生成 AI のトレーニングと抽出により、次のことが可能になります。
- ゼロショットと少数ショットのテクノロジーを使用して、基盤モデルを使用し、トレーニング データがほとんどないか、まったくない状態で高性能モデルを取得します。
- ファインチューニングを使用すると、トレーニング データを増やしていくにつれて精度をさらに高めることができます。
生成 AI のトレーニング方法
選択するトレーニング方法は、利用可能なドキュメントの量と、モデルのトレーニングに費やせる労力によって異なります。生成 AI モデルをトレーニングする方法は 3 つあります。
| トレーニング方法 | ゼロショット | 少数ショット | ファインチューニング |
|---|---|---|---|
| 精度 | 中 | やや高い | 高 |
| 作業量 | 低 | 低 | 中 |
| 推奨されるトレーニング ドキュメントの数 | 0 | 5 ~ 10 | 10 ~ 50+ |
カスタム エクストラクタ モデルのバージョン
カスタム抽出ツールでは、次のモデルを使用できます。モデル バージョンを変更するには、プロセッサ バージョンを管理するをご覧ください。
バージョン 1.3、1.4、1.5、1.5 Pro は信頼スコアをサポートしていますが、バージョン 1.2 はサポートしていません。
| モデル バージョン | 説明 | リリース チャンネル | ML 処理(米国 / EU) | ファインチューニング(米国 / EU) | リリース日 |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-02-05 |
Gemini 2.0 Flash LLM を搭載した一般提供モデル。チェックボックス検出などの高度な OCR 機能も含まれています。 | Stable | ○ | 米国、EU | 2025 年 2 月 5 日 |
pretrained-foundation-model-v1.5-2025-05-05 |
Gemini 2.5 Flash LLM によるプロダクション レディな候補。新しいモデルを試してみたい方におすすめします。 | Stable | ○ | 米国、EU(プレビュー) | 2025 年 5 月 5 日 |
pretrained-foundation-model-v1.5-pro-2025-06-20 |
Gemini 2.5 Pro LLM を搭載したプロダクション レディなモデル。オンライン処理リクエストで 1 分あたり最大 30 ページの割り当てをサポートします。このモデルは v1.5 と比較して品質が向上していますが、レイテンシが高くなる可能性があります。 | Stable | ○ | いいえ | 2025 年 6 月 20 日 |
