Dokumen ini menjelaskan cara menginstal dan menggunakan ekstensi JupyterLab di mesin atau VM yang dikelola sendiri yang memiliki akses ke layanan Google. Panduan ini juga menjelaskan cara mengembangkan dan men-deploy kode notebook Spark serverless.
Instal ekstensi dalam beberapa menit untuk memanfaatkan fitur berikut:
- Luncurkan notebook Spark & BigQuery serverless untuk mengembangkan kode dengan cepat
- Menjelajahi dan melihat pratinjau set data BigQuery di JupyterLab
- Mengedit file Cloud Storage di JupyterLab
- Menjadwalkan notebook di Composer
Sebelum memulai
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Jika Anda menggunakan penyedia identitas (IdP) eksternal, Anda harus login ke gcloud CLI dengan identitas gabungan Anda terlebih dahulu.
-
Untuk melakukan inisialisasi gcloud CLI, jalankan perintah berikut:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Jika Anda menggunakan penyedia identitas (IdP) eksternal, Anda harus login ke gcloud CLI dengan identitas gabungan Anda terlebih dahulu.
-
Untuk melakukan inisialisasi gcloud CLI, jalankan perintah berikut:
gcloud init Download dan instal Python versi 3.11 atau yang lebih tinggi dari
python.org/downloads.- Verifikasi penginstalan Python 3.11+.
python3 --version
- Verifikasi penginstalan Python 3.11+.
Virtualisasikan lingkungan Python.
pip3 install pipenv
- Buat folder penginstalan.
mkdir jupyter
- Ubah ke folder penginstalan.
cd jupyter
- Buat lingkungan virtual.
pipenv shell
- Buat folder penginstalan.
Instal JupyterLab di lingkungan virtual.
pipenv install jupyterlab
Instal ekstensi JupyterLab.
pipenv install bigquery-jupyter-plugin
jupyter lab
Halaman Launcher JupyterLab akan terbuka di browser Anda. Halaman ini berisi bagian Dataproc Jobs and Sessions. Halaman ini juga dapat berisi bagian Notebook Serverless untuk Apache Spark dan Notebook Cluster Dataproc jika Anda memiliki akses ke notebook serverless Dataproc atau cluster Dataproc dengan komponen opsional Jupyter yang berjalan di project Anda.
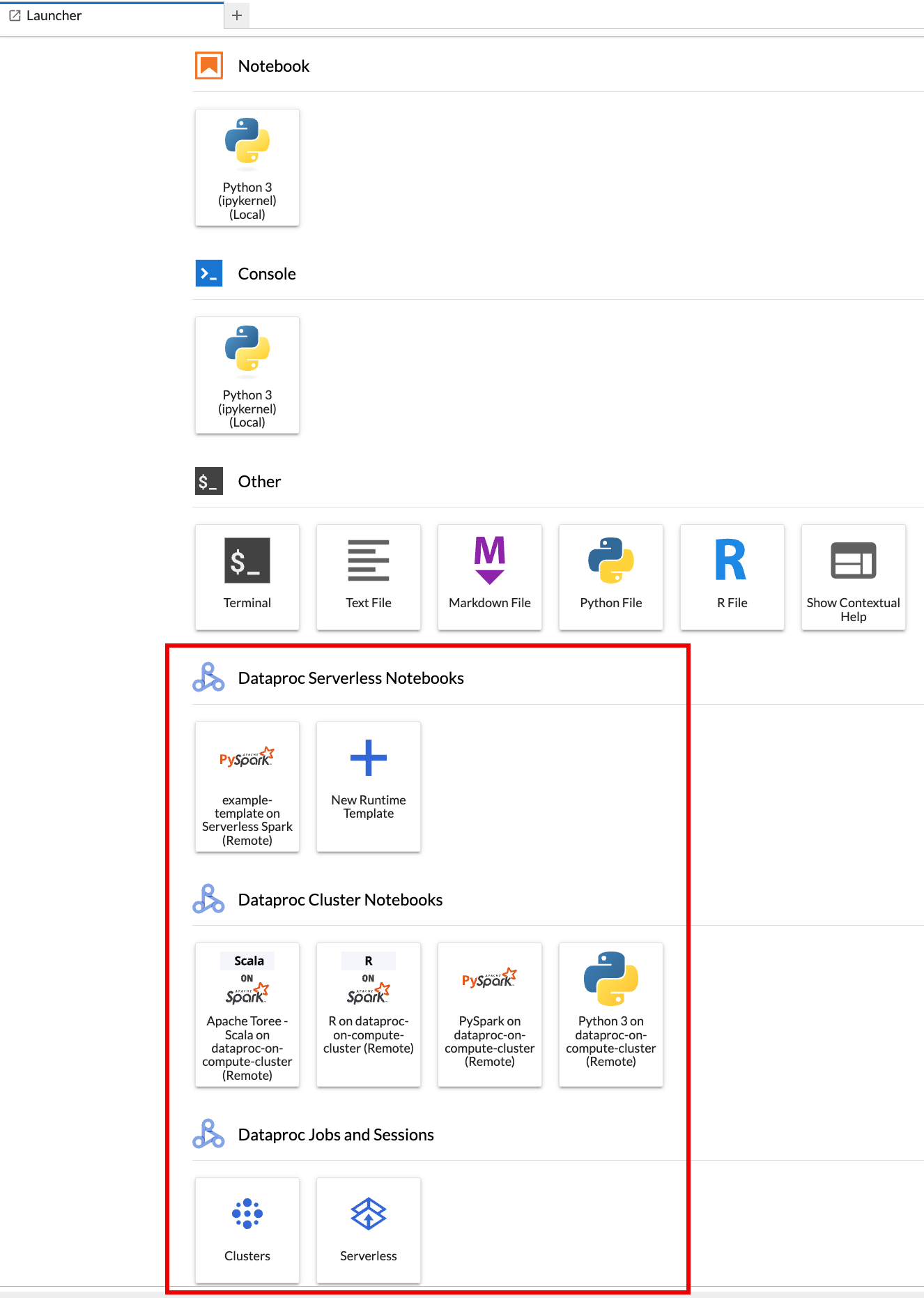
Secara default, sesi Interaktif Serverless untuk Apache Spark Anda berjalan di project dan region yang Anda tetapkan saat menjalankan
gcloud initdi Sebelum memulai. Anda dapat mengubah setelan project dan region untuk sesi dari JupyterLab Settings > Google Cloud Settings > Google Cloud Project Settings.Anda harus memulai ulang ekstensi agar perubahan diterapkan.
