프로세서 버전을 학습시키거나 업트레이닝하거나 평가하려면 문서에 라벨이 지정된 데이터 세트가 필요합니다.
이 페이지에서는 데이터 세트를 만들고 문서를 가져오고 스키마를 정의하는 방법을 설명합니다. 가져온 문서에 라벨을 지정하려면 문서에 라벨 지정을 참고하세요.
이 페이지에서는 학습, 업트레이닝 또는 평가를 지원하는 프로세서를 이미 만들었다고 가정합니다. 프로세서가 지원되면 Google Cloud 콘솔에 학습 탭이 표시됩니다.
데이터 세트 스토리지 옵션
데이터 세트를 저장하는 방법에는 다음 두 가지 옵션이 있습니다.
- Google 관리
- 맞춤 위치 Cloud Storage
특별한 요구사항 (예: CMEK 지원 폴더에 문서를 보관)이 없는 경우 더 간단한 Google 관리 스토리지 옵션을 사용하는 것이 좋습니다. 데이터 세트 스토리지 옵션은 생성된 후에는 프로세서에 대해 변경할 수 없습니다.
맞춤 Cloud Storage 위치의 폴더 또는 하위 폴더는 비어 있는 상태로 시작해야 하며 엄격하게 읽기 전용으로 처리되어야 합니다. 콘텐츠를 수동으로 변경하면 데이터 세트를 사용할 수 없게 되어 손실될 위험이 있습니다. Google 관리 스토리지 옵션에는 이러한 위험이 없습니다.
다음 단계에 따라 스토리지 위치를 프로비저닝하세요.
Google 관리 스토리지 (권장)
새 프로세서를 만드는 동안 고급 옵션을 표시합니다.
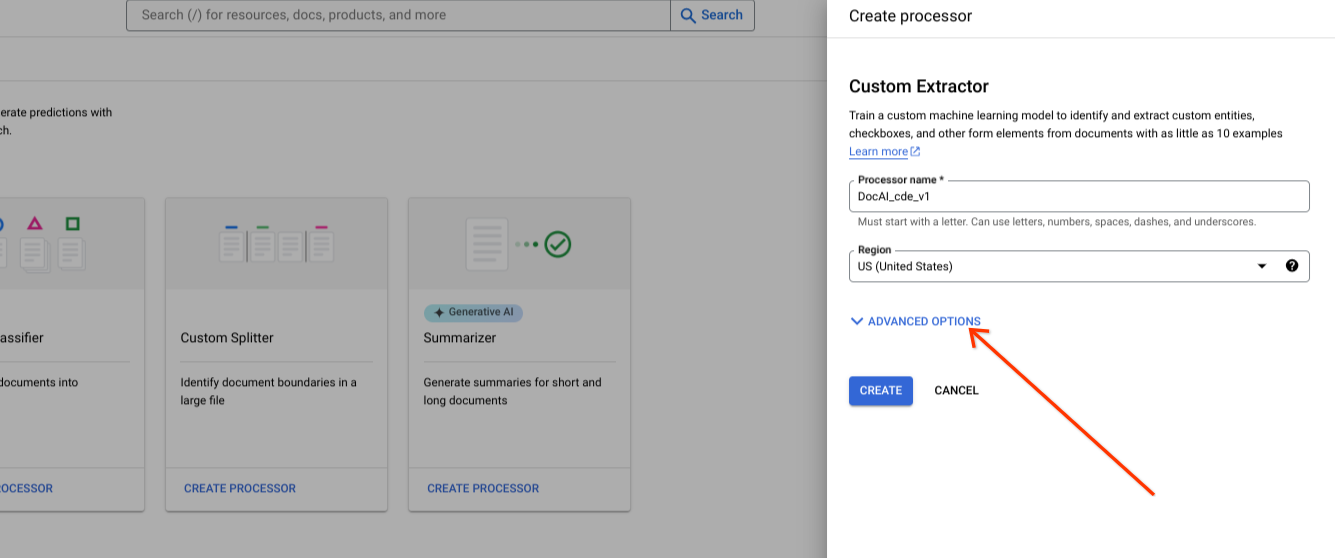
기본 라디오 그룹 옵션을 Google 관리 스토리지로 유지합니다.
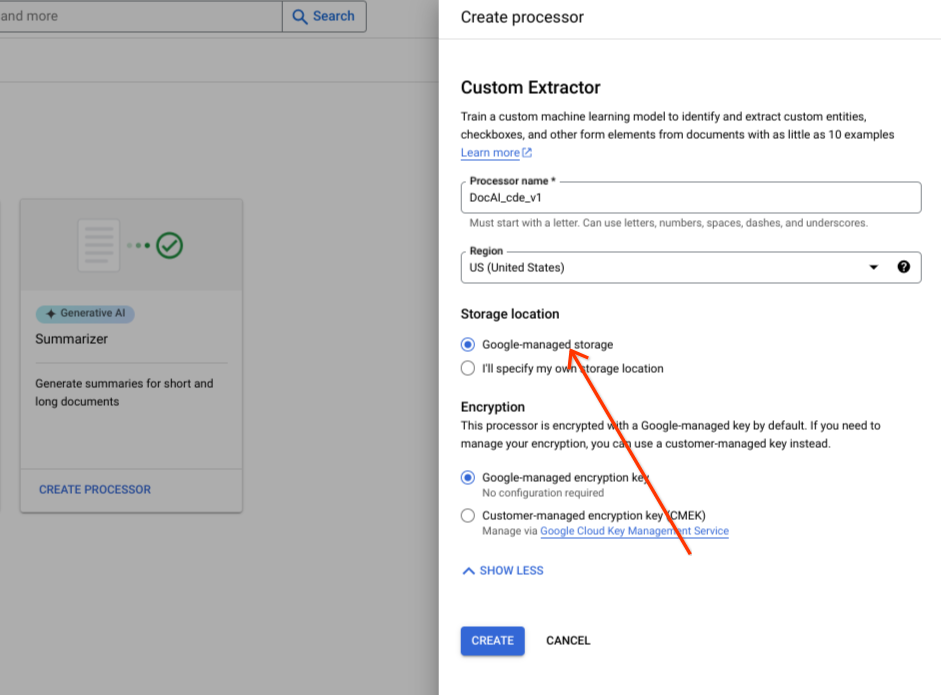
만들기를 선택합니다.
