En este documento, se describen las herramientas y los archivos que puedes usar para supervisar y solucionar problemas de las cargas de trabajo por lotes de Serverless para Apache Spark.
Soluciona problemas de cargas de trabajo desde la consola de Google Cloud
Cuando un trabajo por lotes falla o tiene un rendimiento deficiente, el primer paso recomendado es abrir su página Detalles del lote desde la página Lotes en la consola de Google Cloud .
Usa la pestaña Resumen: tu centro de solución de problemas
En la pestaña Resumen, que se selecciona de forma predeterminada cuando se abre la página Detalles del lote, se muestran métricas críticas y registros filtrados para ayudarte a realizar una evaluación inicial rápida del estado del lote. Después de esta evaluación inicial, puedes realizar un análisis más profundo con herramientas más especializadas que se encuentran en la página Detalles del lote, como la IU de Spark, el Explorador de registros y Gemini Cloud Assist.
Aspectos destacados de las métricas por lotes
La pestaña Resumen de la página Detalles del lote incluye gráficos que muestran valores importantes de las métricas de la carga de trabajo por lotes. Los gráficos de métricas se completan después de que finaliza el proceso y ofrecen una indicación visual de posibles problemas, como contención de recursos, sesgo de datos o presión de memoria.
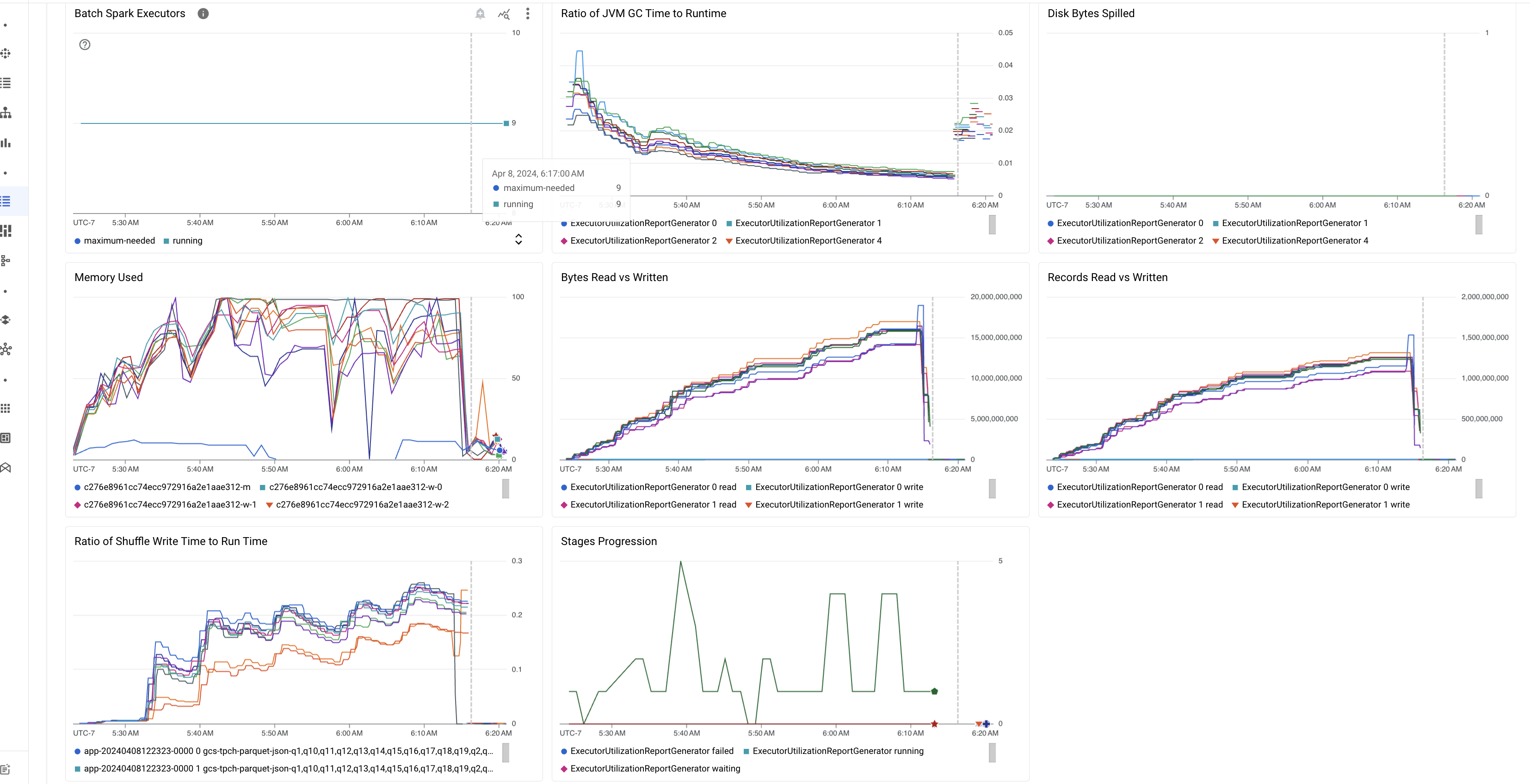
En la siguiente tabla, se enumeran las métricas de la carga de trabajo de Spark que se muestran en la página Detalles del lote de la consola de Google Cloud y se describe cómo los valores de las métricas pueden proporcionar información sobre el estado y el rendimiento de la carga de trabajo.