Klik kartu
New runtime templatedi bagian Serverless for Apache Spark Notebooks di halaman Launcher JupyterLab.
Isi formulir Runtime template.
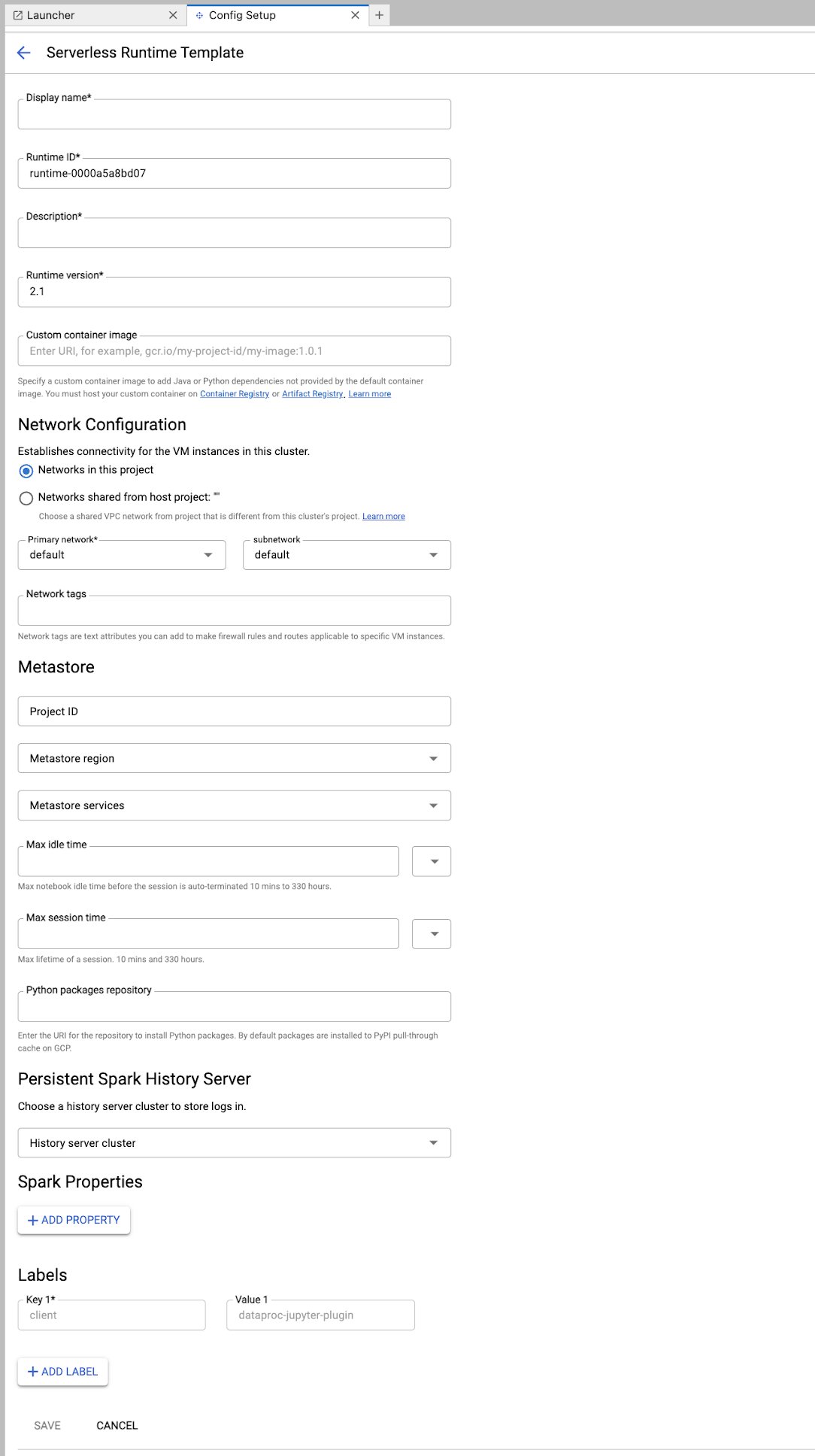
Info Template:
- Nama tampilan, ID runtime, dan Deskripsi: Terima atau isi nama tampilan template, ID runtime template, dan deskripsi template.
Konfigurasi Eksekusi: Pilih Akun Pengguna untuk mengeksekusi notebook dengan identitas pengguna, bukan identitas akun layanan Dataproc.
- Akun Layanan: Jika Anda tidak menentukan akun layanan, akun layanan default Compute Engine akan digunakan.
- Versi runtime: Konfirmasi atau pilih versi runtime.
- Image container kustom: Secara opsional, tentukan URI dari image container kustom.
- Bucket Staging: Anda dapat secara opsional menentukan nama bucket staging Cloud Storage untuk digunakan oleh Serverless for Apache Spark.