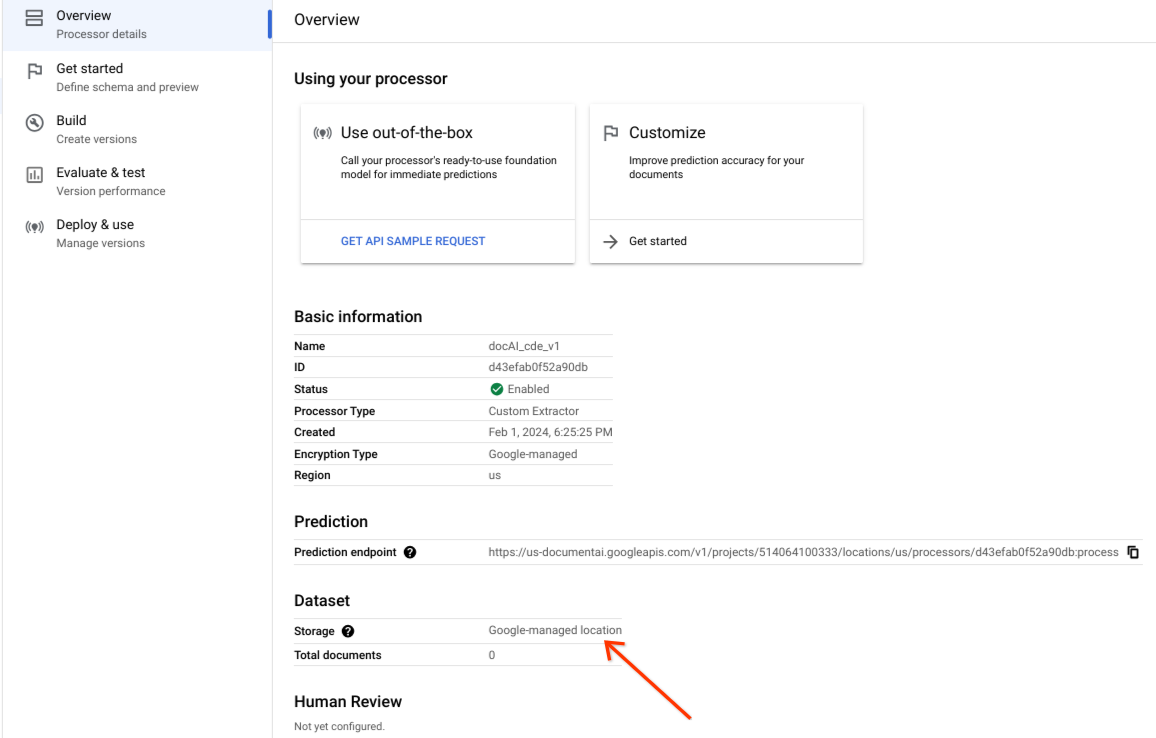
데이터 세트가 생성되었는지, 데이터 세트 위치가 Google 관리 위치인지 확인합니다.
맞춤 스토리지 옵션
고급 옵션을 사용 설정 또는 사용 중지합니다.
직접 스토리지 위치 지정을 선택합니다.
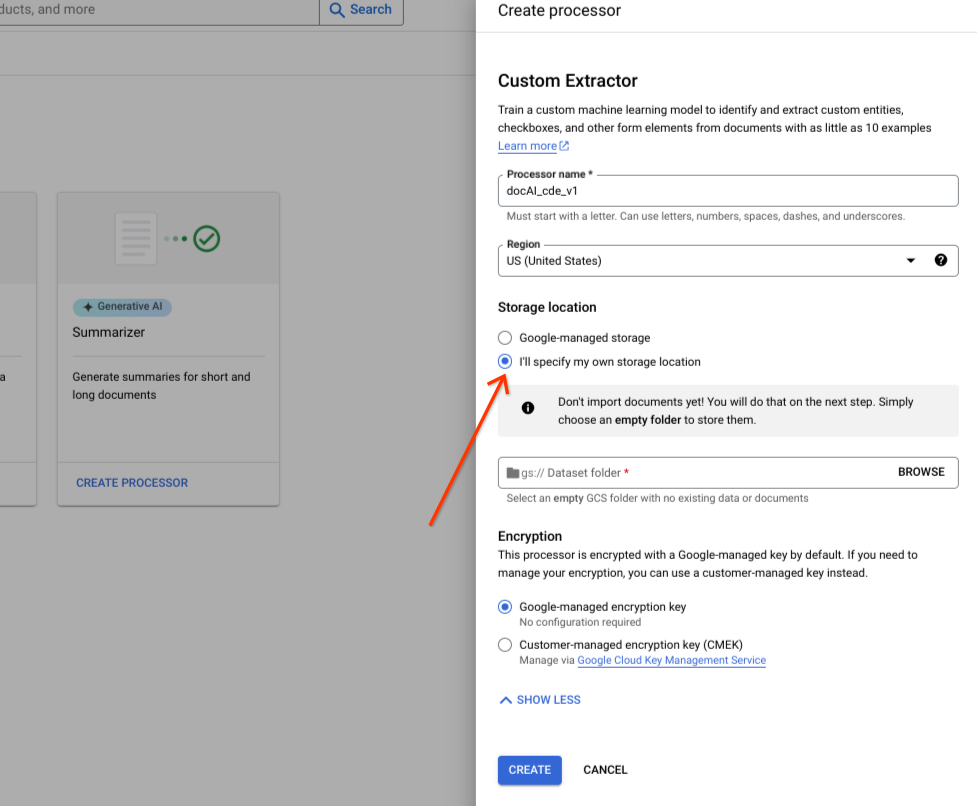
입력 구성요소에서 Cloud Storage 폴더를 선택합니다.
