Enterprise Document OCR は、Document AI の一部として使用して、さまざまなドキュメントからテキストとレイアウト情報を検出して抽出できます。構成可能な機能を使用すると、特定のドキュメント処理要件を満たすようにシステムを調整できます。
概要
Enterprise Document OCR は、アルゴリズムや ML に基づくデータ入力、データ精度の向上と検証などのタスクに使用できます。Enterprise Document OCR を使用して、次のようなタスクを処理することもできます。
- テキストのデジタル化: 検索、ルールベースのドキュメント処理パイプライン、カスタムモデルの作成のために、ドキュメントからテキストとレイアウトのデータを抽出します。
- 大規模言語モデル アプリケーションの使用: LLM のコンテキスト理解と OCR のテキストとレイアウトの抽出機能を使用して、質問と回答を自動化します。データから分析情報を引き出し、ワークフローを効率化します。
- アーカイブ: 紙のドキュメントを機械読み取り可能なテキストに変換して、ドキュメントのアクセシビリティを向上させます。
ユースケースに最適な OCR の選択
| ソリューション | プロダクト | 説明 | ユースケース |
|---|---|---|---|
| Document AI | Enterprise Document OCR | ドキュメントのユースケースに特化したモデル。高度な機能には、画像の品質スコア、言語ヒント、回転補正などがあります。 | ドキュメントからテキストを抽出する場合におすすめします。ユースケースには、PDF、画像としてのスキャンされたドキュメント、Microsoft DocX ファイルなどがあります。 |
| Document AI | OCR アドオン | 特定の要件に対応するプレミアム機能。Enterprise Document OCR バージョン 2.0 以降とのみ互換性があります。 | 数式を検出して認識する必要がある、フォント スタイル情報を受け取る必要がある、またはチェックボックスの抽出を有効にする必要がある。 |
| Cloud Vision API | テキスト検出 | Google Cloud 標準 OCR モデルに基づくグローバルに利用可能な REST API。デフォルトの割り当ては 1 分あたり 1,800 リクエストです。 | 低レイテンシと高容量を必要とする一般的なテキスト抽出のユースケース。 |
| Cloud Vision | OCR Google Distributed Cloud(非推奨) | GKE Enterprise を使用して任意の GKE クラスタにコンテナとしてデプロイできる Google Cloud Marketplace アプリケーション。 | データ所在地またはコンプライアンスの要件を満たすため。 |
検出と抽出
Enterprise Document OCR は、PDF や画像からブロック、段落、行、単語、記号を検出できるほか、ドキュメントの歪みを補正して精度を高めることもできます。
サポートされているレイアウトの検出と抽出の属性:
| 印刷されたテキスト | 手書き入力 | 段落 | ブロック | ライン | Word | シンボルレベル | ページ番号 |
|---|---|---|---|---|---|---|---|
| デフォルト | デフォルト | デフォルト | デフォルト | デフォルト | デフォルト | 構成可能 | デフォルト |
構成可能な Enterprise Document OCR 機能には、次のものがあります。
デジタル PDF から埋め込みテキストまたはネイティブ テキストを抽出する: この機能では、回転したテキスト、極端なフォントサイズやスタイル、部分的に隠れたテキストなど、原本のドキュメントに表示されているとおりにテキストや記号が抽出されます。
回転補正: Enterprise Document OCR を使用してドキュメント画像を前処理し、抽出の品質や処理に影響する可能性のある回転の問題を修正します。
画質スコア: ドキュメントのルーティングに役立つ品質指標を取得します。画質スコアは、ぼやけ、通常よりも小さいフォントの有無、グレアなど、8 つの項目においてページ単位での品質指標を提供します。
ページ範囲を指定: OCR の入力ドキュメント内のページの範囲を指定します。これにより、不要なページでの費用と処理時間を節約できます。
言語検出: 抽出されたテキストで使用されている言語を検出します。
言語と手書きのヒント: データセットの既知の特性に基づいて OCR モデルに言語または手書きのヒントを提供することで、精度を向上させます。
OCR 構成を有効にする方法については、OCR 構成を有効にするをご覧ください。
OCR アドオン
Enterprise Document OCR には、必要に応じて個々の処理リクエストで有効にできるオプションの分析機能があります。
次のアドオン機能は、安定版の pretrained-ocr-v2.0-2023-06-02 バージョンと pretrained-ocr-v2.1-2024-08-07 バージョン、リリース候補版の pretrained-ocr-v2.1.1-2025-01-31 バージョンで利用できます。
- 数式 OCR: LaTeX 形式のドキュメントから数式を特定し、抽出します。
- チェックボックスの抽出: チェックボックスを検出し、Enterprise Document OCR レスポンスでステータス(チェック済み/未チェック)を抽出します。
- フォント スタイルの検出: フォントの種類、フォント スタイル、手書き、太さ、色など、単語レベルのフォント プロパティを特定します。
一覧に表示されているアドオンを有効にする方法については、OCR アドオンを有効にするをご覧ください。
サポートされているファイル形式
Enterprise Document OCR は、PDF、GIF、TIFF、JPEG、PNG、BMP、WebP のファイル形式をサポートしています。詳しくは、サポートされているファイルをご覧ください。
