Crea, usa y administra un clasificador de documentos personalizado
Usa el clasificador personalizado para clasificar documentos. Compílalo desde cero con tus propios documentos y clases personalizadas. Su aspecto de IA generativa permite el aprendizaje en pocos intentos y el ajuste. Estos modelos mejoran la precisión con menos muestras y correcciones con el etiquetado automático iterativo.
El clasificador personalizado abarca estos tres casos de uso generales.
- Modelo previamente entrenado: Usa el modelo de base de IA generativa previamente entrenado para clasificar rápidamente documentos con las etiquetas que proporcionaste.
- Ajuste: Mejora la precisión entrenando el modelo de base de IA generativa con tus propios datos y etiquetas.
- Entrena un modelo personalizado: Entrena un extractor personalizado que no use IA generativa con tus propios datos y etiquetas.
Versiones del modelo de clasificador personalizado
| Versión del modelo | Descripción | Canal de versiones | Procesamiento de AA en EE.UU. y la UE | Ajuste en EE.UU. y la UE | Fecha de lanzamiento |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-05-16 |
Es una versión candidata para lanzamiento potenciada por el LLM de Gemini 2.0 Flash. También incluye funciones avanzadas de OCR. | Versión candidata para lanzamiento | Sí | EE.UU., UE (vista previa) | 16 de mayo de 2025 |
pretrained-classifier-v1.5-2025-08-05 |
Es una versión candidata para lanzamiento potenciada por el LLM de Gemini 2.5 Flash. También incluye funciones avanzadas de OCR. | Versión candidata para lanzamiento | Sí | EE.UU., UE (vista previa) | 5 de agosto de 2025 |
Las puntuaciones de confianza no se admiten en los modelos de clasificadores personalizados.
Crea un clasificador personalizado en la consola de Google Cloud
