カスタム ドキュメント分類器を作成、使用、管理する
カスタム分類を使用してドキュメントを分類します。独自のドキュメントとカスタムクラスを使用してゼロから構築します。生成 AI の側面により、少数ショット学習とファインチューニングが可能になります。このため、少ないサンプルでも反復的な自動ラベル付けで修正が行われ、精度が向上します。
カスタム分類は、次の 3 つの一般的なユースケースに対応しています。
- 事前トレーニング済みモデル: 事前トレーニング済みの生成 AI 基盤モデルを使用して、指定したラベルでドキュメントをすばやく分類します。
- ファインチューニング: 独自のデータとラベルを使用して生成 AI 基盤モデルをトレーニングすることで、精度を向上させます。
- カスタムモデルのトレーニング: 独自のデータとラベルを使用して、非生成 AI カスタム エクストラクタをトレーニングします。
カスタム分類モデルのバージョン
信頼性スコアは、プレビュー版のカスタム分類モデルでサポートされています。最適なパフォーマンスを得るには、ファインチューニングされたモデルで信頼性スコアを使用してください。
| モデル バージョン | 説明 | リリース チャンネル | ML 処理(米国 / EU) | ファインチューニング(米国 / EU) | リリース日 |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-05-16 |
Gemini 2.0 Flash LLM を活用するリリース候補。高度な OCR 機能も含まれています。 | リリース候補 | ○ | 米国、EU(プレビュー) | 2025 年 5 月 16 日 |
pretrained-classifier-v1.5-2025-08-05 |
Gemini 2.5 Flash LLM を活用するリリース候補。高度な OCR 機能も含まれています。 | リリース候補 | ○ | 米国、EU(プレビュー) | 2025 年 8 月 5 日 |
Google Cloud コンソールでカスタム分類を作成する
