Release di dicembre 2022
Stepper di configurazione HITL
La scheda "Configurazione" in "Human-In-The-Loop" ora è formattata come una coppia ordinata di passaggi per consentire un'esperienza di configurazione più semplice e strutturata.
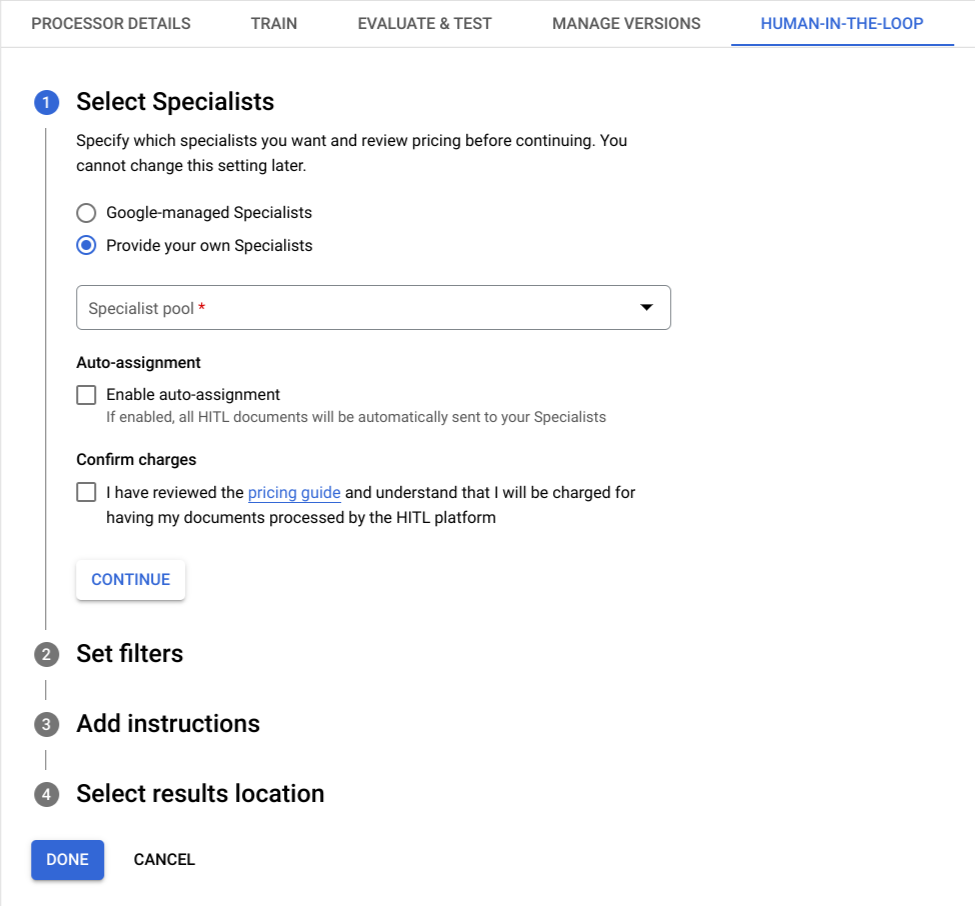 L'utente ora può visualizzare passaggi separati per configurare le impostazioni relative al pool di specialisti e ai filtri per attivare l'intervento umano e selezionare la posizione delle istruzioni e dei risultati per gli specialisti.
L'utente ora può visualizzare passaggi separati per configurare le impostazioni relative al pool di specialisti e ai filtri per attivare l'intervento umano e selezionare la posizione delle istruzioni e dei risultati per gli specialisti.
Release di ottobre 2022
Dashboard di analisi dei richiedenti HITL
Human in the Loop ora ha una scheda dedicata, chiamata Analytics, che fornisce all'utente metriche e grafici per analizzare lo stato delle attività HITL per processore e apportare le modifiche necessarie.
Attualmente, l'utente può visualizzare tre metriche diverse. I dati possono essere aggregati in base a un selettore dell'intervallo di tempo che offre all'utente le seguenti opzioni:

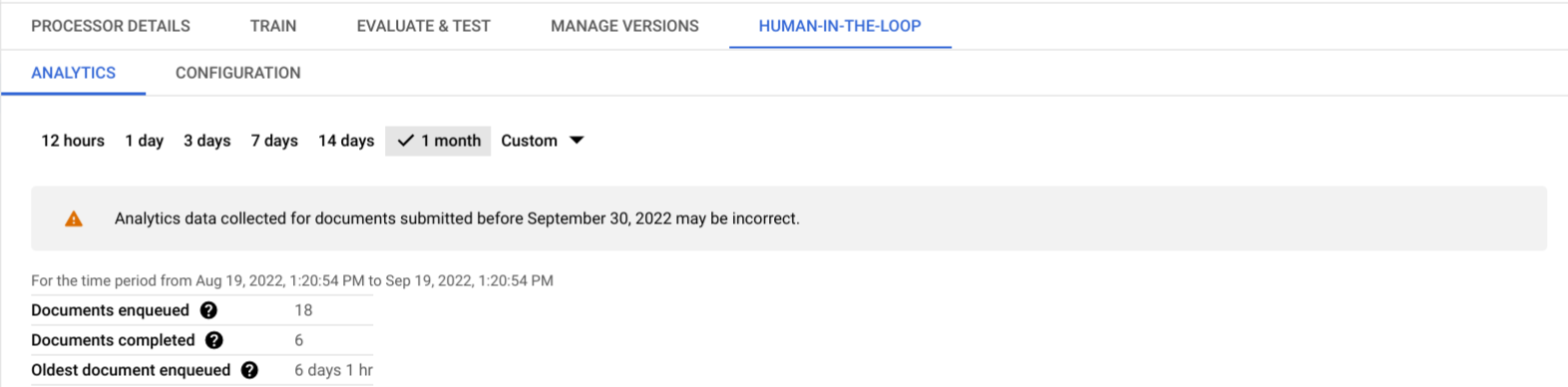
Per ogni intervallo di tempo selezionato, l'utente può visualizzare quanto segue:
- Statistiche aggregate: una visualizzazione istantanea del numero totale di documenti
che sono stati caricati correttamente nella coda, del numero totale di
documenti completati (ovvero inviati e rifiutati) dagli esperti e del tempo
trascorso dall'aggiunta del documento più vecchio nella coda per l'intervallo di tempo
selezionato.
- Grafico dell'attività human-in-the-loop: un grafico che mostra i dati delle serie temporali
relativi al momento in cui i documenti sono stati aggiunti alla coda (
enqueuedDocumentCount) e al momento in cui sono stati completati dagli esperti (completedDocumentCount).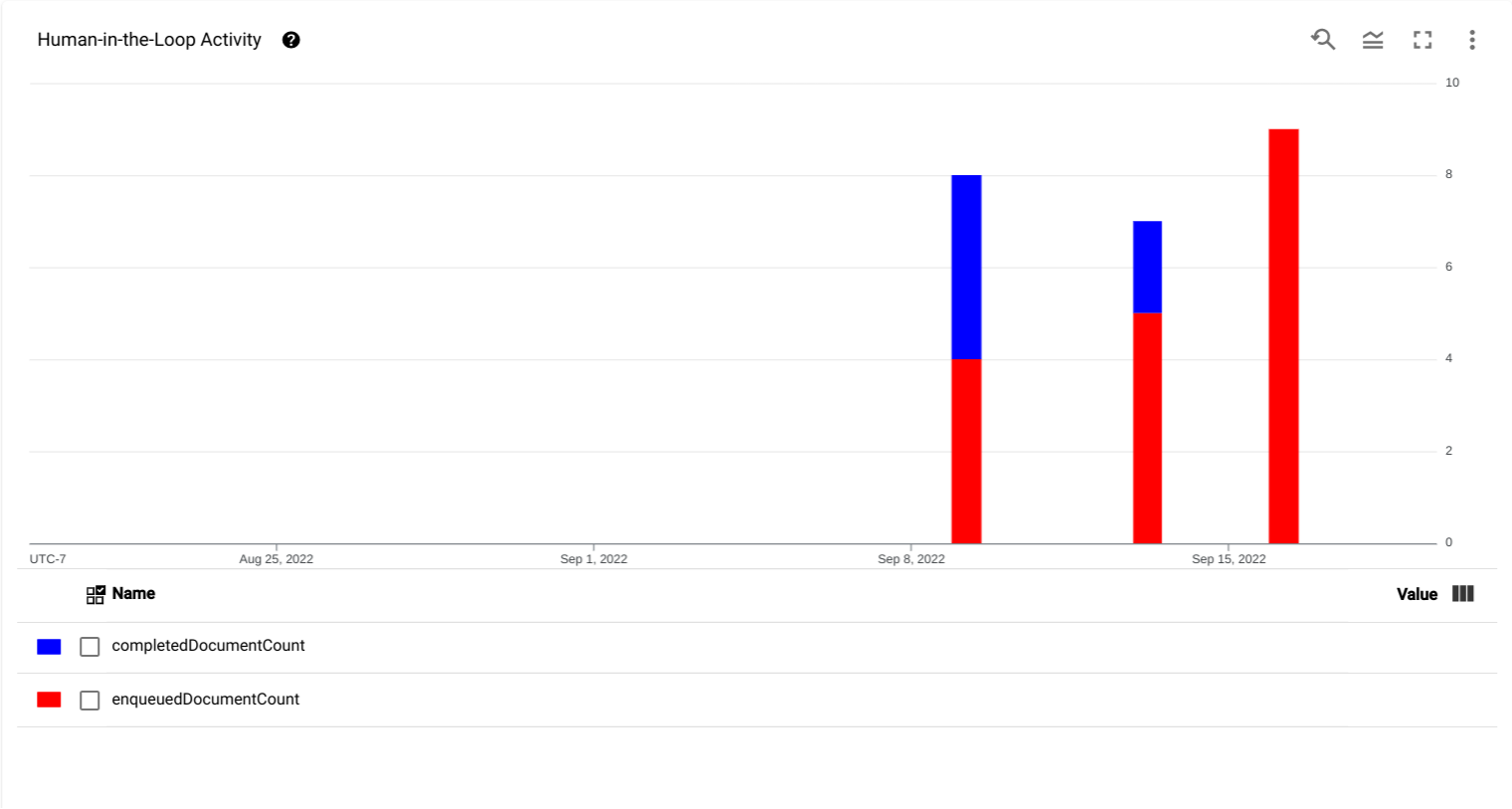
