En este documento, se describe cómo instalar y usar la extensión de JupyterLab en una máquina o VM autoadministrada que tenga acceso a los servicios de Google. También se describe cómo desarrollar e implementar código de notebooks de Spark sin servidores.
Instala la extensión en cuestión de minutos para aprovechar las siguientes funciones:
- Inicia notebooks de Spark y BigQuery sin servidores para desarrollar código rápidamente
- Explora y obtén una vista previa de los conjuntos de datos de BigQuery en JupyterLab
- Edita archivos de Cloud Storage en JupyterLab
- Programa un notebook en Composer
Antes de comenzar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc API.
-
Install the Google Cloud CLI.
-
Si usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc API.
-
Install the Google Cloud CLI.
-
Si usas un proveedor de identidad externo (IdP), primero debes acceder a gcloud CLI con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init Descarga e instala la versión 3.11 o posterior de Python desde
python.org/downloads.- Verifica la instalación de Python 3.11 o una versión posterior.
python3 --version
- Verifica la instalación de Python 3.11 o una versión posterior.
Virtualiza el entorno de Python.
pip3 install pipenv
- Crea una carpeta de instalación.
mkdir jupyter
- Cambia a la carpeta de instalación.
cd jupyter
- Crea un entorno virtual.
pipenv shell
- Crea una carpeta de instalación.
Instala JupyterLab en el entorno virtual.
pipenv install jupyterlab
Instala la extensión de JupyterLab.
pipenv install bigquery-jupyter-plugin
jupyter lab
La página del Launcher de JupyterLab se abre en tu navegador. Contiene una sección de Trabajos y sesiones de Dataproc. También puede contener secciones de Notebooks de Serverless para Apache Spark y Notebooks de clústeres de Dataproc si tienes acceso a notebooks de Serverless Dataproc o clústeres de Dataproc con el componente opcional de Jupyter en ejecución en tu proyecto.
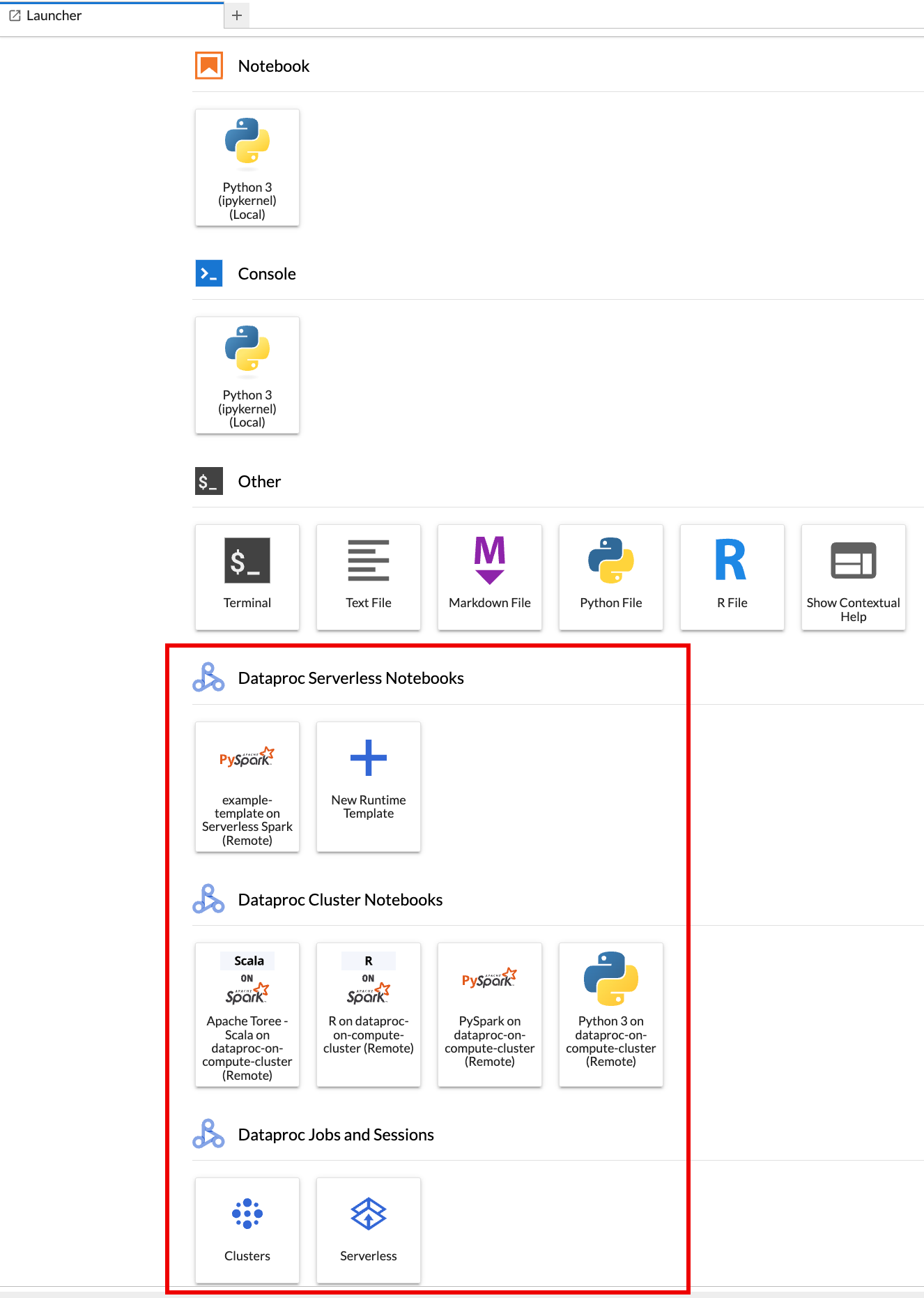
De forma predeterminada, tu sesión interactiva de Serverless para Apache Spark se ejecuta en el proyecto y la región que estableciste cuando ejecutaste
gcloud initen Antes de comenzar. Puedes cambiar la configuración del proyecto y la región de tus sesiones desde Configuración > Google Cloud Configuración > Google Cloud Configuración del proyecto de JupyterLab.Debes reiniciar la extensión para que se apliquen los cambios.
