Séparateur personnalisé
Le séparateur personnalisé est conçu pour scinder des documents composites (documents composés de plusieurs classes) en plusieurs documents à classe unique, en identifiant chaque document logique. Par exemple, un package hypothécaire contient plusieurs classes telles qu'une application, une vérification du revenu et une pièce d'identité avec photo. Afin d'être utilisés, les processeurs de séparateurs personnalisés sont entraînés à partir de zéro à l'aide de vos propres documents et classes personnalisées.
Description et utilisation du séparateur
Vous créez des séparateurs personnalisés qui sont spécifiquement adaptés à vos documents, puis entraînés et évalués avec vos données. Cet outil de traitement identifie les classes de documents d'un ensemble de classes défini par l'utilisateur. Vous pouvez ensuite utiliser cet outil de traitement entraîné dans des documents de production. En règle générale, vous utilisez un séparateur personnalisé sur des fichiers composés de différents types de documents logiques, puis vous utilisez l'identification de classe de chacun pour transmettre les documents à un processeur d'extraction approprié afin d'extraire les entités.
Comme les modèles de ML ne sont pas parfaits et présentent un certain taux d'erreur, et que les erreurs de division sont généralement très problématiques (une division incorrecte rend deux documents incorrects et provoque des erreurs d'extraction), une bonne pratique consiste à toujours avoir une étape de révision humaine après la prédiction de division, mais avant la division réelle du fichier. En fonction des exigences métier, il existe des alternatives à la révision humaine systématique :
- Utilisez les scores de confiance dans la prédiction pour décider de contourner la révision humaine (si suffisamment élevé). Ce seuil de score de confiance doit être déterminé en fonction des données historiques relatives aux taux d'erreur pour des scores de confiance donnés. Il doit s'agir d'une décision commerciale basée sur la tolérance du processus métier aux erreurs et sur l'exigence de contournement d'une révision humaine.
- Dans certains cas d'utilisation, les documents fractionnés peuvent être acheminés directement vers l'extracteur approprié en fonction de la classe prédite. Ensuite, si l'extraction est incomplète ou présente des scores de confiance faibles, isolez les documents fractionnés et déclenchez l'examen du document composite d'origine et de la décision de division. Le workflow implique des exigences assez complexes.