| Métrica | ¿Qué muestra? |
|---|---|
| Métricas a nivel del ejecutor | |
| Proporción del tiempo de GC de JVM en relación con el tiempo de ejecución | Esta métrica muestra la proporción del tiempo de GC (recolección de elementos no utilizados) de la JVM en relación con el tiempo de ejecución por ejecutor. Los ratios altos pueden indicar pérdidas de memoria en las tareas que se ejecutan en ejecutores particulares o estructuras de datos ineficientes, lo que puede generar una alta rotación de objetos. |
| Bytes volcados al disco | Esta métrica muestra la cantidad total de bytes de disco que se desbordaron en los diferentes ejecutores. Si un ejecutor muestra una gran cantidad de bytes volcados en el disco, esto puede indicar una asimetría de datos. Si la métrica aumenta con el tiempo, esto puede indicar que hay etapas con presión de memoria o fugas de memoria. |
| Bytes leídos y escritos | Esta métrica muestra los bytes escritos en comparación con los bytes leídos por cada ejecutor. Las grandes discrepancias en los bytes leídos o escritos pueden indicar situaciones en las que las uniones replicadas generan una amplificación de datos en ejecutores específicos. |
| Registros leídos y escritos | Esta métrica muestra los registros leídos y escritos por cada ejecutor. Una gran cantidad de registros leídos con una baja cantidad de registros escritos puede indicar un cuello de botella en la lógica de procesamiento de ejecutores específicos, lo que provoca que se lean registros mientras se espera. Los ejecutores que se retrasan de forma constante en las lecturas y escrituras pueden indicar una contención de recursos en esos nodos o ineficiencias de código específicas del ejecutor. |
| Proporción del tiempo de escritura de shuffle en relación con el tiempo de ejecución | La métrica muestra la cantidad de tiempo que el ejecutor dedicó al tiempo de ejecución de la aleatorización en comparación con el tiempo de ejecución general. Si este valor es alto para algunos ejecutores, puede indicar una asimetría de datos o una serialización de datos ineficiente. Puedes identificar las etapas con tiempos de escritura de la aleatorización prolongados en la IU de Spark. Busca tareas atípicas dentro de esas etapas que tarden más del tiempo promedio en completarse. Verifica si los ejecutores con tiempos de escritura de intercambio altos también muestran una actividad de E/S de disco alta. Podría ser útil una serialización más eficiente y pasos de partición adicionales. Las escrituras de registros muy grandes en comparación con las lecturas de registros pueden indicar una duplicación de datos no deseada debido a uniones ineficientes o transformaciones incorrectas. |
| Métricas a nivel de la aplicación | |
| Avance entre etapas | Esta métrica muestra la cantidad de etapas en las etapas con errores, en espera y en ejecución. Una gran cantidad de etapas fallidas o en espera puede indicar una distorsión de los datos. Verifica las particiones de datos y depura el motivo de la falla de la etapa con la pestaña Stages en la IU de Spark. |
| Ejecutores de Spark por lotes | Esta métrica muestra la cantidad de ejecutores que podrían ser necesarios en comparación con la cantidad de ejecutores en ejecución. Una gran diferencia entre los ejecutores requeridos y los en ejecución puede indicar problemas de ajuste de escala automático. |
| Métricas a nivel de la VM | |
| Memoria usada | Esta métrica muestra el porcentaje de memoria de la VM en uso. Si el porcentaje de la instancia principal es alto, puede indicar que el controlador está bajo presión de memoria. En el caso de otros nodos de VM, un porcentaje alto puede indicar que los ejecutores se están quedando sin memoria, lo que puede generar un alto derrame de disco y un tiempo de ejecución de la carga de trabajo más lento. Usa la IU de Spark para analizar los ejecutores y verificar si hay un tiempo de GC alto y una gran cantidad de errores de tareas. También depura el código de Spark para el almacenamiento en caché de conjuntos de datos grandes y la transmisión innecesaria de variables. |
Registros del trabajo
La página Detalles del lote incluye una sección Registros de trabajos que enumera las advertencias y los errores filtrados de los registros de trabajos (carga de trabajo por lotes). Esta función permite identificar rápidamente los problemas críticos sin necesidad de analizar manualmente los extensos archivos de registro. Puedes seleccionar una gravedad del registro (por ejemplo, Error) en el menú desplegable y agregar un filtro de texto para restringir los resultados. Para realizar un análisis más detallado, haz clic en el ícono Ver en el Explorador de registros para abrir los registros por lotes seleccionados en el Explorador de registros.
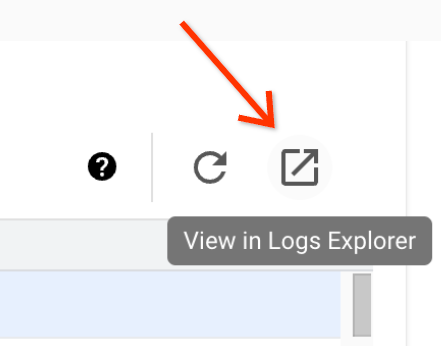
Ejemplo: Explorador de registros se abre después de elegir Errors en el selector de gravedad de la página Detalles del lote en la consola de Google Cloud .
IU de Spark
La IU de Spark recopila detalles de la ejecución de Apache Spark de las cargas de trabajo por lotes de Serverless para Apache Spark. No se aplican cargos por usar la función de la IU de Spark, que está habilitada de forma predeterminada.
Los datos recopilados por la función de la IU de Spark se conservan durante 90 días. Puedes usar esta interfaz web para supervisar y depurar cargas de trabajo de Spark sin tener que crear un servidor de historial persistente.
Permisos y roles necesarios de Identity and Access Management
Se requieren los siguientes permisos para usar la función de IU de Spark con cargas de trabajo por lotes.
Permiso de recopilación de datos:
dataproc.batches.sparkApplicationWrite. Este permiso se debe otorgar a la cuenta de servicio que ejecuta cargas de trabajo por lotes. Este permiso se incluye en el rolDataproc Worker, que se otorga automáticamente a la cuenta de servicio predeterminada de Compute Engine que Serverless para Apache Spark usa de forma predeterminada (consulta Cuenta de servicio de Serverless para Apache Spark). Sin embargo, si especificas una cuenta de servicio personalizada para tu carga de trabajo por lotes, debes agregar el permisodataproc.batches.sparkApplicationWritea esa cuenta de servicio (por lo general, otorgándole a la cuenta de servicio el rolWorkerde Dataproc).Permiso de acceso a la IU de Spark:
dataproc.batches.sparkApplicationRead. Este permiso se debe otorgar a un usuario para que pueda acceder a la IU de Spark en la consola deGoogle Cloud . Este permiso se incluye en los rolesDataproc Viewer,Dataproc EditoryDataproc Administrator. Para abrir la IU de Spark en la consola de Google Cloud , debes tener uno de estos roles o un rol personalizado que incluya este permiso.
Abre la IU de Spark
La página de la IU de Spark está disponible en las cargas de trabajo por lotes de la consola de Google Cloud .
Ve a la página Sesiones interactivas de Serverless para Apache Spark.
Haz clic en un ID de lote para abrir la página Detalles del lote.
Haz clic en Ver IU de Spark en el menú superior.