Haz clic en la tarjeta
New runtime templateen la sección Notebooks sin servidores para Apache Spark de la página Launcher de JupyterLab.
Completa el formulario de Plantilla de entorno de ejecución.
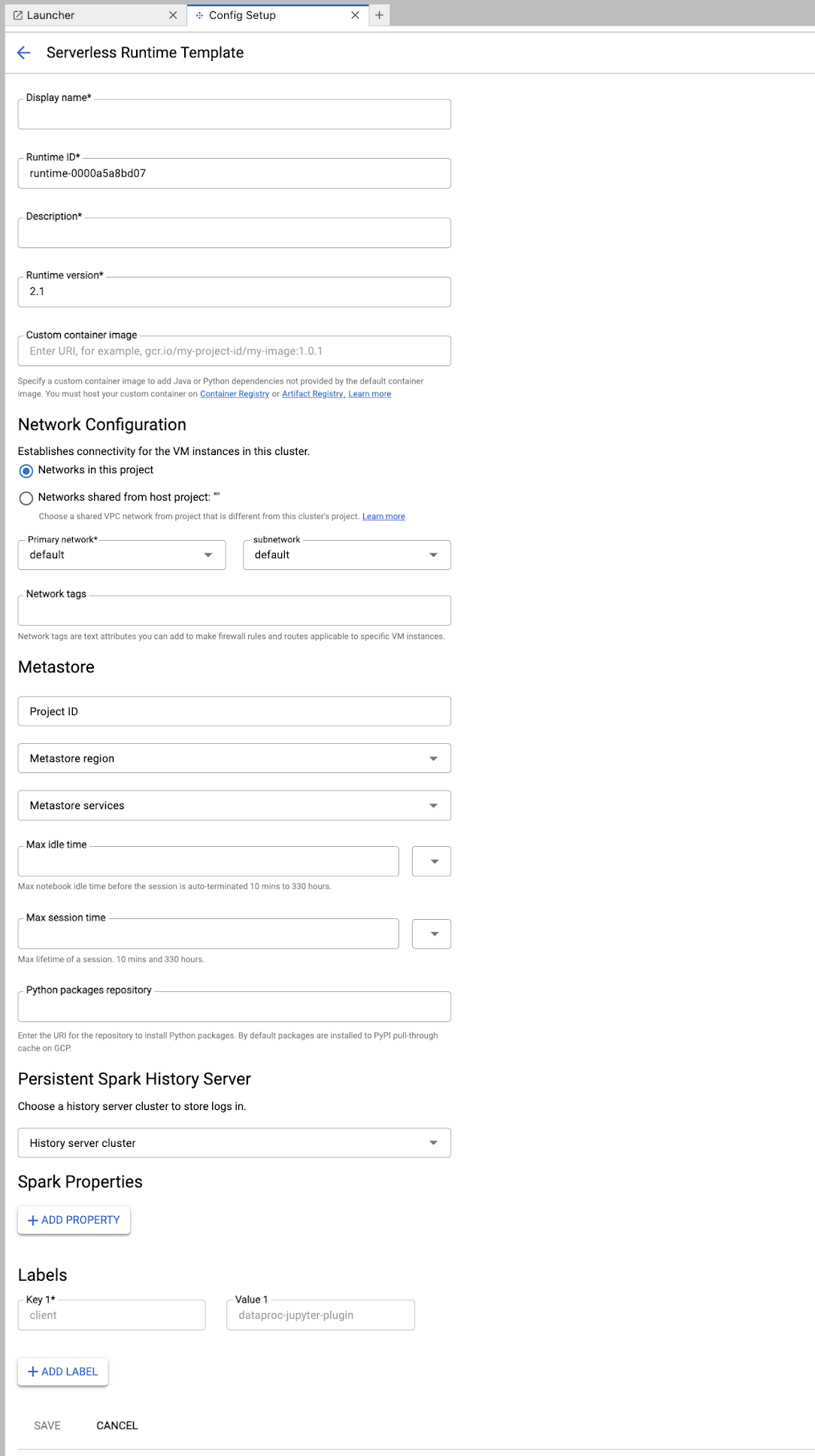
Información de la plantilla:
- Nombre visible, ID de tiempo de ejecución y Descripción: Acepta o completa un nombre visible, un ID de tiempo de ejecución y una descripción de la plantilla.
Configuración de ejecución: Selecciona Cuenta de usuario para ejecutar notebooks con la identidad del usuario en lugar de la identidad de la cuenta de servicio de Dataproc.
- Cuenta de servicio: Si no especificas una cuenta de servicio, se usa la cuenta de servicio predeterminada de Compute Engine.
- Versión del entorno de ejecución: Confirma o selecciona la versión del entorno de ejecución.
- Imagen de contenedor personalizada: De manera opcional, especifica el URI de una imagen de contenedor personalizada.
- Bucket de etapa de pruebas: De manera opcional, puedes especificar el nombre de un bucket de etapa de pruebas de Cloud Storage para que lo use Serverless for Apache Spark.
