De nombreuses organisations déploient des entrepôts de données cloud pour stocker des informations sensibles afin de pouvoir les analyser à des fins diverses. Ce document explique comment mettre en œuvre le framework des principaux contrôles de Cloud Data Management Capabilities (CDMC), géré par le Enterprise Data Management Council, dans un entrepôt de données BigQuery.
Le framework des principaux contrôles CDMC a été publié principalement pour les fournisseurs de services cloud et les fournisseurs de technologie. Le framework décrit 14 contrôles clés que les fournisseurs peuvent mettre en œuvre pour permettre à leurs clients de gérer et de gouverner efficacement les données sensibles dans le cloud. Les contrôles ont été rédigés par le groupe de travail CDMC, et plus de 300 professionnels ont participé à partir de plus de 100 entreprises. Lors de la rédaction de ce framework, le groupe de travail CDMC a pris en compte de nombreuses exigences légales et réglementaires.
Cette architecture de référence BigQuery et Data Catalog a été évaluée et certifiée en tant que solution cloud certifiée CDMC par rapport au framework des principaux contrôles CDMC. L'architecture de référence utilise divers services et fonctionnalités Google Cloud , ainsi que des bibliothèques publiques pour mettre en œuvre les principaux contrôles CDMC et l'automatisation recommandée. Ce document explique comment mettre en œuvre les principaux contrôles pour protéger les données sensibles dans un entrepôt de données BigQuery.
Architecture
L'architecture de référence Google Cloud suivante est conforme à la version 1.1.1 des spécifications du test du framework des principaux contrôles CDMC. Les numéros indiqués dans le schéma représentent les principaux contrôles adressés aux services Google Cloud .

L'architecture de référence s'appuie sur le plan d'entrepôt de données sécurisé, qui fournit une architecture permettant de protéger un entrepôt de données BigQuery incluant des informations sensibles. Dans le schéma précédent, les projets situés en haut du schéma (en gris) font partie du plan d'entrepôt de données sécurisé, et le projet de gouvernance des données (en bleu) inclut les services ajoutés pour répondre aux exigences du framework des principaux contrôles CDMC. Pour mettre en œuvre le framework des principaux contrôles CDMC, l'architecture étend le projet de gouvernance des données. Le projet de gouvernance des données fournit des contrôles tels que la classification, la gestion du cycle de vie et la gestion de la qualité des données. Le projet permet également d'auditer l'architecture et de générer des rapports sur les résultats.
Pour en savoir plus sur la mise en œuvre de cette architecture de référence, consultez l'architecture de référence CDMCGoogle Cloud sur GitHub.
Présentation du framework des principaux contrôles CDMC
Le tableau suivant récapitule le framework des contrôles principaux CDMC.
| # | Principaux contrôles CDMC | Exigence de contrôle CDMC |
|---|---|---|
| 1 | Conformité du contrôle des données | Les cas d'utilisation de la gestion des données dans le cloud sont définis et régis par une licence. Tous les éléments de données contenant des données sensibles doivent être surveillés pour garantir leur conformité avec les principaux contrôles CDMC, à l'aide de métriques et de notifications automatisées. |
| 2 | La propriété des données est établie pour les données migrées et générées dans le cloud. | Le champ Propriété d'un catalogue de données doit être renseigné pour toutes les données sensibles ou être signalé à un workflow défini. |
| 3 | L'approvisionnement et la consommation des données sont régis et soutenus par l'automatisation. | Un registre de sources de données faisant autorité et de points de provisionnement doit être renseigné pour tous les éléments de données contenant des données sensibles. Sinon, il doit être signalé à un workflow défini. |
| 4 | La souveraineté des données et le transfert des données à l'international sont gérés. | La souveraineté des données et le déplacement des données sensibles au-delà des frontières doivent être enregistrés, audités et contrôlés conformément à la stratégie définie. |
| 5 | Les catalogues de données sont mis en œuvre, utilisés et interopérables. | Le catalogage doit être automatisé pour toutes les données au moment de la création ou de l'ingestion, et ce, dans tous les environnements. |
| 6 | Les classifications de données sont définies et utilisées. | La classification doit être automatisée pour toutes les données au moment de la création ou de l'ingestion et doit toujours être activée. La classification est automatisée pour les opérations suivantes :
|
| 7 | Les droits d'accès aux données sont gérés, appliqués et suivis. | Ce contrôle nécessite les éléments suivants :
|
| 8 | L'accès éthique, l'utilisation et les résultats sont gérés. | L'objectif de consommation des données doit être fourni pour tous les accords de partage de données impliquant des données sensibles. L'objectif doit spécifier le type de données requis et, pour les organisations mondiales, le champ d'application du pays ou de l'entité légale. |
| 9 | Les données sont sécurisées, et les contrôles sont prouvés. | Ce contrôle nécessite les éléments suivants :
|
| 10 | Un cadre spécifique à la confidentialité des données est défini et opérationnel. | Les évaluations d'impact sur la protection des données doivent être automatiquement déclenchées pour toutes les données à caractère personnel conformément à leur juridiction. |
| 11 | Le cycle de vie des données est planifié et géré. | La conservation, l'archivage et la suppression définitive des données doivent être gérés selon un calendrier de conservation défini. |
| 12 | Gestion de la qualité des données. | La mesure de la qualité des données doit être activée pour les données sensibles comportant des métriques distribuées, le cas échéant. |
| 13 | Les principes de gestion des coûts sont établis et appliqués. | Les principes de conception technique sont établis et appliqués. Les métriques de coûts directement associées à l'utilisation, au stockage et au déplacement des données doivent être disponibles dans le catalogue. |
| 14 | La provenance et la traçabilité des données sont comprises. | Les informations de traçabilité des données doivent être disponibles pour toutes les données sensibles. Ces informations doivent au moins inclure la source à partir de laquelle les données ont été ingérées ou dans lesquelles elles ont été créées dans un environnement cloud. |
1. Conformité du contrôle des données
Ce contrôle nécessite de vérifier que toutes les données sensibles sont surveillées afin de garantir leur conformité avec ce framework à l'aide de métriques.
L'architecture utilise des métriques qui indiquent dans quelle mesure chacun des principaux contrôles est opérationnel. L'architecture inclut également des tableaux de bord indiquant à quel moment les métriques ne respectent pas les seuils définis.