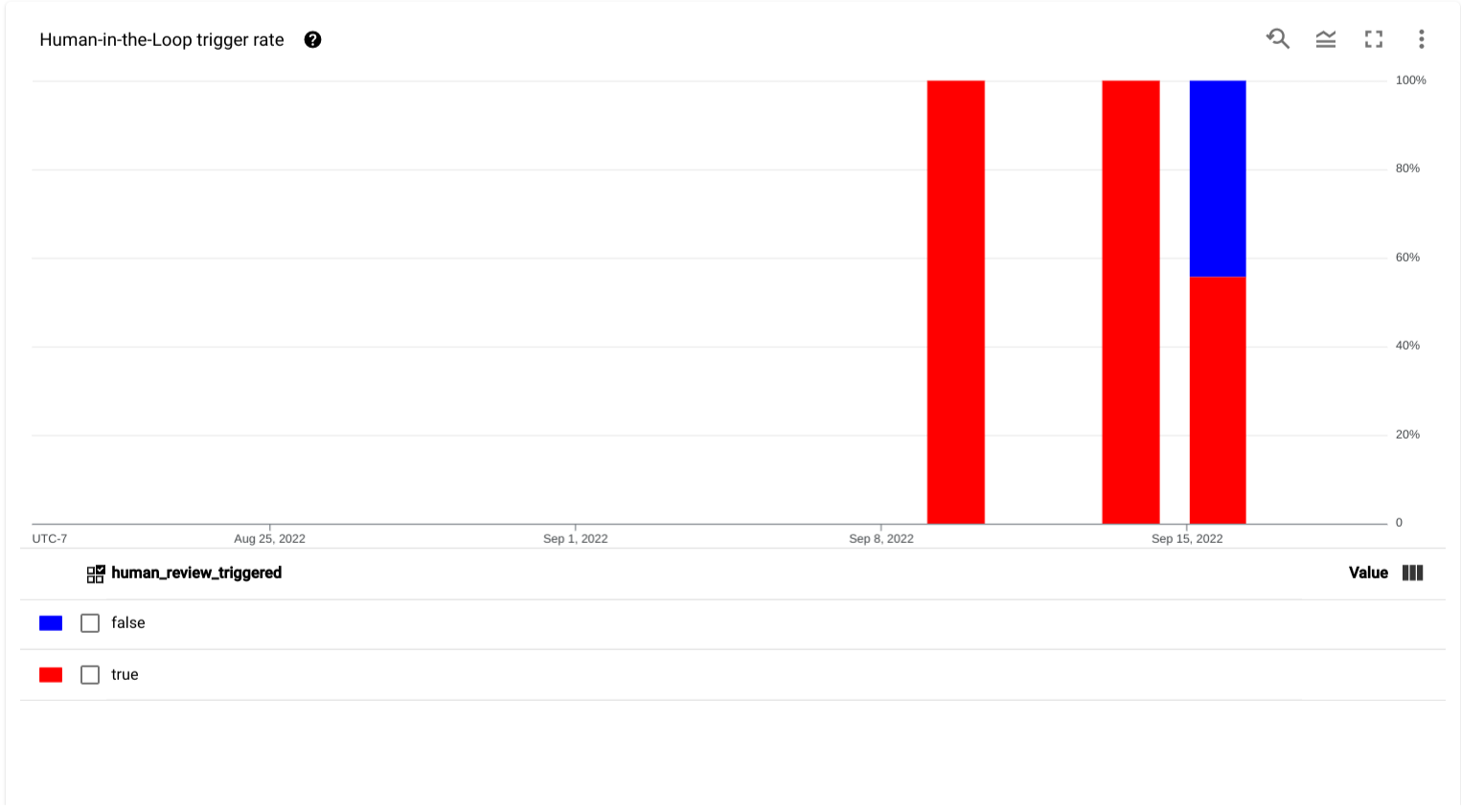
- Percentuale di attivazione di human-in-the-loop: un grafico che mostra i dati delle serie temporali per la percentuale di documenti caricati che hanno attivato la revisione human-in-the-loop nel periodo di tempo selezionato.
- Statistiche aggregate: una visualizzazione istantanea del numero totale di documenti
che sono stati caricati correttamente nella coda, del numero totale di
documenti completati (ovvero inviati e rifiutati) dagli esperti e del tempo
trascorso dall'aggiunta del documento più vecchio nella coda per l'intervallo di tempo
selezionato.
Release di settembre 2022
Nota: i clienti che utilizzano Document AI Workbench, gli estrattori di ordini di acquisto, fatture e spese hanno accesso a un nuovo schema che consente di etichettare le caselle di controllo (se definite nello schema) e di rappresentare con precisione le entità nidificate, ovvero la relazione padre-figlio, nell'interfaccia utente di annotazione e revisione HITL. Man mano che altri processori adotteranno il nuovo schema, queste note di rilascio verranno aggiornate di conseguenza
Entità nidificata
- L'interfaccia utente di annotazione ora supporta l'etichettatura per le entità nidificate. Il riquadro a sinistra viene aggiornato con un nuovo aspetto per le righe nidificate per rappresentare le entità nidificate. Il valore di "parent" è la concatenazione di tutti i relativi "children".
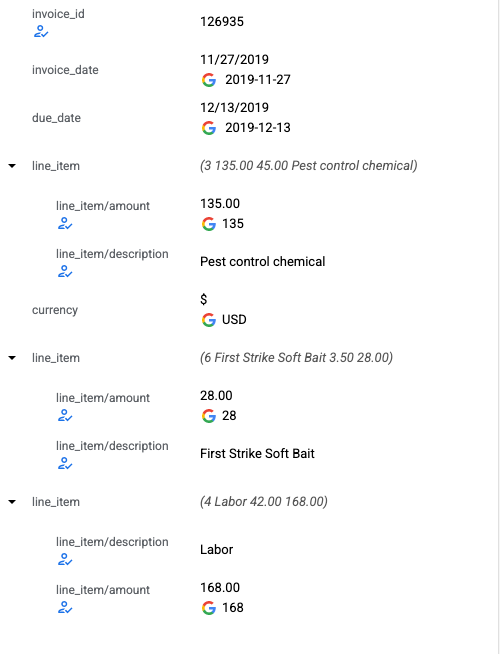
- La selezione delle entità nel riquadro a sinistra mostra le etichette padre e figlio.

- Anche il menu delle etichette delle entità nel documento viene aggiornato per supportare l'etichettatura delle entità nidificate.
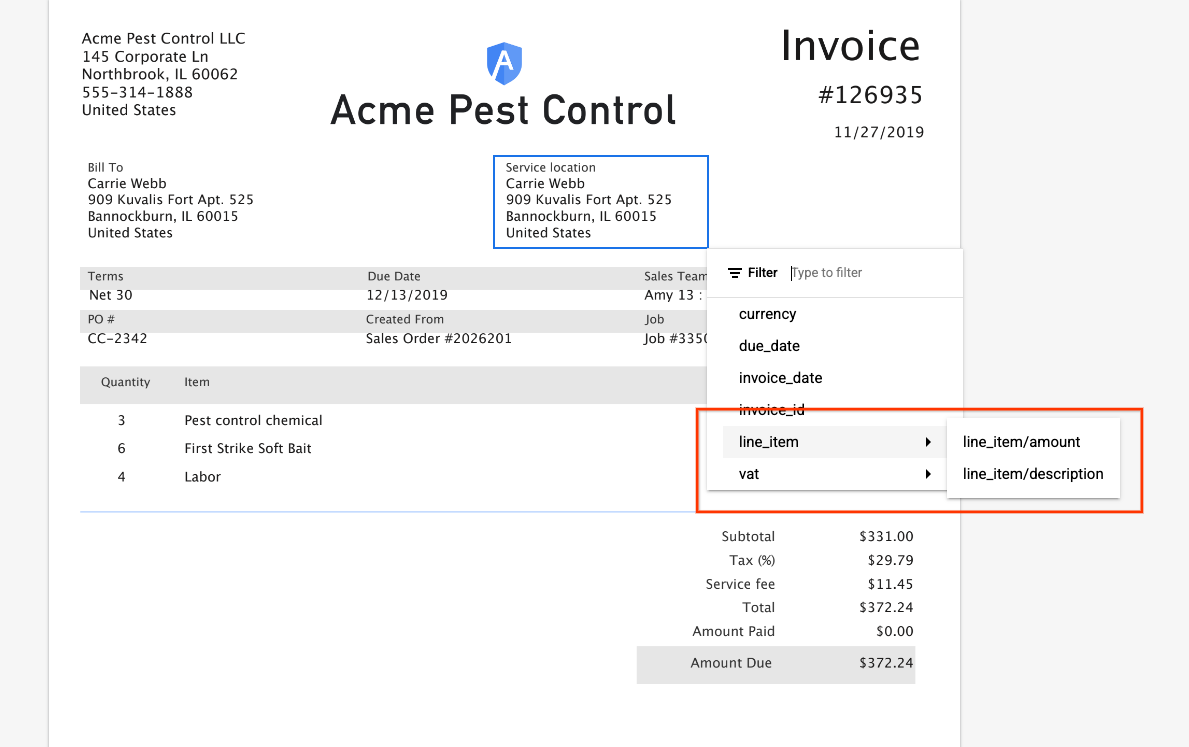
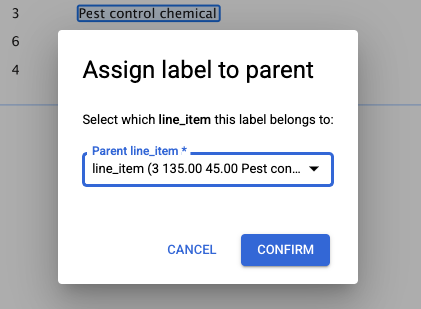
- Se fai clic su un'etichetta nidificata, viene visualizzata una finestra di dialogo per assegnare l'entità padre corretta all'entità secondaria nidificata.
