Pour de nombreux champs spécifiques acceptés, Document AI renvoie également un entity.normalizedValue en plus du champ brut extrait obtenu via le textAnchor de chaque entité. Elle normalise le texte littéral. La normalisation divise souvent la valeur du texte en sous-champs.
Il contient les données dans un format standardisé pour réduire le post-traitement et permettre la conversion au format sélectionné. La valeur mentionText, qui représente le contenu littéral du document, n'est jamais modifiée par la normalisation.
Les champs normalisés appartiennent à l'une des catégories suivantes.
Valeurs normalisées dans la console
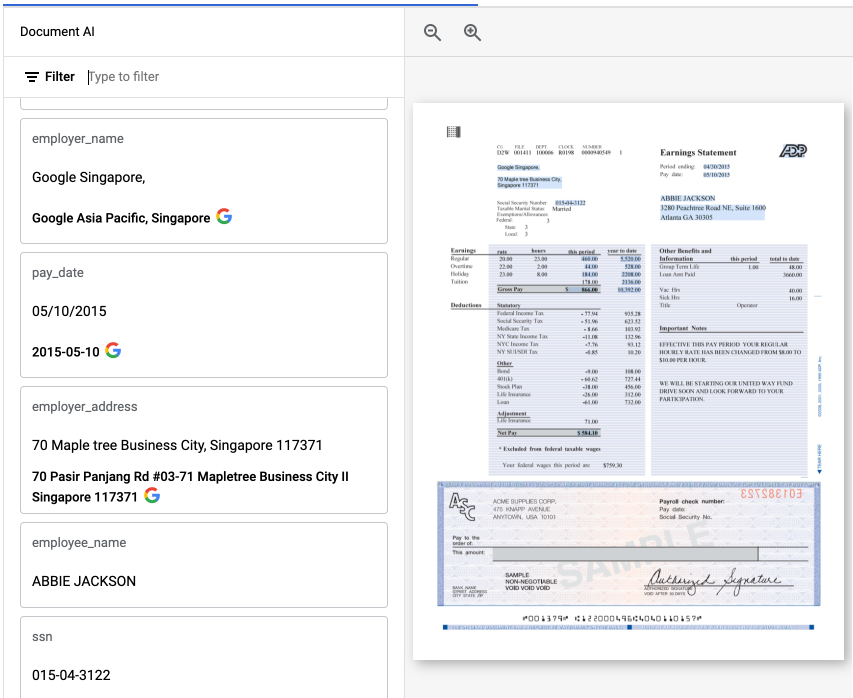
Dans la console Google Cloud , les champs normalisés sont annotés avec G. Exemple :
Exemple de champ normalisé affiché dans l'application Web.
Processeurs compatibles
Voici les processeurs et les champs compatibles avec l'enrichissement et la normalisation des entités :
L'extracteur personnalisé permet de normaliser toutes les entités avec les types de données courants suivants : dateTime, currency, money et number. Google Cloud
Sauf indication contraire, le contenu de cette page est régi par une licence Creative Commons Attribution 4.0, et les échantillons de code sont régis par une licence Apache 2.0. Pour en savoir plus, consultez les Règles du site Google Developers. Java est une marque déposée d'Oracle et/ou de ses sociétés affiliées.
Dernière mise à jour le 2025/10/19 (UTC).
[[["Facile à comprendre","easyToUnderstand","thumb-up"],["J'ai pu résoudre mon problème","solvedMyProblem","thumb-up"],["Autre","otherUp","thumb-up"]],[["Difficile à comprendre","hardToUnderstand","thumb-down"],["Informations ou exemple de code incorrects","incorrectInformationOrSampleCode","thumb-down"],["Il n'y a pas l'information/les exemples dont j'ai besoin","missingTheInformationSamplesINeed","thumb-down"],["Problème de traduction","translationIssue","thumb-down"],["Autre","otherDown","thumb-down"]],["Dernière mise à jour le 2025/10/19 (UTC)."],[],[]]