Créer un séparateur personnalisé dans la console Google Cloud
Ce guide de démarrage rapide explique comment utiliser Document AI pour créer et entraîner un séparateur personnalisé qui divise et classe les documents d'approvisionnement. La majeure partie de la préparation du document est terminée, ce qui vous permet de vous concentrer sur la création d'un séparateur personnalisé.
Voici un workflow type pour créer et utiliser un séparateur personnalisé :
- Créez un séparateur personnalisé dans Document AI.
- Créez un ensemble de données à l'aide d'un bucket Cloud Storage vide.
- Définissez et créez le schéma de l'outil de traitement (classes).
- Importez des documents.
- Attribuez des documents aux ensembles d'entraînement et de test.
- Annotez les documents manuellement dans Document AI Workbench ou avec des tâches d'étiquetage.
- Entraînez l'outil de traitement.
- Évaluez l'outil de traitement.
- Déployez l'outil de traitement.
- Testez l'outil de traitement.
- Utilisez l'outil de traitement dans vos documents.
Si vos documents se trouvent dans des dossiers distincts par classe, vous pouvez ignorer l'étape 6 en spécifiant la classe au moment de l'importation.
Pour obtenir des instructions détaillées sur cette tâche directement dans la console Google Cloud , cliquez sur Visite guidée :
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Dans la console Google Cloud , accédez à la page Workbench de la section Document AI.
Dans le champ Outil de séparation de documents personnalisé, sélectionnez
Créer un outil de traitement .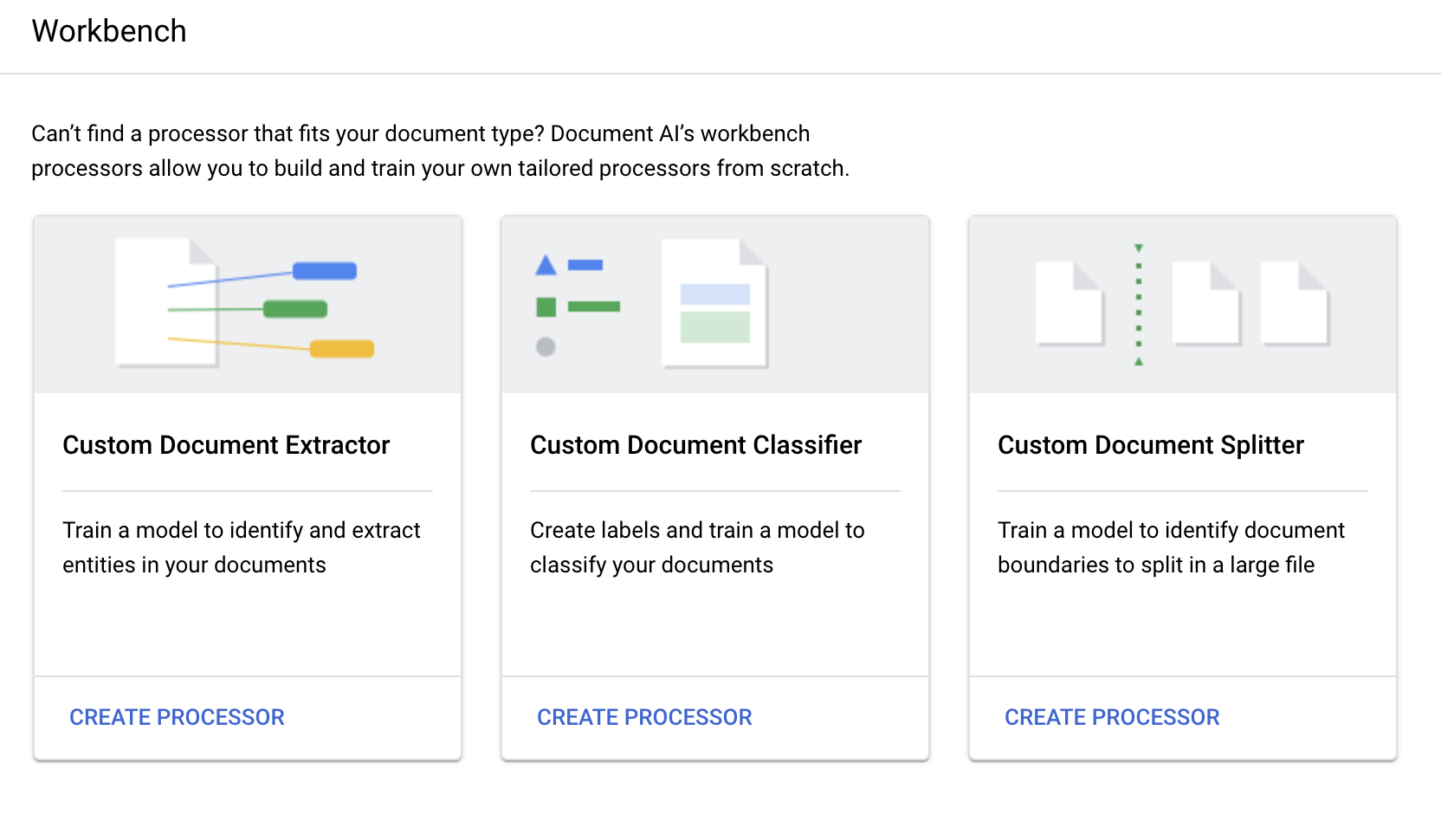
Dans le menu Créer un outil de traitement, saisissez le nom de votre outil de traitement (par exemple,
my-custom-document-splitter).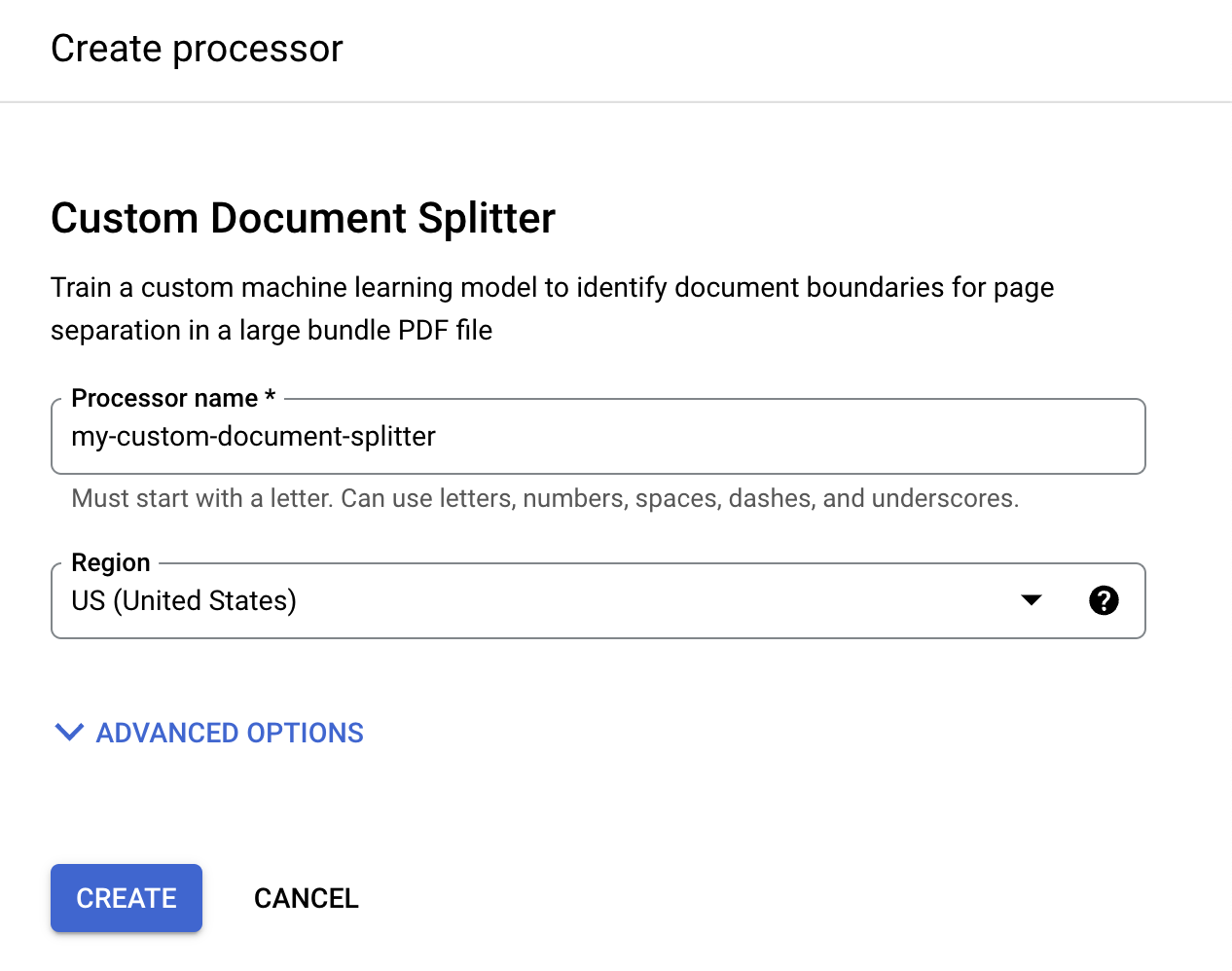
Sélectionnez la région la plus proche de vous.
Sélectionnez Créer. L'onglet Détails de l'outil de traitement s'affiche.
- Sélectionnez cette option si vous souhaitez utiliser l'espace de stockage géré par Google.
- Si vous souhaitez utiliser votre propre espace de stockage afin d'utiliser des clés de chiffrement gérées par le client (CMEK), sélectionnez Je spécifierai mon propre emplacement de stockage et suivez la procédure suivante.
Accédez à l'onglet
Entraînement de votre outil de traitement.Sélectionnez Définir l'emplacement de l'ensemble de données. Vous êtes alors invité à sélectionner ou à créer un bucket ou un dossier Cloud Storage vide.
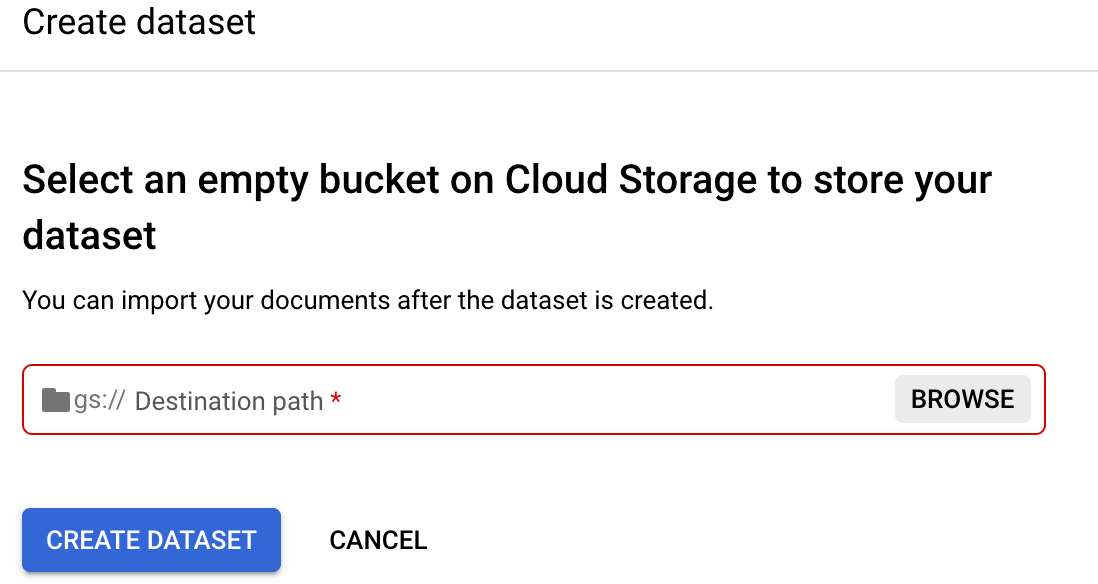
Cliquez sur Parcourir pour ouvrir l'option Sélectionner un dossier.