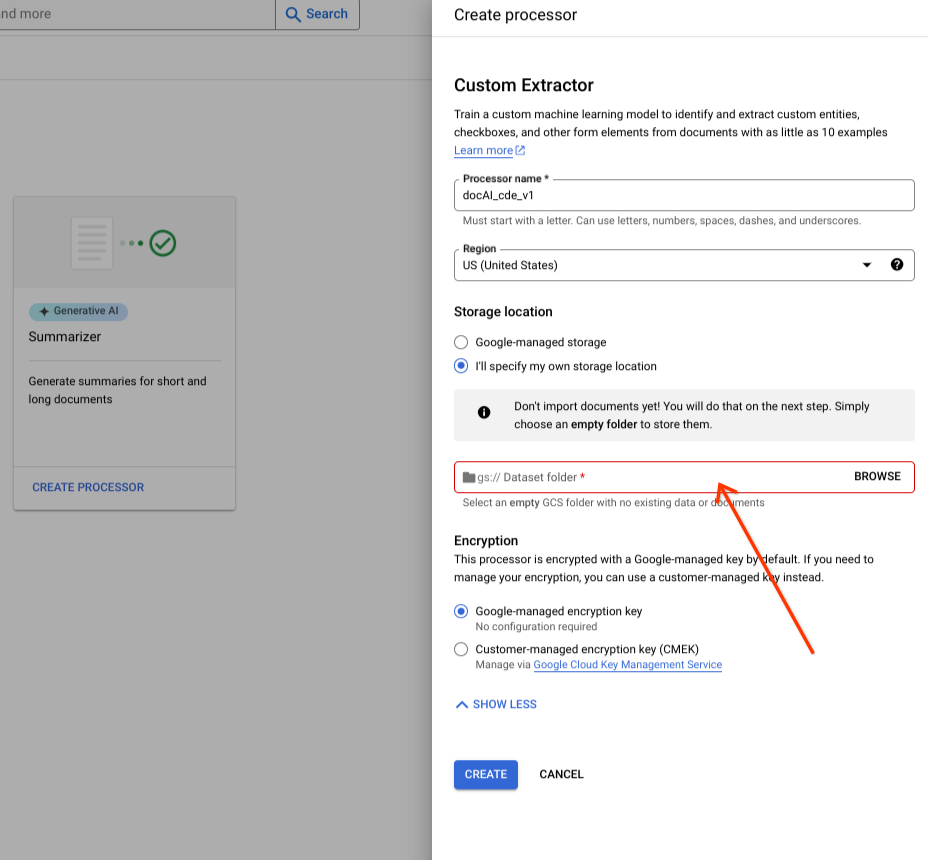
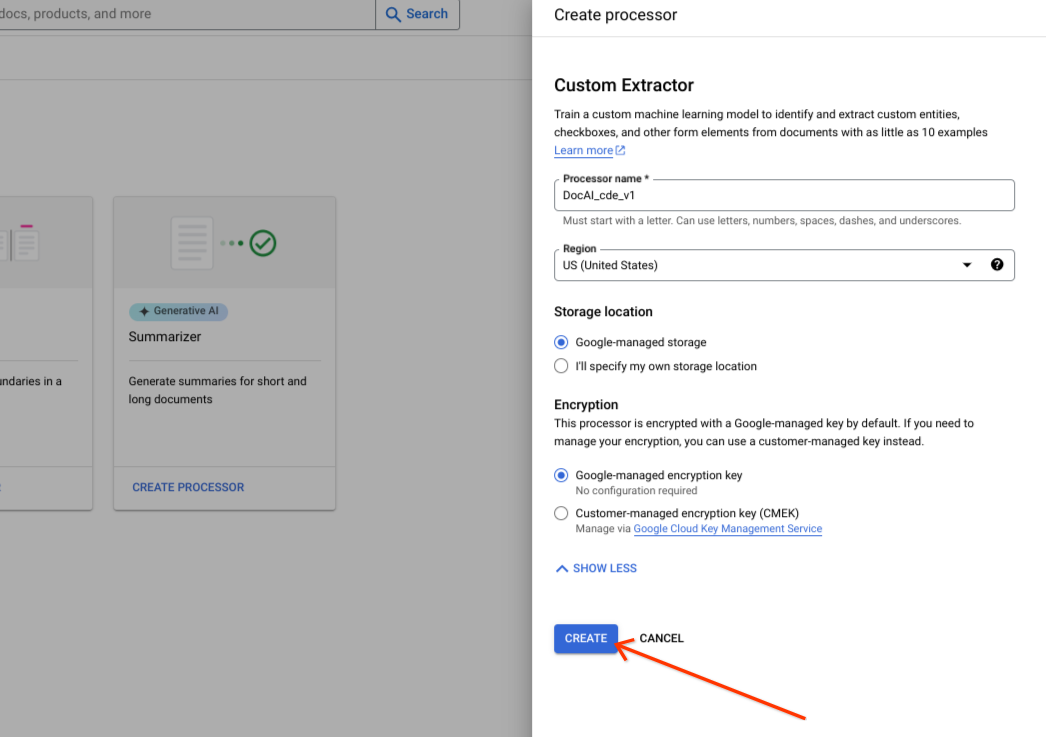
만들기를 선택합니다.
