Mécanismes d'extraction personnalisés
Vous pouvez créer des extracteurs personnalisés spécifiquement adaptés à vos documents, et entraînés et évalués à l'aide de vos données. Cet outil de traitement identifie et extrait les entités de vos documents. Vous pouvez ensuite utiliser cet outil de traitement entraîné dans d'autres documents.
Avant de commencer
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Dans la console Google Cloud , accédez à la page Workbench de la section Document AI.
Pour l'extracteur personnalisé, sélectionnez
Créer un outil de traitement .
Dans le menu Créer un outil de traitement, saisissez le nom de votre outil de traitement (par exemple,
my-custom-document-extractor).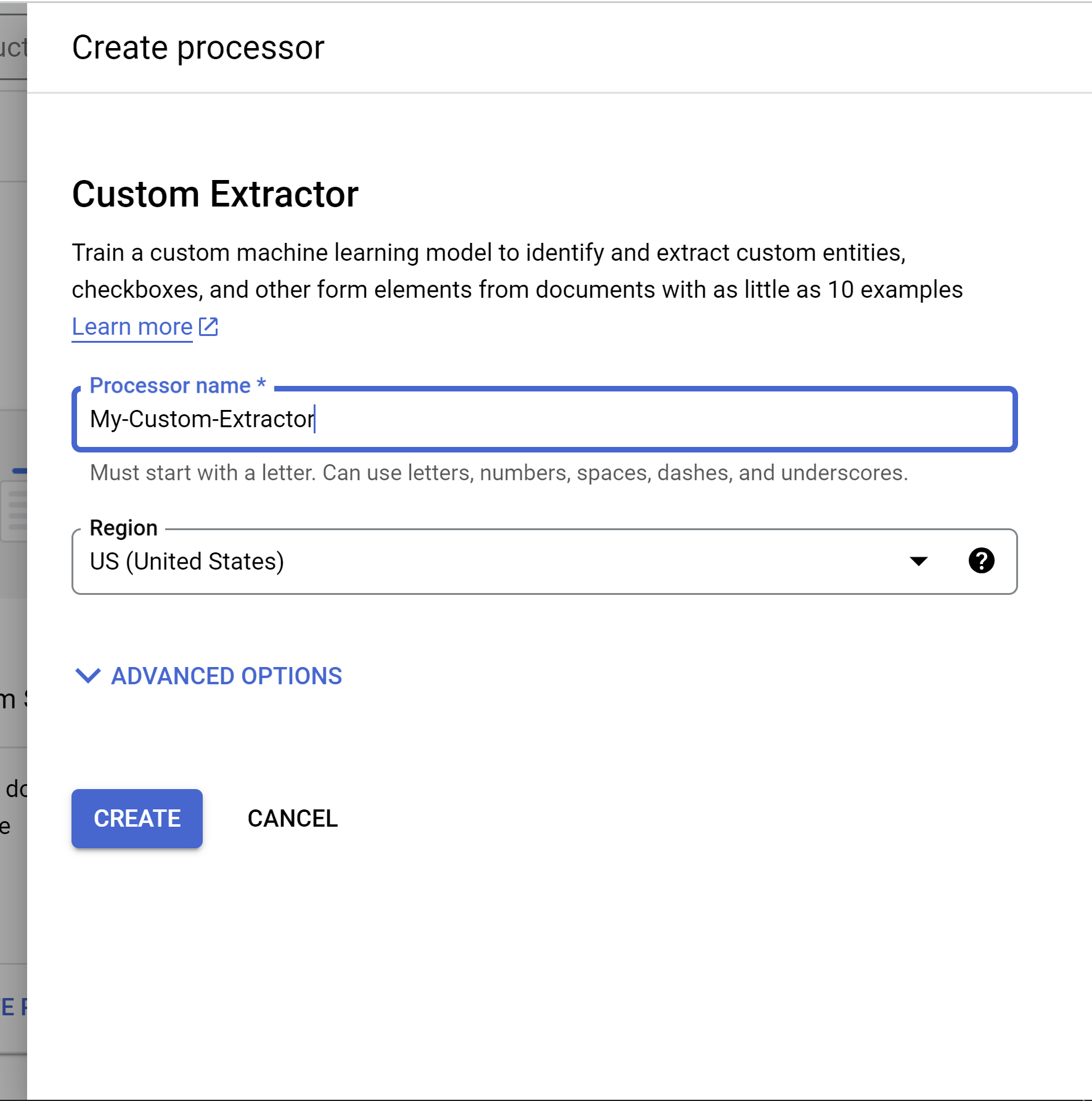
Sélectionnez la région la plus proche de vous.
Facultatif : ouvrez les Options avancées.
Vous pouvez laisser Google créer un bucket Cloud Storage à votre place ou créer le vôtre. Pour ce tutoriel, sélectionnez Stockage géré par Google.
Vous avez également la possibilité d'utiliser des clés de chiffrement gérées par le client (CMEK) ou gérées par Google. Pour ce tutoriel, sélectionnez Google-managed encryption key.
Sélectionnez Créer pour créer l'outil de traitement.
