BigQuery s'intègre à Document AI pour vous aider à créer des cas d'utilisation d'analyse de documents et d'IA générative. Alors que la transformation numérique s'accélère, les organisations génèrent d'énormes quantités de texte et d'autres données de documents, qui offrent un immense potentiel pour obtenir des insights et alimenter de nouveaux cas d'utilisation de l'IA générative. Pour vous aider à exploiter ces données, nous sommes heureux d'annoncer l'intégration de BigQuery et de Document AI. Vous pourrez ainsi extraire des insights à partir des données de vos documents et créer de nouvelles applications de grands modèles de langage (LLM).
Présentation
Les clients BigQuery peuvent désormais créer des extracteurs personnalisés Document AI, optimisés par les modèles de fondation de pointe de Google, qu'ils peuvent personnaliser en fonction de leurs propres documents et métadonnées. Ces modèles personnalisés peuvent ensuite être appelés depuis BigQuery pour extraire des données structurées à partir de documents de manière sécurisée et contrôlée, en utilisant la simplicité et la puissance de SQL. Avant cette intégration, certains clients ont essayé de créer des pipelines Document AI indépendants, ce qui impliquait de sélectionner manuellement la logique et le schéma d'extraction. L'absence de fonctionnalités d'intégration intégrées les a obligés à développer une infrastructure sur mesure pour synchroniser et maintenir la cohérence des données. Chaque projet d'analyse de documents s'est ainsi transformé en une entreprise considérable nécessitant un investissement important. Grâce à cette intégration, les clients peuvent désormais créer des modèles distants dans BigQuery pour leurs extracteurs personnalisés dans Document AI, et les utiliser pour effectuer des analyses de documents et de l'IA générative à grande échelle. Ils ouvrent ainsi une nouvelle ère d'insights et d'innovations basés sur les données.
Une expérience unifiée et régie pour passer des données à l'IA
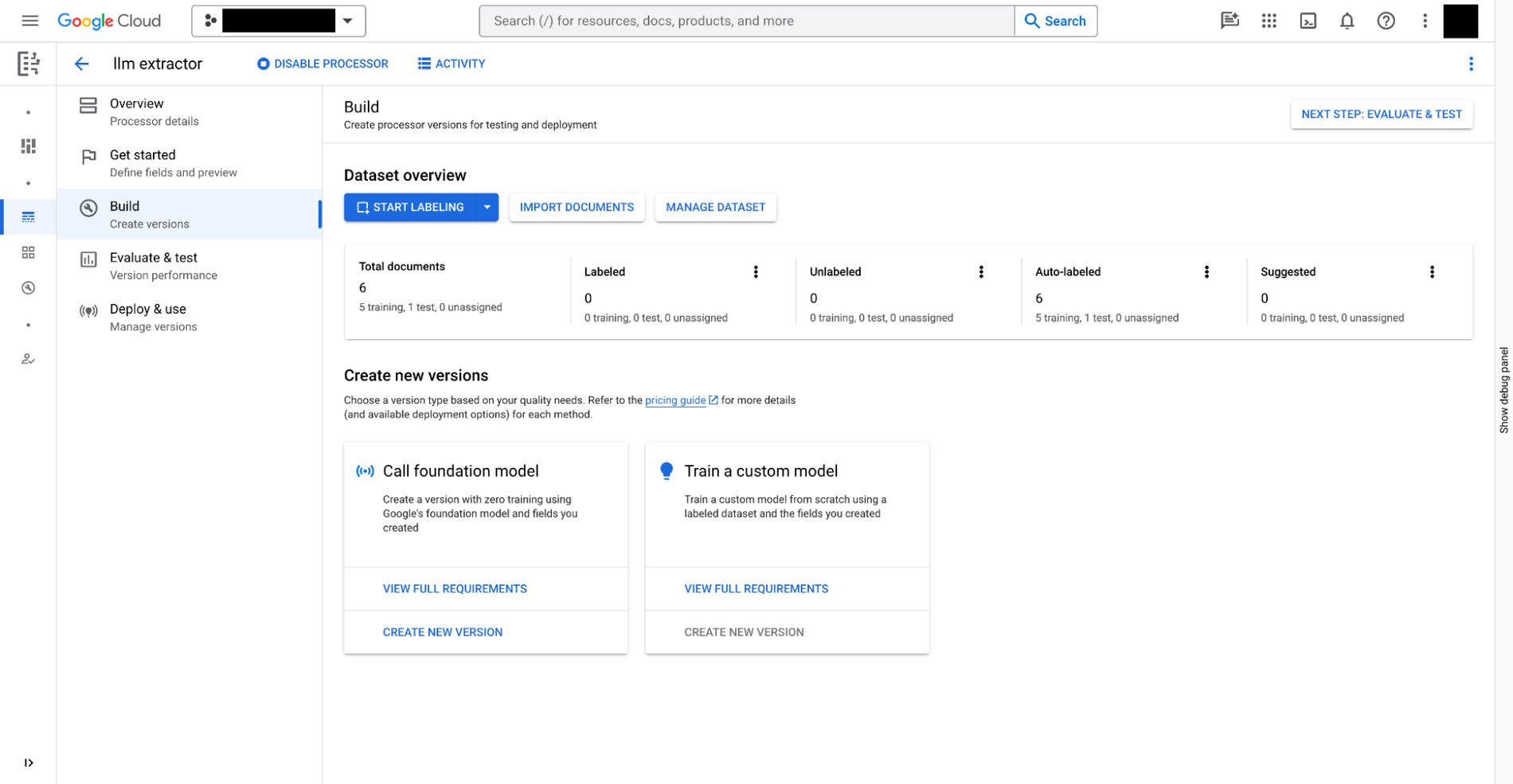
