L'estrazione e l'addestramento dell'AI generativa ti consentono di:
- Utilizza la tecnologia zero-shot e few-shot per ottenere un modello ad alte prestazioni con pochi o nessun dato di addestramento utilizzando il foundation model.
- Utilizza il perfezionamento per aumentare ulteriormente l'accuratezza man mano che fornisci più dati di addestramento.
Metodi di addestramento dell'IA generativa
Il metodo di addestramento che scegli dipende dalla quantità di documenti a tua disposizione e dall'impegno che puoi dedicare all'addestramento del modello. Esistono tre modi per addestrare un modello di AI generativa:
| Metodo di addestramento | Zero-shot | Few-shot | Ottimizzazione |
|---|---|---|---|
| Accuratezza | Media | Medio-alta | Alta |
| Sforzo | Bassa | Bassa | Media |
| Numero consigliato di documenti di addestramento | 0 | Da 5 a 10 | Da 10 a 50+ |
Versioni del modello di estrattore personalizzato
Per l'estrattore personalizzato sono disponibili i seguenti modelli. Per modificare le versioni del modello, consulta Gestione delle versioni del processore.
Le versioni 1.4, 1.5 e 1.5 Pro supportano i punteggi di confidenza.
| Versione del modello | Descrizione | Canale di rilascio | Elaborazione ML negli Stati Uniti/UE | Ottimizzazione negli Stati Uniti/UE | Data di uscita |
|---|---|---|---|---|---|
pretrained-foundation-model-v1.4-2025-02-05 |
Modello GA basato sul modello LLM Gemini 2.0 Flash. Include anche funzionalità OCR avanzate, come il rilevamento delle caselle di controllo. | Stabile | Sì | US, EU | 5 febbraio 2025 |
pretrained-foundation-model-v1.5-2025-05-05 |
Candidato pronto per la produzione basato sul modello LLM Gemini 2.5 Flash. Consigliato per chi vuole sperimentare con modelli più recenti. | Stabile | Sì | Stati Uniti, UE (anteprima) | 5 maggio 2025 |
pretrained-foundation-model-v1.5-pro-2025-06-20 |
Modello pronto per la produzione basato sul modello LLM Gemini 2.5 Pro. Supporta una quota massima di 30 pagine al minuto per le richieste di elaborazione online. Questo modello ha una qualità migliore rispetto alla versione 1.5 e potrebbe avere una latenza maggiore. | Stabile | Sì | No | 20 giugno 2025 |
pretrained-foundation-model-v1.5.1-2025-08-07 |
Modello di anteprima pubblica basato sul modello LLM Gemini 2.5 Flash. Questo modello ha le stesse funzionalità della v1.5 e ha migliorato l'apprendimento adattivo few-shot. | Candidato per la release | Sì | No | 8 agosto 2025 |
Per modificare la versione del processore nel tuo progetto, consulta Gestione delle versioni del processore.
Per inviare una richiesta di aumento della quota (QIR) per la quota predefinita del processore, segui i passaggi descritti in Gestire la quota.
Configurazione iniziale
Se non l'hai ancora fatto, abilita la fatturazione e le API Document AI.
Crea e valuta un modello di AI generativa
Crea un processore e definisci i campi che vuoi estrarre seguendo le best practice, il che è importante perché influisce sulla qualità dell'estrazione.
- Vai a Workbench > Estrattore personalizzato > Crea processore > Assegna un nome.

- Vai a Inizia > Crea nuovo campo.

Importa documenti
- Importa i documenti con l'etichettatura automatica e assegnali al set di addestramento e test.
- Per lo zero-shot, è richiesto solo lo schema. Per valutare l'accuratezza del modello, è necessario solo un set di test.
- Per il few-shot, consigliamo cinque documenti di addestramento.
- Il numero di documenti di test necessari dipende dal caso d'uso. In generale, più documenti di test sono disponibili, meglio è.
- Conferma o modifica le etichette nel documento.
Addestra modello:
- Seleziona Build, quindi Crea nuova versione.
- Inserisci un nome e seleziona Crea.