L'architecture inclut des détecteurs qui publient les résultats et des recommandations de résolution lorsque les éléments de données ne répondent pas à un contrôle des clés. Ces résultats et recommandations sont au format JSON et publiés dans un sujet Pub/Sub pour la distribution aux abonnés. Vous pouvez intégrer votre centre de services interne ou vos outils de gestion de service au sujet Pub/Sub afin que les incidents soient automatiquement créés dans votre système de demande d'assistance.
L'architecture utilise Dataflow pour créer un exemple d'abonné aux événements de résultats, qui sont ensuite stockés dans une instance BigQuery qui s'exécute dans le projet de gouvernance des données. À l'aide d'un certain nombre de vues fournies, vous pouvez interroger les données à l'aide de BigQuery Studio dans la console Google Cloud . Vous pouvez également créer des rapports à l'aide de Looker Studio ou d'autres outils d'informatique décisionnelle compatibles avec BigQuery. Les rapports que vous pouvez afficher incluent les éléments suivants :
- Récapitulatif des résultats de la dernière exécution
- Détails des résultats de la dernière exécution
- Métadonnées de la dernière exécution
- Éléments de données de dernière exécution couverts
- Statistiques de la dernière exécution d'un ensemble de données
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Pub/Sub publie les résultats.
- Dataflow charge les résultats dans une instance BigQuery.
- BigQuery stocke les données des résultats et fournit des vues récapitulatives.
- Looker Studio fournit des tableaux de bord et des rapports.
La capture d'écran suivante montre un exemple de tableau de bord récapitulatif de Looker Studio.
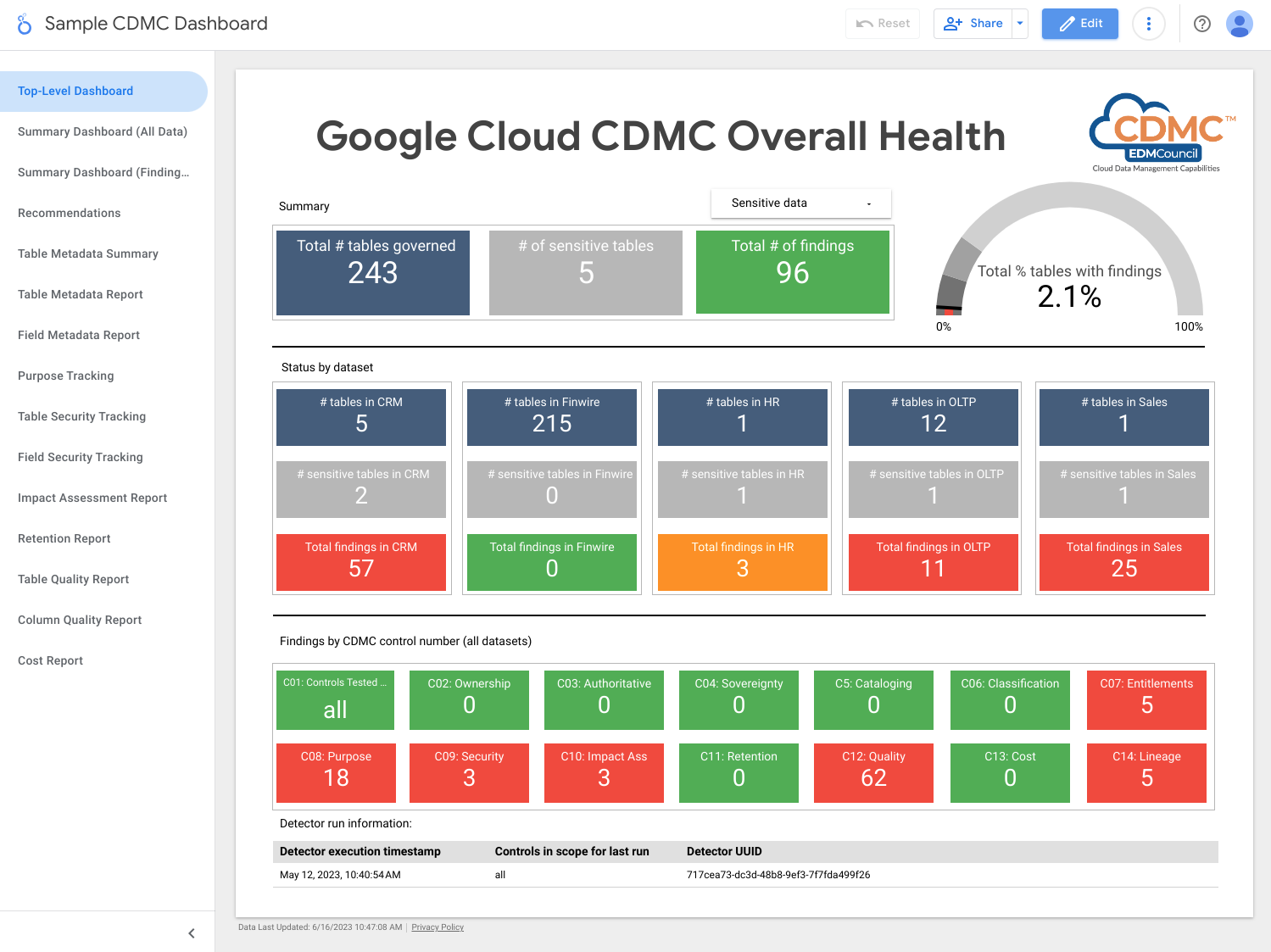
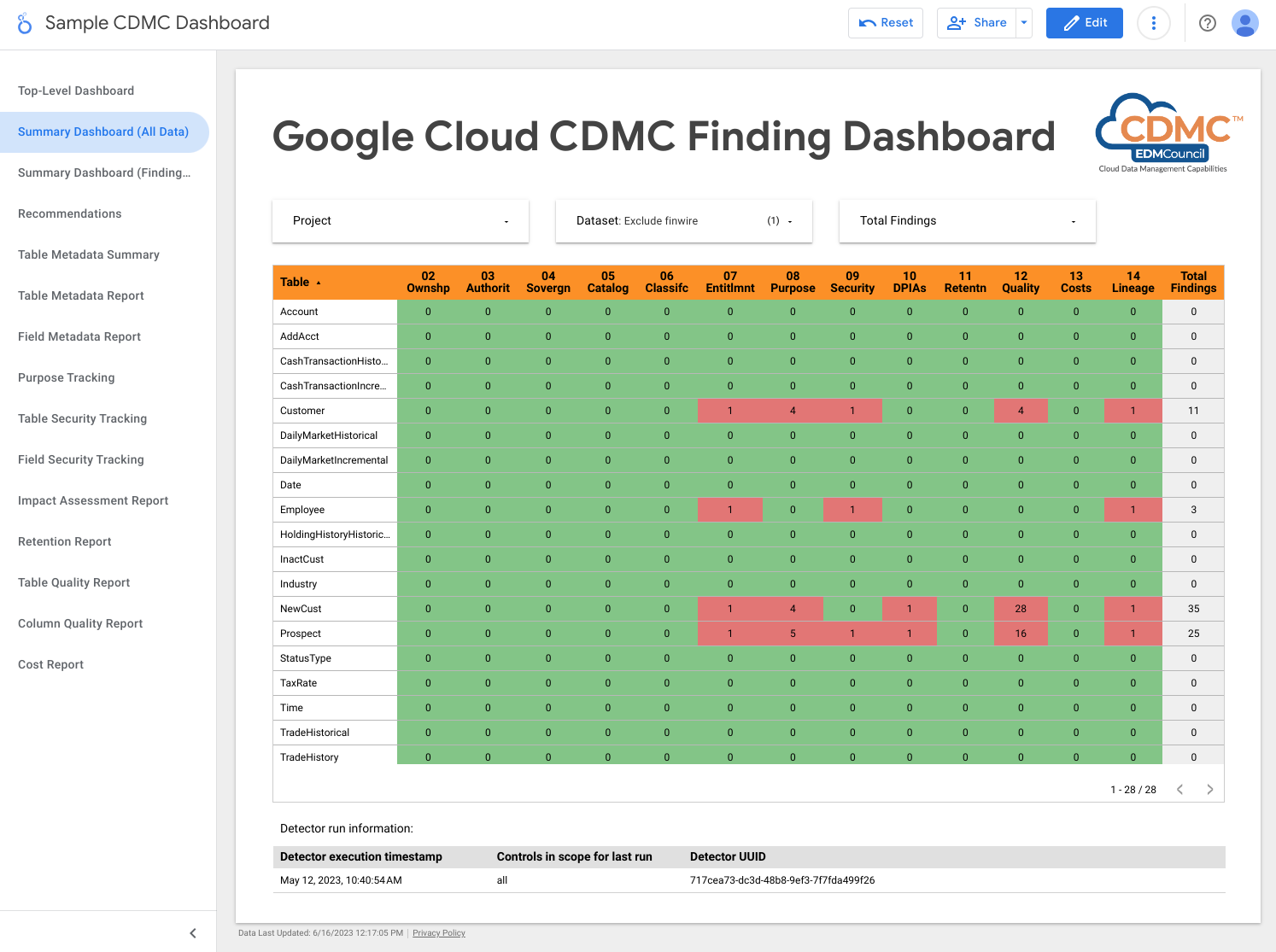
La capture d'écran suivante montre un exemple d'affichage des résultats par élément de données.
2. La propriété des données est établie pour les données migrées et générées dans le cloud.
Pour répondre aux exigences de ce contrôle, l'architecture examine automatiquement les données dans l'entrepôt de données BigQuery et ajoute des tags de classification des données qui indiquent que les propriétaires sont identifiés pour toutes les données sensibles.
Data Catalog gère deux types de métadonnées : les métadonnées techniques et les métadonnées commerciales. Pour un projet donné, Data Catalog répertorie automatiquement les ensembles de données, tables et vues BigQuery, puis renseigne les métadonnées techniques. La synchronisation entre le catalogue et les éléments de données est gérée quasiment en temps réel.
L'architecture utilise Tag Engine pour ajouter les tags de métadonnées commerciales suivants à un modèle de tag CDMC controls dans Data Catalog :
is_sensitive: indique si l'élément de données contient des données sensibles (consultez la section Contrôle 6 pour la classification des données).owner_name: propriétaire des donnéesowner_email: adresse e-mail du propriétaire
