La pseudonymisation est une technique d'anonymisation qui remplace les valeurs de données sensibles par des jetons générés de manière cryptographique. La Pseudonymisation est largement utilisée dans les secteurs de la finance et de la santé, pour réduire le risque de données utilisées, réduire la portée de conformité, et minimiser l'exposition des données sensibles aux systèmes tout en préservant l'utilité et la précision des données.
La protection des données sensibles accepte trois techniques de pseudonymisation d'anonymisation et génère des jetons en appliquant l'une des trois méthodes de transformation cryptographique aux valeurs d'origine des données sensibles. Chaque valeur sensible d'origine est ensuite remplacée par son jeton correspondant. La pseudonymisation est parfois appelée tokenisation ou remplacement de substitution.
Les techniques de pseudonymisation activent les jetons à sens unique ou de façon bidirectionnelle. Un jeton à sens unique a été transformé de manière irréversible, tandis qu'un jeton bidirectionnel peut être inversé. Comme le jeton est créé à l'aide d'un chiffrement symétrique, la même clé cryptographique pouvant générer de nouveaux jetons peut également inverser les jetons. Dans les cas où vous n'avez pas besoin d'inverser les jetons, vous pouvez utiliser des jetons à sens unique qui utilisent des mécanismes de hachage sécurisés.
Il est utile de comprendre comment la pseudonymisation peut protéger les données sensibles tout en permettant aux opérations commerciales et aux flux de travail analytiques d'accéder facilement aux données dont ils ont besoin. Cet article explore le concept de pseudonymisation et les trois méthodes cryptographiques de transformation des données compatibles avec la protection des données sensibles.
Pour obtenir des instructions sur la mise en œuvre de ces méthodes de pseudonymisation et obtenir d'autres exemples d'utilisation de la protection des données sensibles, consultez la page Supprimer l'identification des données sensibles.
Méthodes cryptographiques compatibles avec la protection des données sensibles
La protection des données sensibles est compatible avec trois techniques de pseudonymisation, qui utilisent toutes des clés cryptographiques. Voici les méthodes disponibles :
- Chiffrement déterministe AES-SIV : une valeur d'entrée est remplacée par une valeur qui a été chiffrée à l'aide de l'algorithme de chiffrement AES-SIV et d'une clé cryptographique, encodée à l'aide de base64, puis est précédée d'une annotation de substitution (si spécifiée) Cette méthode génère une valeur hachée. Elle ne conserve donc pas le jeu de caractères ni la longueur de la valeur d'entrée. Les valeurs hachées chiffrées peuvent être restaurées à l'aide de la clé cryptographique d'origine et de la valeur de sortie entière, y compris l'annotation de substitution. Découvrez le format des valeurs tokenisées à l'aide du chiffrement AES-SIV.
- Chiffrement préservant le format : une valeur d'entrée est remplacée par une valeur qui a été chiffrée à l'aide de l'algorithme de chiffrement FPE-FFX avec une clé cryptographique, et est précédée d'une annotation de substitution, si spécifiée. De par sa conception, le jeu de caractères et la longueur de la valeur d'entrée sont conservés dans la valeur de sortie. Les valeurs chiffrées peuvent être restaurées à l'aide de la clé cryptographique d'origine et de la valeur de sortie entière, y compris l'annotation de substitution. (Pour obtenir des informations importantes sur l'utilisation de cette méthode de chiffrement, consultez la section Chiffrement préservant le format de cette page.)
- Hachage cryptographique : Une valeur d'entrée est remplacée par une valeur qui a été chiffrée et hachée à l'aide de l'algorithme sécurisé HMAC SHA-256 (Secure Hash Algorithm) basé sur le hachage sur la valeur d'entrée avec une clé cryptographique. La sortie hachée de la transformation a toujours la même longueur et ne peut pas être restaurée. En savoir plus sur le format des valeurs tokenisées à l'aide du hachage cryptographique
Ces méthodes de pseudonymisation sont récapitulées dans le tableau ci-après. Les lignes du tableau sont expliquées après le tableau.
