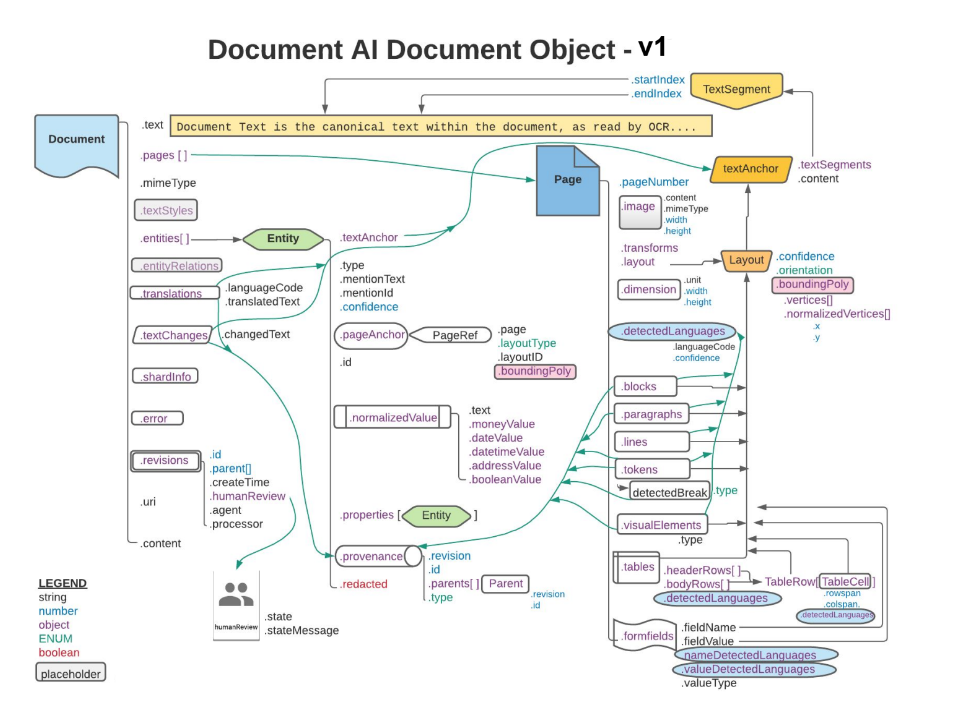
Processar a resposta
A resposta a uma solicitação de processamento contém um objeto Document
que contém tudo o que é conhecido sobre o documento processado, incluindo todas
as informações estruturadas que a IA de documentos conseguiu extrair.
Nesta página, explicamos o layout do objeto Document com documentos de exemplo e mapeamento de aspectos dos resultados de OCR para os elementos específicos do objeto JSON Document.
Ela também oferece exemplos de código de bibliotecas de cliente
e do SDK da Document AI Toolbox.
Esses exemplos de código usam o processamento on-line, mas a análise de objeto Document funciona
da mesma forma para o processamento em lote.
Use um visualizador JSON ou um utilitário de edição projetado especificamente para abrir ou fechar elementos. Analisar JSON bruto em um utilitário de texto simples é ineficiente.
Pontuações de texto, layout e qualidade
Confira um exemplo de documento de texto:

Confira o objeto de documento completo retornado pelo processador de OCR de documentos corporativos:
Essa saída de OCR também é sempre incluída na saída do processador da Document AI, já que o OCR é executado pelos processadores. Ele usa os dados de OCR atuais. Por isso, é possível inserir esses dados JSON usando a opção de documento inline nos processadores do Document AI.
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
Estes são alguns dos campos importantes:
Texto bruto
O campo text contém o texto reconhecido pelo Document AI.
Esse texto não contém nenhuma estrutura de layout além de espaços, guias e
alimentações de linha. Esse é o único campo que armazena as informações textuais de um documento
e serve como a fonte da verdade do texto do documento. Outros
campos podem se referir a partes do campo de texto por posição (startIndex e endIndex).
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
Tamanho da página e idiomas
Cada page no objeto de documento corresponde a uma
página física do documento de exemplo. O exemplo de saída JSON contém uma
página porque é uma única imagem PNG.