Casella di controllo
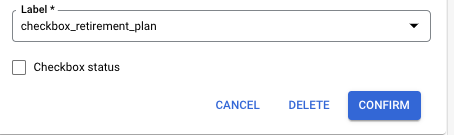
- L'interfaccia utente di annotazione supporta le caselle di controllo per l'etichettatura. Nel riquadro a sinistra, la casella di controllo può essere modificata nella riga.

- La modifica delle caselle di controllo è disponibile anche nella finestra di dialogo di modifica dell'entità.
Release di agosto 2022
Seleziona etichetta entità
- L'input dell'etichetta dell'entità viene sostituito da un elenco a discesa. Questo elenco a discesa contiene le opzioni di etichetta disponibili quando aggiungi una nuova entità. Questa modifica aiuta a evitare che gli etichettatori commettano errori di battitura e creino etichette di entità indesiderate.
Formato data ISO
- Le date normalizzate vengono visualizzate nel formato data ISO 8601(aaaa-mm-gg).

Release di luglio 2022
Pulsante Conferma rapida
- Nei suggerimenti delle entità è disponibile un pulsante Conferma per esaminare e confermare rapidamente un valore di entità/etichetta. Il pulsante Modifica viene rimosso, in quanto gli utenti possono fare clic direttamente sulla descrizione comando dell'entità per apportare modifiche.
Release di gennaio 2022
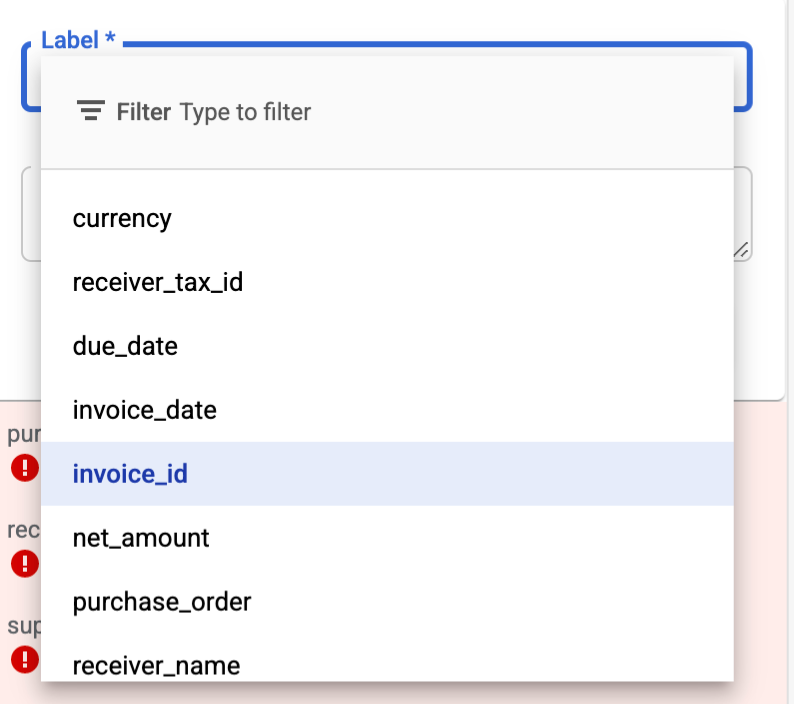
Opzioni per le etichette delle entità
- Le opzioni di selezione delle etichette delle entità ora sono limitate all'elenco dei campi filtrati(impostati nella configurazione del filtro HITL).
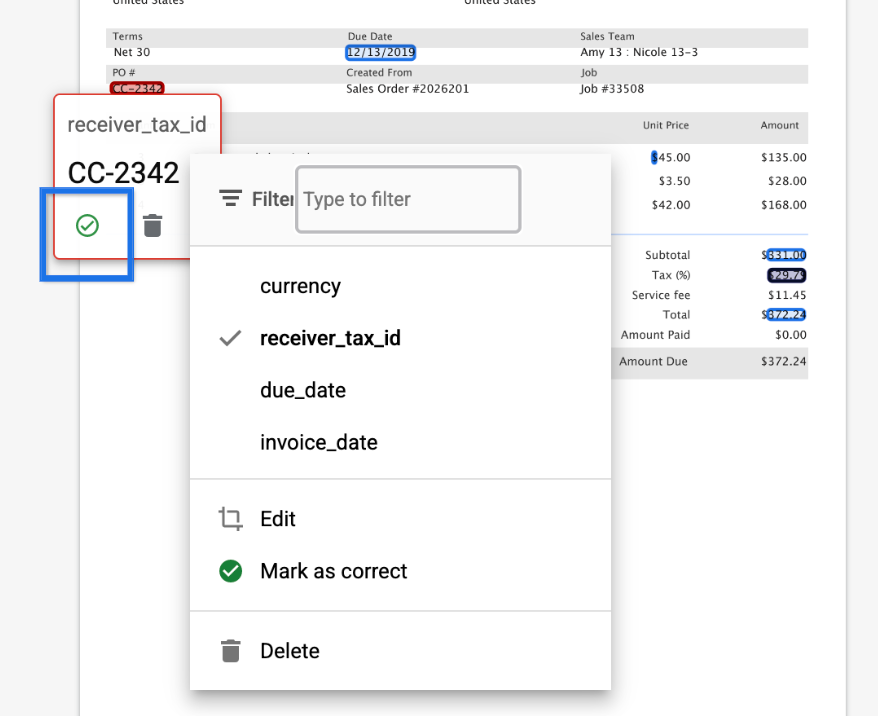
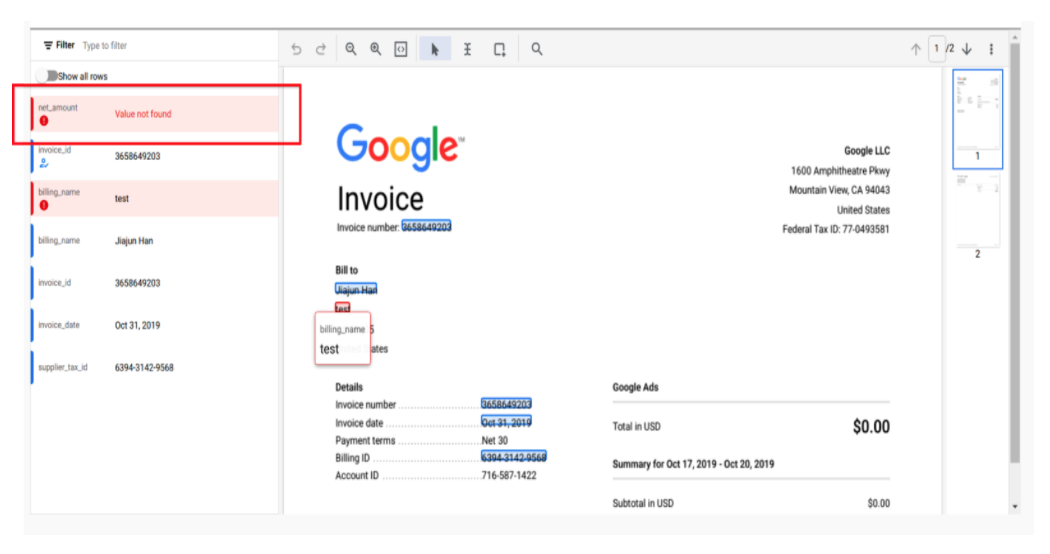
Campi mancanti
- Ora mostriamo i campi mancanti (ovvero i campi contrassegnati come "Obbligatori" nella configurazione del filtro HITL, ma per i quali il processore non ha previsto valori) in un colore rosso distinto, in modo che il revisore possa aggiornare facilmente il valore del campo.