Valutazione:
- Vai a Valuta e verifica, seleziona la versione che hai appena addestrato, quindi seleziona Visualizza valutazione completa.

- Ora visualizzi metriche come F1, precisione e richiamo per l'intero documento e per ogni campo.
- Decidi se il rendimento soddisfa i tuoi obiettivi di produzione. In caso contrario, rivaluta i set di addestramento e test.
Imposta una nuova versione come predefinita:
- Vai a Gestisci versioni.
- Seleziona per espandere le opzioni, poi seleziona Imposta come predefinito.

Il modello è stato implementato. I documenti inviati a questo processore utilizzano la tua versione personalizzata. Puoi valutare le prestazioni del modello per verificare se richiede ulteriore addestramento.
Riferimento alla valutazione
Il motore di valutazione può eseguire la corrispondenza esatta o la corrispondenza fuzzy. Per una corrispondenza esatta, il valore estratto deve corrispondere esattamente al dato di riferimento o viene conteggiato come mancata corrispondenza.
Le estrazioni con corrispondenza fuzzy che presentavano lievi differenze, ad esempio differenze di maiuscole e minuscole, vengono comunque conteggiate come corrispondenze. Puoi modificare questa impostazione nella schermata Valutazione.

Ottimizzazione
Con il perfezionamento, utilizzi centinaia o migliaia di documenti per l'addestramento.
Crea un processore e definisci i campi da estrarre seguendo le best practice, il che è importante perché influisce sulla qualità dell'estrazione.
Importa i documenti con l'etichettatura automatica e assegnali al set di addestramento e test.
Conferma o modifica le etichette nel documento.
Addestra il modello.
- Seleziona la scheda Crea e poi Crea nuova versione nella casella Ottimizzazione.
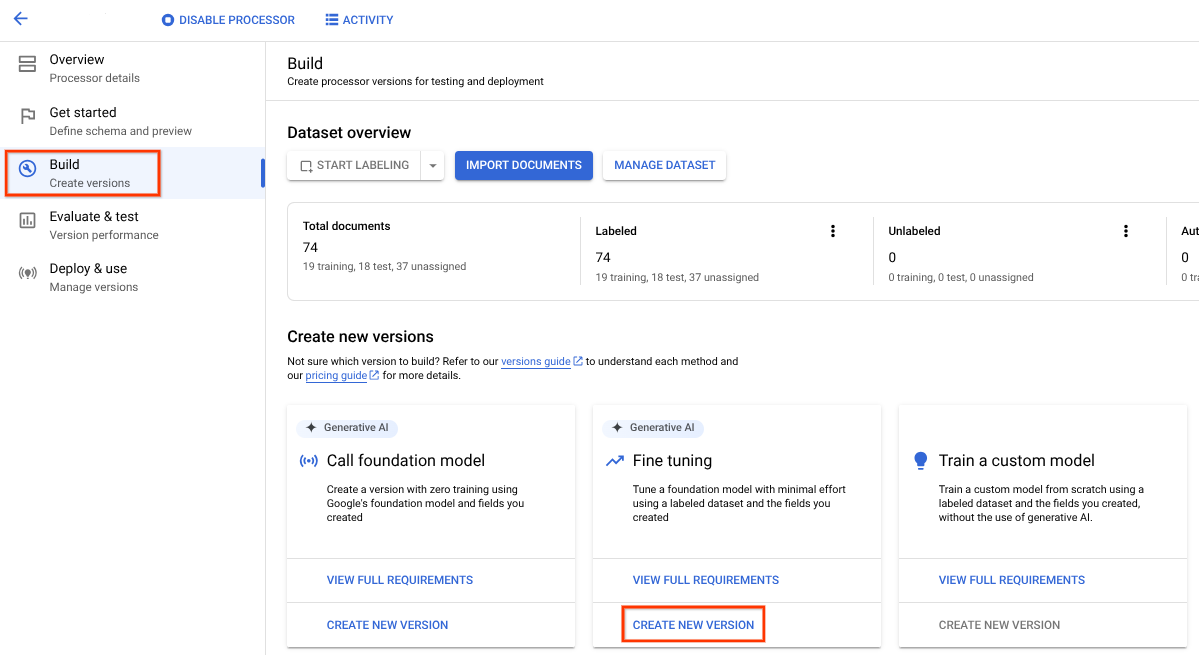
Prova i parametri o i valori di addestramento predefiniti forniti. Se i risultati non sono soddisfacenti, prova queste opzioni avanzate:
Passaggi di addestramento (tra 100 e 400): controlla la frequenza con cui i pesi vengono ottimizzati su un batch di dati durante l'ottimizzazione.
- Un valore troppo basso indica il rischio che l'addestramento termini prima della convergenza (sottoadattamento).
- Se è troppo alto, il modello potrebbe visualizzare più volte lo stesso batch di dati durante l'addestramento, il che può portare a un overfitting.
- Un numero inferiore di passaggi comporta un tempo di addestramento più rapido. Conteggi più elevati possono essere utili per i documenti con poca variazione del modello (e conteggi più bassi per quelli con più variazione).
Moltiplicatore del tasso di apprendimento (tra 0,1 e 10): controlla la velocità con cui i parametri del modello vengono ottimizzati in base ai dati di addestramento. Corrisponde approssimativamente alle dimensioni di ogni passaggio di addestramento.
- Tassi bassi significano piccole modifiche ai pesi del modello a ogni passaggio di addestramento. Se è troppo basso, il modello potrebbe non convergere verso una soluzione stabile.
- Tassi elevati indicano grandi cambiamenti e un valore troppo alto può significare che il modello supera la soluzione ottimale e converge invece verso una soluzione non ottimale.
- Il tempo di addestramento non è influenzato dalla scelta del tasso di apprendimento.
Assegna un nome, seleziona la versione del processore di base richiesta e seleziona Crea.