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
- O campo
pages[].detectedLanguages[]contém os idiomas encontrados em uma determinada página, além da pontuação de confiança.
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
Dados de OCR
O OCR de documentos da IA detecta texto com várias granularidades ou organizações na página, como blocos de texto, parágrafos, tokens e símbolos. O nível de símbolo é opcional, se configurado para gerar dados no nível do símbolo. Todos são membros do objeto da página.
Cada elemento tem um layout correspondente que
descreve a posição e o texto dele. Elementos visuais que não são de texto
(como caixas de seleção) também estão no nível da página.
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
O texto bruto é mencionado no objeto textAnchor,
que é indexado na string de texto principal com startIndex e endIndex.
Para
boundingPoly, o canto superior esquerdo da página é a origem(0,0). Os valores positivos de X estão à direita, e os valores positivos de Y estão para baixo.O objeto
verticesusa as mesmas coordenadas da imagem original, enquantonormalizedVerticesestá no intervalo[0,1]. Há uma matriz de transformação que indica a correção de distorção das medidas e outros atributos da normalização da imagem.
- Para desenhar a
boundingPoly, desenhe segmentos de linha de um vértice para o próximo. Em seguida, feche o polígono desenhando um segmento de linha do último vértice de volta ao primeiro. O elemento orientation do layout indica se o texto foi girado em relação à página.
Para ajudar você a visualizar a estrutura do documento, as imagens a seguir mostram polígonos
de delimitação para page.paragraphs,
page.lines e page.tokens.
Parágrafos

Linhas

Tokens

Bloqueios

O processador Enterprise Document OCR pode realizar a avaliação de qualidade de um documento com base na legibilidade.
- Defina o campo
processOptions.ocrConfig.enableImageQualityScorescomotruepara receber esses dados na resposta da API.
Essa avaliação de qualidade é um índice de qualidade em [0, 1], em que 1 significa qualidade perfeita.
O índice de qualidade é retornado no campo Page.imageQualityScores.
Todos os defeitos detectados são listados como quality/defect_* e classificados em ordem
decrescente pelo valor de confiança.
Confira um PDF que está muito escuro e desfocado para ser lido com conforto:
Confira as informações de qualidade do documento retornadas pelo processador Enterprise Document OCR:
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Amostras de código
Os exemplos de código a seguir demonstram como enviar uma solicitação de processamento e, em seguida, ler e imprimir os campos no terminal:
Java
