El entrenamiento y la extracción de modelos personalizados te permiten compilar tu propio modelo diseñado específicamente para tus documentos sin usar IA generativa. Es ideal si no quieres usar la IA generativa y deseas controlar todos los aspectos del modelo entrenado.
Configuración del conjunto de datos
Se requiere un conjunto de datos de documentos para entrenar, enriquecer o evaluar una versión del procesador. Los procesadores de Document AI aprenden de ejemplos, al igual que los humanos. El conjunto de datos alimenta la estabilidad del procesador en términos de rendimiento.Conjunto de datos de entrenamiento
Para mejorar el modelo y su precisión, entrena un conjunto de datos en tus documentos. El modelo se compone de documentos con verdad fundamental. Necesitas un mínimo de tres documentos para entrenar un modelo nuevo.Conjunto de datos de prueba
El conjunto de datos de prueba es el que usa el modelo para generar una puntuación F1 (precisión). Se compone de documentos con verdad fundamental. Para ver con qué frecuencia el modelo acierta, se usa la verdad fundamental para comparar las predicciones del modelo (campos extraídos del modelo) con las respuestas correctas. El conjunto de datos de prueba debe tener al menos tres documentos.Antes de comenzar
Si aún no lo hiciste, habilita la facturación y la API de Document AI.
Crea y evalúa un modelo personalizado
Comienza por compilar y, luego, evaluar un procesador personalizado.
Crea un procesador y define los campos que deseas extraer, lo cual es importante porque afecta la calidad de la extracción.
Establece la ubicación del conjunto de datos: Selecciona la carpeta de opciones predeterminada Administrada por Google. Esto se puede hacer automáticamente poco después de crear el procesador.
Navega a la pestaña Compilación y selecciona Importar documentos con el etiquetado automático habilitado (consulta Etiquetado automático con el modelo de base). Necesitas un mínimo de 10 documentos en el conjunto de entrenamiento y 10 en el conjunto de pruebas para entrenar un modelo personalizado.
Entrena el modelo:
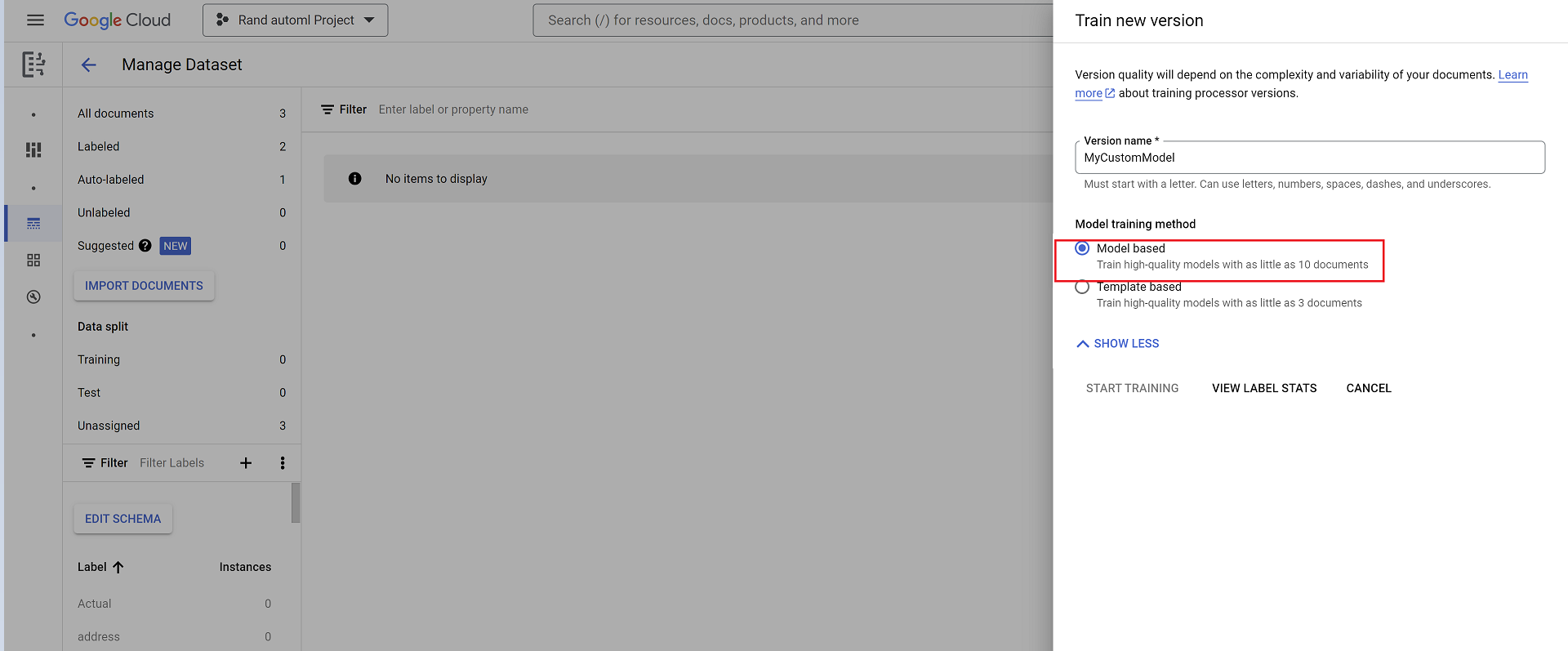
- Selecciona Entrenar versión nueva y asígnale un nombre a la versión del procesador.