ドキュメントに特化し、データを使用してトレーニングと評価を行うカスタム分類を作成できます。このプロセッサは、一連のユーザー定義のクラスからドキュメントのクラスを識別します。このトレーニング済みプロセッサを追加のドキュメントに使用できます。通常は、異なるタイプのドキュメントに対してカスタム分類を使用し、次に ID を使用して抽出プロセッサにそのドキュメントを渡してエンティティを抽出します。
プロセッサを作成して使用する一般的なプロセスについては、方法のセクションをご覧ください。
ワークフローに合わせて独自の構成の組み合わせを選択できます。
このタスクを Google Cloud コンソールで直接行う際の順を追ったガイダンスについては、「ガイドを表示」をクリックしてください。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. ワークベンチに移動します。
カスタム ドキュメント分類器では、[
プロセッサを作成 ] を選択します。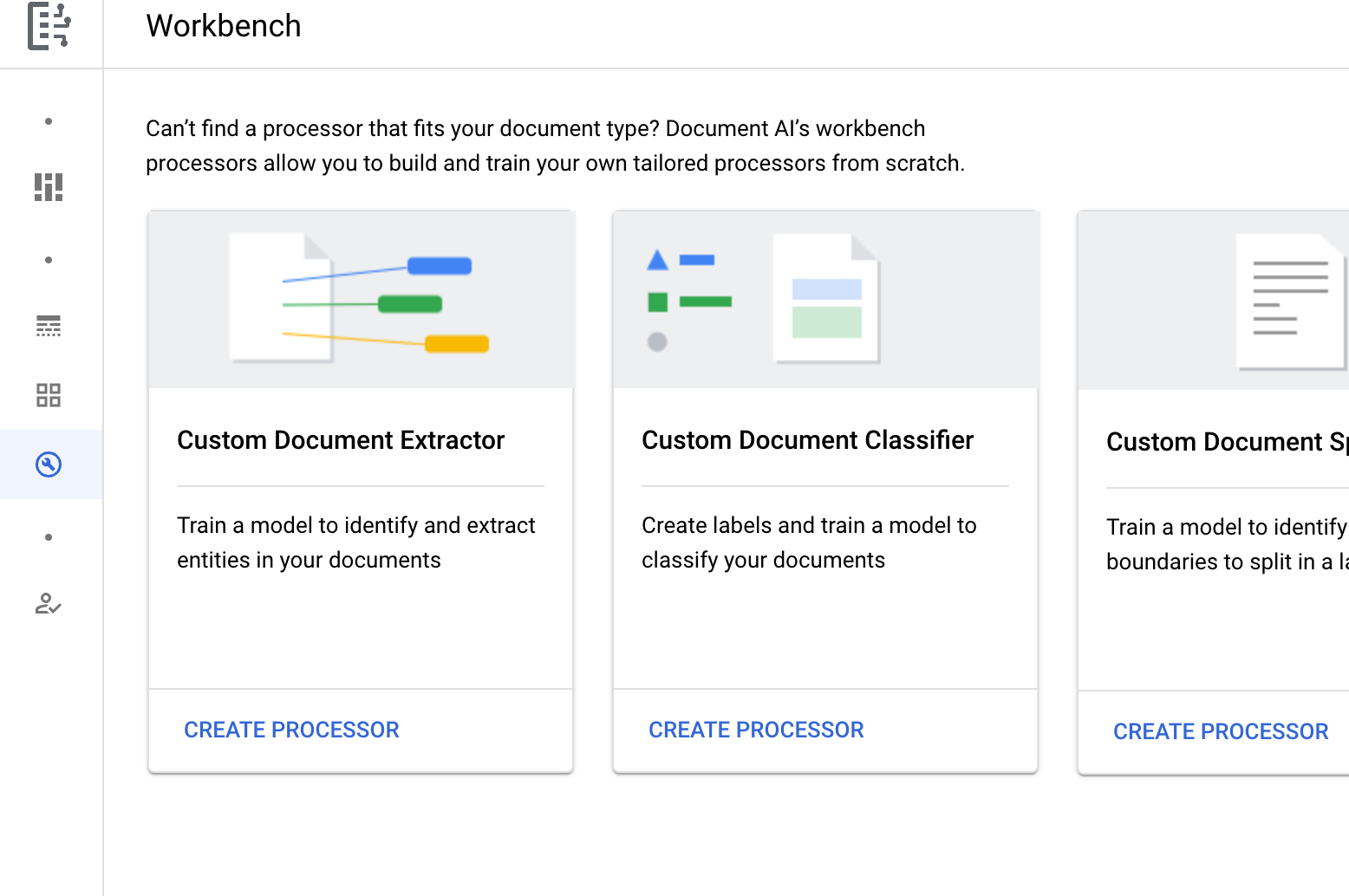
[プロセッサを作成] メニューで、プロセッサの名前を入力します(例:
my-custom-document-classifier)。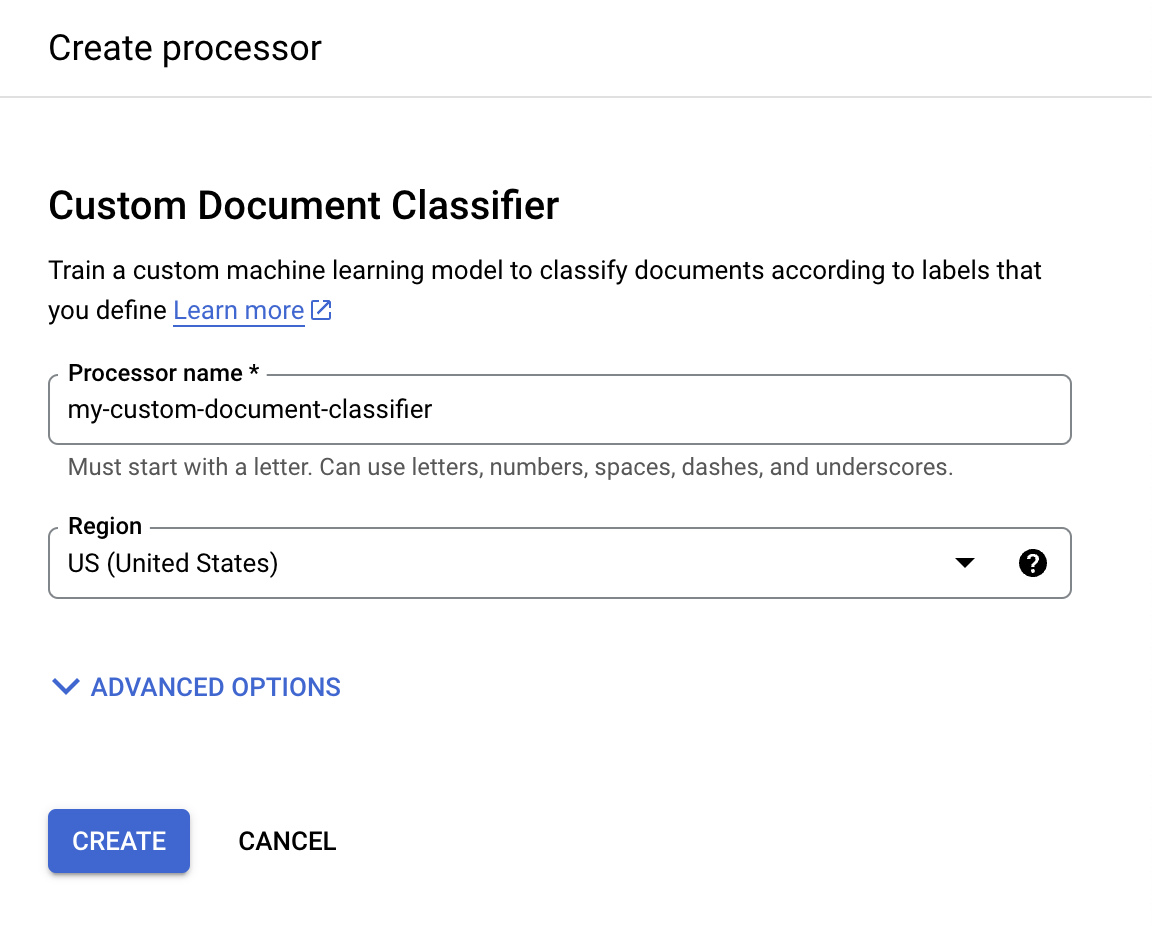
最も近いリージョンを選択します。
[作成] を選択します。[プロセッサの詳細] タブが表示されます。
- Cloud Storage を使用する場合は、[Google が管理するストレージ] を選択します。
- 顧客管理の暗号鍵(CMEK)を使用するために独自のストレージを使用する場合は、[独自のストレージ ロケーションを指定] を選択し、データセットを作成するの手順を行います。
[ビルド] タブで、[
ドキュメントのインポート ] を選択します。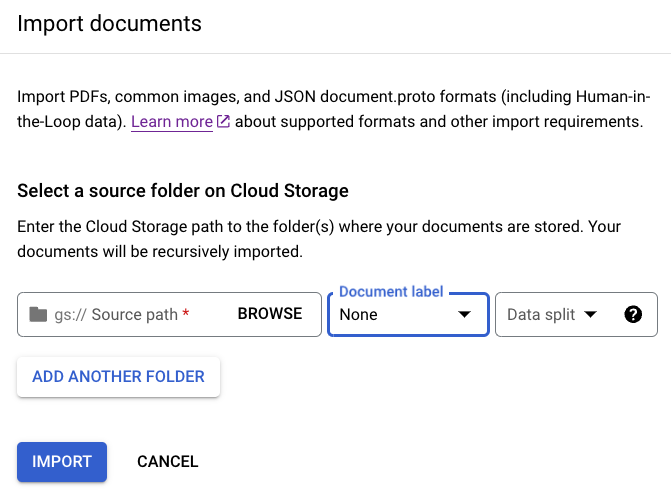
ストレージ バケットを使用する場合は、バケットのソースパスを入力する必要があります。このトレーニングの例では、このバケット名を [