Cliquez sur l'icône Créer un bucket, puis suivez les instructions pour créer un bucket. Une fois le bucket créé, la page Sélectionner un dossier s'affiche. Pour en savoir plus sur la création d'un bucket Cloud Storage, consultez la page Buckets Cloud Storage.
Sur la page Sélectionner un dossier de votre bucket, cliquez sur le bouton Sélectionner en bas de la boîte de dialogue.
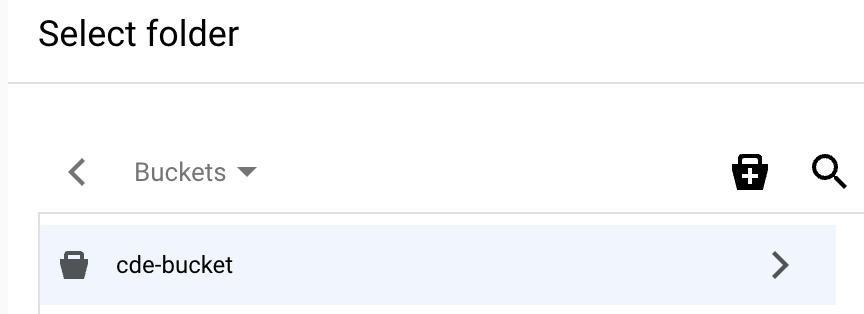
Dans l'onglet Entraînement, sélectionnez
Modifier le schéma en bas à gauche. La page Gérer les étiquettes s'ouvre.Sélectionnez
Créer un libellé .Saisissez le nom de l'étiquette. Sélectionnez Créer. Consultez la section Définir le schéma de l'outil de traitement pour obtenir des instructions détaillées sur la création et la modification d'un schéma.
Créez chacune des étiquettes suivantes pour le schéma de l'outil de traitement.
bank_statementform_1040form_w2form_w9paystub
Sélectionnez
Enregistrer lorsque vos étiquettes sont créées.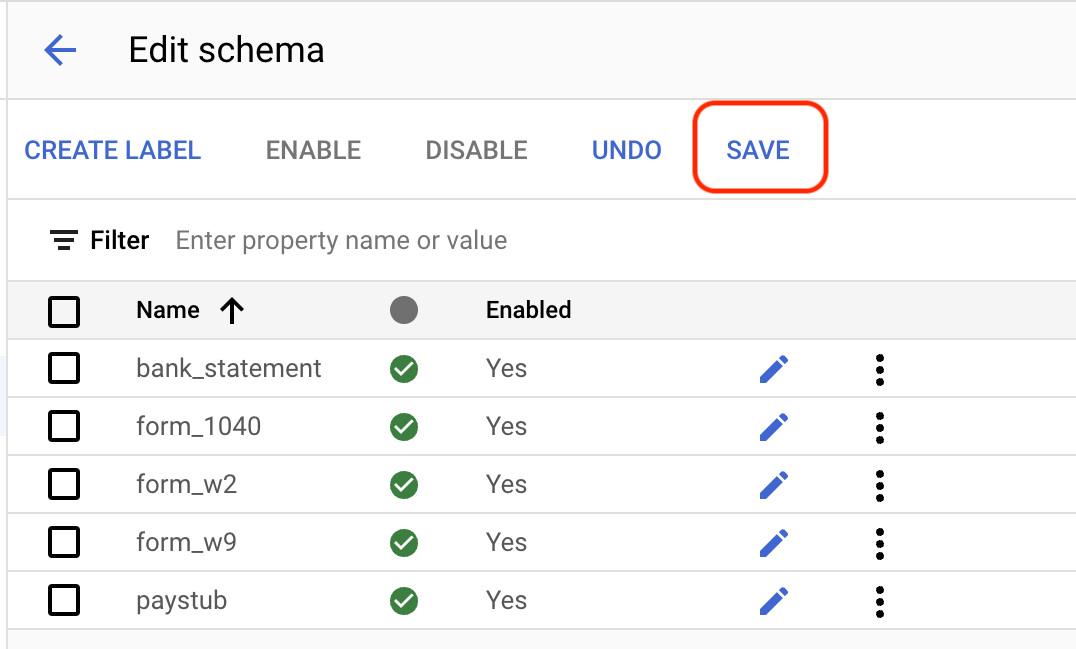
Dans l'onglet Entraînement, sélectionnez
Importer des documents .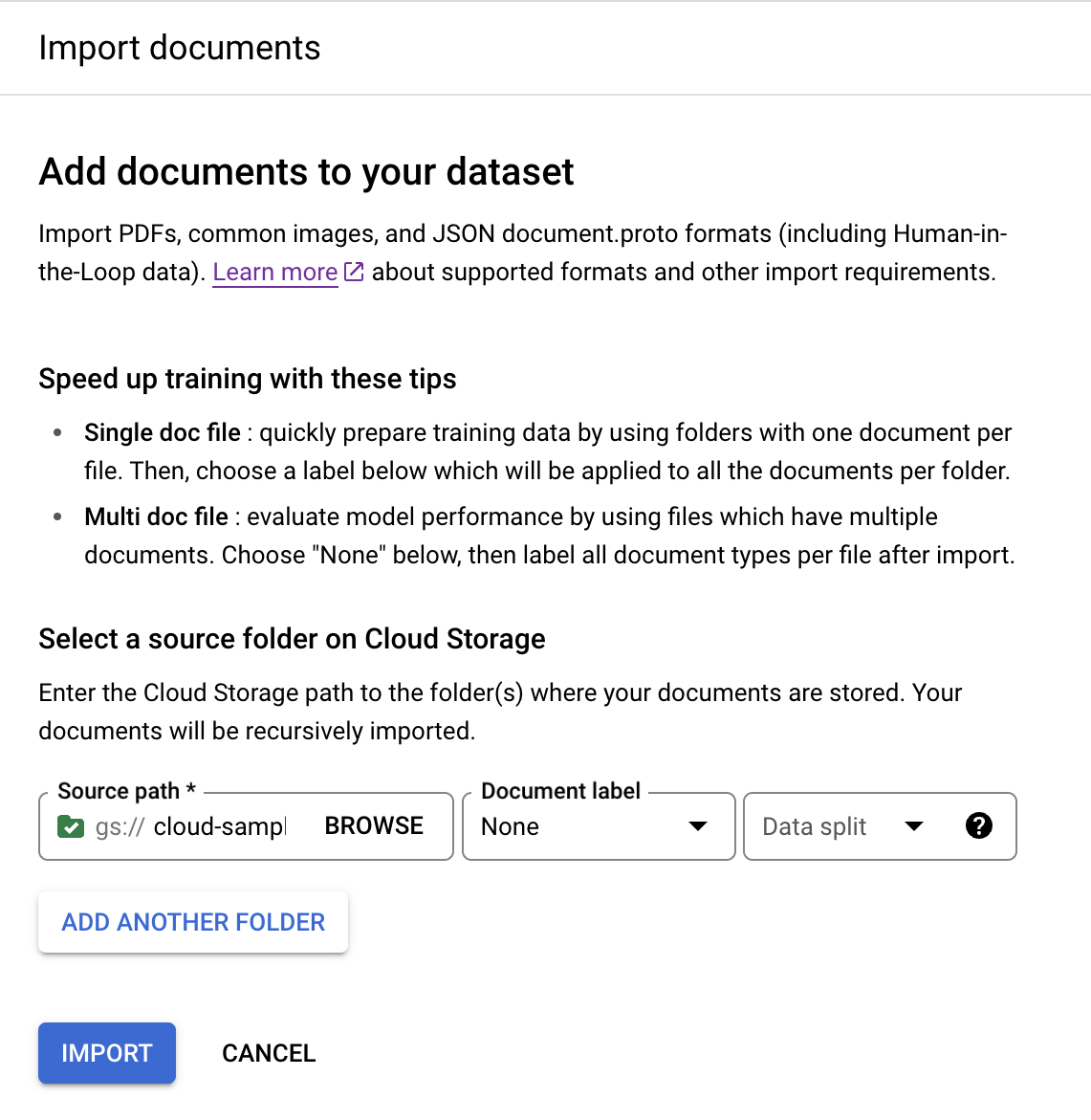
Pour cet exemple, saisissez ce chemin dans
Chemin source . Il contient un document PDF.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-UnlabeledDéfinissez l'option
Étiquette du document sur Aucune.Définissez le menu déroulant
Répartition des ensembles de données sur Non attribuée.Le document de ce dossier ne recevra pas d'étiquette et il ne sera attribué ni à l'ensemble de test, ni à l'ensemble d'entraînement par défaut.