Puedes crear clasificadores personalizados que se adaptan específicamente a tus documentos, entrenados y evaluados con tus datos. Este procesador identifica las clases de documentos de un conjunto de clases definido por el usuario. Luego, puedes este procesador entrenado en documentos adicionales. Por lo general, se usa un clasificador personalizado en documentos de distintos tipos y, luego, se usa la identificación para pasar los documentos a un procesador de extracción para extraer las entidades.
Para conocer el proceso general para crear y usar un procesador, consulta la sección Cómo.
Puedes realizar tus propias opciones de configuración que se adapten a tu flujo de trabajo.
Para seguir la guía paso a paso sobre esta tarea directamente en la consola Google Cloud , haz clic en Guiarme:
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Ve a Workbench.
En el clasificador de documentos personalizado, selecciona
Crear procesador .
En el menú Crear procesador, ingresa un nombre para tu procesador, como
my-custom-document-classifier.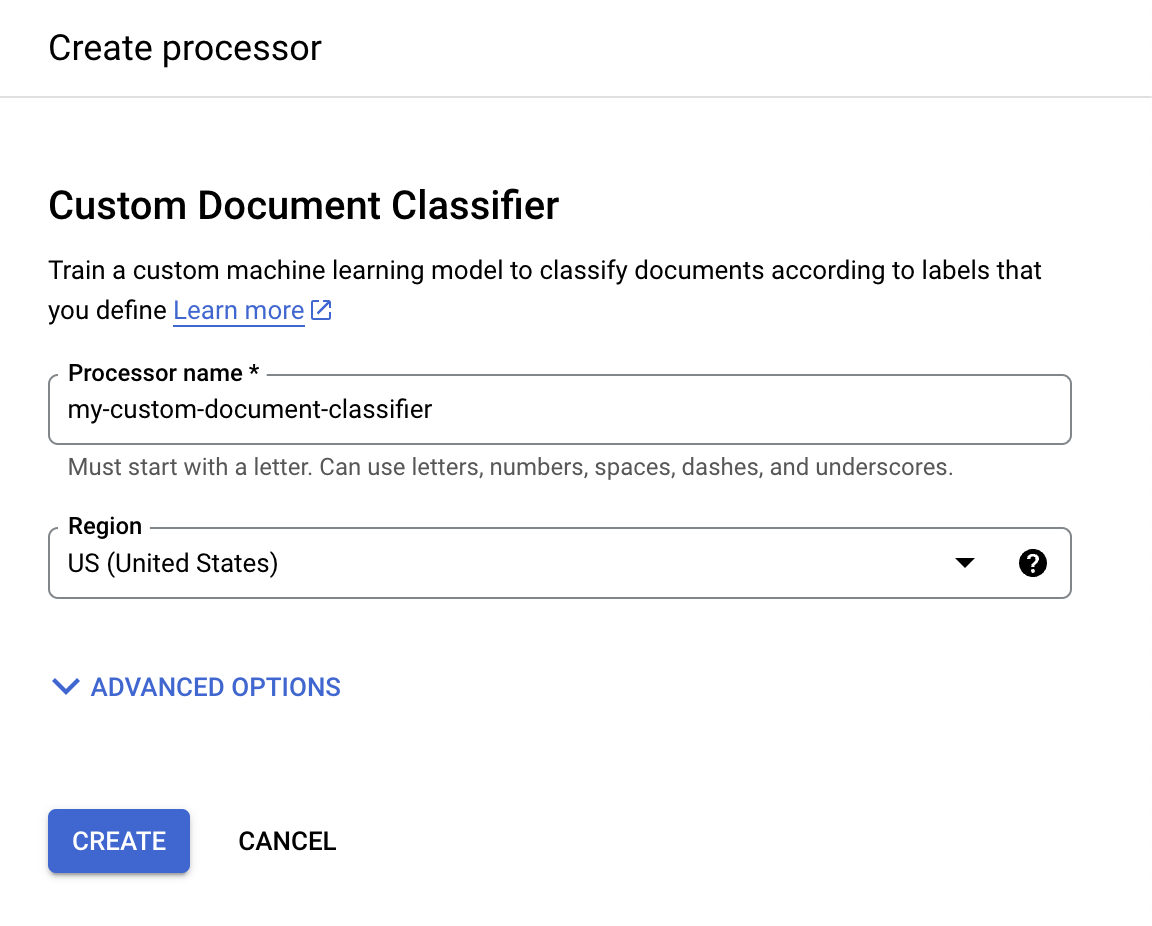
Selecciona la región más cercana a ti.
Selecciona Crear. Aparecerá la pestaña Processor Details.
- Seleccionar Almacenamiento administrado por Google en caso de que quieras usar Cloud Storage.
- Selecciona Especificaré mi propia ubicación de almacenamiento si deseas usar tu propio almacenamiento para usar claves de encriptación administradas por el cliente (CMEK) y sigue el procedimiento en Crea un conjunto de datos.
En la pestaña Compilación, selecciona
Importar documentos .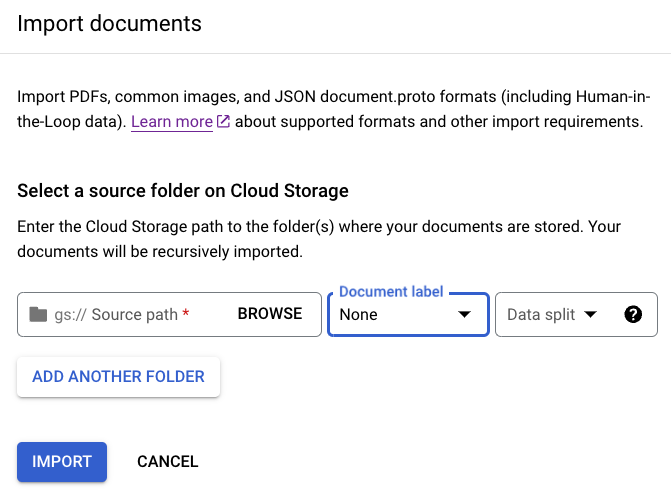
Cuando elijas usar un bucket de almacenamiento, debes ingresar la Ruta de acceso de origen del bucket. Para este ejemplo de entrenamiento, ingresa el nombre de este bucket en
Ruta de acceso de origen . Esta vincula directamente a un documento.cloud-samples-data/documentai/Custom/Patents/PDF/computer_vision_20.pdfEn División de datos, selecciona Sin asignar. El documento de esta carpeta no está asignado al conjunto de prueba ni de entrenamiento. Deje desmarcada la opción Importar con etiquetado automático.
