プロセッサ バージョンのトレーニング、アップトレーニング、評価を行うには、ドキュメントのラベル付きデータセットが必要です。
このページでは、データセットの作成方法、ドキュメントのインポート方法、スキーマの定義方法について説明します。インポートしたドキュメントにラベルを付けるには、ドキュメントにラベルを付けるをご覧ください。
このページは、トレーニング、アップトレーニング、評価をサポートするプロセッサをすでに作成していることを前提としています。プロセッサがサポートされている場合は、 Google Cloud コンソールに [トレーニング] タブが表示されます。
データセットのストレージ オプション
データセットを保存するには、次の 2 つのオプションから選択できます。
- Google が管理
- カスタム ロケーションの Cloud Storage
特別な要件(CMEK 対応フォルダのセットにドキュメントを保持するなど)がない限り、よりシンプルな Google 管理のストレージ オプションをおすすめします。データセットのストレージ オプションを作成すると、プロセッサで変更できなくなります。
カスタム Cloud Storage ロケーションのフォルダまたはサブフォルダは、空の状態で開始し、厳密に読み取り専用として扱う必要があります。コンテンツを手動で変更すると、データセットが使用できなくなり、データが失われる可能性があります。Google 管理のストレージ オプションには、このリスクはありません。
ストレージの場所をプロビジョニングする手順は次のとおりです。
Google が管理するストレージ(推奨)
新しいプロセッサの作成時に詳細オプションを表示します。
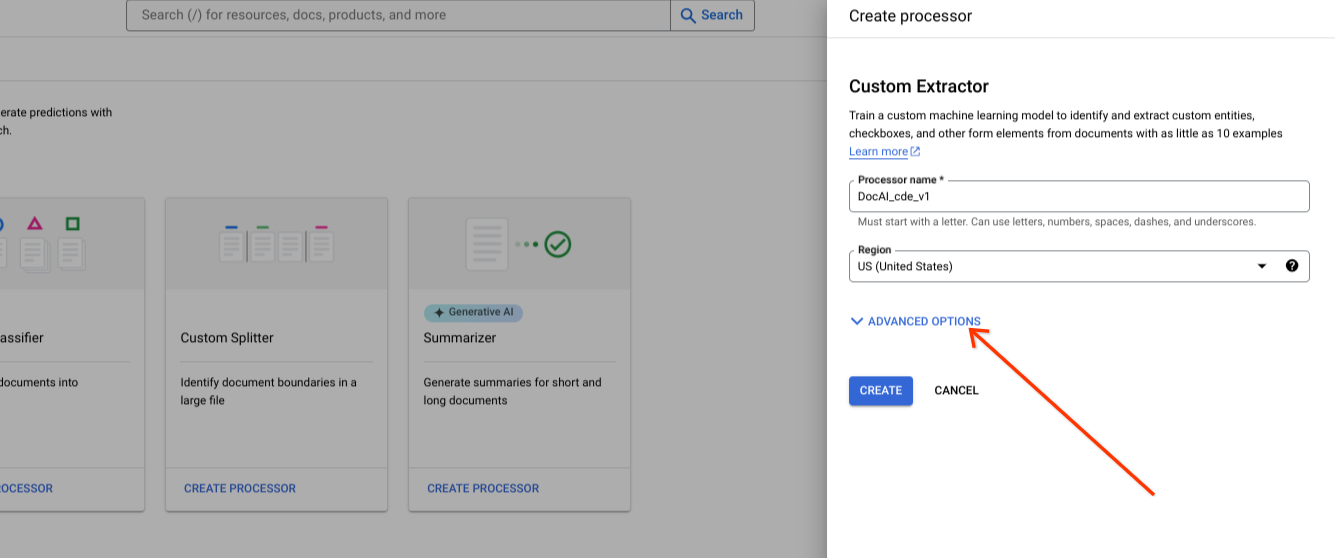
