Usa el conector de BigQuery con Google Cloud Serverless for Apache Spark
Organiza tus páginas con colecciones
Guarda y categoriza el contenido según tus preferencias.
Usa el conector de Spark-BigQuery con Apache Spark para leer y escribir datos desde y hacia BigQuery.
En este instructivo, se muestra una aplicación de PySpark que usa spark-bigquery-connector.
Usa el conector de BigQuery con tu carga de trabajo
Consulta las versiones de tiempo de ejecución de Serverless for Apache Spark para determinar la versión del conector de BigQuery que está instalada en la versión de tiempo de ejecución de tu carga de trabajo por lotes. Si el conector no aparece en la lista, consulta la siguiente sección para obtener instrucciones sobre cómo hacer que el conector esté disponible para las aplicaciones.
Cómo usar el conector con la versión 2.0 del entorno de ejecución de Spark
El conector de BigQuery no está instalado en la versión 2.0 del tiempo de ejecución de Spark. Cuando usas la versión 2.0 del entorno de ejecución de Spark, puedes hacer que el conector esté disponible para tu aplicación de una de las siguientes maneras:
Usa el parámetro jars para apuntar a un archivo .jar del conector cuando envíes tu carga de trabajo por lotes de Google Cloud Serverless for Apache Spark. En el siguiente ejemplo, se especifica un archivo .jar del conector (consulta el repositorio de GoogleCloudDataproc/spark-bigquery-connector en GitHub para obtener una lista de los archivos .jar del conector disponibles).
El conector escribe el resultado del recuento de palabras en BigQuery de la siguiente manera:
Almacenamiento en búfer de los datos en archivos temporales en tu bucket de Cloud Storage
Copiar los datos en una operación desde tu bucket de Cloud Storage a BigQuery
Borra los archivos temporales en Cloud Storage después de que se completa la operación de carga de BigQuery (los archivos temporales también se borran después de que finaliza la aplicación Spark). Si falla la eliminación, deberás borrar los archivos temporales no deseados de Cloud Storage, que suelen colocarse en gs://YOUR_BUCKET/.spark-bigquery-JOB_ID-UUID.
Configura la facturación
De forma predeterminada, el proyecto asociado con las credenciales o la cuenta de servicio se factura por el uso de la API. Para facturar un proyecto diferente, establece la siguiente configuración: spark.conf.set("parentProject", "<BILLED-GCP-PROJECT>").
También puedes agregarla a una operación de lectura o escritura, de la siguiente manera: .option("parentProject", "<BILLED-GCP-PROJECT>").
Envía una carga de trabajo por lotes de conteo de palabras de PySpark
Ejecuta una carga de trabajo por lotes de Spark que cuenta la cantidad de palabras en un conjunto de datos públicos.
Reemplaza YOUR_BUCKET por el nombre del
bucket de Cloud Storage que creaste.
Copia el siguiente código de PySpark para crear el archivo wordcount.py de forma local en un editor de texto.