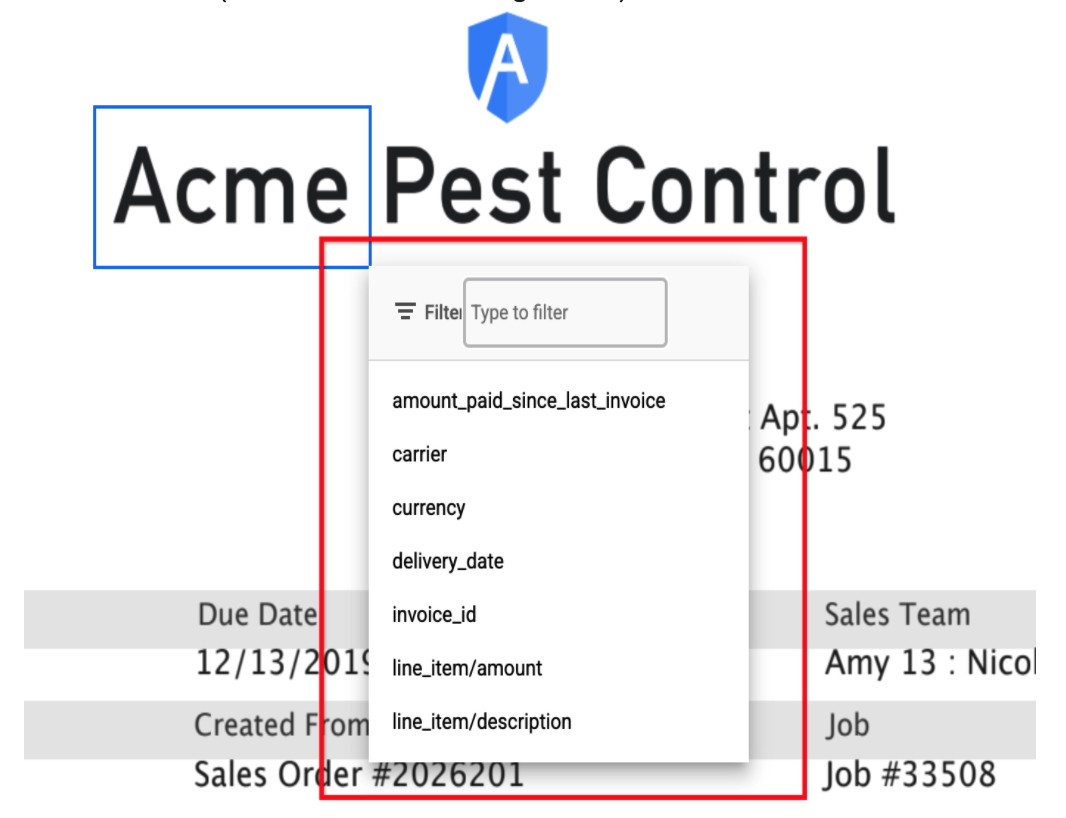
Campioni completi casuali
- Ora supportiamo la revisione completa (ovvero tutte le entità nel documento, non solo i campi filtrati) di un campione casuale (ad es. il 2% del volume giornaliero) di documenti. Ciò è utile per monitorare la deriva del modello e le analisi sull'accuratezza del processore in ogni campo. Raccogliamo queste analisi, che vengono utilizzate per sapere quando è necessario un nuovo addestramento. Questo serve anche come set di dati con dati empirici reali etichettati per i modelli di up-training.
- I clienti possono attivare e impostare il campione casuale [1-10%] in base al volume. Il targeting di 100-500 campioni a settimana sarebbe utile. Pertanto, se il cliente elabora 10.000 documenti/settimana, questo valore può essere impostato su 500/10.000 = 5%
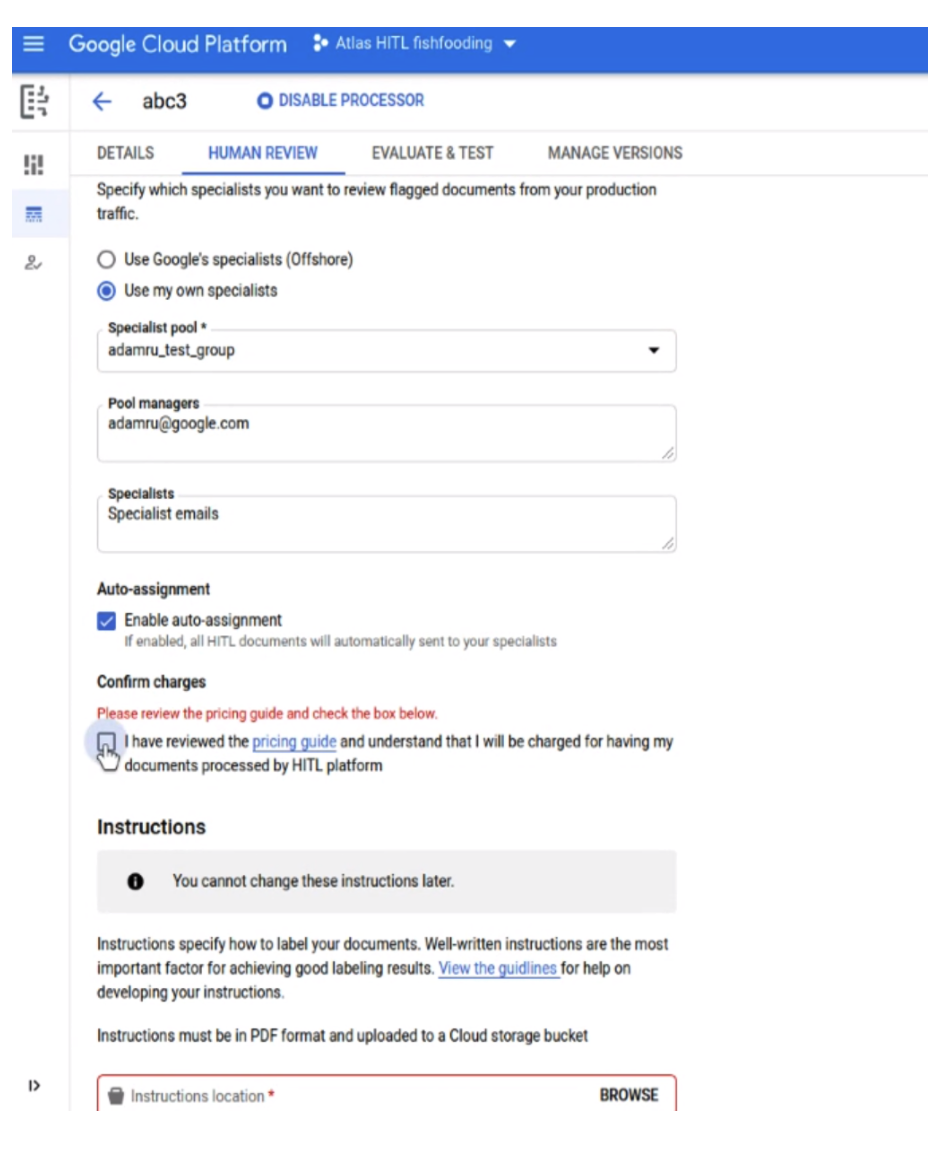
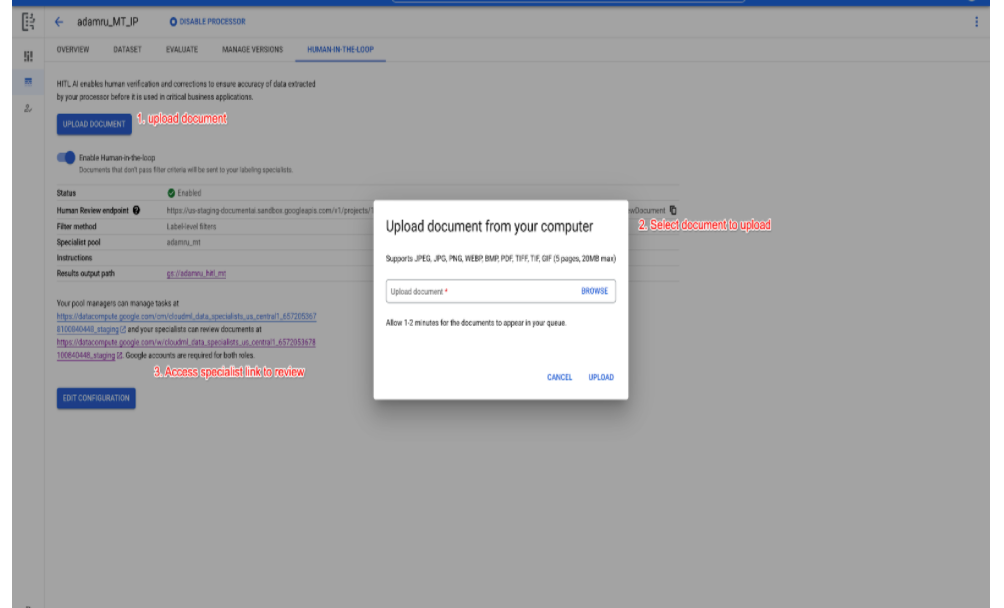
Configurazione semplificata di human-in-the-loop per i nuovi utenti
- Abbiamo semplificato la configurazione BYOL HITL per i clienti che utilizzano HITL per la prima volta, in modo che possano configurare rapidamente un'attività, assegnare specialisti e avviarla da un'unica schermata, in modo da poterla provare rapidamente prima di aumentare il volume di produzione o esternalizzare l'operazione.
- Come mostrato nello screenshot di seguito, l'utente diventa il gestore predefinito del pool e può aggiungere altri specialisti, tutti assegnati automaticamente all'attività nella stessa schermata.
- In precedenza, al gestore assegnato veniva inviato via email un link alla console del gestore, dove aggiungeva gli specialisti e assegnava loro l'attività.
- Dopo aver inviato l'attività, lui e gli altri specialisti assegnati possono andare all'app HITL per esaminare i documenti.
- L'utente può anche caricare un documento di test (uno alla volta) nella coda di attività.
Rimuovi interruzione di riga finale
- I separatori di riga finali("\n") vengono rimossi in entity.mentionText.
Release di dicembre 2021
Ordinare le entità con punteggio di confidenza basso in alto
- Le entità con punteggio di confidenza basso (ovvero le entità al di sotto della soglia di confidenza) ora sono ordinate nella parte superiore della pagina, consentendo allo specialista di concentrarsi su queste entità. Ciò consente di migliorare ulteriormente l'efficienza dell'etichettatura.