Para mais informações, consulte a documentação de referência da API Document AI Java.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Node.js
Para mais informações, consulte a documentação de referência da API Document AI Node.js.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Python
Para mais informações, consulte a documentação de referência da API Document AI Python.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Formulários e tabelas
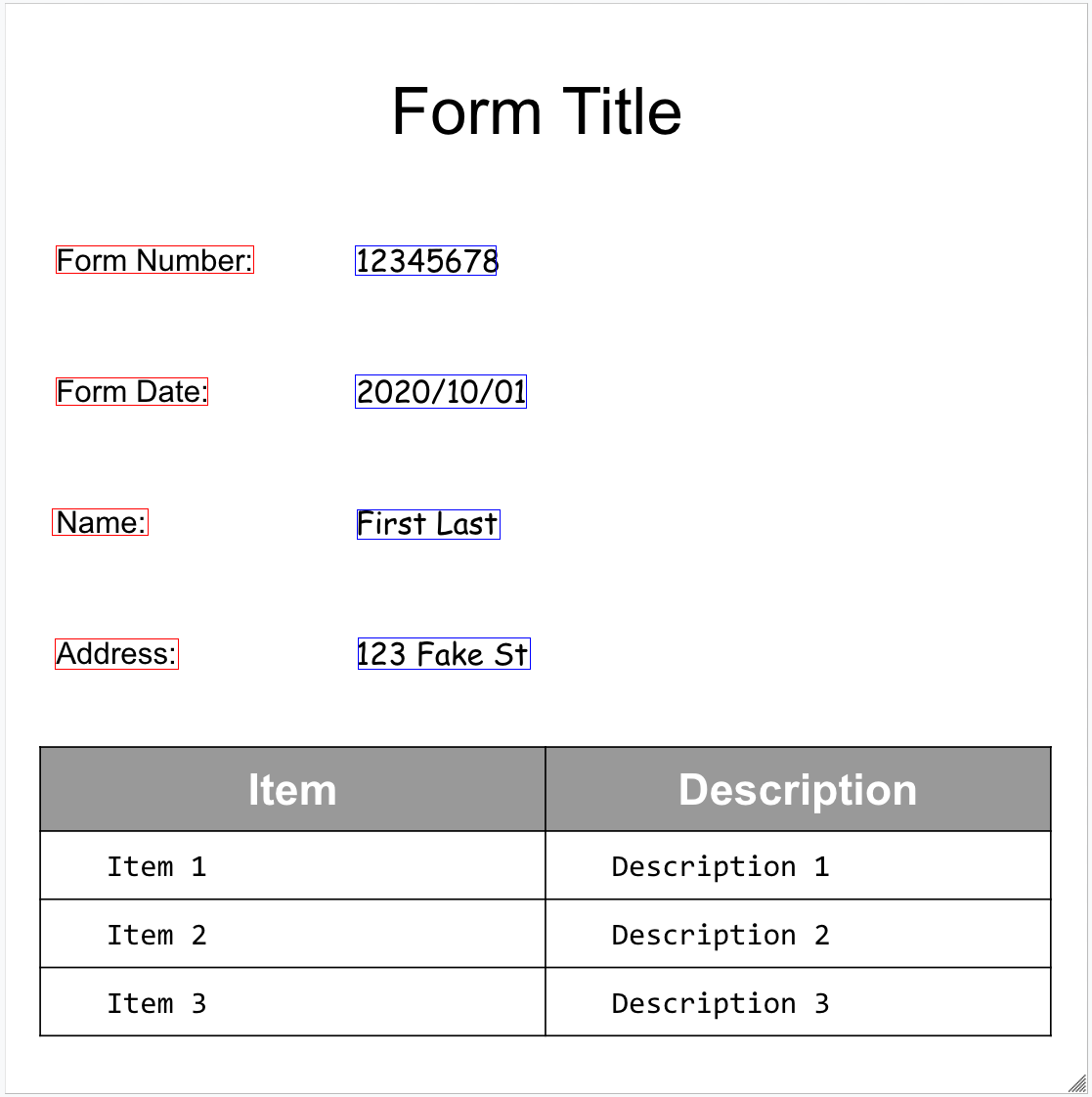
Confira nosso exemplo de formulário:
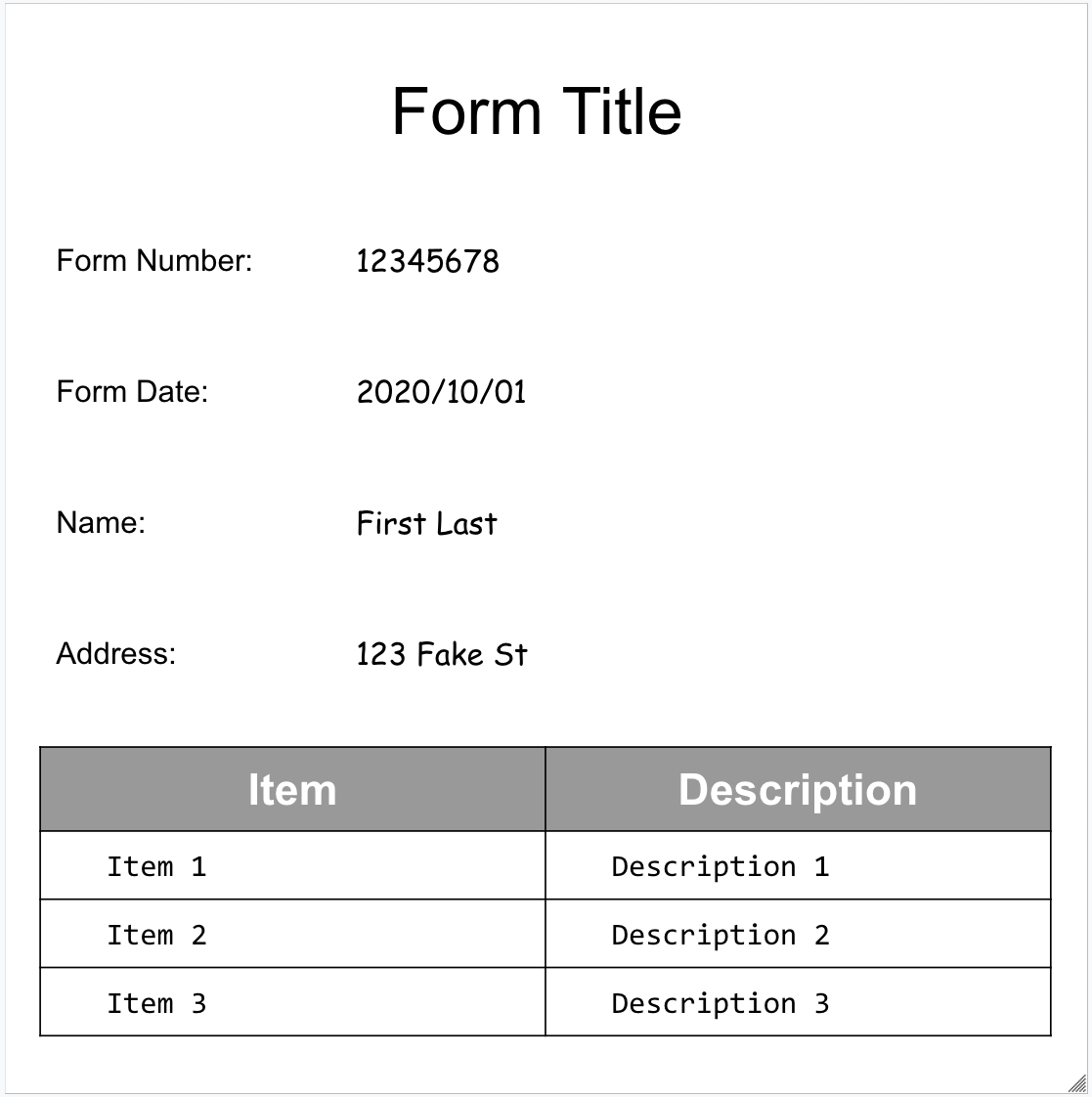
Confira o objeto de documento completo retornado pelo analisador de formulários:
Estes são alguns dos campos importantes:
O Parser de formulários pode detectar FormFields
na página. Cada campo de formulário tem um nome e um valor. Eles também são chamados de
pares de chave-valor (KVP, na sigla em inglês). Os KVPs são diferentes das entidades (esquemas) em outros extratores:
Os nomes das entidades são configurados. As chaves em KVPs são literalmente o texto da chave no documento.
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
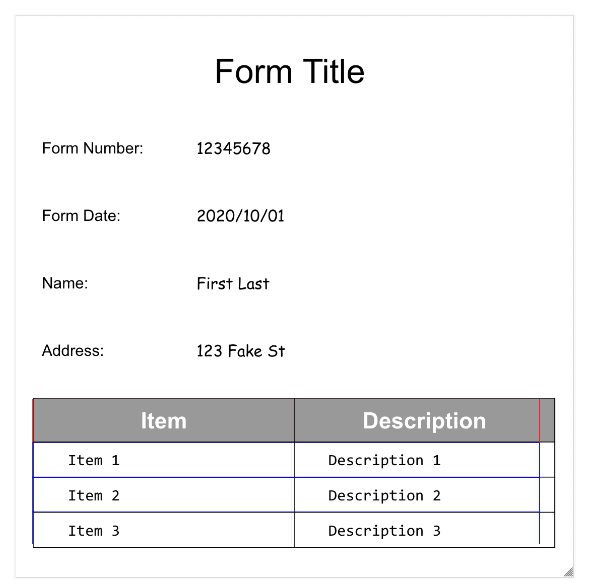
- A Document AI também pode detectar
Tablesna página.
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
A extração de tabelas no Parser de formulários reconhece apenas tabelas simples,
aquelas sem células que abrangem linhas ou colunas. Portanto, rowSpan e colSpan são sempre 1.
