仮名化は、機密データの値を暗号で生成されるトークンに置き換える匿名化手法です。仮名化は金融や医療などの業界で広く使用されており、使用中のデータのリスクを軽減し、コンプライアンスの範囲を狭め、データのユーティリティと精度を維持しつつ機密データがシステムに公開されるのを最小限に抑えるうえで有用です。
機密データの保護は、匿名化の 3 つの仮名化手法をサポートしており、3 つの暗号変換メソッドのいずれかを元の機密データの値に適用してトークンを生成します。元の機密値はそれぞれ対応するトークンに置き換えられます。仮名化は、トークン化やサロゲート置換と呼ばれることもあります。
仮名化手法では、一方向または双方向のいずれかでトークンを有効にできます。一方向の場合は不可逆的に変換され、双方向の場合は可逆的に変換されます。トークンは対称暗号化を使用して作成されるため、新しいトークンを生成できる同じ暗号鍵でトークンを元に戻すこともできます。元に戻す必要がない場合は、安全なハッシュ メカニズムを使用する一方向トークンを使用できます。
仮名化によって機密データが保護され、ビジネス オペレーションと分析ワークフローで必要なデータに簡単にアクセスして使用できるようにする仕組みを理解することは有用です。このトピックでは、仮名化の概念と、機密データの保護でサポートされているデータを変換するための 3 つの暗号化方法について説明します。
これらの仮名化メソッドの実装方法と機密データの保護のその他の使用例については、機密データの匿名化をご覧ください。
機密データの保護でサポートされている暗号方法
機密データの保護は、3 つの仮名化手法をサポートしており、そのすべてが暗号化キーを使用します。使用可能な方法は次のとおりです。
- AES-SIV を使用した確定的暗号化: 入力値は、AES-SIV 暗号化アルゴリズムを使用して暗号化された値に置き換えられます。暗号鍵を base64 でエンコードし、必要に応じてサロゲート アノテーションを付加します。この方法はハッシュ値を生成するため、文字セットや入力値の長さを保持しません。暗号化された値は、元の暗号鍵とサロゲート アノテーションを含む出力値全体を使用して再識別できます。AES-SIV 暗号化を使用してトークン化される値の形式について確認してください。
- フォーマット保持暗号化: 入力値は、FPE-FFX 暗号化アルゴリズムと暗号鍵を使用して暗号化された値に置き換えられ、指定された場合は、サロゲート アノテーションが先頭に付加されます。設計では、文字セットと入力値の長さの両方が出力値に保持されます。暗号化された値は、元の暗号鍵とサロゲート アノテーションを含む出力値全体を使用して再識別できます。この暗号化方式の使用に関する重要な検討事項については、このトピックで後述するフォーマット保持暗号化をご覧ください。
- 暗号ハッシュ: ハッシュベースのメッセージ認証コード(HMAC)- セキュア ハッシュ アルゴリズム(SHA)-256 を使用して暗号鍵で入力値を暗号化し、ハッシュ化した値で元の入力値を置き換えます。変換のハッシュ出力は常に同じ長さとなり、再識別できません。詳細については、暗号ハッシュを使用してトークン化される値の形式をご覧ください。
次の表に、これらの仮名化手法の概要を示します。表の行については、表の後で説明します。
| AES-SIV を使用した確定的暗号化 | フォーマット保持暗号化 | 暗号ハッシュ | |
|---|---|---|---|
| 暗号化のタイプ | AES-SIV | FPE-FFX | HMAC-SHA-256 |
| サポートされる入力値 | 1 文字以上。文字セットの制限はありません。 | 2 文字以上。ASCII としてエンコードする必要があります。 | 文字列または整数値となる必要があります。 |
| サロゲート アノテーション | 省略可。 | 省略可。 | なし |
| コンテキスト微調整 | 省略可。 | 省略可。 | なし |
| 文字セットと長さを保持 | ✗ | ✓ | ✗ |
| 復元可能 | ✓ | ✓ | ✗ |
| 参照整合性 | ✓ | ✓ | ✓ |
- 暗号化のタイプ: 匿名化変換で使用される暗号化のタイプ。
- サポートされる入力値: 入力値の最小要件。
- サロゲート アノテーション: ユーザーに対してコンテキストを示し、匿名化された値の再識別に使用する機密データの保護に関する情報を提供するために、暗号化された値の先頭に付加されるユーザーが指定するアノテーション。サロゲート アノテーションは、非構造化データの再識別に必要です。
RecordTransformationを使用して構造化データ、または表形式のデータの列を変換する場合は省略可能です。 - コンテキスト調整: 入力値を「微調整」して、異なる出力値で同一の入力値を再識別できるようにするデータ フィールドへの参照。