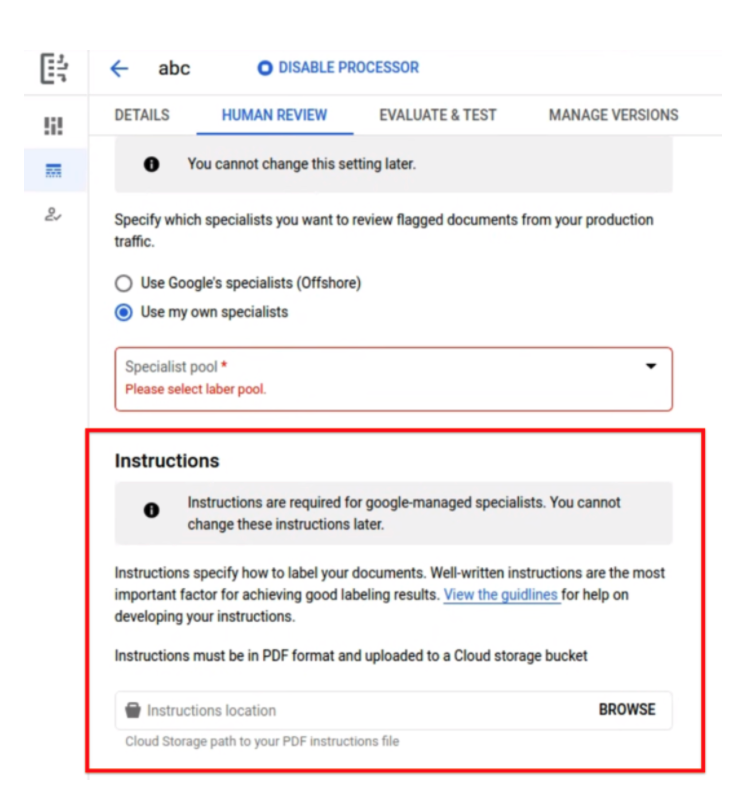
Istruzioni facoltative per le attività BYOL
- Le istruzioni in formato PDF da caricare per configurare un'attività HITL sono ora facoltative. In questo modo, i test e i lanci interni rapidi vengono semplificati e gli specialisti non hanno bisogno di una guida alle istruzioni.
Opzione Adatta alla larghezza e Adatta all'altezza della pagina
- Pulsante per adattare la pagina alla larghezza o all'altezza. Questa opzione è utile quando gli specialisti hanno documenti di dimensioni variabili (ad es. ricevute) in un'attività.

Nome dell'attività visualizzato nell'interfaccia utente di Specialist
- Il nome dell'attività viene ora visualizzato nell'UI dello specialista per fornire un contesto aggiuntivo sull'attività e sul tipo di documento, il che è molto utile quando lo specialista è assegnato a più attività.
- Tieni presente che questo valore viene visualizzato nei nuovi processori attivati dopo questa release.

Casella di ricerca per gli specialisti
- Gli specialisti possono cercare entità/testo nei documenti. Ciò è utile soprattutto per i documenti di grandi dimensioni con più pagine e rende gli specialisti più produttivi.

Release di settembre 2021
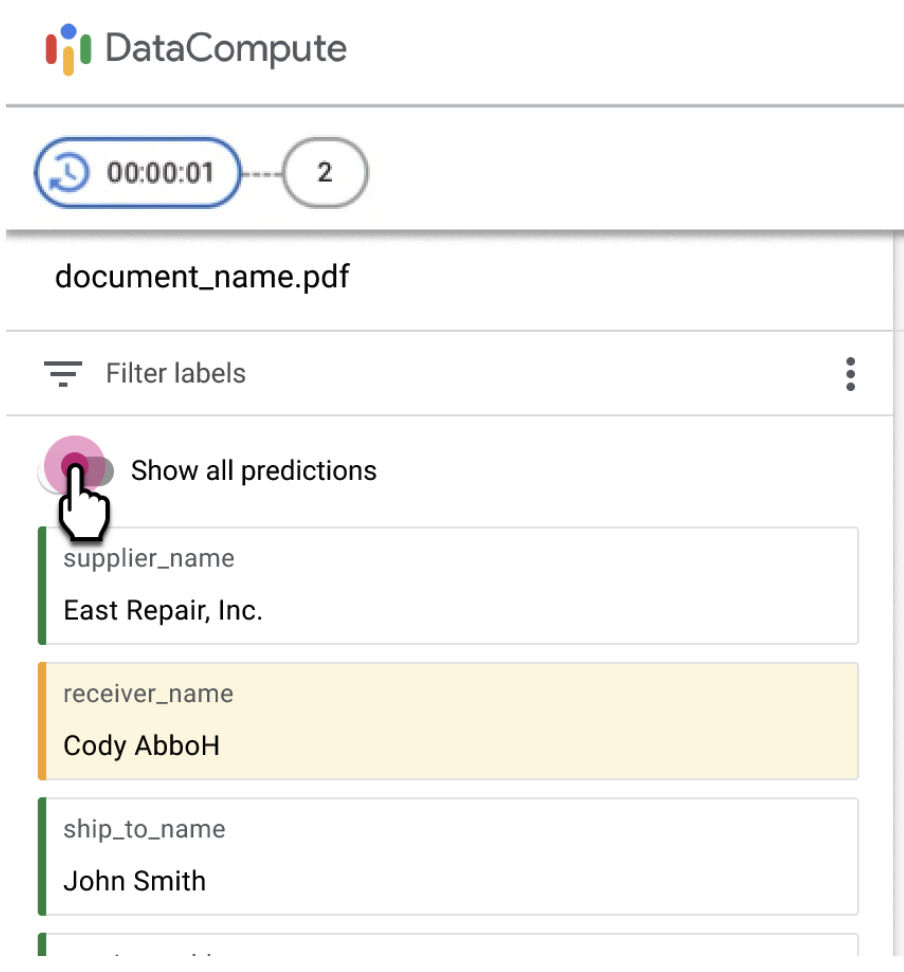
Attiva/disattiva per mostrare tutti i campi
- Gli etichettatori potrebbero dover esaminare e aggiornare i campi che non si trovano nel set filtrato di entità per documenti specifici nella coda.
Puoi attivare/disattivare l'opzione Mostra tutte le previsioni
per consentire agli etichettatori di esaminare i campi non filtrati.
HITL per l'analizzatore sintattico di moduli
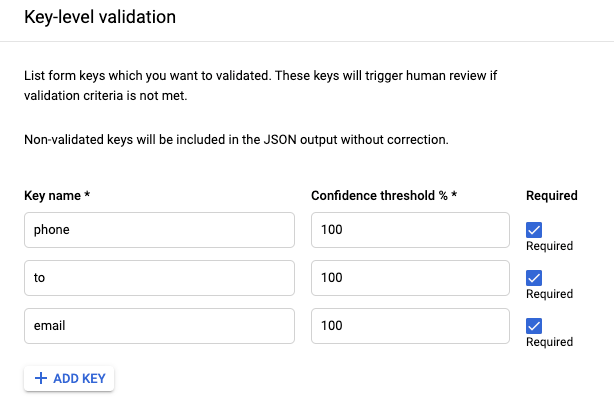
- HITL ora supporta l'analizzatore sintattico di moduli, in modo che gli utenti possano esaminare e correggere le coppie chiave-valore estratte dall'analizzatore sintattico di moduli. Il cliente può attivare HITL sul processore Form Parser nella piattaforma DocAI e configurare i nomi delle chiavi (come mostrato nello screenshot di seguito) che vuole filtrare per la revisione HITL. L'output HITL viene inserito come file JSON nel bucket Google Cloud Storage specificato dal cliente al termine della revisione HITL.
- Possono specificare nomi di chiavi alternativi separati da virgole, ad esempio "cliente, nome cliente, cliente, account n., numero di account", in modo che il filtro HITL rilevi i documenti con tutte le varianti del nome della chiave e li invii per la revisione HITL.