転送元のパス ] に入力します。これは 1 つのドキュメントに直接リンクしています。cloud-samples-data/documentai/Custom/Patents/PDF/computer_vision_20.pdf[データ分割] で、[未割り当て] を選択します。このフォルダ内のドキュメントには、テストセットやトレーニング セットに割り当てられません。[自動ラベル付けを使用したインポート] をオフのままにします。
[インポート] を選択します。 Document AI により、ドキュメントがバケットからデータセットに読み込まれます。インポート バケットの変更や、インポート完了後のバケットからの読み取りは行われません。
省略可: インポートしたドキュメントを削除するには、[ビルド] タブで [データセットを管理] に移動し、ドキュメントを選択して [削除] をクリックします。
[ビルド] タブで、[データセットを管理] > [スキーマを編集] を選択します。[スキーマの編集] ページが開きます。
[
ラベルを作成 ] を選択します。ラベルの名前を入力します。
[作成] を選択します。スキーマの作成と編集の詳細な手順については、プロセッサ スキーマを定義するをご覧ください。
プロセッサ スキーマ用に次のラベルをそれぞれ作成します。
computer_visioncryptomed_techother
ラベルが完成したら、[
保存 ] を選択します。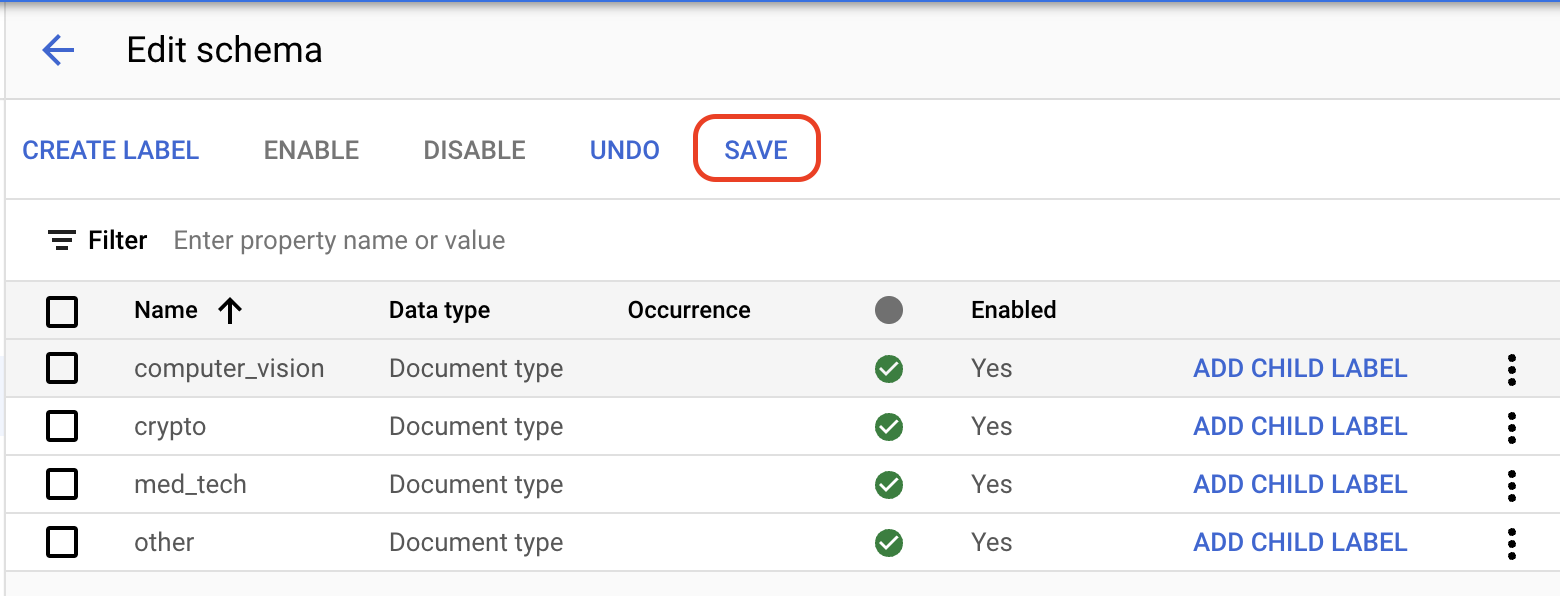
[ビルド] タブに戻り、
ドキュメント を選択して [データセットの管理] コンソールを開きます。オプション の中から、ドキュメントに適したラベルを選択します。提供されたサンプル ドキュメントを使用している場合はcomputer_visionを選択します。ラベル付けすると、ドキュメントは次のようになります。
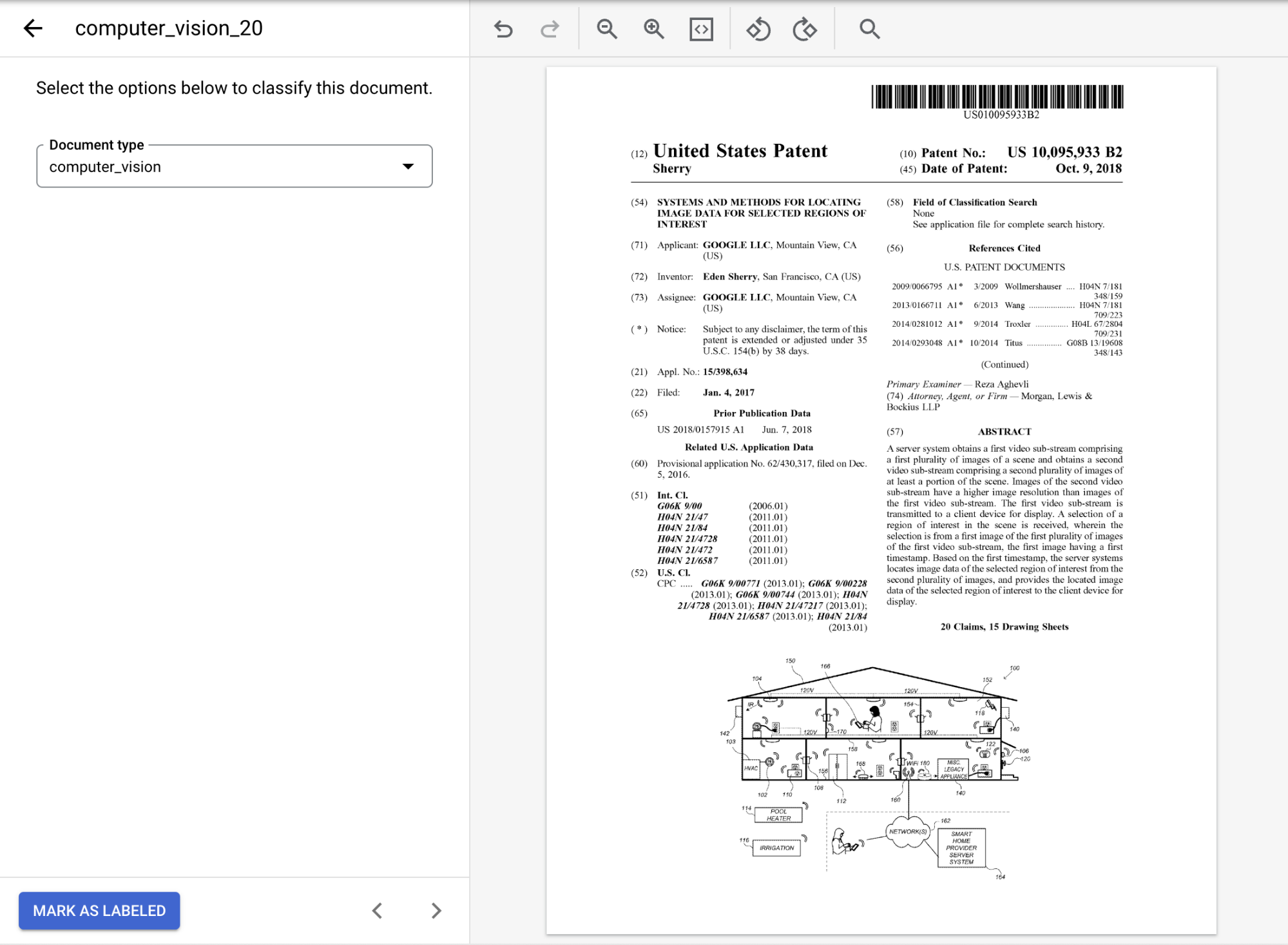
ドキュメントのアノテーションが完成したら、[