A partir da versão
pretrained-form-parser-v2.0-2022-11-10do processador, o Analisador de formulários também pode reconhecer entidades genéricas. Para mais informações, consulte Parsador de formulários.Para ajudar você a visualizar a estrutura do documento, as imagens a seguir mostram os polígonos delimitadores de
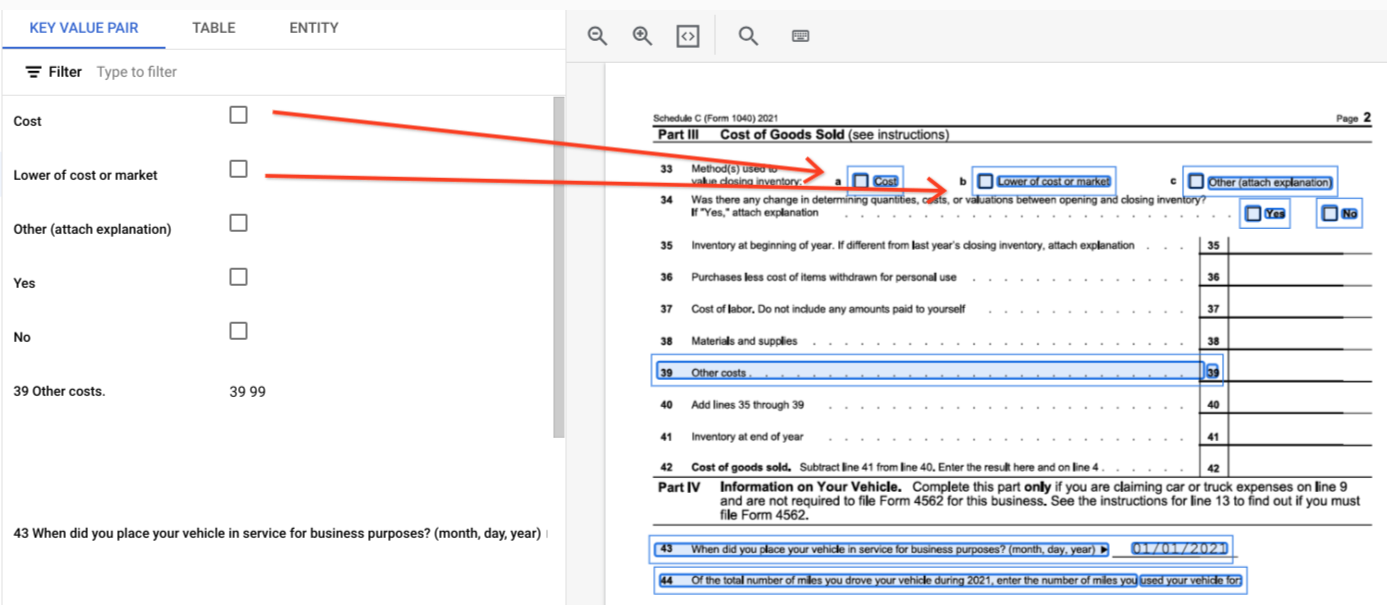
page.formFieldsepage.tables.Caixas de seleção em tabelas. O analisador de formulários pode digitalizar caixas de seleção de imagens e PDFs como KVPs. Exemplo de digitalização de caixas de seleção como um par de chave-valor.