デフォルトのラジオ グループ オプションは、Google 管理のストレージのままにします。
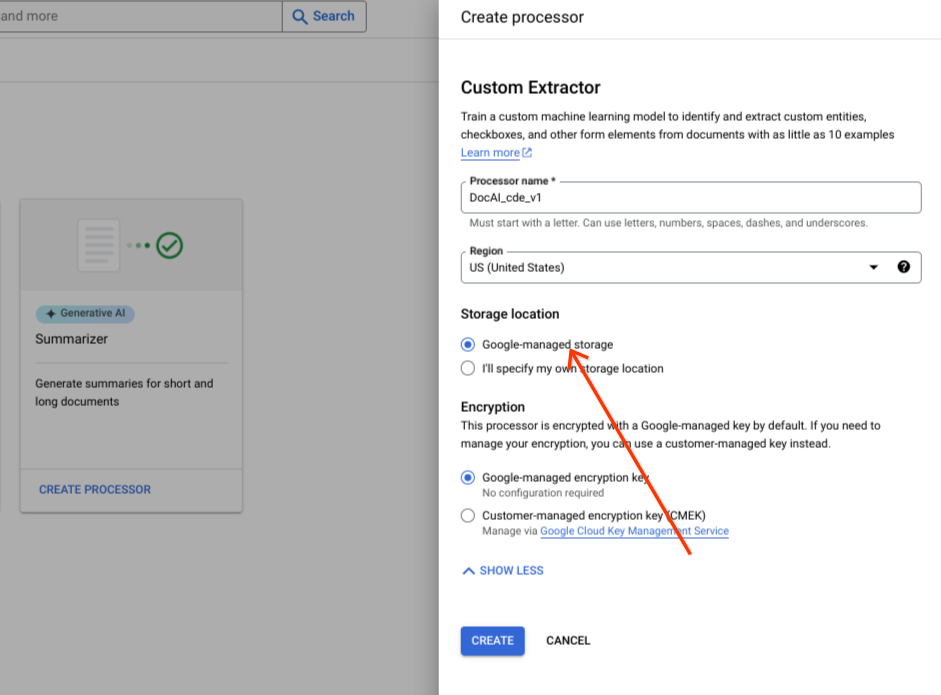
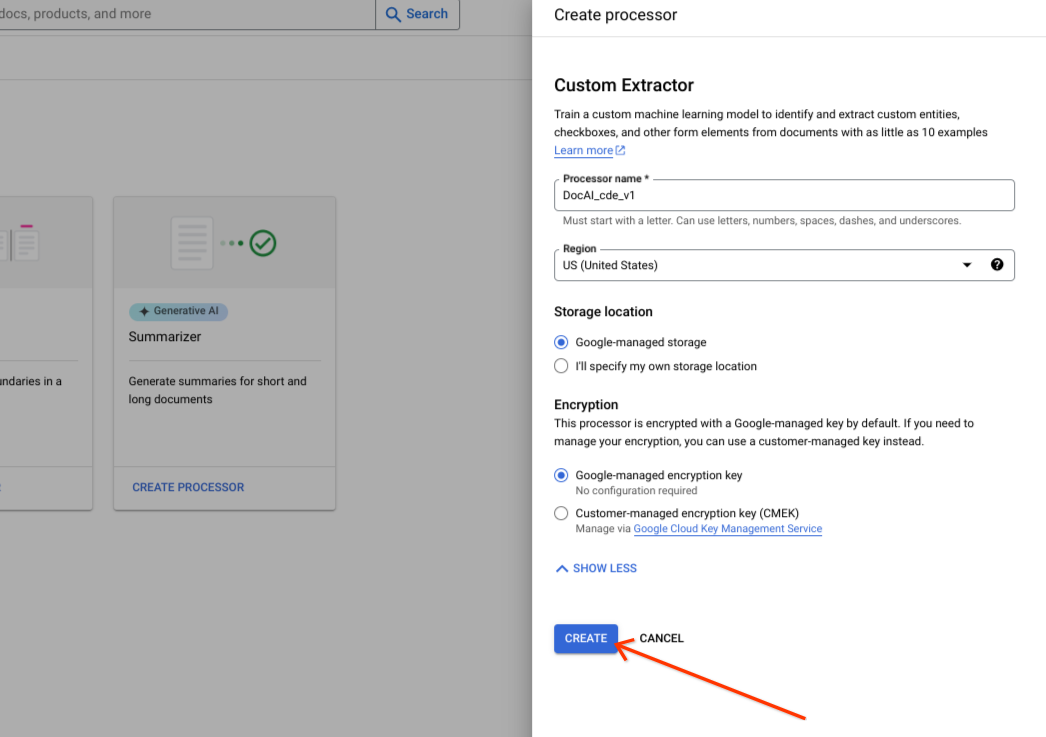
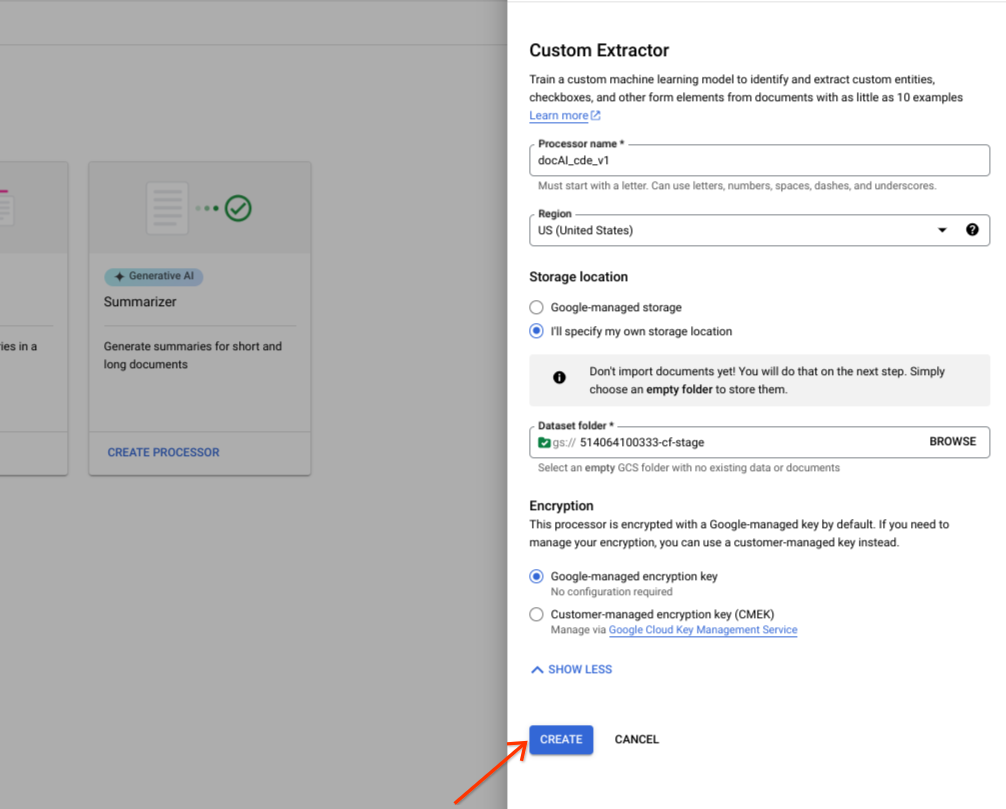
[作成] を選択します。
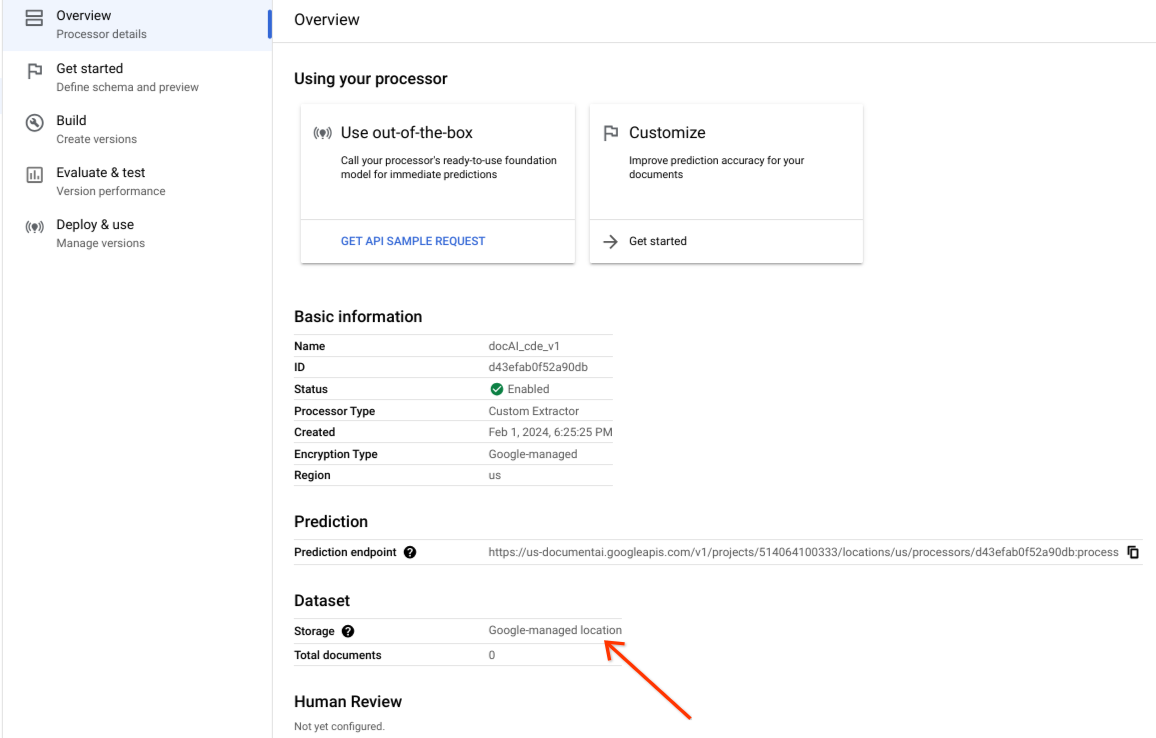
データセットが正常に作成され、データセットのロケーションが Google マネージド ロケーションであることを確認します。
カスタム ストレージ オプション
詳細オプションをオンまたはオフに設定します。
[独自のストレージ ロケーションを指定] を選択します。
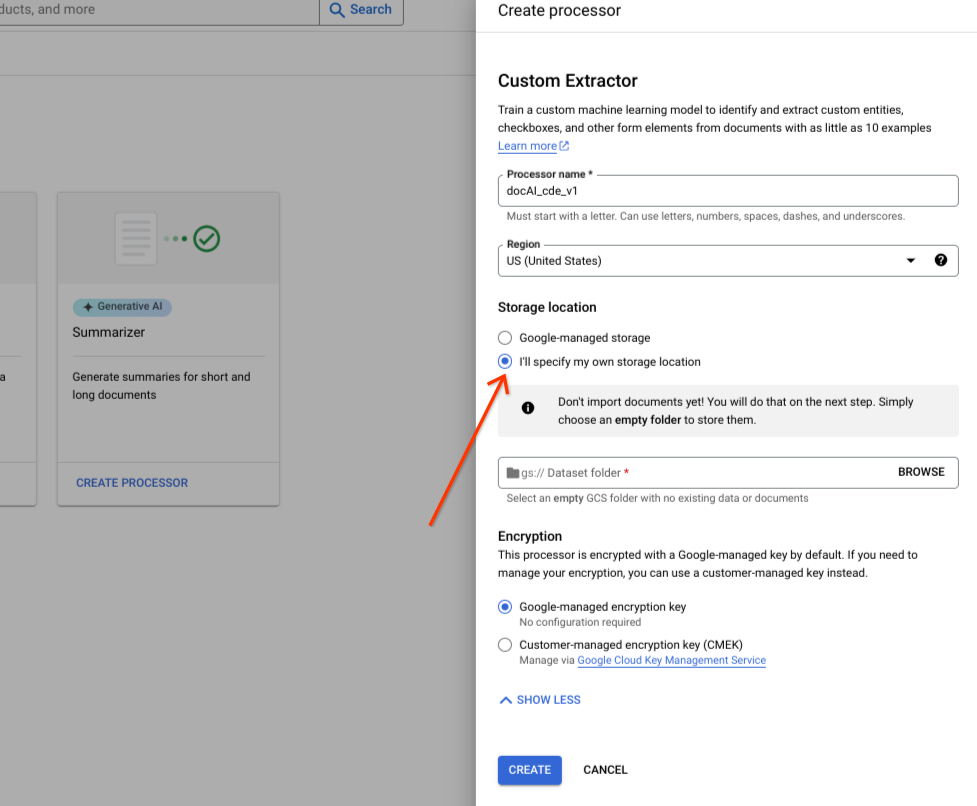
入力コンポーネントから Cloud Storage フォルダを選択します。
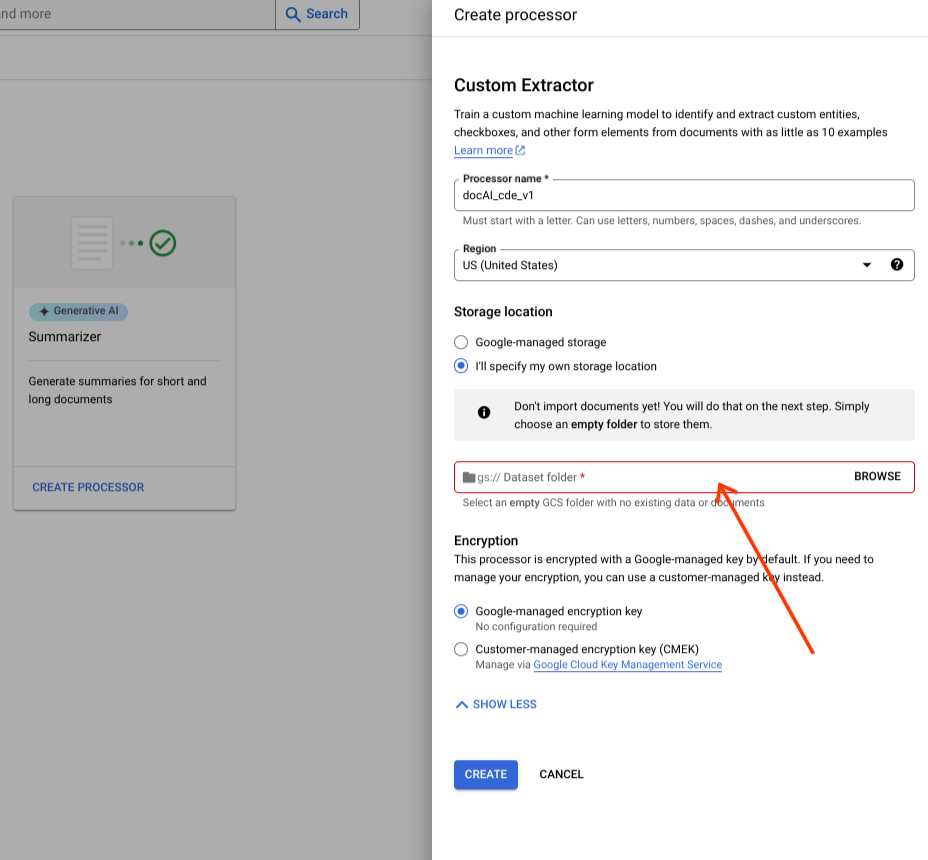
[作成] を選択します。
Dataset API オペレーション
このサンプルでは、processors.updateDataset メソッドを使用してデータセットを作成する方法を示します。データセット リソースはプロセッサ内のシングルトン リソースです。つまり、リソース作成 RPC はありません。代わりに、updateDataset RPC を使用して設定できます。Document AI には、ユーザーが指定した Cloud Storage バケットにデータセット ドキュメントを保存するか、Google が自動的に管理するかのオプションがあります。
リクエストのデータを使用する前に、次のように置き換えます。