ラベル付きとしてマーク ] を選択します。[データセットの管理] タブの [ドキュメント] パネルに、1 つのドキュメントにラベルが付けられていることが示されます。
[データセットの管理] タブで、[
すべて選択 ] チェックボックスをオンにします。[
セットに割り当て ] リストから [トレーニング] を選択します。[
ドキュメントをインポート ] を選択します。[
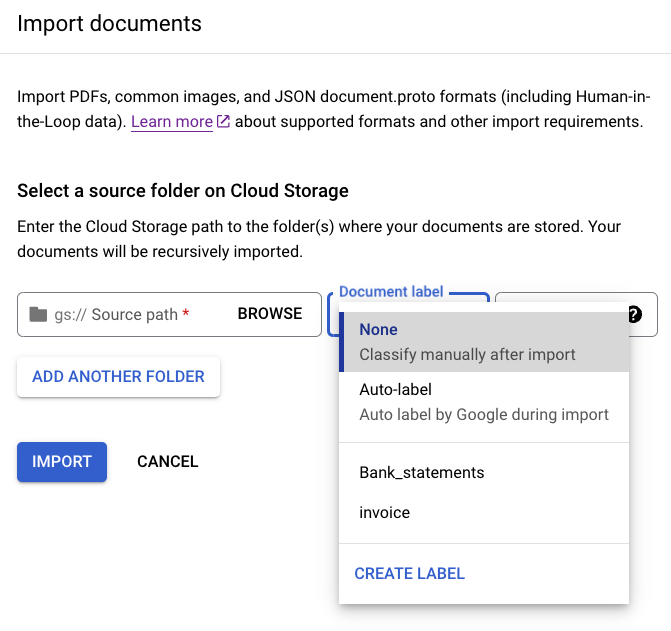
ソースパス ] に次のパスを入力します。このバケットには、事前にラベル付けされたドキュメントが Document JSON 形式で含まれています。cloud-samples-data/documentai/Custom/Patents/JSON/Classification-InventionType[データ分割] リストから [自動分割] を選択します。こうすることで、トレーニング セットが 80%、テストセットが 20% になるようにドキュメントが自動的に分割されます。[ラベルの適用] セクションは無視します。
[インポート] を選択します。 インポートの完了には数分かかることがあります。
[
ドキュメントをインポート ] を選択します。[
ソースパス ] に次のパスを入力します。このバケットには、ラベル付けされていないドキュメントが PDF 形式で含まれています。cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabel[データ分割] リストから [自動分割] を選択します。これにより、トレーニング セットが 80%、テストセットが 20% になるようにドキュメントが自動的に分割されます。
[ラベルを適用] で、[ラベルを選択] を選択します。
これらのサンプル ドキュメントには
otherを選択します。[インポート] を選択し、処理が完了するまで待ちます。このページを離れて、後で戻ってくることもできます。 完了すると、[データセットの管理] タブにラベルが適用されたドキュメントが表示されます。
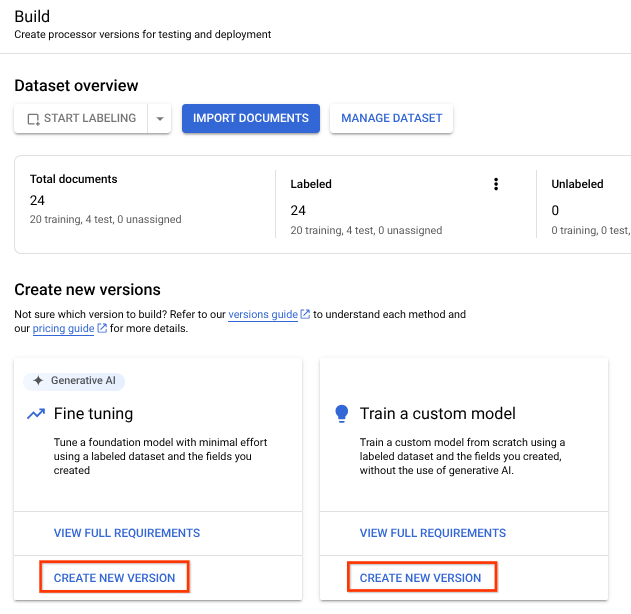
- [
