커스텀 문서 분류기 만들기, 사용, 관리
커스텀 분류기를 사용하여 문서를 분류합니다. 자체 문서와 커스텀 클래스를 사용하여 처음부터 빌드하세요. 생성형 AI 부분에서는 퓨샷 학습과 세부 조정이 가능합니다. 이를 통해 반복적인 자동 라벨 지정으로 샘플과 수정이 적어도 정확도가 향상됩니다.
맞춤 분류 기준은 이러한 세 가지 일반적인 사용 사례를 다룹니다.
- 사전 학습된 모델: 사전 학습된 생성형 AI 파운데이션 모델을 사용하여 제공된 라벨로 문서를 빠르게 분류합니다.
- 파인 튜닝: 자체 데이터와 라벨을 사용하여 생성형 AI 파운데이션 모델을 학습시켜 정확성을 개선합니다.
- 커스텀 모델 학습: 자체 데이터와 라벨을 사용하여 생성형 AI가 아닌 커스텀 추출기를 학습시킵니다.
커스텀 분류기 모델 버전
| 모델 버전 | 설명 | 출시 채널 | US/EU의 ML 처리 | US/EU의 세부 조정 | 출시일 |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-05-16 |
Gemini 2.0 Flash LLM을 기반으로 한 출시 후보입니다. 고급 OCR 기능도 포함되어 있습니다. | 출시 후보 | 예 | US, EU(프리뷰) | 2025년 5월 16일 |
pretrained-classifier-v1.5-2025-08-05 |
Gemini 2.5 Flash LLM을 기반으로 한 출시 후보입니다. 고급 OCR 기능도 포함되어 있습니다. | 출시 후보 | 예 | US, EU(프리뷰) | 2025년 8월 5일 |
맞춤 분류기 모델에는 신뢰도 점수가 지원되지 않습니다.
Google Cloud 콘솔에서 커스텀 분류기 만들기
문서에 특히 적합하고 데이터로 학습 및 평가되는 커스텀 분류기를 만들 수 있습니다. 이 프로세서는 사용자가 정의한 클래스 집합에서 문서 클래스를 식별합니다. 그런 다음 이 학습된 프로세서를 추가 문서에 사용할 수 있습니다. 일반적으로 다른 유형의 문서에서 커스텀 분류기를 사용한 다음 ID를 사용하여 문서를 추출 프로세서에 전달하여 항목을 추출합니다.
프로세서를 만들고 사용하는 일반적인 프로세스는 방법 섹션을 참고하세요.
워크플로에 적합한 고유 구성을 선택할 수 있습니다.
Google Cloud 콘솔에서 이 태스크에 대한 단계별 안내를 직접 수행하려면 둘러보기를 클릭합니다.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Workbench로 이동
커스텀 문서 분류기의 경우
프로세서 만들기 를 선택합니다.
프로세서 만들기 메뉴에서 프로세서 이름(예:
my-custom-document-classifier)을 입력합니다.
가장 가까운 리전을 선택합니다.
만들기를 선택합니다. 프로세서 세부정보 탭이 표시됩니다.
- Cloud Storage를 사용하려면 Google 관리형 스토리지를 선택합니다.
- 고객 관리 암호화 키(CMEK)를 사용하기 위해 자체 스토리지를 사용하려면 직접 자체 스토리지 위치 지정을 선택하고 데이터 세트 만들기의 절차를 따릅니다.
빌드 탭에서
문서 가져오기 를 선택합니다.
스토리지 버킷을 사용하려면 버킷의 소스 경로를 입력해야 합니다. 이 학습 예시에서는
소스 경로 에 이 버킷 이름을 입력합니다. 문서 하나에 직접 연결됩니다.cloud-samples-data/documentai/Custom/Patents/PDF/computer_vision_20.pdf데이터 분할로 할당되지 않음을 선택합니다. 이 폴더의 문서는 테스트 또는 학습 세트에 할당되지 않습니다. 자동 라벨링을 사용하여 가져오기는 선택하지 않은 상태로 둡니다.
