Muitas organizações implementam armazéns de dados na nuvem para armazenar informações confidenciais, de modo a poderem analisar os dados para vários fins empresariais. Este documento descreve como pode implementar a estrutura de controlos principais das capacidades de gestão de dados na nuvem (CDMC), gerida pelo Enterprise Data Management Council, num data warehouse do BigQuery.
A estrutura de controlos principais da CDMC foi publicada principalmente para fornecedores de serviços na nuvem e fornecedores de tecnologia. A estrutura descreve 14 controlos principais que os fornecedores podem implementar para permitir que os respetivos clientes geram e governem eficazmente os dados confidenciais na nuvem. Os controlos foram escritos pelo grupo de trabalho do CDMC, com a participação de mais de 300 profissionais de mais de 100 empresas. Ao escrever a estrutura, o grupo de trabalho do CDMC considerou muitos dos requisitos legais e regulamentares existentes.
Esta arquitetura de referência do BigQuery e do Data Catalog foi avaliada e certificada em conformidade com a estrutura de controlos principais do CDMC como uma solução de nuvem certificada pelo CDMC. A arquitetura de referência usa vários serviços e funcionalidades, bem como bibliotecas públicas, para implementar os principais controlos do CDMC e a automatização recomendada. Google Cloud Este documento explica como pode implementar os controlos principais para ajudar a proteger os dados confidenciais num armazém de dados do BigQuery.
Arquitetura
A seguinte Google Cloud arquitetura de referência está alinhada com as especificações de teste da framework de controlos principais do CDMC v1.1.1. Os números no diagrama representam os controlos principais que são abordados com os serviços Google Cloud .

A arquitetura de referência baseia-se no projeto de armazém de dados seguro, que fornece uma arquitetura que ajuda a proteger um armazém de dados do BigQuery que inclui informações confidenciais. No diagrama anterior, os projetos na parte superior do diagrama (a cinzento) fazem parte do esquema do armazém de dados seguro, e o projeto de administração de dados (a azul) inclui os serviços que são adicionados para cumprir os requisitos da estrutura de controlos principais do CDMC. Para implementar a estrutura de controlos principais do CDMC, a arquitetura expande o projeto de gestão de dados. O projeto de administração de dados oferece controlos como a classificação, a gestão do ciclo de vida e a gestão da qualidade de dados. O projeto também oferece uma forma de auditar a arquitetura e comunicar as conclusões.
Para mais informações sobre como implementar esta arquitetura de referência, consulte a Google Cloud arquitetura de referência do CDMC no GitHub.
Vista geral da estrutura de controlos principais do CDMC
A tabela seguinte resume a framework de controlos principais do CDMC.
| # | Controlo de chaves CDMC | Requisito de controlo do CDMC |
|---|---|---|
| 1 | Conformidade com o controlo de dados | Os exemplos de utilização da gestão de dados na nuvem são definidos e regidos. Todos os recursos de dados que contenham dados confidenciais têm de ser monitorizados para garantir a conformidade com os controlos principais do CDMC, através de métricas e notificações automáticas. |
| 2 | A propriedade dos dados é estabelecida para os dados migrados e gerados na nuvem | O campo Propriedade num catálogo de dados tem de ser preenchido para todos os dados confidenciais ou comunicado de outra forma a um fluxo de trabalho definido. |
| 3 | A obtenção e o consumo de dados são regidos e suportados pela automação | Tem de ser preenchido um registo de origens de dados autorizadas e pontos de aprovisionamento para todos os recursos de dados que contenham dados confidenciais ou que, de outra forma, tenham de ser comunicados a um fluxo de trabalho definido. |
| 4 | A soberania dos dados e a movimentação de dados transfronteiriços são geridas | A soberania dos dados e a circulação transfronteiriça de dados confidenciais têm de ser registadas, auditadas e controladas de acordo com a política definida. |
| 5 | Os catálogos de dados são implementados, usados e interoperáveis | A catalogação tem de ser automatizada para todos os dados no ponto de criação ou carregamento, com consistência em todos os ambientes. |
| 6 | As classificações de dados são definidas e usadas | A classificação tem de ser automatizada para todos os dados no ponto de criação ou carregamento e tem de estar sempre ativada. A classificação é automatizada para o seguinte:
|
| 7 | As autorizações de dados são geridas, aplicadas e monitorizadas | Este controlo requer o seguinte:
|
| 8 | O acesso, a utilização e os resultados éticos dos dados são geridos | A finalidade do consumo de dados tem de ser fornecida para todos os contratos de partilha de dados que envolvam dados confidenciais. A finalidade tem de especificar o tipo de dados necessários e, para organizações globais, o âmbito do país ou da entidade legal. |
| 9 | Os dados estão protegidos e os controlos são comprovados | Este controlo requer o seguinte:
|
| 10 | Uma framework de privacidade de dados está definida e operacional | As avaliações do impacto da proteção de dados (AIPDs) têm de ser acionadas automaticamente para todos os dados pessoais de acordo com a respetiva jurisdição. |
| 11 | O ciclo de vida dos dados é planeado e gerido | A retenção, o arquivo e a remoção de dados têm de ser geridos de acordo com um cronograma de retenção definido. |
| 12 | A qualidade de dados é gerida | A medição da qualidade de dados tem de estar ativada para dados confidenciais com métricas distribuídas quando disponíveis. |
| 13 | Os princípios de gestão de custos são estabelecidos e aplicados | Os princípios de design técnico são estabelecidos e aplicados. As métricas de custo diretamente associadas à utilização, ao armazenamento e à movimentação de dados têm de estar disponíveis no catálogo. |
| 14 | A proveniência e a linhagem dos dados são compreendidas | As informações de linhagem de dados têm de estar disponíveis para todos os dados confidenciais. Estas informações têm de incluir, no mínimo, a origem a partir da qual os dados foram carregados ou em que foram criados num ambiente de nuvem. |
1. Conformidade com o controlo de dados
Este controlo requer que possa validar se todos os dados confidenciais são monitorizados para conformidade com esta framework através de métricas.
A arquitetura usa métricas que mostram a extensão em que cada um dos controlos principais está operacional. A arquitetura também inclui painéis de controlo que indicam quando as métricas não atingem os limites definidos.
A arquitetura inclui detetores que publicam conclusões e recomendações de correção quando os recursos de dados não cumprem um controlo fundamental. Estas conclusões e recomendações estão no formato JSON e são publicadas num tópico do Pub/Sub para distribuição aos subscritores. Pode integrar o seu serviço de assistência técnica interno ou as ferramentas de gestão de serviços com o tópico Pub/Sub para que os incidentes sejam criados automaticamente no seu sistema de emissão de pedidos.