Valutazione: vai a Valuta e verifica, seleziona la versione che hai appena addestrato e poi Visualizza valutazione completa.
- Ora visualizzi metriche come F1, precisione e richiamo per l'intero documento e per ogni campo.
- Decidi se il rendimento soddisfa i tuoi obiettivi di produzione. In caso contrario, potrebbero essere necessari ulteriori documenti di formazione.
Imposta una nuova versione come predefinita:
- Vai a Gestisci versioni.
- Seleziona per espandere le opzioni e seleziona Imposta come predefinito.
Il modello è ora implementato e i documenti inviati a questo processore utilizzano la tua versione personalizzata. Vuoi valutare le prestazioni del modello per verificare se richiede ulteriore addestramento.
Etichettatura automatica con il modello di base
Il modello di base è in grado di estrarre con precisione i campi per vari tipi di documenti, ma puoi anche fornire dati di addestramento aggiuntivi per migliorare l'accuratezza del modello per strutture di documenti specifiche.
Document AI utilizza i nomi delle etichette che definisci e le annotazioni precedenti per rendere più rapida e semplice l'etichettatura dei documenti su larga scala grazie all'etichettatura automatica.
- Dopo aver creato un processore personalizzato, vai alla scheda Inizia.
- Seleziona Crea nuovo campo.
Assegna all'etichetta un nome descrittivo e distinto. Scegli Estrai per i valori direttamente dal documento o Deriva per i valori dedotti dal sistema. Ciò migliora l'accuratezza e le prestazioni del modello di base.

Per migliorare l'accuratezza e il rendimento dell'estrazione, aggiungi una descrizione (ad esempio contesto, approfondimenti e conoscenze precedenti per ogni entità) per i tipi di entità che deve rilevare.

Vai alla scheda Crea e seleziona Importa documenti.

Seleziona il percorso dei documenti e il set in cui devono essere importati. Seleziona l'opzione di etichettatura automatica e il modello di base.
Nella scheda Crea, seleziona Gestisci set di dati.
Quando vengono visualizzati i documenti importati, selezionane uno.