가져오기를 선택합니다. Document AI는 문서를 버킷에서 데이터 세트로 읽습니다. 가져오기가 완료된 후에는 가져오기 버킷을 수정하거나 버킷에서 데이터를 읽지 않습니다.
선택사항: 가져온 문서를 삭제하려면 빌드 탭에서 데이터 세트 관리로 이동하여 문서를 선택하고 삭제를 클릭합니다.
빌드 탭에서 데이터 세트 관리 > 스키마 수정을 선택합니다. 스키마 수정 페이지가 열립니다.
라벨 만들기 를 선택합니다.라벨 이름을 입력합니다.
만들기를 선택합니다. 스키마 생성 및 수정에 관한 자세한 안내는 프로세서 스키마 정의를 참고하세요.
프로세서 스키마에 대한 다음과 같은 각 라벨을 만듭니다.
computer_visioncryptomed_techother
라벨이 완료되면
저장 을 선택합니다.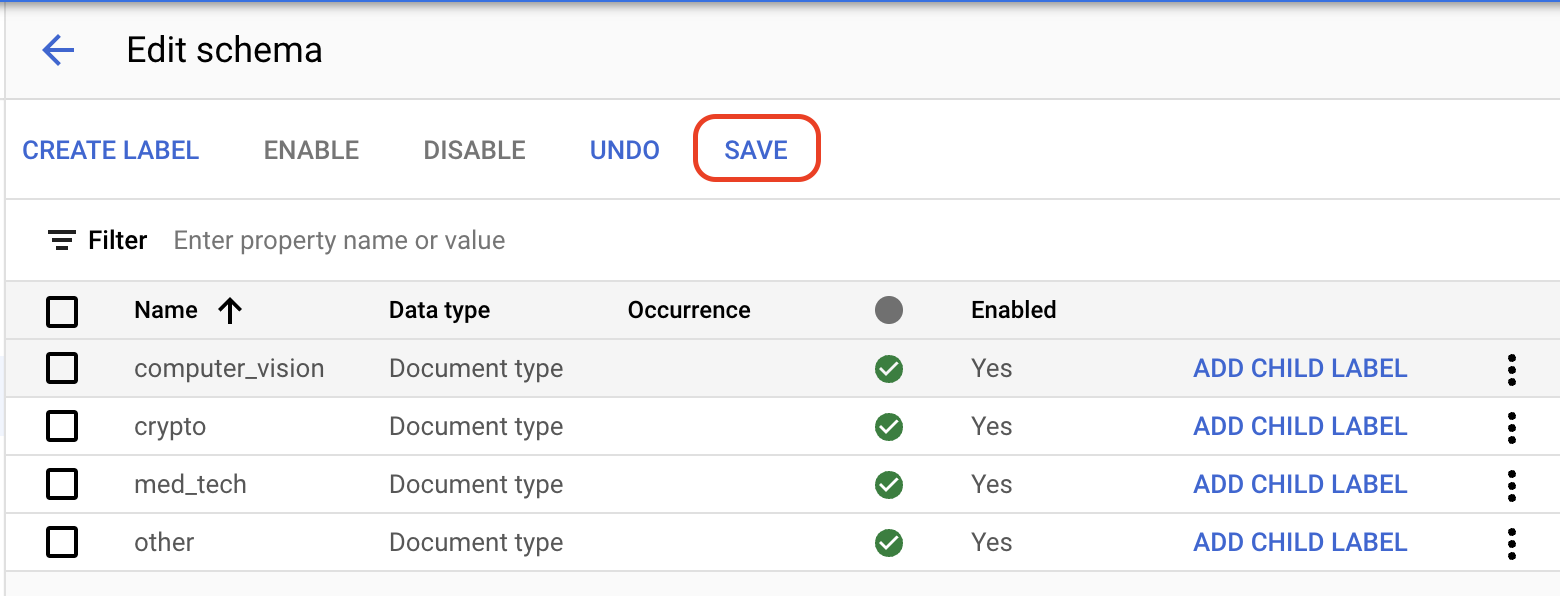
빌드 탭으로 돌아가서
문서 를 선택하여 데이터 세트 관리 콘솔을 엽니다.옵션 중에서 문서에 적합한 라벨을 선택합니다. 제공된 샘플 문서를 사용하는 경우computer_vision을 선택합니다.라벨이 지정되면 문서가 다음과 같이 표시됩니다.