- Repositori paket Python: Secara default, paket Python didownload dan diinstal dari cache pull-through PyPI saat pengguna menjalankan perintah penginstalan
pipdi notebook mereka. Anda dapat menentukan repositori artefak pribadi organisasi Anda untuk paket Python yang akan digunakan sebagai repositori paket Python default.
Encryption: Terima Google-owned and Google-managed encryption key default atau pilih Customer-managed encryption key (CMEK). Jika CMEK, pilih atau berikan informasi kunci.
Konfigurasi Jaringan: Pilih subnet di project atau yang dibagikan dari project host (Anda dapat mengubah project dari JupyterLab Settings > Google Cloud Settings > Google Cloud Project Settings. Anda dapat menentukan tag jaringan yang akan diterapkan ke jaringan yang ditentukan. Perhatikan bahwa Serverless untuk Apache Spark mengaktifkan Akses Google Pribadi (PGA) di subnet yang ditentukan. Untuk persyaratan konektivitas jaringan, lihat Google Cloud Konfigurasi jaringan Serverless untuk Apache Spark.
Konfigurasi Sesi: Anda dapat mengisi kolom ini secara opsional untuk membatasi durasi sesi yang dibuat dengan template.
- Waktu tidak aktif maksimum: Waktu tidak aktif maksimum sebelum sesi diakhiri. Rentang yang diizinkan: 10 menit hingga 336 jam (14 hari).
- Waktu sesi maks: Masa aktif maksimum sesi sebelum sesi diakhiri. Rentang yang diizinkan: 10 menit hingga 336 jam (14 hari).
Metastore: Untuk menggunakan layanan Dataproc Metastore dengan sesi Anda, pilih project ID dan layanan metastore.
Persistent History Server: Anda dapat memilih Persistent Spark History Server yang tersedia untuk memungkinkan Anda mengakses log sesi selama dan setelah sesi.
Properti Spark: Anda dapat memilih lalu menambahkan properti Alokasi Resource, Penskalaan Otomatis, atau GPU Spark. Klik Tambahkan Properti untuk menambahkan properti Spark lainnya. Untuk mengetahui informasi selengkapnya, lihat Properti Spark.
Label: Klik Tambahkan Label untuk setiap label yang akan ditetapkan pada sesi yang dibuat dengan template.
Klik Simpan untuk membuat template.
Untuk melihat atau menghapus template runtime.
- Klik Setelan > Google Cloud Setelan.
Bagian Dataproc Settings > Serverless Runtime Templates menampilkan daftar template runtime.
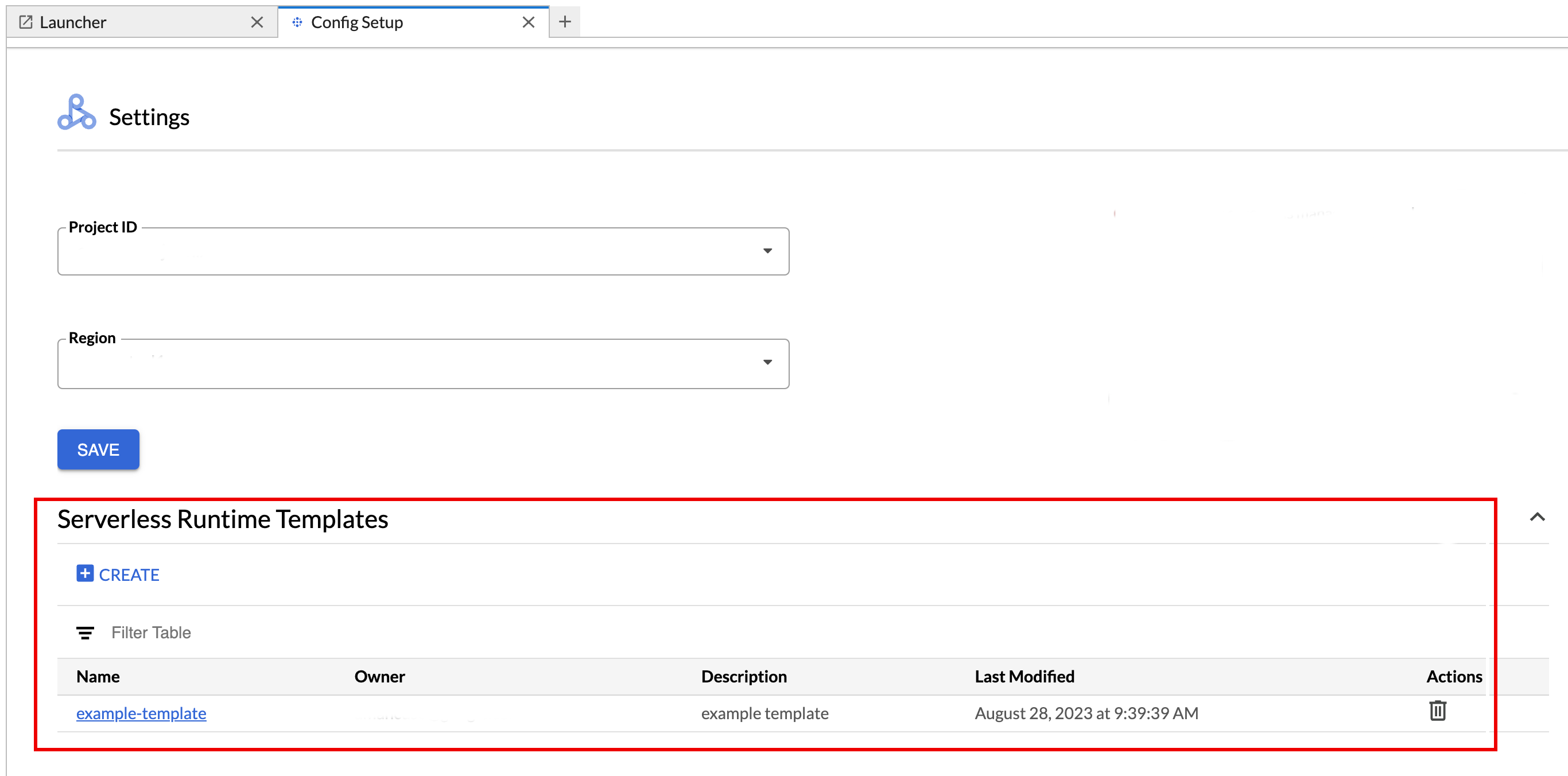
- Klik nama template untuk melihat detail template.