プロジェクトのプロセッサ バージョンを変更するには、プロセッサ バージョンの管理をご覧ください。
デフォルトのプロセッサ割り当ての割り当て増加リクエスト(QIR)を行うには、割り当てを管理するの手順に沿って操作します。
初期設定
まだ行っていない場合は、請求と Document AI API を有効にします。
生成 AI モデルを構築して評価する
プロセッサを作成し、ベスト プラクティスに沿って抽出するフィールドを定義します。これは、抽出の品質に影響するため重要です。
- [Workbench] > [カスタム抽出ツール] > [プロセッサを作成] > [名前を割り当てる] に移動します。
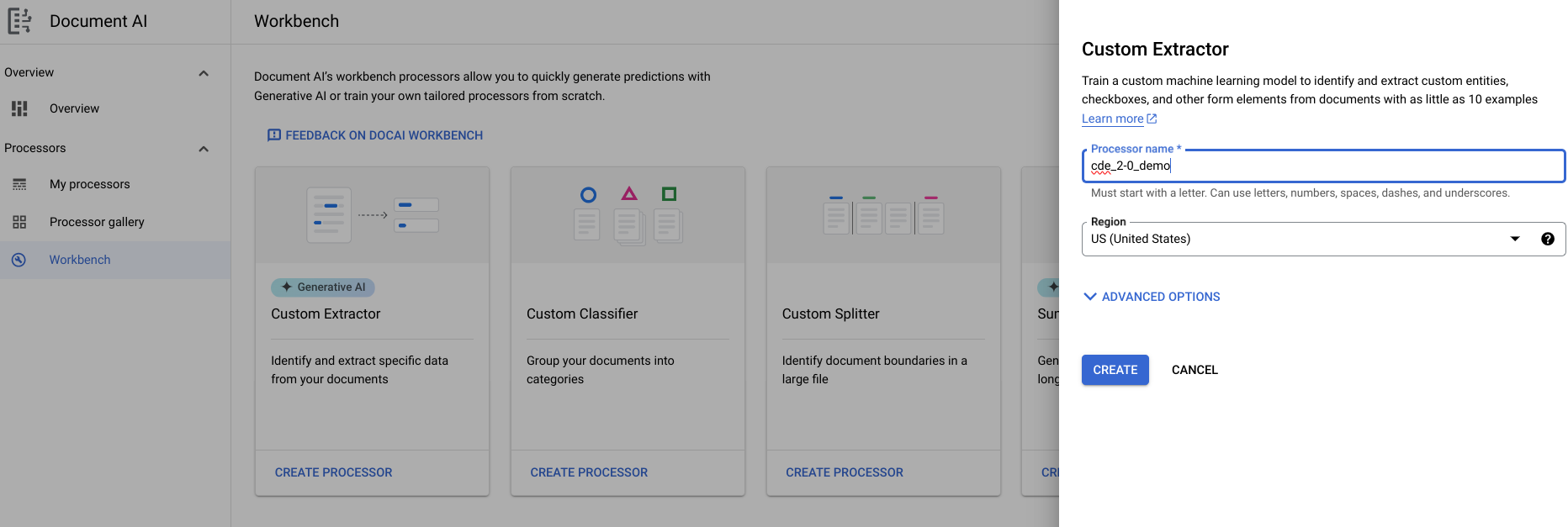
- [開始する] > [新しいフィールドを作成] に移動します。
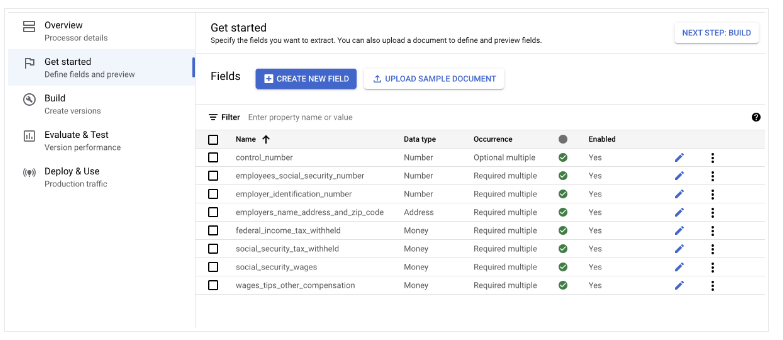
ドキュメントのインポート
- 自動ラベル付けを使用してドキュメントをインポートし、トレーニング セットとテストセットにドキュメントを割り当てます。
- ゼロショットの場合、スキーマのみが必要です。モデルの精度を評価するには、テストセットのみが必要です。
- フューショットの場合は、5 つのトレーニング ドキュメントをおすすめします。
- 必要なテスト ドキュメントの数はユースケースによって異なります。一般的に、テスト ドキュメントが多いほど良いです。
- ドキュメント内のラベルを確認または編集します。
モデルをトレーニングします。
- [ビルド]、[新しいバージョンを作成] の順に選択します。
- 名前を入力して [作成] を選択します。
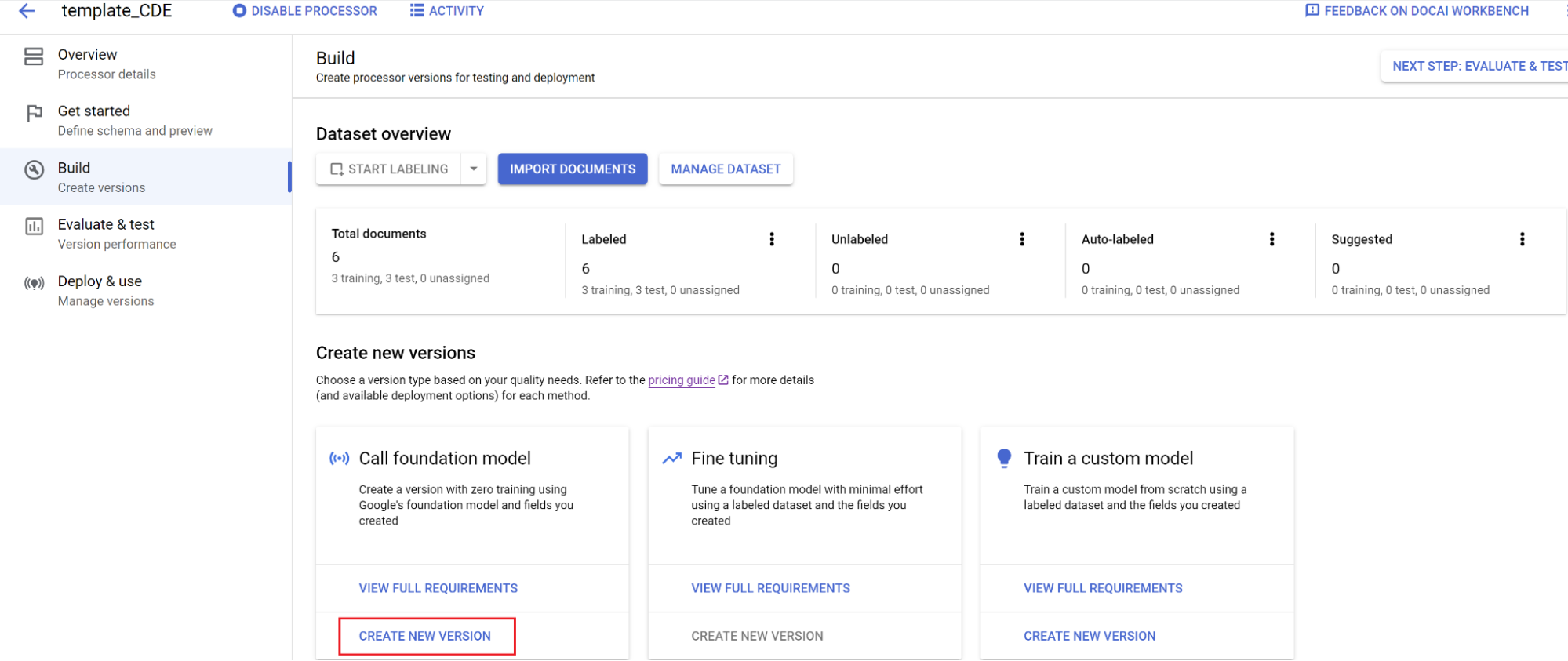
評価:
- [評価とテスト] に移動し、トレーニングしたばかりのバージョンを選択して、[完全な評価を表示] を選択します。
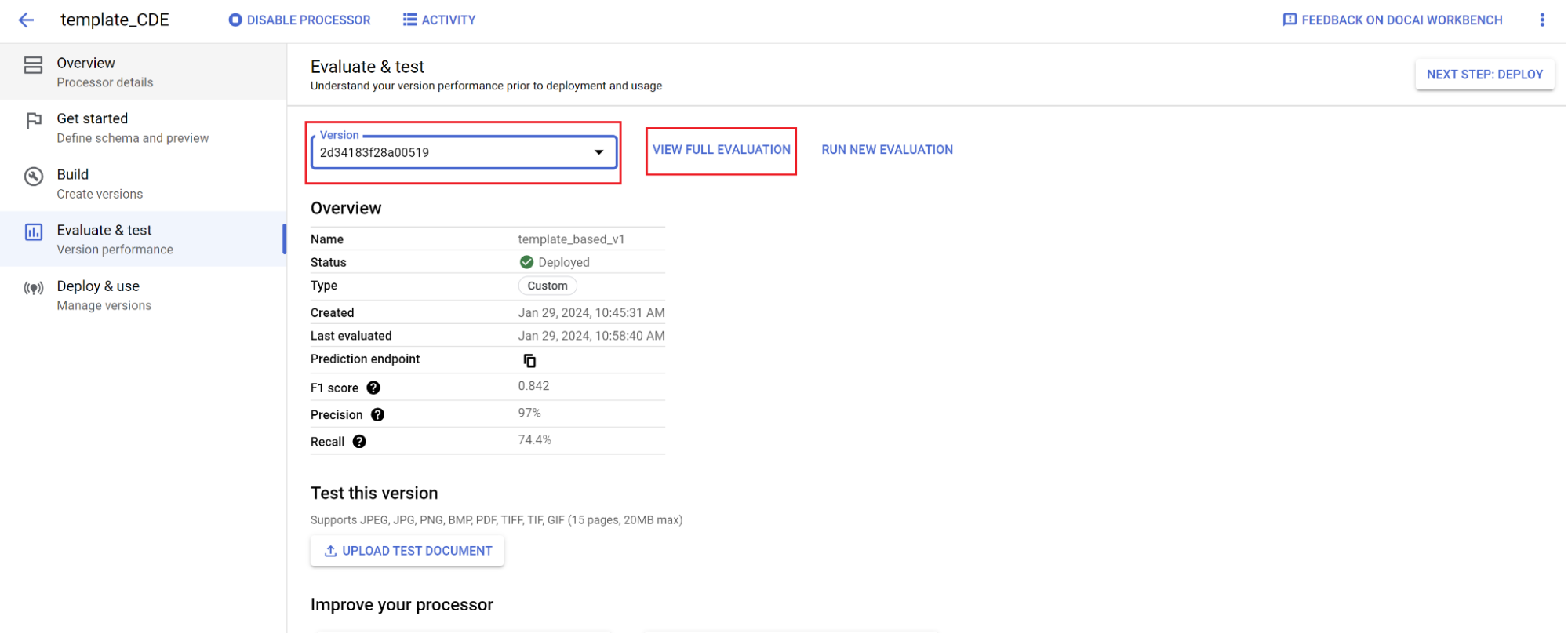
- ドキュメント全体と各フィールドの f1、適合率、再現率などの指標が表示されます。
- パフォーマンスが本番環境の目標を満たしているかどうかを判断します。満たしていない場合は、トレーニング セットとテストセットを再評価します。
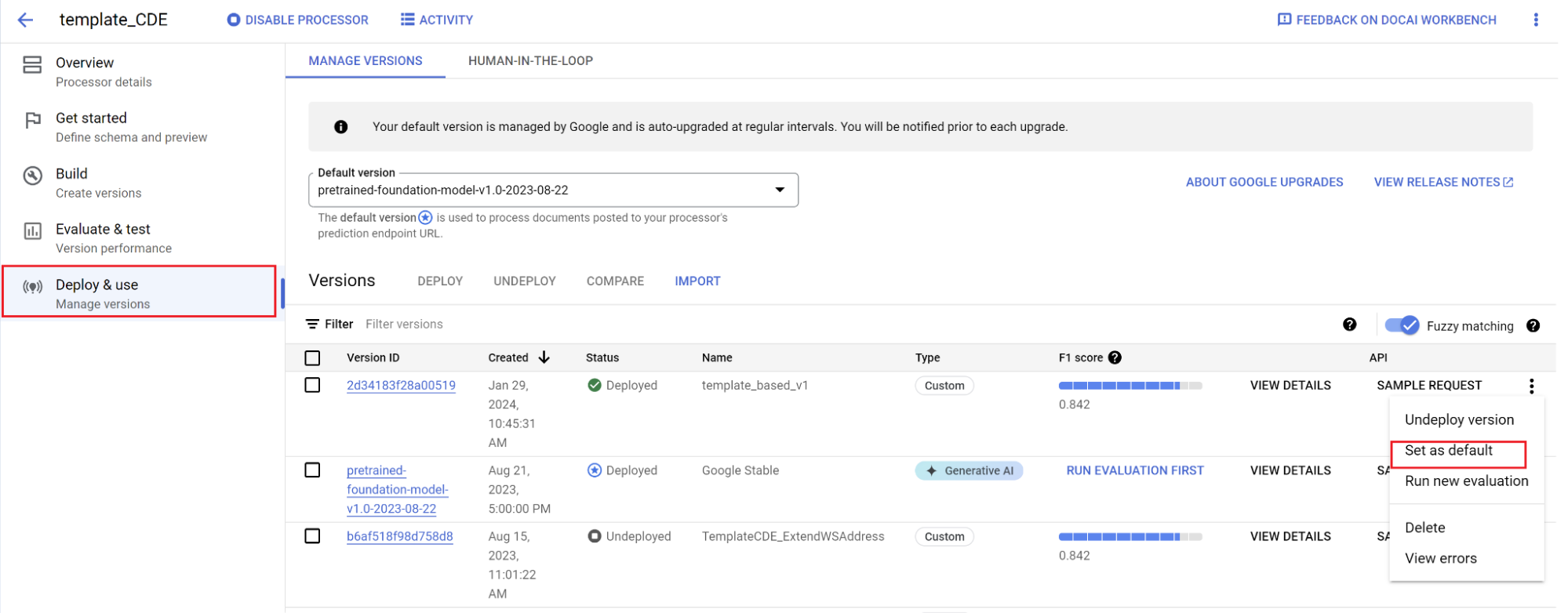
新しいバージョンをデフォルトとして設定します。
- [版を管理] に移動します。
- 選択してオプションを開き、[デフォルトに設定] を選択します。