Sélectionnez
Importer . Document AI lit les documents du bucket dans l'ensemble de données. Il ne modifie pas le bucket d'importation et ne lit pas ses données une fois l'importation terminée.- Cliquez sur Importer des documents.
Saisissez le chemin suivant dans Chemin source. Ce bucket contient des documents sans étiquettes au format PDF.
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabelDans la liste Répartition des données, sélectionnez Répartition automatique. Les documents sont automatiquement répartis de la manière suivante : 80 % dans l'ensemble d'entraînement et 20 % dans l'ensemble de test.
Dans la section Appliquer des étiquettes, sélectionnez Sélectionner une étiquette.
Pour ces exemples de documents, sélectionnez "Autre".
Cliquez sur Importer et attendez que les documents soient importés. Vous pouvez quitter cette page et y revenir plus tard.
Revenez à l'onglet Entraînement, puis sélectionnez
un document pour ouvrir la console Gestion des étiquettes.Ce document contient plusieurs groupes de pages qui doivent être identifiés et étiquetés. Tout d'abord, vous devez identifier les points de division. Déplacez la souris entre les pages 1 et 2 dans la vue de l'image, puis sélectionnez le symbole
+ .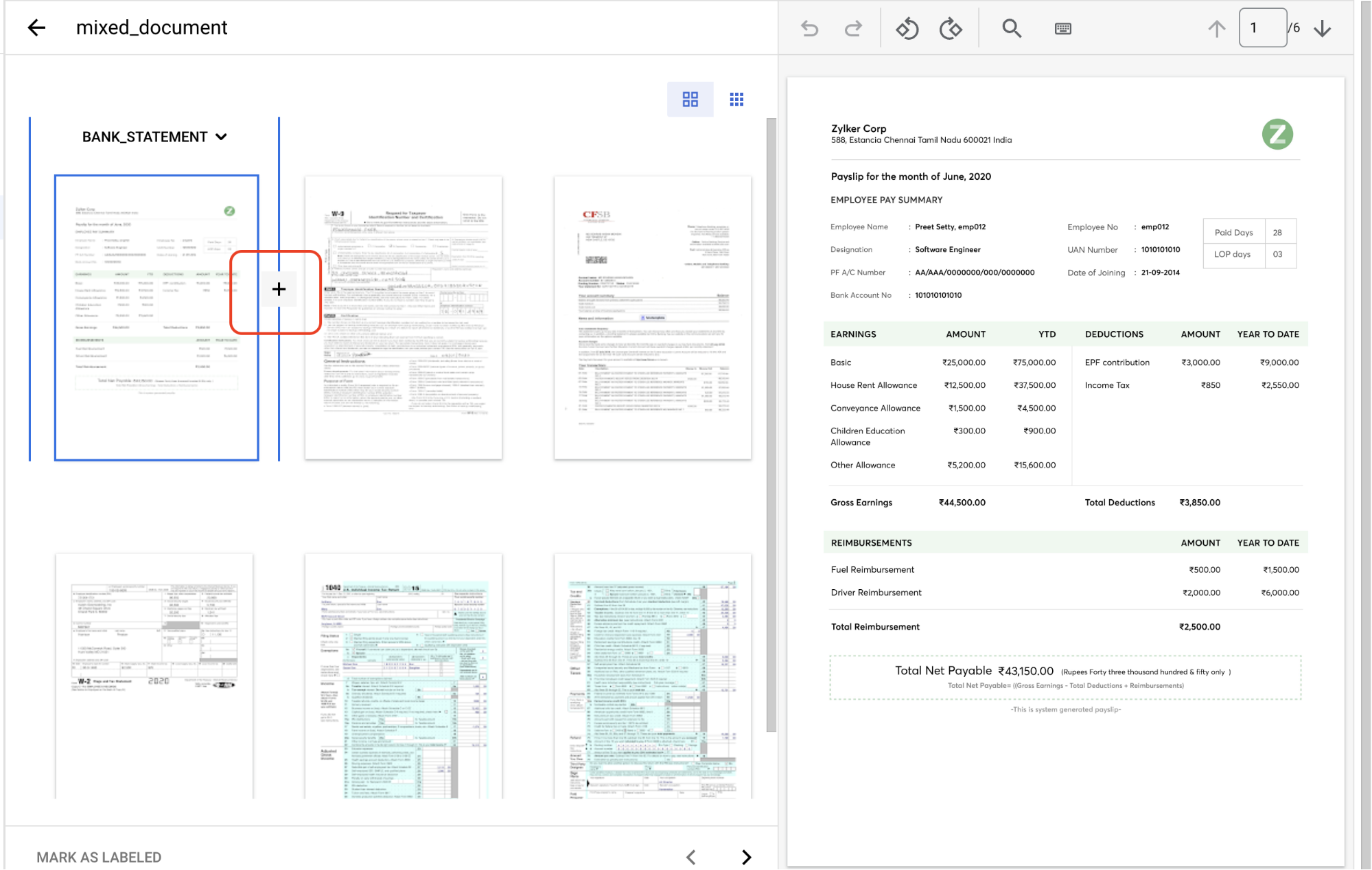
Créez des points de division avant les numéros de page suivants : 2, 3, 4 ou 5.