Dataset API 작업
이 샘플에서는 processors.updateDataset 메서드를 사용하여 데이터 세트를 만드는 방법을 보여줍니다. 데이터 세트 리소스는 프로세서의 싱글톤 리소스입니다. 즉, 리소스 생성 RPC가 없습니다. 대신 updateDataset RPC를 사용하여 환경설정을 설정할 수 있습니다. Document AI는 사용자가 제공한 Cloud Storage 버킷에 데이터 세트 문서를 저장하거나 Google에서 자동으로 관리하도록 하는 옵션을 제공합니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
제공된 버킷
다음 단계에 따라 제공한 Cloud Storage 버킷으로 데이터 세트 요청을 만듭니다.
HTTP 메서드
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetJSON 요청:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"gcs_managed_config" {
"gcs_prefix" {
"gcs_uri_prefix": "GCS_URI"
}
}
"spanner_indexing_config" {}
}Google 관리
Google 관리 데이터 세트를 만들려면 다음 정보를 업데이트하세요.
HTTP 메서드
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetJSON 요청:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"unmanaged_dataset_config": {}
"spanner_indexing_config": {}
}요청을 보내려면 Curl을 사용하면 됩니다.
요청 본문을 request.json 파일에 저장합니다. 다음 명령어를 실행합니다.
CURL
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"다음과 비슷한 JSON 응답이 표시됩니다.
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}문서 가져오기
새로 만든 데이터 세트는 비어 있습니다. 문서를 추가하려면 문서 가져오기를 선택하고 데이터 세트에 추가할 문서가 포함된 하나 이상의 Cloud Storage 폴더를 선택합니다.
Cloud Storage가 다른 Google Cloud 프로젝트에 있는 경우 Document AI가 해당 위치에서 파일을 읽을 수 있도록 액세스 권한을 부여해야 합니다. 특히 Document AI의 핵심 서비스 에이전트 service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com에 스토리지 객체 뷰어 역할을 부여해야 합니다. 자세한 내용은 서비스 에이전트를 참고하세요.
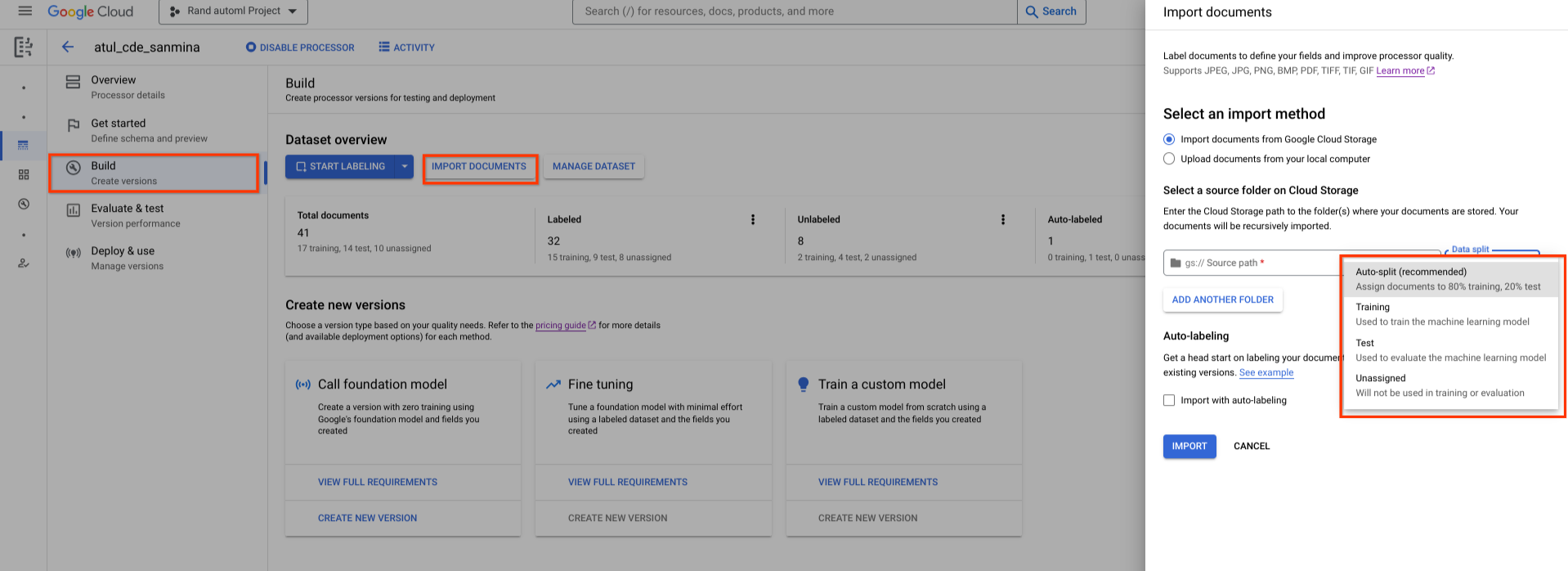
그런 다음 다음 할당 옵션 중 하나를 선택합니다.