新しいバージョンのトレーニング ] を選択します。 [
バージョン名 ] フィールドに、このプロセッサ バージョンの名前(my-cdc-version-1など)を入力します。省略可: [ラベルの統計データを表示] を選択して、カバレッジの判断に役立つ、ドキュメント ラベルに関する情報を確認します。[閉じる] を選択してトレーニングの設定に戻ります。
[
トレーニングを開始 ] を選択します。ステータスはサイドパネルで確認できます。トレーニングが完了したら、[
バージョンの管理 ] タブに移動します。トレーニングしたバージョンの詳細を表示できます。デプロイするバージョンの横にある
を選択し、[バージョンをデプロイ] を選択します。 ダイアログ ウィンドウから [
デプロイ ] を選択します。デプロイが完了するまで数分かかります。
デプロイが完了したら、[
評価とテスト ] タブに移動します。このページでは、ドキュメント全体の F1 スコア、ドキュメント全体の適合率と再現率、個々のラベルなどの評価指標を表示できます。 評価と統計情報について詳しくは、プロセッサを評価するをご覧ください。
プロセッサのバージョンを評価するために使用できるように、これまでトレーニングやテストに関与していないドキュメントをダウンロードします。独自のデータを使用している場合は、この目的のために用意されたドキュメントを使用します。
[
テスト ドキュメントをアップロード ] を選択し、ダウンロードしたドキュメントを選択します。[カスタム ドキュメント分類器の分析] ページが開きます。出力に、ドキュメントがどの程度適切に分類されたかが表示されます。
別のテストセットまたは別のプロセッサ バージョンで評価を再実行することもできます。
[データセットの管理] ページで、[
ドキュメントをインポート ] をクリックします。次の Cloud Storage パスをコピーして貼り付けます。このディレクトリには、ラベルのない特許の PDF が 5 つ含まれています。[データ分割] プルダウン リストから [トレーニング] を選択します。