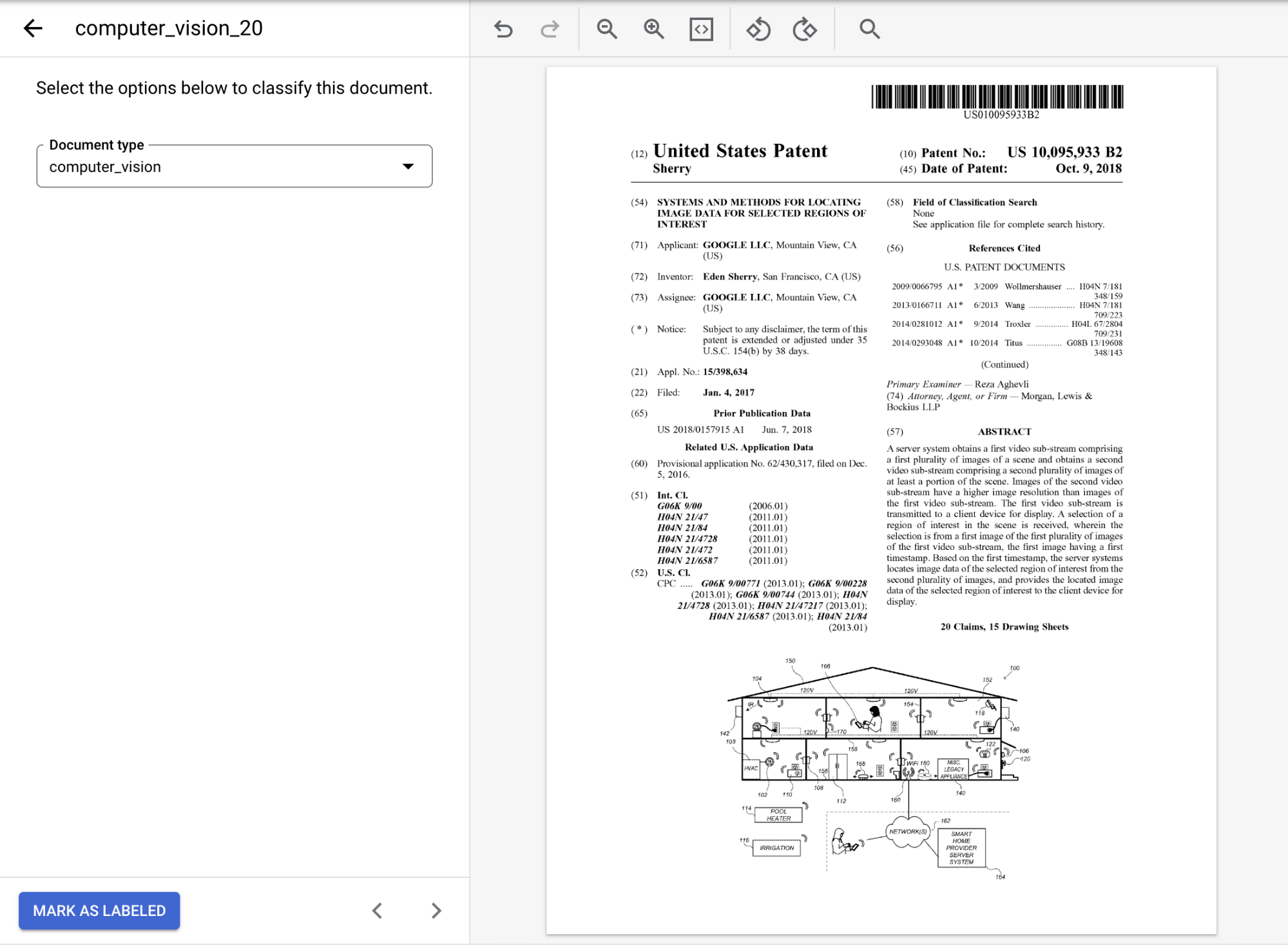
문서에 주석을 달았으면
라벨이 지정된 것으로 표시 를 선택합니다.데이터 세트 관리 탭의 문서 패널에 문서 1개에 라벨이 지정되었다고 표시됩니다.