Selecciona Importar. Document AI lee los documentos del bucket en el conjunto de datos. No modifica el bucket de importación ni lee desde el bucket una vez que se completa la importación.
Opcional: Para borrar documentos importados, en la pestaña Compilación, ve a Administrar conjunto de datos > selecciona los documentos > haz clic en Borrar.
En la pestaña Compilación, selecciona Administrar conjunto de datos > Editar esquema. Se abrirá la página Editar esquema.
Selecciona
Crear etiqueta .Ingresa el nombre de la etiqueta.
Selecciona Crear. Consulta Define el procesador del esquema para obtener instrucciones detalladas para crear y editar un esquema.
Crea cada una de las siguientes etiquetas para el esquema del procesador.
computer_visioncryptomed_techother
Selecciona
Guardar cuando las etiquetas estén completas.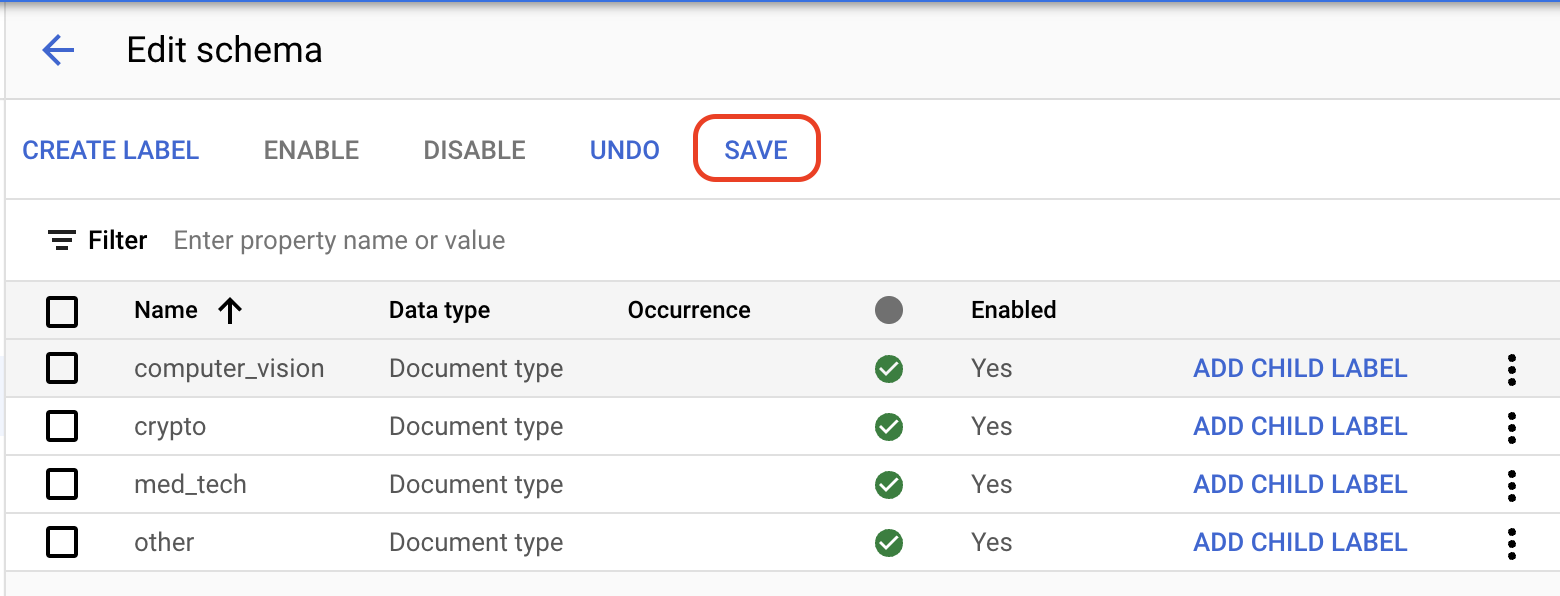
Regresa a la pestaña Compilación y selecciona
un documento para abrir la consola de Administrar conjunto de datos.Entre las
opciones , selecciona la etiqueta adecuada para el documento. Si usas el documento de muestra proporcionado, seleccionacomputer_vision.Cuando esté etiquetado, el documento debería verse de la siguiente manera:
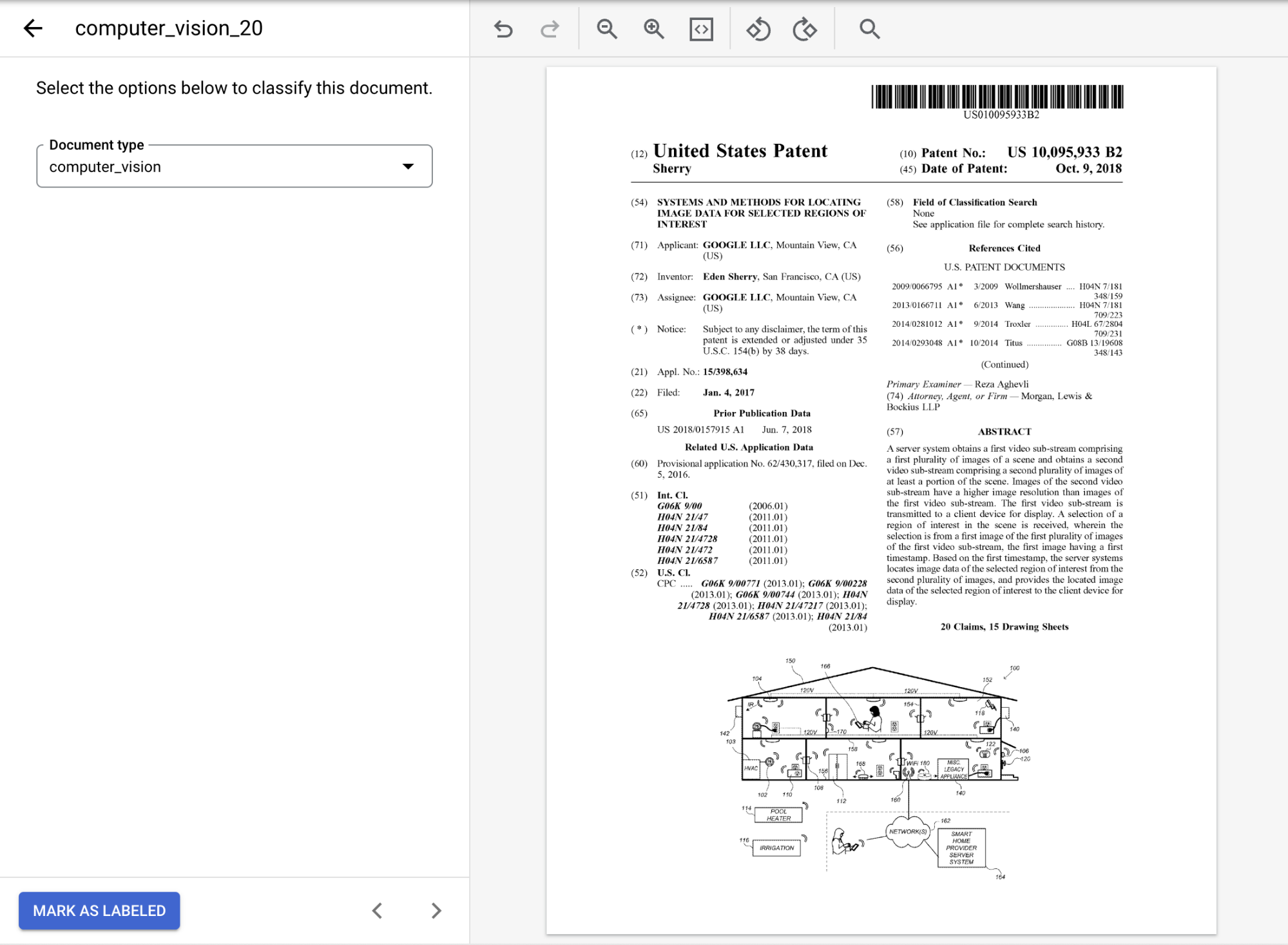
Selecciona
Marcar como etiquetado cuando termines de anotar el documento.En la pestaña Administrar conjunto de datos, el panel Documento muestra que se etiquetó un documento.