| Chiffrement déterministe à l'aide de AES-SIV | Chiffrement préservant le format | Hachage cryptographique | |
|---|---|---|---|
| Type de chiffrement | AES-SIV | FPE-FFX | HMAC-SHA-256 |
| Valeurs d'entrée acceptées | Au moins un caractère, aucune limitation de jeu de caractères. | Au moins deux caractères, doit être encodé au format ASCII. | Doit être une chaîne ou une valeur entière. |
| Annotation de substitution | Facultatif. | Facultatif. | Non disponible |
| Réglage du contexte | Facultatif. | Facultatif. | Non disponible |
| Ensemble de caractères et longueur préservés | ✗ | ✓ | ✗ |
| Réversible | ✓ | ✓ | ✗ |
| Intégrité référentielle | ✓ | ✓ | ✓ |
- Type de chiffrement : type de chiffrement utilisé dans la transformation d'anonymisation.
- Valeurs d'entrée acceptées : conditions minimales requises pour les valeurs d'entrée.
- Annotation de substitution:annotation spécifiée par l'utilisateur devant les valeurs chiffrées pour fournir du contexte aux utilisateurs et fournir des informations que la protection des données sensibles pourra utiliser lors de la restauration de l'identification d'une valeur anonymisée. Une annotation de substitution est requise pour la restauration de l'identification des données non structurées. Elle est facultative lors de la transformation d'une colonne de données structurées ou tabulaires avec une
RecordTransformation. - Réglage du contexte : référence à un champ de données qui "ajuste" la valeur d'entrée afin que les valeurs d'entrée identiques puissent être anonymisées avec différentes valeurs de sortie. Le réglage de contexte est facultatif lors de la transformation d'une colonne de données structurées ou tabulaires, avec une
RecordTransformation. Pour en savoir plus, consultez la section Utiliser les réglages de contexte. - Jeu de caractères et longueur préservés : lorsque la valeur anonymisée est composée du même ensemble de caractères que la valeur d'origine, et que la longueur de la valeur anonymisée correspond de sa valeur d'origine.
- Réversible : peut être restauré à l'aide de la clé de chiffrement, de l'annotation de substitution et de tout réglage du contexte.
- Intégrité référentielle : l'intégrité référentielle permet de maintenir les relations existant entre les enregistrements, même après l'anonymisation individuelle de leurs données. Avec la même clé cryptographique et le même réglage du contexte, une table de données sera remplacée par la même forme obscurcie à chaque transformation, ce qui garantit que les connexions entre les valeurs (et, avec des données structurées, des enregistrements) sont conservées, même entre les tables.
Fonctionnement de la tokenisation dans la protection des données sensibles
Le processus de base de tokenisation est le même pour les trois méthodes compatibles avec la protection des données sensibles.
Étape 1: La protection des données sensibles sélectionne les données à tokeniser. Le moyen le plus courant consiste à utiliser un détecteur d'infoType intégré ou personnalisé pour rechercher des valeurs sensibles. Si vous analysez des données structurées (telles qu'une table BigQuery), vous pouvez également effectuer une tokenisation sur des colonnes de données entières à l'aide de transformations d'enregistrement.
Pour plus d'informations sur les deux catégories de transformations (infoType et transformations d'enregistrement), consultez la section Transformations d'anonymisation.
Étape 2: À l'aide d'une clé cryptographique, la protection des données sensibles chiffre chaque valeur d'entrée. Vous pouvez fournir cette clé de l'une des trois manières suivantes :
- En l'encapsulant à l'aide de Cloud Key Management Service (Cloud KMS) (Pour une sécurité maximale, Cloud KMS est la méthode recommandée.)
- En utilisant une clé temporaire, que la protection des données sensibles génère au moment de l'anonymisation, puis la supprime. Une clé temporaire conserve uniquement l'intégrité par requête API. Si vous avez besoin d'une intégrité ou si vous prévoyez de restaurer l'identification de ces données, n'utilisez pas ce type de clé.
- Directement au format texte brut. Option déconseillée :
Pour en savoir plus, consultez la section Utiliser des clés cryptographiques plus loin dans cet article.
Étape 3 (hachage cryptographique et chiffrement déterministe avec AES-SIV uniquement) : La protection des données sensibles encode la valeur chiffrée en base64. Avec le hachage cryptographique, cette valeur chiffrée encodée est le jeton, et le processus passe à l'étape 6. Avec le chiffrement déterministe à l'aide de AES-SIV, cette valeur chiffrée et encodée est la valeur de substitution, qui est un composant du jeton. La procédure se poursuit avec l'étape 4.