Vous pouvez créer un extracteur personnalisé dans Document AI en trois étapes :
- Définissez les données que vous devez extraire de vos documents. Il s'agit de
document schema, qui est stocké avec chaque version de l'extracteur personnalisé et accessible depuis BigQuery. - Si vous le souhaitez, vous pouvez fournir des documents supplémentaires avec des annotations comme exemples d'extraction.
- Entraînez le modèle pour l'extracteur personnalisé, en fonction des modèles de fondation fournis dans Document AI.
En plus des extracteurs personnalisés qui nécessitent un entraînement manuel, Document AI fournit également des extracteurs prêts à l'emploi pour les dépenses, les reçus, les factures, les formulaires fiscaux, les pièces d'identité délivrées par le gouvernement et une multitude d'autres scénarios, dans la galerie de processeurs.
Une fois l'extracteur personnalisé prêt, vous pouvez passer à BigQuery Studio pour analyser les documents à l'aide de SQL en quatre étapes :
- Enregistrez un modèle distant BigQuery pour l'extracteur à l'aide de SQL. Le modèle peut comprendre le schéma du document (créé ci-dessus), appeler l'extracteur personnalisé et analyser les résultats.
- Créez des tables d'objets à l'aide de SQL pour les documents stockés dans Cloud Storage. Vous pouvez régir les données non structurées dans les tables en définissant des règles d'accès au niveau des lignes. Cela limite l'accès des utilisateurs à certains documents et restreint ainsi la puissance de l'IA pour la confidentialité et la sécurité.
- Utilisez la fonction
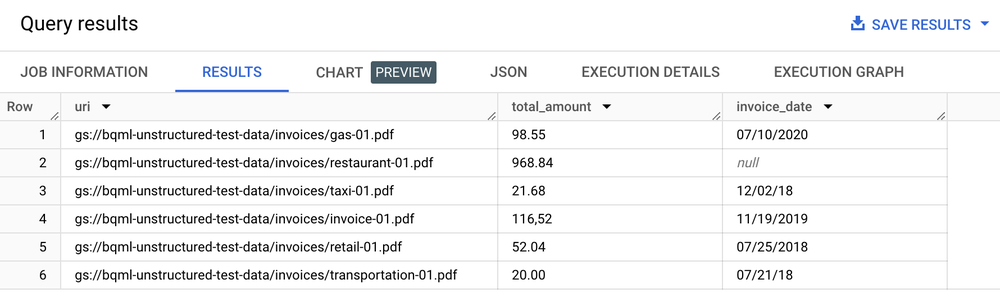
ML.PROCESS_DOCUMENTsur le tableau d'objets pour extraire les champs pertinents en effectuant des appels d'inférence au point de terminaison de l'API. Vous pouvez également filtrer les documents pour les extractions avec une clauseWHEREen dehors de la fonction. La fonction renvoie une table structurée, chaque colonne étant un champ extrait. - Joignez les données extraites à d'autres tables BigQuery pour combiner les données structurées et non structurées, et générer ainsi de la valeur commerciale.