- 학습: 학습 세트에 할당합니다.
- 테스트: 테스트 세트에 할당
- 자동 분할: 학습 및 테스트 세트의 문서를 무작위로 셔플합니다.
- 할당되지 않음: 학습 또는 평가에 사용되지 않습니다. 나중에 수동으로 할당할 수 있습니다.
나중에 언제든지 과제를 수정할 수 있습니다.
가져오기를 선택하면 Document AI에서 지원되는 파일 형식과 JSON Document 파일을 모두 데이터 세트로 가져옵니다. JSON Document 파일의 경우 Document AI가 문서를 가져와 entities을 라벨 인스턴스로 변환합니다.
가져오기가 완료된 후에는 Document AI가 가져오기 폴더를 수정하거나 폴더에서 데이터를 읽지 않습니다.
페이지 상단에서 활동을 선택하여 활동 패널을 엽니다. 이 패널에는 가져오기에 성공한 파일과 가져오기에 실패한 파일이 나열됩니다.
프로세서의 기존 버전이 이미 있는 경우 문서 가져오기 대화상자에서 자동 라벨 지정을 사용하여 가져오기 체크박스를 선택하면 됩니다. 문서를 가져올 때 이전 프로세서를 사용하여 자동으로 라벨이 지정됩니다. 자동 라벨 지정 문서를 라벨 지정됨으로 표시하지 않고 학습 또는 업트레이닝하거나 테스트 세트에서 사용할 수는 없습니다. 자동으로 라벨이 지정된 문서를 가져온 후 자동으로 라벨이 지정된 문서를 수동으로 검토하고 수정합니다. 그런 다음 저장을 선택하여 수정사항을 저장하고 문서를 라벨이 지정된 것으로 표시합니다. 그런 다음 적절하게 문서를 할당할 수 있습니다. 자동 라벨 지정을 참고하세요.
문서 가져오기 RPC
이 샘플에서는 dataset.importDocuments 메서드를 사용하여 데이터 세트로 문서를 가져오는 방법을 보여줍니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
DATASET_TYPE: The dataset type to which you want to add documents. The value should be either `DATASET_SPLIT_TRAIN` or `DATASET_SPLIT_TEST`.
TRAINING_SPLIT_RATIO: The ratio of documents which you want to autoassign to the training set.
학습 또는 테스트 데이터 세트
학습 또는 테스트 데이터 세트에 문서를 추가하려면 다음 단계를 따르세요.
HTTP 메서드
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsJSON 요청:
{
"batch_documents_import_configs": {
"dataset_split": DATASET_TYPE
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": GCS_URI
}
}
}
}학습 및 테스트 데이터 세트
문서를 학습 및 테스트 데이터 세트 간에 자동 분할하려면 다음 단계를 따르세요.
HTTP 메서드
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsJSON 요청:
{
"batch_documents_import_configs": {
"auto_split_config": {
"training_split_ratio": TRAINING_SPLIT_RATIO
},
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": "gs://test_sbindal/pdfs-1-page/"
}
}
}
}요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments"다음과 비슷한 JSON 응답이 표시됩니다.
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}문서 삭제 RPC
이 샘플에서는 dataset.batchDeleteDocuments 메서드를 사용하여 데이터 세트에서 문서를 삭제하는 방법을 보여줍니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
DOCUMENT_ID: The document ID blob returned by <code>ImportDocuments</code> request
문서 삭제
HTTP 메서드
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocumentsJSON 요청:
{
"dataset_documents": {
"individual_document_ids": {
"document_ids": DOCUMENT_ID
}
}
}요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments"다음과 비슷한 JSON 응답이 표시됩니다.