Étape 4 (conservation du format et chiffrement déterministe avec AES-SIV uniquement) : La protection des données sensibles ajoute une annotation de substitution facultative à la valeur chiffrée. L'annotation de substitution permet d'identifier les valeurs de substitution chiffrées en les préfixant avec une chaîne descriptive que vous définissez. Par exemple, sans annotation, il se peut que vous ne puissiez pas distinguer un numéro de téléphone anonymisé, d'un numéro de sécurité sociale ou d'un autre numéro d'identification. En outre, pour restaurer l'identification des valeurs dans des données non structurées qui ont été anonymisées à l'aide d'un chiffrement préservant le format ou d'un chiffrement déterministe, vous devez spécifier une annotation de substitution. (Les annotations de substitution ne sont pas requises lors de la transformation d'une colonne de données structurées ou tabulaires, à l'aide d'une RecordTransformation.)
Étape 5 (conservation du format et chiffrement déterministe avec AES-SIV pour les données structurées uniquement): La protection des données sensibles peut utiliser le contexte facultatif d'un autre champ pour "ajuster" le jeton généré. Cela vous permet de modifier le champ d'application du jeton. Par exemple, supposons que vous disposiez d'une base de données de données de campagnes marketing incluant des adresses e-mail et que vous souhaitiez générer des jetons uniques pour la même adresse e-mail "réglée" par l'ID de campagne. Cela permet de joindre des données pour le même utilisateur dans la même campagne, mais pas dans différentes campagnes. Si un réglage contextuel est utilisé pour créer le jeton, ce réglage doit l'être également pour inverser les transformations d'anonymisation. Préservation des formats et chiffrement déterministe à l'aide des contextes compatibles avec AES-SIV. En savoir plus sur l'utilisation du réglage du contexte
Étape 6: La protection des données sensibles remplace la valeur d'origine par la valeur anonymisée.
Comparaison de valeurs tokenisées
Cette section montre à quoi ressemblent les jetons types après leur anonymisation à l'aide de chacune des trois méthodes décrites dans cette rubrique. L'exemple de valeur de données sensible est un numéro de téléphone d'Amérique du Nord (1-206-555-0123).
Chiffrement déterministe à l'aide de AES-SIV
Avec l'anonymisation à l'aide du chiffrement déterministe et AES-SIV, la valeur d'entrée (et éventuellement tout réglage de contexte spécifié) est chiffrée à l'aide de l'algorithme AES-SIV avec une clé cryptographique, encodée à l'aide de base64, puis éventuellement est précédée d'une annotation de substitution, si spécifiée. Cette méthode ne conserve pas le jeu de caractères (ou "alphabet") de la valeur d'entrée. Afin de générer une sortie imprimable, la valeur résultante est encodée en base64.
Le jeton résultant, en supposant qu'un infoType de substitution a été spécifié, se présente sous la forme suivante :
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
Le schéma annoté ci-dessous montre un exemple de jeton, le résultat d'une opération d'anonymisation avec un chiffrement déterministe avec AES-SIV sur la valeur 1-206-555-0123. L'infoType de substitution facultatif a été défini sur NAM_PHONE_NUMB :

- Annotation de substitution
- InfoType de substitution (défini par l'utilisateur)
- Longueur de caractère de la valeur transformée
- Valeur de substitution (transformée)
Si vous ne spécifiez pas d'annotation de substitution, le jeton obtenu est égal à la valeur transformée ou #4 dans le schéma annoté. Pour restaurer l'identification des données non structurées, l'intégralité de ce jeton est obligatoire, y compris l'annotation de substitution. Lors de la transformation de données structurées telles qu'une table, l'annotation de substitution est facultative. La protection des données sensibles peut effectuer l'anonymisation et la réidentification d'une colonne entière à l'aide d'un élément RecordTransformation sans annotation de substitution.
