Managed migration is an automated feature that helps you migrate data from a self-managed Hive Metastore to a Dataproc Metastore service, without any sizable down time (otherwise known as a flag day).
Managed Migration Architecture
The following diagram provides the high-level architecture of a managed migration.
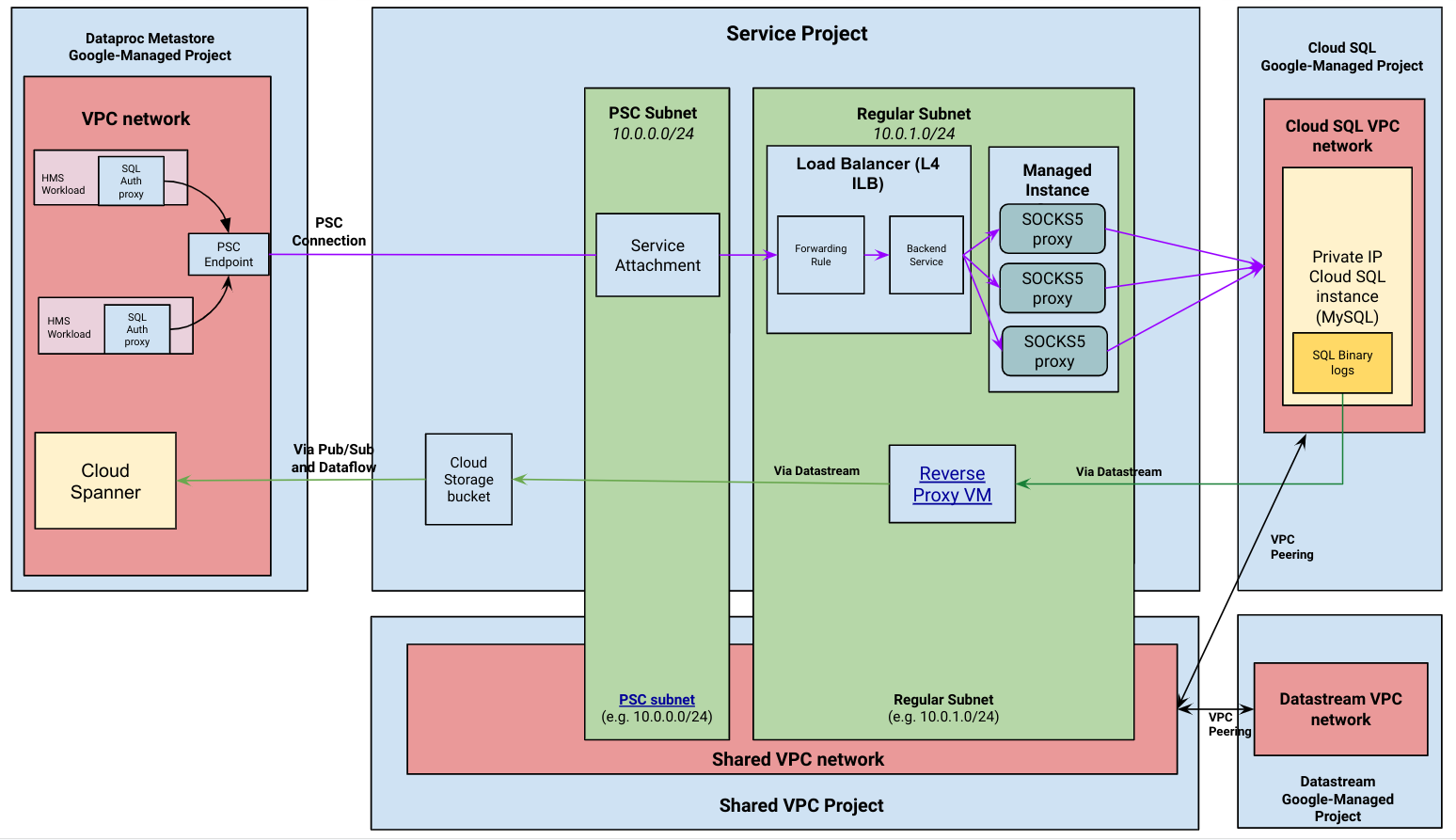
Managed migration flow
To complete a managed migration, your service runs through two migration processes—start migration and complete migration. You can cancel a migration at any time with the cancel migration process. There are also a number of operational commands you can run, which aren't required to complete a migration. For example, list migrations or delete migrations.
As your service moves through this process, it also moves between various
migration states and migration phases. These states and phases represent the
processes that are occurring in the background. For example, the MIGRATING
state indicates that your service is actively transferring data from your
Cloud SQL database to Dataproc Metastore.
Start Migration
Dataproc Metastore establishes a connection with your private IP Cloud SQL instance. After the connection is made, Dataproc Metastore uses the Cloud SQL instance as it's Hive Metastore (HMS) backend database. It also remains as the source of truth for your data during the migration. Metadata reads and writes still occur in Cloud SQL when the migration is active.
A change data capture (CDC) pipeline is started. This pipeline keeps the Cloud SQL instance in your project and Spanner in the Dataproc Metastore managed project in sync. This means that all changes to the HMS database in the Cloud SQL instance are captured through Datastream and written to the Dataproc Metastore Spanner database.
Once the start migration process is successful, you can start routing data workloads to Dataproc Metastore. At this point, Cloud SQL is still the source of truth for your data.
Complete migration
After you finish moving your workloads to Dataproc Metastore, you can complete the migration. When a complete migration process is called, the following occurs:
- Dataproc Metastore transitions into a read-only mode until the complete migration process finishes.
- The CDC stream transfers all in-flight data to Dataproc Metastore.
- Dataproc Metastore connects to Spanner and disconnects from Cloud SQL. Dataproc Metastore now acts as the source of truth for your HMS data.
Proxy and pipeline considerations
Proxies
Dataproc Metastore uses a Cloud SQL Auth proxy chained to a SOCKS5 proxy to connect to your private IP Cloud SQL instance. The SOCKS5 proxy servers are exposed through a service attachment as shown in previous architecture diagram.
Each migration requires a dedicated NAT subnet. This is because a NAT subnet can't have more than one service attachment.
To avoid cross-region latency issues, provide subnets that are in the same region as your Cloud SQL instance to host the SOCKS5 proxy. For example,
proxy_subnetandnat_subnet.
Change data capture pipeline
The change data capture pipeline uses VPC peering to establish a connection between Datastream and private IP Cloud SQL
For each migration, a new private connection is created and a new peering connection is established.
The VPC network hosting the Cloud SQL instance has as many peering connections as there are active migrations. Make sure that your VPC network has the capacity to host all of the necessary peering connections.