- Ve a Mostrar opciones avanzadas y selecciona la opción Basado en el modelo.
Evaluación:
- Ve a Evalúa y prueba, selecciona la versión que acabas de entrenar y, luego, selecciona Ver evaluación completa.
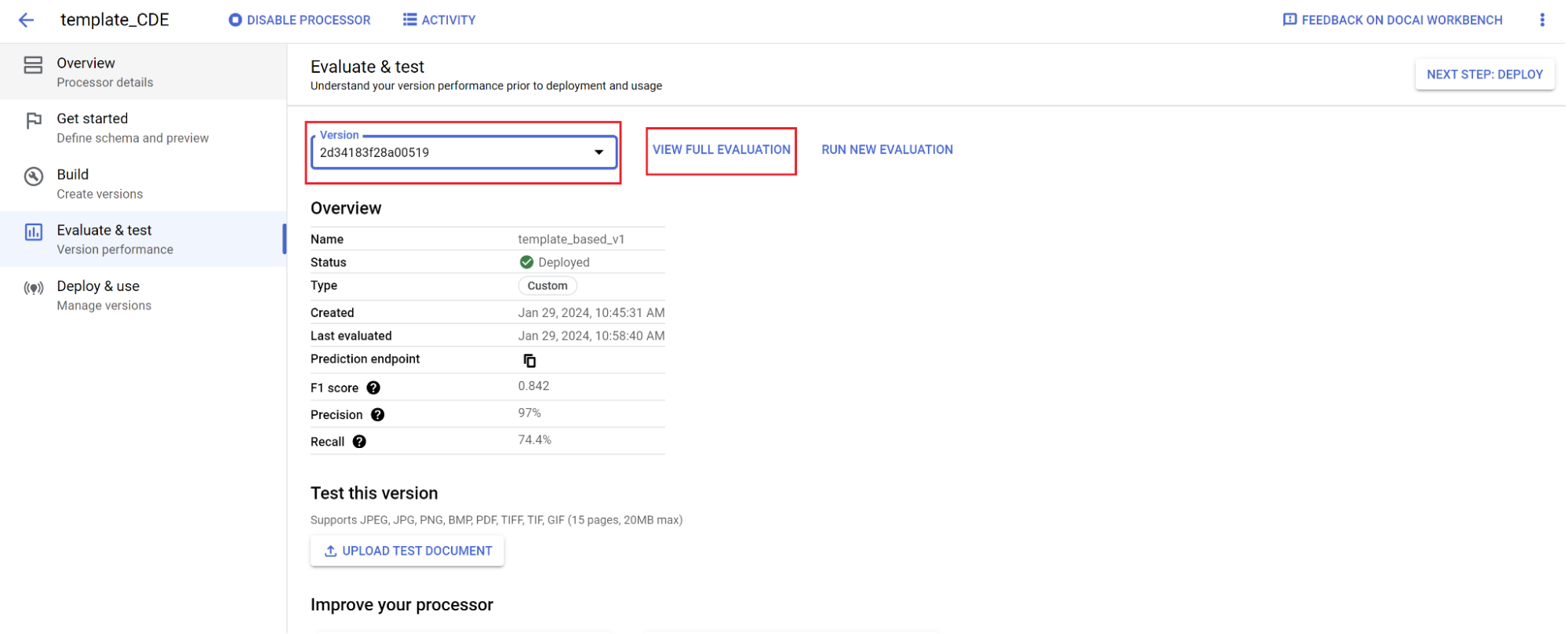
- Ahora verás métricas como f1, precisión y recuperación para todo el documento y cada campo.