Release di agosto 2021
Pipeline di audit/QA
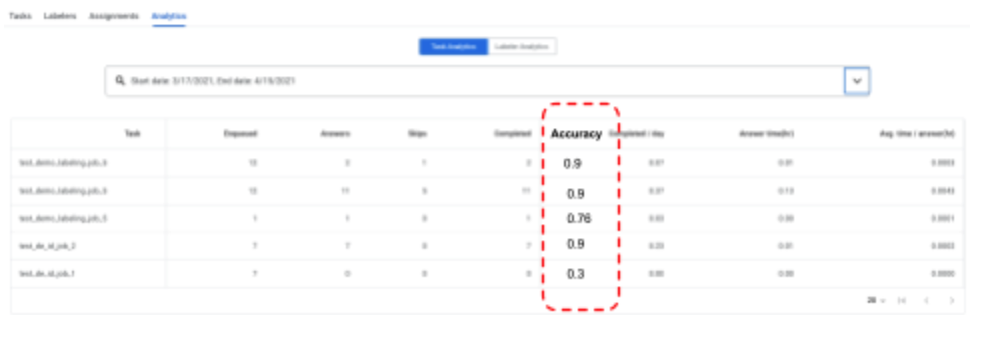
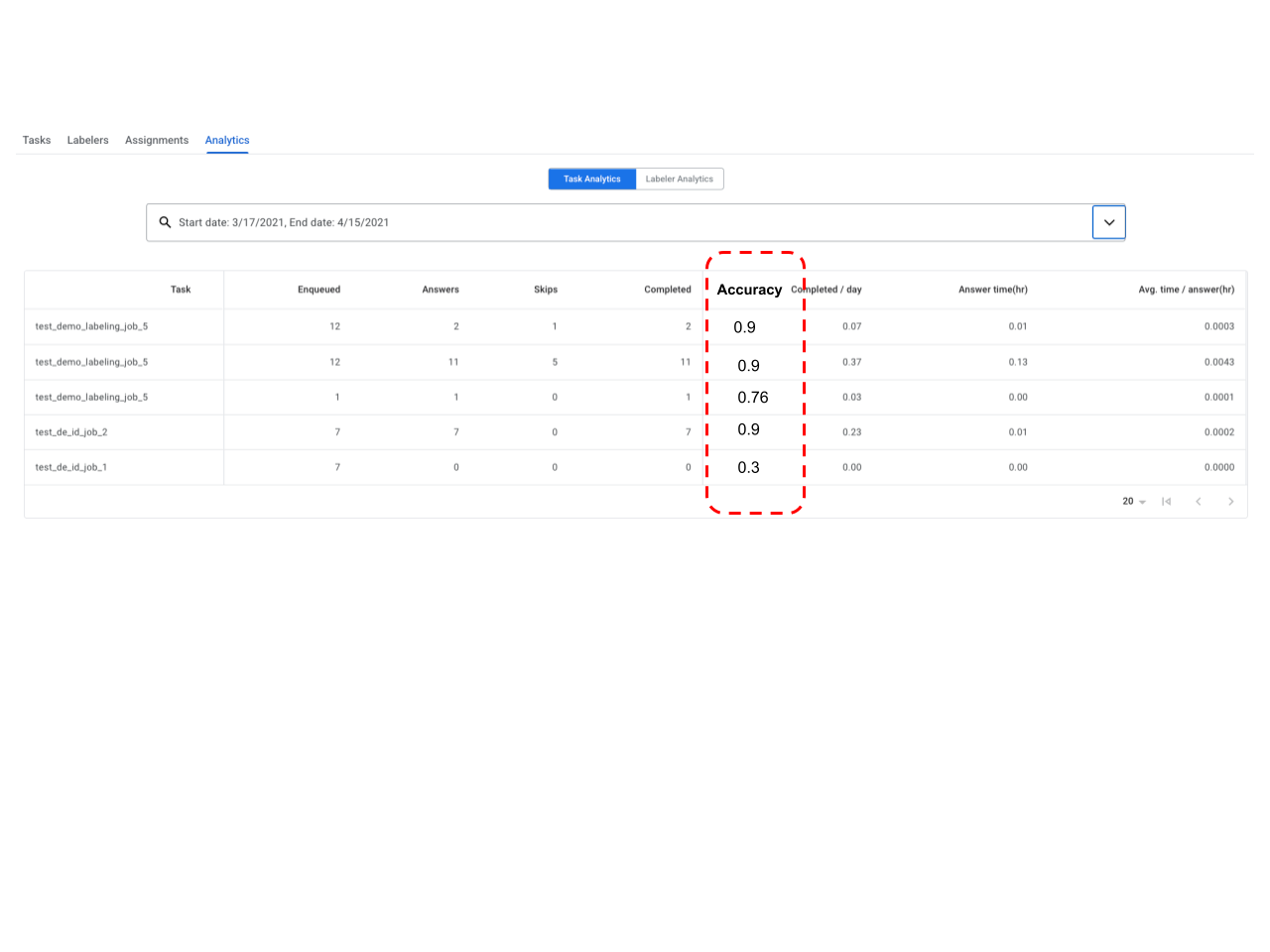
- HITL ora consente una seconda fase di controllo qualità o di audit e segnala l'accuratezza delle attività di revisione (e dei revisori). Un team di controllo qualità o un revisore può essere assegnato a un'attività come "etichettatore esperto". Il team di controllo qualità/revisore riceve una percentuale pari a X (ad esempio 1-100%, configurabile dal cliente) dei documenti esaminati. L'Auditor può correggere l'output del Revisore. Il sistema tiene traccia delle correzioni e assegna un punteggio di accuratezza (ad es. 90%) a ogni documento sottoposto a controllo. Il punteggio di accuratezza aggregato di un'attività o di un etichettatore viene riportato rispettivamente nelle dashboard di analisi delle attività e degli etichettatori.
- Ecco istruzioni dettagliate su come configurare una pipeline di controllo.
- Designazione di un revisore
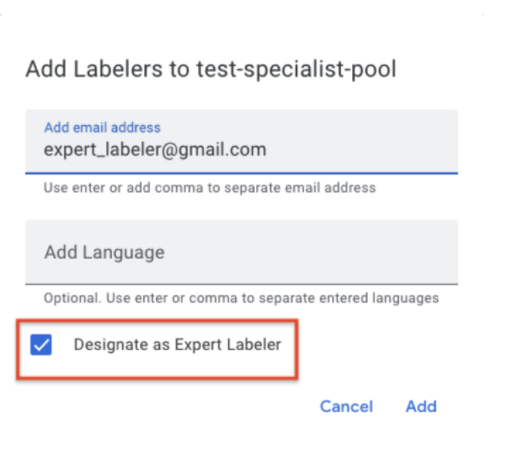
- Precisione dei report
Parser AI per i prestiti (15 agosto)
- HITL è ora supportato su alcuni analizzatori sintattici di Lending AI, tra cui 1040, 1040 Schedule E, 1040 Schedule C, 1099 DIV, 1099 G, 1099 INT, 1099 MISC, buste paga, estratti conto bancari, W2, W9, 1120, 1120S, 1065, SSA-1099, 1099 NEC, 1099-R.
Release di luglio 2021
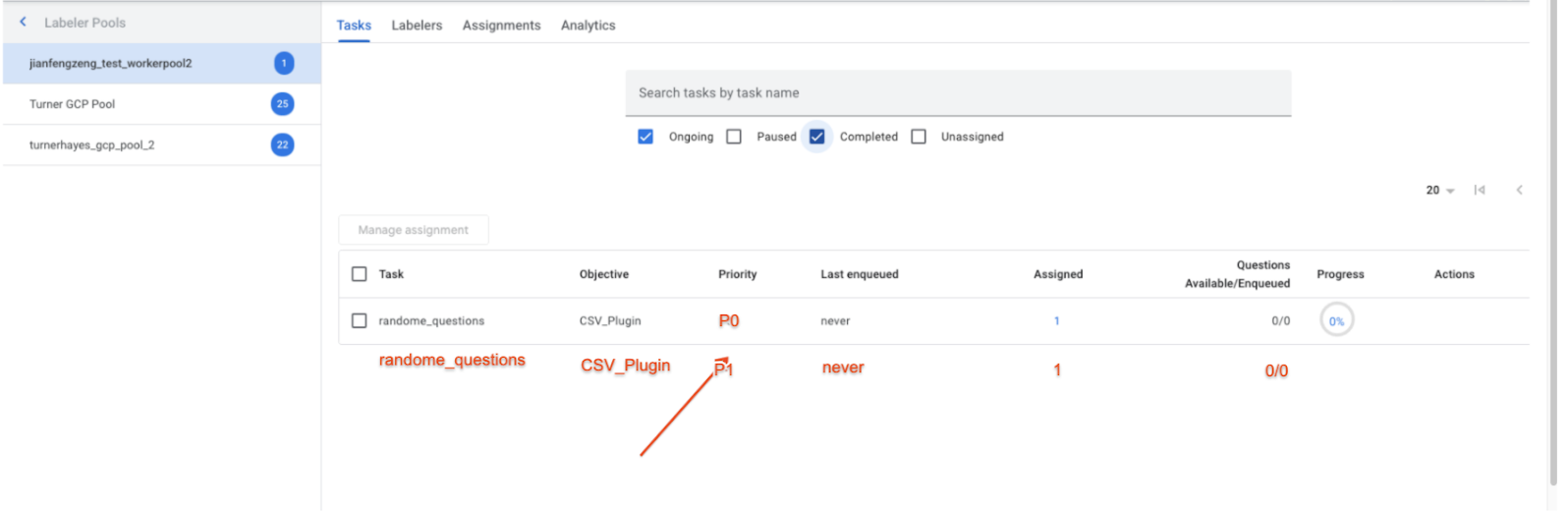
Code standard e urgenti (2 luglio)
- Ora supportiamo due code di priorità (anziché una) per ogni processore, in base all'urgenza di ogni documento.
- Invio: dopo la previsione, i documenti estratti possono essere valutati in base all'urgenza e inviati a due code (standard e urgente/fast track) in base all'urgenza del documento. Ad esempio, le fatture con date di scadenza urgenti possono essere inviate alla coda Fast-track. La logica che valuta l'urgenza è attualmente al di fuori dell'intervento umano nel ciclo di vita e può essere una funzione personalizzata.
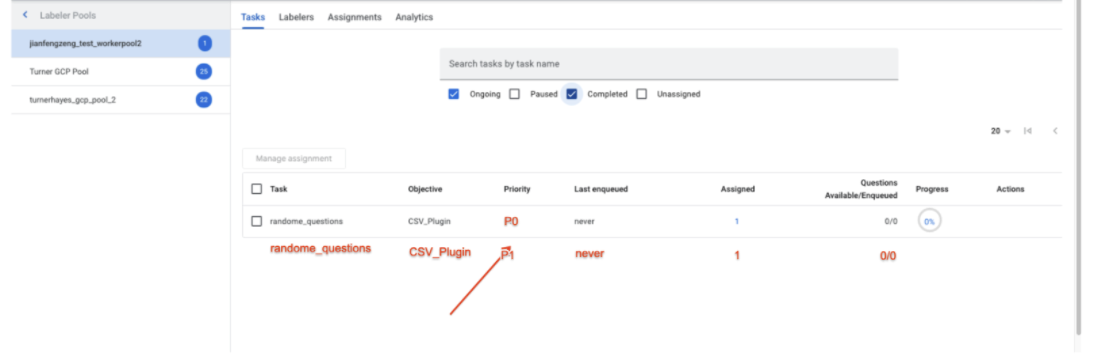
- Assegnazione delle attività: il responsabile dell'etichettatura vede due code diverse con priorità diverse, come mostrato nello screenshot di seguito, e può assegnare lo stesso gruppo di etichettatori a entrambe le code.