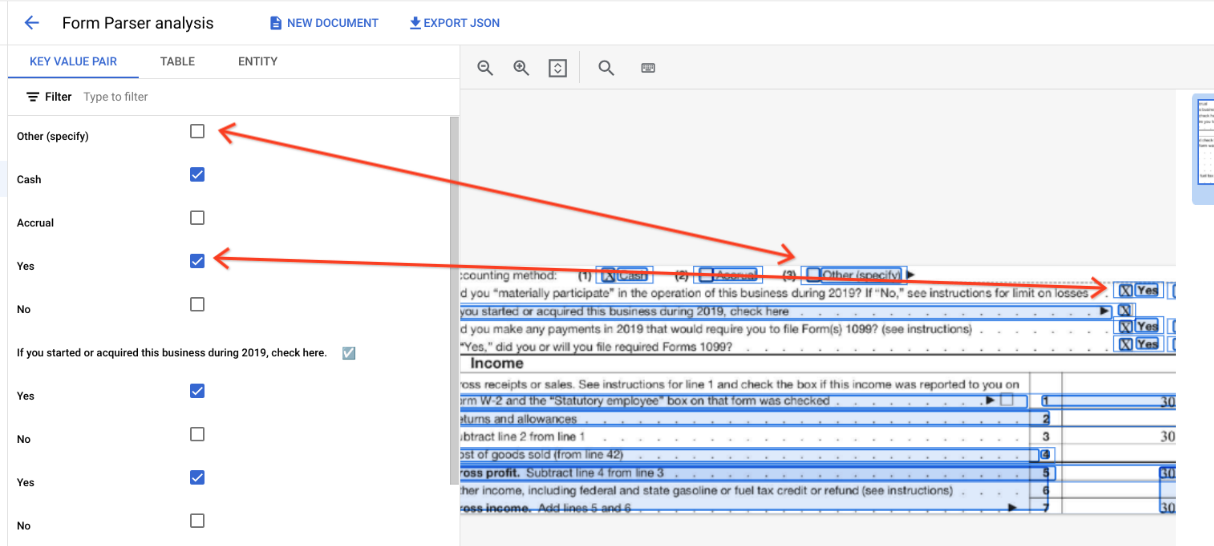
Fora das tabelas, as caixas de seleção são representadas como elementos visuais no Parser de formulários. Destaque das caixas quadradas com marcações de seleção na interface e unicode ✓ no JSON.
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
Nas tabelas, as caixas de seleção aparecem como caracteres Unicode, como ✓ (ativada) ou ☐ (desativada).
As caixas de seleção preenchidas têm o valor filled_checkbox:
under pages > x > formFields > x > fieldValue > valueType.. As caixas de seleção
desmarcadas têm o valor unfilled_checkbox.
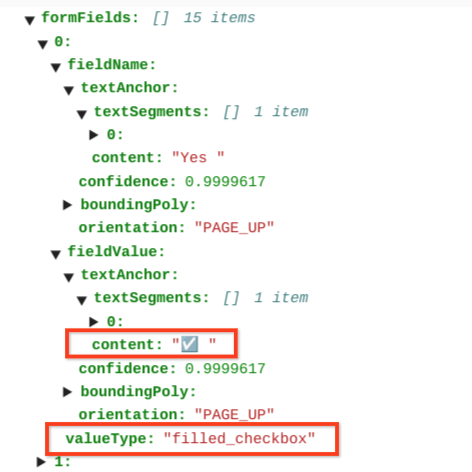
Os campos de conteúdo mostram o valor do conteúdo da caixa de seleção como destacado ✓ no
caminho pages>formFields>x>fieldValue>textAnchor>content.
Para ajudar você a visualizar a estrutura do documento, as imagens a seguir desenham polígonos
limitadores para page.formFields e page.tables.