Enterprise Document OCR は、同期で最大 15 ページ、非同期で最大 30 ページの DocX ファイルもサポートしています。割り当て増加リクエスト(QIR)を行うには、割り当ての調整をリクエストするの手順に沿って操作します。DocX のサポートは限定公開プレビュー版です。アクセス権のリクエストについては、Google アカウント チームにお問い合わせください。
高度なバージョニング
高度なバージョニングはプレビュー版です。基盤となる AI/ML OCR モデルのアップグレードにより、OCR の動作が変更されることがあります。厳密な整合性が必要な場合は、フリーズされたモデル バージョンを使用して、最大 18 か月間、動作を以前の OCR モデルに固定します。これにより、同じ画像から OCR 機能の結果が得られます。プロセッサ バージョンに関する表をご覧ください。
プロセッサ バージョン
この機能に対応しているプロセッサのバージョンは次のとおりです。詳細については、プロセッサ バージョンの管理をご覧ください。
| バージョン ID | リリース チャンネル | 説明 |
|---|---|---|
pretrained-ocr-v1.2-2022-11-10 |
Stable | フリーズされたモデル バージョン v1.0: コンテナ イメージで最大 18 か月間フリーズされたバージョン スナップショットのモデルファイル、構成、バイナリ。 |
pretrained-ocr-v2.0-2023-06-02 |
Stable | ドキュメント ユースケースに特化した本番環境対応モデル。すべての OCR アドオンへのアクセスが含まれます。 |
pretrained-ocr-v2.1-2024-08-07 |
Stable | v2.1 の主な改善点は、印刷されたテキストの認識の向上、チェックボックスの検出の精度向上、読み取り順序の精度向上です。 |
pretrained-ocr-v2.1.1-2025-01-31 |
リリース候補 | v2.1.1 は V2.1 と同様で、US、EU、asia-southeast1 を除くすべてのリージョンで利用できます。 |
Enterprise Document OCR を使用してドキュメントを処理する
このクイックスタートでは、Enterprise Document OCR の概要について説明します。このドキュメントでは、使用可能な OCR 構成を有効または無効にして、ワークフローのドキュメント OCR 結果を最適化する方法について説明します。
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. quality/defect_blurryquality/defect_noisyquality/defect_darkquality/defect_faintquality/defect_text_too_smallquality/defect_document_cutoffquality/defect_text_cutoffquality/defect_glare- 欠陥のないデジタル ドキュメントで誤検出が返されることがあります。この機能は、スキャンしたドキュメントや撮影したドキュメントに最適です。
グレアの欠陥はローカルです。それらの存在がドキュメント全体の読みやすさを妨げない可能性があります。
- 2 ページ目と 5 ページ目のみを処理するには:
- 最初の 3 ページのみを処理するには:
- 最後の 4 ページのみを処理するには:
画像が検出されました
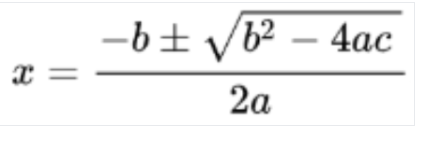
LaTeX への変換
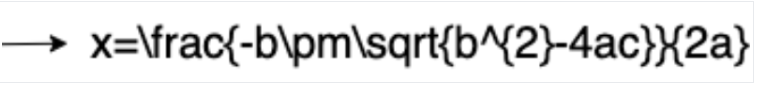
- Vision AI API レスポンスは、画像リクエストの場合は
verticesのみを入力し、PDF リクエストの場合はnormalized_verticesのみを入力します。Document AI のレスポンスとコンバータは、verticesとnormalized_verticesの両方に値を入力します。 - Vision AI API レスポンスは、単語の最後の記号の
detected_breakを入力します。Document AI API レスポンスとコンバータは、単語と単語の最後の記号のdetected_breakを入力します。 - Vision AI API のレスポンスでは、常にシンボル フィールドが入力されます。デフォルトでは、Document AI のレスポンスに記号フィールドは入力されません。Document AI のレスポンスとコンバータでシンボル フィールドが入力されるようにするには、
enable_symbol機能を詳細に設定します。 - LOCATION: プロセッサのロケーション(例:
-
)
us- 米国eu- 欧州連合
- PROJECT_ID: 実際の Google Cloud プロジェクト ID。
- PROCESSOR_ID: カスタム プロセッサの ID。
- PROCESSOR_VERSION: プロセッサのバージョン ID。詳細については、プロセッサ バージョンを選択するをご覧ください。例:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- skipHumanReview: 人間によるレビューを無効にするブール値(人間参加型プロセッサでのみサポートされます)。
true- 人間によるレビューをスキップしますfalse- 人間による確認を有効にします(デフォルト)
- MIME_TYPE†: 有効な MIME タイプ オプションのいずれか。
- IMAGE_CONTENT†: 有効なインライン ドキュメント コンテンツのいずれか。バイト ストリームとして表されます。JSON 表現の場合、バイナリ画像データの base64 エンコード(ASCII 文字列)。これは次のような文字列になります。