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
提供されたバケット
次の手順に沿って、指定した Cloud Storage バケットを使用してデータセット リクエストを作成します。
HTTP メソッド
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetリクエストの JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"gcs_managed_config" {
"gcs_prefix" {
"gcs_uri_prefix": "GCS_URI"
}
}
"spanner_indexing_config" {}
}Google 管理
Google 管理のデータセットを作成する場合は、次の情報を更新します。
HTTP メソッド
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetリクエストの JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"unmanaged_dataset_config": {}
"spanner_indexing_config": {}
}リクエストを送信するには、Curl を使用します。
リクエスト本文を request.json という名前のファイルに保存します。次のコマンドを実行します。
CURL
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}ドキュメントのインポート
新しく作成したデータセットは空です。ドキュメントを追加するには、[ドキュメントをインポート] を選択し、データセットに追加するドキュメントを含む 1 つ以上の Cloud Storage フォルダを選択します。
Cloud Storage が別の Google Cloud プロジェクトにある場合は、Document AI がその場所からファイルを読み取れるようにアクセス権を付与してください。具体的には、Document AI のコア サービス エージェント service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com に ストレージ オブジェクト閲覧者ロールを付与する必要があります。詳細については、サービス エージェントをご覧ください。
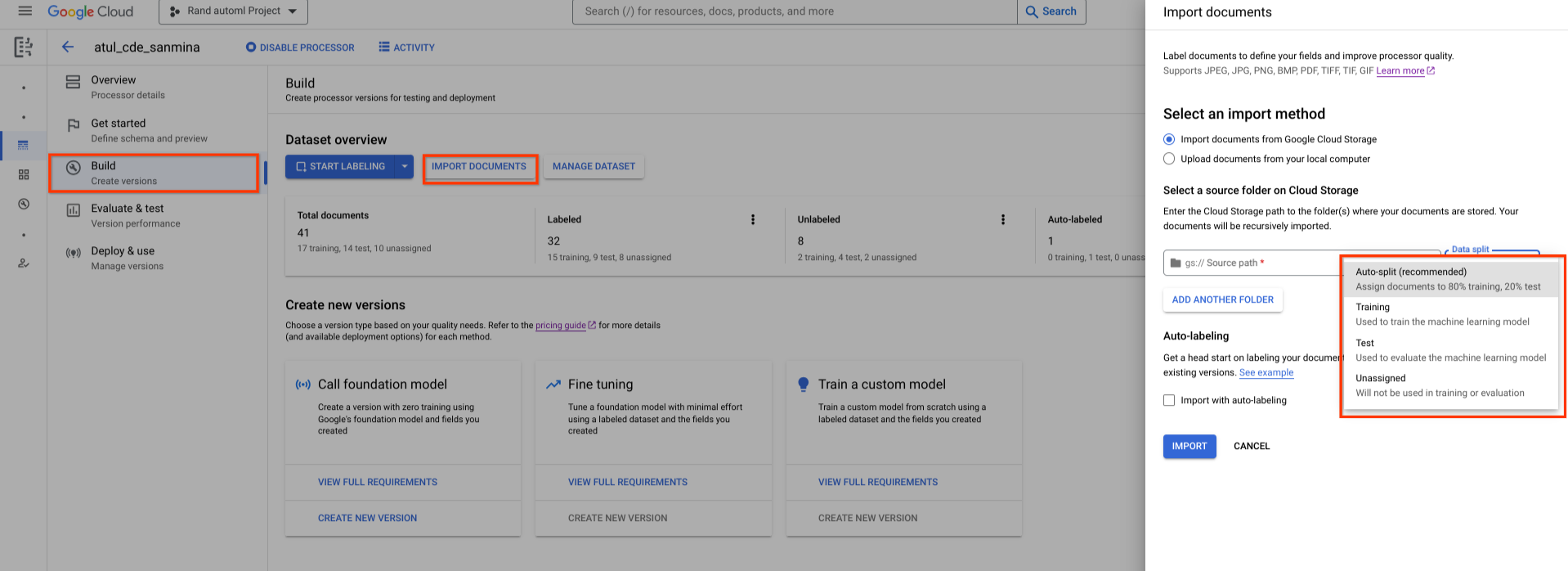
次に、次のいずれかの割り当てオプションを選択します。
- トレーニング: トレーニング セットに割り当てます。
- テスト: テストセットに割り当てます。
- 自動分割: トレーニング セットとテストセットのドキュメントをランダムにシャッフルします。
- 未割り当て: トレーニングや評価では使用されません。後で手動で割り当てることができます。
割り当ては後でいつでも変更できます。
[インポート] を選択すると、Document AI は、サポートされているすべてのファイル形式と JSON Document ファイルをデータセットにインポートします。JSON Document ファイルの場合、Document AI はドキュメントをインポートし、その entities をラベル インスタンスに変換します。
Document AI は、インポート完了後にインポート フォルダを変更したり、フォルダから読み取ったりすることはありません。
ページ上部の [アクティビティ] を選択して [アクティビティ] パネルを開きます。このパネルには、インポートに成功したファイルと失敗したファイルが一覧表示されます。
既存のプロセッサ バージョンがある場合は、[ドキュメントをインポート] ダイアログで [自動ラベル付けを使用したインポート] チェックボックスをオンにします。ドキュメントは、インポート時に以前のプロセッサを使用して自動的にラベル付けされます。ラベル付きとマークしないと、自動ラベル付けされたドキュメントでトレーニングやアップトレーニングを行ったり、テストセットで使用したりすることはできません。自動的にラベル付けされたドキュメントをインポートしたら、自動的にラベル付けされたドキュメントを手動で確認して修正します。[保存] を選択して、修正を保存し、ドキュメントにラベル付けされたことをマークします。その後、必要に応じてドキュメントを割り当てることができます。自動ラベル付けをご覧ください。
ドキュメントのインポート RPC
このサンプルでは、dataset.importDocuments メソッドを使用してドキュメントをデータセットにインポートする方法を示します。
リクエストのデータを使用する前に、次のように置き換えます。
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
DATASET_TYPE: The dataset type to which you want to add documents. The value should be either `DATASET_SPLIT_TRAIN` or `DATASET_SPLIT_TEST`.
TRAINING_SPLIT_RATIO: The ratio of documents which you want to autoassign to the training set.