Le previsioni del modello ora vengono visualizzate evidenziate in viola.
- Esamina ogni etichetta prevista dal modello e verifica che sia corretta.
Se mancano campi, aggiungili.

Una volta esaminato il documento, seleziona Contrassegna come etichettato. Il documento è ora pronto per essere utilizzato dal modello.
Assicurati che il documento si trovi nel set di test o di addestramento.
Annidamento a tre livelli
L'estrattore personalizzato ora fornisce tre livelli di nidificazione. Questa funzionalità consente un'estrazione migliore per le tabelle complesse.
Puoi determinare il tipo di modello utilizzando le seguenti chiamate API:
La risposta è un ProcessorVersion, che contiene il campo modelType nell'anteprima v1beta3.
Procedura ed esempio
Stiamo utilizzando questo esempio:

Seleziona Inizia e poi crea un campo:
- Crea il livello superiore.
- In questo esempio viene utilizzato
officer_appointments. - Seleziona Questa è un'etichetta padre.
- Seleziona Occorrenza:
Optional multiple.



Seleziona Aggiungi campo secondario. Ora è possibile creare l'etichetta di secondo livello:
- Per questa etichetta di livello, crea
officer. - Seleziona Questa è un'etichetta padre.
- Seleziona Occorrenza:
Optional multiple.


- Per questa etichetta di livello, crea
Seleziona Aggiungi campo secondario dal secondo livello
officer. Crea etichette secondarie per il terzo livello di nidificazione.
Una volta impostato lo schema, puoi ottenere previsioni dai documenti con tre livelli di nidificazione utilizzando l'etichettatura automatica.