- Decide si el rendimiento cumple con tus objetivos de producción. Si no es así, vuelve a evaluar los conjuntos de entrenamiento y de prueba, y agrega documentos al conjunto de prueba de entrenamiento que no se analicen bien.
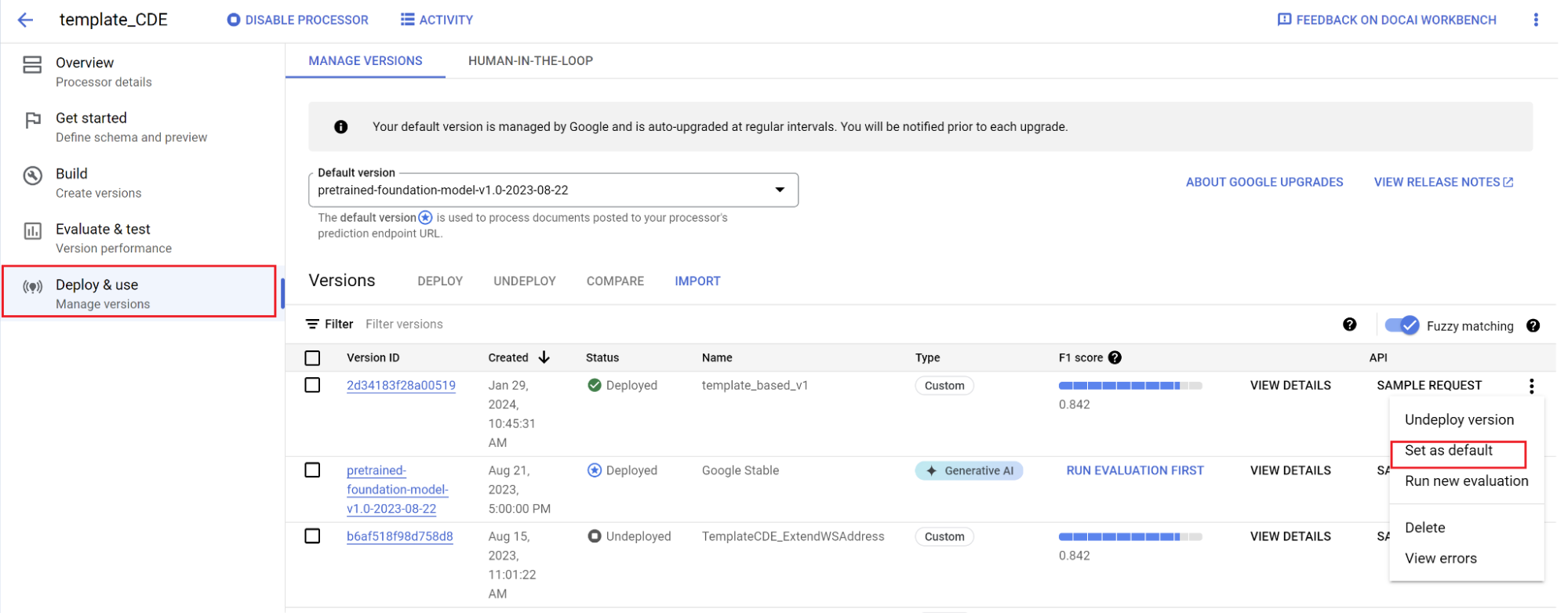
Establece una versión nueva como predeterminada.
- Navega a Administrar versiones.
- Navega al menú y, luego, selecciona Establecer como predeterminado.
Tu modelo ya está implementado y los documentos que se envían a este procesador ahora usan tu versión personalizada. Quieres evaluar el rendimiento del modelo para verificar si requiere más entrenamiento.