Les tags sont renseignés à l'aide des valeurs par défaut stockées dans une table BigQuery de référence du projet de gouvernance des données.
Par défaut, l'architecture définit les métadonnées de propriété au niveau de la table, mais vous pouvez la modifier pour que les métadonnées soient définies au niveau de la colonne. Pour en savoir plus, consultez la page Tags et modèles de tags Data Catalog.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Deux entrepôts de données BigQuery : l'un stocke les données confidentielles et l'autre stocke les valeurs par défaut de la propriété des éléments de données.
- Data Catalog stocke les métadonnées de propriété via des modèles de tag et des tags.
- Deux instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
- Pub/Sub publie les résultats.
Pour détecter les problèmes liés à ce contrôle, l'architecture vérifie si des données sensibles se voient attribuer un tag de nom de propriétaire.
3. L'approvisionnement et la consommation des données sont régis et soutenus par l'automatisation
Ce contrôle nécessite la classification des éléments de données ainsi qu'un registre de données de sources faisant autorité et de distributeurs autorisés. L'architecture utilise Data Catalog pour ajouter le tag is_authoritative au modèle de tag CDMC
controls. Ce tag indique si l'élément de données fait autorité.
Data Catalog propose un catalogue des ensembles de données, des tables et des vues BigQuery avec des métadonnées techniques et commerciales. Les métadonnées techniques sont automatiquement renseignées et incluent l'URL de la ressource, qui correspond à l'emplacement du point de provisionnement. Les métadonnées commerciales sont définies dans le fichier de configuration de Tag Engine et incluent le tag is_authoritative.
Lors de la prochaine exécution programmée, Tag Engine renseigne le tag is_authoritative dans le modèle de tag CDMC controls à partir des valeurs par défaut stockées dans une table de référence dans BigQuery.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Deux entrepôts de données BigQuery : l'un stocke les données confidentielles et l'autre stocke les valeurs par défaut de la source faisant autorité de l'élément de données.
- Data Catalog stocke les métadonnées sources faisant autorité via des tags.
- Deux instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
- Pub/Sub publie les résultats.
Pour détecter les problèmes liés à ce contrôle, l'architecture vérifie si les données sensibles se voient attribuer le tag source faisant autorité.
4. La souveraineté des données et le transfert des données à l'international sont gérés.
Ce contrôle nécessite que l'architecture inspecte le registre de données pour connaître les exigences de stockage spécifiques à la région et appliquer des règles d'utilisation. Un rapport décrit l'emplacement géographique des éléments de données.
L'architecture utilise Data Catalog pour ajouter le tag approved_storage_location au modèle de tag CDMC controls. Ce tag définit l'emplacement géographique dans lequel l'élément de données peut être stocké.