- Anda dapat menghapus template dari menu Tindakan untuk template tersebut.
Buka dan muat ulang halaman Launcher JupyterLab untuk melihat kartu template notebook tersimpan di halaman Launcher JupyterLab.

Buat file YAML dengan konfigurasi template runtime Anda.
YAML Sederhana
environmentConfig: executionConfig: networkUri: default jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing description: Team A Development Environment
YAML Kompleks
description: Example session template environmentConfig: executionConfig: serviceAccount: sa1 # Choose either networkUri or subnetworkUri networkUri: subnetworkUri: default networkTags: - tag1 kmsKey: key1 idleTtl: 3600s ttl: 14400s stagingBucket: staging-bucket peripheralsConfig: metastoreService: projects/my-project-id/locations/us-central1/services/my-metastore-id sparkHistoryServerConfig: dataprocCluster: projects/my-project-id/regions/us-central1/clusters/my-cluster-id jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing runtimeConfig: version: "2.3" containerImage: gcr.io/my-project-id/my-image:1.0.1 properties: "p1": "v1" description: Team A Development Environment
Buat template sesi (runtime) dari file YAML Anda dengan menjalankan perintah gcloud beta dataproc session-templates import secara lokal atau di Cloud Shell:
gcloud beta dataproc session-templates import TEMPLATE_ID \ --source=YAML_FILE \ --project=PROJECT_ID \ --location=REGION
- Lihat gcloud beta dataproc session-templates untuk mengetahui perintah guna menjelaskan, mencantumkan, mengekspor, dan menghapus template sesi.
Luncurkan notebook Jupyter di Serverless untuk Apache Spark.
Luncurkan notebook Jupyter di cluster Dataproc di Compute Engine.
Klik kartu untuk membuat sesi Serverless for Apache Spark dan meluncurkan notebook. Setelah pembuatan sesi selesai dan kernel notebook siap digunakan, status kernel akan berubah dari
StartingmenjadiIdle (Ready).Menulis dan menguji kode notebook.
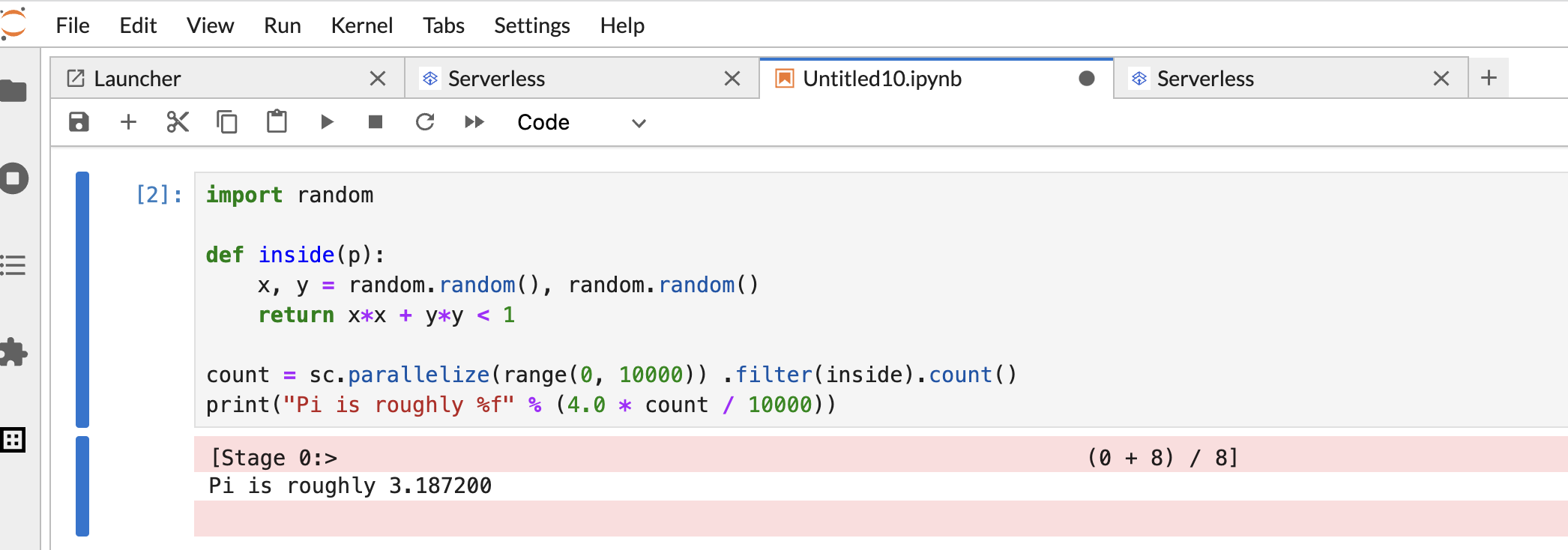
Salin dan tempel kode
Pi estimationPySpark berikut di sel notebook PySpark, lalu tekan Shift+Return untuk menjalankan kode.import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, 10000)) .filter(inside).count() print("Pi is roughly %f" % (4.0 * count / 10000))
Hasil notebook:
Setelah membuat dan menggunakan notebook, Anda dapat mengakhiri sesi notebook dengan mengklik Shut Down Kernel dari tab Kernel.