데이터 세트 관리 탭에서
모두 선택 체크박스를 선택합니다.세트에 할당 목록에서 학습을 선택합니다.문서 가져오기 를 선택합니다.소스 경로 에 다음 경로를 입력합니다. 이 버킷에는 문서 JSON 형식으로 라벨이 미리 지정된 문서가 포함되어 있습니다.cloud-samples-data/documentai/Custom/Patents/JSON/Classification-InventionType데이터 분할 목록에서 자동 분할을 선택합니다. 이렇게 하면 문서가 학습 세트에서는 80%, 테스트 세트에서는 20%로 자동 분할됩니다. 라벨 적용 섹션은 무시합니다.
가져오기를 선택합니다. 가져오기를 완료하는 데 몇 분 정도 걸릴 수 있습니다.
문서 가져오기 를 선택합니다.소스 경로 에 다음 경로를 입력합니다. 이 버킷에는 라벨이 지정되지 않은 PDF 형식의 문서가 포함되어 있습니다.cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabel데이터 분할 목록에서 자동 분할을 선택합니다. 이렇게 하면 문서가 학습 세트에서는 80%, 테스트 세트에서는 20%로 자동 분할됩니다.
라벨 적용 섹션에서 라벨 선택을 선택합니다.
이 샘플 문서의 경우
other를 선택합니다.가져오기를 선택하고 프로세스가 완료될 때까지 기다립니다. 이 페이지를 나갔다가 다시 돌아와도 됩니다. 완료되면 데이터 세트 관리 탭에서 라벨이 적용된 문서를 찾습니다.
새 버전 학습 을 선택합니다.버전 이름 필드에 이 프로세서 버전의 이름(예:my-cdc-version-1)을 입력합니다.선택사항: 라벨 통계 보기를 선택하여 범위를 결정하는 데 도움이 되는 문서 라벨에 대한 정보를 확인합니다. 닫기를 선택하여 학습 설정으로 돌아갑니다.
학습 시작 을 선택합니다. 측면 패널에서 상태를 확인할 수 있습니다.학습이 완료되면
버전 관리 탭으로 이동합니다. 방금 학습한 버전에 대한 세부정보를 볼 수 있습니다.배포할 버전 옆에 있는
을 선택하고 버전 배포를 선택합니다. 대화상자 창에서
배포 를 선택합니다.배포를 완료하는 데 몇 분 정도 걸립니다.
배포가 완료되면
평가 및 테스트 탭으로 이동합니다.이 페이지에서 F1 점수, 전체 문서의 정밀도 및 재현율, 개별 라벨을 포함한 평가 측정항목을 확인할 수 있습니다. 평가 및 통계에 관한 자세한 내용은 프로세서 평가를 참고하세요.
이전 학습 또는 테스트에 포함되지 않은 문서를 다운로드하여 프로세서 버전을 평가하는 데 사용할 수 있습니다. 자체 데이터를 사용하는 경우에는 이러한 목적을 위해 따로 보관된 문서를 사용하게 됩니다.
테스트 문서 업로드 를 선택하고 방금 다운로드한 문서를 선택합니다.커스텀 문서 분류기 분석 페이지가 열립니다. 출력은 문서가 얼마나 잘 분류되었는지를 보여줍니다.