En la pestaña Administrar conjunto de datos, selecciona la casilla de verificación
Seleccionar todo .En la lista
Asignar al conjunto , selecciona Entrenamiento.Selecciona
Importar documentos .Ingresa la siguiente ruta en
Ruta de acceso del origen . Este bucket contiene documentos etiquetados previamente en el formato Documento JSON.cloud-samples-data/documentai/Custom/Patents/JSON/Classification-InventionTypeEn la lista División de datos, selecciona División automática. Esto divide automáticamente los documentos para tener un 80% en el conjunto de entrenamiento y un 20% en el conjunto de prueba. Ignora la sección Aplicar etiquetas.
Selecciona Importar. La importación puede tardar varios minutos en completarse.
Selecciona
Importar documentos .Ingresa la siguiente ruta en
Ruta de acceso del origen . Este bucket contiene documentos sin etiquetar en formato PDF.cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabelEn la lista División de datos, selecciona División automática. Esto divide automáticamente los documentos para tener un 80% en el conjunto de entrenamiento y un 20% en el conjunto de prueba.
En la sección Aplicar etiquetas, selecciona Elegir etiqueta.
Para estos documentos de muestra, selecciona
other.Selecciona Importar y espera a que finalice el proceso. Puedes salir de esta página y volver más tarde. Cuando termines, encontrarás los documentos en la pestaña Administrar conjunto de datos con la etiqueta aplicada.
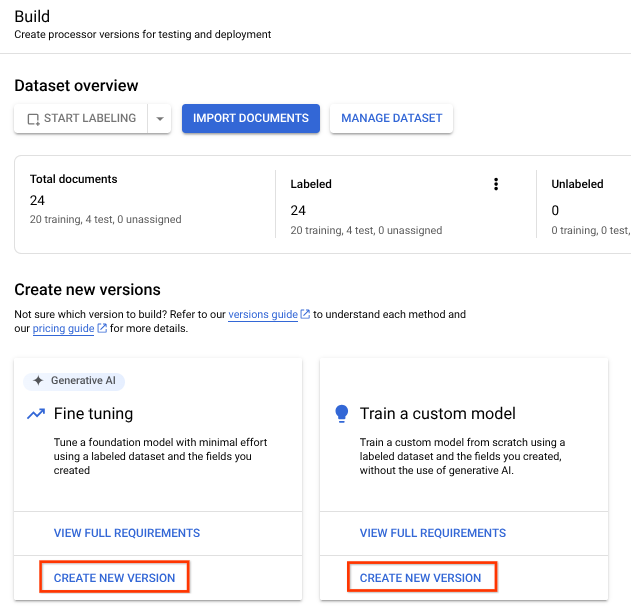
- Selecciona
Entrenar una versión nueva . En el campo
Nombre de la versión , ingresa un nombre para esta versión del procesador, comomy-cdc-version-1.Opcional: Selecciona Ver estadísticas de etiquetas para buscar información sobre las etiquetas de documentos que pueden ayudarte a determinar tu cobertura. Selecciona Cerrar para volver a la configuración de entrenamiento.