モデルがデプロイされました。このプロセッサに送信されたドキュメントは、カスタム バージョンを使用します。モデルのパフォーマンスを評価して、追加のトレーニングが必要かどうかを確認できます。
評価参照
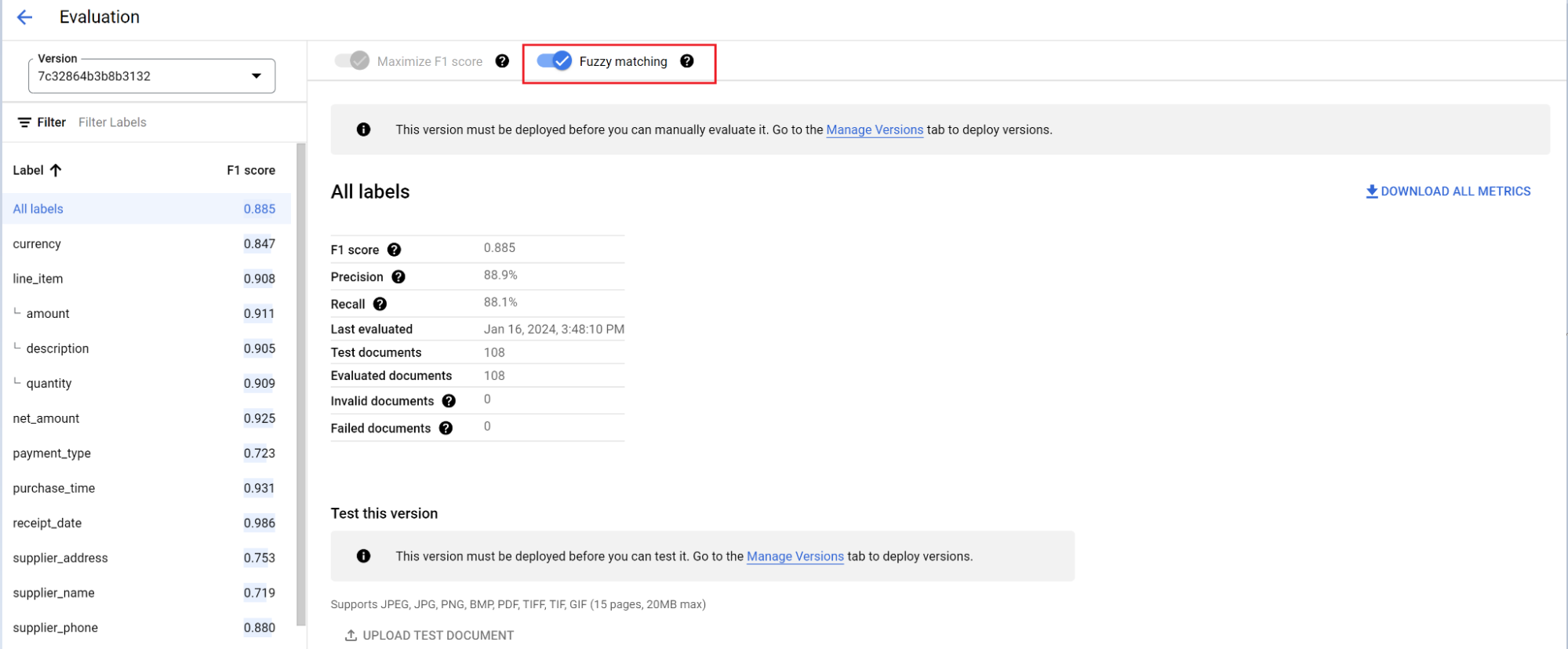
評価エンジンは、完全一致とファジー マッチングの両方を行うことができます。完全一致の場合、抽出された値が正解ラベルと完全に一致している必要があります。一致していない場合は、不一致としてカウントされます。
大文字と小文字の違いなど、わずかな違いがあるファジー マッチング抽出は、一致としてカウントされます。この設定は [評価] 画面で変更できます。
ファインチューニング
ファインチューニングでは、トレーニングに数百または数千のドキュメントを使用します。
ベスト プラクティスに沿ってプロセッサを作成し、抽出するフィールドを定義します。これは抽出の品質に影響するため、重要です。
自動ラベル付けを使用してドキュメントをインポートし、トレーニング セットとテストセットにドキュメントを割り当てます。
ドキュメント内のラベルを確認または編集します。
モデルをトレーニングする。
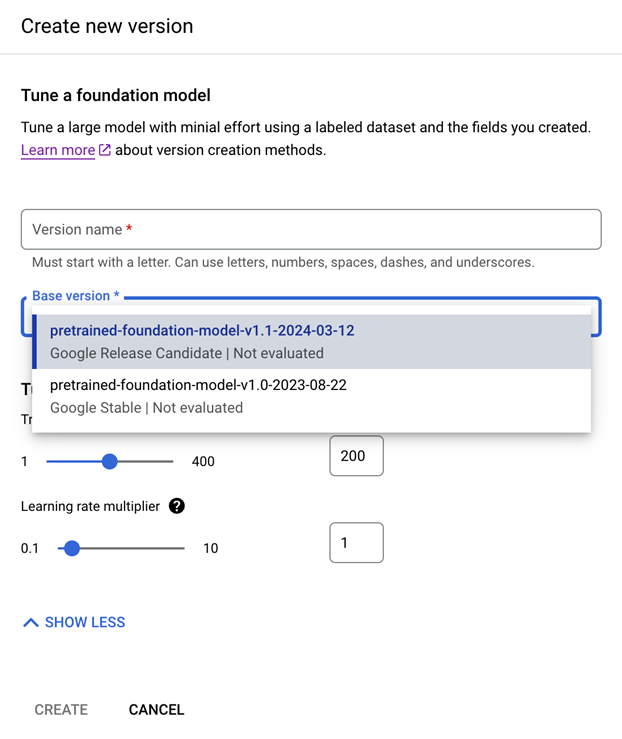
- [ビルド] タブを選択し、[ファインチューニング] ボックスで [新しいバージョンを作成] を選択します。
提供されたデフォルトのトレーニング パラメータまたは値を試します。結果が満足のいくものでない場合は、次の高度なオプションを試してください。
トレーニング ステップ(100 ~ 400): チューニング中にデータのバッチで重みが最適化される頻度を制御します。
- 値が小さすぎると、収束前にトレーニングが終了するリスク(過小適合)を示します。
- 値が高すぎると、トレーニング中にモデルが同じデータバッチを複数回認識し、過学習につながる可能性があります。
- ステップ数が少ないほど、トレーニング時間が短縮されます。カウントを増やすと、テンプレートのバリエーションが少ないドキュメントに役立ちます(バリエーションが多いドキュメントの場合はカウントを減らします)。
学習率乗数(0.1 ~ 10): トレーニング データでモデル パラメータを最適化する速度を制御します。これは、各トレーニング ステップのサイズにほぼ対応しています。
- 学習率が低いほど、各トレーニング ステップでのモデルの重みの変化が小さくなります。低すぎると、モデルが安定した解に収束しない可能性があります。
- レートが高いほど変化が大きいことを示します。レートが高すぎると、モデルが最適解を飛び越えて、最適でない解に収束する可能性があります。