#!/usr/bin/python"""BigQuery I/O PySpark example."""frompyspark.sqlimportSparkSessionspark=SparkSession \
.builder \
.appName('spark-bigquery-demo') \
.getOrCreate()# Use the Cloud Storage bucket for temporary BigQuery export data used# by the connector.bucket="YOUR_BUCKET"spark.conf.set('temporaryGcsBucket',bucket)# Load data from BigQuery.words=spark.read.format('bigquery') \
.option('table','bigquery-public-data:samples.shakespeare') \
.load()words.createOrReplaceTempView('words')# Perform word count.word_count=spark.sql('SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word')word_count.show()word_count.printSchema()# Saving the data to BigQueryword_count.write.format('bigquery') \
.option('table','wordcount_dataset.wordcount_output') \
.save()
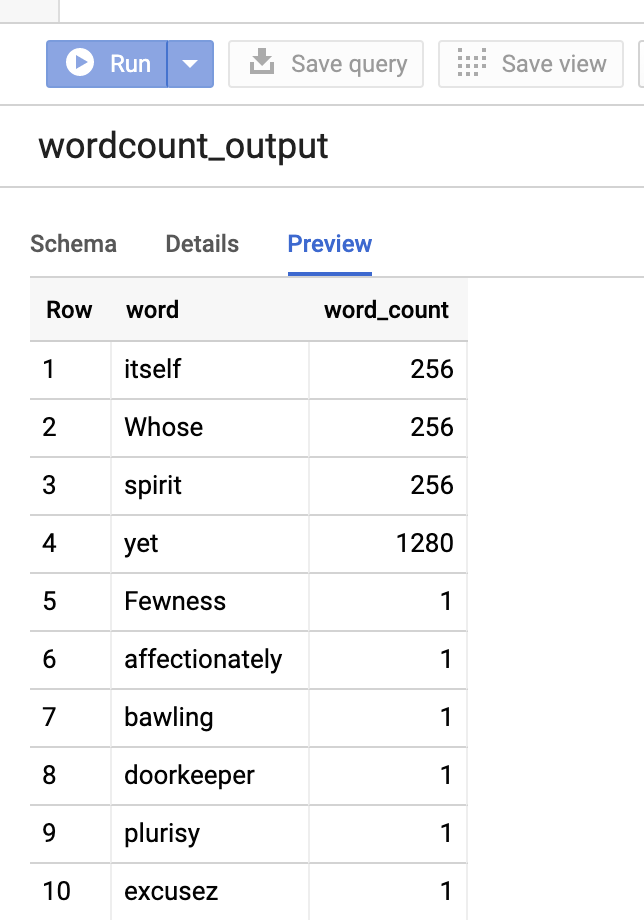
Para obtener una vista previa de la tabla de salida en la consola de Google Cloud , abre la página de tu proyecto de
BigQuery,
selecciona la tabla wordcount_output y, luego, haz clic en
Vista previa.
[[["Fácil de comprender","easyToUnderstand","thumb-up"],["Resolvió mi problema","solvedMyProblem","thumb-up"],["Otro","otherUp","thumb-up"]],[["Difícil de entender","hardToUnderstand","thumb-down"],["Información o código de muestra incorrectos","incorrectInformationOrSampleCode","thumb-down"],["Faltan la información o los ejemplos que necesito","missingTheInformationSamplesINeed","thumb-down"],["Problema de traducción","translationIssue","thumb-down"],["Otro","otherDown","thumb-down"]],["Última actualización: 2025-09-04 (UTC)"],[[["\u003cp\u003eThe \u003ccode\u003espark-bigquery-connector\u003c/code\u003e allows Apache Spark to read and write data to and from BigQuery, leveraging the BigQuery Storage API for efficient data retrieval.\u003c/p\u003e\n"],["\u003cp\u003eWhen using Spark runtime version 2.0, the BigQuery connector must be made available to the application either by using the \u003ccode\u003ejars\u003c/code\u003e parameter when submitting the batch workload or by including the connector JAR file as a dependency in the Spark application.\u003c/p\u003e\n"],["\u003cp\u003eThis tutorial demonstrates a PySpark word count application that reads data from BigQuery, performs the word count operation, and writes the result back to BigQuery, using temporary files in a Cloud Storage bucket.\u003c/p\u003e\n"],["\u003cp\u003eThe tutorial outlines the necessary steps to set up and submit a PySpark batch workload, including creating a BigQuery dataset, a Cloud Storage bucket, writing the \u003ccode\u003ewordcount.py\u003c/code\u003e code, and submitting the workload via the Google Cloud CLI.\u003c/p\u003e\n"],["\u003cp\u003eBilling for API usage is associated with the project credentials by default, but a different project can be specified for billing through the \u003ccode\u003eparentProject\u003c/code\u003e configuration setting.\u003c/p\u003e\n"]]],[],null,["# Use the BigQuery connector with Google Cloud Serverless for Apache Spark\n\nUse the [spark-bigquery-connector](https://github.com/GoogleCloudDataproc/spark-bigquery-connector)\nwith [Apache Spark](https://spark.apache.org \"Apache Spark\")\nto read and write data from and to [BigQuery](/bigquery \"BigQuery\").\nThis tutorial demonstrates a PySpark application that uses the\n`spark-bigquery-connector`.\n| The spark-bigquery-connector takes advantage of the [BigQuery\n| Storage API](/bigquery/docs/reference/storage) when reading data from BigQuery.