- Untuk menggunakan kembali sesi, buat notebook baru dengan memilih Notebook dari menu File>>Baru. Setelah notebook baru dibuat, pilih sesi yang ada dari dialog pemilihan kernel. Notebook baru akan menggunakan kembali sesi dan mempertahankan konteks sesi dari notebook sebelumnya.
Jika Anda tidak menghentikan sesi, Dataproc akan menghentikan sesi saat timer tidak ada aktivitas sesi berakhir. Anda dapat mengonfigurasi waktu tidak ada aktivitas sesi di konfigurasi template runtime. Waktu tidak ada aktivitas sesi default adalah satu jam.
Klik kartu di bagian Dataproc Cluster Notebook.
Saat status kernel berubah dari
StartingmenjadiIdle (Ready), Anda dapat mulai menulis dan menjalankan kode notebook.Setelah membuat dan menggunakan notebook, Anda dapat mengakhiri sesi notebook dengan mengklik Shut Down Kernel dari tab Kernel.
Untuk mengakses browser Cloud Storage, klik ikon browser Cloud Storage di sidebar halaman Launcher JupyterLab, lalu klik dua kali folder untuk melihat kontennya.
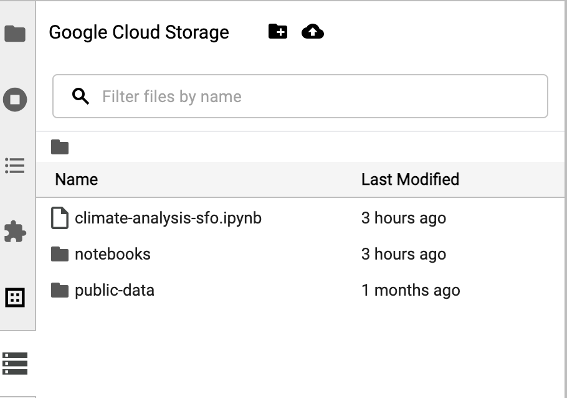
Anda dapat mengklik jenis file yang didukung Jupyter untuk membuka dan mengeditnya. Saat Anda menyimpan perubahan pada file, file tersebut akan ditulis ke Cloud Storage.
Untuk membuat folder Cloud Storage baru, klik ikon folder baru, lalu masukkan nama folder.
Untuk mengupload file ke bucket atau folder Cloud Storage, klik ikon upload, lalu pilih file yang akan diupload.
Klik kartu PySpark di bagian Serverless for Apache Spark Notebooks atau Dataproc Cluster Notebook di halaman Launcher JupyterLab untuk membuka notebook PySpark.
Klik kartu kernel Python di bagian Dataproc Cluster Notebook di halaman Launcher JupyterLab untuk membuka notebook Python.
Klik kartu Apache Toree di bagian Notebook cluster Dataproc di halaman Launcher JupyterLab untuk membuka notebook bagi pengembangan kode Scala.

Gambar 1. Kartu kernel Apache Toree di halaman Peluncur JupyterLab. - Kembangkan dan jalankan kode Spark di notebook Serverless untuk Apache Spark.
- Buat dan kelola template runtime (sesi) Serverless untuk Apache Spark, sesi interaktif, dan workload batch.
- Mengembangkan dan menjalankan notebook BigQuery.
- Jelajahi, periksa, dan pratinjau set data BigQuery.
- Download dan instal VS Code.
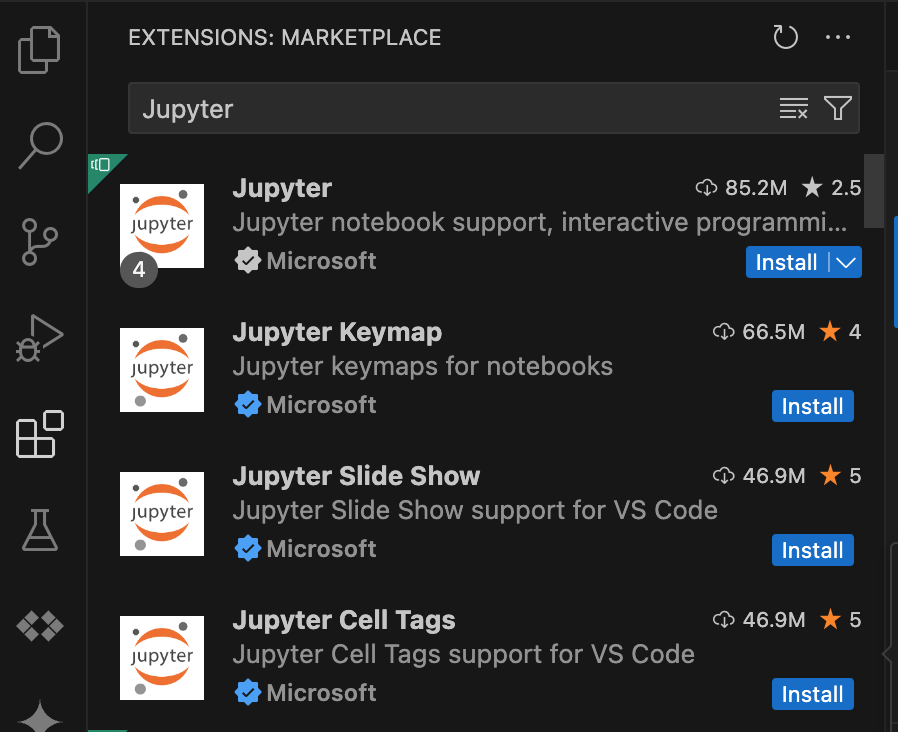
- Buka VS Code, lalu di panel aktivitas, klik Extensions.