- 学習率の選択はトレーニング時間に影響しません。
名前を指定し、必要なベース プロセッサ バージョンを選択して、[作成] を選択します。
評価: [評価とテスト] に移動し、トレーニングしたバージョンを選択して、[評価全体を表示] を選択します。
- ドキュメント全体と各フィールドの f1、適合率、再現率などの指標が表示されます。
- パフォーマンスが本番環境の目標を満たしているかどうかを判断します。満たしていない場合は、追加のトレーニング ドキュメントが必要になることがあります。
新しいバージョンをデフォルトとして設定します。
- [版を管理] に移動します。
- オプションを展開して [デフォルトとして設定] を選択します。
モデルがデプロイされ、このプロセッサに送信されたドキュメントでカスタム バージョンが使用されるようになりました。モデルのパフォーマンスを評価して、追加のトレーニングが必要かどうかを確認します。
基盤モデルを使用した自動ラベル付け
基盤モデルは、さまざまなドキュメント タイプのフィールドを正確に抽出できますが、追加のトレーニング データを提供して、特定のドキュメント構造に対するモデルの精度を向上させることもできます。
Document AI は、定義したラベル名と以前のアノテーションを使用して、自動ラベル付けで素早く簡単にドキュメントを大規模にラベル付けすることができます。
- カスタム プロセッサを作成したら、[スタートガイド] タブに移動します。
- [新しいフィールドを作成] を選択します。
ラベルにわかりやすく、区別できる名前を付けます。ドキュメントから値を直接取得するには [抽出] を選択します。システムによって推測された値を取得するには [導出] を選択します。これにより、基盤モデルの精度とパフォーマンスが向上します。
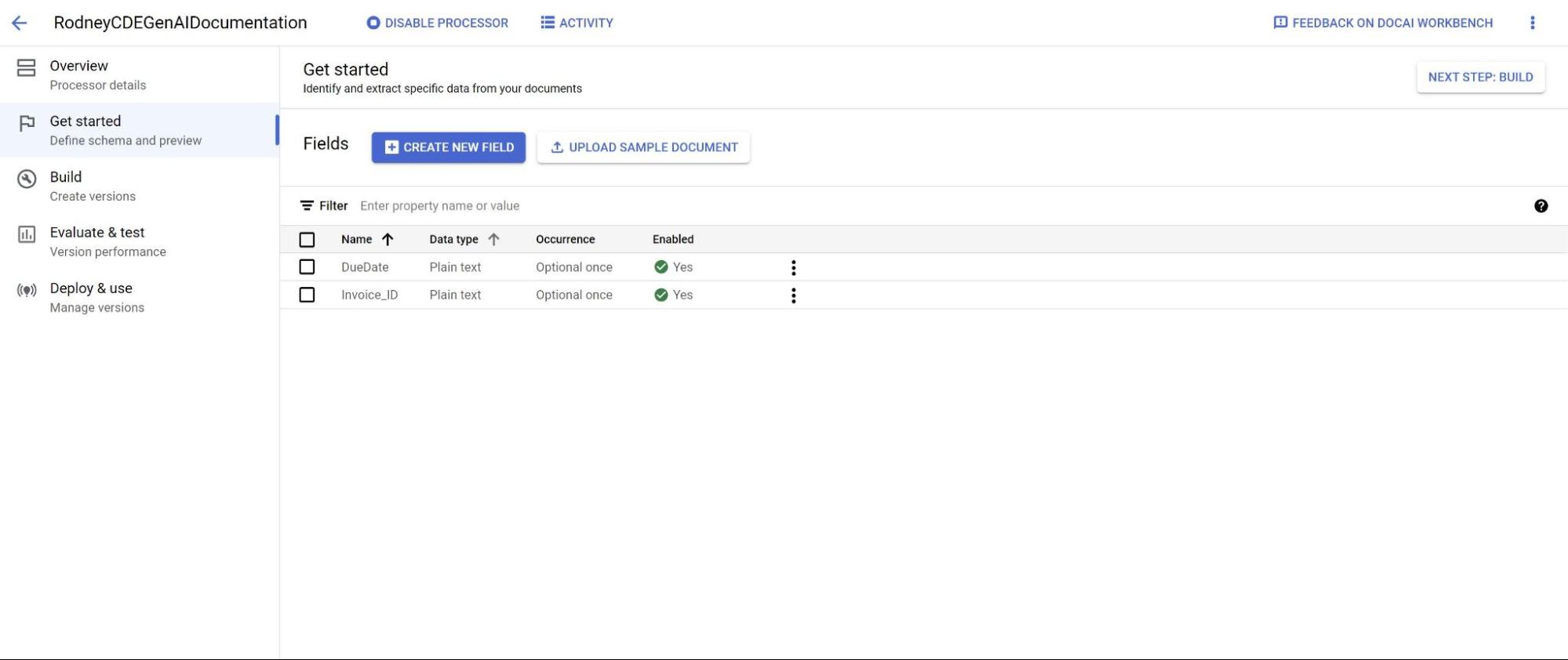
抽出の精度とパフォーマンスを高めるには、抽出するエンティティの種類の説明(各エンティティに追加されたコンテキスト、分析情報、事前知識など)を追加します。
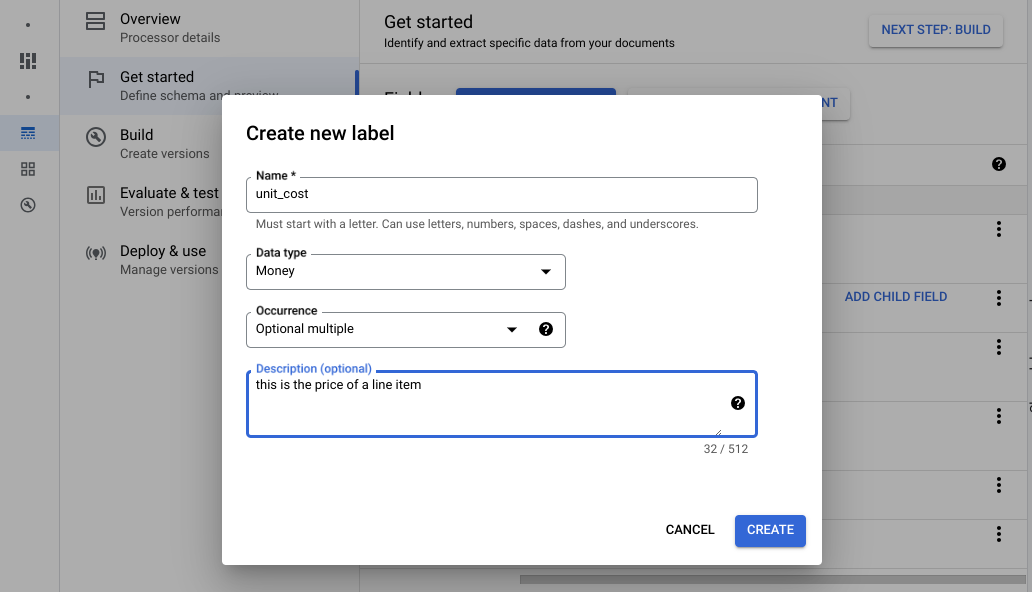
[ビルド] タブに移動し、[ドキュメントのインポート] を選択します。
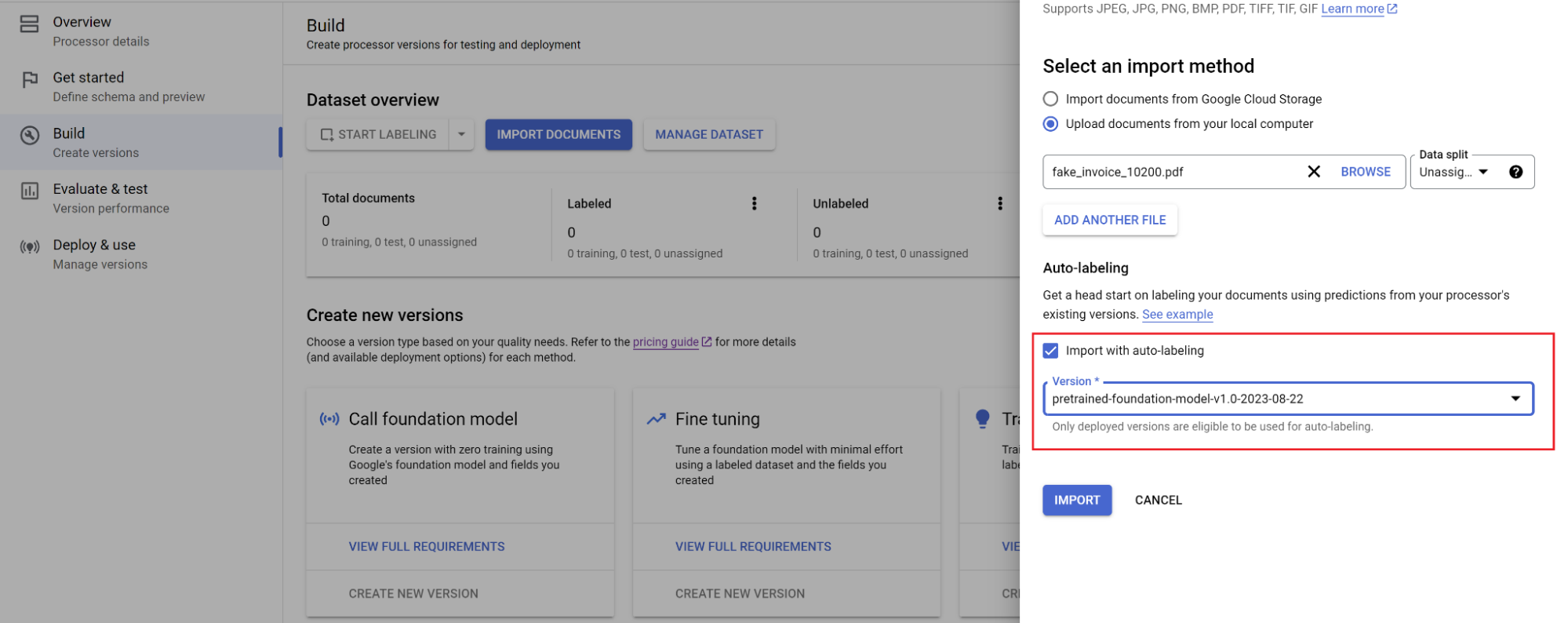
ドキュメントのパスと、ドキュメントのインポート先のセットを選択します。自動ラベル付けオプションをオンにして、基盤モデルを選択します。
[ビルド] タブで、[データセットを管理] を選択します。