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-AutoLabel[ラベルを適用] セクションで、[自動ラベル付け] を選択します。
ドキュメントのラベル付けを行う既存のプロセッサ バージョンを選択します。
- 例:
2af620b2fd4d1fcf
- 例:
[インポート] を選択し、処理が完了するまで待ちます。このページを離れて、後で戻ってくることもできます。 完了すると、[データセットの管理] ページの [自動的にラベル付け] セクションにドキュメントが表示されます。
ラベル付きとマークしないと、自動的にラベル付けされたドキュメントをトレーニングやテストで使用できません。[
自動的にラベル付け ] セクションに移動して、自動的にラベル付けされたドキュメントを表示します。最初のドキュメントを選択して、ラベル付けのコンソールを開きます。
ラベルを検証して正しいことを確認します。正しくない場合は調整します。
完了したら、[
ラベル付きとしてマーク ] を選択します。自動的にラベル付けされたドキュメントごとにラベルの確認を繰り返します。その後、[データセットの管理] ページに戻り、トレーニング用のデータを割り当てます。
Google Cloud コンソールのナビゲーション メニューで、[Document AI]、[マイプロセッサ] の順に選択します。
削除するプロセッサと同じ行にある [
その他の操作 ] を選択します。[プロセッサを削除] を選択し、プロセッサ名を入力して、もう一度 [削除] を選択して確定します。
- 詳しくは、ガイドをご覧ください。
- プロセッサ リストを確認します。
- レイアウト パーサーを使用してドキュメントを読み取り可能なチャンクに分割します。
- Enterprise Document OCR を使用して、テキストを検出して抽出します。
プロセッサの作成
次の手順を行います。
データセットの構成