\n\nUse the BigQuery connector with your workload\n---------------------------------------------\n\nSee [Serverless for Apache Spark runtime releases](/dataproc-serverless/docs/concepts/versions/spark-runtime-versions)\nto determine the BigQuery connector version that is installed in\nyour batch workload runtime version. If the connector is not listed,\nsee the next section for instructions on how to make the connector available to\napplications.\n| **Note:** You can update the installed BigQuery connector version using the `dataproc.sparkBqConnector.version` property (see [Other Spark properties](/dataproc-serverless/docs/concepts/properties#other_properties)).\n\n### How to use the connector with Spark runtime version 2.0\n\nThe BigQuery connector is not installed in Spark runtime version 2.0. When using\nSpark runtime version 2.0, you can make the connector available to your application\nin one of the following ways:\n\n- Use the `jars` parameter to point to a connector jar file when you submit your Google Cloud Serverless for Apache Spark batch workload The following example specifies a connector jar file (see the [GoogleCloudDataproc/spark-bigquery-connector](https://github.com/GoogleCloudDataproc/spark-bigquery-connector/releases) repository on GitHub for a list of available connector jar files).\n - Google Cloud CLI example: \n\n ```\n gcloud dataproc batches submit pyspark \\\n --region=region \\\n --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.13-version.jar \\\n ... other args\n ```\n- Include the connector jar file in your Spark application as a dependency (see [Compiling against the connector](https://github.com/GoogleCloudDataproc/spark-bigquery-connector#compiling-against-the-connector))\n\n| **Note:** If the connector is not available to your application at runtime, a `ClassNotFoundException` is thrown.\n\nCalculate costs\n---------------\n\nThis tutorial uses billable components of Google Cloud, including:\n\n- Serverless for Apache Spark\n- BigQuery\n- Cloud Storage\n\nUse the [Pricing Calculator](/products/calculator) to generate a cost\nestimate based on your projected usage.\n\nNew Cloud Platform users may be eligible for a [free trial](/free-trial). \n\n\u003cbr /\u003e\n\nBigQuery I/O\n------------\n\nThis example reads data from\n[BigQuery](https://console.cloud.google.com/bigquery)\ninto a Spark DataFrame to perform a word count using the [standard data source\nAPI](https://spark.apache.org/docs/latest/sql-data-sources.html \"Data Sources\").\n\nThe connector writes the wordcount output to BigQuery as follows:\n\n1. Buffering the data into temporary files in your Cloud Storage bucket\n\n2. Copying the data in one operation from your Cloud Storage bucket into\n BigQuery\n\n3. Deleting the temporary files in Cloud Storage after the BigQuery\n load operation completes (temporary files are also deleted after\n the Spark application terminates). If deletion fails, you will need to delete\n any unwanted temporary Cloud Storage files, which typically are placed\n in `gs://`\u003cvar translate=\"no\"\u003eYOUR_BUCKET\u003c/var\u003e`/.spark-bigquery-`\u003cvar translate=\"no\"\u003eJOB_ID\u003c/var\u003e`-`\u003cvar translate=\"no\"\u003eUUID\u003c/var\u003e.\n\nConfigure billing\n-----------------\n\nBy default, the project associated with the credentials or service account is\nbilled for API usage. To bill a different project, set the following\nconfiguration: `spark.conf.set(\"parentProject\", \"\u003cBILLED-GCP-PROJECT\u003e\")`.