Etichettare le entità nidificate tra le pagine
Il processore pretrained-foundation-model-v1.5-2025-05-05 supporta la nidificazione a tre livelli nelle pagine.
Etichetta un'entità normalmente su una pagina. Nota: l'entità etichettata sarà visibile solo nella pagina in cui è etichettata, con la barra di navigazione che cambia da pagina a pagina. Se blocchi l'entità padre, questa barra di navigazione rimane visibile.
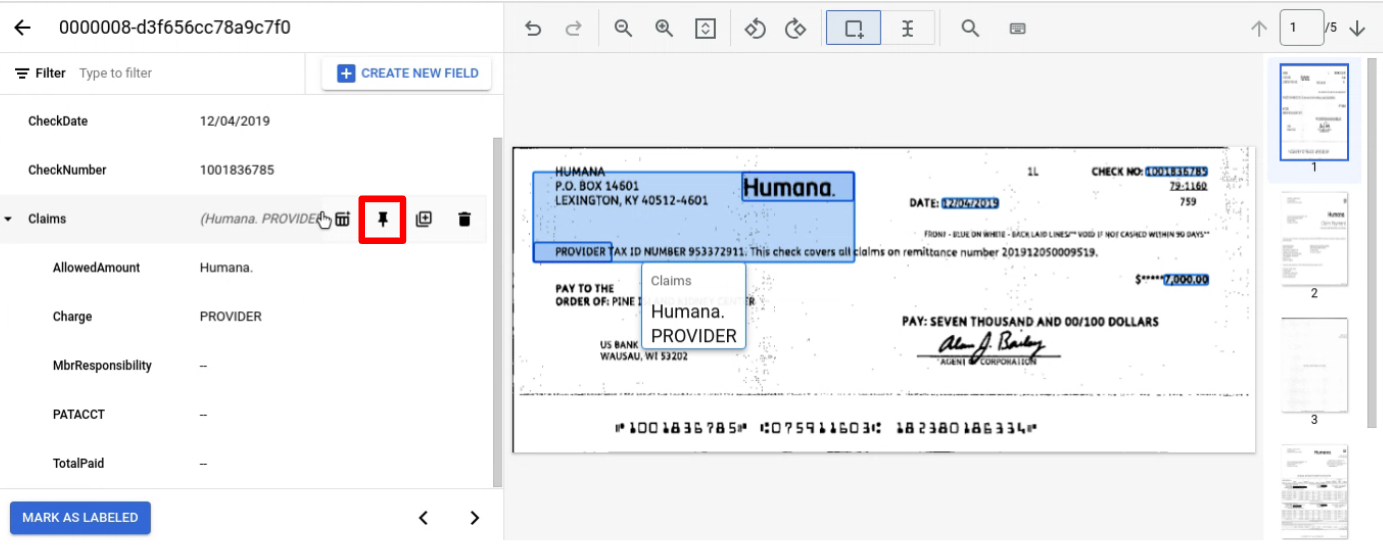
Fissa l'entità padre con i figli che vuoi etichettare nelle varie pagine.
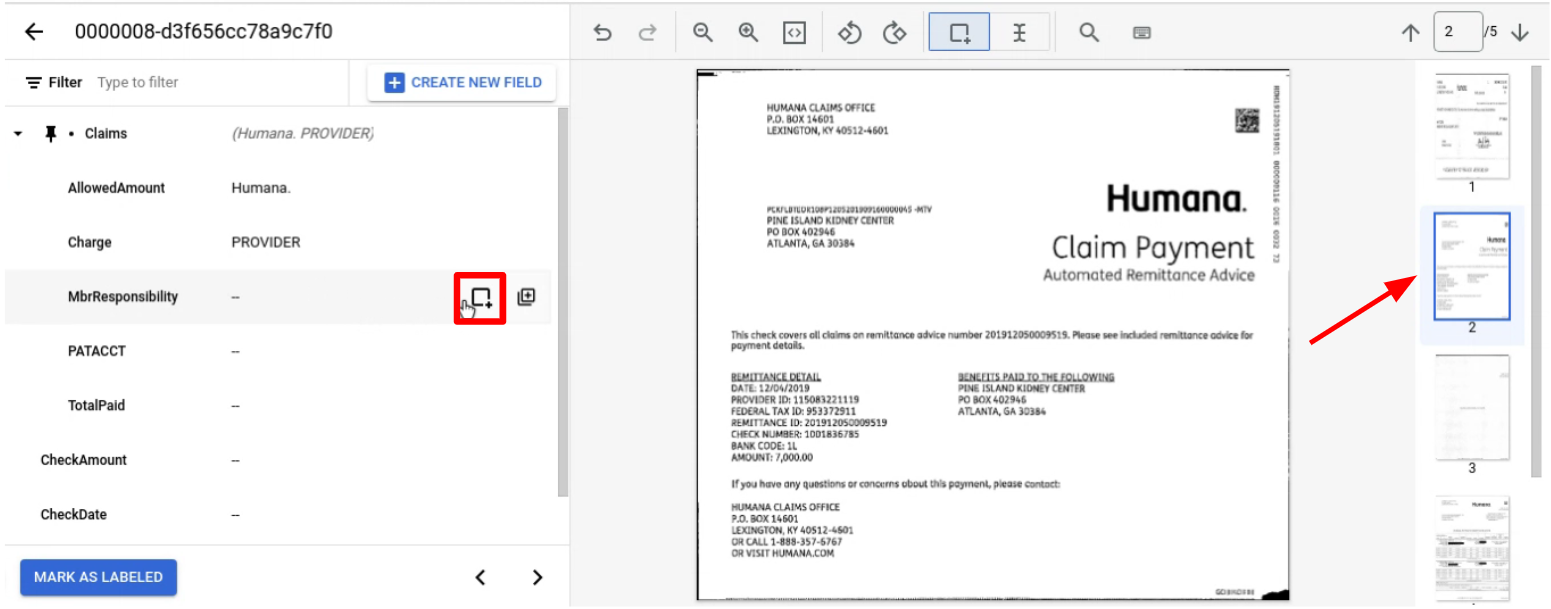
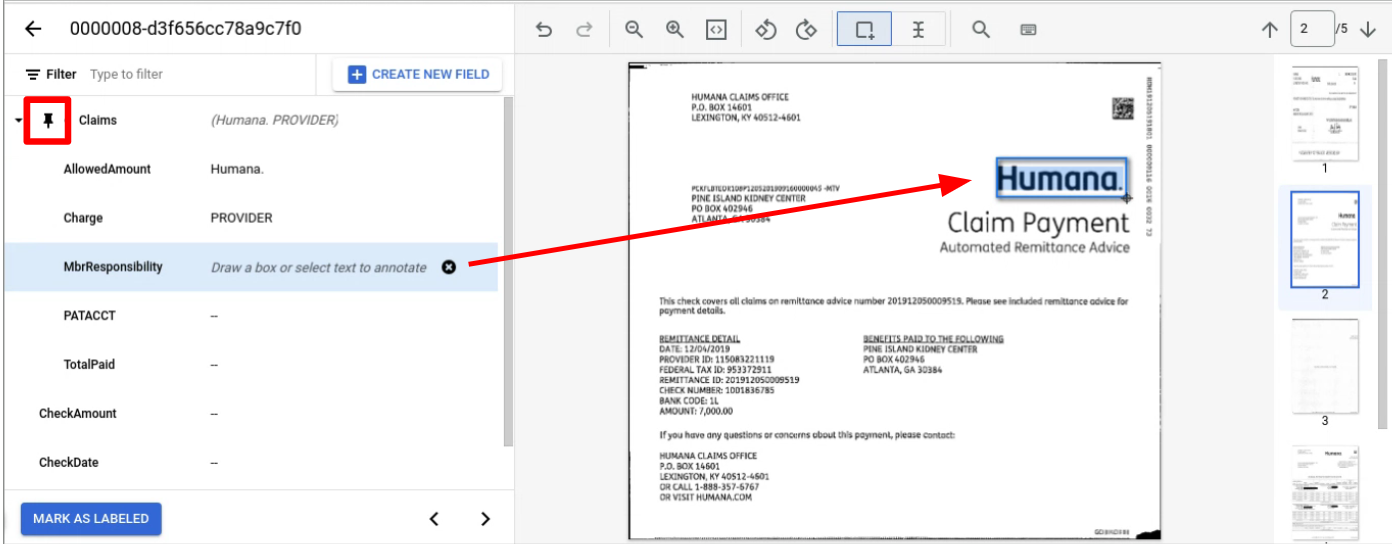
Vai alla pagina con l'entità o le entità secondarie da etichettare.
Configurazione del set di dati
Per addestrare, eseguire l'ottimizzazione dell'addestramento o valutare una versione del processore è necessario un set di dati di documenti. I processori Document AI imparano dagli esempi, proprio come gli esseri umani. Il set di dati alimenta la stabilità del processore in termini di prestazioni.Addestrare set di dati
Per migliorare il modello e la sua accuratezza, addestra un set di dati sui tuoi documenti. Il modello è composto da documenti con dati di riferimento.- Per il perfezionamento, è necessario un minimo di 1 documento per addestrare un nuovo modello con la versione
per
pretrained-foundation-model-v1.2-2024-05-10epretrained-foundation-model-v1.3-2024-08-31. - Per il few-shot, sono consigliati cinque documenti.
- Per lo zero-shot, è richiesto solo uno schema.
Set di dati di test
Il set di dati di test è ciò che il modello utilizza per generare un punteggio F1 (accuratezza). È composto da documenti con dati di riferimento. Per vedere la frequenza con cui il modello è corretto, i dati empirici reali vengono utilizzati per confrontare le previsioni del modello (campi estratti dal modello) con le risposte corrette. Il set di dati di test deve contenere almeno un documento perpretrained-foundation-model-v1.2-2024-05-10 e
pretrained-foundation-model-v1.3-2024-08-31.
Estrattore personalizzato con descrizioni delle proprietà