L'emplacement réel des données est stocké sous forme de métadonnées techniques dans les détails de la table BigQuery. BigQuery ne permet pas aux administrateurs de modifier l'emplacement d'un ensemble de données ou d'une table. Si les administrateurs souhaitent modifier l'emplacement des données, ils doivent copier l'ensemble de données.
La contrainte du service de règles d'administration des emplacements de ressources définit les régions Google Cloud dans lesquelles vous pouvez stocker des données. Par défaut, l'architecture définit la contrainte sur le projet de données confidentielles, mais vous pouvez la définir au niveau de l'organisation ou du dossier si vous le souhaitez. Tag Engine réplique les emplacements autorisés dans le modèle de tag Data Catalog et stocke l'emplacement dans le tag approved_storage_location. Si vous activez le niveau Premium de Security Command Center et qu'un utilisateur met à jour la contrainte d'emplacement des ressources du service de règles d'administration, Security Command Center génère des résultats de failles pour les ressources stockées en dehors de la règle mise à jour.
Access Context Manager définit l'emplacement géographique où les utilisateurs doivent se trouver avant de pouvoir accéder aux éléments de données. À l'aide des niveaux d'accès, vous pouvez spécifier les régions d'où proviennent les requêtes. Ensuite, ajoutez la règle d'accès au périmètre VPC Service Controls pour le projet de données confidentielles.
Pour suivre le déplacement des données, BigQuery conserve une piste d'audit complète pour chaque tâche et requête sur chaque ensemble de données. La trace d'audit est stockée dans la vue Tâches du schéma d'informations BigQuery.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Le service de règles d'administration définit et applique la contrainte d'emplacement des ressources.
- Access Context Manager définit les emplacements à partir desquels les utilisateurs peuvent accéder aux données.
- Deux entrepôts de données BigQuery : l'un stocke les données confidentielles et l'autre héberge une fonction distante permettant d'inspecter la stratégie de localisation.
- Data Catalog stocke les emplacements de stockage approuvés en tant que tags.
- Deux instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
- Pub/Sub publie les résultats.
- Cloud Logging écrit les journaux d'audit.
- Security Command Center génère des rapports sur tous les résultats liés à l'emplacement des ressources ou à l'accès aux données.
Pour détecter les problèmes liés à ce contrôle, l'architecture inclut un résultat indiquant si le tag d'emplacement approuvé inclut l'emplacement des données sensibles.
5. Les catalogues de données sont mis en œuvre, utilisés et interopérables.
Ce contrôle nécessite qu'un catalogue de données existe et que l'architecture puisse analyser les éléments nouveaux et mis à jour pour ajouter des métadonnées si nécessaire.
Pour répondre aux exigences de ce contrôle, l'architecture utilise Data Catalog. Data Catalog enregistre automatiquement les élémentsGoogle Cloud , y compris les ensembles de données, les tables et les vues BigQuery. Lorsque vous créez une table dans BigQuery, Data Catalog enregistre automatiquement les métadonnées et le schéma techniques de la nouvelle table. Lorsque vous mettez à jour une table dans BigQuery, Data Catalog met à jour ses entrées presque instantanément.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Deux entrepôts de données BigQuery : l'un stocke les données confidentielles et l'autre stocke les données non confidentielles.
- Data Catalog stocke les métadonnées techniques pour les tables et les champs.
Par défaut, dans cette architecture, Data Catalog stocke les métadonnées techniques à partir de BigQuery. Si nécessaire, vous pouvez intégrer Data Catalog à d'autres sources de données.
6. Les classifications de données sont définies et utilisées.
Cette évaluation nécessite que les données soient classées en fonction de leur sensibilité, par exemple s'il s'agit d'informations personnelles, d'identification de clients ou d'une autre norme définie par votre organisation. Pour répondre aux exigences de ce contrôle, l'architecture crée un rapport sur les éléments de données et leur sensibilité. Vous pouvez utiliser ce rapport pour vérifier si les paramètres de sensibilité sont corrects. De plus, chaque nouvel élément de données ou modification d'un élément de données existant entraîne une mise à jour du catalogue de données.
Les classifications sont stockées dans le tag sensitive_category du modèle de tag Data Catalog au niveau de la table et de la colonne. Un tableau de référence de classification vous permet de classer les types d'informations Sensitive Data Protection disponibles (infoTypes), avec des classements plus élevés pour le contenu plus sensible.
Pour répondre aux exigences de ce contrôle, l'architecture utilise la protection des données sensibles, Data Catalog et Tag Engine pour ajouter les tags suivants aux colonnes sensibles des tables BigQuery :
is_sensitive: indique si l'élément de données contient des informations sensibles.sensitive_category: catégorie des données, l'un des éléments suivants :- Informations personnelles sensibles
- Informations personnelles
- Informations personnelles sensibles
- Informations personnelles
- Informations publiques
Vous pouvez modifier les catégories de données en fonction de vos besoins. Par exemple, vous pouvez ajouter la classification Informations non publiques importantes (MNPI)
Une fois que la protection des données sensibles a inspecté les données, Tag Engine lit les tables DLP results par élément pour compiler les résultats. Si une table contient des colonnes avec un ou plusieurs infoTypes sensibles, l'infoType le plus notable est déterminé, et les colonnes sensibles ainsi que la table entière sont marquées en tant que catégorie avec le classement le plus élevé. Tag Engine attribue également un tag avec stratégie correspondant à la colonne et attribue le tag booléen is_sensitive à la table.
Vous pouvez utiliser Cloud Scheduler pour automatiser l'inspection de la protection des données sensibles.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Quatre entrepôts de données BigQuery stockent les informations suivantes :
- Données confidentielles
- Informations sur les résultats de la protection des données sensibles
- Données de référence sur la classification des données
- Informations sur l'exportation de tags
- Data Catalog stocke les tags de classification.
- La protection des données sensibles inspecte les éléments pour rechercher des infoTypes sensibles.
- Compute Engine exécute le script d'inspection des ensembles de données, qui déclenche une tâche de protection des données sensibles pour chaque ensemble de données BigQuery.
- Deux instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
- Pub/Sub publie les résultats.
Pour détecter les problèmes liés à ce contrôle, l'architecture comprend les résultats suivants :
- Indique si les données sensibles se voient attribuer un tag de catégorie sensible.
- Indique si les données sensibles se voient attribuer un tag de type de sensibilité au niveau de la colonne.
7. Les droits d'accès aux données sont gérés, appliqués et suivis.
Par défaut, seuls les créateurs et les propriétaires se voient attribuer des droits d'accès et un accès aux données sensibles. En outre, ce contrôle nécessite que l'architecture effectue le suivi de tout accès aux données sensibles.