RecordTransformationを使用して、構造化データまたは表形式データの列を変換する場合、コンテキストの微調整は省略可能です。詳細については、コンテキスト微調整の使用をご覧ください。 - 文字セットと長さの保持: 匿名化された値が元の値と同じ文字セットで構成されているかどうか、および匿名化された値の長さが元の値の長さと一致するかどうか。
- 復元可能: 暗号鍵、サロゲート アノテーション、コンテキストの微調整を使用して再識別できます。
- 参照整合性: 参照整合性を使用すると、データを個別に匿名化した後でも、レコード同士の関係を維持できます。同じ暗号鍵とコンテキスト微調整が指定された場合、変換されるたびにデータのテーブルは難読化された形式に置き換えられます。これにより、テーブル間でも値(構造化データ、レコードを含む)間の接続が保持されます。
機密データの保護でのトークン化の仕組み
トークン化の基本的なプロセスは、機密データの保護でサポートされている 3 つの手法すべてで同じです。
ステップ 1: 機密データの保護で、トークン化するデータを選択します。これを行う最も一般的な方法は、組み込みまたはカスタムの infoType 検出器を使用して目的の機密データ値を照合することです。構造化データ(BigQuery テーブルなど)をスキャンする場合は、レコード変換を使用してデータの列全体に対してトークン化を実行することもできます。
変換の 2 つのカテゴリ(infoType とレコード変換)の詳細については、匿名化変換をご覧ください。
ステップ 2: 暗号鍵を使用して、機密データの保護で各入力値を暗号化します。この鍵は、次の 3 つの方法のいずれかで指定します。
- Cloud Key Management Service(Cloud KMS)を使用してラップする(最大限のセキュリティを確保するため、Cloud KMS の使用をおすすめします)。
- 一時的な鍵を使用。この鍵は、匿名化時に機密データの保護によって作成され、その後破棄されます。一時的な鍵は、API リクエスト単位でのみ整合性を保持します。整合性が必要な場合や、このデータを再識別する予定がある場合は、この鍵タイプを使用しないでください。
- 未加工のテキスト形式で直接作成する。(おすすめしません。)
詳細については、このトピックで後述する暗号鍵の使用をご覧ください。
ステップ 3(AES-SIV による暗号ハッシュと確定的暗号化のみ): 機密データの保護により、暗号化された値を base64 を使用してエンコードします。暗号ハッシュでは、エンコードされ暗号化されたこの値がトークンになり、プロセスはステップ 6 に進みます。AES-SIV を使用した確定的暗号化では、このエンコードされ暗号化された値は、トークンの 1 つのコンポーネントであるサロゲート値になります。プロセスは、手順 4 に進みます。
ステップ 4(AES-SIV によるフォーマット保持暗号化と確定的暗号化のみ): 機密データの保護により、暗号化された値にオプションのサロゲート アノテーションを追加します。サロゲート アノテーションは、ユーザーが定義したわかりやすい文字列を付加することによって、暗号化されたサロゲート値を識別します。たとえば、アノテーションがないと、匿名化された電話番号と匿名化されていない社会保障番号などの ID 番号を識別できません。さらに、フォーマット保持暗号化または確定的暗号化のいずれかを使用して匿名化された非構造化データの値を再識別するには、サロゲート アノテーションを指定する必要があります。(RecordTransformation を使用して構造化データまたは表形式データの列を変換する場合は、サロゲート アノテーションは不要です)。
ステップ 5(構造化データの AES-SIV によるフォーマット保持暗号化と確定的暗号化のみ): 機密データの保護により、別のフィールドのオプションのコンテキストを使用して、生成されたトークンを「微調整」します。これにより、トークンの範囲を変更できます。たとえば、メールアドレスを含むマーケティング キャンペーン データのデータベースがあり、キャンペーン ID によって「微調整」された同じメールアドレスに対して一意のトークンを生成するとします。この場合、同じキャンペーン内で同一ユーザーのデータを結合することはできますが、異なるキャンペーン間でデータを結合することはできません。トークンの作成にコンテキストの微調整が使用されている場合、匿名化変換を元に戻すには、このコンテキスト調整も必要です。AES-SIV サポート コンテキストを使用したフォーマット保存および確定的暗号化。詳しくは、コンテキストの微調整の使用をご覧ください。
ステップ 6: 機密データの保護で、元の値を匿名化された値に置き換えます。
トークン化された値の比較