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
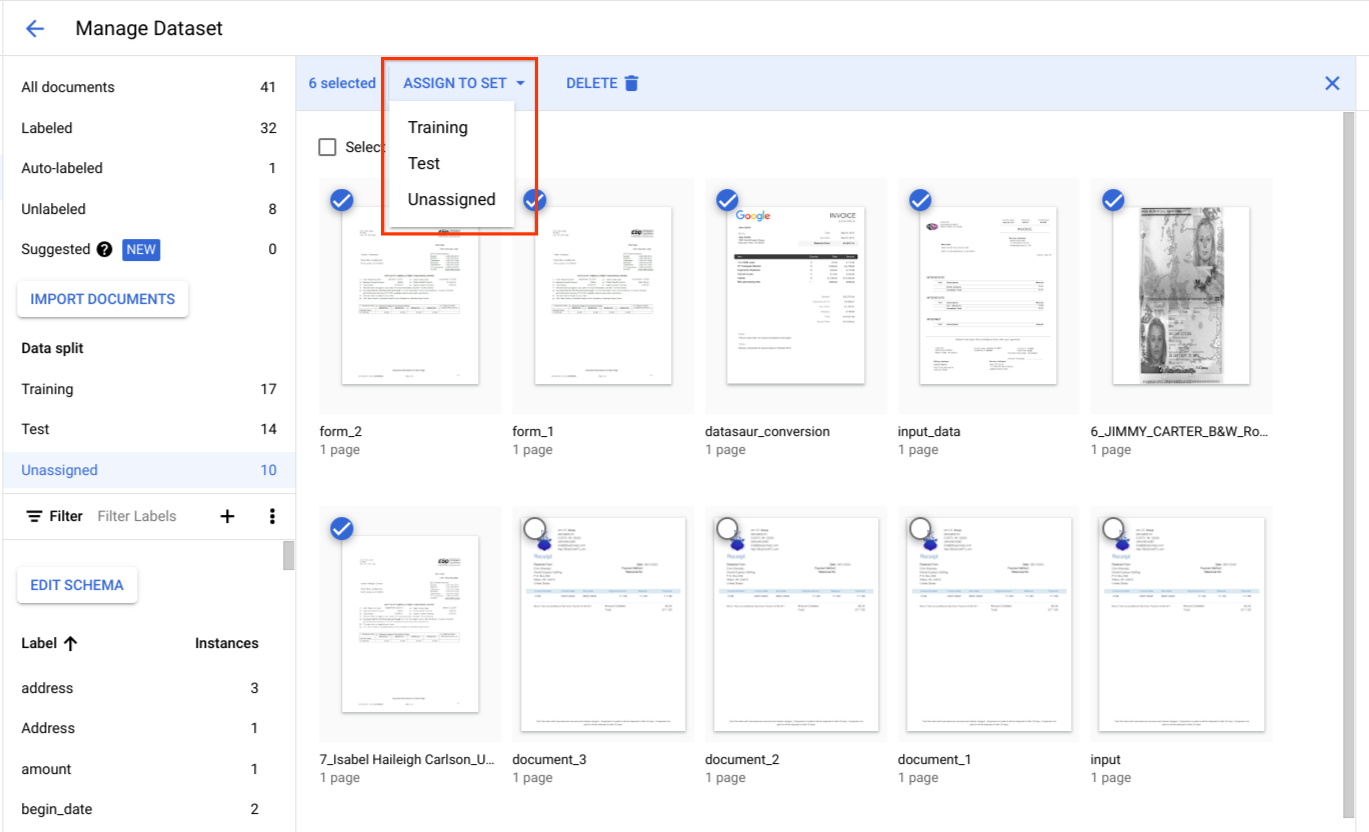
}문서를 학습 또는 테스트 세트에 할당
데이터 분할에서 문서를 선택하고 학습 세트, 테스트 세트 또는 할당되지 않음 중 하나에 할당합니다.
테스트 세트 권장사항
테스트 세트의 품질에 따라 평가의 품질이 결정됩니다.
테스트 세트는 프로세서 개발 주기 초기에 생성되고 잠겨야 시간이 지남에 따라 프로세서의 품질을 추적할 수 있습니다.
테스트 세트의 문서 유형당 문서를 100개 이상 사용하는 것이 좋습니다. 테스트 세트가 개발 중인 모델에 고객이 사용하는 문서 유형을 대표하는지 확인하는 것이 중요합니다.
테스트 세트는 빈도 측면에서 프로덕션 트래픽을 대표해야 합니다. 예를 들어 W2 양식을 처리하고 70% 가 2020년, 30% 가 2019년 양식일 것으로 예상되는 경우 테스트 세트의 약 70% 가 W2 2020 문서로 구성되어야 합니다. 이러한 테스트 세트 구성은 프로세서의 성능을 평가할 때 각 문서 하위 유형에 적절한 중요도가 부여되도록 합니다. 또한 국제 양식에서 사람 이름을 추출하는 경우 테스트 세트에 타겟팅된 모든 국가의 양식이 포함되어 있는지 확인하세요.
학습 세트 관련 권장사항
이미 테스트 세트에 포함된 문서는 학습 세트에 포함하면 안 됩니다.
테스트 세트와 달리 최종 학습 세트는 문서 다양성이나 빈도 측면에서 고객 사용량을 엄격하게 나타낼 필요가 없습니다. 일부 라벨은 다른 라벨보다 학습하기가 더 어렵습니다. 따라서 학습 세트를 이러한 라벨 쪽으로 기울이면 성능이 향상될 수 있습니다.
처음에는 어떤 라벨이 어려운지 파악할 좋은 방법이 없습니다. 테스트 세트에 설명된 것과 동일한 접근 방식을 사용하여 무작위로 샘플링된 작은 초기 학습 세트로 시작해야 합니다. 이 초기 학습 세트에는 주석을 달 계획인 총 문서 수의 약 10% 가 포함되어야 합니다. 그런 다음 프로세서 품질을 반복적으로 평가하고(특정 오류 패턴 찾기) 학습 데이터를 추가할 수 있습니다.
프로세서 스키마 정의
데이터 세트를 만든 후 문서를 가져오기 전이나 후에 프로세서 스키마를 정의할 수 있습니다.
프로세서의 schema는 문서에서 추출할 이름, 주소 등의 라벨을 정의합니다.