Selecciona
Iniciar entrenamiento. Puedes verificar el estado en el panel lateral.Una vez finalizado el entrenamiento, navega a la pestaña
Administrar versiones . Puedes ver detalles sobre la versión que acabas de entrenar.Selecciona
junto a la versión que deseas implementar y, luego, Implementar versión. Selecciona
Implementar en la ventana de diálogo.La implementación tarda unos minutos en completarse.
Una vez finalizada la implementación, navega a la pestaña
Evaluar y probar .En esta página, puedes ver las métricas de evaluación, incluidas la puntuación F1, la precisión y recuperación del documento completo, y las etiquetas individuales. Para obtener más información sobre la evaluación y las estadísticas, consulta Evalúa el procesador.
Descarga un documento que no haya participado en pruebas ni entrenamientos anteriores para que puedas usarlo para evaluar la versión del procesador. Si usas tus propios datos, debes usar un documento que se reserve para ello.
Selecciona
Subir documento de prueba y selecciona el documento que acabas de descargar.Se abrirá la página Análisis de clasificadores personalizados de documentos. El resultado demuestra qué tan bien se clasificó el documento.
También puedes volver a ejecutar la evaluación en un conjunto de prueba diferente o en una versión del procesador.
En la página Administrar conjunto de datos,
Importar documentos .Copia y pega la siguiente ruta de Cloud Storage. Este directorio contiene cinco PDFs de facturas sin etiquetar. En la lista desplegable División de datos, selecciona Entrenamiento.
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-AutoLabelEn la sección Aplicar etiquetas, selecciona Etiquetado automático.
Selecciona una versión del procesador existente para etiquetar los documentos.
- Por ejemplo:
2af620b2fd4d1fcf.
- Por ejemplo:
Selecciona Importar y espera a que finalice el proceso. Puedes salir de esta página y volver más tarde. Cuando se complete el proceso, los documentos aparecerán en la sección Etiquetado automático de la página Administrar conjunto de datos.
No puedes usar documentos etiquetados automáticamente para entrenamiento ni pruebas sin marcarlos como etiquetados. Ve a la sección
Etiquetado automático para ver los documentos etiquetados automáticamente.Selecciona el primer documento para ingresar a la consola de etiquetado.
Verifica que la etiqueta sea correcta. Realiza los ajustes necesarios.
Cuando termines, selecciona
Marcar como etiquetado .Repite la verificación de etiquetas para cada documento etiquetado automáticamente y, luego, vuelve a la página Administrar conjunto de datos para asignar los datos al entrenamiento.
En el menú de navegación de la consola de Google Cloud , selecciona Document AI y, después, Mis procesadores.
Selecciona
Más acciones en la misma fila del procesador que quieres borrar.Selecciona Borrar procesador, escribe el nombre del procesador y, luego, vuelve a seleccionar Borrar para confirmar.
- Para obtener más detalles, consulta Guías.
- Revisa la lista de procesadores.
- Separa documentos en fragmentos legibles con el analizador de diseño.
- Usa el Enterprise Document OCR para detectar y extraer texto.
Crea un procesador
Completa los siguientes pasos.
Configura el conjunto de datos
Para entrenar este nuevo procesador, debes crear un conjunto de datos con datos de entrenamiento y de prueba para ayudar al procesador a identificar los documentos que deseas dividir y clasificar. Este conjunto de datos requiere una ubicación nueva. Puede ser un bucket de Cloud Storage vacío o una carpeta, o puedes permitir una ubicación administrada de forma interna.
Después de que aparezca la pestaña Detalles del procesador, podrás hacer lo siguiente:

Importar documentos a un conjunto de datos
A continuación, importarás tus documentos al conjunto de datos.
Cuando importas documentos, puedes asignarlos de forma opcional al conjunto de Entrenamiento o Prueba cuando se importan, o esperar para asignarlos más tarde.
Si deseas obtener más información para preparar tus datos para importar, consulta la Guía de preparación de datos.
Define el esquema del procesador
Puedes crear el esquema del procesador antes o después de importar documentos a tu conjunto de datos. El esquema proporciona etiquetas que utilizas para anotar documentos.
Etiqueta un documento
El proceso de seleccionar texto en un documento y aplicar etiquetas se conoce como anotación.