Campos do formulário
Tabelas
Amostras de código
Os exemplos de código a seguir demonstram como enviar uma solicitação de processamento e, em seguida, ler e imprimir os campos no terminal:
Java
Para mais informações, consulte a documentação de referência da API Document AI Java.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Node.js
Para mais informações, consulte a documentação de referência da API Document AI Node.js.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Python
Para mais informações, consulte a documentação de referência da API Document AI Python.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Entidades, entidades aninhadas e valores normalizados
Muitos dos processadores especializados extraem dados estruturados que são baseados em um
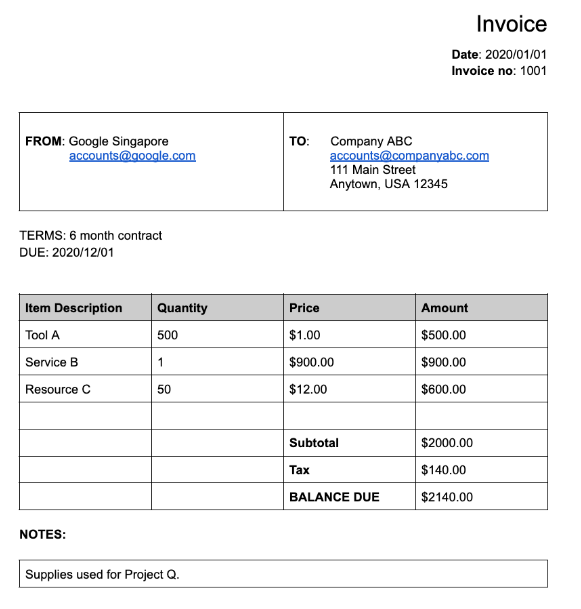
esquema bem definido. Por exemplo, o analisador de faturas
detecta campos específicos, como invoice_date e supplier_name. Confira um
exemplo de fatura:
Confira o objeto de documento completo retornado pelo parser de faturas:
Estas são algumas das partes importantes do objeto de documento:
Campos detectados:
Entitiescontém os campos que o processador conseguiu detectar, por exemplo, oinvoice_date:{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }Para alguns campos, o processador também normaliza o valor. Neste exemplo, a data foi normalizada de
2020/01/01para2020-01-01.Normalização: para muitos campos específicos com suporte, o processador também normaliza o valor e retorna um
entity. O camponormalizedValueé adicionado ao campo extraído bruto recebido pelotextAnchorde cada entidade. Assim, ele normaliza o texto literal, muitas vezes dividindo o valor do texto em subcampos. Por exemplo, uma data como 1º de setembro de 2024 seria representada como:
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
Neste exemplo, a data foi normalizada de 2020/01/01 para 2020-01-01, um formato padronizado para reduzir o pós-processamento e permitir a conversão para o formato escolhido.
Os endereços também são frequentemente normalizados, o que divide os elementos do endereço em campos individuais. Os números são normalizados com um número inteiro ou de ponto
flutuante como normalizedValue.
- Enriquecimento: alguns processadores e campos também oferecem suporte a enriquecimento.
Por exemplo, o
supplier_nameoriginal no documentoGoogle Singaporefoi normalizado em relação ao Enterprise Knowledge Graph paraGoogle Asia Pacific, Singapore. Além disso, como o Enterprise Knowledge Graph contém informações sobre o Google, a Document AI infere osupplier_address, mesmo que ele não esteja presente no documento de exemplo.
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
Campos aninhados: é possível criar um esquema (campos) aninhado declarando primeiro uma entidade como mãe e, em seguida, criando entidades filhas na mãe. A resposta de análise para o elemento pai inclui os campos filhos no elemento
propertiesdo campo pai. No exemplo abaixo,line_itemé um campo pai que tem dois campos filhos:line_item/descriptioneline_item/quantity.{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
Os seguintes analisadores seguem essa regra:
- Extrair (extrator personalizado)
- Legado
- Analisador de extrato bancário
- Analisador de despesas
- Analisador de faturas
- Analisador de holerite
- Analisador W2
Amostras de código
Os exemplos de código abaixo demonstram como enviar uma solicitação de processamento e, em seguida, ler e imprimir os campos de um processador especializado para o terminal:
Java
Para mais informações, consulte a documentação de referência da API Document AI Java.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Node.js
Para mais informações, consulte a documentação de referência da API Document AI Node.js.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Python
Para mais informações, consulte a documentação de referência da API Document AI Python.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Extrator de documentos personalizado
O processador do extrator de documentos personalizado pode extrair entidades personalizadas de documentos que não têm um processador pré-treinado disponível. Isso pode ser feito treinando um modelo personalizado ou usando modelos de base da IA generativa para extrair entidades nomeadas sem nenhum treinamento. Para mais informações, consulte Criar um extrator de documentos personalizado no console.
- Se você treinar um modelo personalizado, o processador poderá ser usado da mesma forma que um processador de extração de entidade pré-treinado.
- Se você usar um modelo de base, poderá criar uma versão do processador para extrair entidades específicas para cada solicitação ou configurá-lo para cada solicitação.
Para informações sobre a estrutura de saída, consulte Entidades, entidades aninhadas e valores normalizados.