トレーニング データセットまたはテスト データセット
トレーニング データセットまたはテスト データセットにドキュメントを追加する場合は、次の操作を行います。
HTTP メソッド
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsリクエストの JSON:
{
"batch_documents_import_configs": {
"dataset_split": DATASET_TYPE
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": GCS_URI
}
}
}
}トレーニング データセットとテスト データセット
ドキュメントをトレーニング データセットとテスト データセットの間で自動的に分割する場合は、次の操作を行います。
HTTP メソッド
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsリクエストの JSON:
{
"batch_documents_import_configs": {
"auto_split_config": {
"training_split_ratio": TRAINING_SPLIT_RATIO
},
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": "gs://test_sbindal/pdfs-1-page/"
}
}
}
}リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments"次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}ドキュメントの削除 RPC
このサンプルでは、dataset.batchDeleteDocuments メソッドを使用してデータセットからドキュメントを削除する方法を示します。
リクエストのデータを使用する前に、次のように置き換えます。
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
DOCUMENT_ID: The document ID blob returned by <code>ImportDocuments</code> request
ドキュメントを削除する
HTTP メソッド
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocumentsリクエストの JSON:
{
"dataset_documents": {
"individual_document_ids": {
"document_ids": DOCUMENT_ID
}
}
}リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments"次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}ドキュメントをトレーニング セットまたはテストセットに割り当てる
[データ分割] で、ドキュメントを選択して、トレーニング セット、テストセット、未割り当てのいずれかに割り当てます。
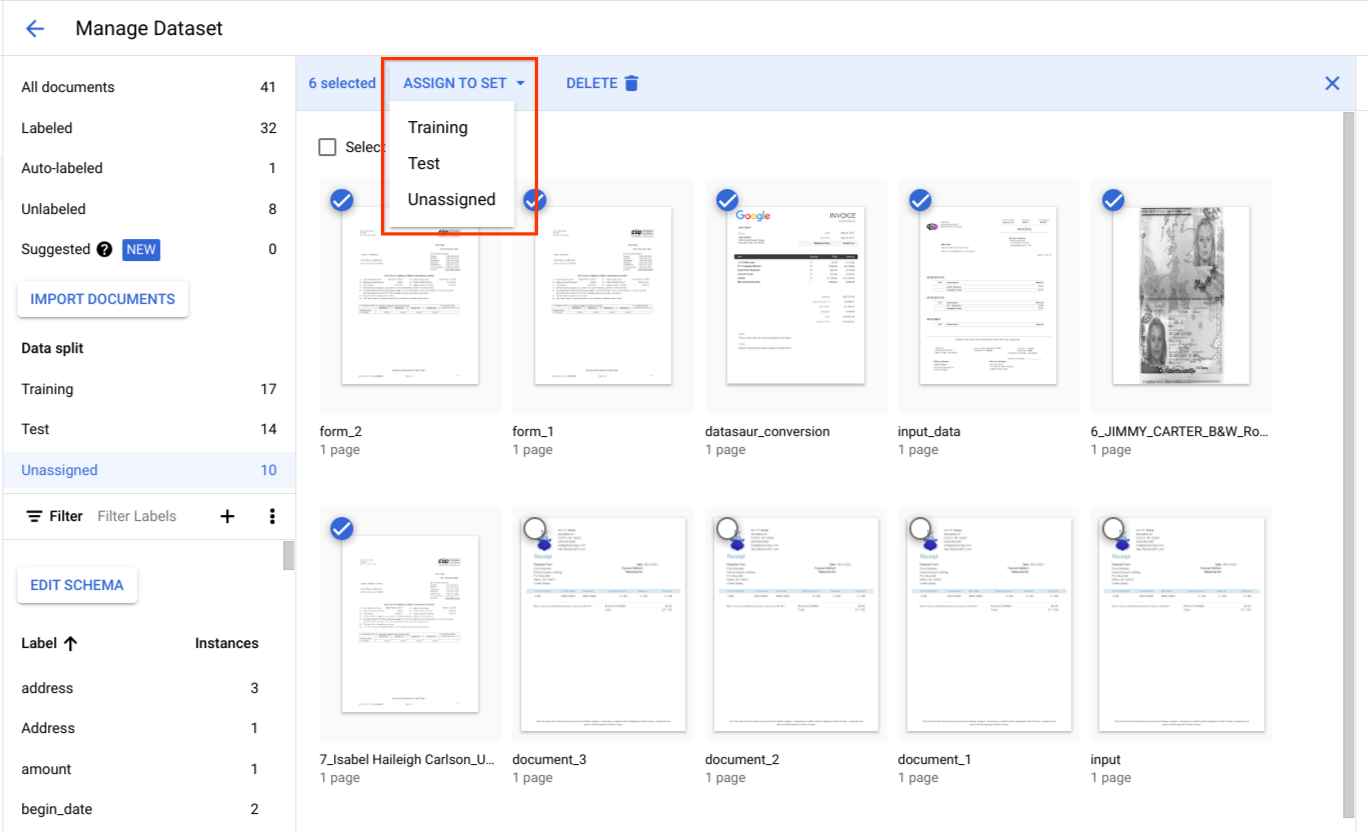
テストセットのベスト プラクティス
テストセットの品質によって、評価の品質が決まります。
テストセットはプロセッサ開発サイクルの開始時に作成し、ロックして、プロセッサの品質を長期にわたって追跡できるようにする必要があります。
テストセットには、ドキュメント タイプごとに少なくとも 100 個のドキュメントを用意することをおすすめします。テストセットが代表的であることを確認することが重要です。
テストセットは、頻度の点で本番環境のトラフィックを代表するものである必要があります。たとえば、W2 フォームを処理していて、70% が 2020 年、30% が 2019 年のフォームであると予想される場合、テストセットの約 70% は W2 2020 ドキュメントで構成されている必要があります。このようなテストセットの構成により、プロセッサのパフォーマンスを評価する際に、各ドキュメント サブタイプに適切な重要度が与えられます。また、国際的なフォームから名前を抽出する場合は、テストセットにすべての対象国のフォームが含まれていることを確認してください。
トレーニング セットのベスト プラクティス
テストセットにすでに含まれているドキュメントは、トレーニング セットに含めないでください。
テストセットとは異なり、最終的なトレーニング セットは、ドキュメントの多様性や頻度の点で、お客様の使用状況を厳密に反映している必要はありません。一部のラベルは、他のラベルよりもトレーニングが難しい場合があります。したがって、トレーニング セットをこれらのラベルに偏らせることで、パフォーマンスが向上する可能性があります。
最初は、どのラベルが難しいかを判断する良い方法はありません。テストセットで説明したのと同じアプローチを使用して、ランダムにサンプリングされた小さな初期トレーニング セットから始める必要があります。この初期トレーニング セットには、アノテーションを付ける予定のドキュメントの総数の約 10% を含める必要があります。その後、プロセッサの品質を繰り返し評価し(特定のエラー パターンを探す)、トレーニング データを追加できます。