Une fois l'opération terminée, votre console doit ressembler à ceci.
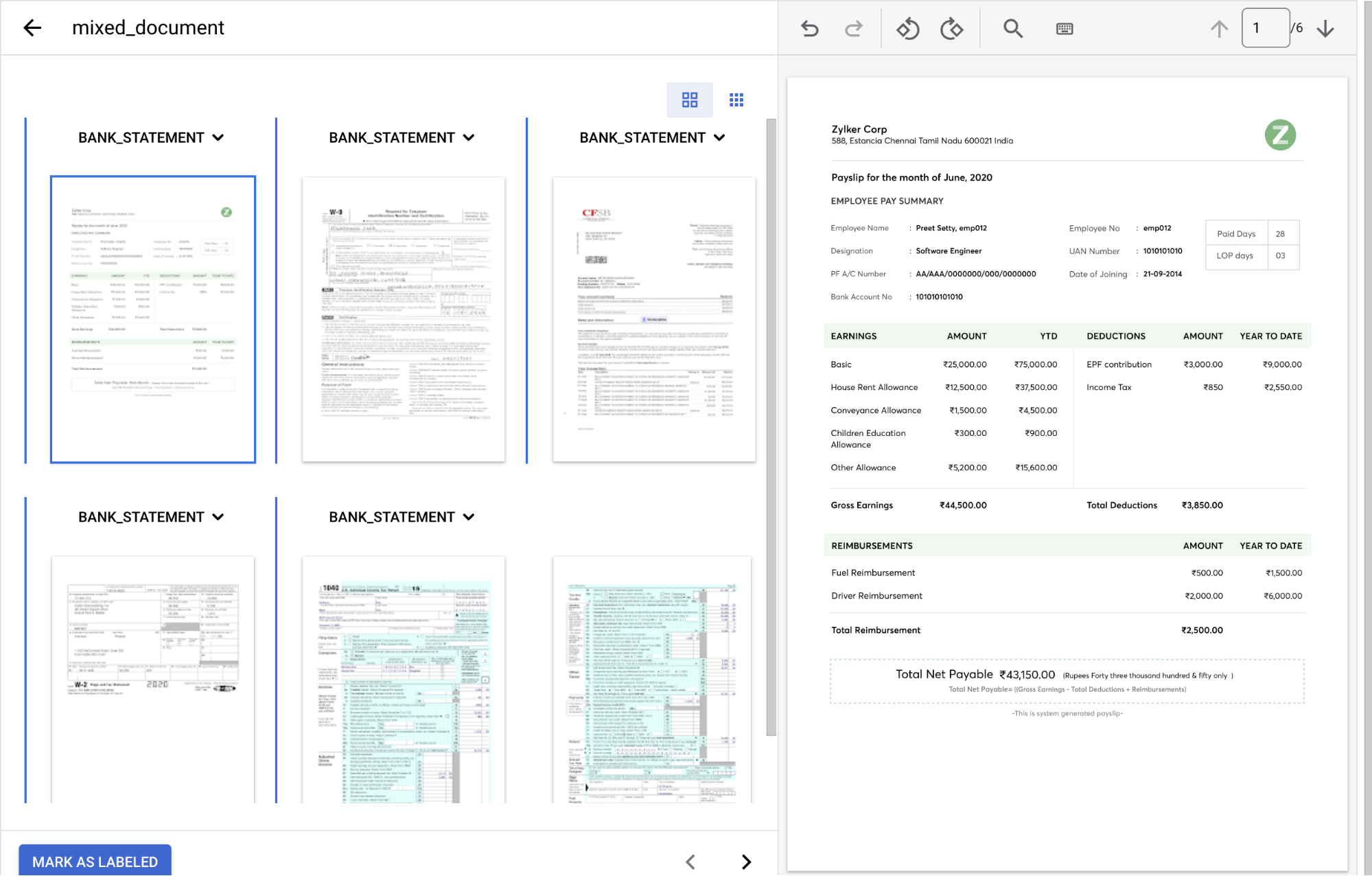
Dans le menu déroulant
Type de document , sélectionnez l'étiquette appropriée pour chaque groupe de pages.Page(s) Type de document 1 paystub2 form_w93 bank_statement4 form_w25 et 6 form_1040Une fois l'opération terminée, le document étiqueté devrait ressembler à ceci :
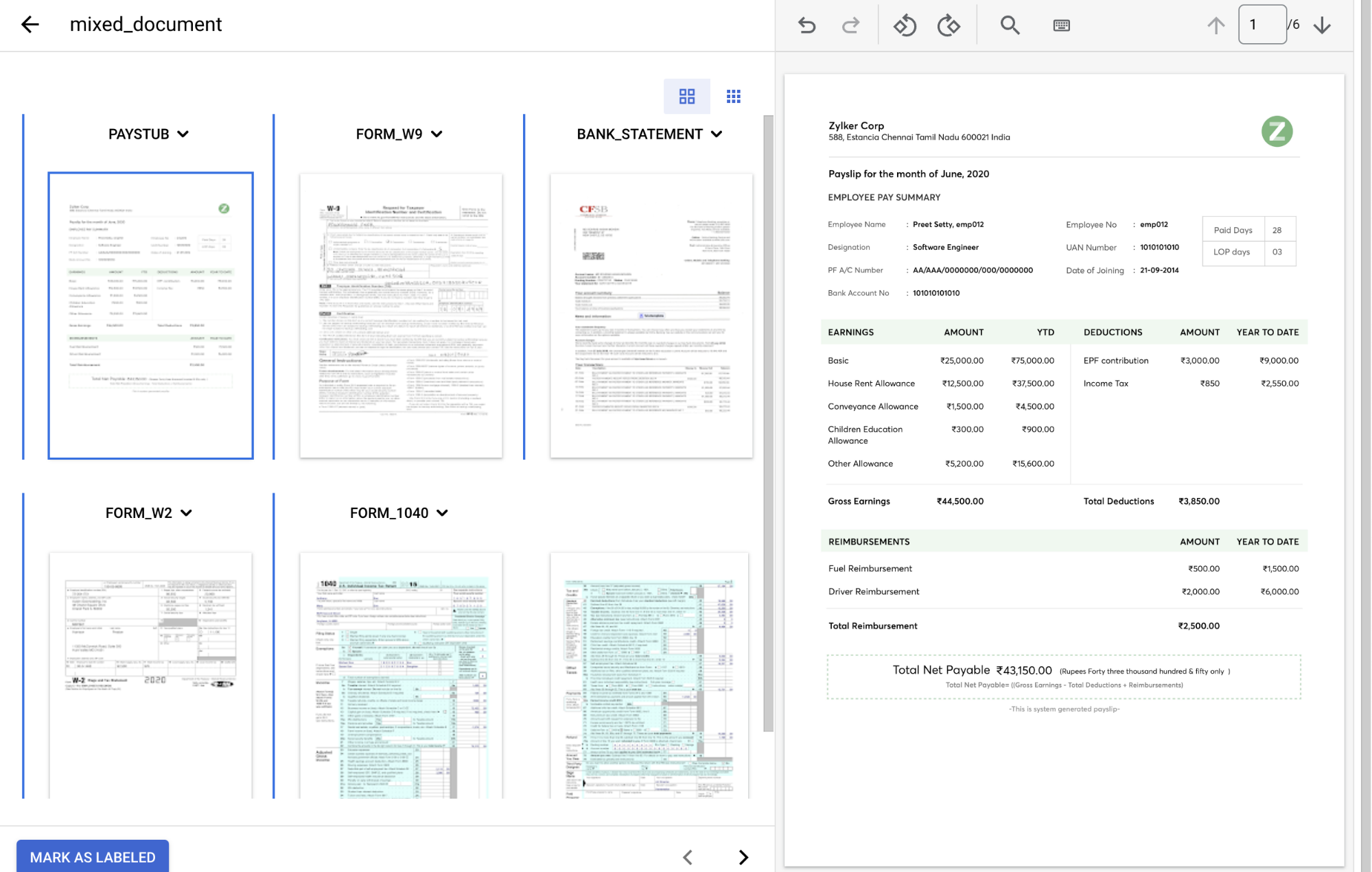
Sélectionnez
Marquer comme étiqueté lorsque vous avez terminé d'annoter le document.Dans l'onglet Entraînement, le panneau de gauche indique qu'un document a été étiqueté.
