Document AI uses Enterprise Knowledge Graph to normalize and
enrich entity extraction results (for supported fields). For example, the addresses
123 Main St Apt 1 and 123 Main street # 1 could be normalized to the same
standardized address.
For each supported field, Document AI also returns a normalizedValue
in addition to the raw extracted field, normalizing the literal text.
This contains the data in a standardized format to reduce post-processing.
Most data belongs to one of the following categories:
- Money
- Date
- Timestamp
- Address
- Boolean
- Integer
- Float
Sample response
The enriched values can be found in the
entities.normalizedValue
field as shown in the following truncated sample:
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "employer_name",
"mentionText": "Google Singapore",
"confidence": 0.69933707,
"pageAnchor": {
"pageRefs": [
{
"boundingPoly": {
"normalizedVertices": [ ... ]
}
}
]
},
"id": "9",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
}
]
}
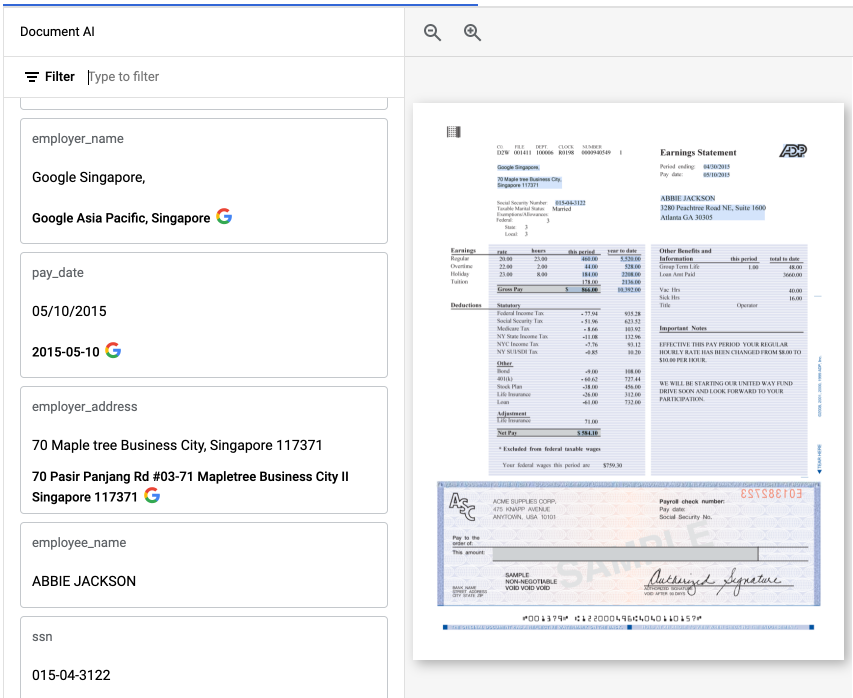
In the sample, the original employer_name "Google Singapore" has been
normalized to "Google Asia Pacific, Singapore".
In the Google Cloud console, the enriched and normalized fields are annotated with G. For example:
Supported processors
Here are the processors and fields that support entity enrichment.
| Processors | Enriched fields | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Bank Statement Parser
|
|
||||||||||||
W2 Parser
|
|
||||||||||||
Pay Slip Parser
|
|
||||||||||||
Expense Parser
|
|
||||||||||||
Invoice Parser
|
|