El botón Ver IU de Spark está inhabilitado en los siguientes casos:
- Si no se otorga un permiso obligatorio
- Si desmarcas la casilla de verificación Habilitar IU de Spark en la página Detalles del lote
- Si configuras la propiedad
spark.dataproc.appContext.enabledcomofalsecuando envías una carga de trabajo por lotes
Investigaciones potenciadas por IA con Gemini Cloud Assist (versión preliminar)
Descripción general
La función en versión preliminar de Gemini Cloud Assist Investigations usa las capacidades avanzadas de Gemini para ayudar a crear y ejecutar cargas de trabajo por lotes de Serverless for Apache Spark. Esta función analiza las cargas de trabajo con errores y las que se ejecutan con lentitud para identificar las causas raíz y recomendar correcciones. Crea análisis persistentes que puedes revisar, guardar y compartir con el equipo de asistencia para facilitar la colaboración y acelerar la resolución de problemas. Google Cloud
Funciones
Sigue estos pasos para crear investigaciones desde la consola de Google Cloud :
- Agrega una descripción del contexto en lenguaje natural a un problema antes de crear una investigación.
- Analizar las cargas de trabajo por lotes lentas y con errores
- Obtén estadísticas sobre las causas raíz de los problemas con las correcciones recomendadas.
- Crea Google Cloud casos de asistencia con el contexto completo de la investigación adjunto.
Antes de comenzar
Para comenzar a usar la función de investigación, en tu proyecto de Google Cloud , habilita la API de Gemini Cloud Assist.
Inicia una investigación
Para iniciar una investigación, realiza una de las siguientes acciones:
Opción 1: En la consola de Google Cloud , ve a la página de la lista de lotes. En el caso de los lotes con el estado
Failed, aparece un botón INVESTIGAR en la columna Estadísticas de Gemini. Haz clic en el botón para iniciar una investigación.
Opción 2: Abre la página Detalles del lote de la carga de trabajo por lotes para investigar. Para las cargas de trabajo por lotes de
SucceededyFailed, en la sección Descripción general del estado de la pestaña Resumen, aparece un botón INVESTIGAR en el panel Estadísticas de Gemini. Haz clic en el botón para iniciar una investigación.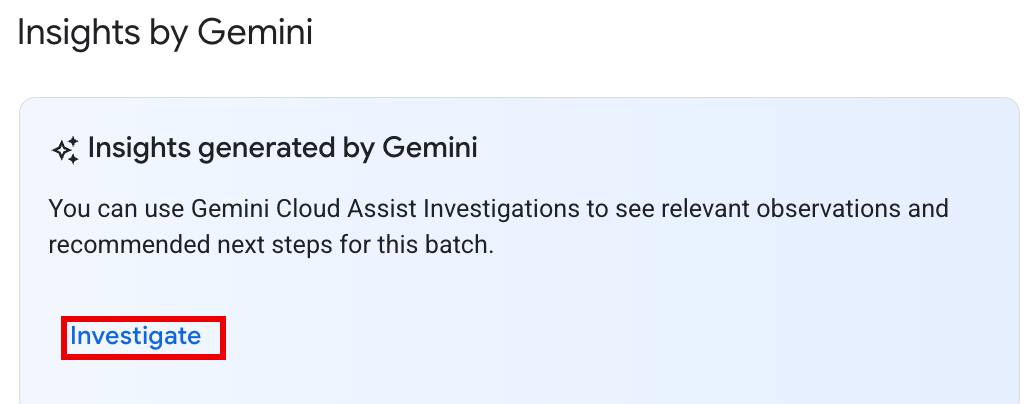
El texto del botón de investigación indica el estado de la investigación:
- INVESTIGATE: No se ejecutó ninguna investigación para este batch_details. Haz clic en el botón para iniciar una investigación.
- VER INVESTIGACIÓN: Se completó una investigación. Haz clic en el botón para ver los resultados.
- INVESTIGANDO: Se está realizando una investigación.
Interpreta los resultados de la investigación
Una vez que se completa una investigación, se abre la página Detalles de la investigación. Esta página contiene el análisis completo de Gemini, que se organiza en las siguientes secciones:
- Problema: Es una sección contraída que contiene detalles completados automáticamente de la carga de trabajo por lotes que se está investigando.
- Observaciones pertinentes: Es una sección contraída que enumera los puntos de datos y las anomalías clave que Gemini encontró durante su análisis de los registros y las métricas.
- Hipótesis: Esta es la sección principal, que se expande de forma predeterminada.
Presenta una lista de posibles causas raíz del problema observado. Cada hipótesis incluye lo siguiente:
- Descripción general: Es una descripción de la posible causa, como "Tiempo de escritura de Shuffle alto y posible sesgo de la tarea".
- Recommended Fixes: Una lista de pasos prácticos para abordar el problema potencial.
Toma medidas
Después de revisar las hipótesis y las recomendaciones, haz lo siguiente:
Aplica una o más de las correcciones sugeridas a la configuración o el código del trabajo y, luego, vuelve a ejecutarlo.
Para brindar comentarios sobre la utilidad de la investigación, haz clic en los íconos de Me gusta o No me gusta que se encuentran en la parte superior del panel.
Revisar y derivar investigaciones
Para revisar los resultados de una investigación ejecutada anteriormente, haz clic en el nombre de la investigación en la página Investigaciones de Cloud Assist para abrir la página Detalles de la investigación.
Si necesitas más ayuda, puedes abrir un Google Cloud caso de asistencia. Este proceso le proporciona al ingeniero de asistencia al cliente el contexto completo de la investigación realizada anteriormente, incluidas las observaciones y las hipótesis generadas por Gemini. Este uso compartido del contexto reduce significativamente la comunicación de ida y vuelta necesaria con el equipo de asistencia al cliente y permite resolver los casos más rápido.
Sigue estos pasos para crear un caso de asistencia a partir de una investigación:
En la página Detalles de la investigación, haz clic en Solicitar asistencia.
Estado y precios de la versión preliminar
No se aplican cargos por las investigaciones de Gemini Cloud Assist durante la versión preliminar pública. Se aplicarán cargos a la función cuando esté disponible para el público en general (DG).
Para obtener más información sobre los precios después de la disponibilidad general, consulta Precios de Gemini Cloud Assist.