Dans l'onglet Entraînement, cochez la case
Sélectionner tout .Dans la liste
Attribuer à un ensemble , sélectionnez Entraînement.Dans l'onglet Entraînement, sélectionnez
Importer des documents .Saisissez le chemin suivant dans
Chemin source . Ce dossier contient des relevés bancaires au format PDF.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/bank-statementDéfinissez l'
étiquette du document surbank_statement.Dans le menu
Répartition de l'ensemble de données , sélectionnez Répartition automatique. Les documents sont automatiquement répartis de la manière suivante : 80 % dans l'ensemble d'entraînement et 20 % dans l'ensemble de test.Sélectionnez
Ajouter un autre dossier pour ajouter d'autres dossiers.Répétez les étapes précédentes avec les chemins d'accès et les étiquettes de document suivants :
Chemin d'accès au bucket Étiquette de document cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/1040form_1040cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w2form_w2cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w9form_w9cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/paystubpaystubUne fois l'opération terminée, la console doit ressembler à ceci :
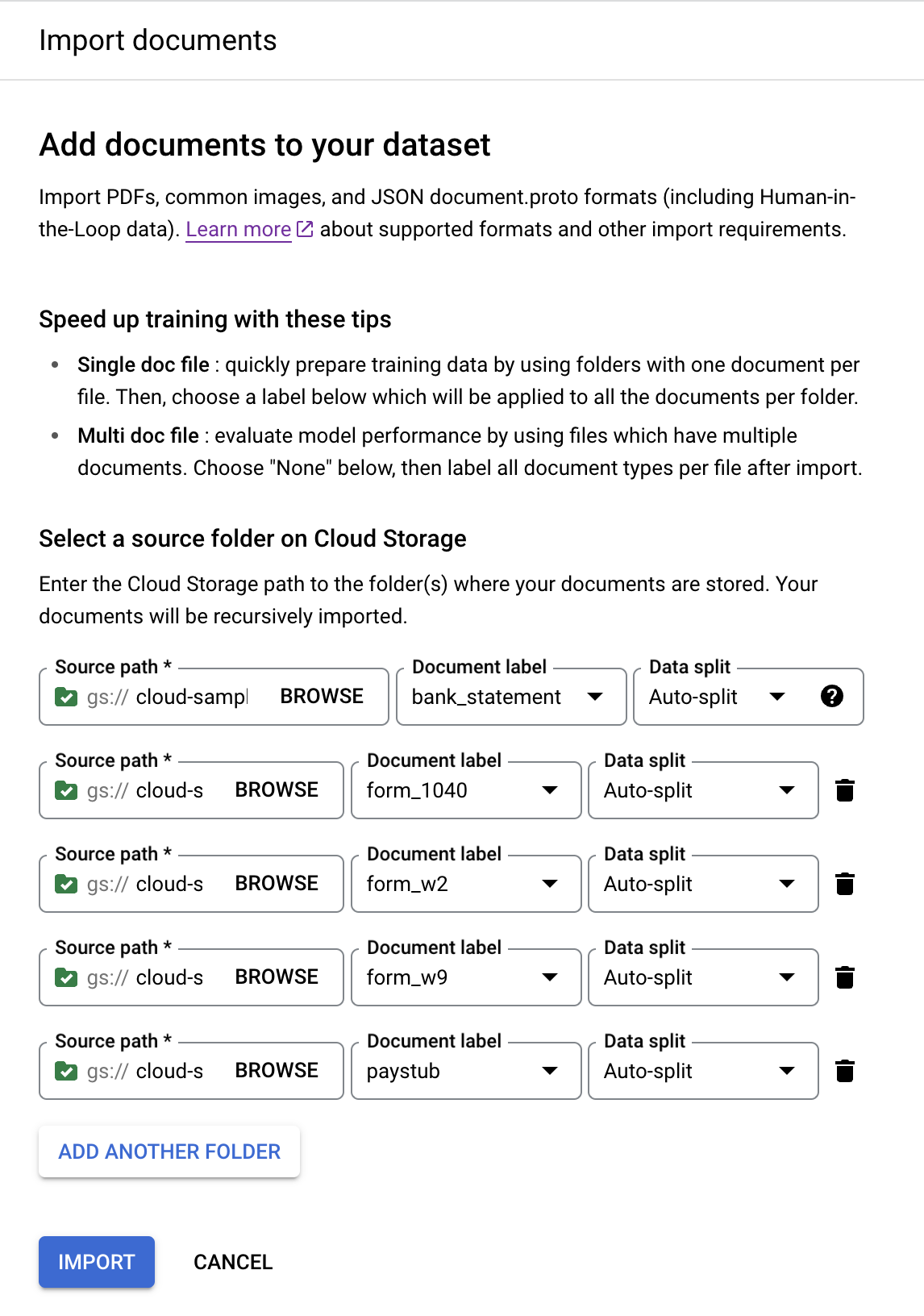
Sélectionnez
Importer . L'importation prend plusieurs minutes.Dans l'onglet Entraînement, sélectionnez
Importer des documents .Saisissez le chemin suivant dans
Chemin source .cloud-samples-data/documentai/Custom/Lending-Splitter/JSON-LabeledDéfinissez l'option
Étiquette du document sur Aucune.Dans le menu déroulant
Répartition des ensembles de données , sélectionnez Répartition automatique.Sélectionnez
Importer .Sélectionnez
Entraîner une nouvelle version .Dans le champ
Nom de la version , saisissez un nom pour cette version de l'outil de traitement (par exemple,my-cds-version-1).(Facultatif) Sélectionnez Afficher les statistiques relatives aux étiquettes pour afficher les informations sur les étiquettes des documents. Cela peut vous aider à déterminer votre couverture. Sélectionnez Fermer pour revenir à la configuration de l'entraînement.
