カスタム エクストラクタのメカニズム
ドキュメントに特化し、データを使用してトレーニングと評価を行うカスタム ドキュメント エクストラクタを作成できます。このプロセッサは、ドキュメントからエンティティを識別して抽出します。このトレーニング済みプロセッサを追加のドキュメントに使用できます。
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Google Cloud コンソールの Document AI セクションで、[Workbench] ページに移動します。
[カスタム エクストラクタ] では、[
プロセッサを作成 ] を選択します。
[プロセッサを作成] メニューで、プロセッサの名前を入力します(例:
my-custom-document-extractor)。
最も近いリージョンを選択します。
省略可: [詳細オプション] を開きます。
Cloud Storage バケットは、Google に作成してもらことも、独自に作成することもできます。このチュートリアルでは、[Google 管理のストレージ] を選択します。
Google が管理する暗号鍵、または顧客管理の暗号鍵(CMEK)を使用することもできます。 このチュートリアルでは、Google-managed encryption key を選択します。
[作成] を選択して、プロセッサを作成します。
[
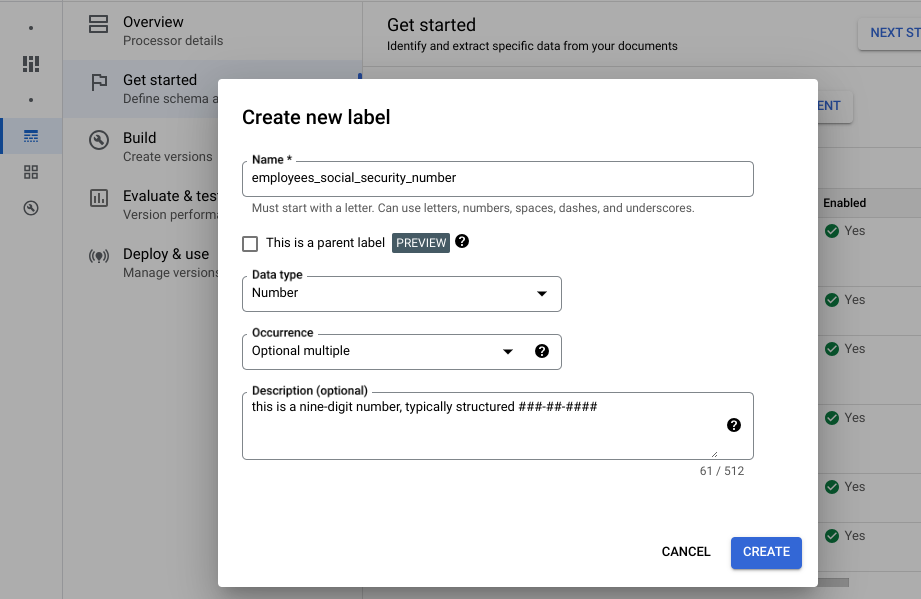
Get started ] タブを選択します。[フィールド] メニューが表示されます。[新しいフィールド] を選択します。
フィールドの名前を入力します。[データ型] と [オカレンス] を選択します。 ラベルにわかりやすく、区別できる [説明] を入力します。プロパティの説明を使用すると、各エンティティに追加のコンテキスト、分析情報、事前知識を提供して、抽出の精度とパフォーマンスを向上させることが可能です。