Pour répondre aux exigences de ce contrôle, l'architecture utilise la taxonomie de tags avec stratégie cdmc
sensitive data classification dans BigQuery pour contrôler l'accès aux colonnes contenant des données confidentielles dans les tables BigQuery. La taxonomie inclut les tags avec stratégie suivants :
- Informations personnelles sensibles
- Informations personnelles
- Informations personnelles sensibles
- Informations personnelles
Les tags avec stratégie vous permettent de contrôler qui peut afficher les colonnes sensibles dans les tables BigQuery. L'architecture mappe ces tags avec stratégie sur des classifications de sensibilité dérivées des infoTypes Sensitive Data Protection. Par exemple, le tag avec stratégie sensitive_personal_identifiable_information et la catégorie sensible sont mappés à des infoTypes tels que AGE, DATE_OF_BIRTH, PHONE_NUMBER et EMAIL_ADDRESS.
L'architecture utilise Identity and Access Management (IAM) pour gérer les groupes, les utilisateurs et les comptes de service qui ont besoin d'accéder aux données. Les autorisations IAM sont accordées à un élément donné pour un accès au niveau de la table. En outre, l'accès au niveau des colonnes basé sur des tags avec stratégie permet un accès précis aux éléments de données sensibles. Par défaut, les utilisateurs n'ont pas accès aux colonnes pour lesquelles des tags avec stratégie sont définis.
Pour garantir que seuls les utilisateurs authentifiés peuvent accéder aux données,Google Cloud utilise Cloud Identity, que vous pouvez fédérer avec vos fournisseurs d'identité existants pour authentifier les utilisateurs.
Ce contrôle nécessite également que l'architecture recherche régulièrement les éléments de données pour lesquels aucun droit n'est défini. Le détecteur géré par Cloud Scheduler recherche les scénarios suivants :
- Un élément de données inclut une catégorie sensible, mais aucun tag avec stratégie associé n'existe.
- Une catégorie ne correspond pas au tag avec stratégie.
Dans de tels scénarios, le détecteur génère des résultats publiés par Pub/Sub, puis écrits dans la table events de BigQuery par Dataflow. Vous pouvez ensuite distribuer les résultats à votre outil de résolution, comme décrit dans la section 1. Conformité du contrôle des données.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Un entrepôt de données BigQuery stocke les données confidentielles et les liaisons de tags avec stratégie pour des contrôles d'accès précis.
- IAM gère l'accès.
- Data Catalog stocke les tags au niveau de la table et de la colonne pour la catégorie sensible.
- Deux instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
Pour détecter les problèmes liés à ce contrôle, l'architecture vérifie si les données sensibles possèdent un tag avec stratégie correspondant.
8. L'accès éthique, l'utilisation et les résultats sont gérés.
Ce contrôle nécessite l'architecture de stockage des accords de partage de données du fournisseur de données et des utilisateurs de données, y compris une liste des objectifs de consommation approuvés. L'objectif de consommation des données sensibles est ensuite mappé aux droits d'accès stockés dans BigQuery à l'aide de libellés de requête.
Lorsqu'un consommateur interroge des données sensibles dans BigQuery, il doit spécifier un objectif valide correspondant à son droit (par exemple, SET @@query_label = “use:3”;).
L'architecture utilise Data Catalog pour ajouter les tags suivants au modèle de tag CDMC controls. Ces tags représentent l'accord de partage des données avec le fournisseur de données:
approved_use: utilisation approuvée ou utilisateurs de l'élément de donnéessharing_scope_geography: liste des emplacements géographiques dans lesquels l'élément de données peut être partagésharing_scope_legal_entity: liste des entités acceptées pouvant partager l'élément de données
Un entrepôt de données BigQuery distinct inclut l'ensemble de données entitlement_management avec les tables suivantes :
provider_agreement: contrat de partage des données avec le fournisseur de données, y compris l'entité juridique convenue et le champ d'application géographique. Ces données sont les valeurs par défaut pour les tagsshared_scope_geographyetsharing_scope_legal_entity.consumer_agreement: contrat de partage des données avec le consommateur de données, y compris l'entité légale et le champ d'application géographique convenus. Chaque contrat est associé à une liaison IAM pour l'élément de données.use_purpose: objectif de consommation, tel que la description de l'utilisation et les opérations autorisées pour l'élément de donnéesdata_asset: informations sur l'élément de données, telles que le nom de l'élément et les détails sur le propriétaire des données.
Pour auditer les accords de partage des données, BigQuery conserve une piste d'audit complète pour chaque tâche et requête sur chaque ensemble de données. La trace d'audit est stockée dans la vue Tâches du schéma d'informations BigQuery. Après avoir associé un libellé de requête à une session et exécuté des requêtes dans la session, vous pouvez collecter des journaux d'audit pour les requêtes portant ce libellé. Pour en savoir plus, consultez la documentation de référence sur les journaux d'audit pour BigQuery.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Deux entrepôts de données BigQuery : l'un stocke les données confidentielles et l'autre stocke les données de droit d'accès, qui incluent les contrats de partage des données du fournisseur et du consommateur, et l'objectif d'utilisation approuvé.
- Data Catalog stocke les informations du contrat de partage des données du fournisseur sous forme de tags.
- Deux instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
- Pub/Sub publie les résultats.
Pour détecter les problèmes liés à ce contrôle, l'architecture comprend les résultats suivants :
- Indique s'il existe une entrée pour un élément de données dans l'ensemble de données
entitlement_management. - Si une opération est effectuée sur une table sensible avec un cas d'utilisation arrivé à expiration (par exemple,
valid_until_datedansconsumer_agreement table) est passé. - Si une opération est effectuée sur une table sensible avec une clé de libellé incorrecte.
- Indique si une opération est effectuée sur une table sensible avec une valeur de libellé de cas d'utilisation vide ou non approuvée.
- Si une table sensible est interrogée avec une méthode d'opération non approuvée (par exemple,
SELECTouINSERT). - Indique si l'objectif enregistré que le consommateur a spécifié lors de l'interrogation des données sensibles correspond à l'accord de partage des données.
9. Les données sont sécurisées, et les contrôles sont prouvés.
Ce contrôle nécessite la mise en œuvre du chiffrement des données et l'anonymisation des données pour protéger les données sensibles et fournir un enregistrement de ces contrôles.