- Assegnazione delle priorità alle attività: gli etichettatori assegnati a entrambe le attività elaboreranno sempre prima i documenti in attesa nella coda Fast-track prima di elaborare la coda Standard (ovvero la priorità della coda viene gestita automaticamente dal sistema)
- Chiamata API: imposta il campo priority (priorità) in ReviewDocument
- Screenshot dell'interfaccia utente (delle attività nell'interfaccia utente di Labeling Manager) -
Release di giugno 2021
Filtri di convalida per l'endpoint HITL (24 giugno)
- I filtri di convalida (configurati nel processore) che filtrano i campi in base al punteggio di affidabilità per determinare i documenti da mettere in coda per la revisione da parte di persone fisiche vengono ora applicati anche ai documenti inviati all'endpoint HITL.
- Quando chiami l'API ReviewDocument, imposta il campo enable_schema_validation su true.
- Tieni presente che, se questa opzione è impostata e la convalida stabilisce che il documento non deve attivare la revisione umana, viene restituito un errore ANNULLATO.
Annulla API
Il cliente può annullare un documento messo in coda per l'elaborazione HITL richiamando l'API Cancel per un determinato ID operazione. Per ogni documento inviato ad attività HITL viene restituito un ID operazione.
`POST https://[us|eu]-documentai.googleapis.com/{api_version}/{name=projects/*/operations/*}:cancel`
Tipo di fattura (revisione della classificazione)
- Labeler Workbench supporta la revisione della classificazione del tipo di fattura.

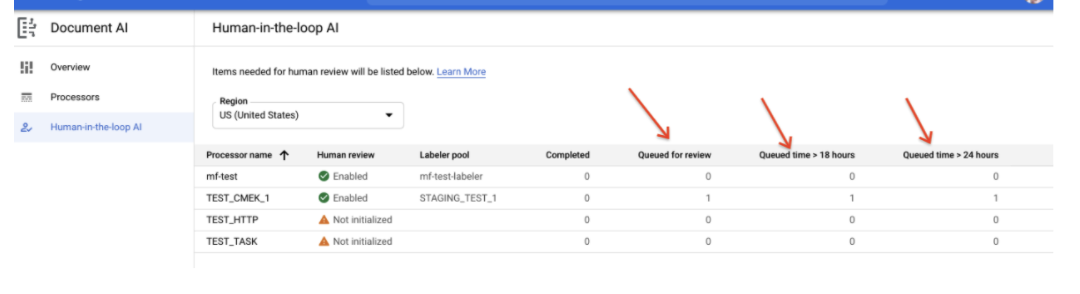
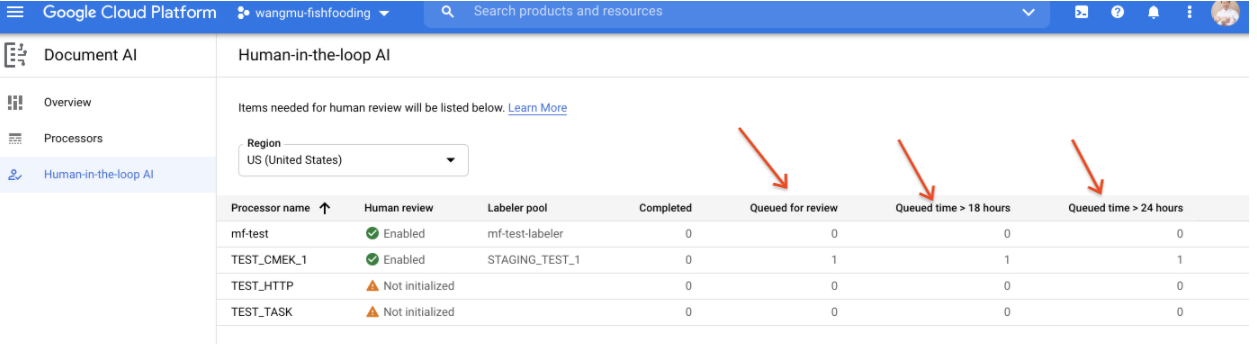
Report Tempo in coda (SLO di latenza HITL)
- Un report mostra il numero di documenti in coda da più di 18 ore e da più di 24 ore. Questa opzione è utile per gli utenti che devono gestire un'aspettativa SLO sulla latenza HITL.
URL noto per Labeler Workbench
- I revisori assegnati a un singolo pool ora possono accedere al workbench a un URL noto e non devono cercare URL criptici inviati nelle notifiche via email (dal sistema o dal responsabile dell'etichettatura). Questo URL non funziona per i revisori assegnati a più pool.
Impostazione dello zoom persistente
- Il plug-in ora ricorda l'impostazione di zoom (larghezza intera o pagina intera) dell'etichettatore per le successive revisioni dei documenti in coda, in modo che non debba ingrandire ogni documento.
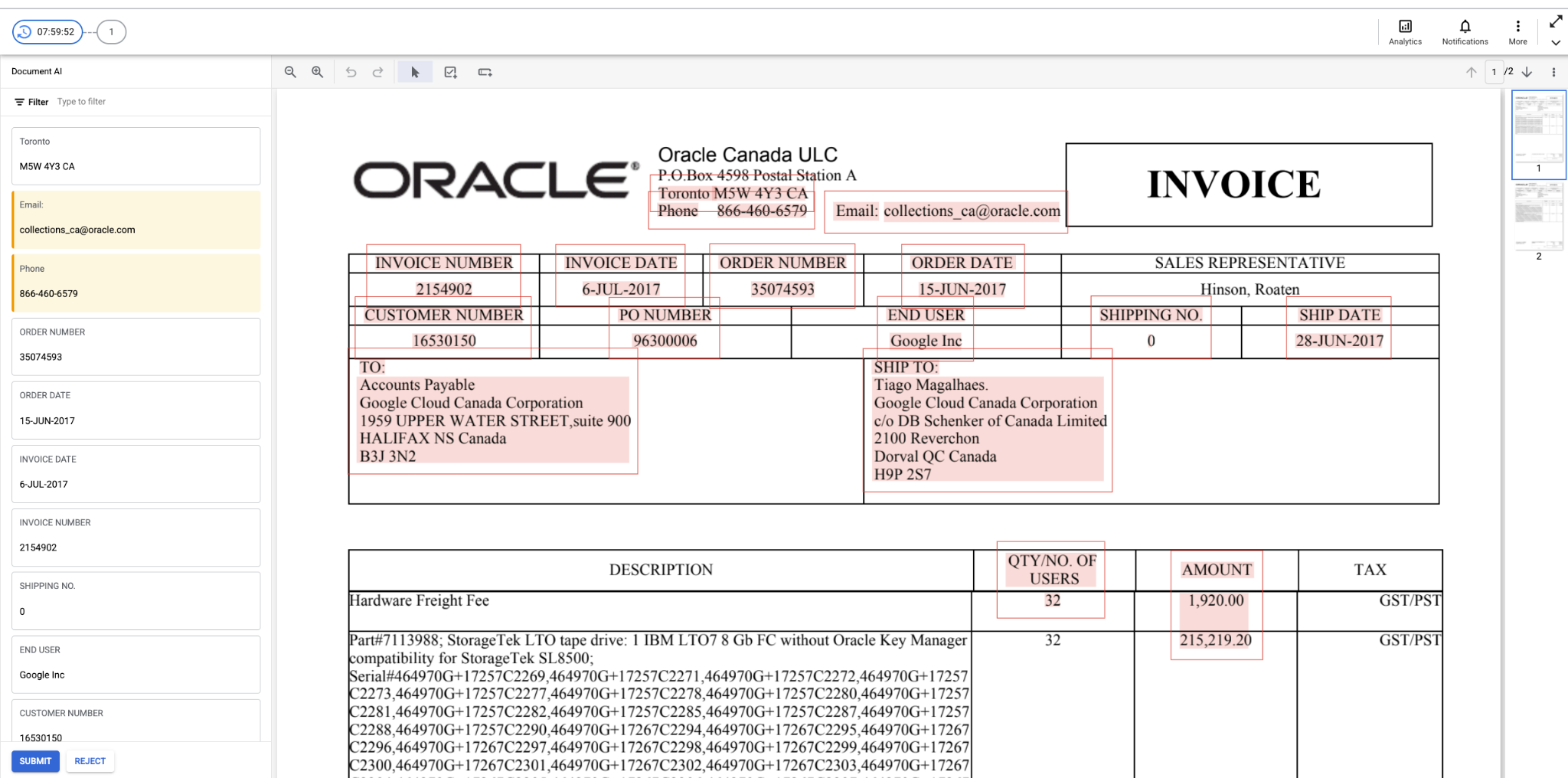
HITL per l'analizzatore sintattico di moduli
- HITL ora supporta Form Parser. Gli utenti possono rivedere e correggere le coppie chiave-valore estratte da Form Parser, attivare HITL sul processore Form Parser nella piattaforma DocAI e configurare i nomi delle chiavi (come mostrato nello screenshot di seguito) che vogliono filtrare per la revisione HITL. Una volta completata la revisione HITL, l'output HITL viene salvato in file JSON nel bucket Google Cloud Storage specificato dal cliente.