Referencia de evaluación
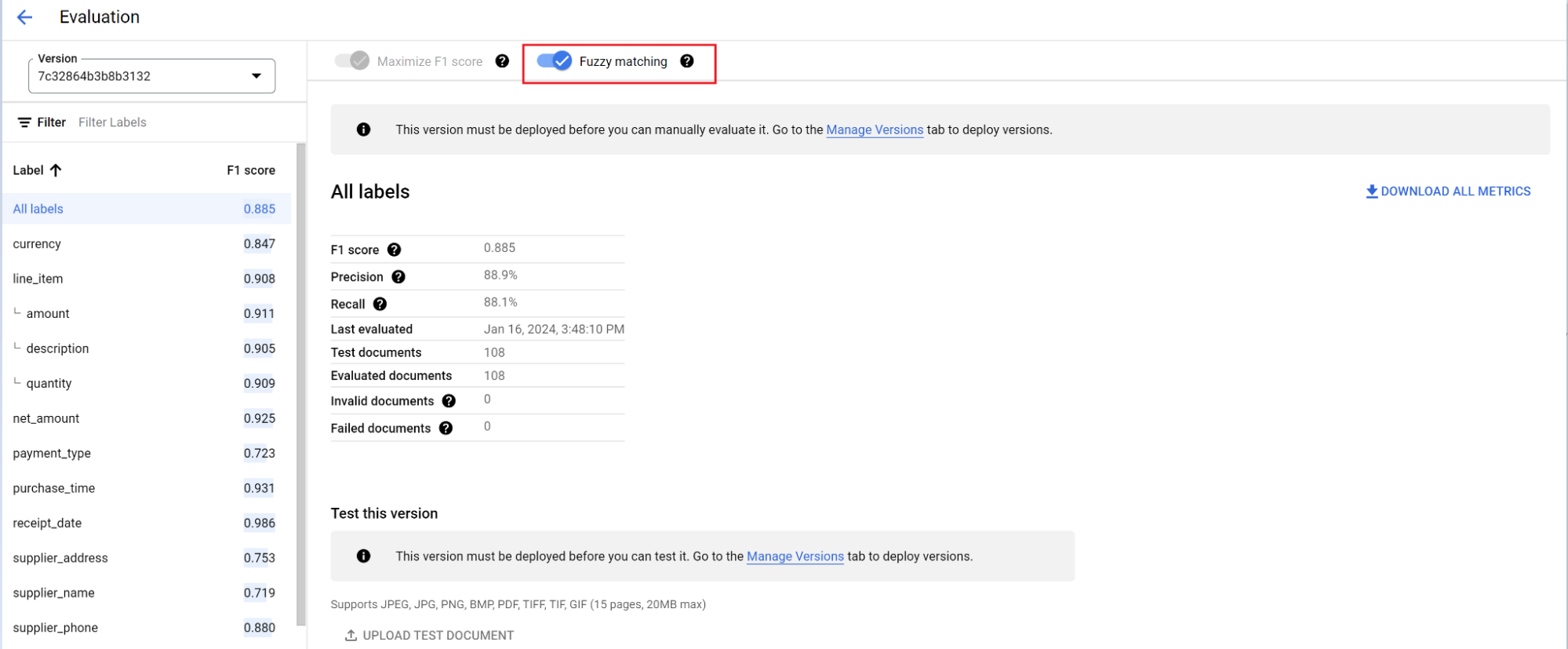
El motor de evaluación puede realizar coincidencias exactas o coincidencias aproximadas. Para una coincidencia exacta, el valor extraído debe coincidir exactamente con la verdad fundamental o se cuenta como un error.
Las extracciones de coincidencias aproximadas que tenían pequeñas diferencias, como diferencias en el uso de mayúsculas, aún se consideran coincidencias. Esto se puede cambiar en la pantalla Evaluación.
Etiquetado automático con el modelo fundamental
El modelo de base puede extraer campos con exactitud para una variedad de tipos de documentos, pero también puedes proporcionar datos de entrenamiento adicionales para mejorar la precisión del modelo para estructuras de documentos específicas.
Document AI usa los nombres de etiquetas que tú defines y las anotaciones anteriores para etiquetar documentos a gran escala con el etiquetado automático.