A arquitetura usa o Dataflow para criar um exemplo de subscritor dos eventos de resultados, que são depois armazenados numa instância do BigQuery que é executada no projeto de administração de dados. Usando várias vistas fornecidas, pode consultar os dados através do BigQuery Studio na Google Cloud consola. Também pode criar relatórios através do Looker Studio ou de outras ferramentas de Business Intelligence compatíveis com o BigQuery. Os relatórios que pode ver incluem o seguinte:
- Resumo das conclusões da última execução
- Detalhes dos resultados da última execução
- Metadados da última execução
- Última execução de recursos de dados no âmbito
- Estatísticas do conjunto de dados da última execução
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- O Pub/Sub publica as conclusões.
- O Dataflow carrega as conclusões numa instância do BigQuery.
- O BigQuery armazena os dados das conclusões e fornece vistas de resumo.
- O Looker Studio fornece painéis de controlo e relatórios.
A captura de ecrã seguinte mostra um exemplo de um painel de controlo de resumo do Looker Studio.
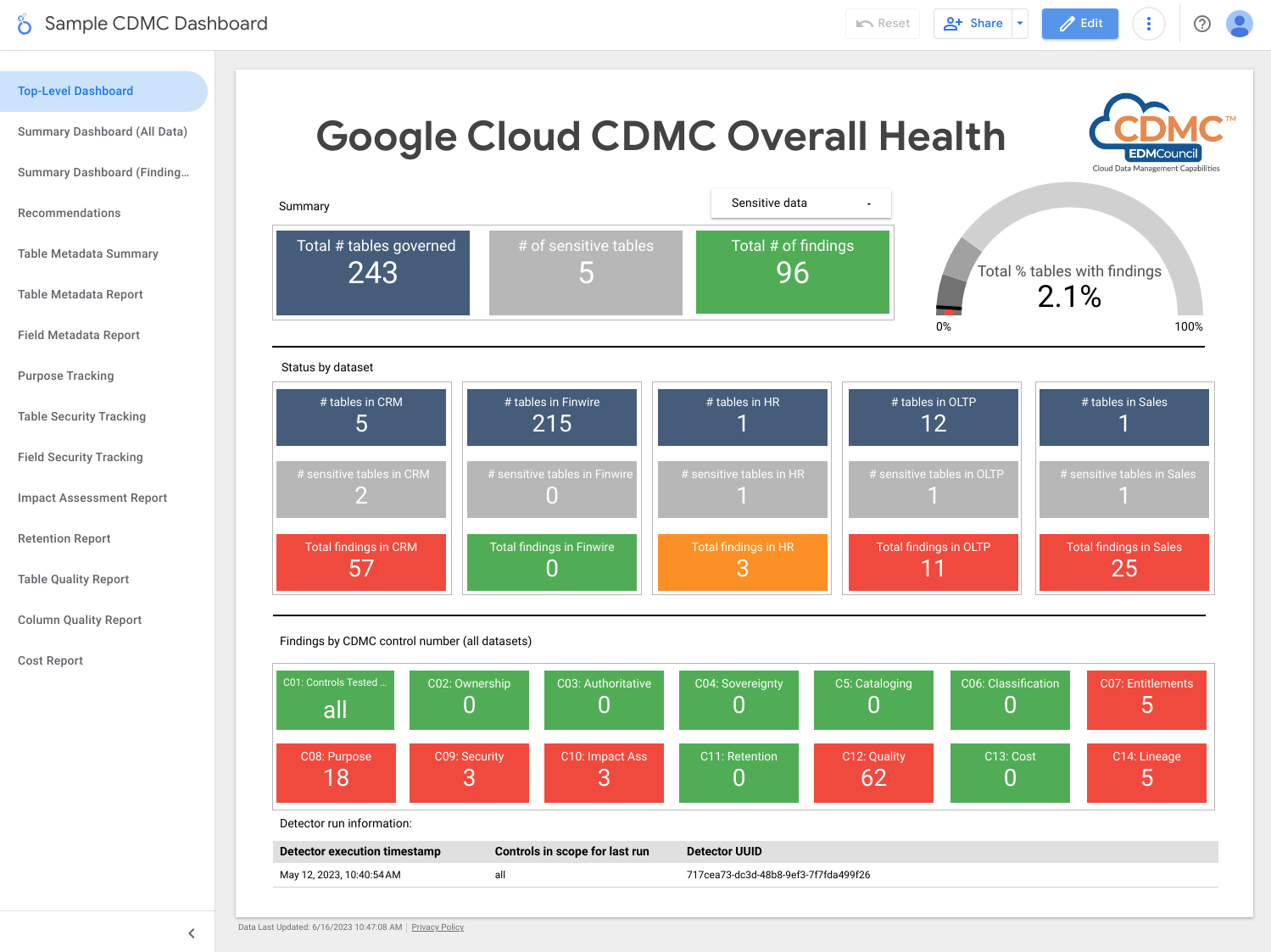
A captura de ecrã seguinte mostra uma vista de exemplo das conclusões por recurso de dados.
