Neste documento, você encontra informações sobre o ajuste automático de cargas de trabalho do Spark. Otimizar uma carga de trabalho do Spark para desempenho e capacidade de recuperação pode ser difícil devido ao número de opções de configuração do Spark e à dificuldade de avaliar como essas opções afetam uma carga de trabalho. O ajuste automático do Serverless para Apache Spark oferece uma alternativa à configuração manual da carga de trabalho. Ele aplica automaticamente as configurações de configuração do Spark a uma carga de trabalho recorrente com base nas práticas recomendadas de otimização do Spark e em uma análise das execuções da carga de trabalho. Google Cloud
Inscrever-se no Google Cloud ajuste automático do Serverless para Apache Spark
Para se inscrever e ter acesso à versão de prévia do ajuste automático do Serverless para Apache Spark descrita nesta página, preencha e envie o formulário de inscrição Solicitação de acesso à prévia do Dataproc. Depois que o formulário é aprovado, os projetos listados nele têm acesso aos recursos de pré-lançamento.
Vantagens
O ajuste automático doGoogle Cloud Serverless para Apache Spark oferece os seguintes benefícios:
- Melhoria na performance: ajuste da otimização para aumentar a performance
- Otimização mais rápida: configuração automática para evitar testes manuais demorados.
- Maior capacidade de recuperação: alocação automática de memória para evitar falhas relacionadas à memória.
Limitações
Google Cloud O ajuste automático do Serverless para Apache Spark tem as seguintes limitações:
- A otimização automática é calculada e aplicada à segunda e às execuções subsequentes de uma carga de trabalho. A primeira execução de uma carga de trabalho recorrente não é ajustada automaticamente porque o ajuste automático do Google Cloud Serverless para Apache Spark usa o histórico da carga de trabalho para otimização.
- Não é possível reduzir a memória.
- O ajuste automático não é aplicado retroativamente a cargas de trabalho em execução, apenas a coortes de carga de trabalho enviadas recentemente.
Coortes de ajuste automático
O ajuste automático é aplicado a execuções recorrentes de uma carga de trabalho em lote, chamadas de coortes.
O nome da coorte especificado ao enviar uma carga de trabalho
a identifica como uma das execuções sucessivas da carga de trabalho recorrente.
Recomendamos que você use nomes de coorte que descrevam o tipo de
carga de trabalho ou que ajudem a identificar as execuções de uma carga de trabalho como parte
de uma carga de trabalho recorrente. Por exemplo, especifique daily_sales_aggregation como o nome da coorte para uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.
Cenários de ajuste automático
Para aplicar o ajuste automático do Google Cloud Serverless para Apache Spark à sua carga de trabalho, selecione um ou mais dos seguintes cenários de ajuste automático:
MEMORY: ajusta automaticamente a alocação de memória do Spark para prever e evitar possíveis erros de falta de memória da carga de trabalho. Corrigir uma carga de trabalho que falhou anteriormente devido a um erro de falta de memória (OOM).SCALING: ajuste automático das configurações de escalonamento automático do Spark.BROADCAST_HASH_JOIN: ajuste automático das configurações de configuração do Spark para otimizar o desempenho da junção de transmissão SQL.
Preços
Google Cloud O ajuste automático do Serverless para Apache Spark é oferecido durante o pré-lançamento sem custo financeiro adicional. Os Google Cloud preços padrão do Serverless para Apache Spark são aplicáveis.
Disponibilidade regional
É possível usar o ajuste automático do Google Cloud Serverless para Apache Spark com lotes enviados nas regiões disponíveis do Compute Engine.
Usar o ajuste automático do Google Cloud Serverless para Apache Spark
É possível ativar o ajuste automático do Google Cloud Serverless para Apache Spark em uma carga de trabalho usando o console Google Cloud , a Google Cloud CLI ou a API Dataproc.
Console
Para ativar o ajuste automático do Google Cloud Serverless para Apache Spark em cada envio de uma carga de trabalho em lote recorrente, siga estas etapas:
No console Google Cloud , acesse a página Lotes do Dataproc.
Para criar uma carga de trabalho em lote, clique em Criar.
Na seção Contêiner, preencha os seguintes campos para sua carga de trabalho do Spark:
Coorte:o nome da coorte, que identifica o lote como uma de uma série de cargas de trabalho recorrentes. Ajuste automático é aplicado à segunda e às próximas cargas de trabalho enviadas com esse nome de coorte. Por exemplo, especifique
daily_sales_aggregationcomo o nome da coorte para uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.Cenários de ajuste automático:um ou mais cenários de ajuste automático para otimizar a carga de trabalho, por exemplo,
BROADCAST_HASH_JOIN,MEMORYeSCALING. É possível mudar a seleção de cenário a cada envio de coorte por lote.