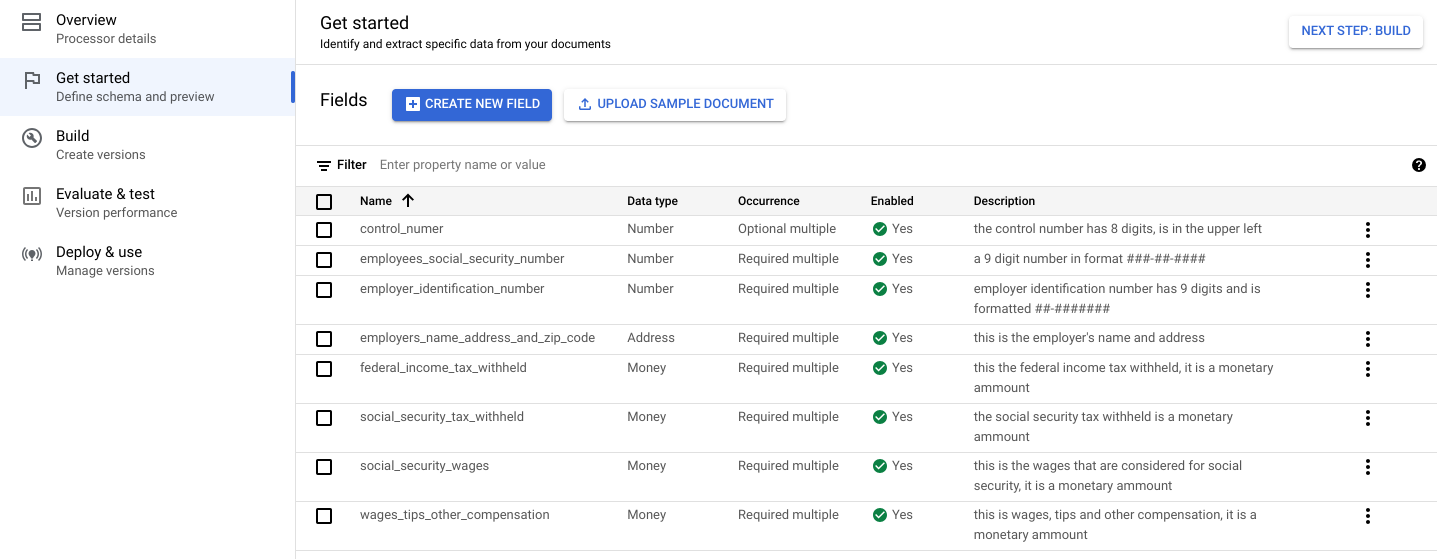
Sélectionnez l'onglet
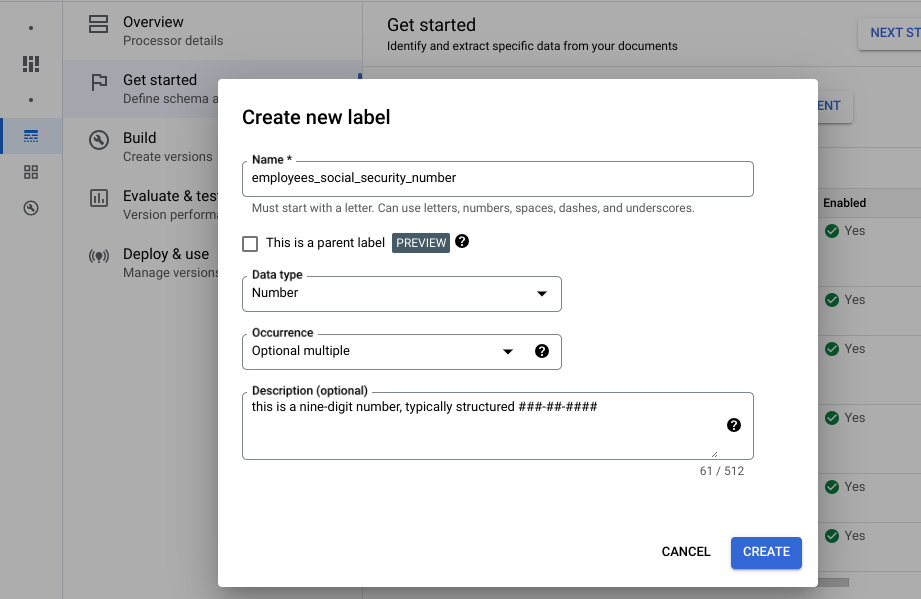
Premiers pas . Le menu Champs s'affiche.Sélectionnez Créer un champ.
Saisissez le nom du champ. Sélectionnez le type de données et l'occurrence. Attribuez au libellé une description distincte. La description de la propriété vous permet de fournir des informations contextuelles, des insights et des connaissances préalables supplémentaires pour chaque entité afin d'améliorer la précision et les performances de l'extraction.
- Sélectionnez Créer. Consultez la section Définir le schéma de l'outil de traitement pour obtenir des instructions détaillées sur la création et la modification d'un schéma.