Dengan menggunakan kotak penelusuran, temukan ekstensi Jupyter, lalu klik Install. Ekstensi Jupyter dari Microsoft adalah dependensi yang diperlukan.
- Buka VS Code, lalu di panel aktivitas, klik Extensions.
Menggunakan kotak penelusuran, temukan ekstensi Google Cloud Code, lalu klik Instal.

Jika diminta, mulai ulang VS Code.
- Buka VS Code, lalu di panel aktivitas, klik Google Cloud Code.
- Buka bagian Dataproc.
- Klik Login ke Google Cloud. Anda akan dialihkan untuk login dengan kredensial Anda.
- Gunakan panel tugas aplikasi tingkat teratas untuk membuka Code > Settings > Settings > Extensions.
- Cari Google Cloud Code, lalu klik ikon Kelola untuk membuka menu.
- Pilih Setelan.
- Di kolom Project dan Dataproc Region, masukkan nama project Google Cloud dan region yang akan digunakan untuk mengembangkan notebook dan mengelola resource Serverless for Apache Spark.
- Buka VS Code, lalu di panel aktivitas, klik Google Cloud Code.
- Buka bagian Notebooks, lalu klik New Serverless Spark Notebook.
- Pilih atau buat template runtime (sesi) baru untuk digunakan pada sesi notebook.
File
.ipynbbaru yang berisi contoh kode dibuat dan dibuka di editor.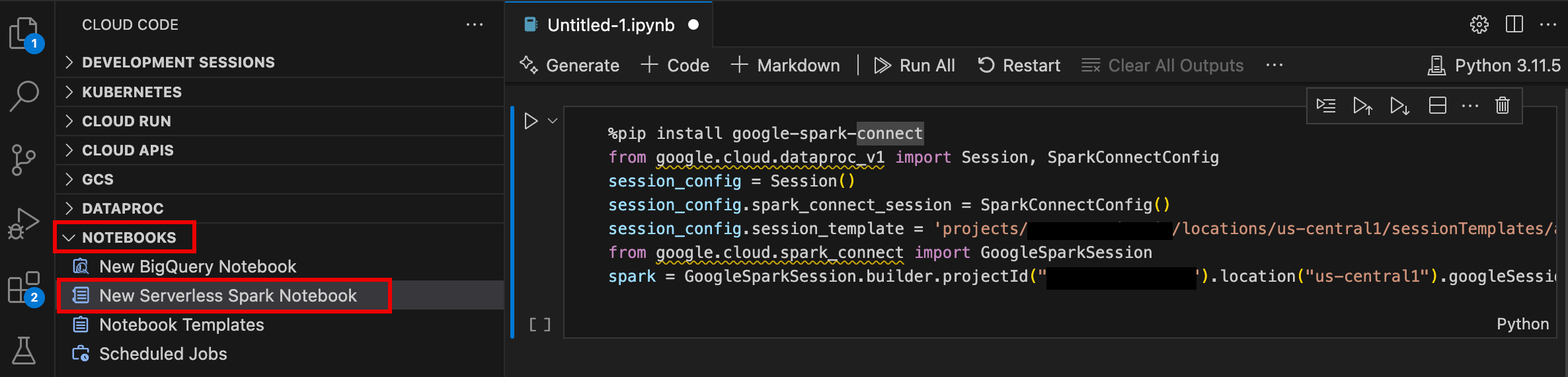
Sekarang Anda dapat menulis dan menjalankan kode di notebook Serverless untuk Apache Spark.
- Buka VS Code, lalu di panel aktivitas, klik Google Cloud Code.
Buka bagian Dataproc, lalu klik nama resource berikut:
- Cluster: Membuat dan mengelola cluster dan tugas.
- Serverless: Buat dan kelola workload batch dan sesi interaktif.
- Template Runtime Spark: Buat dan kelola template sesi.

Jalankan kode notebook Anda di Google Cloud infrastruktur Serverless untuk Apache Spark
Menjadwalkan eksekusi notebook di Cloud Composer
Kirimkan tugas batch ke infrastruktur Google Cloud Serverless untuk Apache Spark atau ke cluster Dataproc di Compute Engine.
Klik tombol Job Scheduler di kanan atas notebook.
Isi formulir Create A Scheduled Job untuk memberikan informasi berikut:
- Nama unik untuk tugas eksekusi notebook
- Lingkungan Cloud Composer yang akan digunakan untuk men-deploy notebook
- Parameter input jika notebook diparameterkan
- Template runtime serverless atau cluster Dataproc yang akan digunakan untuk menjalankan notebook
- Jika cluster dipilih, apakah akan menghentikan cluster setelah notebook selesai dieksekusi di cluster
- Jumlah percobaan ulang dan penundaan percobaan ulang dalam menit jika eksekusi notebook gagal pada percobaan pertama
- Notifikasi eksekusi yang akan dikirim dan daftar penerima. Notifikasi dikirim menggunakan konfigurasi SMTP Airflow.
- Jadwal eksekusi notebook
Klik Buat.
Setelah notebook berhasil dijadwalkan, nama tugas akan muncul dalam daftar tugas terjadwal di lingkungan Cloud Composer.

Klik kartu Serverless di bagian Dataproc Jobs and Sessions di halaman Launcher JupyterLab.
Klik tab Batch, lalu klik Create Batch dan isi kolom Batch Info.
Klik Kirim untuk mengirimkan tugas.