Amostras de código
Se você estiver usando um modelo personalizado ou criou uma versão do processador usando um modelo de base, use as amostras de código de extração de entidades.
O exemplo de código a seguir demonstra como configurar entidades específicas para um extrator de documentos personalizado do modelo de base por solicitação e imprimir as entidades extraídas:
Python
Para mais informações, consulte a documentação de referência da API Document AI Python.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Resumo
O processador de resumo usa modelos básicos de IA generativa para resumir o texto extraído de um documento. O comprimento e o formato da resposta podem ser personalizados das seguintes maneiras:
- Comprimento
BRIEF: um breve resumo de uma ou duas frasesMODERATE: um resumo de um parágrafoCOMPREHENSIVE: a opção mais longa disponível
- Formatar
É possível criar uma versão do processador para um comprimento e formato específicos ou configurá-la por solicitação.
O texto resumido aparece em Document.entities.normalizedValue.text. Confira um exemplo completo de arquivo JSON de saída em Exemplo de saída do processador.
Para mais informações, consulte Criar um resumo de documentos no console.
Amostras de código
O exemplo de código abaixo demonstra como configurar um comprimento e um formato específicos em uma solicitação de processamento e imprimir o texto resumido:
Python
Para mais informações, consulte a documentação de referência da API Document AI Python.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Divisão e classificação
Aqui está um PDF composto de 10 páginas com diferentes tipos de documentos e formulários:
Confira o objeto de documento completo retornado pelo classificador e divisor de documentos de empréstimo:
Cada documento detectado pelo divisor é representado por um
entity. Exemplo:
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchorindica que este documento tem duas páginas.pageRefs[].pageé baseado em zero e é o índice do campodocument.pages[].Entity.typeespecifica que este documento é um formulário 1040 Schedule SE. Para acessar uma lista completa de tipos de documentos que podem ser identificados, consulte Tipos de documentos identificados na documentação do processador.
Para mais informações, consulte Comportamento dos divisores de documentos.
Amostras de código
Os divisores identificam os limites da página, mas não dividem o documento de entrada para você. É possível usar o Document AI Toolbox para dividir fisicamente um arquivo PDF usando os limites de página. Os exemplos de código a seguir imprimem os intervalos de páginas sem dividir o PDF:
Java
Para mais informações, consulte a documentação de referência da API Document AI Java.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Node.js
Para mais informações, consulte a documentação de referência da API Document AI Node.js.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Python
Para mais informações, consulte a documentação de referência da API Document AI Python.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Document processado.
Python
Para mais informações, consulte a documentação de referência da API Document AI Python.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Document AI Toolbox
A Document AI Toolbox é um SDK para Python que oferece funções de utilitário
para gerenciar, manipular e extrair informações da resposta do documento.
Ele cria um objeto de documento "encapsulado" a partir de uma resposta de documento processada de arquivos JSON no
Cloud Storage, arquivos JSON locais ou saída diretamente do método
process_document().
Ele pode realizar as seguintes ações:
- Combine arquivos JSON fragmentados
Documentdo processamento em lote em um único documento "encapsulado". - Exporte os fragmentos como um
Documentunificado. -
Receba a saída
Documentde: - Acesse o texto de
Pages,Lines,Paragraphs,FormFieldseTablessem processar informaçõesLayout. - Pesquise um
Pagesque contenha uma string de destino ou que corresponda a uma expressão regular. - Pesquise
FormFieldspelo nome. - Pesquise
Entitiespor tipo. - Converta
Tablesem um Dataframe ou CSV do Pandas. - Insira
EntitieseFormFieldsem uma tabela do BigQuery. - Divida um arquivo PDF com base na saída de um processador de classificação/separação.
- Extraia a imagem
EntitiesdasDocumentcaixas delimitadoras. -
Converta
Documentspara e de formatos usados com frequência:- API Cloud Vision
AnnotateFileResponse - hOCR
- Formatos de processamento de documentos de terceiros
- API Cloud Vision
- Crie lotes de documentos para processamento em uma pasta do Cloud Storage.
Exemplos de código
Os exemplos de código abaixo demonstram como usar a Document AI Toolbox.