Créez chacune des étiquettes suivantes pour le schéma de l'outil de traitement.
Nom Type de données Occurrence control_numberNombre Facultatif multiple employees_social_security_numberNombre Obligatoire multiple employer_identification_numberNombre Obligatoire multiple employers_name_address_and_zip_codeAdresse Obligatoire multiple federal_income_tax_withheldValeur monétaire Obligatoire multiple social_security_tax_withheldValeur monétaire Obligatoire multiple social_security_wagesValeur monétaire Obligatoire multiple wages_tips_other_compensationValeur monétaire Obligatoire multiple Vous pouvez également créer et utiliser d'autres types d'étiquettes dans le schéma de votre outil de traitement, tels que des cases à cocher et des entités tabulaires. Par exemple, les formulaires W-2 contiennent des cases à cocher Employé légal, Régime de retraite et Indemnités tierces en cas de maladie que vous pouvez également ajouter au schéma.
Sélectionnez Importer un exemple de document.
Dans la barre latérale, sélectionnez Importer des documents depuis Cloud Storage.
Pour cet exemple, saisissez le nom de ce bucket dans
Chemin source . Cela renvoie directement vers un document.cloud-samples-data/documentai/Custom/W2/PDF/W2_XL_input_clean_2950.pdfSélectionnez Importer.
Lorsque vous vous trouvez dans la console d'étiquetage, notez que de nombreuses étiquettes sont déjà renseignées. En effet, le type de modèle d'extracteur personnalisé par défaut est un modèle de fondation, qui peut effectuer une prédiction zero-shot, c'est-à-dire sans entraînement.
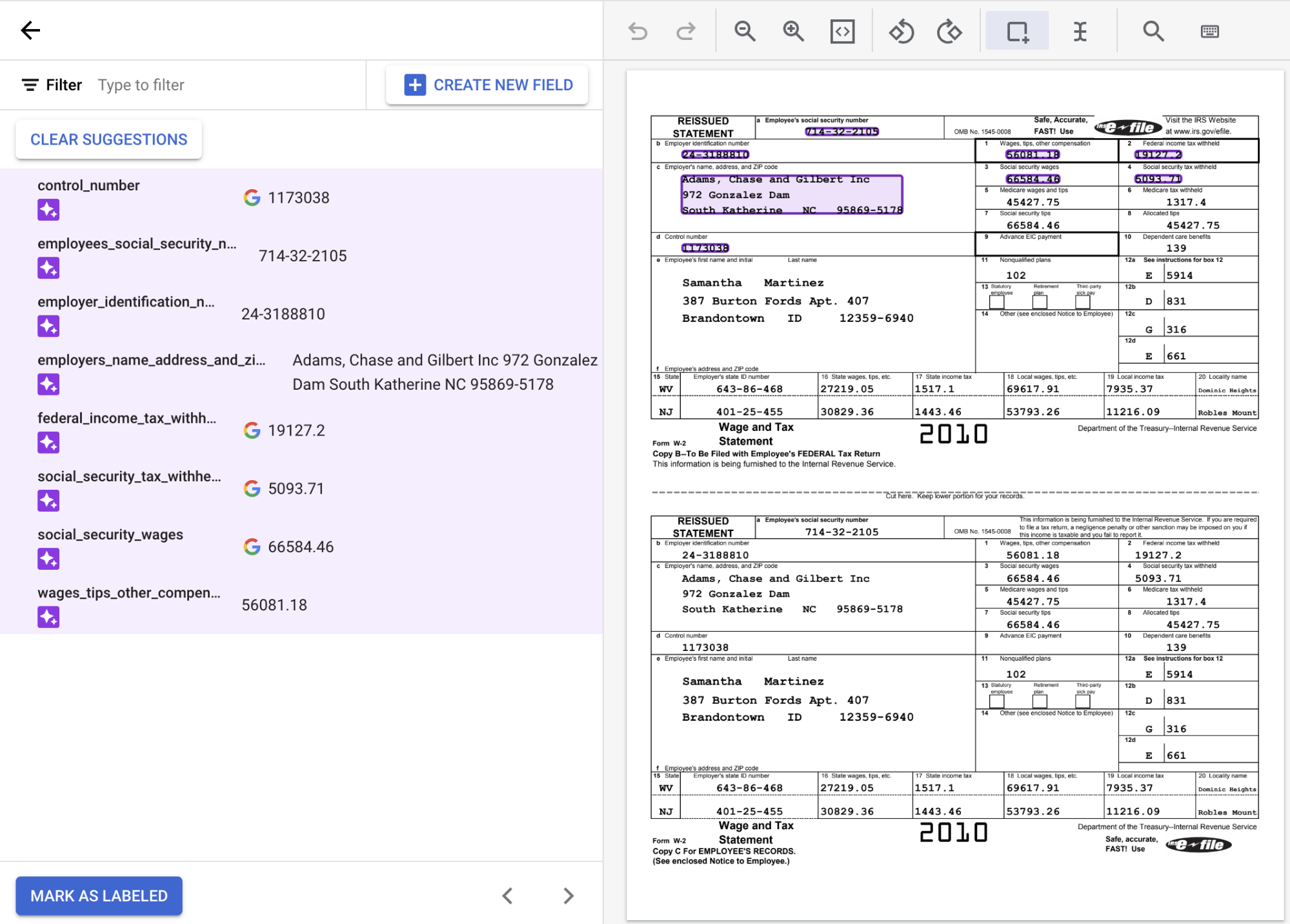
Pour utiliser les étiquettes suggérées, pointez sur chacune des
étiquettes dans le panneau latéral, puis sélectionnez la coche pour confirmer qu'elles sont correctes. Ne modifiez pas le texte, même si la ROC ne le lit pas correctement.Dans cet exemple, les valeurs au bas du document n'ont pas été identifiées automatiquement. Vous devez donc les étiqueter manuellement.