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==
- FIELD_MASK:
Document出力に含めるフィールドを指定します。これは、FieldMask形式の完全修飾フィールド名のカンマ区切りリストです。- 例:
text,entities,pages.pageNumber
- 例:
- OCR 構成
- ENABLE_NATIVE_PDF_PARSING: (ブール値)PDF から埋め込みテキストを抽出します(利用可能な場合)。
- ENABLE_IMAGE_QUALITY_SCORES: (ブール値)ドキュメントのインテリジェントな品質スコアを有効にします。
- ENABLE_SYMBOL: (ブール値)記号(文字)の OCR 情報を含めます。
- DISABLE_CHARACTER_BOXES_DETECTION:(ブール値)OCR エンジンで文字ボックス検出ツールを無効にします。
- LANGUAGE_HINTS: OCR に使用する BCP-47 言語コードのリスト。
- ADVANCED_OCR_OPTIONS: OCR の動作をさらに微調整するための高度な OCR オプションのリスト。現在の有効な値は次のとおりです。
legacy_layout: 現在の ML ベースのレイアウト検出アルゴリズムの代替となるヒューリスティック レイアウト検出アルゴリズム。
- プレミアム OCR アドオン
- ENABLE_SELECTION_MARK_DETECTION:(ブール値)OCR エンジンで選択マーク検出ツールを有効にします。
- COMPUTE_STYLE_INFO(ブール値)フォント識別モデルを有効にして、フォント スタイル情報を返します。
- ENABLE_MATH_OCR: (ブール値)LaTeX 数学公式を抽出できるモデルを有効にします。
- INDIVIDUAL_PAGES: 処理する個々のページのリスト。
- プロセッサ リストを確認します。
- レイアウト パーサーを使用してドキュメントを読み取り可能なチャンクに分割します。
- カスタム分類子を作成します。
Enterprise Document OCR プロセッサを作成する
まず、Enterprise Document OCR プロセッサを作成します。詳細については、プロセッサの作成と管理をご覧ください。
OCR 構成
すべての OCR 構成は、ProcessDocumentRequest または BatchProcessDocumentsRequest の ProcessOptions.ocrConfig でそれぞれのフィールドを設定することで有効にできます。
詳細については、処理リクエストを送信するをご覧ください。
画質分析
インテリジェントなドキュメント品質分析では、機械学習を使用して、コンテンツの読みやすさに基づいてドキュメントの品質評価を行います。この品質評価は品質スコア [0, 1] として返されます。1 は品質が完全であることを意味します。検出された品質スコアが 0.5 未満の場合、品質が低い理由のリスト(可能性が高い順)も返されます。尤度が 0.5 より大きい場合は、ポジティブな検出と見なされます。
ドキュメントに欠陥があると判断された場合、API は次の 8 つのドキュメントの欠陥タイプを返します。
現在のドキュメント品質分析には、いくつかの制限があります。
入力
処理リクエストで ProcessOptions.ocrConfig.enableImageQualityScores を true に設定して有効にします。この追加機能により、処理のコールへの OCR 処理と同程度の遅延が増えます。
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableImageQualityScores": true
}
}
}
出力
欠陥検出の結果は Document.pages[].imageQualityScores[] に表示されます。
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
完全な出力例については、サンプル プロセッサ出力をご覧ください。
言語ヒント
OCR プロセッサは、OCR エンジンのパフォーマンスを向上させるために定義する言語ヒントをサポートしています。言語ヒントを適用すると、OCR は推測された言語ではなく、選択された言語に合わせて最適化されます。
入力
BCP-47 言語コードのリストで ProcessOptions.ocrConfig.hints[].languageHints[] を設定して有効にします。
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"hints": {
"languageHints": ["en", "es"]
}
}
}
}
完全な出力例については、サンプル プロセッサ出力をご覧ください。
記号検出
ドキュメント レスポンスでシンボル(または個々の文字)レベルでデータを入力します。
入力
処理リクエストで ProcessOptions.ocrConfig.enableSymbol を true に設定することで有効になります。
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableSymbol": true
}
}
}
出力
この機能が有効になっている場合、Document.pages[].symbols[] フィールドに値が入力されます。
完全な出力例については、サンプル プロセッサ出力をご覧ください。
組み込みの PDF 解析
デジタル PDF ファイルから埋め込みテキストを抽出します。有効にすると、デジタル テキストがある場合、組み込みのデジタル PDF モデルが自動的に使用されます。デジタル以外のテキストがある場合は、光学式 OCR モデルが自動的に使用されます。ユーザーは、両方のテキスト結果が統合された状態で受け取ります。
入力