Versión preliminar de Pregúntale a Gemini (se retirará el 22 de septiembre de 2025)
La función de vista previa Pregúntale a Gemini proporcionaba acceso con un solo clic a estadísticas en las páginas Lotes y Detalles del lote de la consola de Google Cloud a través de un botón Pregúntale a Gemini. Esta función generó un resumen de los errores, las anomalías y las posibles mejoras en el rendimiento según los registros y las métricas de la carga de trabajo.
Después de que se retire la versión preliminar de "Pregúntale a Gemini" el 22 de septiembre de 2025, los usuarios podrán seguir obteniendo asistencia potenciada por IA con la función de investigaciones de Gemini Cloud Assist.
Importante: Para garantizar una asistencia ininterrumpida de la IA para la solución de problemas, se recomienda habilitar Gemini Cloud Assist Investigations antes del 22 de septiembre de 2025.
Registros de Serverless para Apache Spark
El registro está habilitado de forma predeterminada en Serverless para Apache Spark, y los registros de carga de trabajo persisten después de que finaliza una carga de trabajo. Serverless for Apache Spark recopila registros de cargas de trabajo en Cloud Logging.
Puedes acceder a los registros de Serverless para Apache Spark en el recurso Cloud Dataproc Batch del Explorador de registros.
Cómo consultar los registros de Serverless para Apache Spark
El Explorador de registros de la consola de Google Cloud proporciona un panel de consultas para ayudarte a compilar una consulta que te permita examinar los registros de la carga de trabajo por lotes. Estos son los pasos que puedes seguir para crear una consulta y examinar los registros de la carga de trabajo por lotes:
- Se seleccionará tu proyecto actual. Puedes hacer clic en Refine scope Project para seleccionar otro proyecto.
Define una consulta de registros por lotes.
Usa los menús de filtro para filtrar una carga de trabajo por lotes.
En Todos los recursos, selecciona el recurso Lote de Cloud Dataproc.
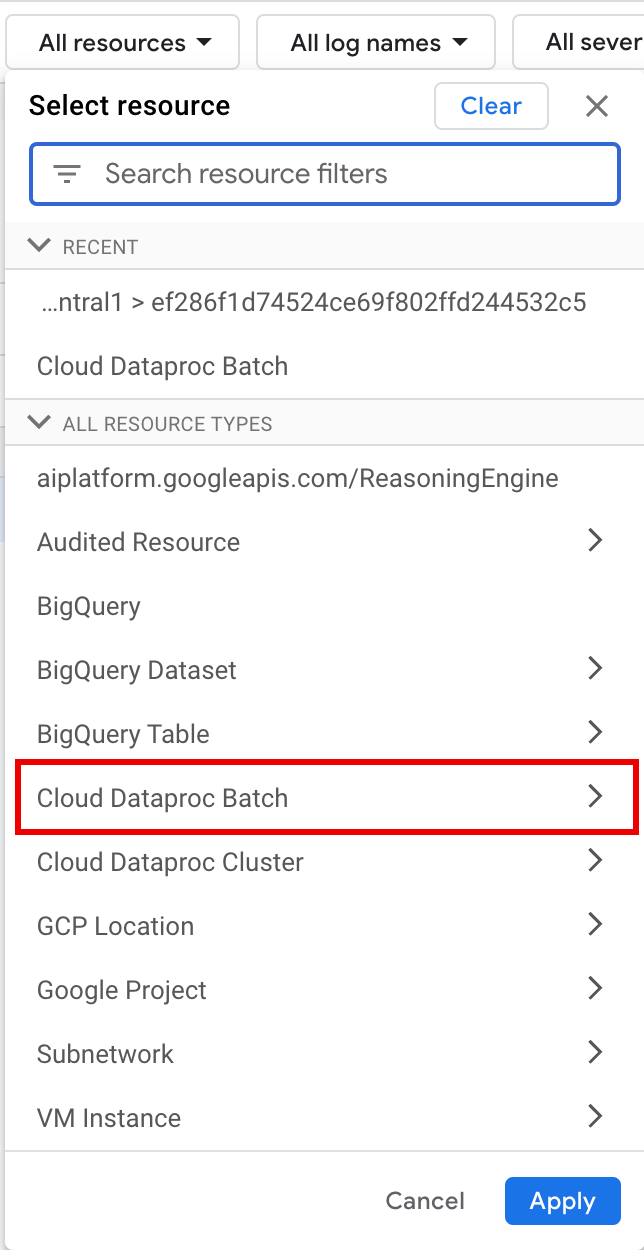
En el panel Seleccionar recurso, selecciona el lote LOCATION y, luego, el ID DEL LOTE. Estos parámetros de lotes se enumeran en la página Lotes de Dataproc en la consola de Google Cloud .