- [作成] を選択します。スキーマの作成と編集の詳細な手順については、プロセッサ スキーマを定義するをご覧ください。
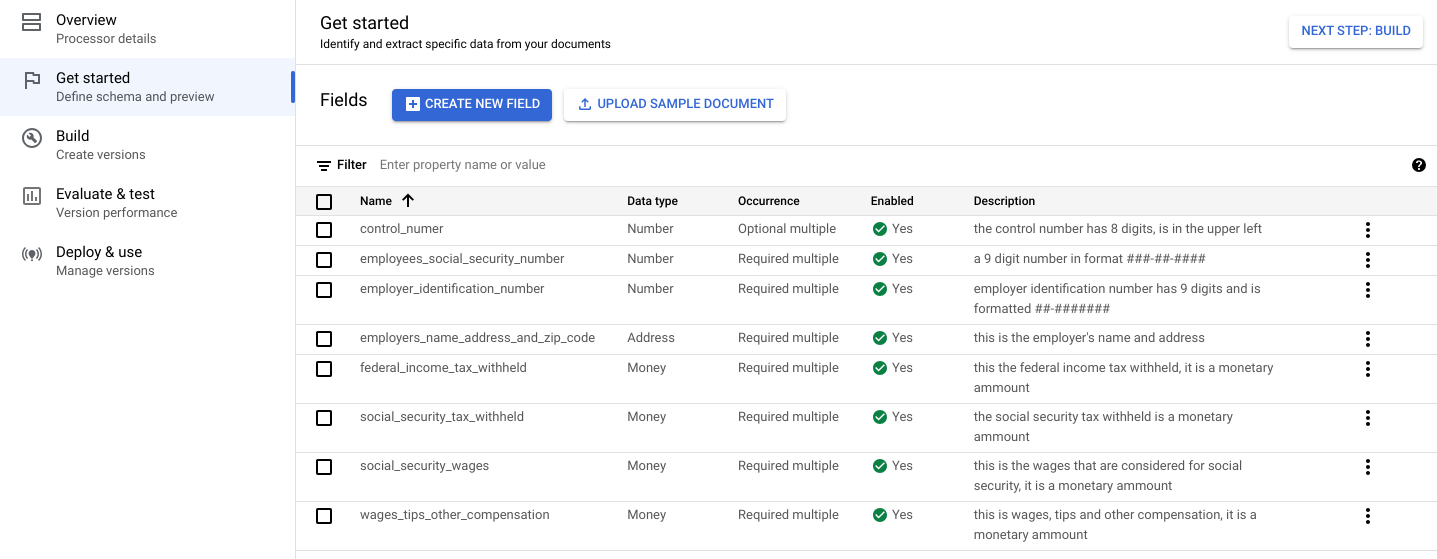
プロセッサ スキーマ用に次のラベルをそれぞれ作成します。
名前 データ型 オカレンス control_number数値 オプションの複数回 employees_social_security_number数値 必須の複数回 employer_identification_number数値 必須の複数回 employers_name_address_and_zip_code住所 必須の複数回 federal_income_tax_withheld金額 必須の複数回 social_security_tax_withheld金額 必須の複数回 social_security_wages金額 必須の複数回 wages_tips_other_compensation金額 必須の複数回 プロセッサ スキーマでは、その他の種類のラベル(チェックボックスや表形式エンティティなど)を作成して使用することもできます。たとえば、W-2 フォームには、スキーマにも追加できる [Statutory employee]、[Retirement plan]、[Third party sick pay] のチェックボックスが含まれています。
[サンプル ドキュメントをアップロード] を選択します。
サイドバーで、[Cloud Storage からドキュメントをインポートする] を選択します。
この例では、このバケット名を [