- Cuando hayas creado un procesador personalizado, ve a la pestaña Comenzar.
- Selecciona Crear nuevo campo.
- Proporciona un nombre descriptivo y completa el campo de descripción. La descripción de la propiedad te permite proporcionar contexto, estadísticas y conocimientos previos adicionales para cada entidad y, así, mejorar la precisión y el rendimiento de la extracción.
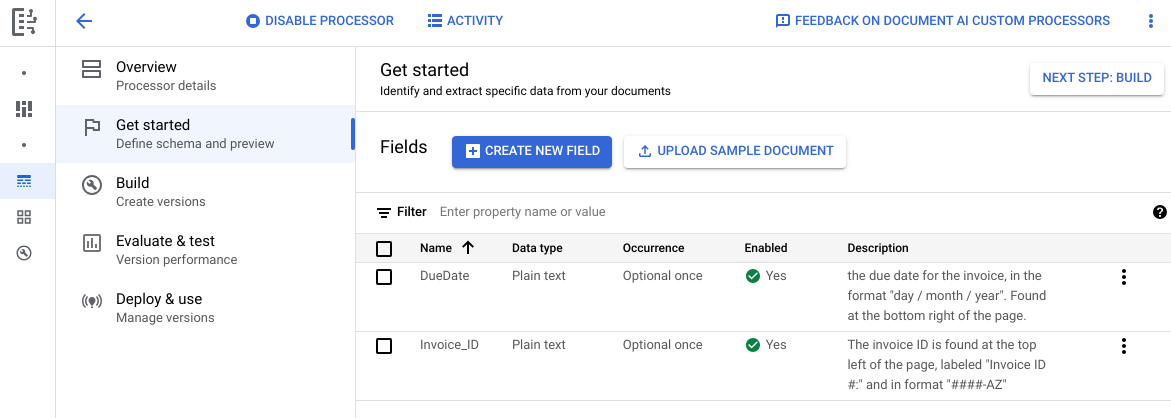
Navega a la pestaña Compilación y, luego, selecciona Importar documentos.
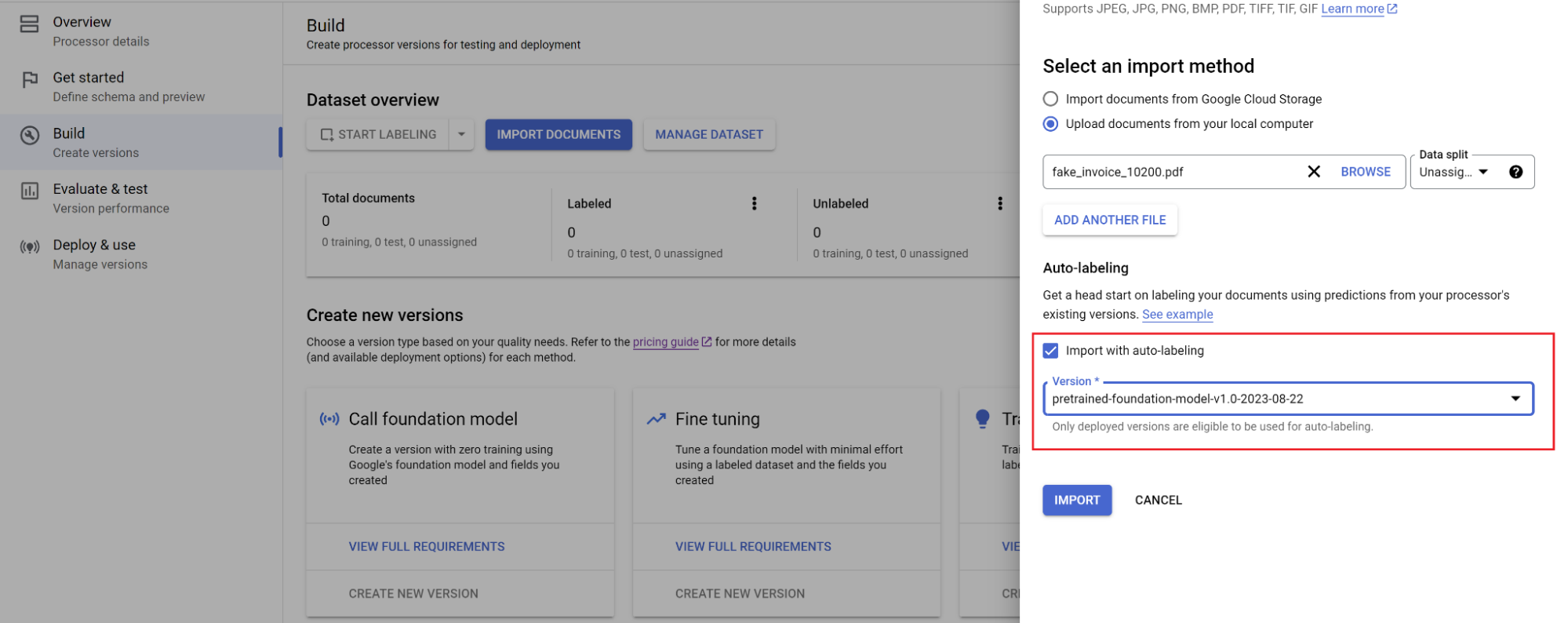
Selecciona la ruta de los documentos y el conjunto al que se deben importar. Marca la casilla de etiquetado automático y selecciona el modelo de base.