Cette architecture s'appuie sur la sécurité par défaut de Google, qui inclut le chiffrement au repos. En outre, l'architecture vous permet de gérer vos propres clés à l'aide de clés de chiffrement gérées par le client (CMEK). Cloud KMS vous permet de chiffrer vos données avec des clés de chiffrement logicielles ou des modules de sécurité matériels (HSM) validés FIPS 140-2 de niveau 3.
L'architecture utilise le masquage dynamique des données au niveau des colonnes configuré via des tags avec stratégie, et stocke les données confidentielles dans un périmètre VPC Service Controls distinct. Vous pouvez également ajouter une anonymisation au niveau de l'application, que vous pouvez mettre en œuvre sur site ou dans le cadre du pipeline d'ingestion de données.
Par défaut, l'architecture met en œuvre le chiffrement CMEK avec HSM, mais accepte Cloud External Key Manager (Cloud EKM).
Le tableau suivant décrit l'exemple de règle de sécurité mis en œuvre par l'architecture pour la région us-central1. Vous pouvez adapter la stratégie à vos besoins, y compris en ajoutant des stratégies différentes pour différentes régions.
| Sensibilité des données | Méthode de chiffrement par défaut | Autres méthodes de chiffrement autorisées | Méthode d'anonymisation par défaut | Autres méthodes d'anonymisation autorisées |
|---|---|---|---|---|
| Informations publiques | Chiffrement par défaut | Toutes | Aucune | Toutes |
| Informations personnelles sensibles | CMEK avec HSM | EKM | Toujours "Null" | Hachage SHA-256 ou valeur de masquage par défaut |
| Informations personnelles | CMEK avec HSM | EKM | Hachage SHA-256 | Valeur toujours "Null" ou valeur de masquage par défaut |
| Informations personnelles sensibles | CMEK avec HSM | EKM | Valeur de masquage par défaut | Hachage SHA-256 ou toujours "Null" |
| Informations personnelles | CMEK avec HSM | EKM | Valeur de masquage par défaut | Hachage SHA-256 ou toujours "Null" |
L'architecture utilise Data Catalog pour ajouter le tag encryption_method au modèle de tag CDMC controls au niveau de la table. Le champ encryption_method définit la méthode de chiffrement utilisée par l'élément de données.
En outre, l'architecture crée un tag security policy template pour identifier la méthode d'anonymisation appliquée à un champ particulier. L'architecture utilise platform_deid_method qui est appliqué à l'aide du masquage dynamique de données. Vous pouvez ajouter app_deid_method et le renseigner à l'aide des pipelines d'ingestion de données Dataflow et Protection des données sensibles inclus dans le plan de sécurité de l'entrepôt de données.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Deux instances facultatives de Dataflow, l'une effectue l'anonymisation au niveau de l'application, l'autre effectue la restauration de l'identification.
- Trois entrepôts de données BigQuery : l'un stocke les données confidentielles, l'autre stocke les données non confidentielles et le troisième stocke la stratégie de sécurité.
- Data Catalog stocke également les modèles de tag d'anonymisation et de chiffrement.
- Deux instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
- Résultats publiés par Pub/Sub.
Pour détecter les problèmes liés à ce contrôle, l'architecture comprend les résultats suivants :
- La valeur du tag de méthode de chiffrement ne correspond pas aux méthodes de chiffrement autorisées pour la sensibilité et l'emplacement spécifiés.
- Une table contient des colonnes sensibles, mais le tag de stratégie de sécurité contient une méthode d'anonymisation non valide au niveau de la plate-forme.
- Une table contient des colonnes sensibles, mais le tag Security Policy Template est manquant.
10. Un cadre spécifique à la confidentialité des données est défini et opérationnel.
Ce contrôle nécessite que l'architecture inspecte le catalogue de données et les classifications pour déterminer si vous devez créer un rapport d'évaluation de l'impact sur la protection des données ou un rapport d'évaluation de l'impact sur la confidentialité. L'évaluation de la confidentialité varie considérablement selon les zones géographiques et les autorités de régulation. Pour déterminer si une évaluation de l'impact est requise, l'architecture doit tenir compte de la résidence des données et de la résidence de la personne concernée.
L'architecture utilise Data Catalog pour ajouter les tags suivants au modèle de tag Impact assessment :
subject_locations: emplacement des sujets auxquels les données de cet élément font référence.is_dpia: indique si une évaluation d'impact sur la confidentialité des données a été effectuée pour cet élément.is_pia: indique si une évaluation de la confidentialité (PIA) a été effectuée pour cet élément.impact_assessment_reports: lien externe vers l'emplacement de stockage du rapport d'évaluation d'impact.most_recent_assessment: date de la dernière évaluation d'impact.oldest_assessment: date de la première évaluation d'impact.
Tag Engine ajoute ces tags à chaque élément de données sensibles, comme défini par le contrôle 6. Le détecteur valide ces tags par rapport à une table de règles dans BigQuery, qui inclut des combinaisons valides de résidence des données, d'emplacement des objets, de sensibilité des données (s'il s'agit d'informations personnelles, par exemple) et du type d'évaluation d'impact (PIA ou DPIA) requis.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Quatre entrepôts de données BigQuery stockent les informations suivantes :
- Données confidentielles
- Données non confidentielles
- Règles d'évaluation de l'impact et horodatages des droits
- Exportations de tags utilisées pour le tableau de bord
- Data Catalog stocke les détails de l'évaluation de l'impact dans les tags au sein de modèles de tag.
- Deux instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
- Pub/Sub publie les résultats.
Pour détecter les problèmes liés à ce contrôle, l'architecture comprend les résultats suivants :
- Il existe des données sensibles sans modèle d'évaluation de l'impact.
- Des données sensibles existent sans lien vers un rapport DPIA ou PIA.
- Les tags ne répondent pas aux exigences du tableau des règles.
- L'évaluation d'impact est plus ancienne que le dernier droit d'accès approuvé pour l'élément de données dans la table des contrats client.
11. Le cycle de vie des données est planifié et géré.
Ce contrôle nécessite de pouvoir inspecter tous les éléments de données pour déterminer si une stratégie de cycle de vie des données existe et s'y conforme.
L'architecture utilise Data Catalog pour ajouter les tags suivants au modèle de tag CDMC controls :
retention_period: durée, en jours, pour conserver la tableexpiration_action: indique si la table doit être archivée ou supprimée définitivement à la fin de la période de conservation.