다른 테스트 세트 또는 프로세서 버전을 대상으로 평가를 다시 실행할 수도 있습니다.
데이터 세트 관리 페이지에서
문서 가져오기 를 클릭합니다.다음 Cloud Storage 경로를 복사하여 붙여넣습니다. 이 디렉터리에는 라벨 지정이 되지 않은 특허 PDF가 5개 있습니다. 데이터 분할 드롭다운 목록에서 학습을 선택합니다.
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-AutoLabel라벨 적용 섹션에서 자동 라벨 지정을 선택합니다.
기존 프로세서 버전을 선택하여 문서에 라벨을 지정합니다.
- 예:
2af620b2fd4d1fcf
- 예:
가져오기를 선택하고 프로세스가 완료될 때까지 기다립니다. 이 페이지를 나갔다가 다시 돌아와도 됩니다. 완료되면 데이터 세트 관리 페이지의 자동 라벨 지정 섹션에 문서가 표시됩니다.
자동 라벨 지정 문서를 라벨 지정됨으로 표시하지 않고 학습 또는 테스트용으로 사용할 수는 없습니다. 자동 라벨 지정 문서를 보려면
자동 라벨 지정 섹션으로 이동하세요.첫 번째 문서를 선택하여 라벨 지정 콘솔로 이동합니다.
라벨이 올바른지 확인합니다. 잘못된 경우 조정합니다.
완료되면
라벨이 지정된 것으로 표시 를 선택합니다.자동으로 라벨이 지정된 각 문서에 대해 라벨 확인을 반복한 다음 데이터 세트 관리 페이지로 돌아가 학습에 데이터를 할당합니다.
Google Cloud 콘솔 탐색 메뉴에서 Document AI를 선택한 다음 내 프로세서를 선택합니다.
삭제하려는 프로세서와 동일한 행에서
작업 더보기 를 선택합니다.프로세서 삭제를 선택하고 프로세서 이름을 입력한 다음 삭제를 다시 선택하여 확인합니다.
- 자세한 내용은 가이드를 참고하세요.
- 프로세서 목록을 검토합니다.
- Layout Parser를 사용하여 문서를 읽을 수 있는 청크로 분리합니다.
- Enterprise Document OCR을 사용하여 텍스트를 감지하고 추출합니다.
프로세서 만들기
다음 단계를 완료합니다.
데이터 세트 구성
새 프로세서를 학습시키려면 학습 및 테스트 데이터로 데이터 세트를 만들어야 프로세서가 분할 및 분류할 문서를 식별할 수 있습니다. 이 데이터 세트에는 새 위치가 필요합니다. 이 위치는 빈 Cloud Storage 버킷 또는 폴더일 수도 있고 허용된 내부 관리 위치일 수도 있습니다.
프로세서 세부정보 탭이 나타나면 다음을 수행할 수 있습니다.

데이터 세트에 문서 가져오기
다음으로는 문서를 데이터 세트로 가져옵니다.
문서를 가져올 때 가져오기 시에 학습 또는 테스트 세트에 문서를 할당하거나 나중에 할당할 수 있습니다.
가져올 데이터를 준비하는 방법을 자세히 알아보려면 데이터 준비 가이드를 참고하세요.
프로세서 스키마 정의
문서를 데이터 세트로 가져오기 전이나 가져온 후에 프로세서 스키마를 만들 수 있습니다. 스키마는 문서에 주석을 추가하는 데 사용할 라벨을 제공합니다.
문서 라벨 지정
문서에서 텍스트를 선택하고 라벨을 적용하는 프로세스를 주석이라고 합니다.
학습 세트에 주석이 달린 문서 할당
이제 이 예시 문서에 라벨을 지정했으므로 이를 학습 세트에 할당할 수 있습니다.
문서 패널에 문서 1개가 학습 세트에 할당되었다고 표시됩니다.