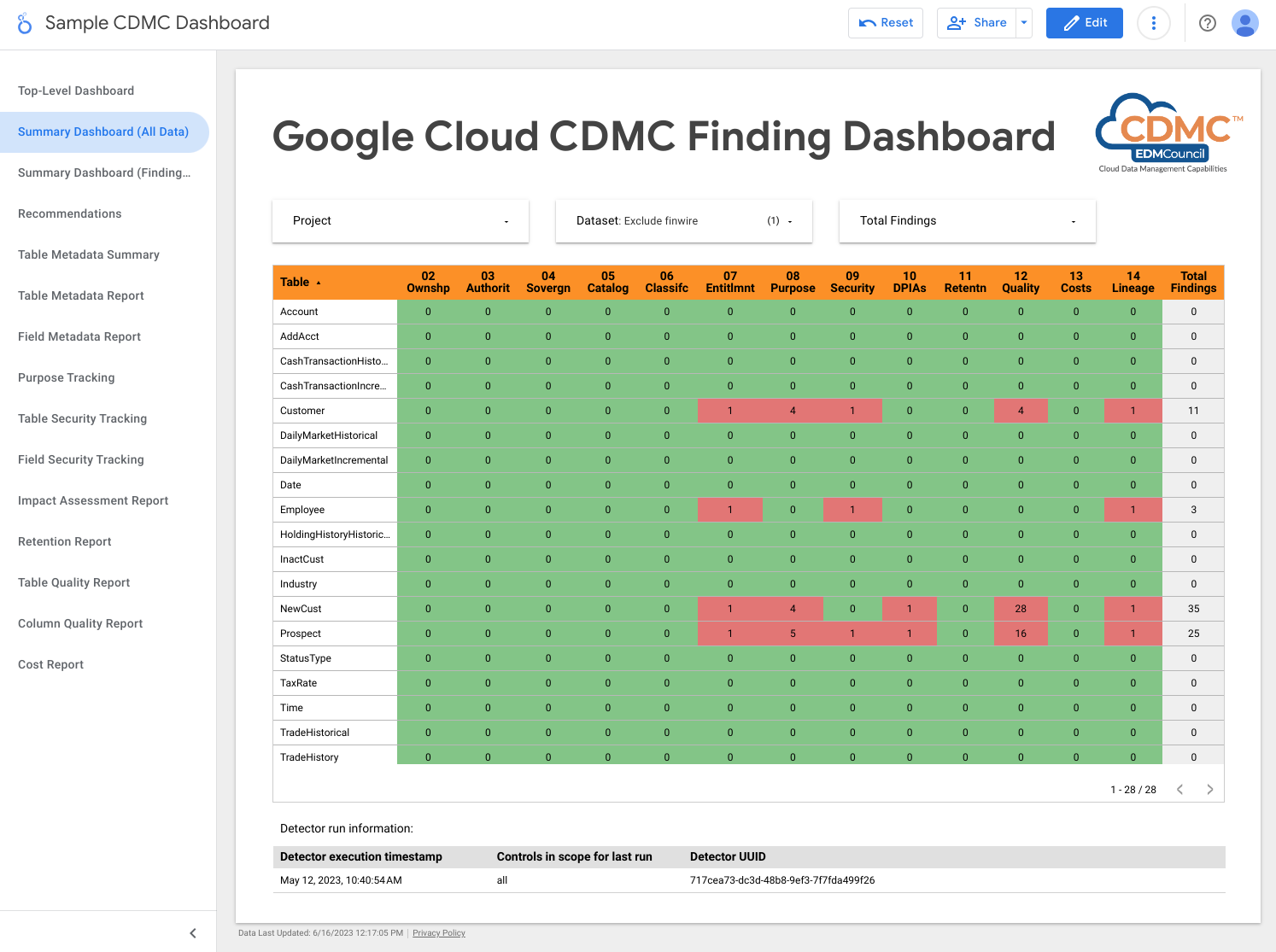
2. A propriedade dos dados é estabelecida para os dados migrados e gerados na nuvem
Para cumprir os requisitos deste controlo, a arquitetura revê automaticamente os dados no data warehouse do BigQuery e adiciona etiquetas de classificação de dados que indicam que os proprietários são identificados para todos os dados confidenciais.
O catálogo de dados processa dois tipos de metadados: metadados técnicos e metadados empresariais. Para um determinado projeto, o Data Catalog cataloga automaticamente conjuntos de dados, tabelas e vistas do BigQuery e preenche os metadados técnicos. A sincronização entre o catálogo e os recursos de dados é mantida quase em tempo real.
A arquitetura usa o motor de etiquetas para adicionar as seguintes etiquetas de metadados da empresa a um modelo de etiqueta CDMC controls no catálogo de dados:
is_sensitive: se o recurso de dados contém dados confidenciais (consulte o Controlo 6 para a classificação de dados)owner_name: o proprietário dos dadosowner_email: o endereço de email do proprietário
As etiquetas são preenchidas com valores predefinidos armazenados numa tabela do BigQuery de referência no projeto de administração de dados.
Por predefinição, a arquitetura define os metadados de propriedade ao nível da tabela, mas pode alterar a arquitetura para que os metadados sejam definidos ao nível da coluna. Para mais informações, consulte o artigo Etiquetas e modelos de etiquetas do catálogo de dados.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- Dois armazéns de dados do BigQuery: um armazena os dados confidenciais e o outro armazena as predefinições para a propriedade de recursos de dados.
- O catálogo de dados armazena metadados de propriedade através de modelos de etiquetas e etiquetas.
- Duas instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
- O Pub/Sub publica as conclusões.
Para detetar problemas relacionados com este controlo, a arquitetura verifica se os dados confidenciais têm uma etiqueta de nome de proprietário atribuída.
3. A obtenção e o consumo de dados são regidos e suportados pela automatização
Este controlo requer a classificação dos recursos de dados e um registo de dados de
origens autorizadas e distribuidores autorizados. A arquitetura usa o Data Catalog para adicionar a etiqueta is_authoritative ao modelo de etiqueta CDMC
controls. Esta etiqueta define se o recurso de dados é
autoritário.
O Data Catalog cataloga conjuntos de dados, tabelas e vistas do BigQuery com metadados técnicos e metadados empresariais. Os metadados técnicos são preenchidos automaticamente e incluem o URL do recurso, que é a localização do ponto de aprovisionamento. Os metadados da empresa são definidos no ficheiro de configuração do motor de etiquetas e incluem a etiqueta is_authoritative.
Durante a próxima execução agendada, o Tag Engine preenche a etiqueta is_authoritative no modelo de etiqueta CDMC controls com os valores predefinidos armazenados numa tabela de referência no BigQuery.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- Dois armazéns de dados do BigQuery: um armazena os dados confidenciais e o outro armazena os predefinições da origem autorizada do recurso de dados.
- O catálogo de dados armazena metadados de origem fidedignos através de etiquetas.
- Duas instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
- O Pub/Sub publica as conclusões.
Para detetar problemas relacionados com este controlo, a arquitetura verifica se os dados confidenciais têm a etiqueta de origem autorizada atribuída.
4. A soberania dos dados e a movimentação de dados transfronteiriços são geridas
Este controlo requer que a arquitetura inspecione o registo de dados para verificar os requisitos de armazenamento específicos da região e aplique as regras de utilização. Um relatório descreve a localização geográfica dos recursos de dados.
A arquitetura usa o Data Catalog para adicionar a etiqueta approved_storage_location ao modelo de etiqueta CDMC controls. Esta etiqueta define a localização geográfica na qual o recurso de dados tem autorização para ser armazenado.
A localização real dos dados é armazenada como metadados técnicos nos detalhes da tabela do BigQuery. O BigQuery não permite que os administradores alterem a localização de um conjunto de dados ou de uma tabela. Em alternativa, se os administradores quiserem alterar a localização dos dados, têm de copiar o conjunto de dados.
