En esta página, se muestra cómo crear un clúster de Dataproc que use el Conector de Spanner de Spark para leer datos de Spanner con Apache Spark
Calcula los costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
- Dataproc
- Spanner
- Cloud Storage
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
Antes de usar el conector de Spanner en este instructivo, configura un clúster de Dataproc, una instancia y una base de datos de Spanner.
Configura un clúster de Dataproc
Crea un clúster de Dataproc o usa uno existente que tenga la siguiente configuración:
Permisos de la cuenta de servicio de la VM. Se deben asignar los permisos de Spanner adecuados a la cuenta de servicio de VM del clúster. Si usas Data Boost (Data Boost está habilitado en el código de ejemplo de Cómo leer datos de Spanner), la cuenta de servicio de la VM también debe tener los permisos de IAM de Data Boost necesarios.
Alcance del acceso. El clúster debe crearse con el alcance
cloud-platformo el alcancespannerapropiado habilitado. El alcance decloud-platformestá habilitado de forma predeterminada para los clústeres creados con la versión de imagen 2.1 o una posterior.En las siguientes instrucciones, se muestra cómo configurar el alcance de
cloud-platformcomo parte de una solicitud de creación de clúster que usa la consola de Google Cloud, gcloud CLI o la API de Dataproc. Para obtener más instrucciones sobre la creación de clústeres, consulta Crea un clúster.Consola de Google Cloud
- En la consola de Google Cloud, abre la página Crea un clúster de Dataproc.
- En el panel Administrar seguridad, en la sección Acceso al proyecto, haz clic en "Habilita el alcance de la plataforma de nube para este clúster".
- Completa o confirma los otros campos de creación del clúster y, luego, haz clic en Crear.
gcloud CLI
Puedes ejecutar el siguiente comando
gcloud dataproc clusters createpara crear un clúster con el permisocloud-platformhabilitado.gcloud dataproc clusters create CLUSTER_NAME --scopes https://www.googleapis.com/auth/cloud-platform
API
Puedes especificar GceClusterConfig.serviceAccountScopes como parte de una solicitud clusters.create.
"serviceAccountScopes": "https://www.googleapis.com/auth/cloud-platform"
Configura una instancia de Spanner con una tabla de base de datos Singers
Crea una instancia de Spanner con una base de datos que contenga una tabla Singers. Anota el ID de la instancia y el ID de la base de datos de Spanner.
Usa el conector de Spanner con Spark
El conector de Spanner está disponible para las versiones 3.1+ de Spark.
Especificas la versión del conector como parte de la especificación del archivo JAR del conector de Cloud Storage cuando envías un trabajo a un clúster de Dataproc.
Ejemplo: Envío de un trabajo de Spark con la CLI de gcloud con el conector de Spanner
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar \ ... [other job submission flags]
Reemplaza lo siguiente:
CONNECTOR_VERSION: Es la versión del conector de Spanner.
Elige la versión del conector de Spanner de la lista de versiones en el repositorio GoogleCloudDataproc/spark-spanner-connector de GitHub.
Lee datos de Spanner
Puedes usar Python o Scala para leer datos de Spanner en un DataFrame de Spark con la API de fuente de datos de Spark.
PySpark
Para ejecutar el código de ejemplo de PySpark en esta sección en tu clúster, envía el trabajo al servicio de Dataproc o ejecútalo desde la REPL de spark-submit en el nodo principal del clúster.
Trabajo de Dataproc
- Crea un archivo
singers.pycon un editor de texto local o en Cloud Shell con el editor de textovi,vimonanopreinstalado. - Pega el siguiente código en el archivo
singers.py. Ten en cuenta que la función Data Boost de Spanner está habilitada, lo que tiene un impacto casi nulo en la instancia principal de Spanner.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()Reemplaza lo siguiente:
- PROJECT_ID: El Google Cloud ID de tu proyecto. Los IDs de los proyectos se enumeran en la sección Información del proyecto en el panel de la consola de Google Cloud.
- INSTANCE_ID, DATABASE_ID y TABLE_NAME : Consulta Cómo configurar una instancia de Spanner con la tabla de base de datos
Singers.