스키마 수정을 선택한 다음 필요에 따라 라벨을 만들고, 수정하고, 사용 설정하고, 사용 중지합니다.
완료되면 저장을 선택해야 합니다.
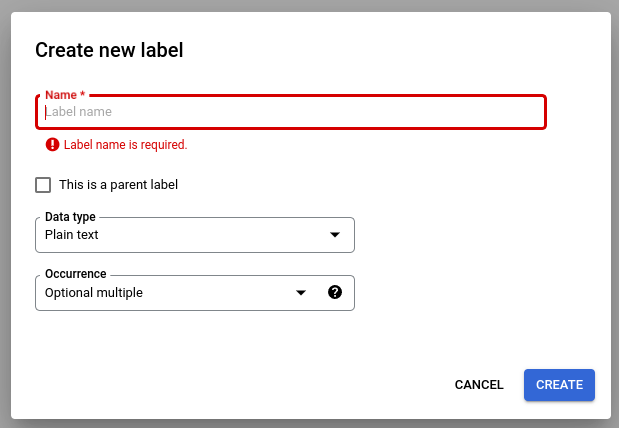
스키마 라벨 관리에 관한 참고사항:
스키마 라벨을 만든 후에는 스키마 라벨의 이름을 수정할 수 없습니다.
스키마 라벨은 학습된 프로세서 버전이 없는 경우에만 수정하거나 삭제할 수 있습니다. 데이터 유형과 발생 유형만 수정할 수 있습니다.
라벨을 사용 중지해도 예측에 영향을 미치지 않습니다. 처리 요청을 보내면 프로세서 버전이 학습 시점에 활성 상태였던 모든 라벨을 추출합니다.
데이터 스키마 가져오기
이 샘플에서는 getDatasetSchema를 사용하여 현재 스키마를 가져오는 방법을 보여줍니다. DatasetSchema는 싱글톤 리소스로, 데이터 세트 리소스를 만들 때 자동으로 생성됩니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
데이터 스키마 가져오기
HTTP 메서드
GET https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaCURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"다음과 비슷한 JSON 응답이 표시됩니다.
{
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema",
"documentSchema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": $LABEL_NAME,
"valueType": $VALUE_TYPE,
"occurrenceType": $OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}문서 스키마 업데이트
이 샘플에서는 dataset.updateDatasetSchema를 사용하여 현재 스키마를 업데이트하는 방법을 보여줍니다. 이 예시에서는 데이터 세트 스키마를 하나의 라벨로 업데이트하는 명령어를 보여줍니다. 기존 라벨을 삭제하거나 업데이트하지 않고 새 라벨을 추가하려면 먼저 getDatasetSchema를 호출하고 응답에서 적절한 변경사항을 적용하면 됩니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
LABEL_NAME: The label name which you want to add
LABEL_DESCRIPTION: Describe what the label represents
DATA_TYPE: The type of the label. You can specify this as string, number, currency, money, datetime, address, boolean.
OCCURRENCE_TYPE: Describes the number of times this label is expected. Pick an enum value.
스키마 업데이트
HTTP 메서드
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaJSON 요청:
{
"document_schema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": LABEL_NAME,
"description": LABEL_DESCRIPTION,
"valueType": DATA_TYPE,
"occurrenceType": OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}요청 본문을 request.json 파일에 저장하고 다음 명령어를 실행합니다.
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"라벨 속성 선택
데이터 유형
Plain text: 문자열 값입니다.Number: 숫자(정수 또는 부동 소수점)입니다.Money: 금액입니다. 라벨을 지정할 때는 통화 기호를 포함하지 마세요.- 엔티티가 추출되면
google.type.Money로 정규화됩니다.
- 엔티티가 추출되면
Currency: 통화 기호입니다.Datetime: 날짜 또는 시간 값입니다.- 항목이 추출되면
ISO 8601텍스트 형식으로 정규화됩니다.
- 항목이 추출되면
Address- 위치 주소입니다.- 항목이 추출되면 EKG로 정규화되고 보강됩니다.
Checkbox-true또는false불리언 값입니다.Signature- 서명이 있는지 여부를 나타내는normalized_value.signature_value의true또는false불리언 값입니다.derive메서드를 지원합니다.mention_text- 서명이 있는지 여부를 나타내는has_signed의Detected또는 빈""불리언 값입니다.derive메서드를 지원합니다.normalized_value.text- 서명이 있는지 여부를 나타내는has_signed의Detected또는 빈""불리언 값입니다.derive메서드를 지원합니다.normalized_value.boolean_value이 채워지지 않습니다.
메서드
- 엔티티가
extracted인 경우textAnchor,type,mentionText,pageAnchor필드가 채워집니다. - 엔티티가
derived인 경우 파생된 값이 문서 텍스트에 없을 수 있습니다.textAnchor및pageAnchor.pageRefs[].bounding_poly필드가 채워져 있지 않습니다.
어커런스
항목이 특정 유형의 문서에 항상 표시되어야 하는 경우 REQUIRED를 선택합니다. 이러한 기대치가 없는 경우 OPTIONAL을 선택합니다.
동일한 값이 동일한 문서에 여러 번 표시되더라도 항목에 하나의 값이 있어야 하는 경우 ONCE를 선택합니다. 엔티티에 값이 여러 개 있을 것으로 예상되는 경우 MULTIPLE을 선택합니다.