A
restrição do serviço de políticas da organização de localizações de recursos
define as Google Cloud regiões nas quais pode armazenar dados. Por predefinição,
a arquitetura define a restrição no projeto de dados confidenciais, mas
pode definir a restrição ao nível da organização ou da pasta, se preferir. O Tag
Engine replica as localizações permitidas para o modelo de etiqueta
do catálogo de dados e armazena a localização na etiqueta approved_storage_location. Se ativar o nível Premium do Security Command Center e alguém atualizar a restrição do serviço de políticas da organização das localizações de recursos, o Security Command Center gera resultados de vulnerabilidades para recursos armazenados fora da política atualizada.
O Gestor de contexto de acesso define a localização geográfica em que os utilizadores têm de estar antes de poderem aceder a recursos de dados. Através dos níveis de acesso, pode especificar as regiões de onde os pedidos podem ser provenientes. Em seguida, adicione a política de acesso ao perímetro dos VPC Service Controls para o projeto de dados confidenciais.
Para acompanhar o movimento de dados, o BigQuery mantém uma trilha de auditoria completa para cada tarefa e consulta em cada conjunto de dados. A trilha de auditoria é armazenada na vista BigQuery Information Schema Jobs.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- O serviço de políticas da organização define e aplica a restrição de localizações de recursos.
- O Access Context Manager define as localizações a partir das quais os utilizadores podem aceder aos dados.
- Dois armazéns de dados do BigQuery: um armazena os dados confidenciais e o outro aloja uma função remota que é usada para inspecionar a política de localização.
- O catálogo de dados armazena localizações de armazenamento aprovadas como etiquetas.
- Duas instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
- O Pub/Sub publica as conclusões.
- O Cloud Logging escreve os registos de auditoria.
- O Security Command Center comunica todas as conclusões relacionadas com a localização de recursos ou o acesso aos dados.
Para detetar problemas relacionados com este controlo, a arquitetura inclui uma descoberta que indica se a etiqueta de localizações aprovadas inclui a localização dos dados confidenciais.
5. Os catálogos de dados são implementados, usados e interoperáveis
Este controlo requer a existência de um catálogo de dados e que a arquitetura possa analisar recursos novos e atualizados para adicionar metadados conforme necessário.
Para cumprir os requisitos deste controlo, a arquitetura usa o Data Catalog. O Data Catalog regista automaticamente Google Cloud recursos, incluindo conjuntos de dados, tabelas e vistas do BigQuery. Quando cria uma nova tabela no BigQuery, o Data Catalog regista automaticamente os metadados técnicos e o esquema da nova tabela. Quando atualiza uma tabela no BigQuery, o Data Catalog atualiza as respetivas entradas quase instantaneamente.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- Dois armazéns de dados do BigQuery: um armazena os dados confidenciais e o outro armazena os dados não confidenciais.
- O Data Catalog armazena os metadados técnicos das tabelas e dos campos.
Por predefinição, nesta arquitetura, o Data Catalog armazena metadados técnicos do BigQuery. Se necessário, pode integrar o catálogo de dados com outras origens de dados.
6. As classificações de dados são definidas e usadas
Esta avaliação requer que os dados possam ser classificados com base na respetiva sensibilidade, como se são PII, identificam clientes ou cumprem alguma outra norma definida pela sua organização. Para cumprir os requisitos deste controlo, a arquitetura cria um relatório dos recursos de dados e da respetiva sensibilidade. Pode usar este relatório para verificar se as definições de sensibilidade estão corretas. Além disso, cada novo recurso de dados ou alteração a um recurso de dados existente resulta numa atualização do catálogo de dados.
As classificações são armazenadas na etiqueta sensitive_category no modelo de etiqueta do catálogo de dados ao nível da tabela e da coluna. Uma tabela de referência de classificação permite-lhe classificar os tipos de informações (infoTypes) de proteção de dados confidenciais disponíveis, com classificações mais elevadas para conteúdo mais sensível.
Para cumprir os requisitos deste controlo, a arquitetura usa o Sensitive Data Protection, o Data Catalog e o Tag Engine para adicionar as seguintes etiquetas a colunas confidenciais em tabelas do BigQuery:
is_sensitive: se o recurso de dados contém informações confidenciaissensitive_category: a categoria dos dados; uma das seguintes:- Informações de identificação pessoal confidenciais
- Informações de identificação pessoal
- Informações pessoais confidenciais
- Informações pessoais
- Informações públicas
Pode alterar as categorias de dados para cumprir os seus requisitos. Por exemplo, pode adicionar a classificação de informações não públicas relevantes (MNPI).
Depois de a proteção de dados confidenciais inspecionar os dados, o motor de etiquetas lê as tabelas DLP results por recurso para compilar as conclusões. Se uma tabela contiver colunas com um ou mais infoTypes confidenciais, o infoType mais notável é determinado e as colunas confidenciais e a tabela inteira são etiquetadas como a categoria com a classificação mais elevada. O motor de etiquetas também atribui uma etiqueta de política correspondente à coluna e atribui a etiqueta booleana is_sensitive à tabela.
Pode usar o Cloud Scheduler para automatizar a inspeção da proteção de dados confidenciais.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- Quatro armazéns de dados do BigQuery armazenam as seguintes informações:
- Dados confidenciais
- Informações sobre os resultados da Proteção de dados confidenciais
- Dados de referência da classificação de dados
- Informações de exportação de etiquetas
- O catálogo de dados armazena as etiquetas de classificação.
- A Proteção de dados confidenciais inspeciona os recursos quanto a infoTypes confidenciais.
- O Compute Engine executa o script Inspect Datasets, que aciona uma tarefa do serviço de dados protegidos para cada conjunto de dados do BigQuery.
- Duas instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
- O Pub/Sub publica as conclusões.
Para detetar problemas relacionados com este controlo, a arquitetura inclui as seguintes conclusões:
- Se os dados confidenciais têm atribuída uma etiqueta de categoria sensível.
- Se os dados confidenciais têm atribuída uma etiqueta de tipo de sensibilidade ao nível da coluna.
7. As autorizações de dados são geridas, aplicadas e monitorizadas
Por predefinição, apenas os criadores e os proprietários têm atribuições e acesso a dados confidenciais. Além disso, este controlo requer que a arquitetura monitorize todo o acesso a dados confidenciais.