- Guarda el archivo
singers.py. - Envía el trabajo al servicio de Dataproc con la consola de Google Cloud, gcloud CLI o la API de Dataproc.
Ejemplo: Envío de trabajos de la CLI de gcloud con el conector de Spanner
gcloud dataproc jobs submit pyspark singers.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSIONReemplaza lo siguiente:
- CLUSTER_NAME el nombre del clúster nuevo.
- REGION: Una región de Compute Engine disponible para ejecutar la carga de trabajo.
- CONNECTOR_VERSION: Es la versión del conector de Spanner.
Elige la versión del conector de Spanner de la lista de versiones en el repositorio
GoogleCloudDataproc/spark-spanner-connectorde GitHub.
Trabajo spark-submit
- Conéctate al nodo principal del clúster de Dataproc mediante SSH.
- Ve a la página Clústeres de Dataproc en la consola de Google Cloud y, luego, haz clic en el nombre de tu clúster.
- En la página Detalles del clúster, selecciona la pestaña Instancias de VM. Luego, haz clic en
SSHa la derecha del nombre del nodo principal del clúster.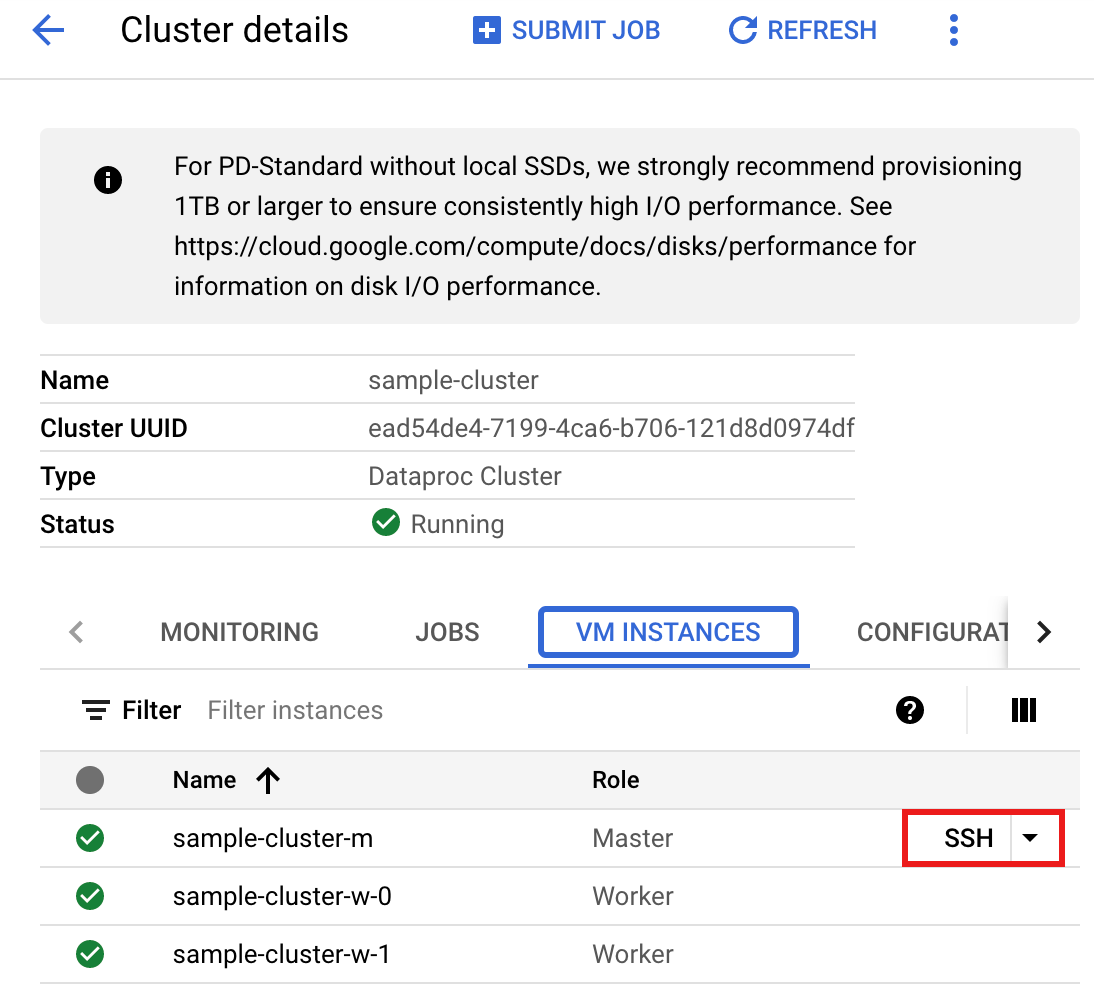
Se abrirá una ventana del navegador en tu directorio principal del nodo.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Crea un archivo
singers.pyen el nodo principal con el editor de textovi,vimonanopreinstalado.- Pega el siguiente código en el archivo
singers.py. Ten en cuenta que la función Data Boost de Spanner está habilitada, lo que tiene un impacto casi nulo en la instancia principal de Spanner.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()Reemplaza lo siguiente:
- PROJECT_ID: El Google Cloud ID de tu proyecto. Los IDs de los proyectos se enumeran en la sección Información del proyecto en el panel de la consola de Google Cloud.
- INSTANCE_ID, DATABASE_ID y TABLE_NAME : Consulta Cómo configurar una instancia de Spanner con la tabla de base de datos
Singers.
- Guarda el archivo
singers.py.
- Pega el siguiente código en el archivo
- Ejecuta
singers.pyconspark-submitpara crear la tablaSingersde Spanner.spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
Reemplaza lo siguiente:
- CONNECTOR_VERSION: Es la versión del conector de Spanner.
Elige la versión del conector de Spanner de la lista de versiones en el repositorio
GoogleCloudDataproc/spark-spanner-connectorde GitHub.
El resultado es el siguiente:
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- CONNECTOR_VERSION: Es la versión del conector de Spanner.
Elige la versión del conector de Spanner de la lista de versiones en el repositorio
Scala
Para ejecutar el ejemplo de código Scala en tu clúster, completa los siguientes pasos:
- Conéctate al nodo principal del clúster de Dataproc mediante SSH.
- Ve a la página Clústeres de Dataproc en la consola de Google Cloud y, luego, haz clic en el nombre de tu clúster.
- En la página Detalles del clúster, selecciona la pestaña Instancias de VM. Luego, haz clic en
SSHa la derecha del nombre del nodo principal del clúster.
Se abrirá una ventana del navegador en tu directorio principal del nodo.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Crea un archivo
singers.scalaen el nodo principal con el editor de textovi,vimonanopreinstalado.- Pega el siguiente código en el archivo
singers.scala. Ten en cuenta que la función de Data Boost de Spanner está habilitada, lo que tiene un impacto casi nulo en la instancia principal de Spanner.object singers { def main(): Unit = { /* * Uncomment (use the following code) if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .option("enableDataBoost", true) .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }Reemplaza lo siguiente:
- PROJECT_ID: El Google Cloud ID de tu proyecto. Los IDs de los proyectos se enumeran en la sección Información del proyecto en el panel de la consola de Google Cloud.
- INSTANCE_ID, DATABASE_ID y TABLE_NAME : Consulta Cómo configurar una instancia de Spanner con la tabla de base de datos
Singers.
- Guarda el archivo
singers.scala.
- Pega el siguiente código en el archivo
- Inicia el REPL de
spark-shell.$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
Reemplaza lo siguiente:
CONNECTOR_VERSION: Es la versión del conector de Spanner. Elige la versión del conector de Spanner de la lista de versiones en el repositorio
GoogleCloudDataproc/spark-spanner-connectorde GitHub. - Ejecuta
singers.scalacon el comando:load singers.scalapara crear la tablaSingersde Spanner. La lista de salida muestra ejemplos del resultado de Singers.> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
Limpieza
Para evitar que se apliquen cargos continuos a tu Google Cloud cuenta, puedes detener o borrar tu clúster de Dataproc y borrar tu instancia de Spanner.