インポートしたドキュメントが表示されたら、そのうちの 1 つを選択します。
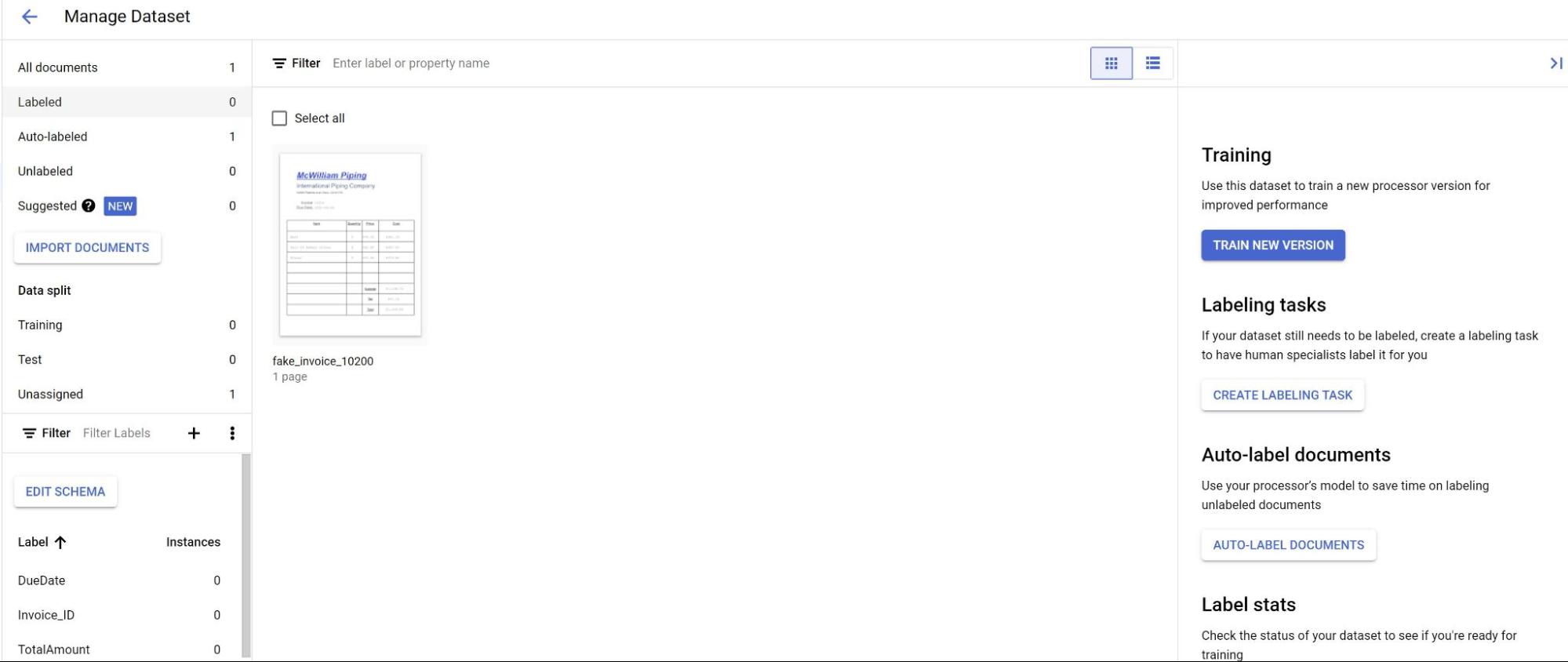
モデルからの予測が紫色のハイライト表示で示されます。
- モデルによって予測された各ラベルを確認し、正しいことを確認します。
不足しているフィールドがある場合は、それらも追加します。
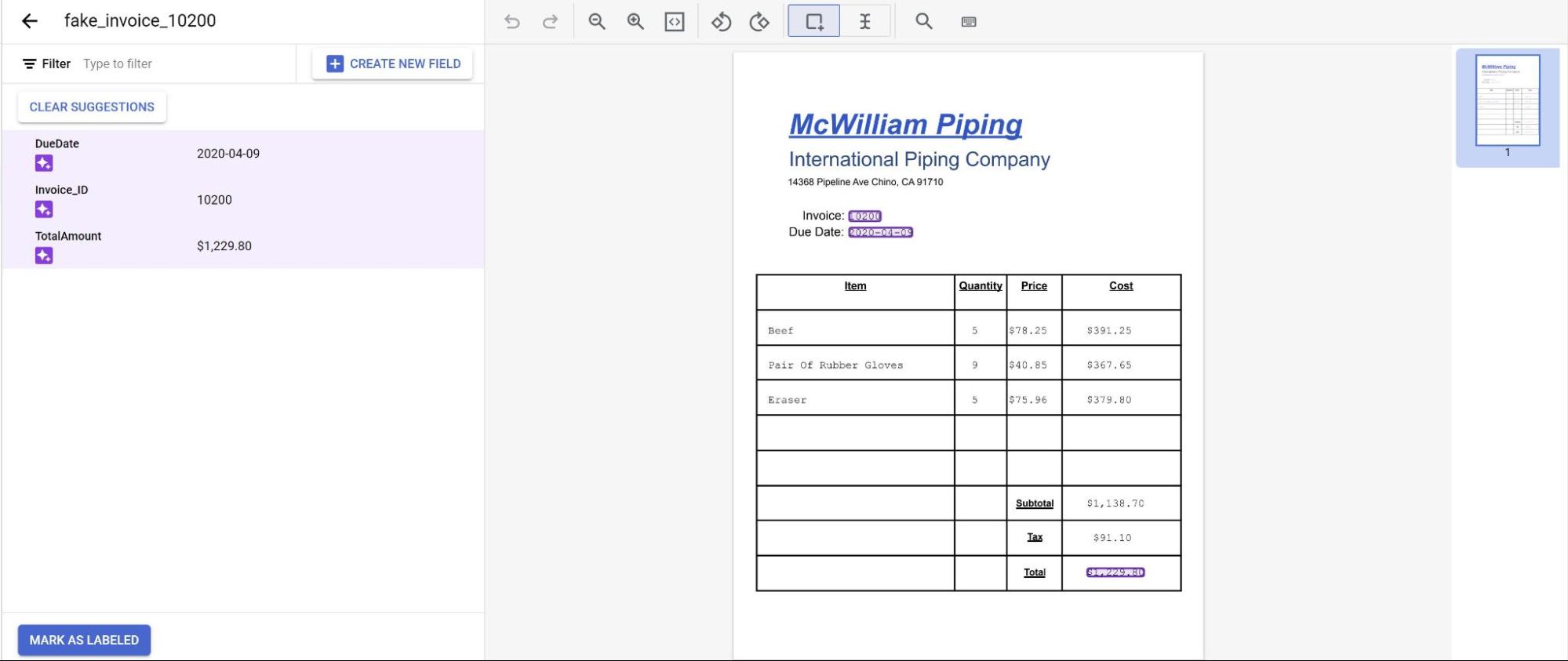
ドキュメントの審査が完了したら、[ラベル付きとしてマーク] を選択します。これで、ドキュメントをモデルで使用できるようになりました。
ドキュメントがテストセットまたはトレーニング セットのいずれかに含まれていることを確認します。
3 レベルのネスト
カスタム エクストラクタで 3 つのレベルのネストが提供されるようになりました。この機能により、複雑なテーブルの抽出が改善されます。
モデルタイプは、次の API 呼び出しで確認できます。
これらのレスポンスは ProcessorVersion で、v1beta3 プレビューの modelType フィールドが含まれています。
手順と例
次のサンプルを使用します。
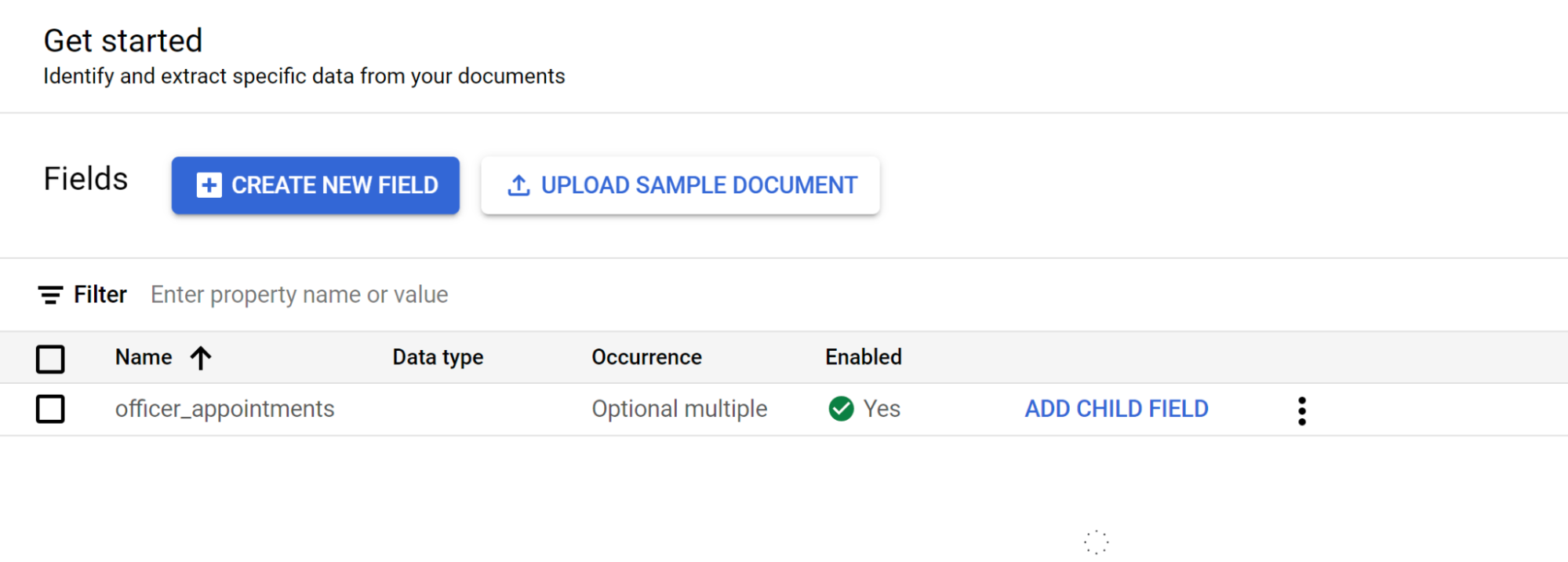
[始める] を選択し、フィールドを作成します。
- 最上位レベルを作成します。
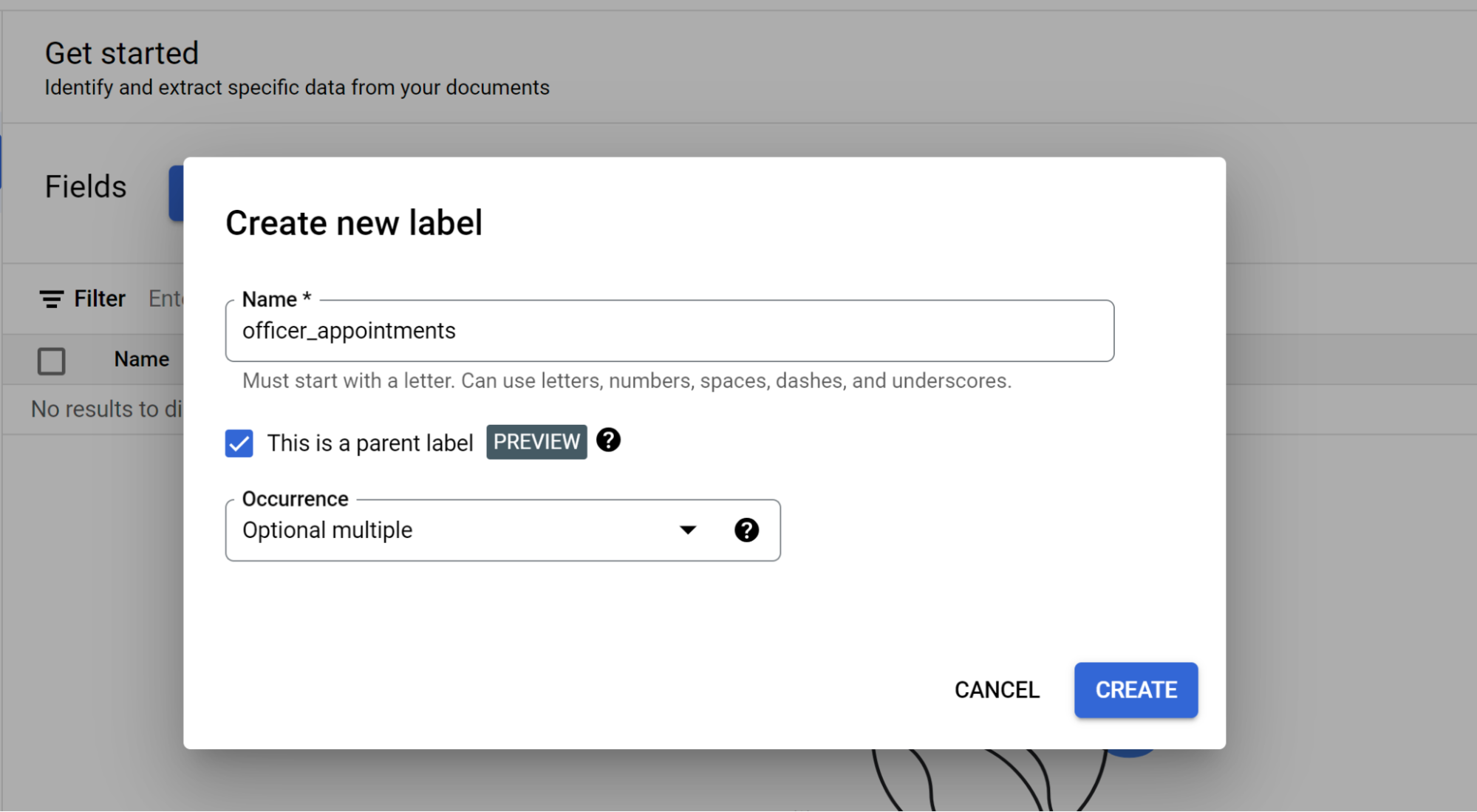
- このサンプルでは、
officer_appointmentsが使用されています。 - [これは親ラベルである] を選択します。
- [発生](
Optional multiple)を選択します。
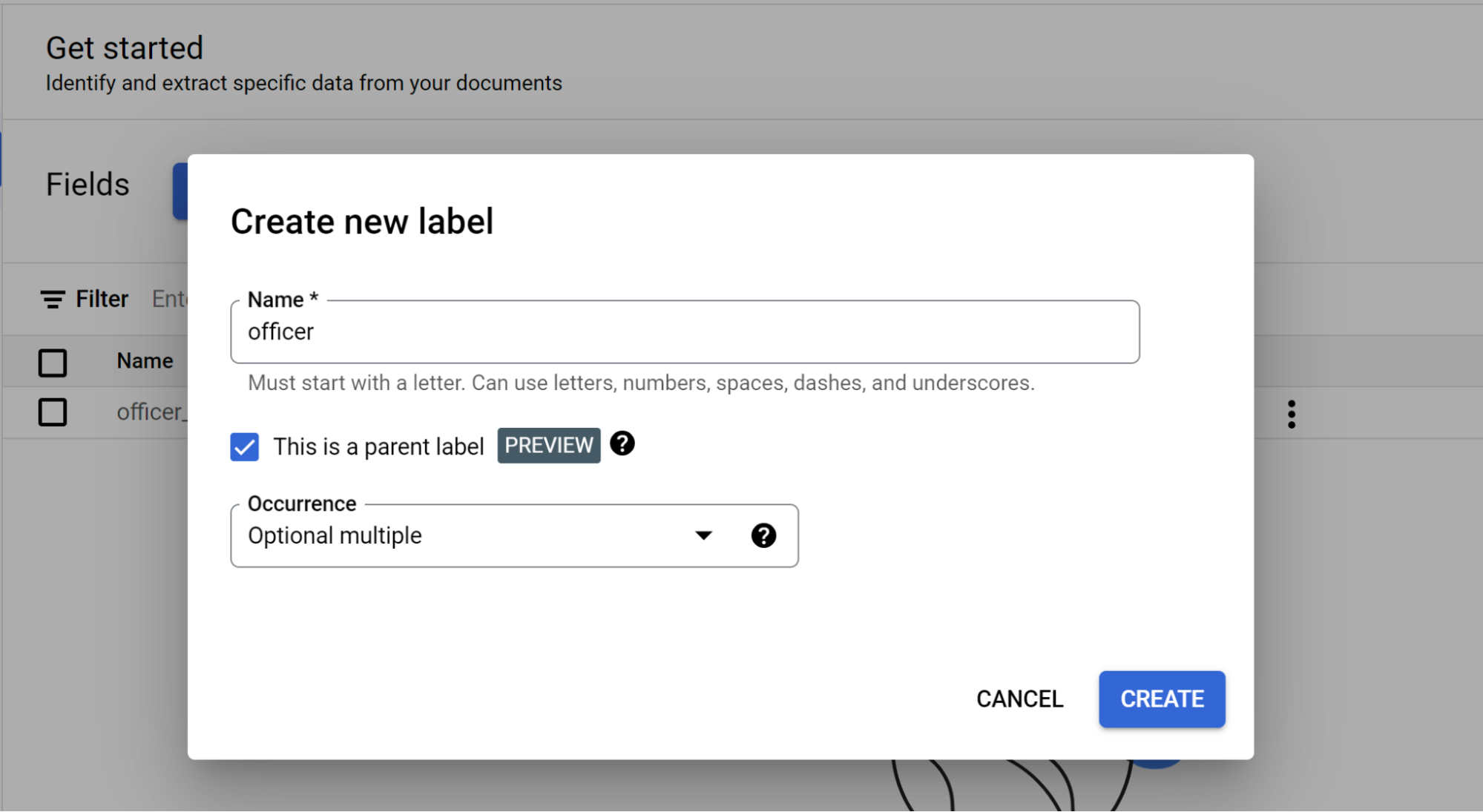
[子フィールドを追加] を選択します。第 2 レベルのラベルを作成できるようになりました。
- このレベルラベルの
officerを作成します。 - [これは親ラベルである] を選択します。
- [発生](
Optional multiple)を選択します。
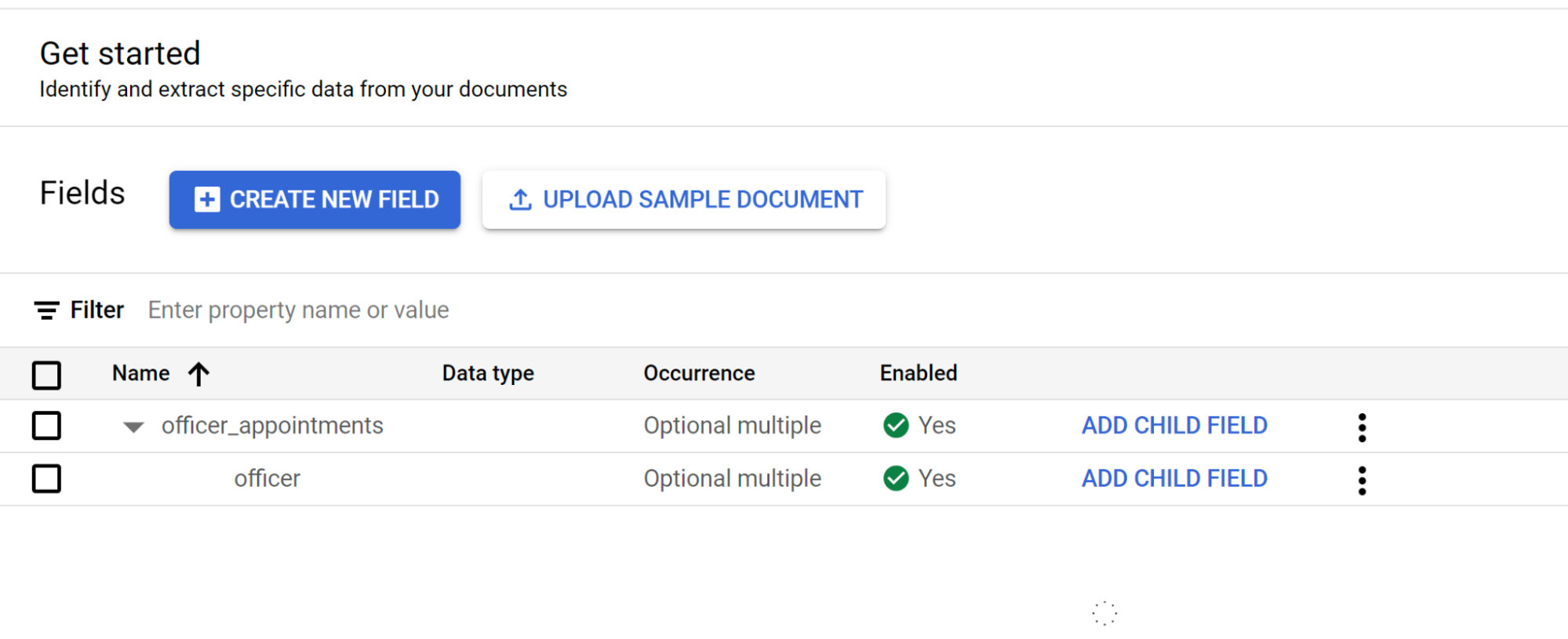
- このレベルラベルの
2 番目のレベルの
officerから [子フィールドを追加] を選択します。ネストの 3 番目のレベルの子ラベルを作成します。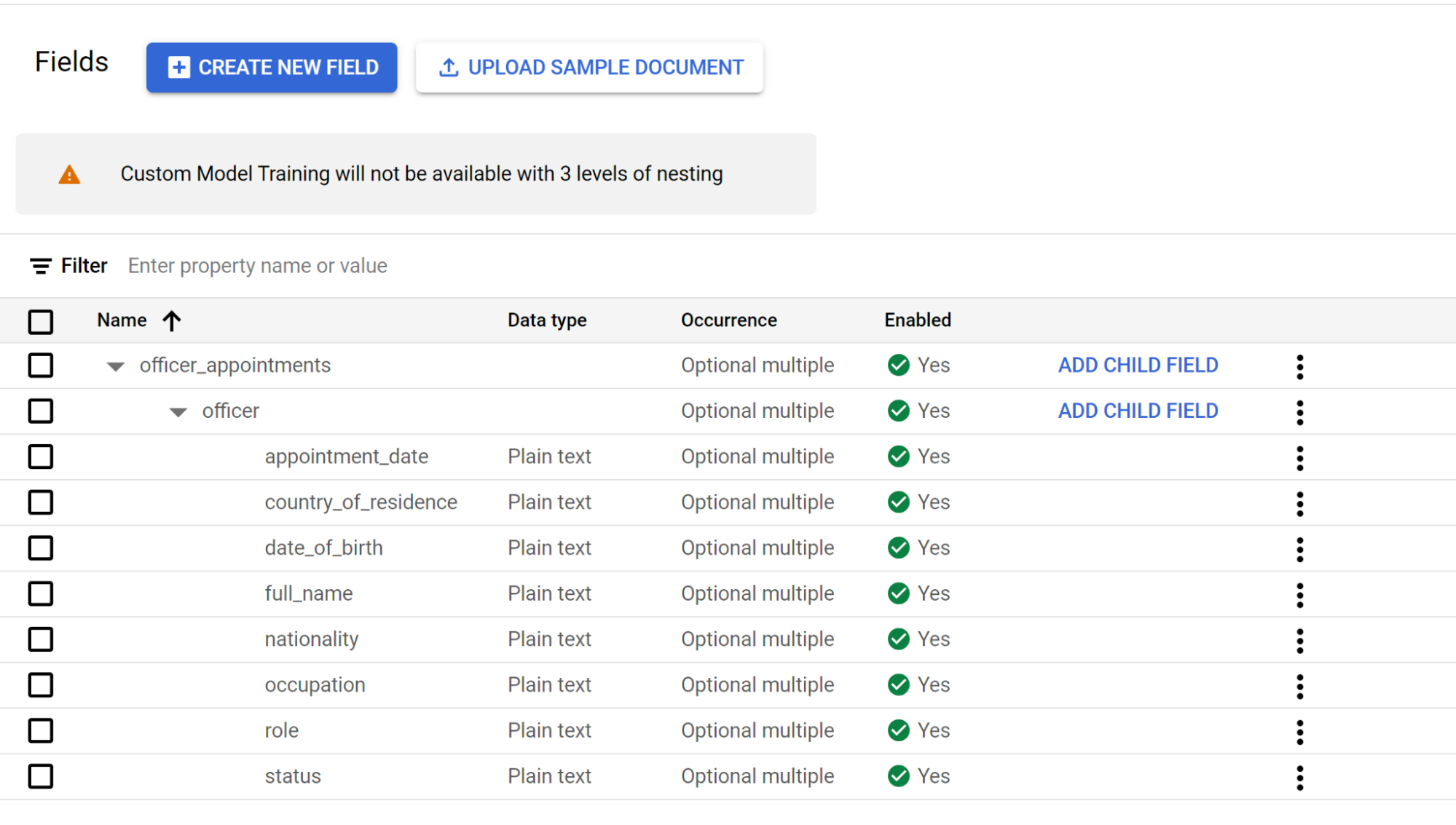
スキーマを設定すると、自動ラベル付けを使用して、3 つのレベルのネストを含むドキュメントから予測を取得できます。
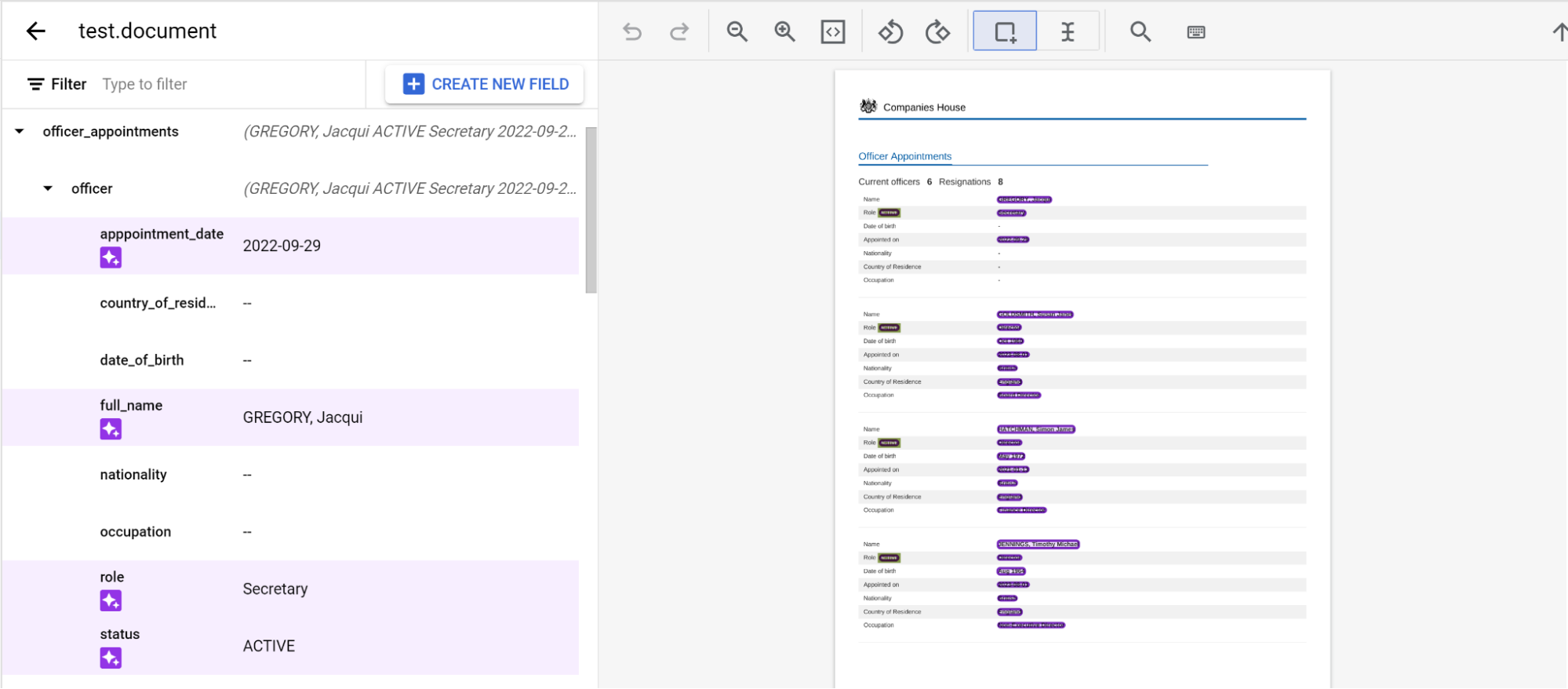