- Repositorio de paquetes de Python: De forma predeterminada, los paquetes de Python se descargan y se instalan desde la caché de extracción de PyPI cuando los usuarios ejecutan comandos de instalación de
pipen sus notebooks. Puedes especificar el repositorio de artefactos privados de tu organización para los paquetes de Python y usarlo como el repositorio predeterminado de paquetes de Python.
Encriptación: Acepta el valor predeterminado Google-owned and Google-managed encryption key o selecciona Clave de encriptación administrada por el cliente (CMEK). Si es CMEK, selecciona o proporciona la información de la clave.
Configuración de red: Selecciona una subred en el proyecto o compartida desde un proyecto host (puedes cambiar el proyecto desde Configuración > Google Cloud Configuración > Google Cloud Configuración del proyecto de JupyterLab. Puedes especificar etiquetas de red para aplicar a la red especificada. Ten en cuenta que Serverless para Apache Spark habilita el Acceso privado a Google (PGA) en la subred especificada. Para conocer los requisitos de conectividad de red, consulta Google Cloud Configuración de red de Serverless para Apache Spark.
Configuración de la sesión: De manera opcional, puedes completar estos campos para limitar la duración de las sesiones creadas con la plantilla.
- Tiempo de inactividad máximo: Es el tiempo máximo de inactividad antes de que finalice la sesión. El rango permitido es de 10 minutos a 336 horas (14 días).
- Tiempo máximo de sesión: Es la duración máxima de una sesión antes de que finalice. El rango permitido es de 10 minutos a 336 horas (14 días).
Metastore: Para usar un servicio de Dataproc Metastore con tus sesiones, selecciona el ID del proyecto y el servicio de metastore.
Servidor de historial persistente: Puedes seleccionar un servidor de historial de Spark persistente disponible para acceder a los registros de sesiones durante y después de las sesiones.
Propiedades de Spark: Puedes seleccionar y, luego, agregar propiedades de Asignación de recursos, Ajuste de escala automático o GPU de Spark. Haz clic en Agregar propiedad para agregar otras propiedades de Spark. Para obtener más información, consulta Propiedades de Spark.
Etiquetas: Haz clic en Agregar etiqueta para cada etiqueta que desees establecer en las sesiones creadas con la plantilla.
Haz clic en Guardar para crear la plantilla.
Permite ver o borrar una plantilla de entorno de ejecución.
- Haz clic en Configuración > Google Cloud Configuración.
En la sección Dataproc Settings > Serverless Runtime Templates, se muestra la lista de plantillas de entorno de ejecución.
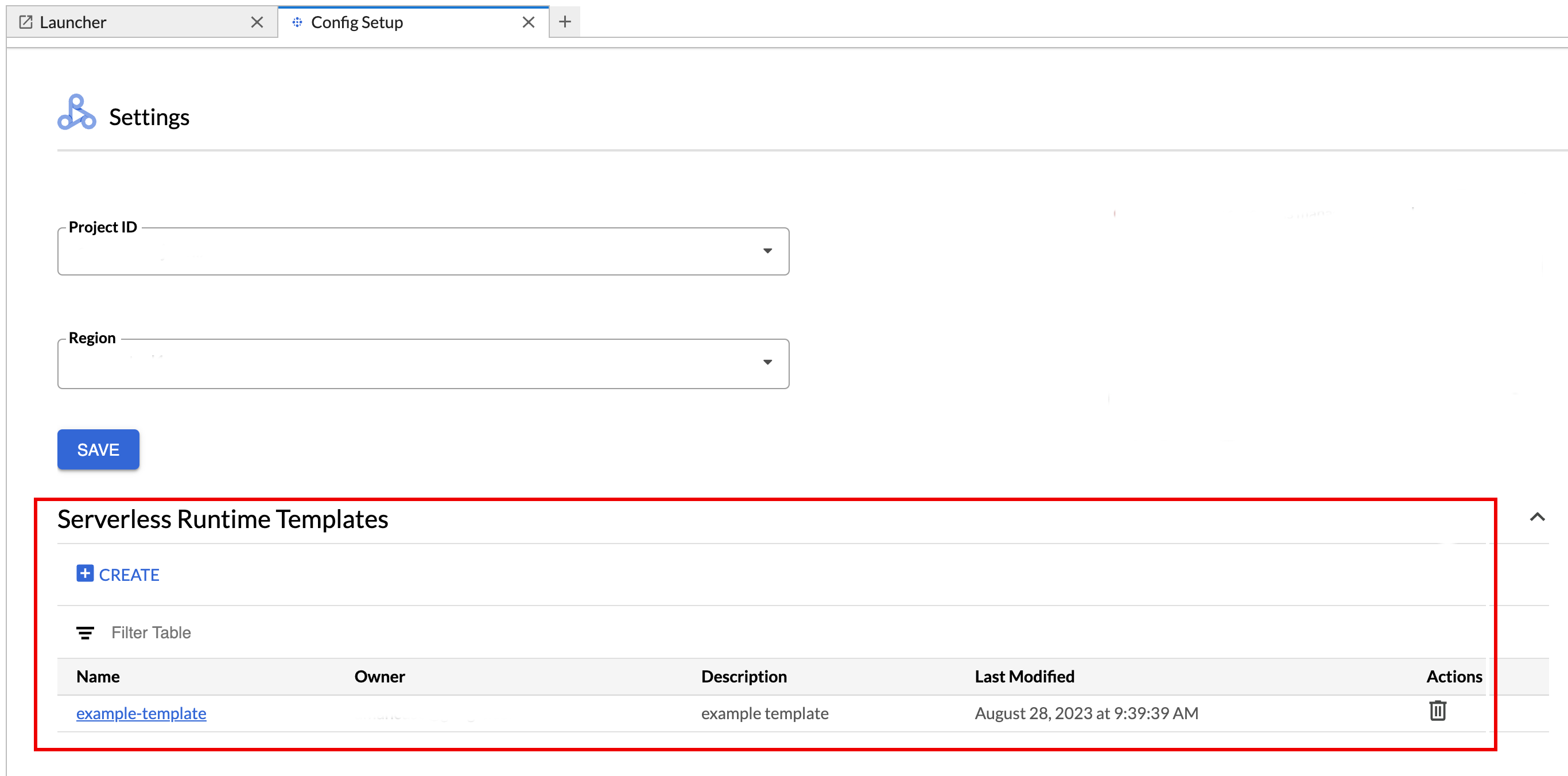
- Haz clic en el nombre de una plantilla para ver sus detalles.