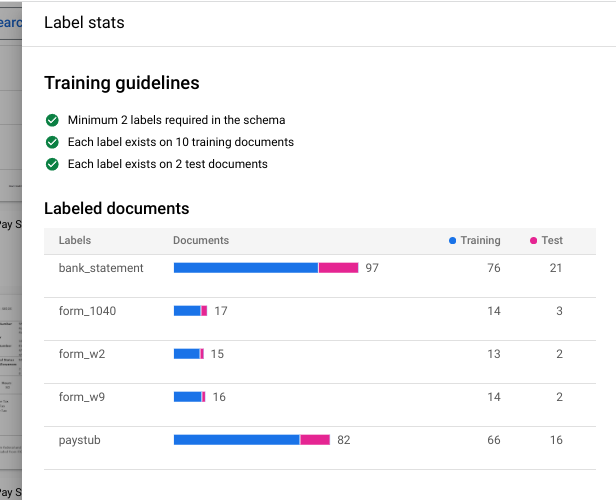
Sélectionnez
Démarrer l'entraînement . Vous pouvez vérifier son état dans le panneau de droite.Une fois l'entraînement terminé, accédez à l'onglet
Gérer les versions . Vous pouvez consulter les détails de la version que vous venez d'entraîner.Sélectionnez les
trois points verticaux à droite de la version que vous souhaitez déployer, puis sélectionnez Déployer la version.Sélectionnez
Déployer dans la fenêtre pop-up.Le déploiement prend quelques minutes.
Une fois le déploiement terminé, accédez à l'onglet
Évaluer et tester .Sur cette page, vous pouvez consulter les métriques d'évaluation, y compris le score F1, la précision et le rappel pour le document complet, ainsi que des étiquettes individuelles. Pour en savoir plus sur l'évaluation et les statistiques, consultez la page Évaluer l'outil de traitement.
Téléchargez un document qui n'a pas été utilisé pour l'entraînement ou les tests précédents afin de pouvoir l'utiliser pour évaluer la version de l'outil de traitement. Si vous utilisez vos propres données, vous devez vous servir d'un document réservé à cette fin.
Sélectionnez
Importer le document de test , puis sélectionnez le document que vous venez de télécharger.La page Analyse personnalisée s'ouvre. La sortie de l'écran montre comment le document a été scindé et classé.
Une fois l'opération terminée, la console doit ressembler à ceci :
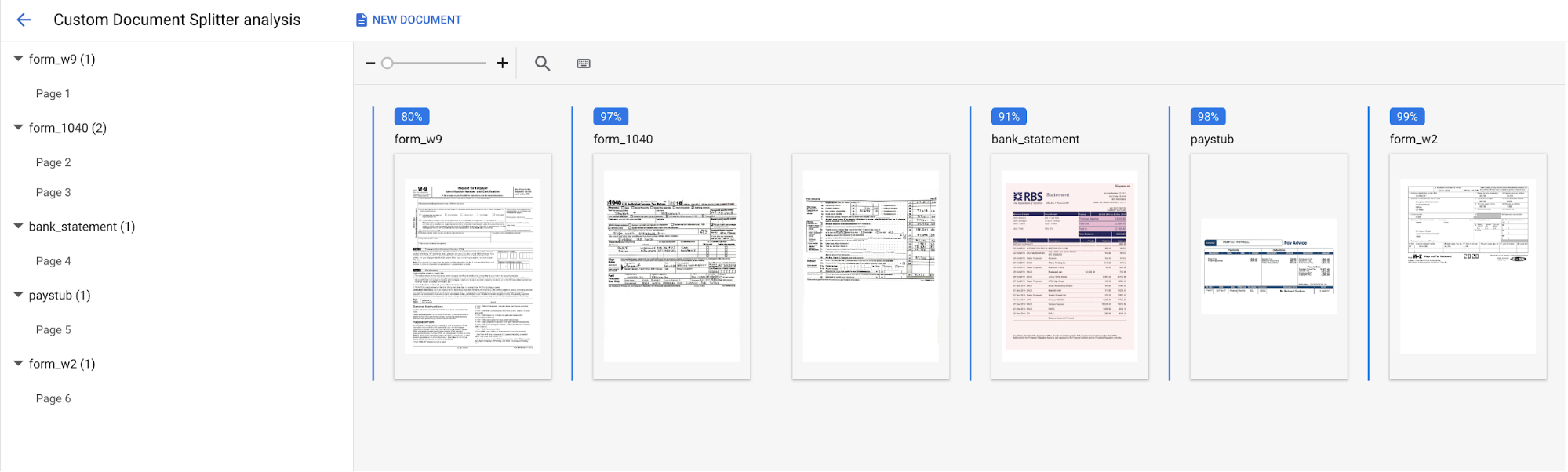
Vous pouvez également réexécuter l'évaluation sur un autre ensemble de test ou une autre version de l'outil de traitement.
Dans l'onglet Entraînement, sélectionnez
Importer des documents .Saisissez le chemin suivant dans
Chemin source . Ce dossier contient des PDF sans étiquette de plusieurs types de documents.cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-AutoLabelDéfinissez l'option
Étiquette du document sur Étiqueter automatiquement.Dans le menu déroulant
Répartition des ensembles de données , sélectionnez Répartition automatique.Dans la section Étiquetage automatique, définissez
Version comme la version que vous avez précédemment entraînée.- Par exemple :
2af620b2fd4d1fcf
- Par exemple :
Sélectionnez
Importer et attendez que les documents soient importés.Vous ne pouvez pas utiliser de documents étiquetés automatiquement pour l'entraînement ou les tests sans les marquer comme étiquetés. Accédez à la section
Étiquette automatique pour afficher les documents étiquetés automatiquement.Sélectionnez le premier document pour accéder à la console d'étiquetage.
Vérifiez que l'étiquetage est correct, puis ajustez-le si ce n'est pas le cas.
Lorsque vous avez terminé, sélectionnez
Marquer comme étiqueté .Répétez la validation des étiquettes pour chaque document étiqueté automatiquement.
Revenez à la page Entraînement et sélectionnez Entraîner une nouvelle version pour utiliser les données d'entraînement.
Dans le menu de navigation de la console Google Cloud , sélectionnez Document AI, puis Mes processeurs.
Sur la ligne correspondant à l'outil de traitement que vous souhaitez supprimer, sélectionnez
Autres actions .Sélectionnez Supprimer le processeur, saisissez son nom, puis sélectionnez à nouveau Supprimer pour confirmer.