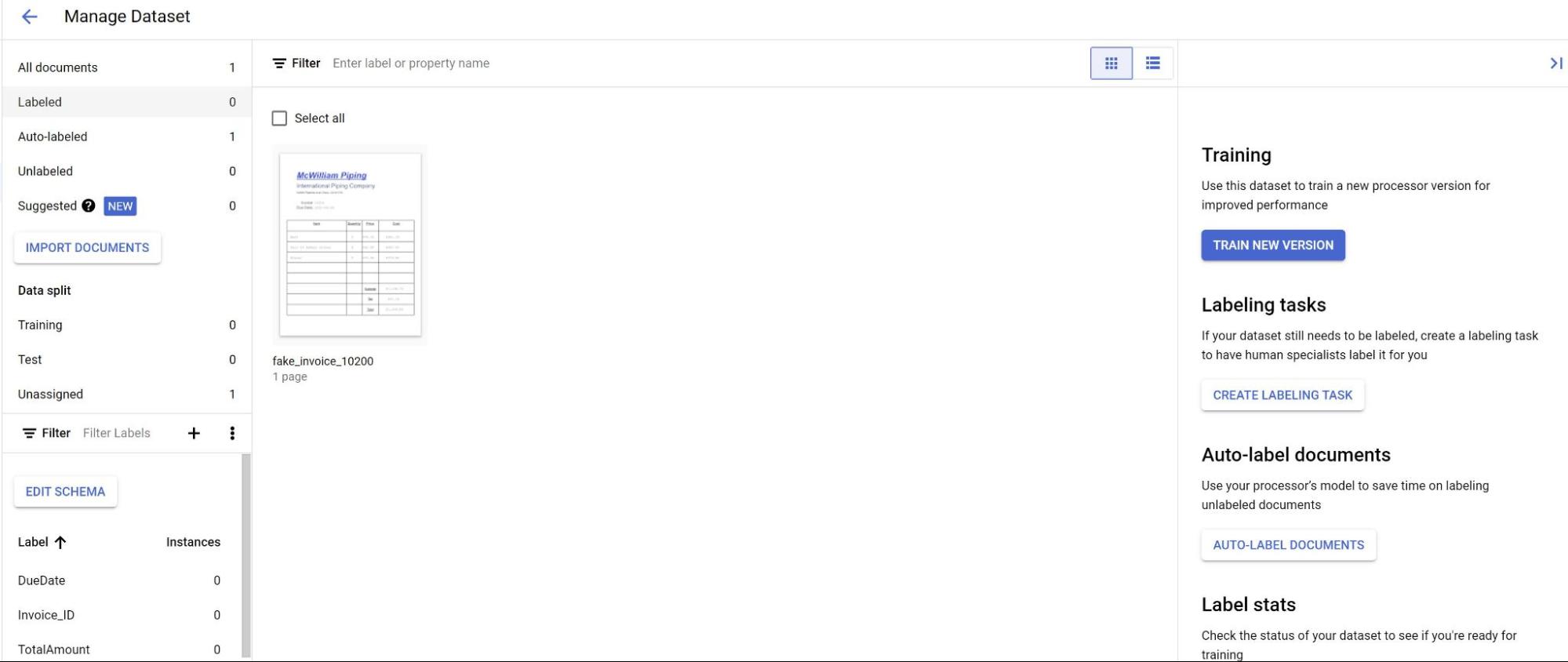
En la pestaña Compilación, selecciona Administrar conjunto de datos. Deberías ver los documentos que importaste. Selecciona uno de tus documentos.