この新しいプロセッサをトレーニングするには、分割して分類するドキュメントをプロセッサが識別できるように、トレーニング データとテストデータを含むデータセットを作成する必要があります。このデータセットには新しいロケーションが必要です。これは空の Cloud Storage バケットまたはフォルダにすることも、社内で管理されるロケーションを許可することもできます。
[プロセッサの詳細] タブが表示されたら、次のことができます。

ドキュメントをデータセットにインポートする
次に、ドキュメントをデータセットにインポートします。
ドキュメントをインポートする際、必要に応じて、インポート時に設定されたトレーニングまたはテストにドキュメントを割り当てるか、後からの割り当てを待つことができます。
インポートするデータの準備について詳しくは、データ準備ガイドをご覧ください。
プロセッサ スキーマを定義する
プロセッサ スキーマは、ドキュメントをデータセットにインポートする前と後のどちらでも作成できます。スキーマには、ドキュメントにアノテーションを付けるために使用するラベルが用意されています。
ドキュメントにラベルを付ける
ドキュメント内のテキストを選択してラベルを適用するプロセスを「アノテーション」と呼びます。
アノテーション付きドキュメントをトレーニング セットに割り当てる
このサンプル ドキュメントにラベルを付けるのが完了したので、これをトレーニング セットに割り当てることができます。
[ドキュメント] パネルに、1 つのドキュメントがトレーニング セットに割り当てられていることが示されます。
事前にラベル付けされたデータをトレーニング セットとテストセットにインポートする
このガイドでは、あらかじめラベル付けされたデータが用意されています。 独自のプロジェクトで作業する場合は、データのラベル付けの方法を決定する必要があります。ラベル付けの方法をご確認ください。
Document AI カスタム プロセッサでは、ラベル付けするドキュメント タイプごとに、トレーニング セットとテストセットの両方で少なくとも 1 つのドキュメントが必要です。最適なパフォーマンスを得るには、ラベルにつき 10 個以上のドキュメントを含めることをおすすめします。5 つのラベルの場合、トレーニング用に 50 個、テスト用に 50 個のドキュメントが必要です。一般に、トレーニング データが多いほど精度が高くなります。