転送元のパス ] に入力します。これは 1 つのドキュメントに直接リンクしています。cloud-samples-data/documentai/Custom/W2/PDF/W2_XL_input_clean_2950.pdf[インポート] を選択します。
ラベル付けコンソールには、多くのラベルがすでに入力されています。これは、デフォルトのカスタム エクストラクタ モデルタイプが基盤モデルであり、ゼロショット予測(トレーニングなし)を実行できるためです。
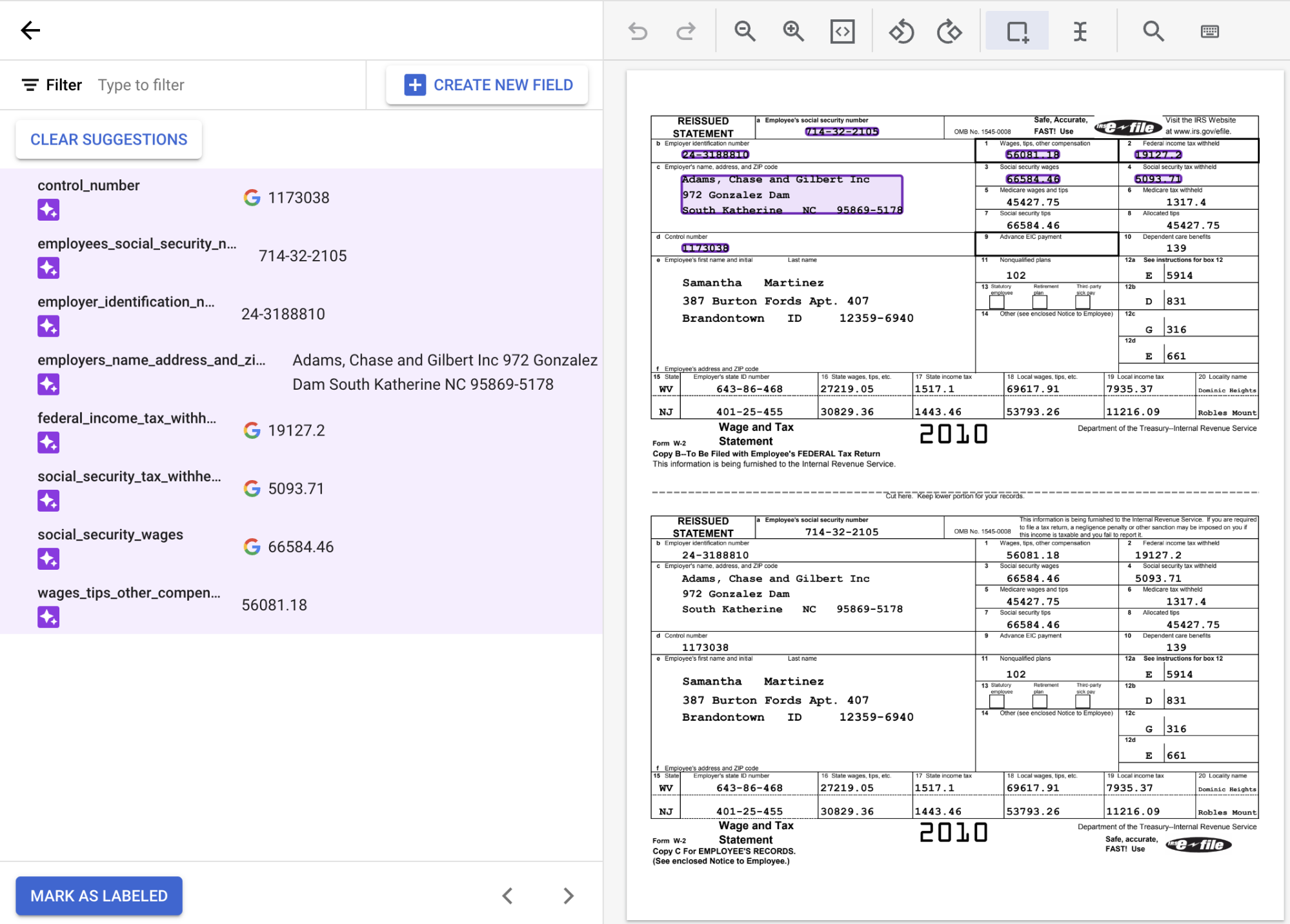
提案されたラベルを使用するには、サイドパネルの各
ラベル にポインタを合わせ、チェックマークを選択してラベルが正しいことを確認します。OCR でテキストが正しく読み取られていない場合でも、テキストは編集しないでください。この例では、ドキュメントの下部にある値は自動的に識別されなかったため、手動でラベルを付ける必要があります。
ドキュメントの上部のツールバーにあるアイコンを使用してラベルを付けます。デフォルトで [
境界ボックス ] ツールを使用するか、複数行値の場合は [テキスト選択 ] ツールを使用して、コンテンツを選択し、ラベルを適用します。テキストを選択すると、定義済みのすべてのフィールド(エンティティ)があるプルダウン メニューが表示され、選択できます。この例では、境界ボックスツールで
wages_tips_other_compensationの値が選択され、そのラベルが適用されています。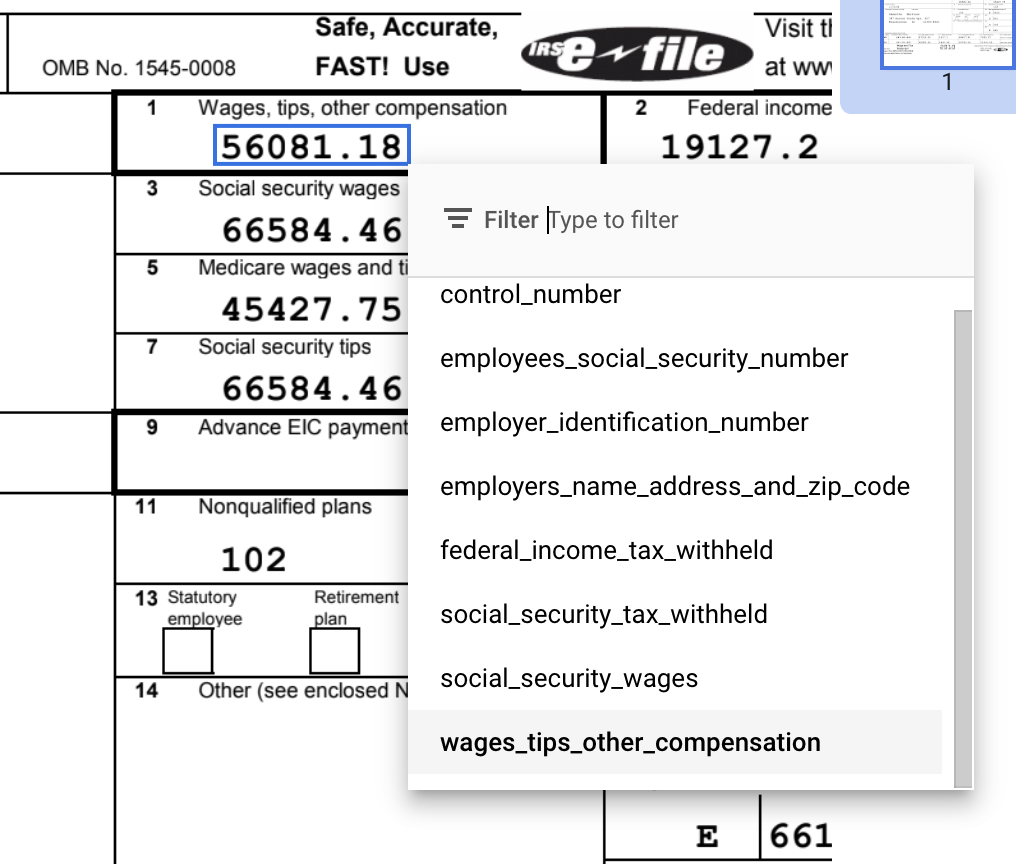
検出されたテキスト値を確認して、各フィールドのテキストの正しい位置が反映されるようにします。完了すると、ラベル付きの W2 ドキュメントは次のように表示されます。
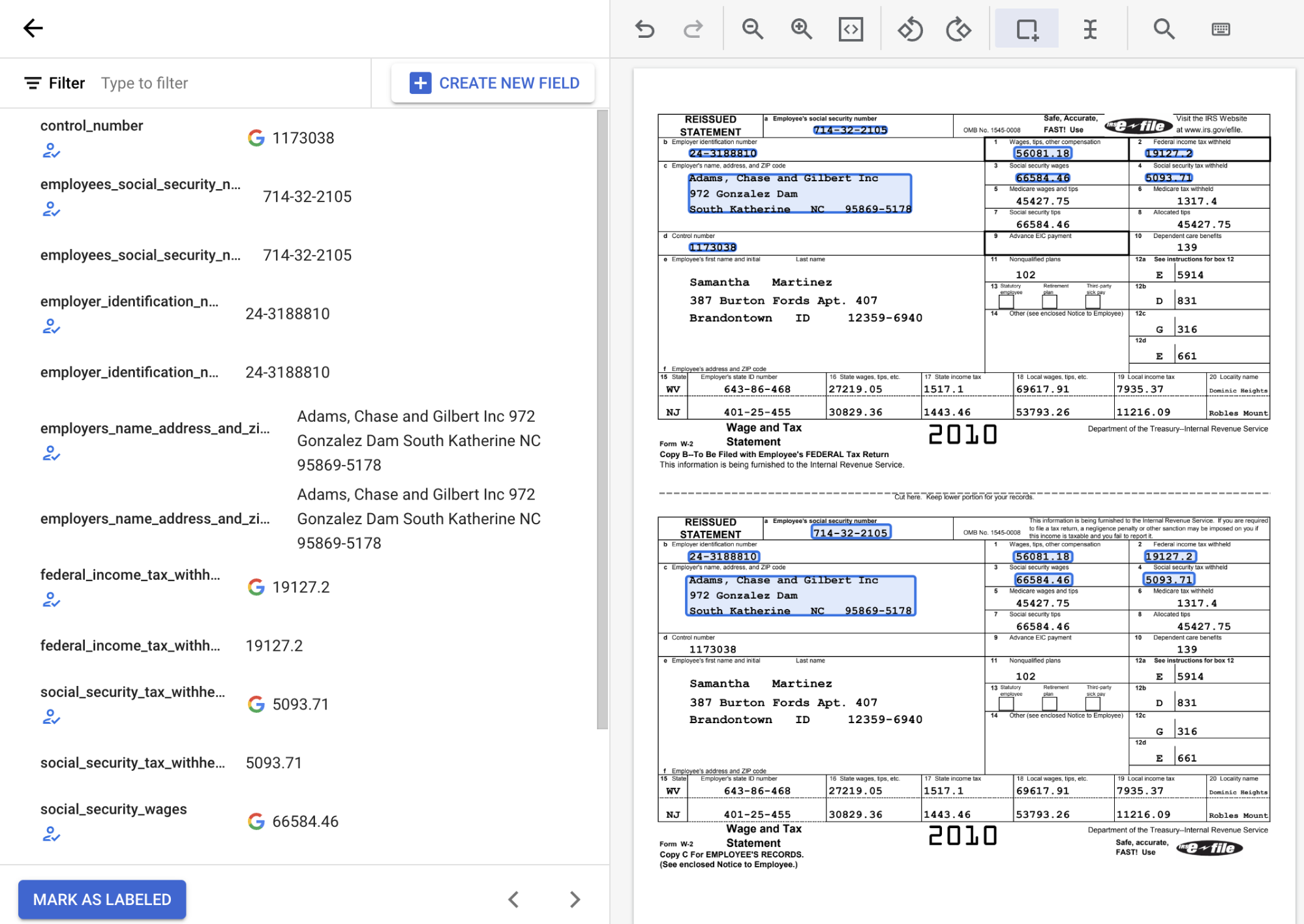
必要に応じて、[