- Puedes borrar una plantilla desde el menú Acción de la plantilla.
Abre y vuelve a cargar la página del Launcher de JupyterLab para ver la tarjeta de la plantilla de notebook guardada en la página del Launcher de JupyterLab.

Crea un archivo YAML con la configuración de la plantilla del entorno de ejecución.
YAML simple
environmentConfig: executionConfig: networkUri: default jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing description: Team A Development Environment
YAML complejo
description: Example session template environmentConfig: executionConfig: serviceAccount: sa1 # Choose either networkUri or subnetworkUri networkUri: subnetworkUri: default networkTags: - tag1 kmsKey: key1 idleTtl: 3600s ttl: 14400s stagingBucket: staging-bucket peripheralsConfig: metastoreService: projects/my-project-id/locations/us-central1/services/my-metastore-id sparkHistoryServerConfig: dataprocCluster: projects/my-project-id/regions/us-central1/clusters/my-cluster-id jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing runtimeConfig: version: "2.3" containerImage: gcr.io/my-project-id/my-image:1.0.1 properties: "p1": "v1" description: Team A Development Environment
Ejecuta el siguiente comando gcloud beta dataproc session-templates import de forma local o en Cloud Shell para crear una plantilla de sesión (tiempo de ejecución) a partir de tu archivo YAML:
gcloud beta dataproc session-templates import TEMPLATE_ID \ --source=YAML_FILE \ --project=PROJECT_ID \ --location=REGION
- Consulta gcloud beta dataproc session-templates para ver los comandos que describen, enumeran, exportan y borran plantillas de sesión.
Inicia un notebook de Jupyter en Serverless for Apache Spark.
Inicia un notebook de Jupyter en un clúster de Dataproc en Compute Engine.
Haz clic en una tarjeta para crear una sesión de Serverless para Apache Spark y, luego, inicia un notebook. Cuando se termina de crear la sesión y el kernel del notebook está listo para usarse, el estado del kernel cambia de
StartingaIdle (Ready).Escribe y prueba el código del notebook.
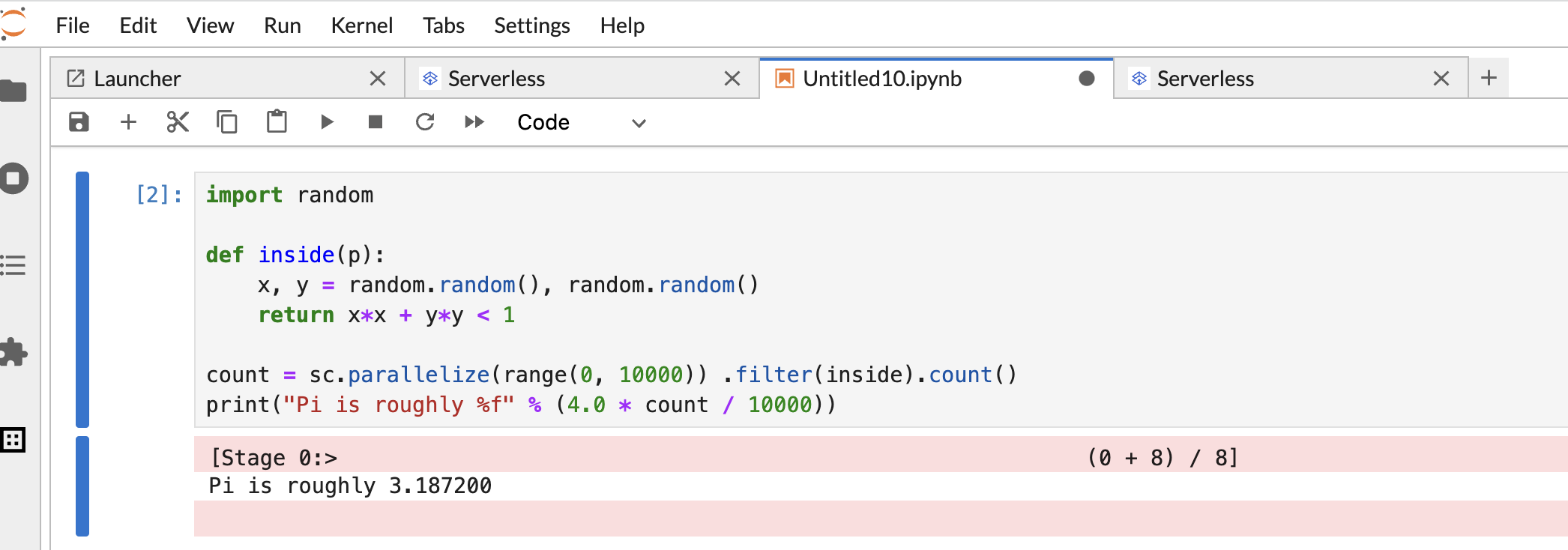
Copia y pega el siguiente código de PySpark
Pi estimationen la celda del notebook de PySpark y, luego, presiona Mayúsculas + Intro para ejecutar el código.import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, 10000)) .filter(inside).count() print("Pi is roughly %f" % (4.0 * count / 10000))
Resultado del notebook:
Después de crear y usar un notebook, puedes terminar la sesión haciendo clic en Shut Down Kernel en la pestaña Kernel.