このセクションでは、このトピックで説明する 3 つの方法をそれぞれ使用して匿名化した場合に、一般的なトークンがどのように表示されるかを示します。機密データの値の例は、北米の電話番号(1-206-555-0123)です。
AES-SIV を使用した確定的暗号化
確定的暗号化と AES-SIV による匿名化では、入力値(および必要に応じて指定されたコンテキストの微調整)が、AES-SIV と暗号鍵を使用して暗号化され、base64 でエンコードされて、指定されている場合は必要に応じてサロゲート アノテーションが先頭に付加されます。この方法では、入力値の文字セット(「アルファベット」)を保持しません。印刷可能な出力を生成するために、結果の値は base64 でエンコードされます。
サロゲート infoType が指定されていると仮定した場合に、生成されるトークンの形式は次のとおりです。
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
次のアノテーションが付加された図は、トークンの例(1-206-555-0123 の値に対して AES-SIV による確定的暗号化を使用した匿名化オペレーションの出力)を示しています。オプションのサロゲート infoType は、NAM_PHONE_NUMB に設定されています。

- サロゲート アノテーション
- サロゲート infoType(ユーザー定義)
- 変換された値の文字数
- サロゲート(変換済み)値
サロゲート アノテーションを指定しない場合、生成されるトークンは変換後、またはアノテーション付きの図 #4 と同じです。非構造化データを再識別するには、サロゲート アノテーションを含むこのトークン全体が必要です。テーブルなどの構造化データを変換する場合、サロゲート アノテーションは省略可能です。機密データの保護では、サロゲート アノテーションなしで RecordTransformation を使用して、列全体に対して匿名化と再識別の両方を実行できます。
フォーマット保持暗号化
フォーマット保持暗号化による匿名化では、入力値(必要に応じて指定されたコンテキスト微調整)が、FFX モードのフォーマット保持暗号化(FPE-FFX)を使用して、暗号鍵で暗号化されます。その後、必要に応じてサロゲート アノテーションを付加します(指定された場合)。
このトピックで説明するトークン化の他の方法とは異なり、出力サロゲート値は入力値と同一の長さであり、base64 でエンコードされていません。暗号化された値を構成する文字セット(「アルファベット」)を定義します。出力値で使用する 機密データの保護のアルファベットを指定するには、次の 3 つの方法があります。
- 最も一般的な 4 つの文字セットまたはアルファベットを表す 4 つの列挙値のいずれかを使用する。
- アルファベットのサイズを指定する基数値を使用する。
2の最小基数値を指定すると、0と1のみで構成されるアルファベットが生成されます。95の最大基数値を指定すると、すべての数字、大文字の英字、小文字の英字、記号を含むアルファベットが生成されます。 - 使用する正確な文字を一覧にしてアルファベットを構築します。たとえば、
1234567890-*を指定すると、サロゲート値は数値、ハイフン、アスタリスクのみで構成されます。
以下の表では、4 つの一般的な文字セットをそれぞれの列挙値(FfxCommonNativeAlphabet)、基数値、セット内の文字のリスト別に示しています。最後の行には、最大基数値に対応する完全な文字セットが表示されます。
| アルファベットまたは文字セット名 | Radix | 文字リスト |
|---|---|---|
NUMERIC |
10 |
0123456789 |
HEXADECIMAL |
16 |
0123456789ABCDEF |
UPPER_CASE_ALPHA_NUMERIC |
36 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
ALPHA_NUMERIC |
62 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| - | 95 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~`!@#$%^&*()_-+={[}]|\:;"'<,>.?/ |
サロゲート infoType が指定されていると仮定した場合に、生成されるトークンの形式は次のとおりです。
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
次のアノテーション付きの図は、95 の基数を使用し値 1-206-555-0123 に対してフォーマット保持暗号化を使用した、機密データの保護の匿名化オペレーションの出力です。オプションのサロゲート infoType は、NAM_PHONE_NUMB に設定されています。