新しいフィールドを作成 ] を選択して、このページからスキーマに新しいフィールドを追加できます。ドキュメントのアノテーションが完成したら、[
ラベル付きとしてマーク ] を選択します。[スタートガイド] タブにリダイレクトされます。[Build] タブを選択します。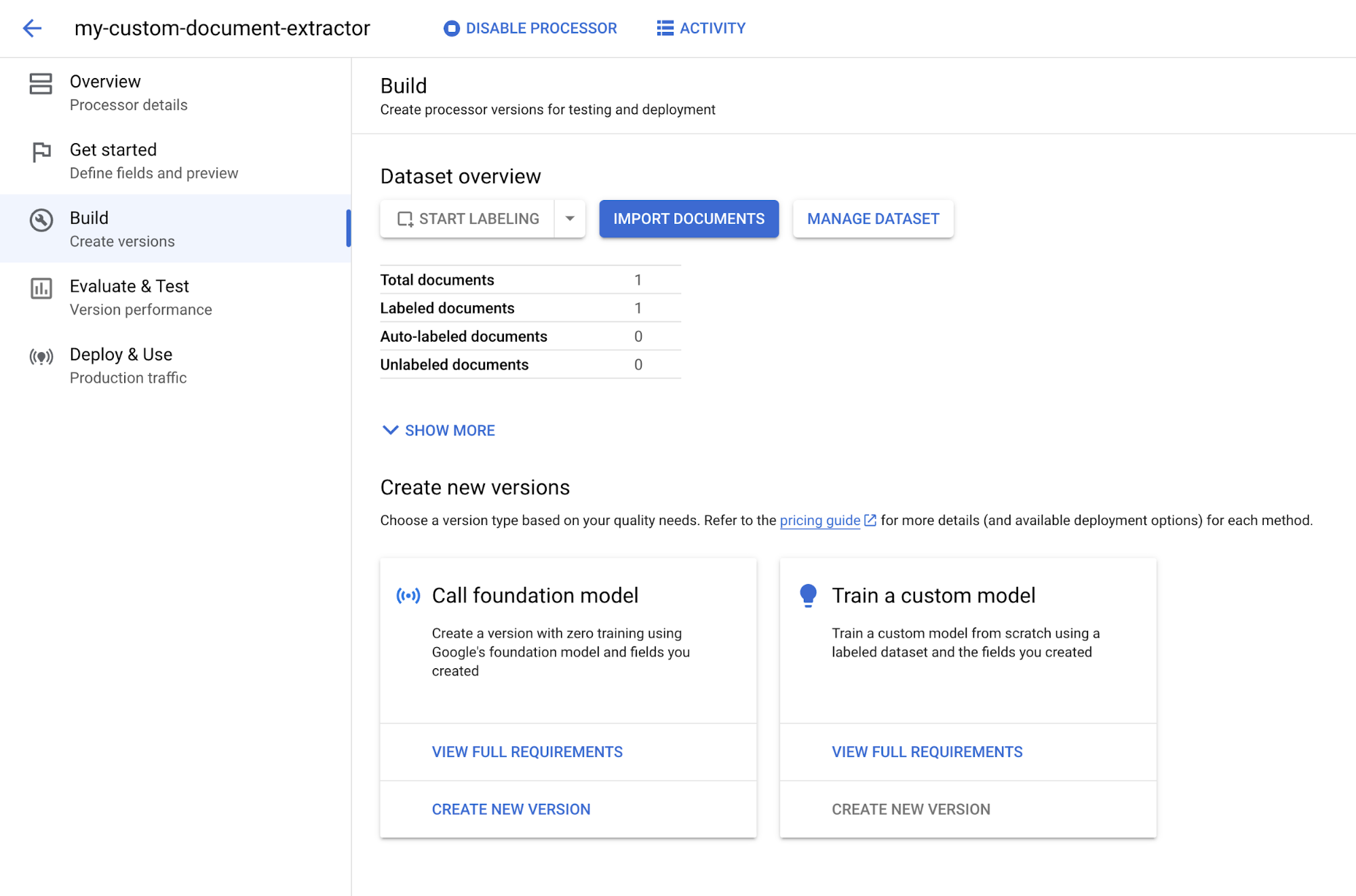
[基盤モデルを呼び出す] で [新しいバージョンを作成] を選択します。
プロセッサ バージョンの名前(
w2-foundation-modelなど)を入力します。[バージョンの作成] を選択します。作成には数分かかります。
省略可: [
デプロイと使用 ] タブを選択します。このページで、利用可能なプロセッサ バージョンと新しいバージョンのデプロイ ステータスを確認できます。[
Build ] ページに移動します。[
ドキュメントのインポート ] を選択します。サイドバーで、[Google Cloud Storage からドキュメントをインポートする] を選択します。
ドキュメントを含むバケット名を入力します。
[データ分割] リストから [自動分割] を選択します。これにより、トレーニング セットが 80%、テストセットが 20% になるようにドキュメントが自動的に分割されます。
[自動ラベル付け] セクションで、[
自動ラベル付けを使用したインポート ] チェックボックスをオンにします。基盤モデル プロセッサのバージョンを選択して、ドキュメントのラベル付けを行います。
[インポート] を選択して、ドキュメントがインポートされるのを待ちます。このページを離れて、後で戻ってくることもできます。
自動でラベル付けされたドキュメントを、トレーニングやテストに使用する前に、確認する必要があります。[
ラベル付けを開始 ] を選択して、自動的にラベル付けされたドキュメントを表示します。提案されたラベルを使用するには、各