Asigna el documento anotado en el conjunto de entrenamiento
Ahora que etiquetaste este documento de ejemplo, puedes asignarlo al conjunto de entrenamiento.
En el panel Documentos, puedes ver que se asignó un documento al conjunto de entrenamiento.
Importa datos etiquetados previamente a los conjuntos de entrenamiento y prueba
En esta guía, se proporcionan datos etiquetados previamente. Si trabajas en tu propio proyecto, deberás determinar cómo etiquetar tus datos. Consulta Opciones de etiquetado.
Los procesadores personalizados de Document AI requieren un mínimo de un documento en los conjuntos de entrenamiento y de prueba para cada tipo de documento que se etiquetará. Para obtener el mejor rendimiento, te recomendamos que tengas, al menos, 10 documentos por etiqueta. Para 5 etiquetas, necesitarías 50 documentos para entrenar y 50 para probar. Por lo general, una mayor cantidad de datos de entrenamiento produce una mayor exactitud.
Cuando finalice la importación, encontrarás los documentos en la pestaña Administrar conjunto de datos.
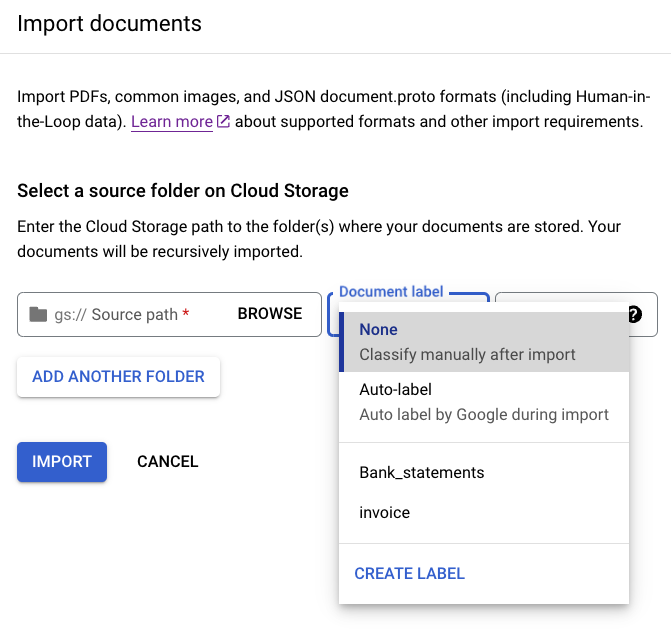
Etiqueta por lotes los documentos durante la importación
Opcionalmente, después de configurar el esquema, puedes etiquetar todos los documentos que se encuentran en un directorio en particular en la importación para ahorrar tiempo con el etiquetado.
Entrena el procesador
Ahora que importaste los datos de entrenamiento y prueba, puedes entrenar el procesador. Dado que el entrenamiento puede tardar varias horas, asegúrate de haber configurado el procesador con los datos y las etiquetas correspondientes antes de comenzar el entrenamiento.
Puedes entrenar modelos personalizados y ajustados con tus datos etiquetados. Los modelos ajustados usan IA generativa. Los modelos personalizados entrenan un modelo de lenguaje grande único con tus datos etiquetados. Necesitas un mínimo de dos etiquetas en el esquema, con diez documentos de entrenamiento y diez documentos de prueba recomendados (mínimo de 1).
Implementa la versión del procesador
Evalúa y prueba el procesador
Etiqueta automáticamente los documentos importados recientemente
Después de implementar una versión de procesador entrenado, puedes usar el etiquetado automático para ahorrar tiempo en el etiquetado cuando importas documentos nuevos.
Usar el procesador
Puedes administrar tus versiones de procesador con entrenamiento personalizado como cualquier otra versión de procesador. Para obtener más información, consulta Administra versiones de procesadores.
También puedes enviar una solicitud de procesamiento a tu procesador personalizado, y la respuesta puede manejarse de la misma manera que otros procesadores de clasificadores.
Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta página.