Para cumprir os requisitos deste controlo, a arquitetura usa a taxonomia de etiquetas de políticas no BigQuery para controlar o acesso a colunas que contêm dados confidenciais em tabelas do BigQuery.cdmc
sensitive data classification A taxonomia inclui as seguintes etiquetas de políticas:
- Informações de identificação pessoal confidenciais
- Informações de identificação pessoal
- Informações pessoais confidenciais
- Informações pessoais
As etiquetas de políticas permitem-lhe controlar quem pode ver colunas confidenciais em tabelas do BigQuery. A arquitetura mapeia estas etiquetas de políticas para classificações de sensibilidade que foram derivadas de infoTypes de proteção de dados confidenciais. Por exemplo, a etiqueta da sensitive_personal_identifiable_informationpolítica
e a categoria sensível são mapeadas para infoTypes, como AGE, DATE_OF_BIRTH, PHONE_NUMBER e EMAIL_ADDRESS.
A arquitetura usa a gestão de identidade e de acesso (IAM) para gerir os grupos, os utilizadores e as contas de serviço que requerem acesso aos dados. As autorizações do IAM são concedidas a um determinado recurso para acesso ao nível da tabela. Além disso, o acesso ao nível da coluna com base em etiquetas de políticas permite um acesso detalhado a recursos de dados confidenciais. Por predefinição, os utilizadores não têm acesso a colunas que tenham etiquetas de políticas definidas.
Para ajudar a garantir que apenas os utilizadores autenticados podem aceder aos dados, o Google Cloud usa o Cloud Identity, que pode federar com os seus fornecedores de identidade existentes para autenticar os utilizadores.
Este controlo também requer que a arquitetura verifique regularmente os recursos de dados que não têm autorizações definidas. O detetor, que é gerido pelo Cloud Scheduler, verifica os seguintes cenários:
- Um recurso de dados inclui uma categoria sensível, mas não existe uma etiqueta de política relacionada.
- Uma categoria não corresponde à etiqueta de política.
Quando estes cenários ocorrem, o detetor gera resultados que são publicados pelo Pub/Sub e, em seguida, são escritos na tabela events no BigQuery pelo Dataflow. Em seguida, pode distribuir as
conclusões à sua ferramenta de correção, conforme descrito no
1. Conformidade com o controlo de dados.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- Um armazém de dados do BigQuery armazena os dados confidenciais e as associações de etiquetas de políticas para controlos de acesso detalhados.
- O IAM gere o acesso.
- O catálogo de dados armazena as etiquetas ao nível da tabela e ao nível da coluna para a categoria sensível.
- Duas instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
Para detetar problemas relacionados com este controlo, a arquitetura verifica se os dados confidenciais têm uma etiqueta de política correspondente.
8. O acesso, a utilização e os resultados éticos dos dados são geridos
Este controlo requer que a arquitetura armazene acordos de partilha de dados do fornecedor de dados e dos consumidores de dados, incluindo uma lista de finalidades de consumo aprovadas. O objetivo de consumo dos dados confidenciais é, em seguida, mapeado para os direitos armazenados no BigQuery através de etiquetas de consulta.
Quando um consumidor consulta dados confidenciais no BigQuery, tem de especificar uma finalidade válida que corresponda ao respetivo direito (por exemplo, SET @@query_label = “use:3”;).
A arquitetura usa o Data Catalog para adicionar as seguintes etiquetas ao modelo de etiqueta CDMC controls. Estas etiquetas representam o contrato de partilha de dados com o fornecedor de dados:
approved_use: a utilização ou os utilizadores aprovados do recurso de dadossharing_scope_geography: a lista de localizações geográficas nas quais o recurso de dados pode ser partilhadosharing_scope_legal_entity: a lista de entidades acordadas que podem partilhar o recurso de dados
Um armazém de dados do BigQuery separado inclui o conjunto de dados entitlement_management com as seguintes tabelas:
provider_agreement: o contrato de partilha de dados com o fornecedor de dados, incluindo a entidade legal acordada e o âmbito geográfico. Estes dados são os predefinidos para as etiquetasshared_scope_geographyesharing_scope_legal_entity.consumer_agreement: o contrato de partilha de dados com o consumidor de dados, incluindo a entidade legal acordada e o âmbito geográfico. Cada contrato está associado a uma associação do IAM para o recurso de dados.use_purpose: a finalidade do consumo, como a descrição da utilização e as operações permitidas para o recurso de dadosdata_asset: informações sobre o recurso de dados, como o nome do recurso e detalhes sobre o proprietário dos dados.
Para auditar os contratos de partilha de dados, o BigQuery mantém uma trilha de auditoria completa para cada tarefa e consulta em relação a cada conjunto de dados. A trilha de auditoria é armazenada na vista Information Schema Jobs do BigQuery. Depois de associar uma etiqueta de consulta a uma sessão e executar consultas na sessão, pode recolher registos de auditoria para consultas com essa etiqueta de consulta. Para mais informações, consulte a referência do registo de auditoria do BigQuery.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- Dois armazéns de dados do BigQuery: um armazena os dados confidenciais e o outro armazena os dados de elegibilidade, que incluem os contratos de partilha de dados do fornecedor e do consumidor, bem como a finalidade de utilização aprovada.
- O catálogo de dados armazena as informações do contrato de partilha de dados do fornecedor como etiquetas.
- Duas instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
- O Pub/Sub publica as conclusões.
Para detetar problemas relacionados com este controlo, a arquitetura inclui as seguintes conclusões:
- Se existe uma entrada para um recurso de dados no conjunto de dados
entitlement_management. - Se uma operação é realizada numa tabela sensível com um exemplo de utilização expirado (por exemplo, o
valid_until_datenoconsumer_agreement tablejá passou). - Se uma operação é realizada numa tabela sensível com uma chave de etiqueta incorreta.
- Se uma operação é realizada numa tabela sensível com um valor de etiqueta de exemplo de utilização em branco ou não aprovado.
- Se uma tabela sensível é consultada com um método de operação não aprovado (por exemplo,
SELECTouINSERT). - Se a finalidade registada que o consumidor especificou ao consultar os dados confidenciais corresponde ao contrato de partilha de dados.
9. Os dados estão protegidos e os controlos são comprovados
Este controlo requer a implementação da encriptação de dados e da desidentificação para ajudar a proteger os dados confidenciais e fornecer um registo destes controlos.
Esta arquitetura baseia-se na segurança predefinida da Google, que inclui a encriptação em repouso. Além disso, a arquitetura permite-lhe gerir as suas próprias chaves através de chaves de encriptação geridas pelo cliente (CMEK). O Cloud KMS permite-lhe encriptar os seus dados com chaves de encriptação suportadas por software ou módulos de segurança de hardware (HSMs) validados ao nível 3 da FIPS 140-2.