アノテーション にポインタを合わせて、チェックマークを選択してラベルが正しいことを確認します。トレーニング用の場合、値がドキュメントのテキストと一致しない場合でも編集しないでください。間違ったテキストが選択されている場合に、境界ボックスのみを変更します。ドキュメントのアノテーションが完成したら、[
ラベル付きとしてマーク ] を選択します。自動的にラベル付けされたドキュメントごとに繰り返します。
[
Build ] ページに移動します。[
ドキュメントのインポート ] を選択します。サイドバーで、[Cloud Storage からドキュメントをインポートする] を選択します。
[ソースパス] にドキュメントを含むパスを入力します。このバケットには、事前にラベル付けされたドキュメントが Document JSON 形式で含まれている必要があります。
[データ分割] リストから [自動分割] を選択します。これにより、トレーニング セットが 80%、テストセットが 20% になるようにドキュメントが自動的に分割されます。[自動ラベル付けを使用したインポート] をオフのままにします。
[インポート] を選択します。インポートには数分かかります。
- [Build] ページから [
データセットの管理 ] コンソールにアクセスし、データセット内のすべてのドキュメントとラベルを表示および編集できます。 データセットの要件については、[カスタムモデルのトレーニング] で [新しいバージョンを作成] または [要件の詳細を見る] を選択します。これは生成 AI モデルではありません。カスタムモデルをベースとしたプロセッサには、各フィールドに少なくとも 10 個のトレーニング インスタンスと 10 個のテスト インスタンスが必要です。
[バージョン名] フィールドに、このプロセッサ バージョンの名前(