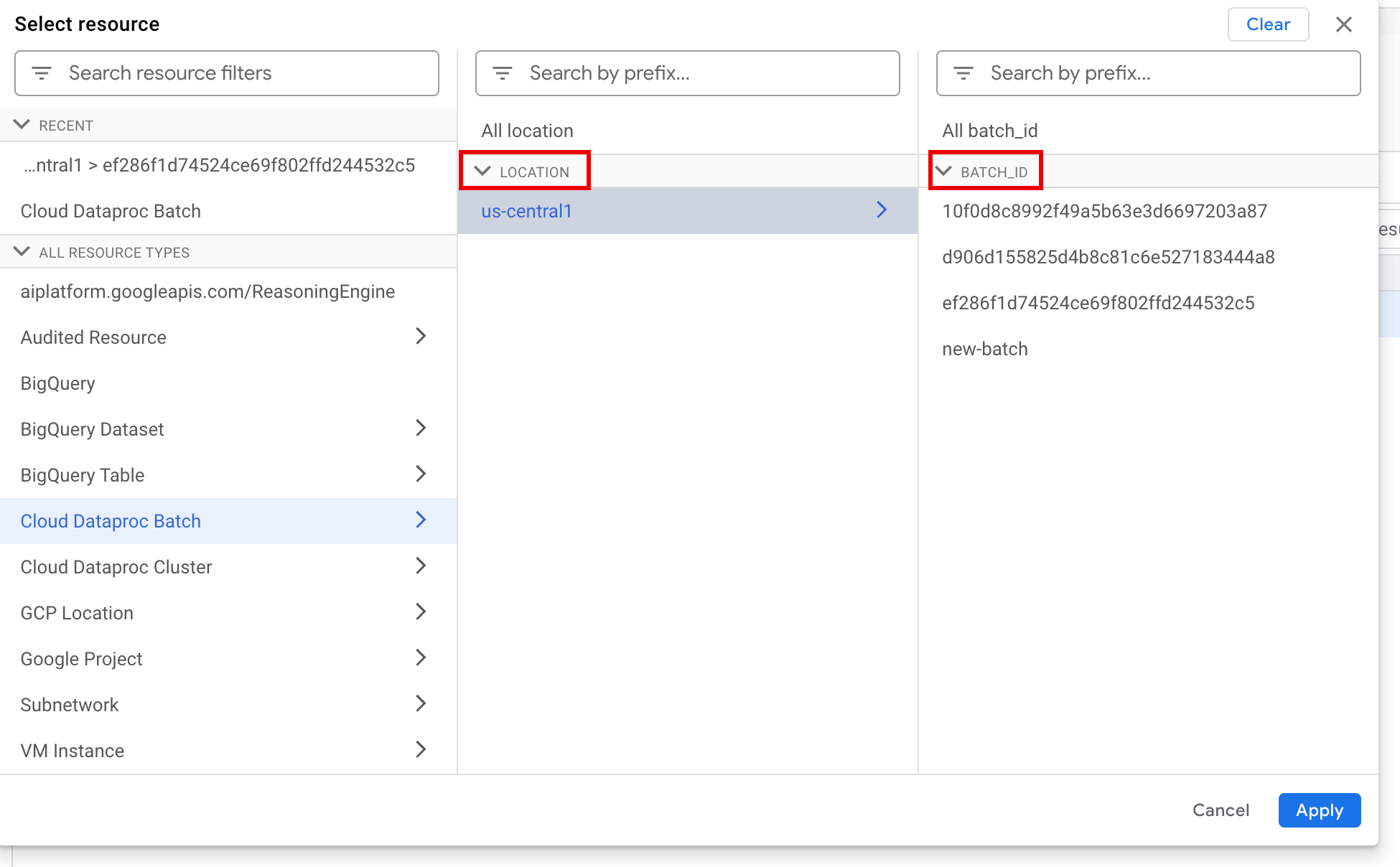
Haz clic en Aplicar.
En Selecciona nombres de registros, ingresa
dataproc.googleapis.comen el cuadro Buscar nombres de registros para limitar los tipos de registros que se consultarán. Selecciona uno o más de los nombres de archivos de registro que se muestran en la lista.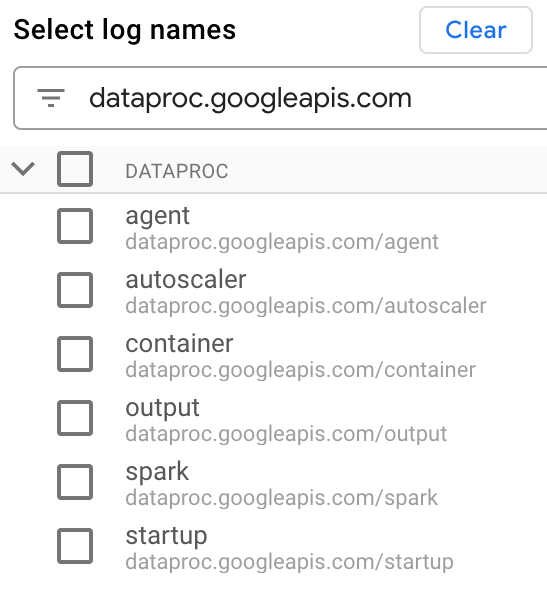
Usa el editor de consultas para filtrar los registros específicos de la VM.
Especifica el tipo de recurso y el nombre del recurso de VM, como se muestra en el siguiente ejemplo:
resource.type="cloud_dataproc_batch" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
- BATCH_UUID: El UUID del lote se muestra en la página Detalles del lote de la consola de Google Cloud , que se abre cuando haces clic en el ID del lote en la página Lotes.
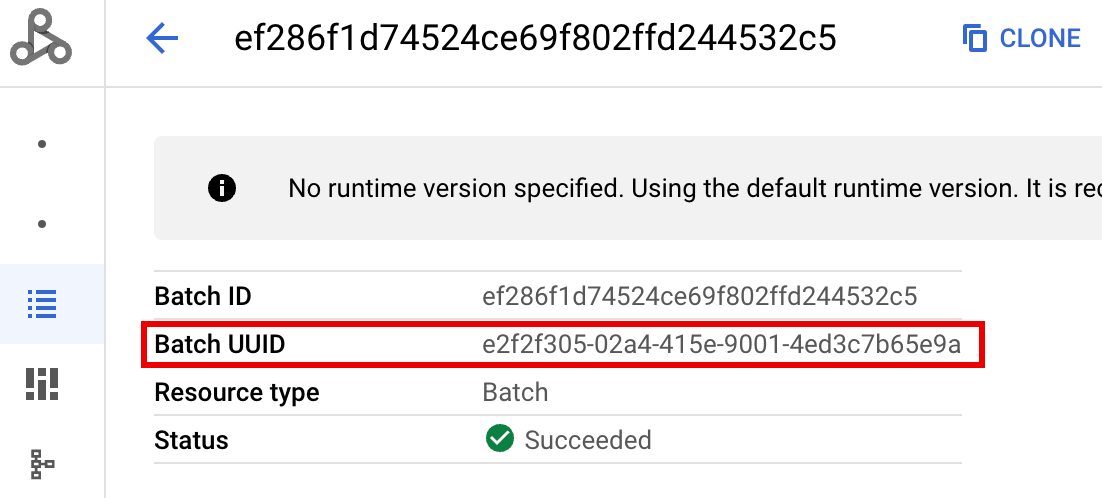
En los registros de lotes, también se muestra el UUID del lote en el nombre del recurso de la VM. Este es un ejemplo de un archivo driver.log por lotes:
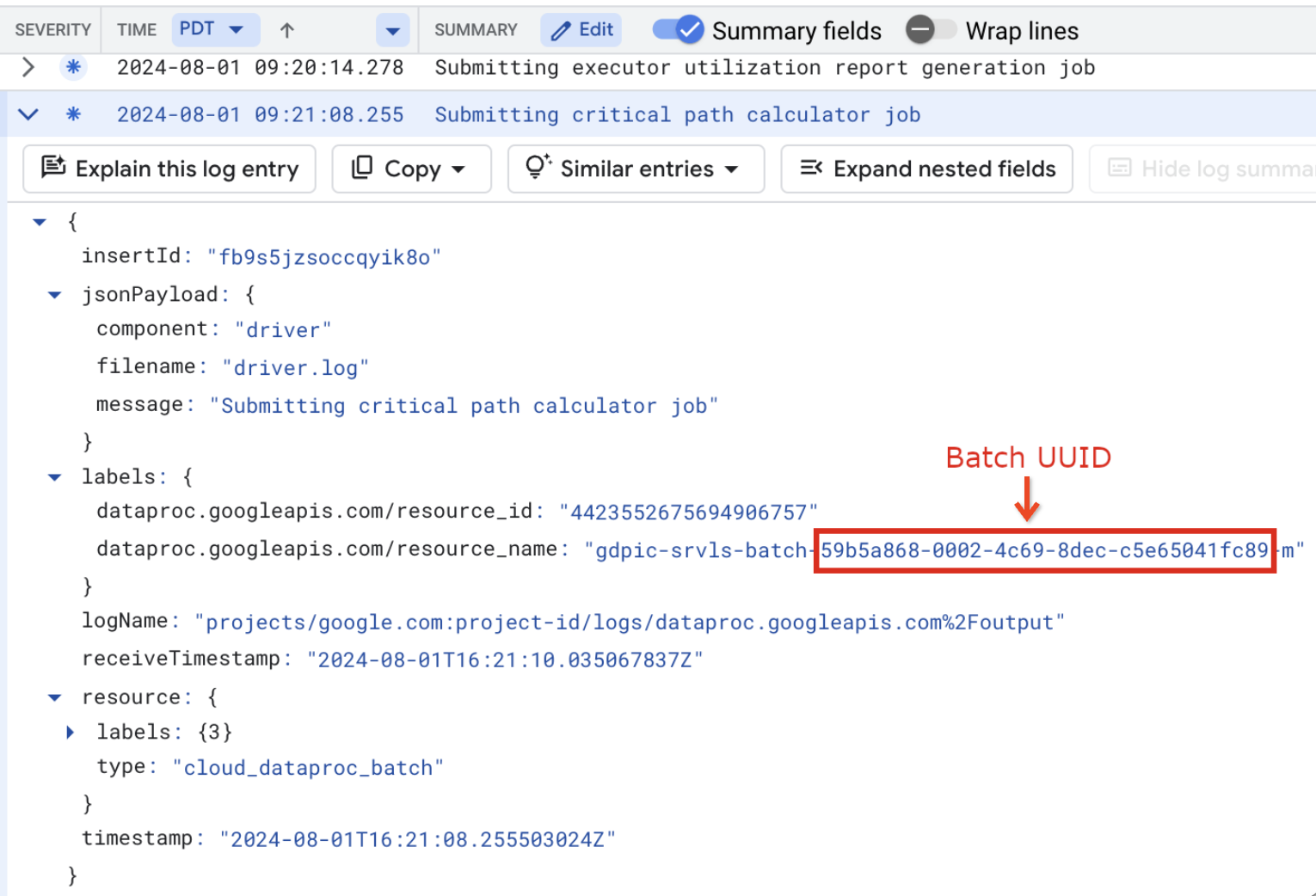
- BATCH_UUID: El UUID del lote se muestra en la página Detalles del lote de la consola de Google Cloud , que se abre cuando haces clic en el ID del lote en la página Lotes.
Haz clic en Ejecutar consulta.
Tipos de registros y ejemplos de consultas de Serverless para Apache Spark
En la siguiente lista, se describen los diferentes tipos de registros de Serverless para Apache Spark y se proporcionan ejemplos de consultas del Explorador de registros para cada tipo de registro.
dataproc.googleapis.com/output: Este archivo de registro contiene el resultado de la carga de trabajo por lotes. Serverless for Apache Spark transmite por lotes el resultado al espacio de nombresoutputy establece el nombre de archivo enJOB_ID.driver.log.Consulta de muestra del Explorador de registros para los registros de salida:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Foutput"
dataproc.googleapis.com/spark: El espacio de nombressparkagrega los registros de Spark para los daemons y los ejecutores que se ejecutan en las VMs de trabajo y instancia principal del clúster de Dataproc. Cada entrada de registro incluye una etiqueta de componentemaster,workeroexecutorpara identificar la fuente del registro, de la siguiente manera:executor: Registros de los ejecutores de código del usuario. Por