상위 및 하위 라벨
상위-하위 라벨 (표 형식 항목이라고도 함)은 표의 데이터에 라벨을 지정하는 데 사용됩니다. 다음 표에는 3개의 행과 4개의 열이 있습니다.

상위-하위 라벨을 사용하여 이러한 테이블을 정의할 수 있습니다. 이 예에서 상위 라벨 line-item는 테이블의 행을 정의합니다.
상위 라벨 만들기
스키마 수정 페이지에서 라벨 만들기를 선택합니다.
상위 라벨입니다 체크박스를 선택하고 기타 정보를 입력합니다. 테이블의 모든 행을 캡처하기 위해 반복될 수 있도록 상위 라벨에
optional_multiple또는require_multiple이 있어야 합니다.저장을 선택합니다.
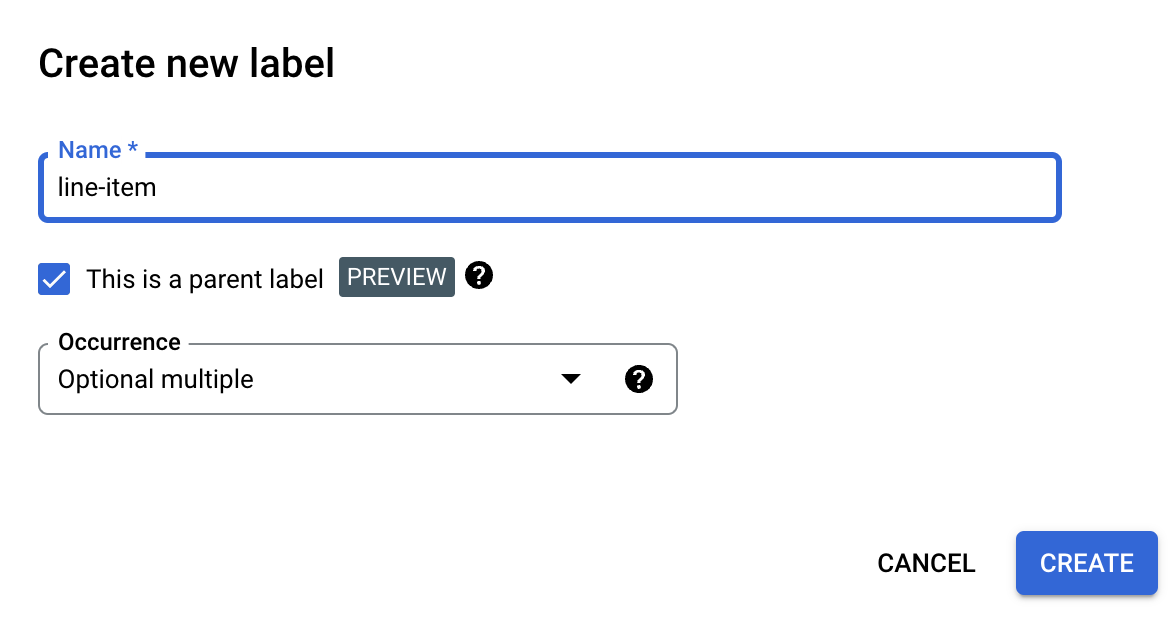
상위 라벨이 스키마 수정 페이지에 표시되며, 옆에 하위 라벨 추가 옵션이 있습니다.
하위 라벨을 만들려면 다음 단계를 따르세요.
스키마 수정 페이지의 상위 라벨 옆에 있는 하위 라벨 추가를 선택합니다.
하위 라벨의 정보를 입력합니다.
저장을 선택합니다.
추가하려는 각 하위 라벨에 대해 이 단계를 반복합니다.
하위 라벨은 스키마 수정 페이지의 상위 라벨 아래에 들여쓰기로 표시됩니다.

상위-하위 라벨은 미리보기 기능이며 표에만 지원됩니다. 중첩 깊이는 1로 제한됩니다. 즉, 하위 항목이 다른 하위 항목을 포함할 수 없습니다.
라벨이 지정된 문서에서 스키마 라벨 만들기
사전 라벨이 지정된 Document JSON 파일을 가져와 스키마 라벨을 자동으로 만듭니다.
Document 가져오기가 진행되는 동안 새로 추가된 스키마 라벨이 스키마 편집기에 추가됩니다. '스키마 수정'을 선택하여 새 스키마 라벨 데이터 유형과 발생 유형을 확인하거나 변경합니다. 확인되면 스키마 라벨을 선택하고 사용 설정을 선택합니다.
샘플 데이터 세트
Document AI Workbench를 시작하는 데 도움이 되도록 여러 문서 유형의 라벨이 지정된 샘플 Document JSON 파일과 라벨이 지정되지 않은 샘플 Document JSON 파일이 포함된 공개 Cloud Storage 버킷에 데이터 세트가 제공됩니다.
문서 유형에 따라 업트레이닝 또는 맞춤 추출기에 사용할 수 있습니다.
gs://cloud-samples-data/documentai/Custom/
gs://cloud-samples-data/documentai/Custom/1040/
gs://cloud-samples-data/documentai/Custom/Invoices/
gs://cloud-samples-data/documentai/Custom/Patents/
gs://cloud-samples-data/documentai/Custom/Procurement-Splitter/
gs://cloud-samples-data/documentai/Custom/W2-redacted/
gs://cloud-samples-data/documentai/Custom/W2/
gs://cloud-samples-data/documentai/Custom/W9/