사전에 라벨이 지정된 데이터를 학습 및 테스트 세트로 가져오기
이 가이드에서는 미리 라벨이 지정된 데이터가 제공됩니다. 자체 프로젝트를 진행하는 경우 데이터에 라벨을 지정하는 방법을 결정해야 합니다. 라벨 지정 옵션을 참고하세요.
Document AI 커스텀 프로세서에는 라벨이 지정될 각 문서 유형의 학습 세트와 테스트 세트에 최소 하나의 문서가 필요합니다. 최상의 성능을 위해서는 라벨당 문서가 10개 이상인 것이 좋습니다. 라벨이 5개인 경우 학습용 문서 50개와 테스트용 문서 50개가 필요합니다. 일반적으로 학습 데이터가 많을수록 정확성이 높아집니다.
가져오기가 완료되면 데이터 세트 관리 탭에 문서가 표시됩니다.
가져오기 시 문서 라벨 일괄 지정
원하는 경우 스키마를 구성한 후 가져오기 시 특정 디렉터리에 있는 모든 문서에 라벨을 지정하여 라벨 지정 시간을 절약할 수 있습니다.
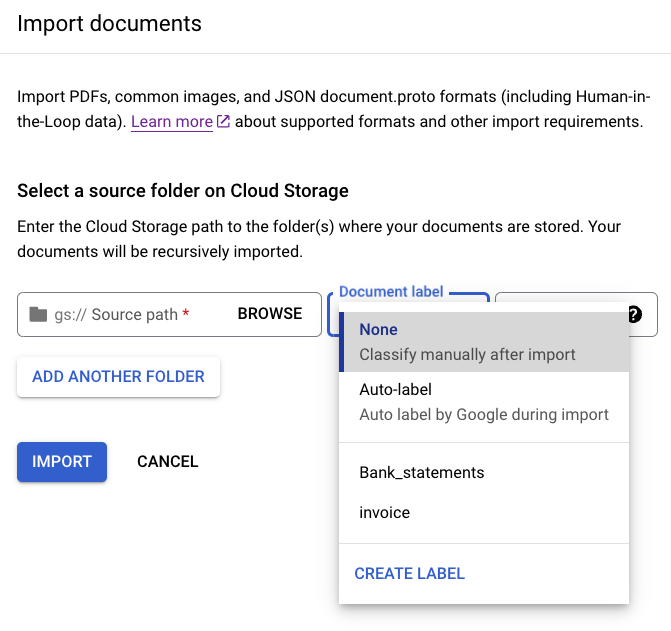
프로세서 학습
이제 학습 데이터와 테스트 데이터를 가져왔으므로 프로세서를 학습시킬 수 있습니다. 학습에 몇 시간이 걸릴 수 있으므로 학습을 시작하기 전에 적절한 데이터와 라벨을 프로세서에 설정했는지 확인하세요.
라벨이 지정된 데이터로 미세 조정된 모델과 커스텀 모델을 학습시킬 수 있습니다. 미세 조정된 모델은 생성형 AI를 사용합니다. 커스텀 모델은 라벨이 지정된 데이터를 사용하여 고유한 대규모 언어 모델을 학습시킵니다. 스키마에 라벨이 2개 이상 있어야 하며, 학습 문서 10개와 테스트 문서 10개(최소 1개)가 권장됩니다.

프로세서 버전 배포
프로세서 평가 및 테스트
새로 가져온 문서를 자동으로 라벨 지정
학습된 프로세서 버전을 배포한 후 자동 라벨 지정을 사용해 새 문서를 가져올 때 라벨 지정 시간을 절약할 수 있습니다.
프로세서 사용
다른 프로세서 버전과 마찬가지로 커스텀 학습 프로세서 버전을 관리할 수 있습니다. 자세한 내용은 프로세서 버전 관리를 참조하세요.
또한 커스텀 프로세서에 처리 요청을 보낼 수 있으며 응답은 다른 분류기 프로세서와 동일하게 처리할 수 있습니다.
삭제
이 페이지에서 사용한 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 수행합니다.