プロセッサ スキーマを定義する
データセットを作成したら、ドキュメントをインポートする前または後にプロセッサ スキーマを定義できます。
プロセッサの schema は、ドキュメントから抽出する名前や住所などのラベルを定義します。
[スキーマを編集] を選択し、必要に応じてラベルを作成、編集、有効化、無効化します。
完了したら、必ず [保存] を選択してください。
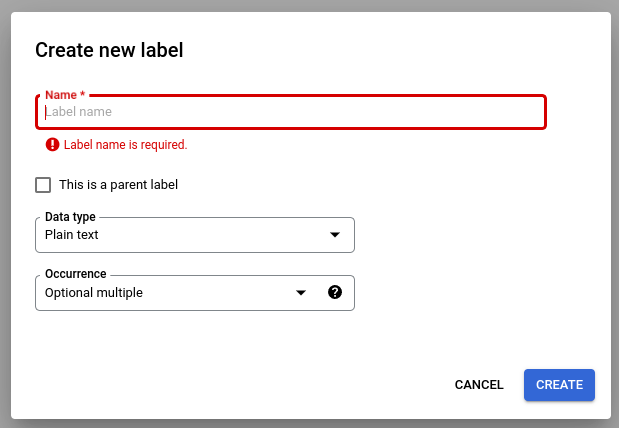
スキーマラベルの管理に関する注意事項:
スキーマラベルを作成した後は、スキーマラベルの名前を編集できません。
スキーマラベルは、トレーニング済みのプロセッサ バージョンがない場合にのみ編集または削除できます。編集できるのはデータ型とオカレンス型のみです。
ラベルを無効にしても、予測には影響しません。処理リクエストを送信すると、プロセッサ バージョンはトレーニング時にアクティブだったすべてのラベルを抽出します。
データスキーマを取得する
このサンプルでは、getDatasetSchema を使用して現在のスキーマを取得する方法を示します。DatasetSchema はシングルトン リソースであり、データセット リソースを作成すると自動的に作成されます。
リクエストのデータを使用する前に、次のように置き換えます。
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
データスキーマを取得する
HTTP メソッド
GET https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaCURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"次のような JSON レスポンスが返されます。
{
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema",
"documentSchema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": $LABEL_NAME,
"valueType": $VALUE_TYPE,
"occurrenceType": $OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}ドキュメント スキーマを更新する
このサンプルでは、dataset.updateDatasetSchema を使用して現在のスキーマを更新する方法を示します。次の例は、データセット スキーマを更新して 1 つのラベルを設定するコマンドを示しています。既存のラベルを削除または更新するのではなく、新しいラベルを追加する場合は、まず getDatasetSchema を呼び出し、そのレスポンスで適切な変更を行うことができます。
リクエストのデータを使用する前に、次のように置き換えます。
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
LABEL_NAME: The label name which you want to add
LABEL_DESCRIPTION: Describe what the label represents
DATA_TYPE: The type of the label. You can specify this as string, number, currency, money, datetime, address, boolean.
OCCURRENCE_TYPE: Describes the number of times this label is expected. Pick an enum value.
スキーマの更新
HTTP メソッド
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaリクエストの JSON:
{
"document_schema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": LABEL_NAME,
"description": LABEL_DESCRIPTION,
"valueType": DATA_TYPE,
"occurrenceType": OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}リクエスト本文を request.json という名前のファイルに保存して、次のコマンドを実行します。
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"ラベルの属性を選択する
データの種類
Plain text: 文字列値。Number: 整数または浮動小数点数。Money: 金額。ラベル付けの際は、通貨記号を含めないでください。- エンティティが抽出されると、
google.type.Moneyに正規化されます。
- エンティティが抽出されると、
Currency: 通貨記号。Datetime: 日付または時刻の値。- エンティティが抽出されると、
ISO 8601テキスト形式に正規化されます。