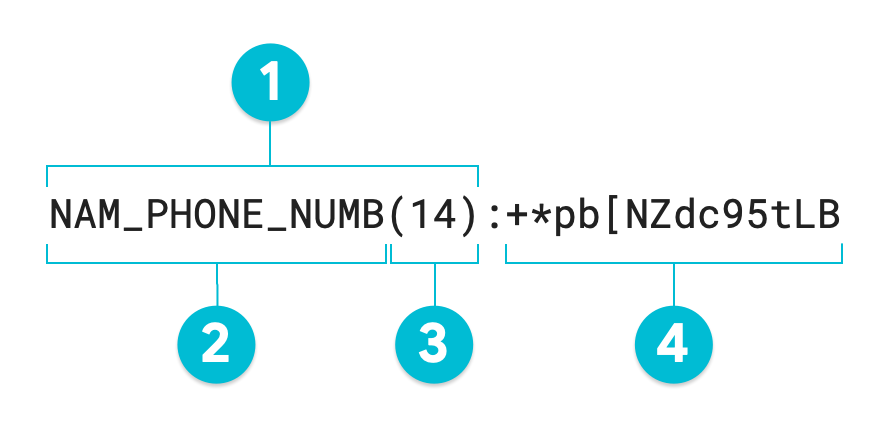
- サロゲート アノテーション
- サロゲート infoType(ユーザー定義)
- 変換された値の文字数
- サロゲート(変換済み)値 - 入力値と同じ長さ
サロゲート アノテーションを指定しない場合、生成されるトークンは変換後、またはアノテーション付きの図 #4 と同じです。非構造化データを再識別するには、サロゲート アノテーションを含むこのトークン全体が必要です。テーブルなどの構造化データを変換する場合、サロゲート アノテーションは省略可能です。機密データの保護では、サロゲートなしで RecordTransformation を使用して、列全体に対して匿名化と再識別の両方を実行できます。
暗号ハッシュ
暗号化ハッシュを使用した匿名化では、入力値は HMAC-SHA-256 を使用して暗号鍵によってハッシュ化され、base64 を使用してエンコードされます。匿名化された値の長さは常に、鍵のサイズに応じて均一です。
このトピックで説明する他のトークン化方法とは異なり、暗号ハッシュは一方向トークンを作成します。つまり、暗号化ハッシュを使用した匿名化は元に戻せません。
以下に示すのは、値 1-206-555-0123 に対して暗号化ハッシュを使用した匿名化オペレーションの出力です。この出力は、ハッシュ値の base64 エンコード表現です。
XlTCv8h0GwrCZK+sS0T3Z8txByqnLLkkF4+TviXfeZY=
暗号鍵の使用
機密データの保護で暗号匿名化手法に使用できる暗号鍵には、次の 3 つのオプションがあります。
Cloud KMS でラップされた暗号鍵: 機密データの保護の匿名化手法で使用できる最も安全なタイプの暗号鍵です。Cloud KMS でラップされた鍵は、別の鍵を使用して暗号化された 128 ビット、192 ビット、256 ビットの暗号鍵で構成されます。最初の暗号鍵を指定し、次に Cloud Key Management Service に保存されている暗号鍵を使用してラップします。このような鍵は、後で再識別できるように Cloud KMS に保存されます。匿名化と再識別の目的で鍵を作成してラップする方法について詳しくは、クイックスタート: 機密テキストの匿名化と再識別をご覧ください。
一時的な暗号鍵: 一時的な暗号鍵は、匿名化の際に機密データの保護によって生成され、後に破棄されます。このため、元に戻すことを必要とする暗号匿名化の方法で一時的な暗号鍵を使用しないでください。一時的な暗号鍵は、API リクエスト単位でのみ整合性を保持します。複数の API リクエスト間で整合性が必要な場合や、データを再識別する予定がある場合は、この鍵タイプを使用しないでください。
ラップ解除された暗号鍵: ラップ解除された鍵は、DLP API への匿名化リクエスト内で指定した base64 でエンコードされた 128 ビット、192 ビット、または 256 ビットの未加工の暗号鍵です。後で再識別できるように、これらの種類の暗号鍵を安全に保持する必要があります。鍵が誤って漏洩するリスクがあるため、これらのタイプの鍵はおすすめしません。これらの鍵はテストでは有用であることが考えられますが、本番環境ワークロードの場合は、代わりに Cloud KMS でラップされた暗号鍵を使用することをおすすめします。
暗号鍵を使用するときに使用できるオプションの詳細については、DLP API リファレンスの CryptoKey をご覧ください。
コンテキストの微調整を使用する
デフォルトでは、出力トークンが一方向か双方向かにかかわらず、すべての匿名化の暗号変換方式に参照整合性があります。つまり、暗号鍵が同じであれば、入力値は常に同じ暗号化された値に変換されます。繰り返しデータやデータパターンが発生する可能性がある状況では、再識別のリスクが高まります。同じ入力値が、常に異なる暗号化された値に変換されないようにするには、一意のコンテキスト微調整を指定します。
テーブルデータを変換する場合はコンテキスト微調整(DLP API では単に context と呼ばれます)を指定します。これは、微調整は実質的にデータ列へのポインタ(識別子など)であるためです。機密データの保護では、入力値を暗号化するときに、コンテキストの微調整で指定されたフィールドの値を使用します。暗号化された値が常に一意の値になるようにするには、一意の ID を含む微調整用の列を指定します。
次の簡単な例を考えてみましょう。次のテーブルは、いくつかの医療記録を示しています。そのうちのいくつかには、重複した患者 ID が含まれています。
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 43789 | E11.9 |