Klik kartu Cluster di bagian Dataproc Jobs and Sessions di halaman Launcher JupyterLab.
Klik tab Jobs, lalu klik Submit Job.
Pilih Cluster, lalu isi kolom Tugas.
Klik Kirim untuk mengirimkan tugas.
- Klik kartu Serverless.
- Klik tab Sesi, lalu ID sesi untuk membuka halaman Detail sesi guna melihat properti sesi, melihat log Google Cloud di Logs Explorer, dan mengakhiri sesi. Catatan: Sesi Google Cloud Serverless for Apache Spark yang unik dibuat untuk meluncurkan setiap notebook Google Cloud Serverless for Apache Spark.
- Klik tab Batch untuk melihat daftar batch Serverless for Apache Spark di project dan region saat ini. Google Cloud Klik ID batch untuk melihat detail batch.
- Klik kartu Cluster. Tab Clusters dipilih untuk mencantumkan cluster Dataproc on Compute Engine yang aktif di project dan region saat ini. Anda dapat mengklik ikon di kolom Tindakan untuk memulai, menghentikan, atau memulai ulang cluster. Klik nama cluster untuk melihat detail cluster. Anda dapat mengklik ikon di kolom Tindakan untuk meng-clone, menghentikan, atau menghapus tugas.
- Klik kartu Tugas untuk melihat daftar tugas di project saat ini. Klik ID tugas untuk melihat detail tugas.
Menginstal ekstensi JupyterLab
Anda dapat menginstal dan menggunakan ekstensi JupyterLab di mesin atau VM yang memiliki akses ke layanan Google, seperti mesin lokal atau instance VM Compute Engine.
Untuk menginstal ekstensi, ikuti langkah-langkah berikut:
Membuat template runtime Serverless for Apache Spark
Template runtime Serverless for Apache Spark (juga disebut template sesi) berisi setelan konfigurasi untuk menjalankan kode Spark dalam sesi. Anda dapat membuat dan mengelola template runtime menggunakan JupyterLab atau gcloud CLI.
JupyterLab
gcloud
Meluncurkan dan mengelola notebook
Setelah menginstal ekstensi Dataproc JupyterLab, Anda dapat mengklik kartu template di halaman Launcher JupyterLab untuk:
Meluncurkan notebook Jupyter di Serverless untuk Apache Spark
Bagian Serverless for Apache Spark Notebooks di halaman JupyterLab Launcher menampilkan kartu template notebook yang dipetakan ke template runtime Serverless for Apache Spark (lihat Membuat template runtime Serverless for Apache Spark).

Meluncurkan notebook di cluster Dataproc di Compute Engine
Jika Anda membuat cluster Jupyter Dataproc di Compute Engine, halaman Peluncur JupyterLab berisi bagian Notebook Cluster Dataproc dengan kartu kernel yang telah diinstal sebelumnya.
Untuk meluncurkan notebook Jupyter di cluster Dataproc di Compute Engine:
Mengelola file input dan output di Cloud Storage
Menganalisis data eksploratif dan membuat model ML sering kali melibatkan input dan output berbasis file. Serverless untuk Apache Spark mengakses file ini di Cloud Storage.
Mengembangkan kode notebook Spark
Setelah menginstal ekstensi Dataproc JupyterLab, Anda dapat meluncurkan notebook Jupyter dari halaman Launcher JupyterLab untuk mengembangkan kode aplikasi.
Pengembangan kode PySpark dan Python
Serverless untuk Apache Spark dan cluster Dataproc di Compute Engine mendukung kernel PySpark. Dataproc di Compute Engine juga mendukung kernel Python.
Pengembangan kode SQL
Untuk membuka notebook PySpark guna menulis dan menjalankan kode SQL, di halaman Launcher JupyterLab, di bagian Serverless for Apache Spark Notebooks atau Dataproc Cluster Notebook, klik kartu kernel PySpark.
Magic Spark SQL: Karena kernel PySpark yang meluncurkan
Notebook Serverless untuk Apache Spark
sudah dimuat sebelumnya dengan magic Spark SQL, Anda dapat mengetik
%%sparksql magic di bagian atas sel, lalu mengetik pernyataan SQL di sel, alih-alih menggunakan spark.sql('SQL STATEMENT').show()
untuk membungkus pernyataan SQL.
SQL BigQuery: Konektor Spark BigQuery memungkinkan kode notebook Anda memuat data dari tabel BigQuery, melakukan analisis di Spark, lalu menulis hasilnya ke tabel BigQuery.
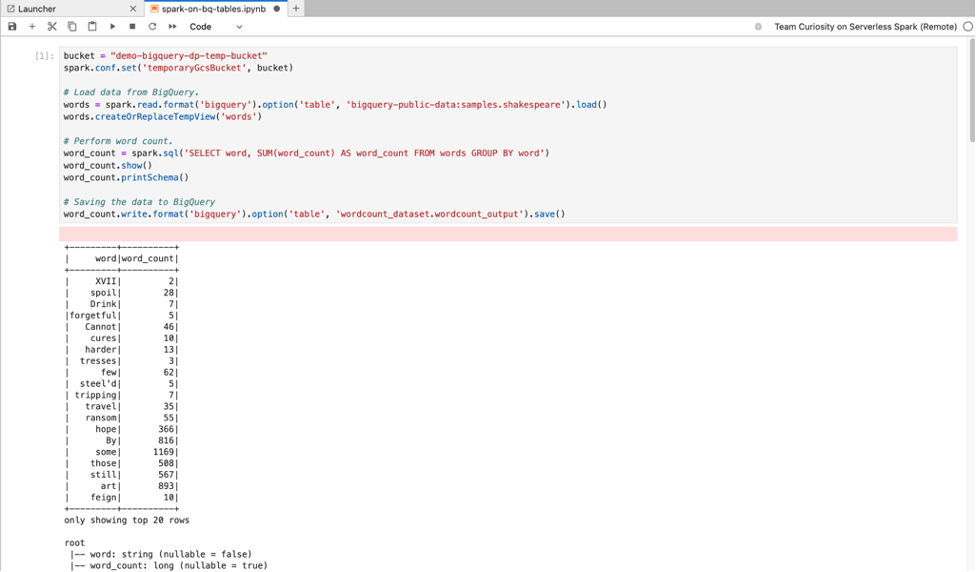
Runtime Serverless untuk Apache Spark 2.2
dan yang lebih baru mencakup
konektor BigQuery Spark.