- Para reutilizar la sesión, crea un cuaderno nuevo seleccionando Notebook en el menú File>>New. Después de crear el notebook nuevo, elige la sesión existente en el diálogo de selección del kernel. El notebook nuevo reutilizará la sesión y conservará el contexto de la sesión del notebook anterior.
Si no terminas la sesión, Dataproc lo hará cuando se agote el tiempo de inactividad de la sesión configurado en el temporizador. Puedes configurar el tiempo de inactividad de la sesión en la configuración de la plantilla del entorno de ejecución. El valor predeterminado es de una hora.
Haz clic en una tarjeta de la sección Notebook del clúster de Dataproc.
Cuando el estado del kernel cambia de
StartingaIdle (Ready), puedes comenzar a escribir y ejecutar código de notebook.Después de crear y usar un notebook, puedes terminar la sesión haciendo clic en Shut Down Kernel en la pestaña Kernel.
Para acceder al navegador de Cloud Storage, haz clic en el ícono del navegador de Cloud Storage en la barra lateral de la página Launcher de JupyterLab y, luego, haz doble clic en una carpeta para ver su contenido.

Puedes hacer clic en los tipos de archivos compatibles con Jupyter para abrirlos y editarlos. Cuando guardas los cambios en los archivos, estos se escriben en Cloud Storage.
Para crear una carpeta nueva de Cloud Storage, haz clic en el ícono de carpeta nueva y, luego, ingresa el nombre de la carpeta.
Para subir archivos a un bucket o una carpeta de Cloud Storage, haz clic en el ícono de carga y, luego, selecciona los archivos que deseas subir.
Haz clic en una tarjeta de PySpark en la sección Notebooks de Serverless for Apache Spark o Notebook de clúster de Dataproc de la página Selector de JupyterLab para abrir un notebook de PySpark.
Haz clic en una tarjeta del kernel de Python en la sección Notebook del clúster de Dataproc de la página del Iniciador de JupyterLab para abrir un notebook de Python.
Haz clic en la tarjeta de Apache Toree en la sección Notebook del clúster de Dataproc de la página Launcher de JupyterLab para abrir un notebook para el desarrollo de código de Scala.

Figura 1. Tarjeta del kernel de Apache Toree en la página de inicio de JupyterLab. - Desarrolla y ejecuta código de Spark en notebooks de Serverless para Apache Spark.
- Crea y administra plantillas de tiempo de ejecución (sesiones) de Serverless for Apache Spark, sesiones interactivas y cargas de trabajo por lotes.
- Desarrollar y ejecutar notebooks de BigQuery
- Explorar, inspeccionar y obtener una vista previa de los conjuntos de datos de BigQuery
- Descarga e instala VS Code.
- Abre VS Code y, luego, en la barra de actividades, haz clic en Extensiones.
En la barra de búsqueda, busca la extensión Jupyter y, luego, haz clic en Instalar. La extensión de Jupyter de Microsoft es una dependencia obligatoria.
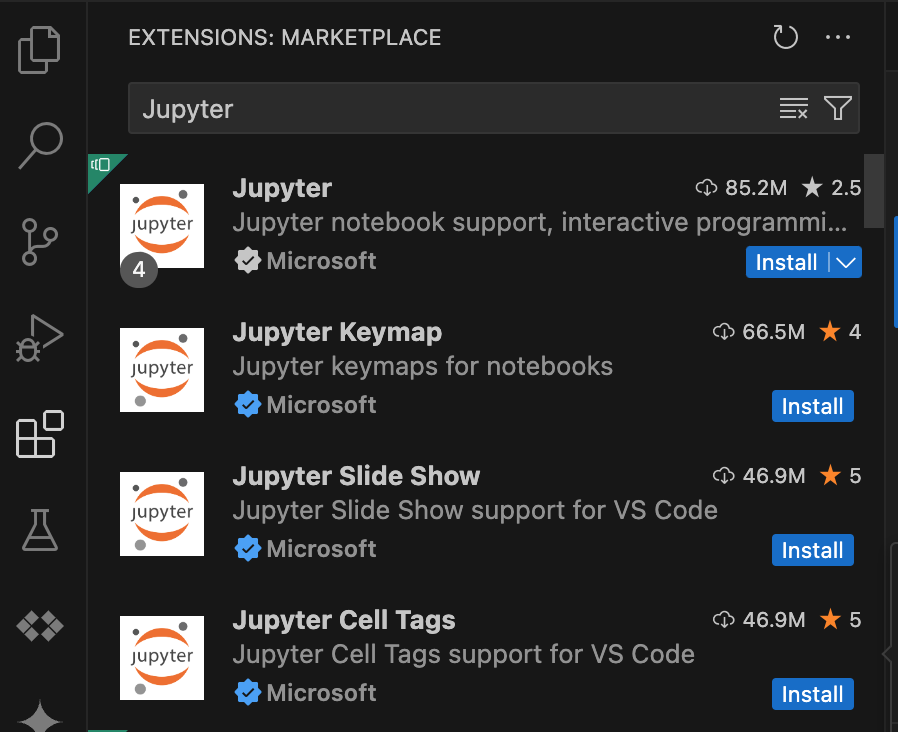
- Abre VS Code y, luego, en la barra de actividades, haz clic en Extensiones.
En la barra de búsqueda, busca la extensión Google Cloud Code y, luego, haz clic en Install.