Preencha outras seções da página Criar lote conforme necessário e clique em Enviar. Para mais informações sobre esses campos, consulte Enviar uma carga de trabalho em lote.
gcloud
Para ativar o ajuste automático do Google Cloud Serverless para Apache Spark em cada envio
de uma carga de trabalho em lote recorrente, execute o seguinte comando da CLI gcloud
gcloud dataproc batches submit
localmente em uma janela de terminal ou no
Cloud Shell.
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=SCENARIOS \ other arguments ...
Substitua:
- COMMAND: o tipo de carga de trabalho do Spark, como
Spark,PySpark,Spark-SqlouSpark-R. - REGION: a região em que sua carga de trabalho será executada.
COHORT: o nome da coorte, que identifica o lote como uma de uma série de cargas de trabalho recorrentes. Ajuste automático é aplicado à segunda e às próximas cargas de trabalho enviadas com esse nome de coorte. Por exemplo, especifique
daily_sales_aggregationcomo o nome da coorte para uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.SCENARIOS: um ou mais cenários de ajuste automático separados por vírgulas para usar na otimização da carga de trabalho. Por exemplo,
--autotuning-scenarios=MEMORY,SCALING. É possível mudar a lista de cenários a cada envio de coorte por lote.
API
Para ativar o ajuste automático do Google Cloud Serverless para Apache Spark em cada envio de uma carga de trabalho em lote recorrente, envie uma solicitação batches.create que inclua os seguintes campos:
RuntimeConfig.cohort: o nome da coorte, que identifica o lote como uma de uma série de cargas de trabalho recorrentes. O ajuste automático é aplicado à segunda e às próximas cargas de trabalho enviadas com esse nome de coorte. Por exemplo, especifiquedaily_sales_aggregationcomo o nome da coorte para uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.AutotuningConfig.scenarios: um ou mais cenários de ajuste automático para otimizar a carga de trabalho, por exemplo,BROADCAST_HASH_JOIN,MEMORYeSCALING. É possível mudar a lista de cenários a cada envio de coorte por lote.
Exemplo:
...
runtimeConfig:
cohort: daily_sales_aggregation
autotuningConfig:
scenarios:
- BROADCAST_HASH_JOIN
- MEMORY
- SCALING
...
Java
Antes de testar esta amostra, siga as instruções de configuração do Java no Guia de início rápido do Serverless para Apache Spark: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API sem servidor para Apache Spark Java.
Para autenticar no Serverless para Apache Spark, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Para ativar o ajuste automático do Google Cloud Serverless para Apache Spark em cada envio de uma carga de trabalho em lote recorrente, chame BatchControllerClient.createBatch com um CreateBatchRequest que inclua os seguintes campos:
Batch.RuntimeConfig.cohort: o nome da coorte, que identifica o lote como uma série de cargas de trabalho recorrentes. O ajuste automático é aplicado à segunda e às próximas cargas de trabalho enviadas com esse nome de coorte. Por exemplo, você pode especificardaily_sales_aggregationcomo o nome da coorte para uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.Batch.RuntimeConfig.AutotuningConfig.scenarios: um ou mais cenários de ajuste automático a serem usados para otimizar a carga de trabalho, comoBROADCAST_HASH_JOIN,MEMORYeSCALING. É possível mudar a lista de cenários a cada envio de coorte por lote. Para a lista completa de cenários, consulte o Javadoc de AutotuningConfig.Scenario.
Exemplo:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.SCALING))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
Para usar a API, é necessário usar a biblioteca de cliente google-cloud-dataproc versão 4.43.0
ou mais recente. Use uma das seguintes configurações para adicionar a biblioteca ao seu
projeto.
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
Antes de testar esta amostra, siga as instruções de configuração do Python no Guia de início rápido do Serverless para Apache Spark: como usar bibliotecas de cliente. Para mais informações, consulte a documentação de referência da API sem servidor para Apache Spark Python.
Para autenticar no Serverless para Apache Spark, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Para ativar o ajuste automático do Google Cloud Serverless para Apache Spark em cada envio de uma carga de trabalho em lote recorrente, chame BatchControllerClient.create_batch com um Batch que inclua os seguintes campos:
batch.runtime_config.cohort: o nome da coorte, que identifica o lote como uma série de cargas de trabalho recorrentes. O ajuste automático é aplicado à segunda e às próximas cargas de trabalho enviadas com esse nome de coorte. Por exemplo, você pode especificardaily_sales_aggregationcomo o nome da coorte para uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.batch.runtime_config.autotuning_config.scenarios: um ou mais cenários de ajuste automático a serem usados para otimizar a carga de trabalho, comoBROADCAST_HASH_JOIN,MEMORY,SCALING. É possível mudar a lista de cenários a cada envio de coorte em lote. Para conferir a lista completa de cenários, consulte a referência de Cenário.