w2-custom-modelなど)を入力します。(省略可)[ラベルの統計データを表示] を選択して、ドキュメント ラベルに関する情報を確認します。これにより、対応範囲を判断できます。[閉じる] を選択してトレーニングの設定に戻ります。
[モデル トレーニング方法] で、[モデルベース] を選択します。
[トレーニングを開始] を選択します。トレーニングには数時間かかります。このページを離れて、後で戻ることができます。
省略可: [
デプロイと使用 ] タブを選択します。このページで、利用可能なプロセッサ バージョンと新しいバージョンのトレーニング ステータスを確認できます。トレーニングが完了したら、[
デプロイと使用 ] タブを選択します。デプロイするバージョンの左側にあるチェックボックスをオンにし、[デプロイ] を選択します。
ダイアログ ウィンドウから [デプロイ] を選択します。デプロイには数分かかります。
デプロイされたバージョンを [
デフォルト バージョン ] として設定するか、API でドキュメントを処理するときにバージョン ID を指定できます。[
評価 ] タブを選択して、プロセッサ バージョンをテストします。このページでは、ドキュメント全体の F1 スコア、ドキュメント全体の適合率と再現率、個々のラベルなどの評価指標を表示できます。評価と統計情報について詳しくは、プロセッサを評価するをご覧ください。[
バージョン ] セレクタを選択し、基盤モデルを使用するバージョンを選択します。プロセッサのバージョンを評価するために使用できるように、これまでトレーニングやテストに関与していないドキュメントをダウンロードします。独自のデータを使用している場合は、この目的のために用意されたドキュメントを使用します。
[
