implantar uma versão do processador treinado, use a Rotulagem automática para poupar tempo ao importar novos documentos.
Na guia Treinar, selecione
Importar documentos .Insira o caminho a seguir em
Caminho de origem . Esta pasta contém PDFs não identificados de vários tipos de documentos.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-AutoLabelDefina o
Rótulo do documento como Rótulo automático.Defina o menu suspenso
Divisão de conjuntos de dados como Divisão automática.Na seção Rotulagem automática, defina a
Versão como a versão que você treinou anteriormente.- Por exemplo:
2af620b2fd4d1fcf
- Por exemplo:
Selecione
Importar e aguarde a importação dos documentos.Não é possível usar documentos com rótulos automáticos para treinamento ou teste sem marcá-los como rotulados. Acesse a seção
Rotulados automaticamente para conferir os documentos rotulados automaticamente.Selecione o primeiro documento para acessar o console de rotulagem.
Verifique o rótulo para garantir que ele esteja correto. Caso não esteja, ajuste-o.
Selecione
Marcar como rotulado quando terminar.Repita a verificação de rótulo para cada documento rotulado automaticamente.
Retorne à página Treinar e selecione Treinar nova versão para usar os dados para treinamento.
Usar o processador
Você criou e treinou um processador do divisor de documentos personalizado.
É possível gerenciar versões do processador treinadas e personalizadas como qualquer outra versão do processador. Para mais informações, consulte Como gerenciar versões do processador.
Depois de implantado, envie uma solicitação de processamento para o processador personalizado. Assim, a resposta pode ser processada da mesma forma que os outros processadores divisores.
Limpar
Para evitar cobranças na conta do Google Cloud pelos recursos usados nesta página, siga estas etapas.
Para evitar cobranças Google Cloud desnecessárias, use o console do Google Cloud para excluir o processador e o projeto se você não precisar deles.
Se você criou um projeto novo para aprender sobre a Document AI e não precisa mais dele, exclua o projeto.
Se você usou um projeto Google Cloud que já existe, exclua os recursos criados para evitar cobranças na sua conta:
No menu de navegação do console do Google Cloud, selecione Document AI e Meus processadores.
Selecione
Mais ações na mesma linha do processador que você quer excluir.Selecione Excluir processador, digite o nome do processador e selecione Excluir novamente para confirmar.