lo general, se trata de registros distribuidos.master: Registros de la instancia principal del administrador de recursos independiente de Spark, que son similares a los registros deResourceManagerde Dataproc en YARN de Compute Engine.worker: Registros del trabajador del administrador de recursos independiente de Spark, que son similares a los registros deNodeManagerde YARN de Dataproc en Compute Engine.
Consulta de muestra del Explorador de registros para todos los registros en el espacio de nombres
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark"
Consulta de muestra del Explorador de registros para los registros de componentes independientes de Spark en el espacio de nombres
spark:resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fspark" jsonPayload.component="COMPONENT"
dataproc.googleapis.com/startup: El espacio de nombresstartupincluye los registros de inicio por lotes (clúster). Se incluyen los registros de cualquier secuencia de comandos de inicialización. Los componentes se identifican por etiqueta, por ejemplo:startup-script[855]: ... activate-component-spark[3050]: ... enable spark-worker
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fstartup" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCH_UUID-VM_SUFFIX"
dataproc.googleapis.com/agent: El espacio de nombresagentagrega los registros del agente de Dataproc. Cada entrada de registro incluye una etiqueta de nombre de archivo que identifica la fuente del registro.Ejemplo de consulta del Explorador de registros para los registros del agente generados por una VM de trabajador especificada:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fagent" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
dataproc.googleapis.com/autoscaler: El espacio de nombresautoscaleragrega los registros del escalador automático de Serverless for Apache Spark.Ejemplo de consulta del Explorador de registros para los registros del agente generados por una VM de trabajador especificada:
resource.type="cloud_dataproc_batch" resource.labels.location="REGION" resource.labels.batch_id="BATCH_ID" logName="projects/PROJECT_ID/logs/dataproc.googleapis.com%2Fautoscaler" labels."dataproc.googleapis.com/resource_name"="gdpic-srvls-batch-BATCHUUID-wWORKER#"
Para obtener más información, consulta Registros de Dataproc.