Exemplo:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.SCALING
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
Para usar a API, é necessário usar a biblioteca de cliente google-cloud-dataproc versão 5.10.1
ou mais recente. Para adicionar ao seu projeto, use o seguinte requisito:
google-cloud-dataproc>=5.10.1
Airflow
Para ativar o ajuste automático do Google Cloud Serverless para Apache Spark em cada envio de uma carga de trabalho em lote recorrente, chame BatchControllerClient.create_batch com um Batch que inclua os seguintes campos:
batch.runtime_config.cohort: o nome da coorte, que identifica o lote como uma série de cargas de trabalho recorrentes. O ajuste automático é aplicado à segunda e às próximas cargas de trabalho enviadas com esse nome de coorte. Por exemplo, você pode especificardaily_sales_aggregationcomo o nome da coorte para uma carga de trabalho programada que executa uma tarefa diária de agregação de vendas.batch.runtime_config.autotuning_config.scenarios: um ou mais cenários de ajuste automático a serem usados para otimizar a carga de trabalho, por exemplo,BROADCAST_HASH_JOIN,MEMORY,SCALING. É possível mudar a lista de cenários a cada envio de coorte em lote. Para conferir a lista completa de cenários, consulte a referência de Cenário.
Exemplo:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.SCALING,
]
}
},
},
batch_id="BATCH_ID",
)
Para usar a API, é necessário usar a biblioteca de cliente google-cloud-dataproc versão 5.10.1
ou mais recente. É possível usar o seguinte requisito de ambiente do Airflow:
google-cloud-dataproc>=5.10.1
Para atualizar o pacote no Cloud Composer, consulte Instalar dependências do Python para o Cloud Composer .
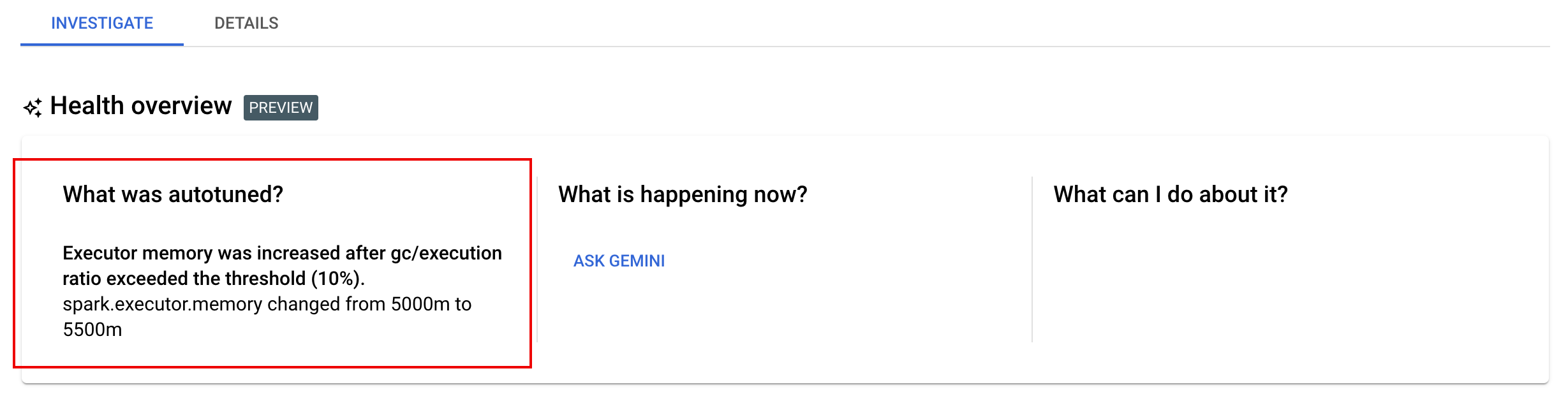
Conferir mudanças de sintonia automática
Para conferir as mudanças de ajuste automático do Google Cloud Serverless para Apache Spark em uma carga de trabalho em lote,
execute o comando
gcloud dataproc batches describe.
Exemplo: a saída de gcloud dataproc batches describe é semelhante a esta:
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties
spark.driver.memory:
annotation: Driver OOM was detected
value: 11520m
spark.driver.memoryOverhead:
annotation: Driver OOM was detected
value: 4608m
# Old overwritten properties.
userProperties
...
É possível conferir as mudanças mais recentes de ajuste automático aplicadas a uma carga de trabalho em execução, concluída ou com falha na página Detalhes do lote no console do Google Cloud , na guia Investigar.