Utilisez les icônes de la barre d'outils située au-dessus du document pour libeller. Utilisez l'outil
Cadre de délimitation par défaut ouSélectionner du texte pour les valeurs multilignes, pour sélectionner le contenu et appliquer l'étiquette.Une fois le texte sélectionné, un menu déroulant s'affiche avec tous les champs définis (entités) pour vous permettre d'en sélectionner un. Dans cet exemple, la valeur de
wages_tips_other_compensationest sélectionnée à l'aide de l'outil "Cadre de délimitation", et cette étiquette est appliquée.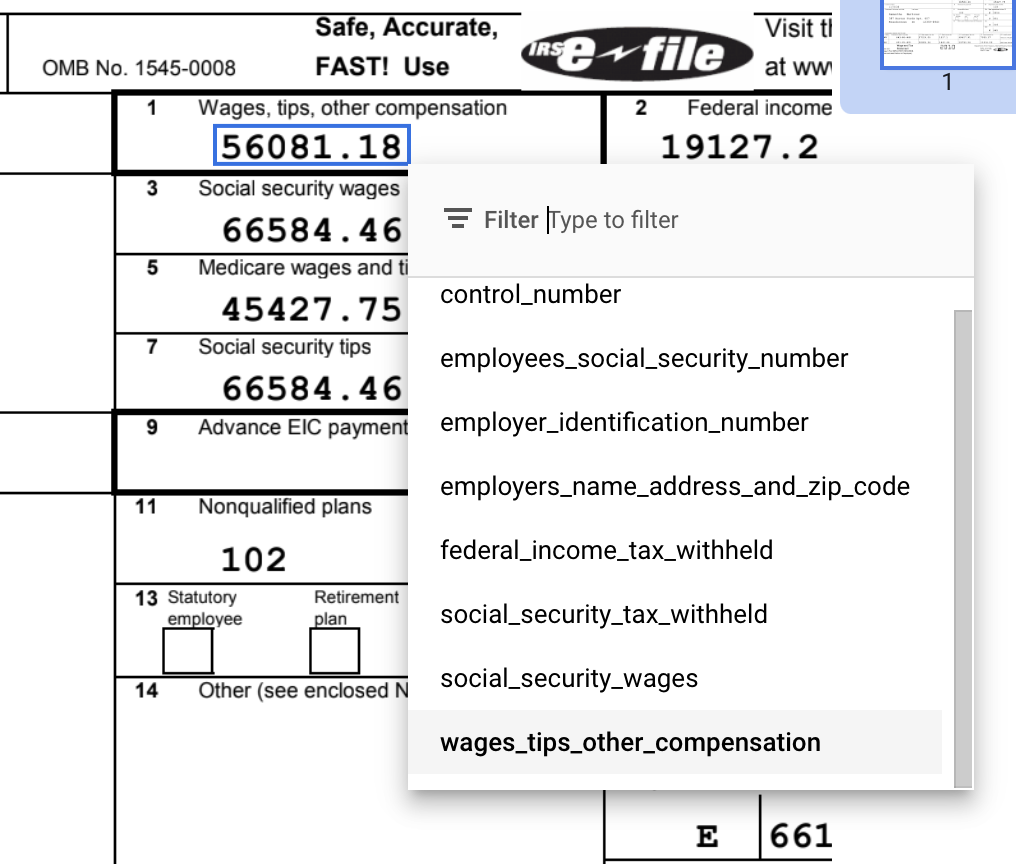
Examinez les valeurs textuelles détectées pour vous assurer qu'elles correspondent à l'emplacement correct du texte pour chaque champ. Le document W2 étiqueté devrait se présenter comme suit une fois l'opération terminée :
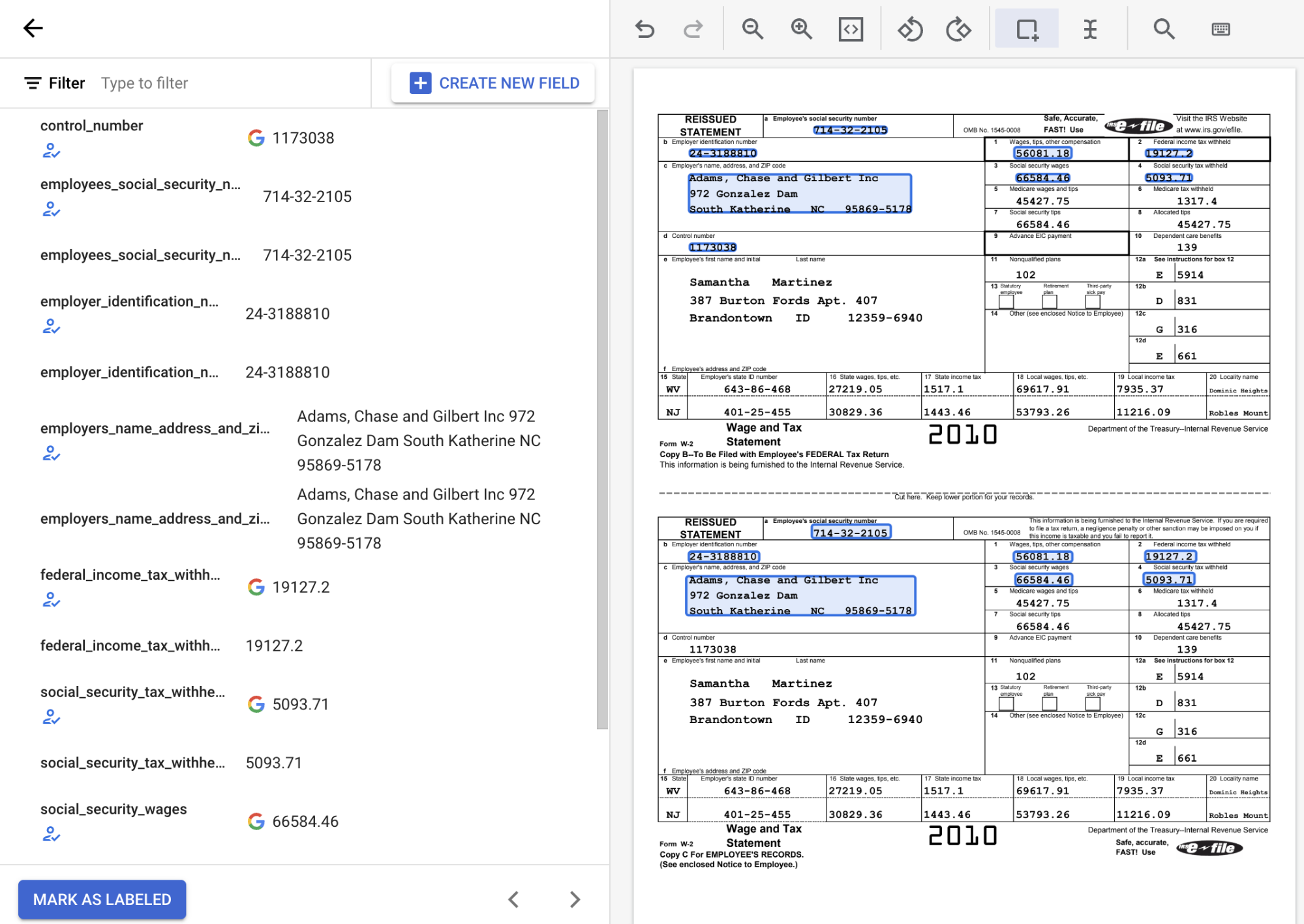
Si nécessaire, vous pouvez sélectionner
Créer un champ pour ajouter un champ au schéma à partir de cette page.Sélectionnez
Marquer comme étiqueté lorsque vous avez terminé d'annoter le document. Vous êtes redirigé vers l'onglet Premiers pas.Sélectionnez l'onglet
Compilation .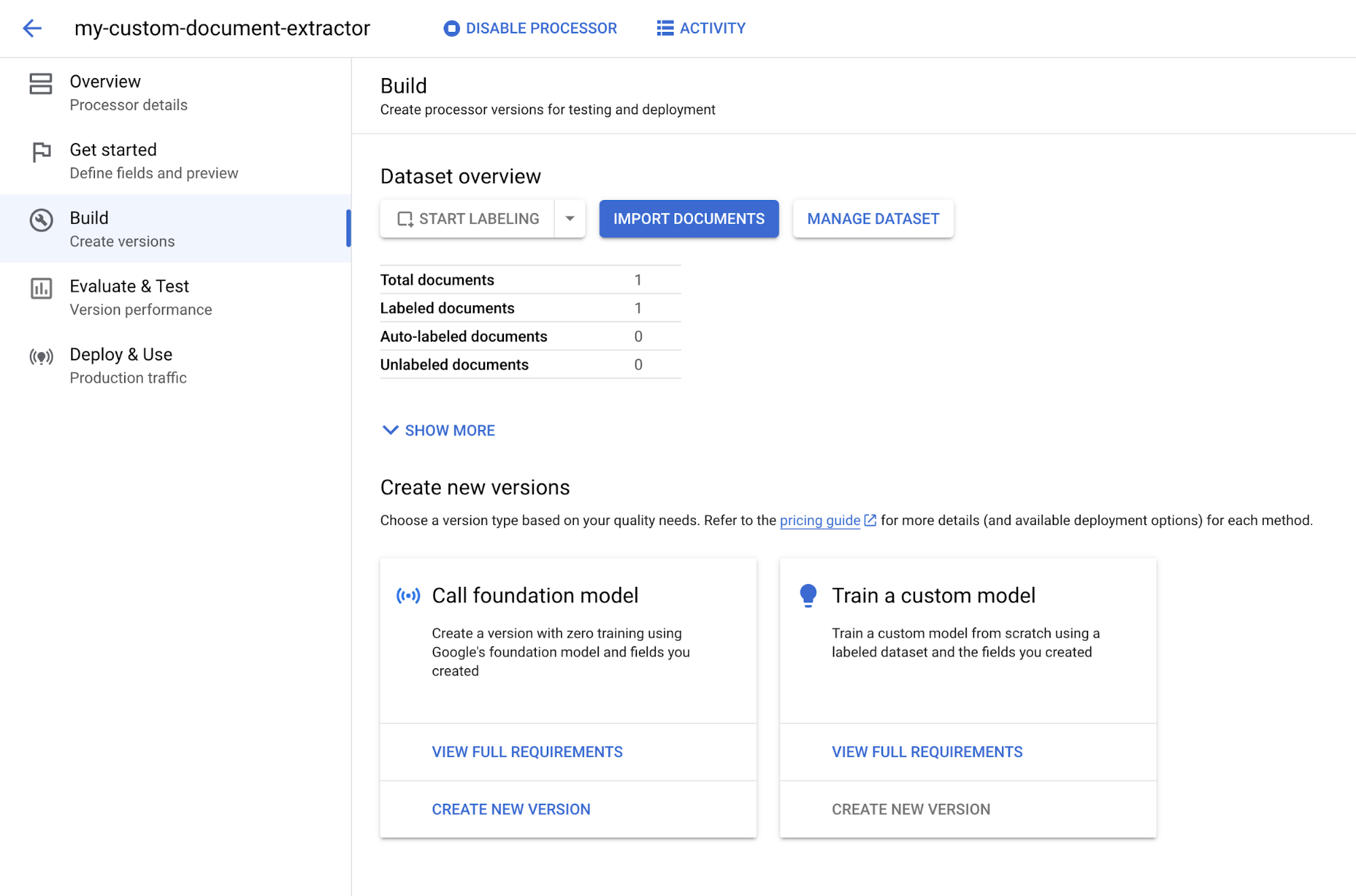
Sous Appeler un modèle de fondation, sélectionnez Créer une version.