処理リクエストで ProcessOptions.ocrConfig.enableNativePdfParsing を true に設定することで有効になります。
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": true
}
}
}
ボックス内の文字の検出
デフォルトでは、Enterprise Document OCR には、ボックス内の文字のテキスト抽出の品質を向上させる検出器が有効になっています。以下に例を示します。

ボックス内の文字で OCR の品質に関する問題が発生している場合は、この機能を無効にできます。
入力
処理リクエストで ProcessOptions.ocrConfig.disableCharacterBoxesDetection を true に設定して無効にします。
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"disableCharacterBoxesDetection": true
}
}
}
以前のレイアウト
ヒューリスティック レイアウト検出アルゴリズムが必要な場合は、現在の ML ベースのレイアウト検出アルゴリズムの代替として機能する以前のレイアウトを有効にできます。これは推奨される構成ではありません。お客様は、ドキュメント ワークフローに基づいて最適なレイアウト アルゴリズムを選択できます。
入力
処理リクエストで ProcessOptions.ocrConfig.advancedOcrOptions を ["legacy_layout"] に設定することで有効になります。
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"advancedOcrOptions": ["legacy_layout"]
}
}
}
ページ範囲を指定する
デフォルトでは、OCR はドキュメントのすべてのページからテキストとレイアウト情報を抽出します。特定のページ番号またはページ範囲を選択して、それらのページからのみテキストを抽出できます。
ProcessOptions でこれを構成する方法は 3 つあります。
{
"individualPageSelector": {"pages": [2, 5]}
}
{
"fromStart": 3
}
{
"fromEnd": 4
}
レスポンスでは、各 Document.pages[].pageNumber はリクエストで指定された同じページに対応します。
OCR アドオンの使用
これらの Enterprise Document OCR のオプションの分析機能は、必要に応じて個々の処理リクエストで有効にできます。
数学 OCR
数式 OCR は、LaTeX で表される数式などの数式を検出し、認識して、境界ボックスの座標とともに抽出します。
LaTeX 表現の例を次に示します。
入力
処理リクエストで ProcessOptions.ocrConfig.premiumFeatures.enableMathOcr を true に設定することで有効になります。
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableMathOcr": true
}
}
}
}
出力
数式 OCR の出力は、"type": "math_formula" を含む Document.pages[].visualElements[] に表示されます。
"visualElements": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "46"
}
]
},
"confidence": 1,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.14662756,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.8027211
},
{
"x": 0.14662756,
"y": 0.8027211
}
]
},
"orientation": "PAGE_UP"
},
"type": "math_formula"
}
]
選択マークの抽出
有効にすると、モデルはドキュメント内のすべてのチェックボックスとラジオボタンを境界ボックスの座標とともに抽出します。
入力
処理リクエストで ProcessOptions.ocrConfig.premiumFeatures.enableSelectionMarkDetection を true に設定することで有効になります。
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableSelectionMarkDetection": true
}
}
}
}
出力
チェックボックスの出力は、Document.pages[].visualElements[] に "type": "unfilled_checkbox" または "type": "filled_checkbox" として表示されます。

"visualElements": [
{
"layout": {
"confidence": 0.89363575,
"boundingPoly": {
"vertices": [
{
"x": 11,
"y": 24
},
{
"x": 37,
"y": 24
},
{
"x": 37,
"y": 56
},
{
"x": 11,
"y": 56
}
],
"normalizedVertices": [
{
"x": 0.017488075,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.9032258
},
{
"x": 0.017488075,
"y": 0.9032258
}
]
}
},
"type": "unfilled_checkbox"
},
{
"layout": {
"confidence": 0.9148201,
"boundingPoly": ...