Si deseas obtener información sobre los registros de auditoría de Serverless para Apache Spark, consulta Registros de auditoría de Dataproc.
Métricas de cargas de trabajo
Serverless for Apache Spark proporciona métricas de Spark y de lotes que puedes ver en el Explorador de métricas o en la página Detalles del lote de la consola de Google Cloud .
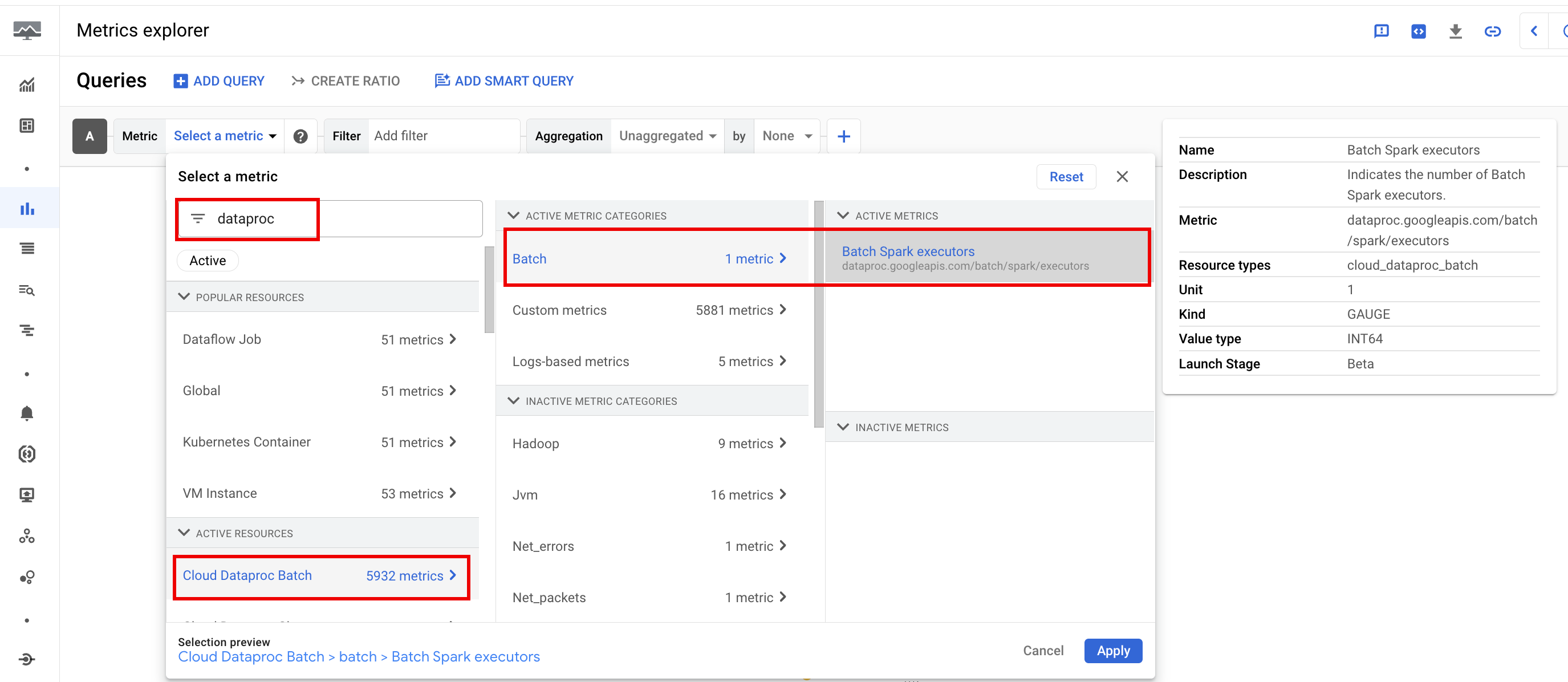
Métricas de lotes
Las métricas de recursos de Dataproc batch proporcionan estadísticas sobre los recursos por lotes, como la cantidad de ejecutores por lotes. Las métricas de lote tienen el prefijo dataproc.googleapis.com/batch.
Métricas de Spark
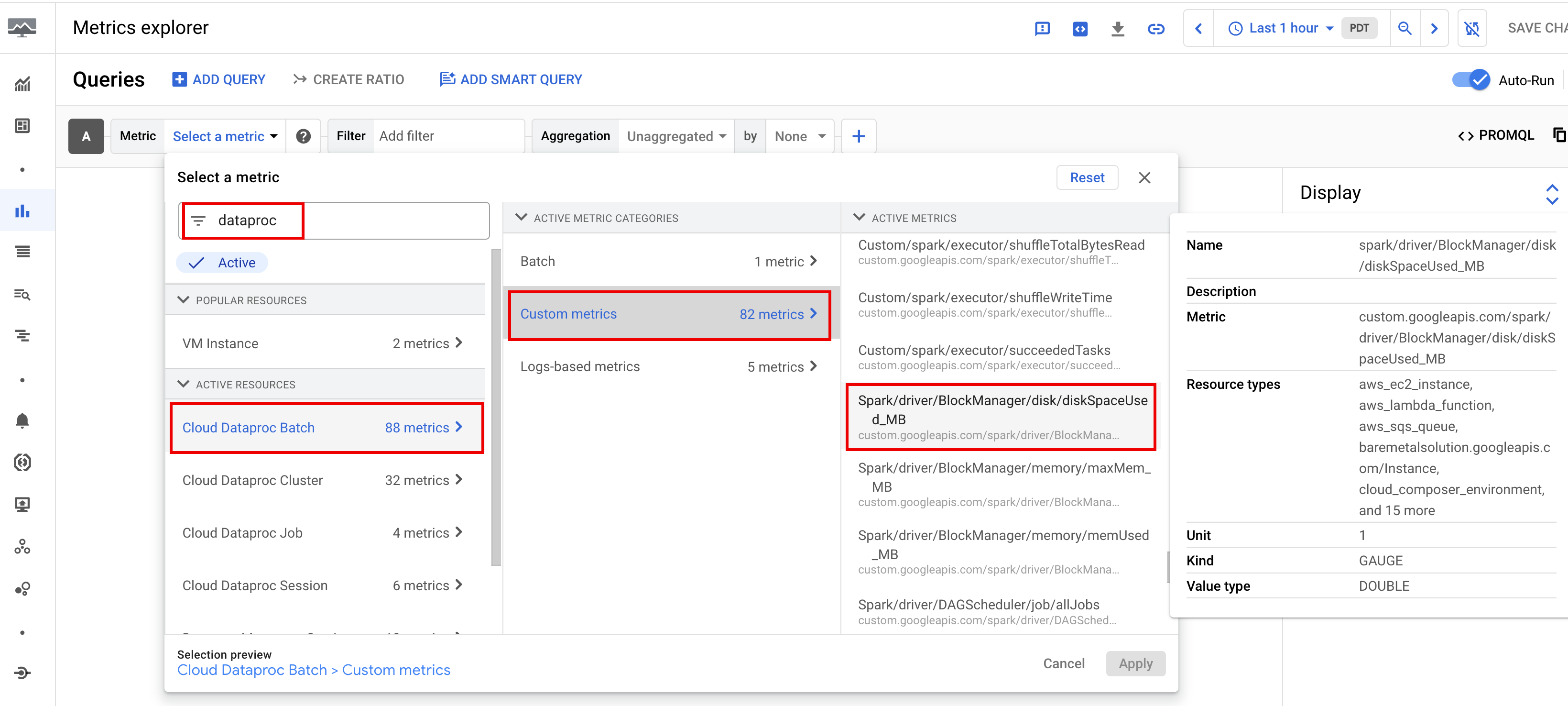
De forma predeterminada, Serverless para Apache Spark habilita la recopilación de las métricas de Spark disponibles, a menos que uses las propiedades de recopilación de métricas de Spark para inhabilitar o anular la recopilación de una o más métricas de Spark.