A arquitetura usa a ocultação dinâmica de dados ao nível da coluna configurada através de etiquetas de políticas e armazena dados confidenciais num perímetro dos VPC Service Controls separado. Também pode adicionar a desidentificação ao nível da aplicação, que pode implementar no local ou como parte do pipeline de carregamento de dados.
Por predefinição, a arquitetura implementa a encriptação CMEK com HSMs, mas também suporta o Cloud External Key Manager (Cloud EKM).
A tabela seguinte descreve a política de segurança de exemplo que a arquitetura implementa para a região us-central1. Pode adaptar a política para cumprir os seus requisitos, inclusive adicionando políticas diferentes para diferentes regiões.
| Confidencialidade dos dados | Método de encriptação predefinido | Outros métodos de encriptação permitidos | Método de anonimização predefinido | Outros métodos de desidentificação permitidos |
|---|---|---|---|---|
| Informações públicas | Encriptação predefinida | Qualquer | Nenhum | Qualquer |
| Informações de identificação pessoal confidenciais | CMEK com HSM | EKM | Anular | Hash SHA-256 ou valor de ocultação predefinido |
| Informações de identificação pessoal | CMEK com HSM | EKM | Hash SHA-256 | Anule ou predefina o valor de ocultação |
| Informações pessoais confidenciais | CMEK com HSM | EKM | Valor de ocultação predefinido | Hash SHA-256 ou anulação |
| Informações pessoais | CMEK com HSM | EKM | Valor de ocultação predefinido | Hash SHA-256 ou anulação |
A arquitetura usa o Data Catalog para adicionar a etiqueta encryption_method
ao modelo de etiqueta CDMC controls ao nível da tabela. O elemento encryption_method
define o método de encriptação usado pelo recurso de dados.
Além disso, a arquitetura cria uma etiqueta security policy template para identificar o método de anonimização aplicado a um campo específico. A arquitetura usa o platform_deid_method, que é aplicado através da ocultação de dados dinâmica. Pode adicionar o app_deid_method e preenchê-lo através dos pipelines de carregamento de dados do Dataflow e do Sensitive Data Protection incluídos no esquema do data warehouse seguro.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- Duas instâncias opcionais do Dataflow, uma que realiza a desidentificação ao nível da aplicação e a outra que realiza a reidentificação.
- Três armazéns de dados do BigQuery: um armazena os dados confidenciais, um armazena os dados não confidenciais e o terceiro armazena a política de segurança.
- O catálogo de dados armazena os modelos de etiquetas de encriptação e desidentificação.
- Duas instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
- Resultados publicados no Pub/Sub.
Para detetar problemas relacionados com este controlo, a arquitetura inclui as seguintes conclusões:
- O valor da etiqueta do método de encriptação não corresponde aos métodos de encriptação permitidos para a sensibilidade e a localização especificadas.
- Uma tabela contém colunas confidenciais, mas a etiqueta do modelo de política de segurança contém um método de desidentificação ao nível da plataforma inválido.
- Uma tabela contém colunas confidenciais, mas a etiqueta do modelo de política de segurança está em falta.
10. Uma framework de privacidade de dados está definida e operacional
Este controlo requer que a arquitetura inspecione o catálogo de dados e as classificações para determinar se tem de criar um relatório de avaliação do impacto da proteção de dados (AIPD) ou um relatório de avaliação do impacto na privacidade (AIP). As avaliações de privacidade variam significativamente entre geografias e reguladores. Para determinar se é necessária uma avaliação de impacto, a arquitetura tem de considerar a residência dos dados e a residência do titular dos dados.
A arquitetura usa o Data Catalog para adicionar as seguintes etiquetas ao modelo de etiqueta Impact assessment:
subject_locations: a localização dos indivíduos referidos pelos dados neste recurso.is_dpia: se foi concluída uma avaliação do impacto da privacidade dos dados (AIPD) para este recurso.is_pia: se foi concluída uma avaliação do impacto na privacidade (PIA) para este recurso.impact_assessment_reports: link externo para onde o relatório de avaliação de impacto está armazenado.most_recent_assessment: a data da avaliação de impacto mais recente.oldest_assessment: a data da primeira avaliação de impacto.
O motor de etiquetas adiciona estas etiquetas a cada recurso de dados confidenciais, conforme definido pelo controlo 6. O detetor valida estas etiquetas com base numa tabela de políticas no BigQuery, que inclui combinações válidas de residência de dados, localização do titular, sensibilidade dos dados (por exemplo, se são PII) e que tipo de avaliação de impacto (PIA ou DPIA) é necessário.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- Quatro armazéns de dados do BigQuery armazenam as seguintes informações:
- Dados confidenciais
- Dados não confidenciais
- Política de avaliação de impacto e datas/horas das concessões
- Exportações de etiquetas usadas para o painel de controlo
- O catálogo de dados armazena os detalhes da avaliação de impacto em etiquetas nos modelos de etiquetas.
- Duas instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
- O Pub/Sub publica as conclusões.
Para detetar problemas relacionados com este controlo, a arquitetura inclui as seguintes conclusões:
- Existem dados confidenciais sem um modelo de avaliação de impacto.
- Existem dados confidenciais sem uma associação a um relatório de DPIA ou PIA.
- As etiquetas não cumprem os requisitos na tabela de políticas.
- A avaliação de impacto é mais antiga do que a autorização mais recentemente aprovada para o recurso de dados na tabela de contrato do consumidor.
11. O ciclo de vida dos dados é planeado e gerido
Este controlo requer a capacidade de inspecionar todos os recursos de dados para determinar que existe uma política de ciclo de vida dos dados e que esta é cumprida.
A arquitetura usa o Data Catalog para adicionar as seguintes etiquetas ao modelo de etiqueta CDMC controls:
retention_period: o tempo, em dias, para reter a tabelaexpiration_action: se deve arquivar ou remover completamente a tabela quando o período de retenção terminar
Por predefinição, a arquitetura usa o seguinte período de retenção e ação de expiração:
| Categoria de dados | Período de retenção, em dias | Ação de expiração |
|---|---|---|
| Informações de identificação pessoal confidenciais | 60 | Eliminar |
| Informações de identificação pessoal | 90 | Arquivar |
| Informações pessoais confidenciais | 180 | Arquivar |
| Informações pessoais | 180 | Arquivar |
O Record Manager, um recurso de código aberto para o BigQuery, automatiza a eliminação e o arquivo de tabelas do BigQuery com base nos valores das etiquetas acima e num ficheiro de configuração. O procedimento de limpeza define uma data de validade numa tabela e cria uma tabela de instantâneo com um tempo de validade definido na configuração do Gestor de registos. Por predefinição, o tempo de expiração é de 30 dias. Durante o período de eliminação temporária, pode recuperar a tabela. O procedimento de arquivo cria uma tabela externa para cada tabela do BigQuery que ultrapassa o respetivo período de retenção. A tabela é armazenada no Cloud Storage no formato Parquet e atualizada para uma tabela BigLake, o que permite etiquetar o ficheiro externo com metadados no Data Catalog.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- Dois armazéns de dados do BigQuery: um armazena os dados confidenciais e o outro armazena a política de retenção de dados.