},
"type": "filled_checkbox"
}
],
フォント スタイルの検出
フォント スタイルの検出を有効にすると、Enterprise Document OCR はフォント属性を抽出し、後処理の改善に使用できます。
トークン(単語)レベルでは、次の属性が検出されます。
入力
処理リクエストで ProcessOptions.ocrConfig.premiumFeatures.computeStyleInfo を true に設定することで有効になります。
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"computeStyleInfo": true
}
}
}
}
出力
font-style 出力は、タイプ StyleInfo の Document.pages[].tokens[].styleInfo に表示されます。

"tokens": [
{
"styleInfo": {
"fontSize": 3,
"pixelFontSize": 13,
"fontType": "SANS_SERIF",
"bold": true,
"fontWeight": 564,
"textColor": {
"red": 0.16862746,
"green": 0.16862746,
"blue": 0.16862746
},
"backgroundColor": {
"red": 0.98039216,
"green": 0.9882353,
"blue": 0.99215686
}
}
},
...
]
ドキュメント オブジェクトを Vision AI API 形式に変換する
Document AI Toolbox には、Document AI API の Document 形式を Vision AI の AnnotateFileResponse 形式に変換するツールが含まれています。これにより、ユーザーはドキュメント OCR プロセッサと Vision AI API のレスポンスを比較できます。サンプルコードを以下に示します。
Vision AI API レスポンスと Document AI API レスポンスおよびコンバータの既知の不一致:
コードサンプル
次のコードサンプルは、OCR 構成とアドオンを有効にして処理リクエストを送信し、フィールドを読み取ってターミナルに出力する方法を示しています。
REST
リクエストのデータを使用する前に、次のように置き換えます。
† このコンテンツは、inlineDocument オブジェクトで Base64 エンコードされたコンテンツを使用して指定することもできます。
HTTP メソッドと URL:
POST https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
リクエストの本文(JSON):
{
"skipHumanReview": skipHumanReview,
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"fieldMask": "FIELD_MASK",
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": ENABLE_NATIVE_PDF_PARSING,
"enableImageQualityScores": ENABLE_IMAGE_QUALITY_SCORES,
"enableSymbol": ENABLE_SYMBOL,
"disableCharacterBoxesDetection": DISABLE_CHARACTER_BOXES_DETECTION,
"hints": {
"languageHints": [
"LANGUAGE_HINTS"
]
},
"advancedOcrOptions": ["ADVANCED_OCR_OPTIONS"],
"premiumFeatures": {
"enableSelectionMarkDetection": ENABLE_SELECTION_MARK_DETECTION,
"computeStyleInfo": COMPUTE_STYLE_INFO,
"enableMathOcr": ENABLE_MATH_OCR,
}
},
"individualPageSelector" {
"pages": [INDIVIDUAL_PAGES]
}
}
}
リクエストを送信するには、次のいずれかのオプションを選択します。
curl
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
リクエストが成功すると、サーバーは 200 OK HTTP ステータス コードと JSON 形式のレスポンスを返します。レスポンスの本文には Document のインスタンスが含まれます。
Python
詳細については、Document AI Python API リファレンス ドキュメントをご覧ください。
Document AI に対する認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。