Questo documento descrive come visualizzare e gestire i ruoli degli account di servizio Identity and Access Management. Un workload batch o una sessione interattiva di Serverless per Apache Spark viene eseguito come account di servizio predefinito di Compute Engine, a meno che tu non specifichi un service account personalizzato quando invii un workload batch, crei una sessione o crei un modello di runtime della sessione.
Requisito di sicurezza:devi disporre dell'autorizzazione
service account ActAs
per eseguire carichi di lavoro o sessioni di Serverless per Apache Spark. Il ruolo
Service Account User contiene questa autorizzazione. Per informazioni dettagliate sulle autorizzazioni del account di servizio,
consulta Ruoli per account di servizioe account.
Ruolo Dataproc Worker richiesto
L'account di servizio del carico di lavoro o della sessione Serverless per Apache Spark deve avere il ruolo IAM
Worker Dataproc. Il account di servizio predefinito di Compute Engine,
project_number-compute@developer.gserviceaccount.com,
utilizzato da Serverless per Apache Spark ha questo ruolo per impostazione predefinita. Se specifichi un
account di serviziot diverso quando crei un batch, una sessione o un modello di sessione,
devi concedere il ruolo Worker Dataproc aaccount di serviziont.
Per altre operazioni, come la lettura e la scrittura di dati da e verso Cloud Storage o BigQuery, potrebbero essere necessari ruoli aggiuntivi.
In alcuni progetti, al account di servizio della sessione o del workload batch potrebbe essere stato concesso automaticamente il ruolo Editor del progetto, che include le autorizzazioni del ruolo Worker Dataproc più autorizzazioni aggiuntive non necessarie per Serverless for Apache Spark. Per seguire il principio della best practice di sicurezza del privilegio minimo, sostituisci il ruolo Editor deaccount di serviziont con il ruolo Worker Dataproc.
Risolvere i problemi relativi agli errori basati sulle autorizzazioni
Autorizzazioni errate o insufficienti per l'account di servizio utilizzato dal tuo batch o sessione Serverless per Apache Spark possono causare errori di creazione di batch o sessioni che segnalano il messaggio di errore "Driver compute node failed to initialize for batch in 600 seconds". Questo errore indica che il driver Spark non è stato avviato entro il periodo di timeout assegnato, spesso a causa della mancanza di accesso necessario alle risorse Google Cloud .
Per risolvere il problema, verifica che il account di servizio disponga dei seguenti ruoli o autorizzazioni minimi:
- Ruolo Dataproc Worker (
roles/dataproc.worker): questo ruolo concede le autorizzazioni necessarie a Serverless per Apache Spark per gestire ed eseguire workload e sessioni Spark. - Storage Object Viewer (
roles/storage.objectViewer), Storage Object Creator (roles/storage.objectCreator) o Storage Object Admin (roles/storage.admin): se la tua applicazione Spark legge o scrive nei bucket Cloud Storage, il account di servizio deve disporre delle autorizzazioni appropriate per accedere ai bucket. Ad esempio, se i dati di input si trovano in un bucket Cloud Storage, è necessarioStorage Object Viewer. Se la tua applicazione scrive l'output in un bucket Cloud Storage, è necessarioStorage Object CreatoroStorage Object Admin. - Editor dati BigQuery (
roles/bigquery.dataEditor) o Visualizzatore dati BigQuery (roles/bigquery.dataViewer): se la tua applicazione Spark interagisce con BigQuery, verifica che l'account di servizio disponga dei ruoli BigQuery appropriati. - Autorizzazioni Cloud Logging:il account di servizio ha bisogno delle autorizzazioni
per scrivere i log in Cloud Logging per un debug efficace. In genere, il ruolo
Logging Writer(roles/logging.logWriter) è sufficiente.
Errori comuni relativi ad autorizzazioni o accesso
Ruolo
dataproc.workermancante: senza questo ruolo principale, l'infrastruttura Serverless per Apache Spark non può eseguire il provisioning e gestire correttamente il nodo driver.Autorizzazioni Cloud Storage insufficienti: se l'applicazione Spark tenta di leggere i dati di input o scrivere l'output in un bucket Cloud Storage senza le autorizzazioni del account di servizio necessarie, l'inizializzazione del driver potrebbe non riuscire perché non ha accesso alle risorse critiche.