| 5438 | 43671 | M25.531 |
| 5439 | 43789 | N39.0, I25.710 |
| 5440 | 43766 | I10 |
| 5441 | 43766 | I10 |
| 5442 | 42989 | R07.81 |
| 5443 | 43098 | I50.1, R55 |
| … | … | … |
テーブル内の患者 ID を匿名化するよう機密データの保護に指示すると、次の表に示すように、繰り返しの患者 ID が同じ値に匿名化されます。たとえば、患者 ID「43789」の両方のインスタンスが「47222」として匿名化されます。(patient_id 列には、FPE-FFX を使用して仮名化を行った後のトークン値が表示され、サロゲート アノテーションは含まれません。詳細については、フォーマット保持暗号化をご覧ください)。
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 47222 | E11.9 |
| 5438 | 82160 | M25.531 |
| 5439 | 47222 | N39.0, I25.710 |
| 5440 | 04452 | I10 |
| 5441 | 04452 | I10 |
| 5442 | 47826 | R07.81 |
| 5443 | 52428 | I50.1, R55 |
| … | … | … |
つまり、参照整合性のスコープはデータセット全体です。
この動作を回避するためにスコープを絞り込むには、コンテキストの微調整を指定します。 任意の列をコンテキスト微調整として指定できますが、匿名化された各値が一意であることを保証するには、すべての値が一意である列を指定します。
icd10_codes 値ごとに同じ患者が表示されるようにしつつ、異なる icd10_codes 値に対して同じ患者が表示されることがないようにすると仮定します。そのためには、コンテキスト微調整として icd10_codes 列を指定します。
これは、コンテキスト微調整として icd10_codes 列を使用して、patient_id 列を匿名化した後のテーブルです。
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 18954 | E11.9 |
| 5438 | 33068 | M25.531 |
| 5439 | 76368 | N39.0, I25.710 |
| 5440 | 29460 | I10 |
| 5441 | 29460 | I10 |
| 5442 | 23877 | R07.81 |
| 5443 | 96129 | I50.1, R55 |
| … | … | … |
4 番目と 5 番目の匿名化された patient_id 値(29460)は同じです。これは、元の patient_id 値が同じであるだけでなく、両方の行の icd10_codes 値も同一であったためです。ここでは、icd10_codes 値のスコープ内で一貫した患者 ID を使用して分析を実行する必要があるため、これが必要とする動作です。
patient_id 値と icd10_codes 値の間で参照整合性を完全に確保するには、代わりに record_id 列をコンテキスト微調整として使用します。
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 15826 | E11.9 |
| 5438 | 61722 | M25.531 |
| 5439 | 34424 | N39.0, I25.710 |
| 5440 | 02875 | I10 |
| 5441 | 52549 | I10 |
| 5442 | 17945 | R07.81 |
| 5443 | 19030 | I50.1, R55 |
| … | … | … |
テーブル内の匿名化された patient_id 値は、それぞれ一意の値となっています。
DLP API でコンテキスト微調整を使用する方法を確認する場合は、次の変換メソッドのリファレンス トピックでの context の使用方法に注意してください。
- フォーマット保持暗号化:
CryptoReplaceFfxFpeConfig - AES-SIV を使用した確定的暗号化:
CryptoDeterministicConfig - 日付シフト:
DateShiftConfig
次のステップ
ラップされた鍵の作成、コンテンツのトークン化、トークン化されたコンテンツの再識別の方法を示すエンドツーエンドの例を確認する。
機密データのトークン化方法を示すコードサンプルを参照する。
DLP API を使用してデータを匿名化する方法を学習します。