テスト ドキュメントをアップロード ] を選択し、ダウンロードしたドキュメントを選択します。[カスタム ドキュメント エクストラクタの分析] ページが開きます。画面出力は、ドキュメントがどの程度適切に抽出されたかを示しています。カスタム トレーニング済みモデルのバージョンを使用して、ドキュメントを再度テストします。
- 処理リクエストの送信のコードサンプルに沿って、オンラインまたはバッチ処理を使用します。
- オンライン処理とバッチ処理でサポートされるページ数については、割り当てと上限をご覧ください。
- レスポンスを処理するにあるカスタム エクストラクタのコードサンプルに沿って、プロセッサから抽出されたエンティティを取得します。
Google Cloud コンソールのナビゲーション メニューで [Document AI] を選択し、[マイプロセッサ] を選択します。
削除するプロセッサと同じ行にある [
その他の操作 ] を選択します。[プロセッサを削除] を選択し、プロセッサ名を入力して、もう一度 [削除] を選択して確定します。
プロセッサの作成
プロセッサ フィールドを定義する
作成したプロセッサの [プロセッサの概要] ページが表示されます。
プロセッサにドキュメントの抽出とラベル付けの開始をさせるフィールドを指定できます。
サンプル ドキュメントをアップロードする
サンプル ドキュメントでテストします。
ラベル表示コンソールにリダイレクトされます。
ドキュメントにラベルを付ける
ドキュメント内のテキストを選択してラベルを適用するプロセスをアノテーションまたはラベル付けと呼びます。
基盤モデルを使用してプロセッサ バージョンをビルドする
1 つのドキュメントにラベルを付けたら、事前トレーニング済みの基盤モデルを使用してプロセッサ バージョンを作成し、エンティティを抽出できます。
生成 AI を使用してドキュメントに自動的にラベルを付ける