- Duas instâncias do Cloud Storage, uma que oferece armazenamento de arquivo e a outra que armazena registos.
- O catálogo de dados armazena o período de retenção e a ação nos modelos de etiquetas e nas etiquetas.
- Duas instâncias do Cloud Run: uma executa o Record Manager e a outra implementa os detetores.
- Três instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
- Outra instância executa o Record Manager, que automatiza a limpeza e o arquivo de tabelas do BigQuery.
- O Pub/Sub publica as conclusões.
Para detetar problemas relacionados com este controlo, a arquitetura inclui as seguintes conclusões:
- Para recursos sensíveis, certifique-se de que o método de retenção está alinhado com a política da localização do recurso.
- Para recursos sensíveis, certifique-se de que o período de retenção está alinhado com a política da localização do recurso.
12. A qualidade de dados é gerida
Este controlo requer a capacidade de medir a qualidade dos dados com base na criação de perfis de dados ou em métricas definidas pelo utilizador.
A arquitetura inclui a capacidade de definir regras de qualidade dos dados para um valor individual ou agregado e atribuir limites a uma coluna de tabela específica. Inclui modelos de etiquetas para garantir a correção e a integridade. O catálogo de dados adiciona as seguintes etiquetas a cada modelo de etiqueta:
column_name: o nome da coluna à qual a métrica se aplicametric: o nome da métrica ou da regra de qualidaderows_validated: o número de linhas validadassuccess_percentage: a percentagem de valores que satisfazem esta métricaacceptable_threshold: o limite aceitável para esta métricameets_threshold: indica se o índice de qualidade (o valorsuccess_percentage) cumpre o limite aceitávelmost_recent_run: a hora mais recente em que a métrica ou a regra de qualidade foi executada
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- Três armazéns de dados do BigQuery: um armazena os dados confidenciais, um armazena os dados não confidenciais e o terceiro armazena as métricas das regras de qualidade.
- O catálogo de dados armazena os resultados da qualidade de dados em modelos de etiquetas e etiquetas.
- O Cloud Scheduler define quando o Cloud Data Quality Engine é executado.
- Três instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
- A terceira instância executa o Cloud Data Quality Engine.
- O motor de qualidade de dados da nuvem define regras de qualidade de dados e agenda verificações de qualidade de dados para tabelas e colunas.
- O Pub/Sub publica as conclusões.
Um painel de controlo do Looker Studio apresenta os relatórios de qualidade de dados para os níveis de tabela e de coluna.
Para detetar problemas relacionados com este controlo, a arquitetura inclui as seguintes conclusões:
- Os dados são sensíveis, mas não são aplicados modelos de etiquetas de qualidade de dados (correção e integridade).
- Os dados são sensíveis, mas a etiqueta de qualidade de dados não é aplicada à coluna sensível.
- Os dados são confidenciais, mas os resultados da qualidade de dados não estão dentro do limite definido na regra.
- Os dados não são confidenciais e os resultados da qualidade de dados não estão dentro do limite definido pela regra.
Em alternativa ao motor de qualidade de dados do Google Cloud, pode configurar tarefas de qualidade de dados do catálogo universal do Dataplex.
13. Os princípios de gestão de custos são estabelecidos e aplicados
Este controlo requer a capacidade de inspecionar os recursos de dados para confirmar a utilização de custos, com base nos requisitos das políticas e na arquitetura de dados. As métricas de custos devem ser abrangentes e não se limitar apenas à utilização e à movimentação de armazenamento.
A arquitetura usa o Data Catalog para adicionar as seguintes etiquetas ao modelo de etiqueta cost_metrics:
total_query_bytes_billed: número total de bytes de consulta que foram faturados para este recurso de dados desde o início do mês atual.total_storage_bytes_billed: o número total de bytes de armazenamento que foram faturados para este recurso de dados desde o início do mês atual.total_bytes_transferred: soma dos bytes transferidos entre regiões para este recurso de dados.estimated_query_cost: custo estimado da consulta, em dólares dos EUA, para o recurso de dados do mês atual.estimated_storage_cost: custo de armazenamento estimado, em dólares dos EUA, do recurso de dados para o mês atual.estimated_egress_cost: saída estimada em dólares americanos para o mês atual em que o recurso de dados foi usado como uma tabela de destino.
A arquitetura exporta informações de preços da Faturação do Google Cloud para uma tabela do BigQuery denominada cloud_pricing_export.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- O Cloud Billing fornece informações de faturação.
- O catálogo de dados armazena as informações de custos em modelos de etiquetas e etiquetas.
- O BigQuery armazena as informações de preços exportadas e as informações do histórico de tarefas de consulta através da vista INFORMATION_SCHEMA integrada.
- Duas instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
- O Pub/Sub publica as conclusões.
Para detetar problemas relacionados com este controlo, a arquitetura verifica se existem recursos de dados confidenciais sem métricas de custos associadas.
14. A proveniência e a linhagem dos dados são compreendidas
Este controlo requer a capacidade de inspecionar a rastreabilidade do recurso de dados a partir da respetiva origem e quaisquer alterações à linhagem do recurso de dados.
Para manter informações sobre a proveniência e a linhagem dos dados, a arquitetura usa as funcionalidades de linhagem de dados incorporadas no Data Catalog. Além disso, os scripts de carregamento de dados definem a origem final e adicionam a origem como um nó adicional ao gráfico de linhagem de dados.
Para cumprir os requisitos deste controlo, a arquitetura usa o Data Catalog para adicionar a etiqueta ultimate_source ao modelo de etiqueta CDMC
controls. A etiqueta ultimate_source define a origem deste recurso de dados.
O diagrama seguinte mostra os serviços que se aplicam a este controlo.