Si se te solicita, reinicia VS Code.
- Abre VS Code y, luego, en la barra de actividades, haz clic en Google Cloud Code.
- Abre la sección Dataproc.
- Haz clic en Acceder a Google Cloud. Se te redireccionará para que accedas con tus credenciales.
- Usa la barra de tareas de nivel superior de la aplicación para navegar a Código > Configuración > Configuración > Extensiones.
- Busca Google Cloud Código y haz clic en el ícono Administrar para abrir el menú.
- Selecciona Configuración.
- En los campos Proyecto y Región de Dataproc, ingresa el nombre del proyecto Google Cloud y la región que se usarán para desarrollar notebooks y administrar recursos de Serverless for Apache Spark.
- Abre VS Code y, luego, en la barra de actividades, haz clic en Google Cloud Code.
- Abre la sección Notebooks y, luego, haz clic en New Serverless Spark Notebook.
- Selecciona o crea una plantilla de entorno de ejecución (sesión) nueva para usarla en la sesión del notebook.
Se crea un nuevo archivo
.ipynbque contiene código de muestra y se abre en el editor.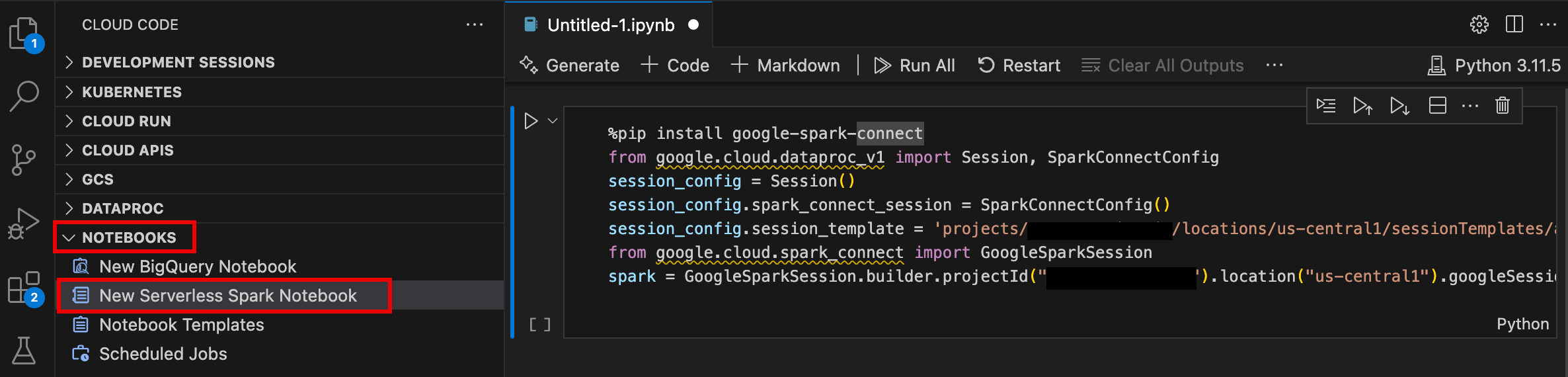
Ahora puedes escribir y ejecutar código en tu notebook de Serverless para Apache Spark.
- Abre VS Code y, luego, en la barra de actividades, haz clic en Google Cloud Code.
Abre la sección Dataproc y, luego, haz clic en los siguientes nombres de recursos:
- Clústeres: Crea y administra clústeres y trabajos.
- Serverless: Crea y administra cargas de trabajo por lotes y sesiones interactivas.
- Plantillas de entorno de ejecución de Spark: Crea y administra plantillas de sesión.

Ejecuta el código de tu notebook en la infraestructura de Google Cloud Serverless para Apache Spark
Programa la ejecución de notebooks en Cloud Composer
Envía trabajos por lotes a la infraestructura de Google Cloud Serverless para Apache Spark o a tu clúster de Dataproc en Compute Engine.
Haz clic en el botón Job Scheduler en la parte superior derecha del notebook.
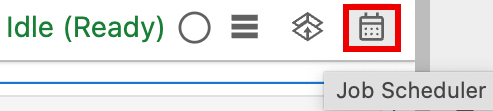
Completa el formulario Create A Scheduled Job para proporcionar la siguiente información:
- Nombre único del trabajo de ejecución del notebook
- Es el entorno de Cloud Composer que se usará para implementar el notebook.
- Parámetros de entrada si el notebook está parametrizado
- Plantilla de entorno de ejecución sin servidores o clúster de Dataproc que se usará para ejecutar el notebook
- Si se selecciona un clúster, indica si se debe detener el clúster después de que el notebook termine de ejecutarse en él.
- Recuento de reintentos y retraso de reintentos en minutos si falla la ejecución del notebook en el primer intento
- Notificaciones de ejecución que se enviarán y la lista de destinatarios. Las notificaciones se envían con una configuración de SMTP de Airflow.
- Programa de ejecución del notebook
Haz clic en Crear.
Una vez que se programa el notebook correctamente, el nombre del trabajo aparece en la lista de trabajos programados en el entorno de Cloud Composer.

Haz clic en la tarjeta Serverless en la sección Trabajos y sesiones de Dataproc de la página Launcher de JupyterLab.
Haz clic en la pestaña Lote, luego en Crear lote y completa los campos de Información del lote.
Haz clic en Enviar para enviar el trabajo.
Haz clic en la tarjeta Clústeres en la sección Trabajos y sesiones de Dataproc de la página Launcher de JupyterLab.
Haz clic en la pestaña Trabajos y, luego, en Enviar trabajo.
Selecciona un clúster y, luego, completa los campos de trabajo.