Créer un outil de traitement
Configurer l'ensemble de données
Pour entraîner ce nouvel outil de traitement, vous devez créer un ensemble de données contenant des données d'entraînement et de test afin de l'aider à identifier les documents que vous souhaitez scinder et classer.
Cet ensemble de données nécessite un nouvel emplacement. Il peut s'agir d'un bucket ou dossier Cloud Storage vide, ou vous pouvez autoriser un emplacement (interne) géré par Google.

Créer un bucket Cloud Storage pour l'ensemble de données
Assurez-vous que le chemin de destination est renseigné avec le nom du bucket que vous avez sélectionné. Sélectionnez Create Dataset (Créer un ensemble de données). Cette opération peut prendre plusieurs minutes.
Définir le schéma de l'outil de traitement
Vous pouvez créer le schéma de l'outil de traitement avant ou après l'importation de documents dans votre ensemble de données. Le schéma fournit des étiquettes que vous utilisez pour annoter les documents.
Importer un document sans étiquette dans un ensemble de données
L'étape suivante consiste à commencer à importer des documents sans étiquette dans votre ensemble de données et à les étiqueter. Une alternative recommandée consiste à importer des documents organisés dans des dossiers par classe, le cas échéant.
Si vous travaillez sur votre propre projet, vous déterminez comment étiqueter vos données. Consultez la section Options d'étiquetage.
Les processeurs personnalisés de Document AI nécessitent au moins 10 documents dans les ensembles d'entraînement et de test, ainsi que 10 instances de chaque étiquette dans chaque ensemble. Pour des performances optimales, nous vous recommandons d'avoir au moins 50 documents dans chaque ensemble, avec 50 instances de chaque étiquette. En général, plus la quantité de données d'entraînement est importante, plus la justesse est élevée.
Lorsque vous importez des documents, vous pouvez les attribuer aux ensembles d'entraînement ou de test définis lors de l'importation, ou attendre de les attribuer ultérieurement.
Si vous souhaitez supprimer un ou plusieurs documents que vous avez importés, sélectionnez-les dans l'onglet Entraînement, puis sélectionnez Supprimer.
Pour en savoir plus sur la préparation de vos données pour l'importation, consultez le guide de préparation des données.
Facultatif : Étiquetez plusieurs documents lors de l'importation
Vous pouvez étiqueter tous les documents d'un répertoire spécifique lors de l'importation pour gagner du temps. Si vos documents d'entraînement sont organisés par classe dans des dossiers, vous pouvez utiliser le champ Étiquette de document pour spécifier la classe de ces documents et éviter l'étiquetage manuel de chaque document.
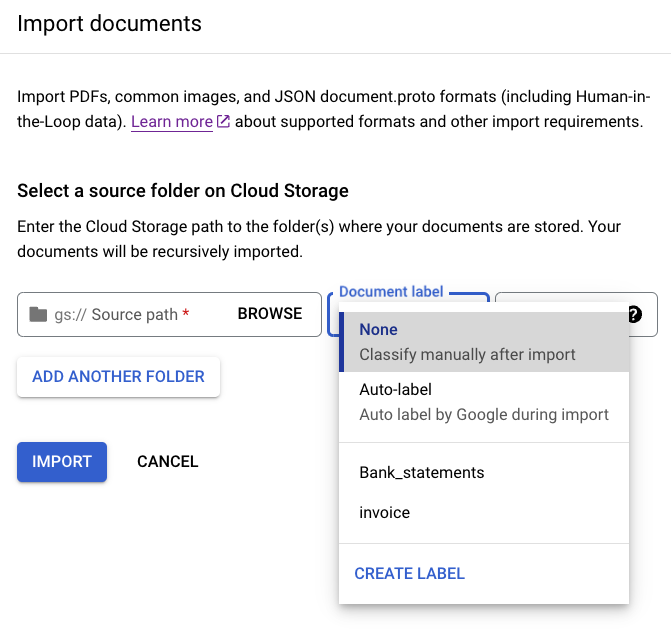
Dans l'image, Bank_statements et Invoice comportent des étiquettes définies (classes de documents) que vous pouvez sélectionner. Vous pouvez également utiliser CREATE LABEL et définir une nouvelle classe.
Ajouter une étiquette à un document
Le processus d'application des étiquettes à un document est appelé annotation.
Attribuer un document annoté à l'ensemble d'entraînement
Maintenant que vous avez étiqueté cet exemple de document, vous pouvez l'attribuer à l'ensemble d'entraînement.
Dans le panneau de gauche, vous pouvez voir qu'un document a été attribué à l'ensemble d'entraînement.
Importer des données avec l'étiquetage par lot
Vous importez ensuite des fichiers PDF sans étiquette, qui sont triés dans différents dossiers Cloud Storage selon leur type. L'étiquetage groupé permet de gagner du temps en attribuant un libellé au moment de l'importation en fonction du chemin d'accès.
Une fois l'importation terminée, vous trouverez les documents dans l'onglet Entraînement.
Importer des données préalablement étiquetées
Ce guide contient des données préalablement étiquetées au format Document sous forme de fichiers JSON.
Il s'agit du format de sortie utilisé par Document AI pour le traitement d'un document, l'étiquetage avec intervention humaine ou l'exportation d'un ensemble de données.
Une fois l'importation terminée, vous trouverez les documents dans l'onglet Entraînement.
Entraîner l'outil de traitement
Maintenant que vous avez importé les données d'entraînement et de test, vous pouvez entraîner l'outil de traitement. Comme l'entraînement peut prendre plusieurs heures, assurez-vous d'avoir configuré l'outil de traitement avec les données et étiquettes appropriées avant de commencer l'entraînement.
Déployer la version de l'outil de traitement
Évaluer et tester l'outil de traitement
(Facultatif) Importer des données avec l'étiquetage automatique
Après avoir déployé une version de processeur entraînée, vous pouvez utiliser l'étiquetage automatique pour gagner du temps sur l'étiquetage lorsque vous importez de nouveaux documents.
Utiliser l'outil de traitement
Vous venez de créer et d'entraîner un outil de séparation personnalisé.
Vous pouvez gérer les versions de votre outil de traitement entraîné personnalisé comme n'importe quelle autre version. Pour en savoir plus, consultez Gérer les versions de l'outil de traitement.
Une fois le déploiement effectué, vous pouvez envoyer une requête de traitement à votre outil de traitement personnalisé. La réponse peut être traitée de la même manière que pour les autres outils de séparation.
Effectuer un nettoyage
Pour éviter que les ressources utilisées sur cette page soient facturées sur votre compte Google Cloud , procédez comme suit :
Pour éviter des frais Google Cloud inutiles, supprimez votre processeur et votre projet à l'aide deGoogle Cloud console si vous n'en avez plus besoin.
Si vous avez créé un projet pour apprendre à utiliser Document AI et que vous n'en avez plus besoin, supprimez-le.
Si vous avez utilisé un projet Google Cloud existant, supprimez les ressources que vous avez créées pour éviter que des frais ne soient facturés sur votre compte :