Problemi di rete o firewall: i Controlli di servizio VPC o le regole firewall possono bloccare inavvertitamente l'accesso dell'account di servizio alle API o alle risorse. Google Cloud
Per verificare e aggiornare le autorizzazioni dell'account di servizio:
- Vai alla pagina IAM e amministrazione > IAM nella console Google Cloud .
- Individua il account di servizio utilizzato per i batch o le sessioni Serverless per Apache Spark.
- Verifica che siano assegnati i ruoli necessari. In caso contrario, aggiungili.
Per un elenco di ruoli e autorizzazioni di Serverless per Apache Spark, consulta Autorizzazioni e ruoli IAM di Serverless per Apache Spark.
Visualizzare e gestire i ruoli degli account di servizio IAM
Per visualizzare e gestire i ruoli concessi al account di servizio del servizio batch o della sessione di Serverless per Apache Spark, procedi nel seguente modo:
Nella console Google Cloud , vai alla pagina IAM.
Fai clic su Includi concessioni di ruoli fornite da Google.
Visualizza i ruoli elencati per il account di servizio del batch workload o della sessione. L'immagine seguente mostra il ruolo Dataproc Worker richiesto elencato per il account di servizio Compute Engine predefinito,
project_number-compute@developer.gserviceaccount.com, che Serverless per Apache Spark utilizza per impostazione predefinita come account di servizio del carico di lavoro o della sessione.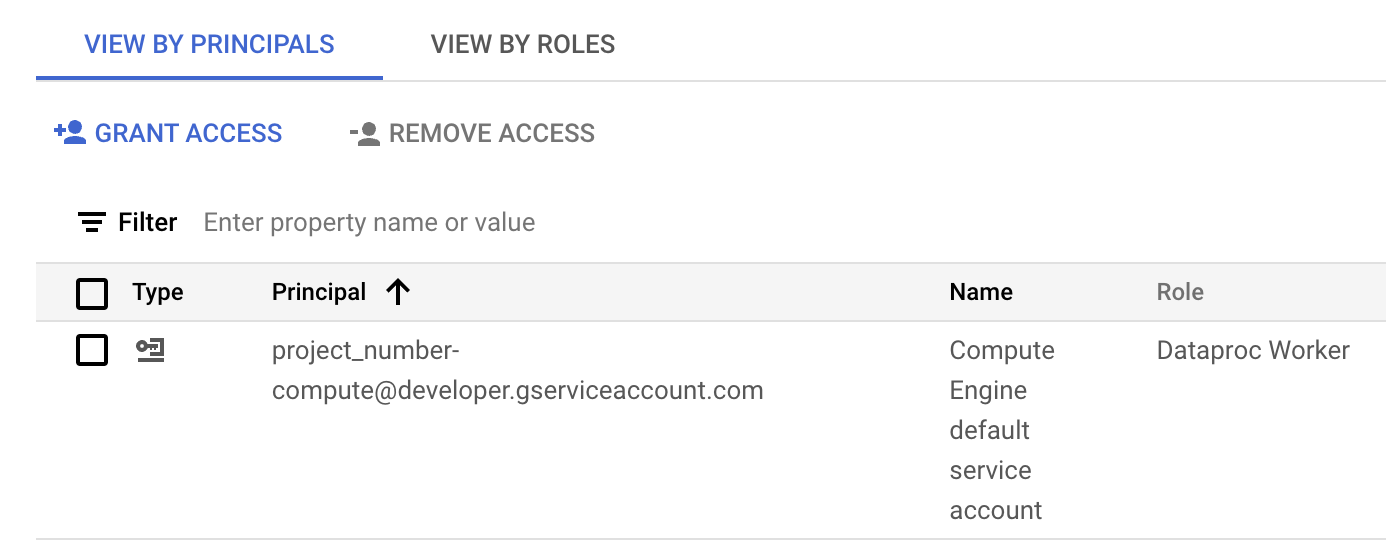
Il ruolo Worker Dataproc assegnato al account di servizio Compute Engine predefinito nella sezione IAM della console Google Cloud . Puoi fare clic sull'icona a forma di matita visualizzata nella riga dell'account di servizio per concedere o rimuovere i ruoli dell'account di servizio.
Account di servizio tra progetti
Puoi inviare un workload batch Serverless for Apache Spark che utilizza un account di servizio di un progetto diverso da quello del workload batch (il progetto in cui viene inviato il batch). In questa sezione, il progetto in cui si trova il account di servizio è chiamato service account project, mentre il progetto in cui viene inviato il batch è chiamato batch project.