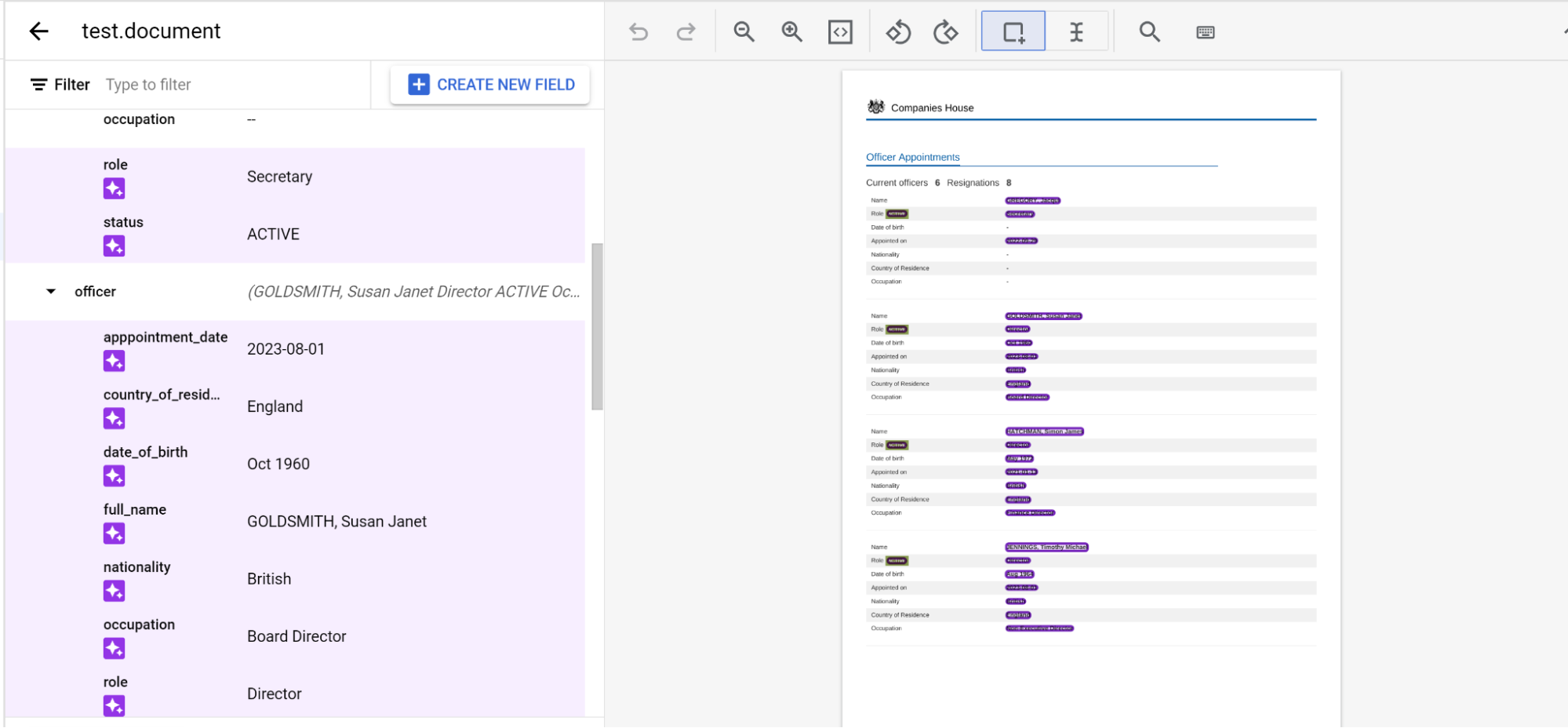
ページをまたぐネストされたエンティティにラベルを付ける
pretrained-foundation-model-v1.5-2025-05-05 プロセッサは、ページ間の 3 レベルのネストをサポートしています。
通常、エンティティにはページ全体にラベルが付けられます。注: ラベル付けされたエンティティは、ラベル付けされたページでのみ表示されます。ナビゲーション バーはページごとに変わります。親エンティティを固定すると、このナビゲーション バーは維持されます。
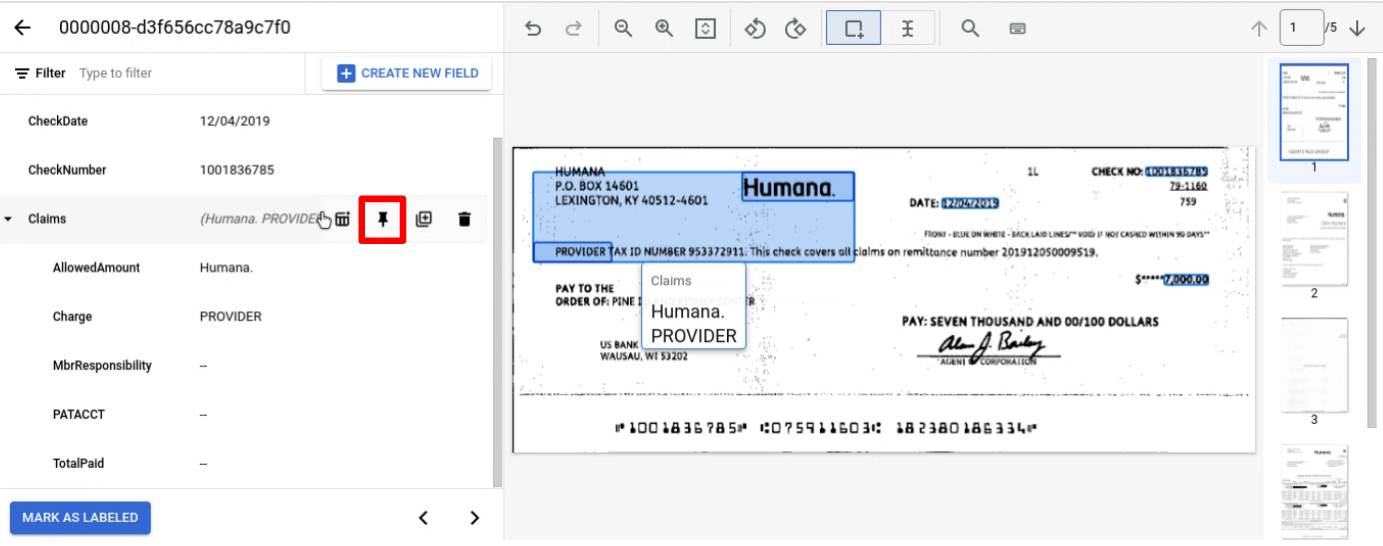
ページ間でラベル付けする子を持つ親エンティティを固定します。
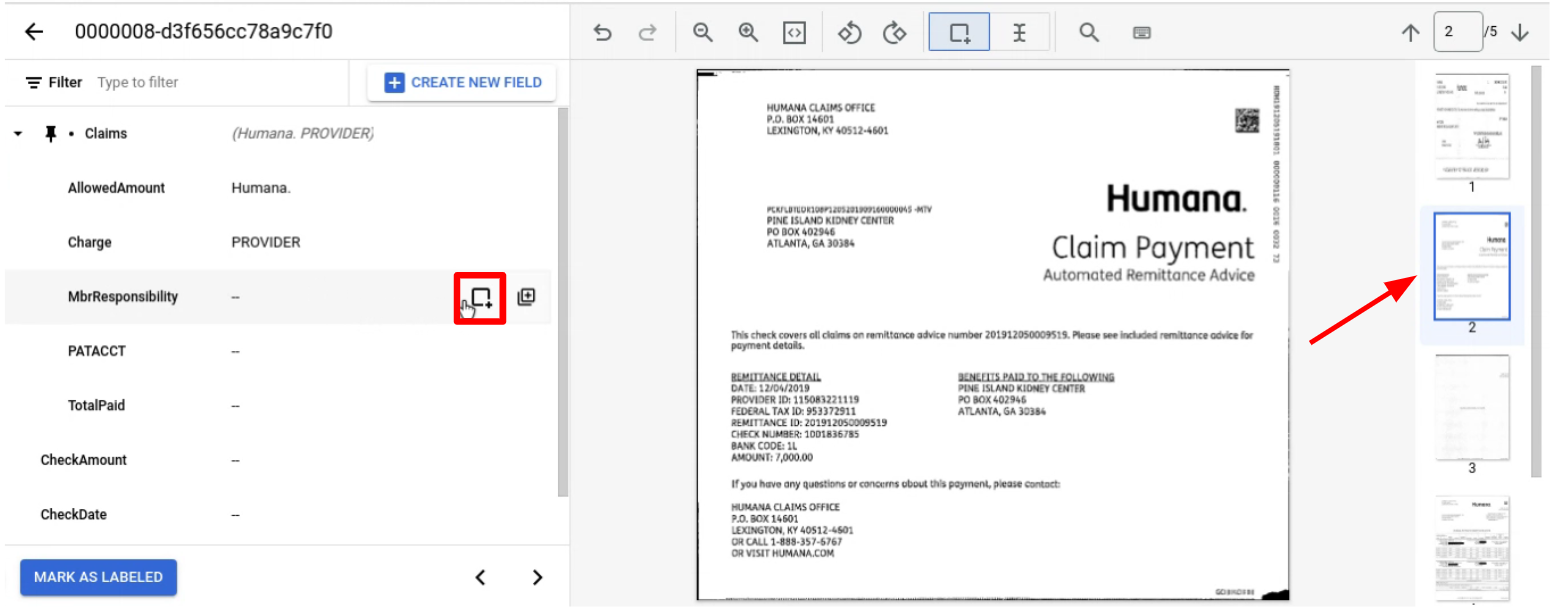
ラベルを付ける子エンティティを含むページに移動します。
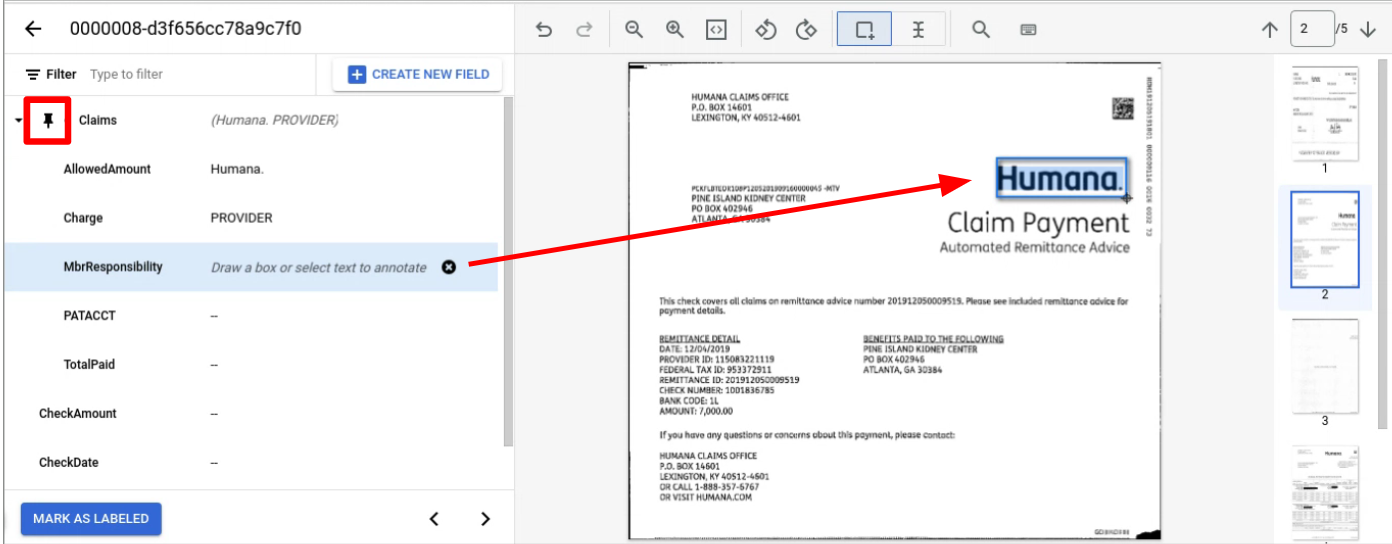
データセットの構成
プロセッサ バージョンのトレーニング、アップトレーニング、評価を行うには、ドキュメント データセットが必要です。Document AI プロセッサは、人間と同じように例から学習します。データセットは、パフォーマンスの面でプロセッサの安定性を高めます。トレーニング データセット
モデルとその精度を向上させるには、ドキュメントでデータセットをトレーニングします。モデルは、グラウンド トゥルースを含むドキュメントで構成されています。- ファインチューニングでは、
pretrained-foundation-model-v1.2-2024-05-10とpretrained-foundation-model-v1.3-2024-08-31のバージョンで新しいモデルをトレーニングするために、少なくとも 1 つのドキュメントが必要です。 - 少数ショットの場合は、5 つのドキュメントをおすすめします。
- ゼロショットでは、スキーマのみが必要です。
テスト データセット
テスト データセットは、モデルが F1 スコア(精度)を生成するために使用するものです。グラウンド トゥルースを含むドキュメントで構成されています。モデルの正答率を確認するには、グラウンド トゥルースを使用して、モデルの予測(モデルから抽出されたフィールド)と正解を比較します。テスト データセットには、pretrained-foundation-model-v1.2-2024-05-10 と pretrained-foundation-model-v1.3-2024-08-31 のドキュメントが少なくとも 1 つ必要です。