Saisissez un nom pour la version de votre outil de traitement, par exemple
w2-foundation-model.Sélectionnez Créer une version. La création prend quelques minutes.
(Facultatif) Sélectionnez l'onglet
Déployer et utiliser . Vous pouvez y consulter les versions de l'outil de traitement disponibles et l'état de déploiement de la nouvelle version.Accédez à la page
Compiler .Sélectionnez
Importer des documents .Dans la barre latérale, sélectionnez Importer des documents depuis Google Cloud Storage.
Saisissez le nom du bucket contenant vos documents.
Dans la liste Répartition des données, sélectionnez Répartition automatique. Les documents sont automatiquement répartis de la manière suivante : 80 % dans l'ensemble d'entraînement et 20 % dans l'ensemble de test.
Dans la section Étiquetage automatique, cochez la case
Importer avec l'étiquetage automatique .Sélectionnez la version de l'outil de traitement du modèle de fondation pour étiqueter les documents.
Sélectionnez Importer et attendez que les documents soient importés. Vous pouvez quitter cette page et y revenir plus tard.
Vous devez vérifier les documents étiquetés automatiquement avant de pouvoir les utiliser à des fins d'entraînement ou de test. Sélectionnez
Démarrer l'étiquetage pour afficher les documents étiquetés automatiquement.Pour utiliser les étiquettes suggérées, pointez sur chaque
annotation , puis sélectionnez la coche pour confirmer qu'elle est correcte. À des fins d'entraînement, ne modifiez pas les valeurs si elles ne correspondent pas au texte du document. Ne modifiez le cadre de délimitation que si vous avez sélectionné un texte incorrect.Sélectionnez
Marquer comme étiqueté lorsque vous avez terminé d'annoter le document.Répétez l'opération pour chaque document étiqueté automatiquement.
Accédez à la page
Compiler .Sélectionnez
Importer des documents .Dans la barre latérale, sélectionnez Importer des documents depuis Cloud Storage.
Saisissez le chemin d'accès dans le champ Chemin source contenant vos documents. Ce bucket doit contenir des documents préalablement étiquetés au format Document JSON.
Dans la liste Répartition des données, sélectionnez Répartition automatique. Les documents sont automatiquement répartis de la manière suivante : 80 % dans l'ensemble d'entraînement et 20 % dans l'ensemble de test. Ne cochez pas la case Importer avec l'étiquetage automatique.
Sélectionnez Importer. L'importation prend plusieurs minutes.