Chiffrement préservant le format
Avec l'anonymisation à l'aide du chiffrement préservant le format, une valeur d'entrée (et éventuellement un réglage de contexte spécifié) est chiffrée à l'aide du mode FFX du chiffrement préservant le format ("FPE-FFX") avec une clé cryptographique, puis, le cas échéant, est précédée d'une annotation de substitution.
Contrairement aux autres méthodes de tokenisation décrites dans cette rubrique, la valeur de substitution de sortie est de la même longueur que la valeur d'entrée, et elle n'est pas encodée en base64. Vous définissez le jeu de caractères, ou "alphabet", dans lequel la valeur chiffrée est composée. Il existe trois façons de spécifier l'alphabet que la protection des données sensibles doit utiliser dans la valeur de sortie:
- Utilisez l'une des quatre valeurs énumérées qui représentent les quatre jeux de caractères/alphabets les plus courants.
- Utilisez une valeur radix qui spécifie la taille de l'alphabet. La spécification de la valeur radix minimale de
2donne lieu à un alphabet composé uniquement de0et de1. La spécification de la valeur radix maximale de95génère un alphabet comprenant tous les caractères numériques, les lettres majuscules et minuscules, et les symboles. - Créez un alphabet en répertoriant les caractères exacts à utiliser. Par exemple, si vous spécifiez
1234567890-*, vous obtenez une valeur de substitution composée uniquement de nombres, de tirets et d'astérisques.
Le tableau suivant répertorie quatre ensembles de caractères courants en fonction de la valeur énumérée (FfxCommonNativeAlphabet), de la valeur radix et de la liste des caractères de l'ensemble. La dernière ligne répertorie le jeu de caractères complet, qui correspond à la valeur radix maximale.
| Nom de l'alphabet ou du jeu de caractères | Base | Liste de caractères |
|---|---|---|
NUMERIC |
10 |
0123456789 |
HEXADECIMAL |
16 |
0123456789ABCDEF |
UPPER_CASE_ALPHA_NUMERIC |
36 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
ALPHA_NUMERIC |
62 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| - | 95 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~`!@#$%^&*()_-+={[}]|\:;"'<,>.?/ |
Le jeton résultant, en supposant qu'un infoType de substitution a été spécifié, se présente sous la forme suivante :
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
Le schéma annoté suivant est le résultat d'une opération d'anonymisation de la protection des données sensibles utilisant le chiffrement préservant le format sur la valeur 1-206-555-0123 à l'aide d'une base 95. L'infoType facultatif de substitution a été défini sur NAM_PHONE_NUMB :
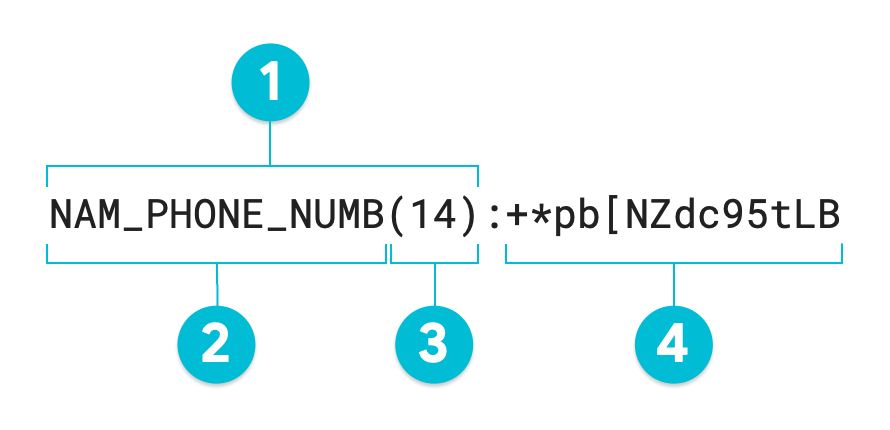
- Annotation de substitution
- InfoType de substitution (défini par l'utilisateur)
- Longueur de caractère de la valeur transformée
- Valeur de substitution (transformée) : longueur identique à la valeur d'entrée
Si vous ne spécifiez pas d'annotation de substitution, le jeton obtenu est égal à la valeur transformée ou #4 dans le schéma annoté. Pour restaurer l'identification des données non structurées, l'intégralité de ce jeton est obligatoire, y compris l'annotation de substitution. Lors de la transformation de données structurées telles qu'une table, l'annotation de substitution est facultative. La protection des données sensibles peut effectuer l'anonymisation et la réidentification d'une colonne entière à l'aide d'un élément RecordTransformation sans substitut.