Haz clic en Enviar para enviar el trabajo.
- Haz clic en la tarjeta Sin servidor.
- Haz clic en la pestaña Sesiones y, luego, en un ID de sesión para abrir la página Detalles de la sesión y ver las propiedades de la sesión, los registros Google Cloud en el Explorador de registros y finalizar una sesión. Nota: Se crea una sesión única de Google Cloud Serverless para Apache Spark para iniciar cada notebook de Google Cloud Serverless para Apache Spark.
- Haz clic en la pestaña Lotes para ver la lista de lotes de Google Cloud Serverless para Apache Spark en el proyecto y la región actuales. Haz clic en un ID de lote para ver los detalles del lote.
- Haz clic en la tarjeta Clústeres. La pestaña Clústeres está seleccionada para enumerar los clústeres activos de Dataproc en Compute Engine en el proyecto y la región actuales. Puedes hacer clic en los íconos de la columna Acciones para iniciar, detener o reiniciar un clúster. Haz clic en el nombre de un clúster para ver sus detalles. Puedes hacer clic en los íconos de la columna Acciones para clonar, detener o borrar un trabajo.
- Haz clic en la tarjeta Trabajos para ver la lista de trabajos en el proyecto actual. Haz clic en un ID de trabajo para ver los detalles.
Instala la extensión de JupyterLab
Puedes instalar y usar la extensión de JupyterLab en una máquina o VM que tenga acceso a los servicios de Google, como tu máquina local o una instancia de VM de Compute Engine.
Para instalar la extensión, sigue estos pasos:
Crea una plantilla de entorno de ejecución de Serverless para Apache Spark
Las plantillas de entorno de ejecución de Serverless para Apache Spark (también llamadas plantillas de sesión) contienen parámetros de configuración para ejecutar código de Spark en una sesión. Puedes crear y administrar plantillas de ejecución con JupyterLab o gcloud CLI.
JupyterLab
gcloud
Inicia y administra notebooks
Después de instalar la extensión de Dataproc JupyterLab, puedes hacer clic en las tarjetas de plantillas de la página Launcher de JupyterLab para realizar las siguientes acciones:
Inicia un notebook de Jupyter en Serverless para Apache Spark
En la sección Notebooks de Serverless para Apache Spark de la página Launcher de JupyterLab, se muestran tarjetas de plantillas de notebooks que se asignan a plantillas de entornos de ejecución de Serverless para Apache Spark (consulta Crea una plantilla de entorno de ejecución de Serverless para Apache Spark).

Inicia un notebook en un clúster de Dataproc en Compute Engine
Si creaste un clúster de Jupyter en Dataproc en Compute Engine, la página Launcher de JupyterLab contiene una sección Dataproc Cluster Notebook con tarjetas de kernel preinstaladas.
Para iniciar un notebook de Jupyter en tu clúster de Dataproc en Compute Engine, haz lo siguiente:
Administra archivos de entrada y salida en Cloud Storage
El análisis de datos exploratorios y la creación de modelos de AA suelen implicar entradas y salidas basadas en archivos. Serverless for Apache Spark accede a estos archivos en Cloud Storage.
Desarrolla código de notebook de Spark
Después de instalar la extensión de Dataproc JupyterLab, puedes iniciar notebooks de Jupyter desde la página Launcher de JupyterLab para desarrollar código de la aplicación.
Desarrollo de código de PySpark y Python
Los clústeres de Serverless para Apache Spark y Dataproc en Compute Engine admiten kernels de PySpark. Dataproc en Compute Engine también admite kernels de Python.
Desarrollo de código SQL
Para abrir un notebook de PySpark y escribir y ejecutar código SQL, en la página Launcher de JupyterLab, en la sección Serverless for Apache Spark Notebooks o Dataproc Cluster Notebook, haz clic en la tarjeta del kernel de PySpark.
Magia de Spark SQL: Dado que el kernel de PySpark que inicia los notebooks sin servidores para Apache Spark se carga previamente con la magia de Spark SQL, en lugar de usar spark.sql('SQL STATEMENT').show() para encapsular tu instrucción de SQL, puedes escribir %%sparksql magic en la parte superior de una celda y, luego, escribir tu instrucción de SQL en la celda.
BigQuery SQL: El conector de BigQuery Spark permite que el código de tu notebook cargue datos de tablas de BigQuery, realice análisis en Spark y, luego, escriba los resultados en una tabla de BigQuery.
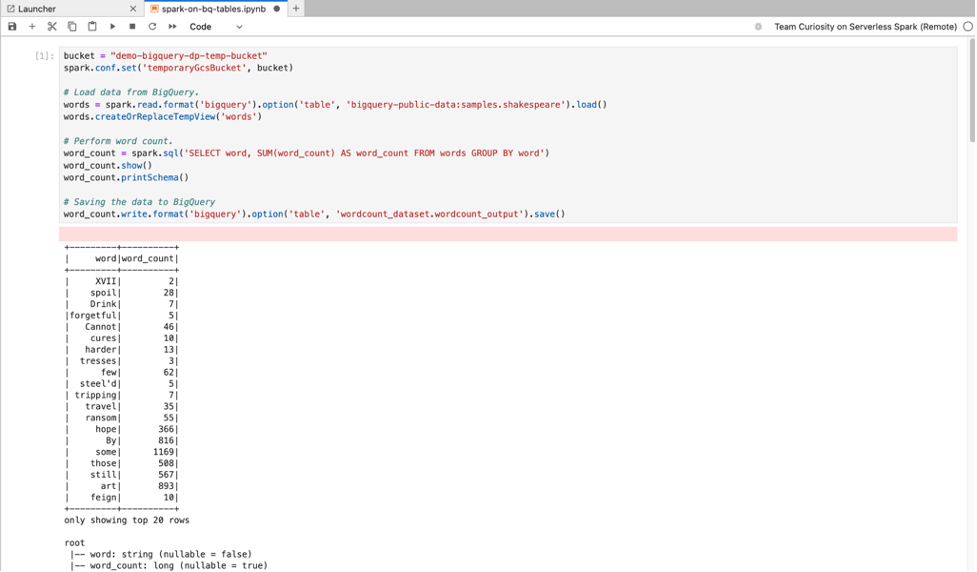
Los tiempos de ejecución de Serverless for Apache Spark 2.2 y versiones posteriores incluyen el conector de BigQuery Spark.