Ahora verás las predicciones del modelo resaltadas en color púrpura.
- Revisa cada etiqueta que predijo el modelo y asegúrate de que sea correcta. Si faltan campos, agrégalos también.
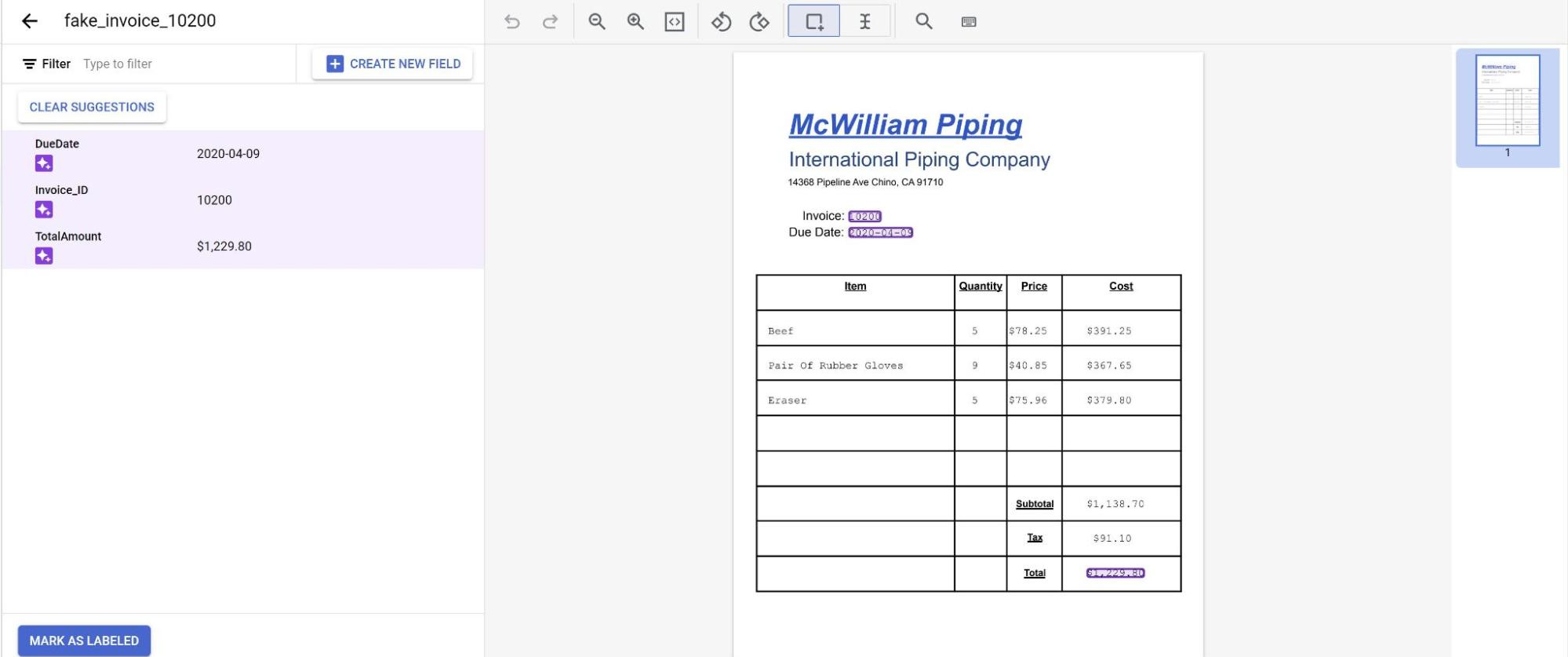
- Después de revisar el documento, selecciona Marcar como etiquetado. El documento ya está listo para que lo use el modelo. Asegúrate de que el documento esté en el conjunto de Prueba o Entrenamiento.