Hachage cryptographique
Avec l'anonymisation à l'aide du hachage cryptographique, une valeur d'entrée est hachée au format HMAC-SHA-256 avec une clé cryptographique, puis encodée au format base64. La valeur anonymisée est toujours d'une longueur uniforme, en fonction de la taille de la clé.
Contrairement aux autres méthodes de tokenisation décrites dans cette rubrique, le hachage cryptographique crée un jeton à sens unique. Autrement dit, l'anonymisation à l'aide du hachage cryptographique ne peut pas être inversée.
Voici le résultat d'une opération d'anonymisation à l'aide du hachage cryptographique de la valeur 1-206-555-0123. Cette sortie est une représentation de la valeur hachée encodée en base64 :
XlTCv8h0GwrCZK+sS0T3Z8txByqnLLkkF4+TviXfeZY=
Utiliser les clés cryptographiques
Vous disposez de trois options pour les clés cryptographiques avec les méthodes d'anonymisation cryptographiques de la protection des données sensibles:
Clé cryptographique encapsulée par Cloud KMS: il s'agit du type de clé cryptographique le plus sécurisé pouvant être utilisé avec les méthodes d'anonymisation de la protection des données sensibles. Une clé encapsulée par Cloud KMS se compose d'une clé cryptographique de 128, 192 ou 256 bits, qui a été chiffrée à l'aide d'une autre clé. Vous fournissez la première clé cryptographique, qui est ensuite encapsulée à l'aide d'une clé cryptographique stockée dans Cloud Key Management Service. Ces types de clés sont stockés dans Cloud KMS pour une restauration ultérieure. Pour en savoir plus sur la création et l'encapsulation d'une clé à des fins d'anonymisation et de restauration de l'identification, consultez la page Guide de démarrage rapide : anonymiser et désanonymiser du texte sensible.
Clé cryptographique temporaire: une clé cryptographique temporaire est générée par la protection des données sensibles au moment de l'anonymisation, puis supprimée. Pour cette raison, veillez à ne pas utiliser une clé cryptographique temporaire avec une méthode d'anonymisation cryptographique que vous souhaitez inverser. Les clés cryptographiques temporaires ne conservent que l'intégrité par requête API. Si vous avez besoin de l'intégrité sur plusieurs requêtes API ou si vous envisagez de restaurer l'identification de vos données, n'utilisez pas ce type de clé.
Clé cryptographique non encapsulée : une clé non encapsulée est une clé cryptographique brute de 128, 192 ou 256 bits encodée en base64 que vous fournissez dans la requête d'anonymisation adressée à l'API DLP. Vous êtes responsable de la sécurité de ces types de clés cryptographiques pour une restauration ultérieure de l'identification. En raison du risque de fuite accidentelle de la clé, ces types de clés ne sont pas recommandés. Ces clés peuvent être utiles à des fins de test, mais il est recommandé d'utiliser une clé cryptographique encapsulée Cloud KMS pour les charges de travail de production.
Pour en savoir plus sur les options disponibles lors de l'utilisation de clés cryptographiques, consultez la section CryptoKey dans la documentation de référence de l'API DLP.
Utiliser des réglages de contexte
Par défaut, toutes les méthodes d'anonymisation avec transformation par cryptographie ont une intégrité référentielle, que les jetons de sortie soient à sens unique ou bidirectionnels. Autrement dit, avec la même clé cryptographique, une valeur d'entrée est toujours transformée en la même valeur chiffrée. Dans le cas où des données répétitives ou des schémas de données peuvent se produire, le risque de restauration de l'identification augmente. Pour faire en sorte que la même valeur d'entrée soit toujours transformée en une valeur chiffrée différente, vous pouvez spécifier un réglage contextuel unique.
Vous spécifiez un réglage de contexte (nommé simplement context dans l'API DLP) lors de la transformation de données tabulaires, car il s'agit en réalité d'un pointeur vers une colonne de données. , comme un identifiant.
