O metastore do Dataproc é um metastore Apache Hive (HMS) totalmente gerenciado, altamente disponível, com recuperação automática e sem servidor que é executado no Google Cloud.
Para gerenciar totalmente seus metadados, o metastore do Dataproc mapeia seus dados para tabelas do Apache Hive.
Versões compatíveis do Apache Hive
O metastore do Dataproc só é compatível com versões específicas do Apache Hive. Para mais informações, consulte a política de versões do Hive.
Como o Hive processa metadados
Como o metastore do Dataproc é um metastore Hive, é importante entender como ele gerencia seus metadados.
Por padrão, todos os aplicativos Hive podem ter tabelas internas gerenciadas ou tabelas externas não gerenciadas. Ou seja, os metadados armazenados em um serviço do Metastore do Dataproc podem existir em tabelas internas e externas.
Ao modificar dados, um serviço do metastore do Dataproc (Hive) trata tabelas internas e externas de maneira diferente.
- Tabelas internas. Gerencia metadados e dados de tabela.
- Tabelas externas. Gerencia apenas metadados.
Por exemplo, se você excluir uma definição de tabela usando a instrução DROP TABLE do Hive SQL:
drop table foo
Tabelas internas. O metastore do Dataproc exclui todos os metadados. Ele também exclui os arquivos associados à tabela.
Tabelas externas. O Dataproc Metastore exclui apenas os metadados. Ele mantém os dados associados à tabela.
Diretório de depósito do Hive
O metastore do Dataproc usa o diretório de armazenamento do Hive para gerenciar suas tabelas internas. O diretório do data warehouse do Hive é onde os dados reais são armazenados.
Quando você usa um serviço do metastore do Dataproc, o diretório padrão do Hive Warehouse é um bucket do Cloud Storage. O metastore do Dataproc só aceita o uso de buckets do Cloud Storage para o diretório do data warehouse. Em comparação, isso é diferente de um HMS local, em que o diretório do warehouse do Hive geralmente aponta para um diretório local.
Ele é criado automaticamente para você sempre que um serviço do metastore do Dataproc é criado. Esse valor pode ser mudado definindo uma substituição de configuração do metastore do Hive na propriedade hive.metastore.warehouse.dir.
Buckets do Cloud Storage de artefatos
O bucket de artefatos armazena os artefatos do metastore do Dataproc, como metadados exportados e dados gerenciados de tabelas internas.
Quando você cria um serviço Metastore do Dataproc, um bucket do Cloud Storage é criado automaticamente no projeto para você. Por padrão, o bucket de artefatos e o diretório do data warehouse apontam para o mesmo bucket. Não é possível mudar o local do bucket de artefatos, mas é possível mudar o local do diretório do data warehouse do Hive.
O bucket de artefatos fica no seguinte local:
gs://your-artifacts-bucket/hive-warehouse.- Por exemplo,
gs://gcs-your-project-name-0825d7b3-0627-4637-8fd0-cc6271d00eb4
Acessar o diretório de depósito do Hive
Depois que o bucket for criado automaticamente, verifique se as contas de serviço do Dataproc têm permissão para acessar o diretório de armazenamento do Hive.
Para acessar o diretório do armazenamento no nível do objeto (por exemplo, gs://mybucket/object), conceda às contas de serviço do Dataproc acesso de leitura e gravação ao objeto de armazenamento do bucket usando o papel
roles/storage.objectAdmin. Esse papel precisa ser definido no nível do bucket ou superior.Para acessar o diretório do data warehouse ao usar uma pasta de nível superior (por exemplo, gs://mybucket), conceda às contas de serviço do Dataproc acesso de leitura e gravação ao objeto de armazenamento do bucket usando a função
roles/storage.storageAdmin.
Se o diretório de armazenamento do Hive não estiver no mesmo projeto que o metastore do Dataproc, verifique se o agente de serviço do metastore do Dataproc tem permissão para acessar o diretório de armazenamento do Hive. O agente de serviço de um projeto do metastore do Dataproc é service-PROJECT_NUMBER@gcp-sa-metastore.iam.gserviceaccount.com.
Conceda ao agente de serviço acesso de leitura e gravação ao bucket usando o papel
roles/storage.objectAdmin.