Las métricas de Spark disponibles incluyen las métricas del controlador y del ejecutor de Spark, y las métricas del sistema. Las métricas de Spark disponibles tienen el prefijo custom.googleapis.com/.
Configura alertas de métricas
Puedes crear alertas de métricas de Dataproc para recibir notificaciones sobre problemas de cargas de trabajo.
Crea gráficos
Puedes crear gráficos que visualicen las métricas de carga de trabajo con el Explorador de métricas en la consola deGoogle Cloud . Por ejemplo, puedes crear un gráfico para mostrar disk:bytes_used y, luego, filtrar por batch_id.
Cloud Monitoring
Monitoring usa metadatos y métricas de la carga de trabajo para proporcionar estadísticas sobre el estado y el rendimiento de las cargas de trabajo de Serverless para Apache Spark. Las métricas de carga de trabajo incluyen métricas de Spark, métricas de lotes y métricas de operación.
Puedes usar Cloud Monitoring en la consola de Google Cloud para explorar métricas, agregar gráficos, crear paneles y crear alertas.
Crea paneles
Puedes crear un panel para supervisar las cargas de trabajo con métricas de varios proyectos y diferentes productos de Google Cloud . Para obtener más información, consulta Crea y administra paneles personalizados.
Servidor de historial persistente
Serverless para Apache Spark crea los recursos de procesamiento necesarios para ejecutar una carga de trabajo, ejecuta la carga de trabajo en esos recursos y, luego, borra los recursos cuando finaliza la carga de trabajo. Las métricas y los eventos de carga de trabajo no persisten después de que se completa una carga de trabajo. Sin embargo, puedes usar un servidor de historial persistente (PHS) para conservar el historial de aplicaciones de la carga de trabajo (registros de eventos) en Cloud Storage.
Para usar un PHS con una carga de trabajo por lotes, haz lo siguiente:
Crea un servidor de historial persistente (PHS) de Dataproc.
Especifica tu PHS cuando envíes una carga de trabajo.
Usa la puerta de enlace del componente para conectarte al PHS y ver los detalles de la aplicación, las etapas del programador, los detalles a nivel de la tarea y la información del entorno y del ejecutor.
Ajuste automático
- Habilita el ajuste automático para Serverless for Apache Spark: Puedes habilitar el ajuste automático para Serverless for Apache Spark cuando envíes cada carga de trabajo por lotes recurrente de Spark con la Google Cloud consola, la gcloud CLI o la API de Dataproc.
Console
Sigue estos pasos para habilitar el ajuste automático en cada carga de trabajo recurrente por lotes de Spark:
En la consola de Google Cloud , ve a la página Lotes de Dataproc.
Para crear una carga de trabajo por lotes, haz clic en Crear.
En la sección Contenedor, completa el nombre de la cohorte, que identifica el lote como parte de una serie de cargas de trabajo recurrentes. El análisis asistido por Gemini se aplica a la segunda carga de trabajo y a las posteriores que se envían con este nombre de cohorte. Por ejemplo, especifica
TPCH-Query1como el nombre de la cohorte para una carga de trabajo programada que ejecuta una consulta de TPC-H diaria.Completa otras secciones de la página Crear lote según sea necesario y, luego, haz clic en Enviar. Para obtener más información, consulta Envía una carga de trabajo por lotes.
gcloud
Ejecuta el siguiente comando de gcloud dataproc batches submit de gcloud CLI de forma local en una ventana de la terminal o en Cloud Shell para habilitar el ajuste automático en cada carga de trabajo recurrente por lotes de Spark:
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ other arguments ...
Reemplaza lo siguiente:
- COMMAND: Es el tipo de carga de trabajo de Spark, como
Spark,PySpark,Spark-SqloSpark-R. - REGION: Es la región en la que se ejecutará tu carga de trabajo.
- COHORT: Es el nombre de la cohorte, que identifica el lote como una de una serie de cargas de trabajo recurrentes.
El análisis asistido por Gemini se aplica a la segunda y las siguientes cargas de trabajo que se envían con este nombre de cohorte. Por ejemplo, especifica
TPCH Query 1como el nombre de la cohorte para una carga de trabajo programada que ejecuta una consulta de TPC-H diaria.
API
Incluye el nombre de RuntimeConfig.cohort en una solicitud de batches.create para habilitar el ajuste automático en cada carga de trabajo recurrente por lotes de Spark. El ajuste automático se aplica a la segunda y las siguientes cargas de trabajo enviadas con este nombre de cohorte. Por ejemplo, especifica TPCH-Query1 como el nombre de la cohorte para una carga de trabajo programada que ejecuta una consulta de TPC-H diaria.
Ejemplo:
...
runtimeConfig:
cohort: TPCH-Query1
...