La protection des données sensibles utilise la valeur du champ spécifié par l'ajustement du contexte lors du chiffrement de la valeur d'entrée. Pour vous assurer que la valeur chiffrée est toujours une valeur unique, spécifiez une colonne pour le réglage contenant des identifiants uniques.
Considérons cet exemple simple. Le tableau suivant présente plusieurs dossiers médicaux, dont certains incluent des ID de patient en double.
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 43789 | E11.9 |
| 5438 | 43671 | M25.531 |
| 5439 | 43789 | N39.0, I25.710 |
| 5440 | 43766 | I10 |
| 5441 | 43766 | I10 |
| 5442 | 42989 | R07.81 |
| 5443 | 43098 | I50.1, R55 |
| ... | ... | ... |
Si vous demandez à la protection des données sensibles d'anonymiser les ID des patients dans le tableau, elle anonymise les ID des patients répétés avec les mêmes valeurs par défaut, comme indiqué dans le tableau suivant. Par exemple, les deux instances de l'ID de patient "43789" sont anonymisées par "47222". (La colonne patient_id affiche les valeurs de jeton après pseudonymisation à l'aide de FPE-FFX et n'inclut pas les annotations de substitution. Pour en savoir plus, consultez la section Chiffrement préservant le format.)
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 47222 | E11.9 |
| 5438 | 82160 | M25.531 |
| 5439 | 47222 | N39.0, I25.710 |
| 5440 | 04452 | I10 |
| 5441 | 04452 | I10 |
| 5442 | 47826 | R07.81 |
| 5443 | 52428 | I50.1, R55 |
| ... | ... | ... |
Cela signifie que le champ d'application de l'intégrité référentielle se trouve sur l'intégralité de l'ensemble de données.
Pour réduire le champ d'application afin d'éviter ce comportement, spécifiez un réglage du contexte. Vous pouvez spécifier n'importe quelle colonne en tant que réglage de contexte, mais pour vous assurer que chaque valeur anonymisée est unique, spécifiez une colonne pour chaque valeur unique.
Supposons que vous souhaitiez voir si le même patient apparaît pour chaque valeur icd10_codes, mais pas si le même patient apparaît dans des valeurs icd10_codes différentes. Pour ce faire, vous devez spécifier la colonne icd10_codes comme réglage de contexte.
Voici la table après l'anonymisation de la colonne patient_id en utilisant la colonne icd10_codes comme réglage du contexte :
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 18954 | E11.9 |
| 5438 | 33068 | M25.531 |
| 5439 | 76368 | N39.0, I25.710 |
| 5440 | 29460 | I10 |
| 5441 | 29460 | I10 |
| 5442 | 23877 | R07.81 |
| 5443 | 96129 | I50.1, R55 |
| ... | ... | ... |
Notez que les quatrième et cinquième valeurs patient_id anonymisées (29460) sont identiques, car non seulement les valeurs patient_id d'origine étaient identiques, mais les valeurs icd10_codes des deux lignes l'étaient également. Étant donné que vous deviez effectuer une analyse avec des ID de patient cohérents dans le champ d'application de la valeur icd10_codes, ce comportement est ce que vous recherchez.
Pour dissocier complètement l'intégrité référentielle entre les valeurs patient_id et icd10_codes, utilisez plutôt la colonne record_id comme réglage de contexte :
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 15826 | E11.9 |
| 5438 | 61722 | M25.531 |
| 5439 | 34424 | N39.0, I25.710 |
| 5440 | 02875 | I10 |
| 5441 | 52549 | I10 |
| 5442 | 17945 | R07.81 |
| 5443 | 19030 | I50.1, R55 |
| ... | ... | ... |
Notez que chaque valeur patient_id anonymisée de la table est maintenant unique.
Pour découvrir comment utiliser les réglages de contexte dans l'API DLP, notez l'utilisation de context dans les rubriques de référence suivantes sur la méthode de transformation :
- Chiffrement préservant le format :
CryptoReplaceFfxFpeConfig - Chiffrement déterministe à l'aide de l'algorithme AES-SIV :
CryptoDeterministicConfig - Changement de date :
DateShiftConfig
Étapes suivantes
Consultez des exemples de code montrant comment tokeniser les données sensibles.
Apprenez à anonymiser des données à l'aide de l'API DLP.