Con le descrizioni delle proprietà, puoi addestrare un modello descrivendo l'aspetto dei campi etichettati. Puoi fornire contesto e approfondimenti aggiuntivi per ogni entità. In questo modo, il modello può eseguire l'addestramento abbinando i campi che corrispondono alla descrizione che fornisci e migliorare l'accuratezza dell'estrazione. Le descrizioni delle proprietà possono essere specificate sia per le entità principali che per quelle secondarie.
Buoni esempi di descrizioni delle proprietà includono informazioni sulla posizione e modelli di testo dei valori delle proprietà, che aiutano a eliminare potenziali fonti di confusione nel documento. Descrizioni delle proprietà chiare e precise guidano il modello con regole che promuovono estrazioni più affidabili e coerenti, indipendentemente dalla struttura specifica del documento o dalle variazioni dei contenuti.
Aggiorna lo schema del documento per un processore
Per informazioni su come impostare le descrizioni delle proprietà, consulta Aggiornare lo schema del documento.
Invia una richiesta di elaborazione con le descrizioni delle proprietà
Se lo schema del documento ha già delle descrizioni impostate, puoi inviare una richiesta di elaborazione con le istruzioni riportate in Invia una richiesta di elaborazione.
Ottimizzare un processore con le descrizioni delle proprietà
Prima di utilizzare i dati della richiesta, apporta le seguenti sostituzioni:
- LOCATION: la posizione del tuo responsabile del trattamento, ad esempio:
us- Stati Unitieu- Unione Europea
- PROJECT_ID: il tuo ID progetto Google Cloud .
- PROCESSOR_ID: l'ID del tuo processore personalizzato.
- DISPLAY_NAME: il nome visualizzato del processore.
- PRETRAINED_PROCESSOR_VERSION: l'identificatore della versione del processore. Per saperne di più, consulta Selezionare una versione del processore. Ad esempio:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- TRAIN_STEPS: passaggi di addestramento per la messa a punto del modello.
- LEARN_RATE_MULTIPLIER: Moltiplicatore del tasso di apprendimento per la messa a punto del modello.
- DOCUMENT_SCHEMA: Schema per il processore. Fai riferimento a DocumentSchema representation.
Metodo HTTP e URL:
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Corpo JSON della richiesta:
{
"rawDocument": {
"parent": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID",
"processor_version": {
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/DISPLAY_NAME",
"display_name": "DISPLAY_NAME",
"model_type": "MODEL_TYPE_GENERATIVE",
},
"base_processor_version": "projects/PROJECT_ID/locations/us/processors/PROCESSOR_ID/processorVersions/PRETRAINED_PROCESSOR_VERSION",
"foundation_model_tuning_options": {
"train_steps": TRAIN_STEPS,
"learning_rate_multiplier": LEARN_RATE_MULTIPLIER,
}
"document_schema": DOCUMENT_SCHEMA
}
}
Per inviare la richiesta, scegli una di queste opzioni:
curl
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Salva il corpo della richiesta in un file denominato request.json,
ed esegui questo comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Estrattore personalizzato con rilevamento della firma
(Anteprima pubblica) L'estrattore personalizzato supporta
il rilevamento della firma. Questa funzionalità consente di rilevare la presenza di firme nei documenti. Il rilevamento della firma è disponibile solo utilizzando il tipo di metodo derived. Puoi specificare uno schema con il tipo di entità signature
per queste entità. Le entità della firma vengono derivate utilizzando indizi visivi dal documento.
Per esempi e istruzioni di configurazione, fai clic su Estrattore personalizzato con campo derivato e rilevamento della firma.
Estrattore personalizzato con campi derivati
L'estrattore personalizzato supporta i campi derivati. Consente di configurare un campo da compilare tramite inferenza o generazione intelligente in base al contesto del documento, anziché tramite l'estrazione diretta del testo. Puoi utilizzare questa funzionalità per casi d'uso come dedurre il paese da un indirizzo, riassumere un documento, contare gli elementi in una tabella o rilevare se un documento di identità è autentico, senza richiedere che il valore sia presente in modo esplicito nel testo.
Per esempi e istruzioni di configurazione, fai clic su Estrattore personalizzato con campo derivato e rilevamento della firma.
Passaggi successivi
Scopri di più sull'estrattore personalizzato con rilevamento di campi derivati e firme.