Para cumprir os requisitos deste controlo, a arquitetura usa os seguintes serviços:
- Dois armazéns de dados do BigQuery: um armazena os dados confidenciais e o outro armazena os dados de origem finais.
- O catálogo de dados armazena a origem final em modelos de etiquetas e etiquetas.
- Os scripts de carregamento de dados carregam os dados do Cloud Storage, definem a origem final e adicionam a origem ao gráfico de linhagem de dados.
- Duas instâncias do Cloud Run, da seguinte forma:
- Uma instância executa o motor de relatórios, que verifica se as etiquetas são aplicadas e publica os resultados.
- Outra instância executa o motor de etiquetas, que etiqueta os dados no armazém de dados seguro.
- O Pub/Sub publica as conclusões.
Para detetar problemas relacionados com este controlo, a arquitetura inclui as seguintes verificações:
- Os dados confidenciais são identificados sem uma etiqueta de origem final.
- O gráfico de linhagem não é preenchido para recursos de dados confidenciais.
Referência da etiqueta
Esta secção descreve os modelos de etiquetas e as etiquetas que esta arquitetura usa para cumprir os requisitos dos controlos principais do CDMC.
Modelos de etiquetas de controlo do CDMC ao nível da tabela
A tabela seguinte lista as etiquetas que fazem parte do modelo de etiqueta de controlo do CDMC e que são aplicadas às tabelas.
| Etiqueta | ID da etiqueta | Controlo de chaves aplicável |
|---|---|---|
| Localização de armazenamento aprovada | approved_storage_location |
4 |
| Uso Autorizado | approved_use |
8 |
| Email do proprietário dos dados | data_owner_email |
2 |
| Nome do proprietário dos dados | data_owner_name |
2 |
| Método de encriptação | encryption_method |
9 |
| Ação de expiração | expiration_action |
11 |
| É autoritário | is_authoritative |
3 |
| É sensível | is_sensitive |
6 |
| Categoria sensível | sensitive_category |
6 |
| Partilha da geografia do âmbito | sharing_scope_geography |
8 |
| Entidade legal do âmbito da partilha | sharing_scope_legal_entity |
8 |
| Período de retenção | retention_period |
11 |
| Origem final | ultimate_source |
14 |
Modelo de etiqueta de avaliação de impacto
A tabela seguinte lista as etiquetas que fazem parte do modelo de etiqueta de avaliação de impacto e que são aplicadas às tabelas.
| Etiqueta | ID da etiqueta | Controlo de chaves aplicável |
|---|---|---|
| Localizações do objeto | subject_locations |
10 |
| É uma avaliação de impacto da AIPD | is_dpia |
10 |
| É uma avaliação de impacto da PIA | is_pia |
10 |
| Relatórios de avaliação de impacto | impact_assessment_reports |
10 |
| Avaliação de impacto mais recente | most_recent_assessment |
10 |
| Avaliação de impacto mais antiga | oldest_assessment |
10 |
Modelo de etiqueta de métricas de custos
A tabela seguinte lista as etiquetas que fazem parte do modelo de etiqueta de métricas de custos e que são aplicadas às tabelas.
| Etiqueta | Separador ID | Controlo de chaves aplicável |
|---|---|---|
| Custo estimado da consulta | estimated_query_cost |
13 |
| Custo de armazenamento estimado | estimated_storage_cost |
13 |
| Custo de saída estimado | estimated_egress_cost |
13 |
| Total de bytes de consulta faturados | total_query_bytes_billed |
13 |
| Total de bytes de armazenamento faturados | total_storage_bytes_billed |
13 |
| Total de bytes transferidos | total_bytes_transferred |
13 |
Modelo de etiqueta de sensibilidade dos dados
A tabela seguinte apresenta as etiquetas que fazem parte do modelo de etiqueta de confidencialidade dos dados e que são aplicadas aos campos.
| Etiqueta | ID da etiqueta | Controlo de chaves aplicável |
|---|---|---|
| Campo confidencial | sensitive_field |
6 |
| Tipo sensível | sensitive_category |
6 |
Modelo de etiqueta de política de segurança
A tabela seguinte lista as etiquetas que fazem parte do modelo de etiqueta da política de segurança e que são aplicadas aos campos.
| Etiqueta | ID da etiqueta | Controlo de chaves aplicável |
|---|---|---|
| Método de desidentificação da aplicação | app_deid_method |
9 |
| Método de desidentificação da plataforma | platform_deid_method |
9 |
Modelos de etiquetas de qualidade de dados
A tabela seguinte lista as etiquetas que fazem parte dos modelos de etiquetas de qualidade de dados de integridade e correção e que são aplicadas aos campos.
| Etiqueta | ID da etiqueta | Controlo de chaves aplicável |
|---|---|---|
| Limite aceitável | acceptable_threshold |
12 |
| Nome da coluna | column_name |
12 |
| Cumpre o limite | meets_threshold |
12 |
| Métrica | metric |
12 |
| Execução mais recente | most_recent_run |
12 |
| Linhas validadas | rows_validated |
12 |
| Percentagem de êxito | success_percentage |
12 |
Etiquetas de políticas da CDMC ao nível do campo
A tabela seguinte apresenta as etiquetas de políticas que fazem parte da taxonomia de etiquetas de políticas de classificação de dados confidenciais do CDMC e que são aplicadas aos campos. Estas etiquetas de políticas restringem o acesso ao nível do campo e permitem a desidentificação de dados ao nível da plataforma.
| Classificação de dados | Nome da etiqueta | Controlo de chaves aplicável |
|---|---|---|
| Informações de identificação pessoal | personal_identifiable_information |
7 |
| Informações pessoais | personal_information |
7 |
| Informações de identificação pessoal confidenciais | sensitive_personal_identifiable_information |
7 |
| Informações pessoais confidenciais | sensitive_personal_data |
7 |
Metadados técnicos pré-preenchidos
A tabela seguinte lista os metadados técnicos que são sincronizados por predefinição no Data Catalog para todos os recursos de dados do BigQuery.
| Metadados | Controlo de chaves aplicável |
|---|---|
| Tipo de recurso | — |
| Hora da criação | — |
| Prazo de validade | 11 |
| Location | 4 |
| URL do recurso | 3 |
O que se segue?
- Saiba mais acerca da CDMC.
- Leia acerca dos controlos de segurança usados no projeto de armazém de dados seguro.
- Descubra o Data Catalog.
- Saiba mais acerca do catálogo universal do Dataplex.
- Saiba mais acerca do motor de etiquetas.
- Implemente esta solução através da Google Cloud arquitetura de referência do CDMC no GitHub.