プロパティの説明を含むカスタム エクストラクタ
プロパティの説明を使用すると、ラベル付きフィールドの内容を説明してモデルをトレーニングできます。各エンティティに追加のコンテキストと分析情報を提供できます。これにより、モデルは指定した説明に一致するフィールドを照合してトレーニングを行い、抽出精度を向上させることができます。プロパティの説明は、親エンティティと子エンティティの両方に指定できます。
プロパティの説明の例としては、プロパティ値の位置情報やテキスト パターンなどがあります。これらは、ドキュメント内の潜在的な混乱の原因を解消するのに役立ちます。明確で正確なプロパティの説明は、特定のドキュメント構造やコンテンツのバリエーションに関係なく、より信頼性が高く一貫性のある抽出を促進するルールでモデルをガイドします。
プロセッサのドキュメント スキーマを更新する
プロパティの説明を設定する方法については、ドキュメント スキーマを更新するをご覧ください。
プロパティの説明を含む処理リクエストを送信する
ドキュメント スキーマに説明がすでに設定されている場合は、処理リクエストを送信するの手順に沿って処理リクエストを送信できます。
プロパティの説明を使用してプロセッサを微調整する
リクエストのデータを使用する前に、次のように置き換えます。
- LOCATION: プロセッサのロケーション(例:
-
)
us- 米国eu- 欧州連合
- PROJECT_ID: 実際の Google Cloud プロジェクト ID。
- PROCESSOR_ID: カスタム プロセッサの ID。
- DISPLAY_NAME: プロセッサの表示名。
- PRETRAINED_PROCESSOR_VERSION: プロセッサのバージョン ID。詳細については、プロセッサ バージョンを選択するをご覧ください。例:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- TRAIN_STEPS: モデルのファインチューニングのトレーニング ステップ。
- LEARN_RATE_MULTIPLIER: モデルのファインチューニングの学習率乗数。
- DOCUMENT_SCHEMA: プロセッサのスキーマ。DocumentSchema 表現を参照してください。
HTTP メソッドと URL:
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
リクエストの本文(JSON):
{
"rawDocument": {
"parent": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID",