インポートが終了すると、[データセットの管理] タブにドキュメントが表示されます。
インポート時にドキュメントに一括ラベルを付ける
スキーマを構成したら、インポート時に特定のディレクトリにあるすべてのドキュメントにラベルを付けることで、ラベル付けにかかる時間を節約することもできます。
プロセッサをトレーニングする
トレーニング データとテストデータがインポートされたので、プロセッサをトレーニングできるようになりました。 トレーニングには数時間かかる場合があるため、トレーニングを開始する前に、適切なデータとラベルがプロセッサに設定されていることを確認してください。
ラベル付きデータを使用して、ファイン チューニングされたモデルとカスタムモデルをトレーニングできます。ファインチューニングされたモデルは生成 AI を使用します。カスタムモデルは、ラベル付きデータを使用して独自の大規模言語モデルをトレーニングします。スキーマには少なくとも 2 つのラベルが必要です。ラベルでは、トレーニング ドキュメントとテスト ドキュメントをそれぞれ 10 個ずつ使用することをおすすめします(最小 1 個)。
プロセッサ バージョンをデプロイする
プロセッサの評価とテストを行う
新しくインポートしたドキュメントに自動的にラベルを付ける
トレーニング済みのプロセッサ バージョンをデプロイした後、自動ラベル付けを使用すると、新しいドキュメントをインポートしたときのラベル付けの時間を短縮できます。
プロセッサを使用する
カスタム トレーニング済みのプロセッサ バージョンは、他のプロセッサ バージョンと同様に管理できます。詳細については、プロセッサ バージョンの管理をご覧ください。
カスタム プロセッサに処理リクエストを送信することもできます。また、レスポンスは他の分類器プロセッサと同じ方法で処理できます。
クリーンアップ
このページで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、次の手順を実施します。