- Sur la page Compiler, vous pouvez accéder à la console
Gérer l'ensemble de données pour afficher et modifier tous les documents et étiquettes de l'ensemble de données. Pour en savoir plus sur les exigences de l'ensemble de données, sous Entraîner un modèle personnalisé, sélectionnez Créer une version ou Afficher l'ensemble des exigences. Il ne s'agit pas d'un modèle d'IA générative. Un outil de traitement basé sur un modèle personnalisé nécessite au moins 10 instances d'entraînement et 10 instances de test pour chaque champ.
Dans le champ Nom de la version, saisissez un nom pour cette version de l'outil de traitement (par exemple,
w2-custom-model).Facultatif : sélectionnez Afficher les statistiques relatives aux étiquettes pour afficher les informations sur les étiquettes des documents. Cela peut vous aider à déterminer votre couverture. Sélectionnez Fermer pour revenir à la configuration de l'entraînement.
Sous Méthode d'entraînement du modèle, sélectionnez Basée sur un modèle.
Sélectionnez Démarrer l'entraînement. L'entraînement prend quelques heures. Vous pouvez quitter cette page et y revenir plus tard.
(Facultatif) Sélectionnez l'onglet
Déployer et utiliser . Vous pouvez y consulter les versions de l'outil de traitement disponibles et l'état d'entraînement de la nouvelle version.Une fois l'entraînement terminé, sélectionnez l'onglet
Déployer et utiliser .Sélectionnez la case située à gauche de la version que vous souhaitez déployer, puis sélectionnez Déployer.
Sélectionnez Déployer dans la boîte de dialogue. Le déploiement prend quelques minutes.
Une fois la version déployée, vous pouvez la définir comme
Version par défaut ou fournir l'ID de version lors du traitement des documents avec l'API.Sélectionnez l'onglet
Évaluation pour tester la version de l'outil de traitement. Sur cette page, vous pouvez consulter les métriques d'évaluation, y compris le score F1, la précision et le rappel pour le document complet, ainsi que des étiquettes individuelles. Pour en savoir plus sur l'évaluation et les statistiques, consultez la page Évaluer l'outil de traitement.Sélectionnez le sélecteur de
version , puis sélectionnez la version à l'aide du modèle de fondation.Téléchargez un document qui n'a pas été utilisé pour l'entraînement ou les tests précédents afin de pouvoir l'utiliser pour évaluer la version de l'outil de traitement. Si vous utilisez vos propres données, vous devez vous servir d'un document réservé à cette fin.
Sélectionnez
Importer le document de test , puis sélectionnez le document que vous venez de télécharger. La page Analyse de l'extracteur de documents personnalisé s'ouvre. La sortie de l'écran montre si le document a bien été extrait.Testez à nouveau le document en utilisant la version avec un modèle entraîné personnalisé.
- Suivez les exemples de code décrits dans la section Envoyer une demande de traitement pour utiliser le traitement en ligne ou par lot.
- Reportez-vous à la section Quotas et limites pour connaître le nombre de pages compatibles avec le traitement en ligne et par lot.
- Suivez l'exemple de code de l'extracteur personnalisé dans Gérer la réponse de traitement pour récupérer les entités extraites via l'outil de traitement.
Dans le menu de navigation de la console Google Cloud , sélectionnez Document AI, puis Mes processeurs.
Sur la ligne correspondant à l'outil de traitement que vous souhaitez supprimer, sélectionnez
Autres actions .Sélectionnez Supprimer l'outil de traitement, saisissez son nom, puis sélectionnez à nouveau Supprimer pour confirmer.
Créer un outil de traitement
Définir les champs de l'outil de traitement
Vous êtes maintenant sur la page Présentation de l'outil de traitement de l'outil que vous venez de créer.