\n\nYou can also add to a read or write operation, as follows:\n`.option(\"parentProject\", \"\u003cBILLED-GCP-PROJECT\u003e\")`.\n\nSubmit a PySpark wordcount batch workload\n-----------------------------------------\n\nRun a Spark batch workload that counts the number of words in a public dataset.\n\n1. Open a local terminal or [Cloud Shell](https://console.cloud.google.com/?cloudshell=true)\n2. Create the `wordcount_dataset` with the [bq](/bigquery/bq-command-line-tool) command-line tool in a local terminal or in [Cloud Shell](https://console.cloud.google.com/?cloudshell=true). \n\n ```\n bq mk wordcount_dataset\n ```\n3. Create a Cloud Storage bucket with the [Google Cloud CLI](/sdk/gcloud/reference/storage). \n\n ```\n gcloud storage buckets create gs://YOUR_BUCKET\n ```\n Replace \u003cvar translate=\"no\"\u003eYOUR_BUCKET\u003cvar translate=\"no\"\u003e\u003c/var\u003e\u003c/var\u003e with the name of the Cloud Storage bucket you created.\n4. Create the file `wordcount.py` locally in a text editor by copying the following PySpark code. \n\n ```python\n #!/usr/bin/python\n \"\"\"BigQuery I/O PySpark example.\"\"\"\n from pyspark.sql import SparkSession\n\n spark = SparkSession \\\n .builder \\\n .appName('spark-bigquery-demo') \\\n .getOrCreate()\n\n # Use the Cloud Storage bucket for temporary BigQuery export data used\n # by the connector.\n bucket = \"\u003cvar translate=\"no\"\u003eYOUR_BUCKET\u003c/var\u003e\"\n spark.conf.set('temporaryGcsBucket', bucket)\n\n # Load data from BigQuery.\n words = spark.read.format('bigquery') \\\n .option('table', 'bigquery-public-data:samples.shakespeare') \\\n .load()\n words.createOrReplaceTempView('words')\n\n # Perform word count.\n word_count = spark.sql(\n 'SELECT word, SUM(word_count) AS word_count FROM words GROUP BY word')\n word_count.show()\n word_count.printSchema()\n\n # Saving the data to BigQuery\n word_count.write.format('bigquery') \\\n .option('table', 'wordcount_dataset.wordcount_output') \\\n .save()\n ```\n5. Submit the PySpark batch workload: \n\n ```\n gcloud dataproc batches submit pyspark wordcount.py \\\n --region=REGION \\\n --deps-bucket=YOUR_BUCKET\n ```\n **Sample terminal output:** \n\n ```\n ...\n +---------+----------+\n | word|word_count|\n +---------+----------+\n | XVII| 2|\n | spoil| 28|\n | Drink| 7|\n |forgetful| 5|\n | Cannot| 46|\n | cures| 10|\n | harder| 13|\n | tresses| 3|\n | few| 62|\n | steel'd| 5|\n | tripping| 7|\n | travel| 35|\n | ransom| 55|\n | hope| 366|\n | By| 816|\n | some| 1169|\n | those| 508|\n | still| 567|\n | art| 893|\n | feign| 10|\n +---------+----------+\n only showing top 20 rows\n\n root\n |-- word: string (nullable = false)\n |-- word_count: long (nullable = true)\n ```\n\n To preview the output table in the Google Cloud console, open your project's [BigQuery](https://console.cloud.google.com/bigquery) page, select the `wordcount_output` table, and then click **Preview** .\n\nFor more information\n--------------------\n\n- [BigQuery Storage \\& Spark SQL - Python](https://github.com/tfayyaz/cloud-dataproc/blob/master/notebooks/python/1.2.%20BigQuery%20Storage%20%26%20Spark%20SQL%20-%20Python.ipynb)\n- [Creating a table definition file for an external data source](/bigquery/external-table-definition)\n- [Use externally partitioned data](/bigquery/docs/hive-partitioned-queries-gcs)"]]