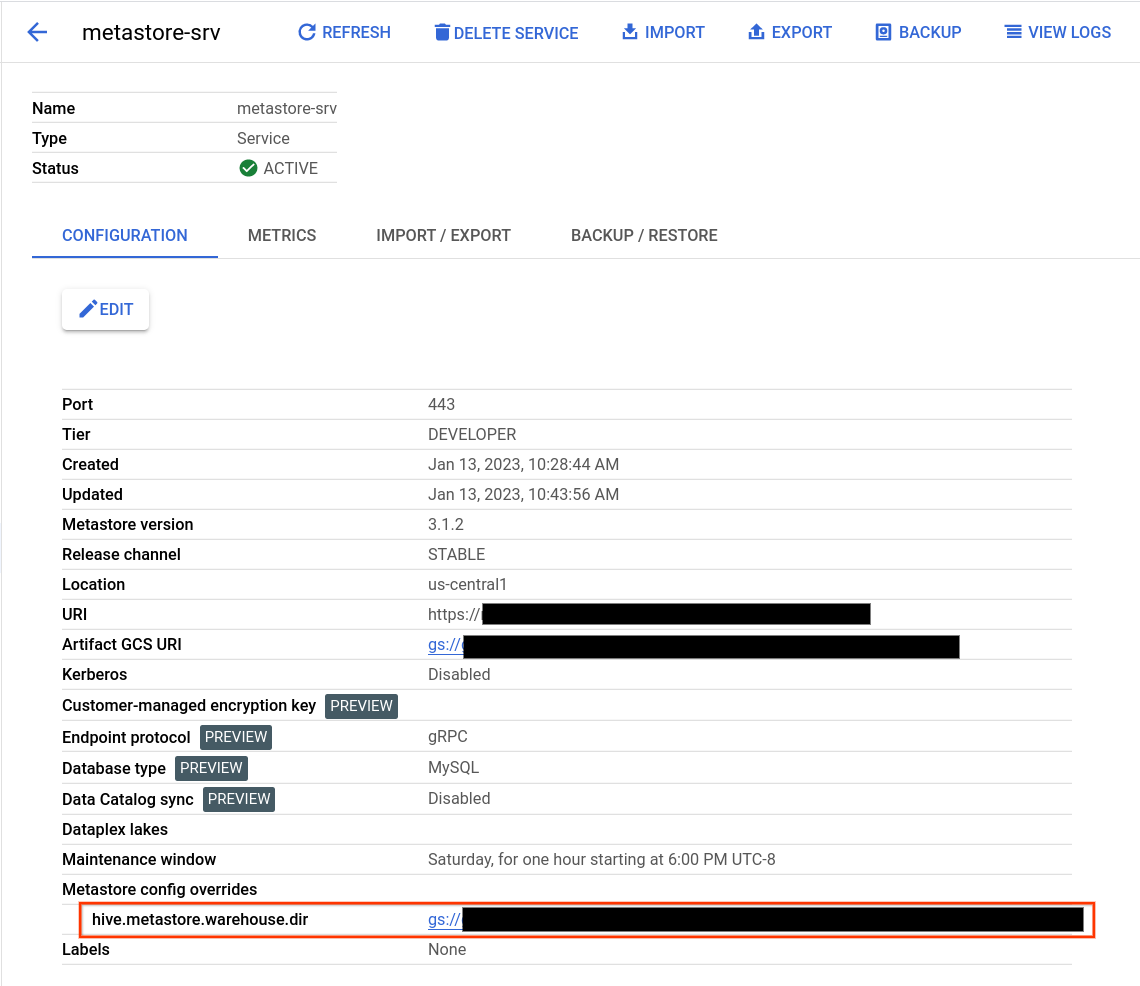
Encontrar o diretório de armazenamento do Hive
- Abra a página Metastore do Dataproc.
Clique no nome do serviço.
A página "Detalhes do serviço" é aberta.
Na tabela de configuração, encontre Substituições de configuração do metastore > hive.metastore.warehouse.dir.
Encontre o valor que começa com
gs://.Esse valor é o local do diretório de depósito do Hive.
Mudar o diretório de depósito do Hive
Para usar seu próprio bucket do Cloud Storage com o metastore do Dataproc, defina uma substituição de configuração do metastore Hive para apontar para o novo local do bucket.
Se você mudar o diretório padrão do armazém, siga estas recomendações.
Não use a raiz do bucket do Cloud Storage (
gs://mybucket) para armazenar tabelas do Hive.Verifique se a conta de serviço da VM do Metastore do Dataproc tem permissão para acessar o diretório de armazenamento do Hive.
Para melhores resultados, use os buckets do Cloud Storage localizados na mesma região do serviço Metastore do Dataproc. Embora o metastore do Dataproc permita buckets entre regiões, os recursos colocalizados têm melhor desempenho. Por exemplo, um bucket multirregional da UE não funciona bem com um serviço
us-central1. O acesso entre regiões resulta em maior latência, falta de isolamento da falha regional e cobranças pela largura de banda da rede entre regiões.
Para mudar o diretório de armazenamento do Hive
- Abra a página Metastore do Dataproc.
Clique no nome do serviço.
A página "Detalhes do serviço" é aberta.
Na tabela de configuração, encontre a seção Modificações de configuração do metastore > hive.metastore.warehouse.dir.
Mude o valor de
hive.metastore.warehouse.dirpara o local do novo bucket. Por exemplo,gs://my-bucket/path/to/location.
Excluir o bucket
A exclusão do serviço Metastore do Dataproc não exclui automaticamente o bucket de artefatos do Cloud Storage. Ele não é excluído automaticamente porque pode conter dados úteis pós-serviço. Para excluir o bucket, execute uma operação de exclusão do Cloud Storage.