基盤モデルは、さまざまなドキュメント タイプのフィールドを正確に抽出できますが、追加のトレーニング データを提供して、特定のドキュメント構造に対するモデルの精度を向上させることもできます。
カスタム エクストラクタは、定義したラベル名と以前のアノテーションを使用して、自動ラベル付けで素早く簡単にドキュメントを大規模にラベル付けすることができます。
事前にラベル付けされたトレーニング ドキュメントをインポートする
省略可: データセットの表示と管理
カスタム モデル ベースのプロセッサをトレーニングする
トレーニングには数時間かかる場合があるため、トレーニングを開始する前に、適切なデータとラベルがプロセッサに設定されていることを確認してください。
プロセッサ バージョンをデプロイする
プロセッサの評価とテストを行う
プロセッサを使用する
カスタム エクストラクタ プロセッサを作成して正常にトレーニングできました。
カスタム トレーニング済みのプロセッサ バージョンは、他のプロセッサ バージョンと同様に管理できます。詳細については、プロセッサ バージョンの管理をご覧ください。
Document AI API を使用するには:
クリーンアップ
このページで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、次の手順を実施します。
不要な Google Cloud 料金が発生しないようにするには、Google Cloud console を使用して、不要なプロセッサやプロジェクトを削除します。
Document AI の学習用に新しいプロジェクトを作成し、そのプロジェクトが不要になった場合は、プロジェクトを削除します。
既存の Google Cloud プロジェクトを使用した場合は、作成したリソースを削除して、アカウントに課金されないようにします。
次のステップ
詳細については、ガイドをご覧ください。