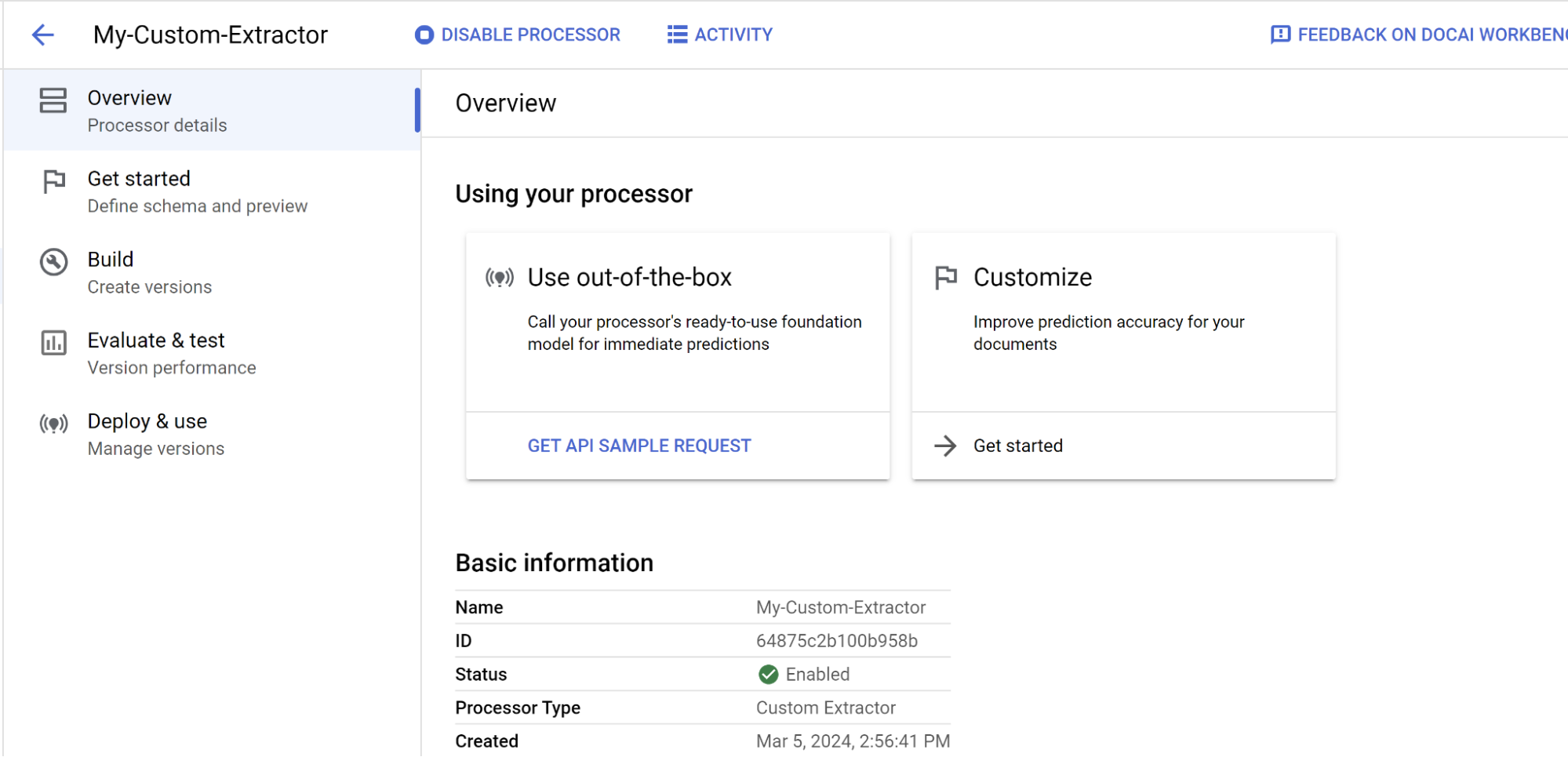
Vous pouvez spécifier les champs que vous souhaitez extraire à l'aide de celui-ci et commencer à étiqueter les documents.
Importer un exemple de document
Effectuez un test avec un exemple de document.
Vous êtes redirigé vers la console d'étiquetage.
Ajouter une étiquette à un document
Le processus de sélection de texte dans un document et d'application d'étiquettes est appelé annotation ou étiquetage.
Créer une version de l'outil de traitement à l'aide du modèle de fondation
Après avoir étiqueté un seul document, vous pouvez créer une version de l'outil de traitement à l'aide du modèle de fondation pré-entraîné pour extraire des entités.
Utiliser l'IA générative pour étiqueter automatiquement des documents
Le modèle de fondation peut extraire avec précision des champs à partir de types de documents divers, mais vous pouvez également fournir des données d'entraînement supplémentaires afin d'améliorer sa précision pour des structures de documents spécifiques.
L'extracteur personnalisé utilise les noms d'étiquettes que vous avez définis et les annotations précédentes pour faciliter et accélérer l'étiquetage des documents à grande échelle grâce à l'étiquetage automatique.
Importer des documents d'entraînement préalablement étiquetés
Facultatif : afficher et gérer l'ensemble de données
Entraîner un outil de traitement basé sur un modèle personnalisé
L'entraînement peut prendre plusieurs heures. Assurez-vous d'avoir configuré l'outil de traitement avec les données et étiquettes appropriées avant de commencer l'entraînement.
Déployer la version de l'outil de traitement
Évaluer et tester l'outil de traitement
Utiliser l'outil de traitement
Vous venez de créer et d'entraîner un outil d'extraction personnalisé.
Vous pouvez gérer les versions de votre outil de traitement entraîné personnalisé comme n'importe quelle autre version. Pour en savoir plus, consultez Gérer les versions de l'outil de traitement.
Pour utiliser l'API Document AI :
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cette démonstration soient facturées sur votre compte Google Cloud , procédez comme suit :
Pour éviter des frais Google Cloud inutiles, supprimez votre processeur et votre projet à l'aide deGoogle Cloud console si vous n'en avez plus besoin.
Si vous avez créé un projet pour apprendre à utiliser Document AI et que vous n'en avez plus besoin, supprimez-le.
Si vous avez utilisé un projet Google Cloud existant, supprimez les ressources que vous avez créées pour éviter que des frais ne soient facturés sur votre compte :
Étapes suivantes
Pour en savoir plus, consultez les Guides.