Par défaut, l'architecture utilise la période de conservation et l'action d'expiration suivantes :
| Catégorie de données | Période de conservation en jours | Action d'expiration |
|---|---|---|
| Informations personnelles sensibles | 60 | Supprimer définitivement |
| Informations personnelles | 90 | Archive |
| Informations personnelles sensibles | 180 | Archive |
| Informations personnelles | 180 | Archive |
Record Manager, un élément Open Source pour BigQuery, automatise la suppression et l'archivage des tables BigQuery en fonction des valeurs de tags ci-dessus et d'un fichier de configuration. La procédure de suppression définitive définit une date d'expiration sur une table et crée une table d'instantanés avec une heure d'expiration définie dans la configuration du gestionnaire d'enregistrements. Par défaut, le délai d'expiration est de 30 jours. Pendant la période de suppression réversible, vous pouvez récupérer la table. La procédure d'archivage crée une table externe pour chaque table BigQuery qui dépasse sa durée de conservation. La table est stockée au format Cloud Storage au format Parquet et mise à niveau vers une table BigLake qui permet au fichier externe d'être tagué avec des métadonnées dans Data Catalog.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Deux entrepôts de données BigQuery : l'un stocke les données confidentielles et l'autre stocke les règles de conservation des données.
- Deux instances Cloud Storage, l'une fournit un stockage d'archives et l'autre stocke les enregistrements.
- Data Catalog stocke la durée de conservation et l'action dans les modèles de tag et les tags.
- Deux instances Cloud Run, l'une qui exécute le gestionnaire d'enregistrements et l'autre déploie les détecteurs.
- Trois instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
- Une autre instance exécute le gestionnaire d'enregistrement, qui automatise la suppression et l'archivage des tables BigQuery.
- Pub/Sub publie les résultats.
Pour détecter les problèmes liés à ce contrôle, l'architecture comprend les résultats suivants :
- Pour les éléments sensibles, assurez-vous que la méthode de conservation est conforme à la règle applicable à l'emplacement des éléments.
- Pour les éléments sensibles, assurez-vous que la durée de conservation est conforme à la règle applicable à l'emplacement des éléments.
12. Gestion de la qualité des données.
Ce contrôle nécessite de pouvoir mesurer la qualité des données en fonction du profilage des données ou des métriques définies par l'utilisateur.
L'architecture permet de définir des règles de qualité des données pour une valeur individuelle ou globale, et d'attribuer des seuils à une colonne de table spécifique. Cela inclut des modèles de tag pour la précision et l'exhaustivité. Data Catalog ajoute les tags suivants à chaque modèle de tag :
column_name: nom de la colonne à laquelle la métrique s'appliquemetric: nom de la métrique ou de la règle de qualitérows_validated: nombre de lignes validéessuccess_percentage: pourcentage de valeurs répondant à cette métriqueacceptable_threshold: seuil acceptable pour cette métriquemeets_threshold: indique si le niveau de qualité (valeursuccess_percentage) atteint le seuil acceptablemost_recent_run: date et heure de la dernière exécution de la métrique ou de la règle de qualité
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Trois entrepôts de données BigQuery : l'un stocke les données sensibles, l'autre stocke les données non sensibles et le troisième stocke les métriques des règles de qualité.
- Data Catalog stocke les résultats concernant la qualité des données dans des modèles de tag et des tags.
- Cloud Scheduler définit la date d'exécution de Cloud Data Quality Engine.
- Trois instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
- La troisième instance exécute Cloud Data Quality Engine.
- Cloud Data Quality Engine définit des règles de qualité des données et planifie des contrôles de qualité des données pour les tables et les colonnes.
- Pub/Sub publie les résultats.
Un tableau de bord Looker Studio affiche les rapports de qualité des données au niveau des tables et des colonnes.
Pour détecter les problèmes liés à ce contrôle, l'architecture comprend les résultats suivants :
- Les données sont sensibles, mais aucun modèle de tag de qualité des données n'est appliqué (exactitude et exhaustivité).
- Les données sont sensibles, mais le tag de qualité des données n'est pas appliqué à la colonne sensible.
- Les données sont sensibles, mais les résultats de qualité des données ne sont pas inférieurs au seuil défini dans la règle.
- Les données ne sont pas sensibles et les résultats de qualité des données ne sont pas inférieurs au seuil défini par la règle.
Au lieu de Cloud Data Quality Engine, vous pouvez configurer des tâches liées à la qualité des données Dataplex Universal Catalog.
13. Les principes de gestion des coûts sont établis et appliqués.
Ce contrôle nécessite de pouvoir inspecter les éléments de données afin de confirmer l'utilisation des coûts, en fonction des exigences de la stratégie et de l'architecture des données. Les métriques de coûts doivent être exhaustives et pas seulement limitées à l'utilisation et au déplacement des espaces de stockage.
L'architecture utilise Data Catalog pour ajouter les tags suivants au modèle de tag cost_metrics :
total_query_bytes_billed: nombre total d'octets de requête facturés pour cet élément de données depuis le début du mois en cours.total_storage_bytes_billed: nombre total d'octets de stockage facturés pour cet élément de données depuis le début du mois en cours.total_bytes_transferred: somme des octets transférés entre les régions entre cet élément de données.estimated_query_cost: coût estimé de la requête en dollars américains pour l'élément de données du mois en cours.estimated_storage_cost: coût de stockage estimé, en dollars américains, pour l'élément de données pour le mois en cours.estimated_egress_cost: sortie estimée en dollars américains pour le mois en cours, lors duquel l'élément de données a été utilisé comme table de destination.
L'architecture exporte les informations tarifaires de Cloud Billing vers une table BigQuery nommée cloud_pricing_export.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Cloud Billing fournit des informations de facturation.
- Data Catalog stocke les informations sur les coûts dans des modèles de tag et des tags.
- BigQuery stocke les informations de tarification exportées et les informations de l'historique des tâches de requête via sa vue INFORMATION_SCHEMA intégrée.
- Deux instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
- Pub/Sub publie les résultats.
Pour détecter les problèmes liés à ce contrôle, l'architecture vérifie si des éléments de données sensibles existent sans associer de métriques de coût.
14. La provenance et la traçabilité des données sont comprises.
Ce contrôle nécessite d'inspecter la traçabilité de l'élément de données à partir de sa source, ainsi que des modifications apportées à la traçabilité des éléments de données.
Pour maintenir les informations sur la provenance et la traçabilité des données, l'architecture utilise les fonctionnalités intégrées de traçabilité des données dans Data Catalog. De plus, les scripts d'ingestion de données définissent la source finale et ajoutent la source en tant que nœud supplémentaire au graphique de traçabilité des données.
Pour répondre aux exigences de ce contrôle, l'architecture utilise Data Catalog pour ajouter le tag ultimate_source au modèle de tag CDMC
controls. Le tag ultimate_source définit la source de cet élément de données.