- Screenshot dell'interfaccia utente per configurare human-in-the-loop nei parser di moduli
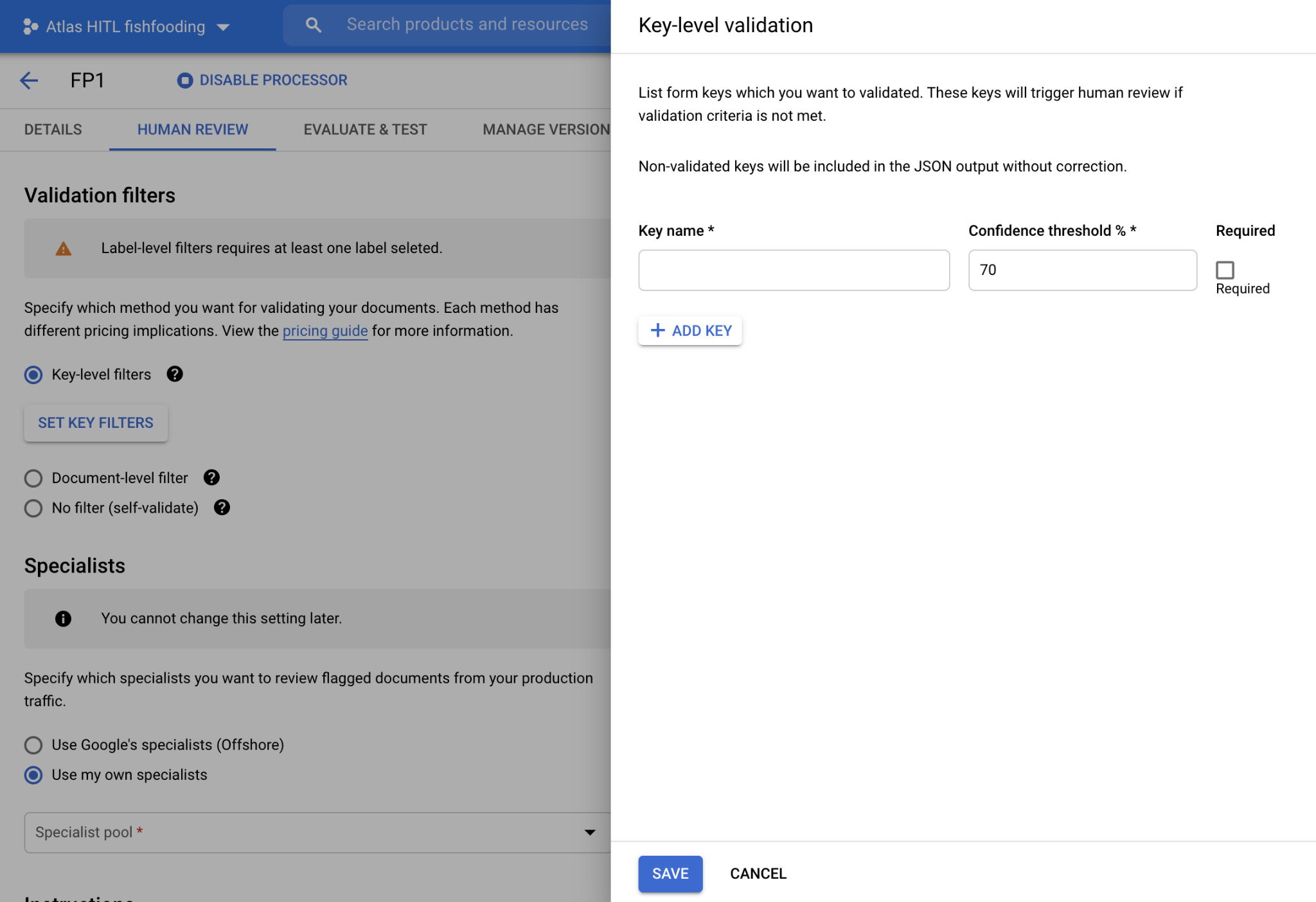
- Interfaccia utente per configurare la convalida a livello di chiave
- Interfaccia utente di Labeler
Pipeline di audit/QA
- HITL ora consente una seconda fase di controllo qualità o di audit e segnala l'accuratezza delle attività di revisione (e dei revisori). Un team di controllo qualità o un revisore può essere assegnato a un'attività come "etichettatore esperto". Il team QA/revisore riceverà una percentuale X (ad esempio 1-100%, configurabile dal cliente) dei documenti esaminati. L'Auditor può correggere l'output del Revisore. Il sistema tiene traccia delle correzioni e assegna un punteggio di accuratezza (ad es. 90%) a ogni documento sottoposto a controllo. Il punteggio di accuratezza aggregato di un'attività o di un etichettatore viene riportato rispettivamente nelle dashboard di analisi delle attività e degli etichettatori. Di seguito sono riportate istruzioni dettagliate sulla configurazione di una pipeline di audit.
Designazione di un revisore
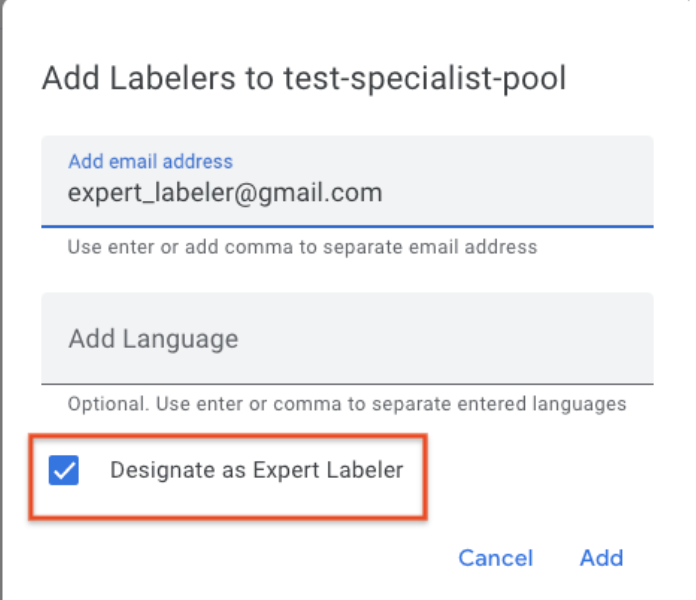
Accuratezza dei report
Parser AI per i prestiti (31 luglio)
- L'HITL è ora supportato su alcuni analizzatori sintattici di Lending AI, tra cui 1040, 1040 Schedule E, 1040 Schedule C, 1099 DIV, 1099 G, 1099 INT, 1099 MISC, buste paga, estratti conto bancari, W2, W9, 1120, 1120S, 1065, SSA-1099, 1099 NEC, 1099-R
Code standard e Fast Track (2 luglio)
- Ora supportiamo due code di priorità (anziché una) per ogni processore, in base all'urgenza di ogni documento.
- Invio: dopo la previsione, i documenti estratti possono essere valutati in base all'urgenza e inviati a due code (standard e urgente/fast track) in base all'urgenza del documento. Ad esempio, le fatture con date di scadenza urgenti possono essere inviate alla coda Fast-track. La logica che valuta l'urgenza può essere inserita tramite una funzione personalizzata.
- Assegnazione delle attività: il responsabile dell'etichettatura vede due code diverse con priorità diverse, come mostrato nello screenshot di seguito, e può assegnare lo stesso gruppo di etichettatori a entrambe le code.
- Assegnazione delle priorità alle attività: gli etichettatori assegnati a entrambe le attività elaboreranno sempre prima i documenti in attesa nella coda Fast-track prima di elaborare la coda Standard (ovvero la priorità della coda viene gestita automaticamente dal sistema)
- Chiamata API: imposta il campo priority (priorità) in ReviewDocument
- Screenshot dell'interfaccia utente (delle attività nell'interfaccia utente di Labeling Manager)
Filtri di convalida per l'endpoint HITL (24 giugno)
- I filtri di convalida (configurati nel processore) che filtrano i campi in base al punteggio di affidabilità per determinare i documenti da mettere in coda per la revisione da parte di persone fisiche vengono ora applicati anche ai documenti inviati all'endpoint HITL.
- Quando chiami l'API
ReviewDocument, imposta il campo enable_schema_validation su true. Tieni presente che, se questa impostazione è configurata e la convalida stabilisce che il documento non deve attivare la revisione umana, verrà restituito un errore CANCELLED.
Annulla API
Puoi annullare un documento messo in coda per l'elaborazione HITL richiamando l'API Cancel per un determinato ID operazione. [Viene restituito un ID operazione per ogni documento inviato ad attività HITL]
`POST https://[us|eu]-documentai.googleapis.com/{api_version}/{name=projects/*/operations/*}:cancel`
Tipo di fattura (revisione della classificazione)
- Labeler Workbench supporta la revisione della classificazione del tipo di fattura.

Report Tempo in coda (SLO di latenza HITL)
- Un report mostra il numero di documenti in coda da più di 18 ore e da più di 24 ore. Questa opzione è utile per gli utenti che devono gestire un'aspettativa SLO sulla latenza HITL.
URL noto per Labeler Workbench
- I revisori assegnati a un singolo pool ora possono accedere al workbench a un URL noto https://datacompute.corp.google.com/w/. Ciò è utile nel caso in cui perdi l'email con l'URL inviato dal sistema o da Labeling Manager. Questo URL non funziona per i revisori assegnati a più pool.
Impostazione dello zoom persistente
- Il plug-in ora ricorda l'impostazione di zoom (larghezza intera o pagina intera) di un etichettatore per le successive revisioni dei documenti in coda, in modo che non debba ingrandire ogni documento.