"processor_version": {
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/DISPLAY_NAME",
"display_name": "DISPLAY_NAME",
"model_type": "MODEL_TYPE_GENERATIVE",
},
"base_processor_version": "projects/PROJECT_ID/locations/us/processors/PROCESSOR_ID/processorVersions/PRETRAINED_PROCESSOR_VERSION",
"foundation_model_tuning_options": {
"train_steps": TRAIN_STEPS,
"learning_rate_multiplier": LEARN_RATE_MULTIPLIER,
}
"document_schema": DOCUMENT_SCHEMA
}
}
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
シグネチャ検出機能付きカスタム エクストラクタ
(公開プレビュー)カスタム エクストラクタで署名検出がサポートされるようになりました。この機能を使用すると、ドキュメント内の署名の有無を検出できます。シグネチャ検出は、derived メソッドタイプを使用する場合にのみ使用できます。このようなエンティティには、エンティティ タイプ signature を使用してスキーマを指定できます。署名エンティティは、ドキュメントの視覚的な手がかりを使用して導出されます。
例と構成手順については、派生フィールドとシグネチャ検出を含むカスタム エクストラクタをクリックしてください。
派生フィールドを含むカスタム エクストラクタ
カスタム抽出ツールは派生フィールドをサポートしています。これにより、テキストを直接抽出するのではなく、ドキュメントのコンテキストに基づいてインテリジェントな推論または生成によってフィールドに入力されるように構成できます。これは、テキストに値が明示的に存在する必要がない、住所から国を推測する、ドキュメントを要約する、テーブル内のアイテムを数える、ID が本物かどうかを検出するなどのユースケースで使用できます。
例と構成手順については、派生フィールドとシグネチャ検出を含むカスタム エクストラクタをクリックしてください。
次のステップ
派生フィールドとシグネチャ検出を使用したカスタム エクストラクタについて学習する。