Le schéma suivant montre les services qui s'appliquent à ce contrôle.

Pour répondre aux exigences de ce contrôle, l'architecture utilise les services suivants :
- Deux entrepôts de données BigQuery : l'un stocke les données confidentielles et l'autre stocke les données sources ultimes.
- Data Catalog stocke la source ultime dans les modèles de tag et les tags.
- Les scripts d'ingestion de données chargent les données depuis Cloud Storage, définissent la source finale et ajoute la source au graphique de traçabilité des données.
- Deux instances Cloud Run, comme suit :
- Une instance exécute Report Engine, qui vérifie si les tags sont appliqués et publie les résultats.
- Une autre instance exécute Tag Engine, qui ajoute des tags aux données dans l'entrepôt de données sécurisé.
- Pub/Sub publie les résultats.
Pour détecter les problèmes liés à ce contrôle, l'architecture inclut les vérifications suivantes :
- Les données sensibles sont identifiées sans tag source final.
- Le graphique de traçabilité n'est pas renseigné pour les éléments de données sensibles.
Référence des tags
Cette section décrit les modèles de tag et les tags utilisés par cette architecture pour répondre aux exigences des principaux contrôles CDMC.
Modèles de tags de contrôle CDMC au niveau de la table
Le tableau suivant répertorie les tags qui font partie du modèle de tag de contrôle CDMC et qui sont appliqués aux tables.
| Tag | ID du tag | Principal contrôle applicable |
|---|---|---|
| Emplacement de stockage approuvé | approved_storage_location |
4 |
| Utilisation approuvée | approved_use |
8 |
| Adresse e-mail du propriétaire des données | data_owner_email |
2 |
| Nom du propriétaire de données | data_owner_name |
2 |
| Méthode de chiffrement | encryption_method |
9 |
| Action d'expiration | expiration_action |
11 |
| Est primaire | is_authoritative |
3 |
| Est sensible | is_sensitive |
6 |
| Catégorie sensible | sensitive_category |
6 |
| Partage de la zone géographique du champ d'application | sharing_scope_geography |
8 |
| Entité juridique du partage de champ d'application | sharing_scope_legal_entity |
8 |
| Durée de conservation | retention_period |
11 |
| Source ultime | ultimate_source |
14 |
Modèle de balise d'évaluation d'impact
Le tableau suivant répertorie les tags qui font partie du modèle de tag d'évaluation de l'impact et qui sont appliqués aux tables.
| Tag | ID du tag | Principal contrôle applicable |
|---|---|---|
| Emplacements des objets | subject_locations |
10 |
| Évaluation de l'impact DPIA | is_dpia |
10 |
| Évaluation de l'impact PIA | is_pia |
10 |
| Rapports d'évaluation de l'impact | impact_assessment_reports |
10 |
| Dernière évaluation de l'impact | most_recent_assessment |
10 |
| Plus ancienne évaluation d'impact | oldest_assessment |
10 |
Modèle de balise des métriques de coût
Le tableau suivant répertorie les tags qui font partie du modèle de tag des métriques de coût et qui sont appliqués aux tables.
| Tag | Onglet ID | Principal contrôle applicable |
|---|---|---|
| Coût estimé de la requête | estimated_query_cost |
13 |
| Coût de stockage estimé | estimated_storage_cost |
13 |
| Coût de sortie estimé | estimated_egress_cost |
13 |
| Nombre total d'octets de requête facturés | total_query_bytes_billed |
13 |
| Nombre total d'octets de stockage facturés | total_storage_bytes_billed |
13 |
| Nombre total d'octets transférés | total_bytes_transferred |
13 |
Modèle de tags de sensibilité des données
Le tableau suivant répertorie les tags qui font partie du modèle de tag de sensibilité des données et qui sont appliqués aux champs.
| Tag | ID du tag | Principal contrôle applicable |
|---|---|---|
| Champ sensible | sensitive_field |
6 |
| Type sensible | sensitive_category |
6 |
Modèle de tags avec stratégie de sécurité
Le tableau suivant répertorie les tags qui font partie du modèle de tag avec stratégie de sécurité et qui sont appliqués aux champs.
| Tag | ID du tag | Principal contrôle applicable |
|---|---|---|
| Méthode d'anonymisation des applications | app_deid_method |
9 |
| Méthode d'anonymisation de la plate-forme | platform_deid_method |
9 |
Modèles de tags de qualité des données
Le tableau suivant répertorie les tags qui font partie des modèles de tag d'exhaustivité et d'exactitude des données et qui sont appliqués aux champs.
| Tag | ID du tag | Principal contrôle applicable |
|---|---|---|
| Seuil acceptable | acceptable_threshold |
12 |
| Nom de la colonne | column_name |
12 |
| Atteint le seuil | meets_threshold |
12 |
| Métrique | metric |
12 |
| Exécution la plus récente | most_recent_run |
12 |
| Lignes validées | rows_validated |
12 |
| Pourcentage de réussite | success_percentage |
12 |
Tags avec stratégie CDMC au niveau du champ
Le tableau suivant répertorie les tags avec stratégie qui font partie de la taxonomie de tags avec stratégie de classification des données sensibles CDMC et sont appliqués aux champs. Ces tags avec stratégie limitent l'accès au niveau des champs et activent l'anonymisation des données au niveau de la plate-forme.
| Classification des données | Nom de la balise | Principal contrôle applicable |
|---|---|---|
| Informations personnelles | personal_identifiable_information |
7 |
| Informations personnelles | personal_information |
7 |
| Informations personnelles sensibles | sensitive_personal_identifiable_information |
7 |
| Informations personnelles sensibles | sensitive_personal_data |
7 |
Métadonnées techniques préremplies
Le tableau suivant répertorie les métadonnées techniques qui sont synchronisées par défaut dans Data Catalog pour tous les éléments de données BigQuery.
| Métadonnées | Principal contrôle applicable |
|---|---|
| Type d'élément | — |
| Heure de création | — |
| Date/Heure d'expiration | 11 |
| Emplacement | 4 |
| URL de la ressource | 3 |
Étapes suivantes
- En savoir plus sur CDMC
- Découvrez les contrôles de sécurité utilisés par le plan d'entrepôt de données sécurisé.
- Découvrez Data Catalog.
- En savoir plus sur Dataplex Universal Catalog
- En savoir plus sur Tag Engine.
- Mettez en œuvre cette solution à l'aide de l'architecture de référence CDMC dans GitHub.Google Cloud