- エンティティが抽出されると、
Address- ロケーションの住所。- エンティティが抽出されると、EKG で正規化され、拡充されます。
Checkbox-trueまたはfalseのブール値。Signature-normalized_value.signature_valueのtrueまたはfalseのブール値。シグネチャが存在するかどうかを示します。deriveメソッドをサポートしています。mention_text-has_signedのDetectedまたは空の""ブール値。シグネチャが存在するかどうかを示します。deriveメソッドをサポートしています。normalized_value.text-has_signedのDetectedまたは空の""ブール値。シグネチャが存在するかどうかを示します。deriveメソッドをサポートしています。normalized_value.boolean_valueに値が入力されていません。
メソッド
- エンティティが
extractedの場合、textAnchor、type、mentionText、pageAnchorのフィールドに値が入力されます。 - エンティティが
derivedの場合、派生値がドキュメント テキストに存在しないことがあります。textAnchorフィールドとpageAnchor.pageRefs[].bounding_polyフィールドが入力されていません。
オカレンス
特定のタイプのドキュメントにエンティティが常に表示されることが想定される場合は、REQUIRED を選択します。そのような期待がない場合は、OPTIONAL を選択します。
同じ値が同じドキュメントに複数回出現する場合でも、エンティティに 1 つの値が想定される場合は、ONCE を選択します。エンティティに複数の値が設定される可能性がある場合は、MULTIPLE を選択します。
親ラベルと子ラベル
親子ラベル(表形式エンティティとも呼ばれます)は、テーブル内のデータにラベルを付けるために使用されます。次の表には 3 行 4 列があります。

このようなテーブルは、親子ラベルを使用して定義できます。この例では、親ラベル line-item はテーブルの行を定義します。
親ラベルを作成する
[スキーマを編集] ページで、[ラベルを作成] を選択します。
[親ラベルです] チェックボックスをオンにして、その他の情報を入力します。テーブル内のすべての行をキャプチャできるように、親ラベルには
optional_multipleまたはrequire_multipleのいずれかの出現が必要です。[保存] を選択します。
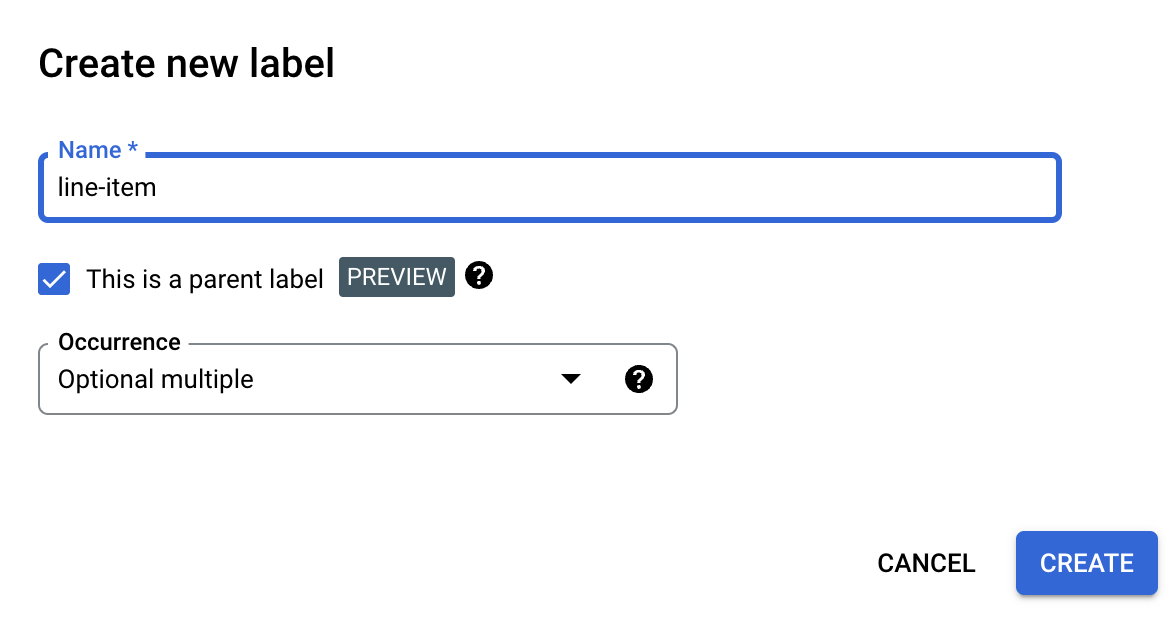
親ラベルが [スキーマの編集] ページに表示され、その横に [子ラベルを追加] オプションが表示されます。
子ラベルを作成するには
[スキーマの編集] ページの親ラベルの横にある [子ラベルを追加] を選択します。
子ラベルの情報を入力します。
[保存] を選択します。
追加する子ラベルごとにこの手順を繰り返します。
子ラベルは、[スキーマを編集] ページで親ラベルの下にインデントされて表示されます。

親子ラベルはプレビュー機能であり、表でのみサポートされています。ネストの深さは 1 に制限されます。つまり、子エンティティに他の子エンティティを含めることはできません。
ラベル付きドキュメントからスキーマ ラベルを作成する
事前ラベル付けされた Document JSON ファイルをインポートして、スキーマラベルを自動的に作成します。
Document のインポートが進行中の場合、新しく追加されたスキーマラベルがスキーマ エディタに追加されます。[スキーマを編集] を選択して、新しいスキーマラベルのデータ型とオカレンス型を確認または変更します。確認したら、スキーマラベルを選択して [有効にする] を選択します。
サンプル データセット
Document AI Workbench の使用を開始する際に役立つように、複数のドキュメント タイプの事前ラベル付けされたサンプル Document JSON ファイルとラベルなしのサンプル Document JSON ファイルを含む、一般公開の Cloud Storage バケットにデータセットが用意されています。
ドキュメントのタイプに応じて、アップトレーニングまたはカスタム エクストラクタに使用できます。
gs://cloud-samples-data/documentai/Custom/
gs://cloud-samples-data/documentai/Custom/1040/
gs://cloud-samples-data/documentai/Custom/Invoices/
gs://cloud-samples-data/documentai/Custom/Patents/
gs://cloud-samples-data/documentai/Custom/Procurement-Splitter/
gs://cloud-samples-data/documentai/Custom/W2-redacted/
gs://cloud-samples-data/documentai/Custom/W2/
gs://cloud-samples-data/documentai/Custom/W9/