Si usas un tiempo de ejecución anterior para iniciar notebooks de Serverless for Apache Spark, puedes instalar el conector de BigQuery de Spark agregando la siguiente propiedad de Spark a tu plantilla de tiempo de ejecución de Serverless for Apache Spark:
spark.jars: gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar
Desarrollo de código en Scala
Los clústeres de Dataproc en Compute Engine creados con versiones de imagen 2.0 y posteriores incluyen Apache Toree, un kernel de Scala para la plataforma de Jupyter Notebook que proporciona acceso interactivo a Spark.
Desarrolla código con la extensión de Visual Studio Code
Puedes usar la extensión de Google Cloud Visual Studio Code (VS Code) para hacer lo siguiente:
La extensión de Visual Studio Code es gratuita, pero se te cobrará por losGoogle Cloud servicios, incluidos los recursos de Dataproc, Serverless for Apache Spark y Cloud Storage que uses.
Usa VS Code con BigQuery: También puedes usar VS Code con BigQuery para hacer lo siguiente:
Antes de comenzar
Instala la extensión de Google Cloud
El ícono Google Cloud Code ahora está visible en la barra de actividades de VS Code.
Configura la extensión
Desarrolla notebooks de Serverless para Apache Spark
Crea y administra recursos de Serverless para Apache Spark
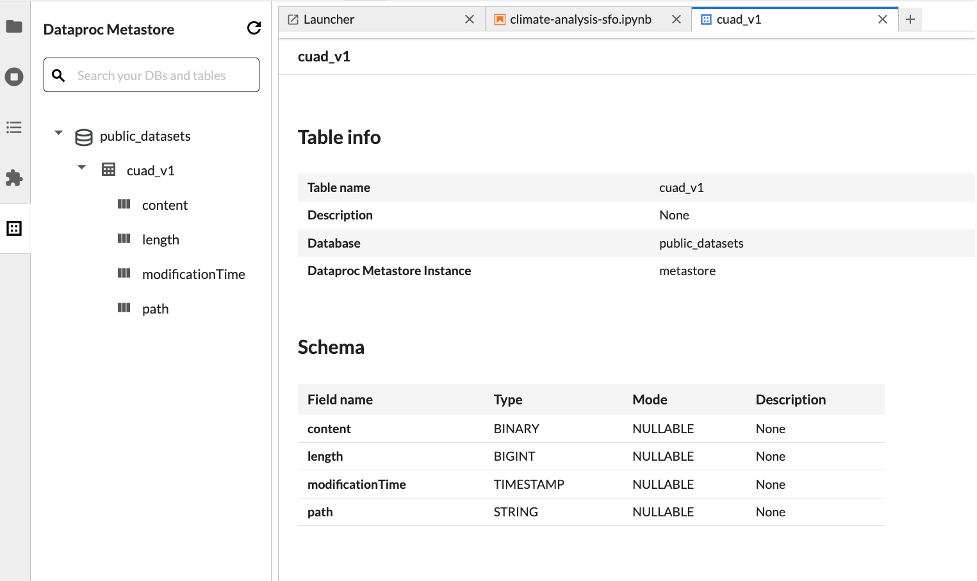
Explorador de conjuntos de datos
Usa el Explorador de conjuntos de datos de JupyterLab para ver los conjuntos de datos de BigLake Metastore.
Para abrir el Explorador de conjuntos de datos de JupyterLab, haz clic en su ícono en la barra lateral.
Puedes buscar una base de datos, una tabla o una columna en el Explorador de conjuntos de datos. Haz clic en el nombre de una base de datos, una tabla o una columna para ver los metadatos asociados.
Implementa tu código
Después de instalar la extensión de Dataproc JupyterLab, puedes usar JupyterLab para hacer lo siguiente:
Programa la ejecución de notebooks en Cloud Composer
Completa los siguientes pasos para programar el código de tu notebook en Cloud Composer para que se ejecute como un trabajo por lotes en Serverless para Apache Spark o en un clúster de Dataproc en Compute Engine.
Envía un trabajo por lotes a Google Cloud Serverless para Apache Spark
Envía un trabajo por lotes a un clúster de Dataproc en Compute Engine
Visualiza y administra recursos
Después de instalar la extensión de JupyterLab de Dataproc, puedes ver y administrar Google Cloud Serverless para Apache Spark y Dataproc en Compute Engine desde la sección Trabajos y sesiones de Dataproc en la página Launcher de JupyterLab.
Haz clic en la sección Trabajos y sesiones de Dataproc para mostrar las tarjetas Clústeres y Sin servidor.
Para ver y administrar Google Cloud sesiones de Serverless para Apache Spark, haz lo siguiente:
Para ver y administrar Google Cloud lotes de Serverless para Apache Spark, haz lo siguiente:
Para ver y administrar clústeres de Dataproc en Compute Engine, haz lo siguiente:
Para ver y administrar los trabajos de Dataproc en Compute Engine, haz lo siguiente: