Document AI を使用すると、独自のトレーニング データを使用して新しいプロセッサ バージョンをトレーニングし、独自のテストデータに対してプロセッサ バージョンの品質を評価できます。
これは、カスタム プロセッサを使用する場合に便利です。ドキュメント タイプに対応する Document AI プロセッサはありますが、ニーズに合わせてカスタム バージョンをアップトレーニングできます。
通常、トレーニングと評価は同時に行われ、高品質で実用的なプロセッサ バージョンに向けて反復処理が行われます。
Document AI
Document AI を使用すると、特定のタイプのドキュメントからエンティティを抽出する独自のカスタム エクストラクタを構築できます。たとえば、メニューの項目や、履歴書の名前や連絡先情報を抽出できます。
他のプロセッサとは異なり、カスタム プロセッサには事前トレーニング済みバージョンのプロセッサが備わっていないため、バージョンにゼロからトレーニングを行った後でなければドキュメントを処理できません。
Document AI の使用を開始するには、独自のカスタム プロセッサを構築するをご覧ください。
プロセッサのアップトレーニング
新しいプロセッサ バージョンをアップトレーニングすると、データの精度を向上させたり、ドキュメントから追加のカスタム フィールドを抽出したり、新しい言語のサポートを追加したりできます。
アップ トレーニングは、Google の事前トレーニング済みプロセッサ バージョンに転移学習を適用することで機能します。通常、ゼロからトレーニングするよりも必要なデータが少なくなります。
使用を開始するには、事前トレーニング済みプロセッサをアップトレーニングするをご覧ください。
サポートされるプロセッサ
すべての専用プロセッサがアップトレーニングをサポートしているわけではありません。アップトレーニングをサポートするプロセッサは次のとおりです。
データの考慮事項と推奨事項
データの質と量によって、トレーニング、アップトレーニング、評価の質が決まります。
代表的な実際のドキュメントのセットを取得し、十分な高品質のラベルを提供することは、多くの場合、プロセスの中で最も時間とリソースを要する部分です。
ドキュメント数
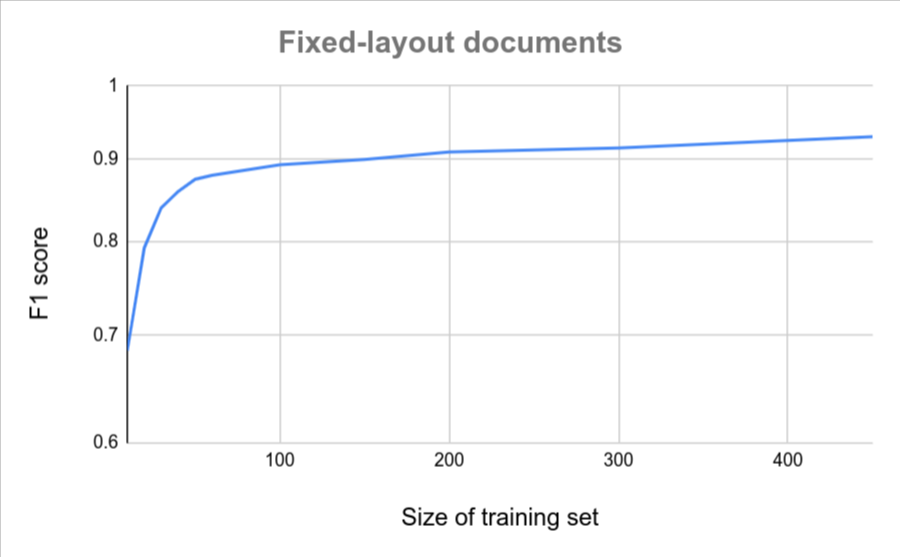
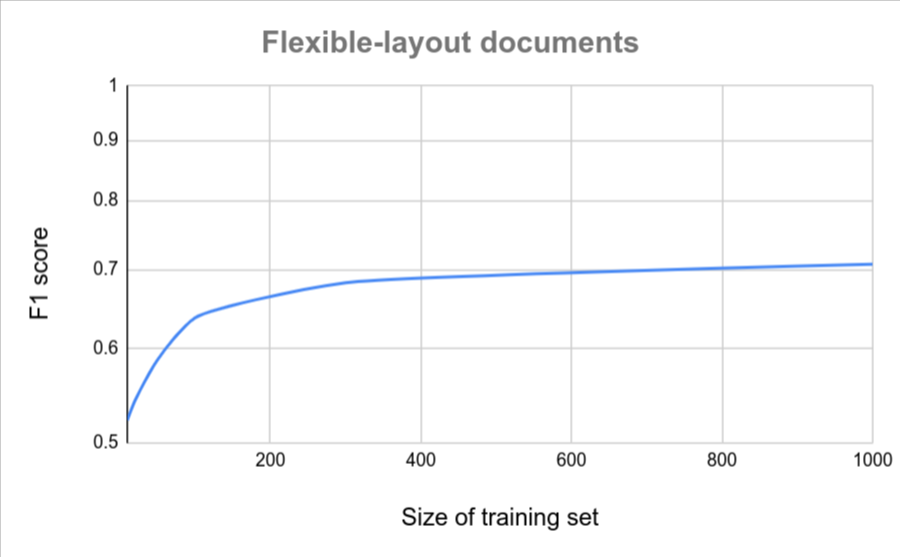
ドキュメントの形式がすべて類似している場合(たとえば、バリエーションが非常に少ない固定フォームなど)、精度を高めるために必要なドキュメントの数は少なくなります。バリエーションが大きいほど、必要なドキュメントが多くなります。
次のグラフは、カスタム ドキュメント エクストラクタが特定の品質スコアを達成するために必要なドキュメント数の概算を示しています。
| 変動が少ない | 変動が大きい |
|---|---|
 |
 |
Data Labeling
ドキュメントにラベルを付けるオプションを検討し、データセット内のドキュメントにアノテーションを付けるのに十分なリソースがあることを確認します。
モデルのトレーニング
カスタム抽出ツール プロセッサは、特定のユースケースと利用可能なトレーニング データに応じて、さまざまなモデルタイプを使用できます。
- カスタムモデル: ラベル付きトレーニング データを使用するモデル。
- テンプレート ベース: レイアウトが固定されたドキュメント。
- モデルベース: レイアウトのバリエーションがあるドキュメント。
- 生成 AI モデル: 事前トレーニング済みの基盤モデルに基づいており、追加のトレーニングは最小限で済みます。
次の表に、各モデルタイプに対応するユースケースを示します。
| カスタムモデル | 生成 AI | ||
|---|---|---|---|
| テンプレート ベース | モデルベース | ||
| レイアウトのバリエーション | なし | 低~中 | 高 |
| 自由形式のテキストの量(契約書の段落など) | 低 | 低 | 高 |
| 必要なトレーニング データの量 | 低 | 高 | 低 |
| トレーニング データが少ない場合の精度 | 高い | 低 | 高い |
プロパティの説明を使用してプロセッサをファインチューニングする方法を学習する。
別のプロセッサを使用する場合
Document AI Workbench 以外のオプションを検討したり、ワークフローを調整したりする必要がある場合について説明します。
- 特定のテキストベースの入力形式(.txt、.html、.docx、.md など)は、Document AI Document AI Workbench でサポートされていません。 Google Cloudの他の事前構築済みまたはカスタムの言語処理サービス(Cloud Natural Language API など)を検討します。
- カスタム ドキュメント エクストラクタ スキーマは、最大 150 個のエンティティ ラベルをサポートします。ビジネス ロジックでスキーマ定義に 150 個を超えるエンティティが必要な場合は、複数のプロセッサをトレーニングして、それぞれがエンティティのサブセットをターゲットにすることを検討してください。
プロセッサをトレーニングする方法
トレーニングまたはアップトレーニングをサポートするプロセッサを作成し、データセットにラベルを付けたことを前提として、新しいプロセッサ バージョンをゼロからトレーニングできます。または、既存のプロセッサ バージョンに基づいて新しいプロセッサ バージョンをアップトレーニングすることもできます。
プロセッサ バージョンをトレーニングする
ウェブ UI
Google Cloud コンソールで、プロセッサの [トレーニング] タブに移動します。
[スキーマを編集] をクリックして、[ラベルの管理] ページを開きます。プロセッサのラベルを確認します。
トレーニング時に有効になっているラベルによって、新しいプロセッサ バージョンで抽出されるエンティティが決まります。スキーマでラベルが非アクティブになっている場合、ドキュメントにラベルが付けられていても、プロセッサ バージョンはそのラベルを抽出しません。
[トレーニング] タブで、[ラベルの統計情報を表示] をクリックし、テストセットとトレーニング セットを確認します。自動ラベル付け、ラベルなし、未割り当てのドキュメントは、トレーニングと評価から除外されます。
[新しいバージョンをトレーニング] をクリックします。
[バージョン名] は、
processorVersionのnameフィールドを定義します。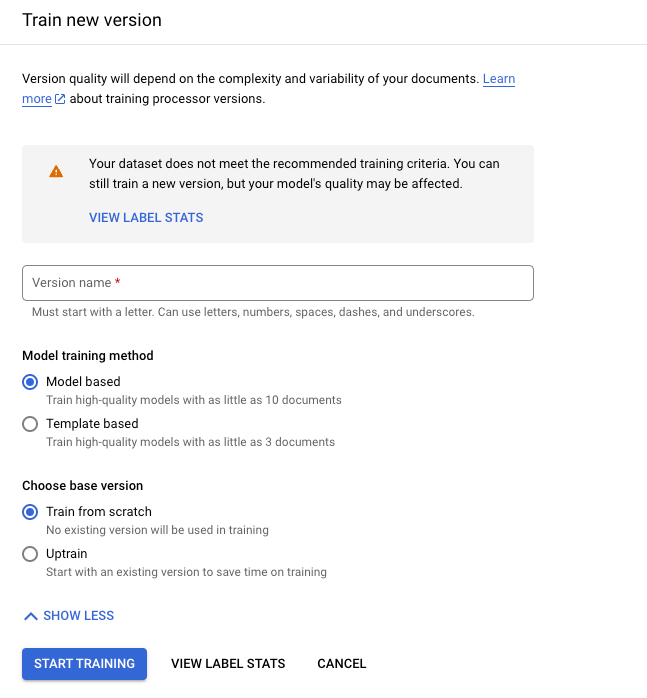
[トレーニングを開始] をクリックし、新しいプロセッサ バージョンがトレーニングされて評価されるまで待ちます。
トレーニングの進行状況は、[バージョンの管理] タブでモニタリングできます。
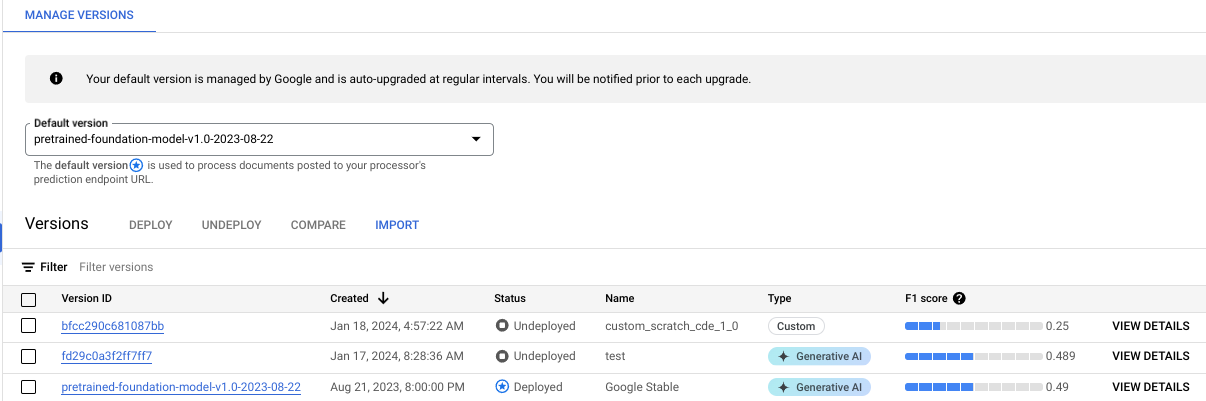
[評価とテスト] タブをクリックして、新しいプロセッサ バージョンがテストセットでどの程度機能したかを確認します。詳細については、プロセッサ バージョンを評価するをご覧ください。
Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
プロセッサ バージョンをデプロイして使用する
プロセッサ バージョンは、他のプロセッサ バージョンと同様にデプロイして管理できます。詳細については、プロセッサ バージョンの管理をご覧ください。
デプロイ後、カスタム プロセッサに処理リクエストを送信できます。
プロセッサを無効にする、削除する
プロセッサが不要になった場合は、無効にするか削除できます。プロセッサを無効にした場合は、再度有効にできます。削除したプロセッサは復元できません。
左側の [Document AI] パネルで、[マイプロセッサ] をクリックします。
プロセッサ名の右にある縦の 3 つの点をクリックします。[プロセッサを無効にする] または [プロセッサを削除する] をクリックします。
詳細については、プロセッサ バージョンの管理をご覧ください。
トレーニング データの暗号化
Document AI のトレーニング データは Cloud Storage に保存され、必要に応じて顧客管理の暗号鍵で暗号化できます。
トレーニング データの削除
Document AI トレーニング ジョブが完了すると、Cloud Storage に保存されたすべてのトレーニング データは 2 日間の保持期間後に期限切れになります。後続のデータ削除アクティビティは、 Google Cloudでのデータ削除で説明されているプロセスに従います。
料金
トレーニングやアップトレーニングの費用はかかりません。ホスティングと予測の料金が発生します。詳細については、Document AI の料金をご覧ください。