L'exemple suivant illustre l'expérience utilisateur :
# Create an object table in BigQuery that maps to the document files stored in Cloud Storage.
CREATE OR REPLACE EXTERNAL TABLE `my_dataset.document`
WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://my_bucket/path/*'],
metadata_cache_mode= 'AUTOMATIC',
max_staleness= INTERVAL 1 HOUR
);
# Create a remote model to register your Doc AI processor in BigQuery.
CREATE OR REPLACE MODEL `my_dataset.layout_parser`
REMOTE WITH CONNECTION `my_project.us.example_connection`
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
document_processor='PROCESSOR_ID'
);
# Invoke the registered model over the object table to parse PDF document
SELECT uri, total_amount, invoice_date
FROM ML.PROCESS_DOCUMENT(
MODEL `my_dataset.layout_parser`,
TABLE `my_dataset.document`,
PROCESS_OPTIONS => (
JSON '{"layout_config": {"chunking_config": {"chunk_size": 250}}}')
)
WHERE content_type = 'application/pdf';
Table de résultats
Cas d'utilisation de l'analyse de texte, de la synthèse et d'autres analyses de documents
Une fois le texte extrait de vos documents, vous pouvez effectuer des analyses de documents de plusieurs manières :
- Utilisez BigQuery ML pour effectuer des analyses de texte : BigQuery ML permet d'entraîner et de déployer des modèles d'embedding de différentes manières. Par exemple, vous pouvez utiliser BigQuery ML pour identifier le sentiment des clients lors d'appels d'assistance ou pour classer les commentaires sur les produits dans différentes catégories. Si vous utilisez Python, vous pouvez également utiliser BigQuery DataFrames pour pandas et des API de type scikit-learn pour l'analyse de texte sur vos données.
- Utilisez le LLM
text-embedding-004pour générer des embeddings à partir des documents segmentés : BigQuery dispose d'une fonctionML.GENERATE_EMBEDDINGqui appelle le modèletext-embedding-004pour générer des embeddings. Par exemple, vous pouvez utiliser Document AI pour extraire les commentaires des clients et les résumer à l'aide de PaLM 2, le tout avec BigQuery SQL. - Joignez les métadonnées des documents à d'autres données structurées stockées dans des tables BigQuery :
Par exemple, vous pouvez générer des embeddings à l'aide des documents segmentés et les utiliser pour la recherche vectorielle.
# Example 1: Parse the chunked data
CREATE OR REPLACE TABLE docai_demo.demo_result_parsed AS (SELECT
uri,
JSON_EXTRACT_SCALAR(json , '$.chunkId') AS id,
JSON_EXTRACT_SCALAR(json , '$.content') AS content,
JSON_EXTRACT_SCALAR(json , '$.pageFooters[0].text') AS page_footers_text,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageStart') AS page_span_start,
JSON_EXTRACT_SCALAR(json , '$.pageSpan.pageEnd') AS page_span_end
FROM docai_demo.demo_result, UNNEST(JSON_EXTRACT_ARRAY(ml_process_document_result.chunkedDocument.chunks, '$')) json)
# Example 2: Generate embedding
CREATE OR REPLACE TABLE `docai_demo.embeddings` AS
SELECT * FROM ML.GENERATE_EMBEDDING(
MODEL `docai_demo.embedding_model`,
TABLE `docai_demo.demo_result_parsed`
);
Implémenter des cas d'utilisation de la recherche et de l'IA générative
Une fois que vous avez extrait le texte structuré de vos documents, vous pouvez créer des index optimisés pour les requêtes de type "chercher une aiguille dans une botte de foin". Grâce aux fonctionnalités de recherche et d'indexation de BigQuery, vous pouvez ainsi effectuer des recherches puissantes. Cette intégration permet également de débloquer de nouvelles applications LLM génératives, comme l'exécution du traitement de fichiers texte pour le filtrage de la confidentialité, les vérifications de la sécurité du contenu et le découpage de jetons à l'aide de requêtes SQL et de modèles Document AI personnalisés. Le texte extrait, combiné à d'autres métadonnées, simplifie la curation du corpus d'entraînement nécessaire pour affiner les grands modèles de langage. De plus, vous créez des cas d'utilisation de LLM sur des données d'entreprise régies, ancrées grâce aux fonctionnalités de génération d'embeddings et de gestion d'index vectoriels de BigQuery. En synchronisant cet index avec Vertex AI, vous pouvez implémenter des cas d'utilisation de génération augmentée par récupération pour une expérience d'IA plus gouvernée et rationalisée.
Exemple d'application
Exemple d'application de bout en bout utilisant le connecteur Document AI :
- Consultez la démonstration de cette note de frais sur GitHub.
- Lisez l'article de blog associé.
- Regardez une vidéo détaillée sur Google Cloud Next 2021.