Perché utilizzare un account di servizio tra progetti per eseguire un carico di lavoro batch? Un possibile motivo è se alaccount di serviziot nell'altro progetto sono stati assegnati ruoli IAM che forniscono un accesso granulare alle risorse in quel progetto.
Procedura di configurazione
Nel progetto del account di servizio:
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.Concedi al tuo account email (l'utente che sta creando il cluster) il ruolo Utente service account nel progetto del account di servizio o, per un controllo più granulare, nel account di servizio del progetto del account di servizio.
Per saperne di più, consulta Gestire l'accesso a progetti, cartelle e organizzazioni per concedere i ruoli a livello di progetto e Gestire l'accesso ai service account per concedere i ruoli a livello di account di servizio.
Esempi di gcloud CLI:
Il seguente comando di esempio concede all'utente il ruolo Utente service account a livello di progetto:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
Note:
USER_EMAIL: fornisci l'indirizzo email del tuo account utente, nel formato:user:user-name@example.com.
Il seguente comando di esempio concede all'utente il ruolo Utente service account a livello diaccount di serviziot:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=USER_EMAIL \ --role="roles/iam.serviceAccountUser"
Note:
USER_EMAIL: fornisci l'indirizzo email del tuo account utente nel formato:user:user-name@example.com.
Concedi al account di servizio il ruolo Dataproc Worker nel progetto batch.
Esempio di gcloud CLI:
gcloud projects add-iam-policy-binding BATCH_PROJECT_ID \ --member=serviceAccount:SERVICE_ACCOUNT_NAME@SERVICE_ACCOUNT_PROJECT_ID.iam.gserviceaccount.com \ --role="roles/dataproc.worker"
Nel progetto batch:
Concedi all'account di servizio dell'agente di servizio Dataproc i ruoli Utente service account e Creatore token service account nel progetto del service account o, per un controllo più granulare, nel service account del progetto del service account. In questo modo, consenti alaccount di serviziot dell'agente di servizio Dataproc nel progetto batch di creare token per iaccount di serviziont nel progetaccount di serviziount.
Per saperne di più, consulta Gestire l'accesso a progetti, cartelle e organizzazioni per concedere i ruoli a livello di progetto e Gestire l'accesso ai service account per concedere i ruoli a livello di account di servizio.
Esempi di gcloud CLI:
I seguenti comandi concedono all'account di servizio dell'agente di servizio Dataproc nel progetto batch i ruoli Utente service account e Creatore di token service account a livello di progetto:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
I seguenti comandi di esempio concedono all'account di servizio dell'agente di servizio Dataproc nel progetto batch i ruoli Utente service account e Creatore token service account a livello di service account:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountUser"
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@dataproc-accounts.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Concedi all'account di servizio agente di servizio Compute Engine nel progetto batch il ruolo Creatore token service account nel progetto service account o, per un controllo più granulare, nel service account nel progetto service account. In questo modo, concedi alaccount di serviziot dell'agente di servizio Compute nel progetto batch la possibilità di creare token per iaccount di serviziont nel progetto del service account.
Per saperne di più, consulta Gestire l'accesso a progetti, cartelle e organizzazioni per concedere i ruoli a livello di progetto e Gestire l'accesso ai service account per concedere i ruoli a livello di account di servizio.
Esempi di gcloud CLI:
Il seguente comando di esempio concede all'account di servizio dell'agente di servizio Compute Engine nel progetto batch il ruolo Creatore token service account a livello di progetto:
gcloud projects add-iam-policy-binding SERVICE_ACCOUNT_PROJECT_ID \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Il seguente comando di esempio concede all'account di servizio agente di servizio Compute Engine nel progetto cluster il ruolo Creatore token service account a livello di service account:
gcloud iam service-accounts add-iam-policy-binding VM_SERVICE_ACCOUNT_EMAIL \ --member=serviceAccount:service-BATCH_PROJECT_NUMBER@compute-system.iam.gserviceaccount.com \ --role="roles/iam.serviceAccountTokenCreator"
Invia il carico di lavoro batch
Dopo aver completato i passaggi di configurazione, puoi inviare un carico di lavoro batch. Assicurati di specificare il account di servizio nel progetto del account di servizio come account di serviziot da utilizzare per il batch.