Jika Anda menggunakan runtime sebelumnya untuk meluncurkan notebook Serverless for Apache Spark, Anda dapat menginstal Spark BigQuery Connector dengan menambahkan properti Spark berikut ke template runtime Serverless for Apache Spark:
spark.jars: gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar
Pengembangan kode Scala
Cluster Dataproc di Compute Engine yang dibuat dengan versi image 2.0 dan yang lebih baru menyertakan Apache Toree,
kernel Scala untuk platform Jupyter Notebook yang menyediakan akses interaktif
ke Spark.
Mengembangkan kode dengan ekstensi Visual Studio Code
Anda dapat menggunakan ekstensi Google Cloud Visual Studio Code (VS Code) untuk melakukan hal berikut:
Ekstensi Visual Studio Code gratis, tetapi Anda akan ditagih untuk setiap Google Cloud layanan, termasuk Dataproc, Serverless untuk Apache Spark, dan resource Cloud Storage yang Anda gunakan.
Menggunakan VS Code dengan BigQuery: Anda juga dapat menggunakan VS Code dengan BigQuery untuk melakukan hal berikut:
Sebelum memulai
Menginstal ekstensi Google Cloud
Ikon Google Cloud Code kini terlihat di panel aktivitas VS Code.
Mengonfigurasi ekstensi
Mengembangkan notebook Serverless for Apache Spark
Membuat dan mengelola resource Serverless untuk Apache Spark
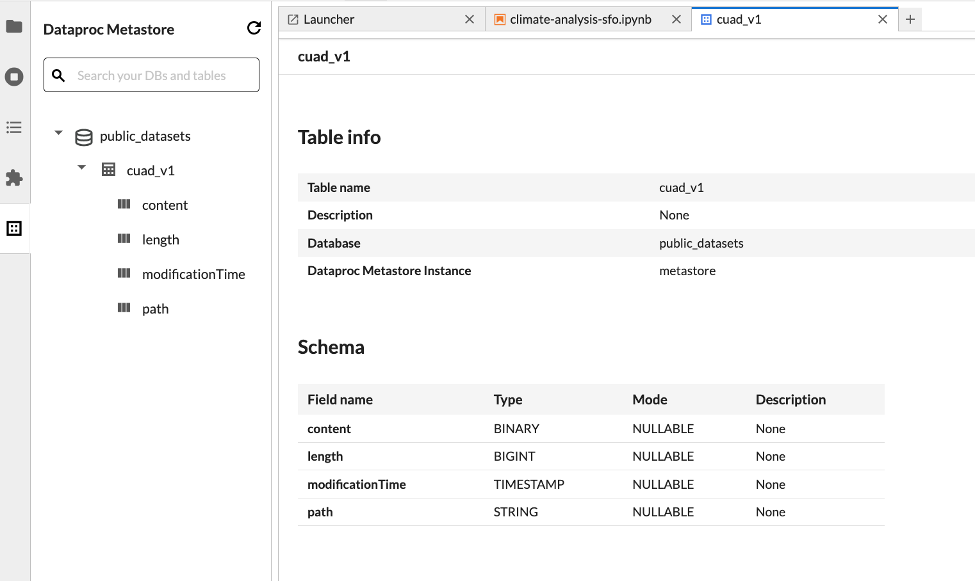
Penjelajah set data
Gunakan penjelajah Set data JupyterLab untuk melihat set data metastore BigLake.
Untuk membuka Penjelajah Dataset JupyterLab, klik ikonnya di sidebar.
Anda dapat menelusuri database, tabel, atau kolom di Penjelajah set data. Klik nama database, tabel, atau kolom untuk melihat metadata terkait.
Men-deploy kode
Setelah menginstal ekstensi Dataproc JupyterLab, Anda dapat menggunakan JupyterLab untuk:
Menjadwalkan eksekusi notebook di Cloud Composer
Selesaikan langkah-langkah berikut untuk menjadwalkan kode notebook Anda di Cloud Composer agar berjalan sebagai tugas batch di Serverless untuk Apache Spark atau di cluster Dataproc di Compute Engine.
Mengirimkan tugas batch ke Google Cloud Serverless untuk Apache Spark
Mengirimkan tugas batch ke cluster Dataproc di Compute Engine
Melihat dan mengelola resource
Setelah menginstal ekstensi Dataproc JupyterLab, Anda dapat melihat dan mengelola Google Cloud Serverless untuk Apache Spark dan Dataproc di Compute Engine dari bagian Dataproc Jobs and Sessions di halaman Launcher JupyterLab.
Klik bagian Dataproc Jobs and Sessions untuk menampilkan kartu Clusters dan Serverless.
Untuk melihat dan mengelola sesi Google Cloud Serverless untuk Apache Spark:
Untuk melihat dan mengelola batch Google Cloud Serverless untuk Apache Spark:
Untuk melihat dan mengelola cluster Dataproc di Compute Engine:
Untuk melihat dan mengelola tugas Dataproc di Compute Engine: