Dataproc Metastore è un metastore Apache Hive (HMS) completamente gestito, ad alta disponibilità, con funzionalità di autoriparazione, serverless e in esecuzione su Google Cloud.
Per gestire completamente i metadati, Dataproc Metastore mappa i tuoi dati alle tabelle Apache Hive.
Versioni di Apache Hive supportate
Dataproc Metastore supporta solo versioni specifiche di Apache Hive. Per saperne di più, consulta le norme relative alle versioni di Hive.
Come Hive gestisce i metadati
Poiché Dataproc Metastore è un metastore Hive, è importante capire come gestisce i metadati.
Per impostazione predefinita, tutte le applicazioni Hive possono avere tabelle interne gestite o tabelle esterne non gestite. Ciò significa che i metadati archiviati in un servizio Dataproc Metastore possono esistere sia in tabelle interne che esterne.
Quando modifichi i dati, un servizio Dataproc Metastore (Hive) tratta le tabelle interne ed esterne in modo diverso.
- Tabelle interne. Gestisce sia i metadati che i dati delle tabelle.
- Tabelle esterne. Gestisce solo i metadati.
Ad esempio, se elimini una definizione di tabella utilizzando l'istruzione SQL DROP TABLE Hive:
drop table foo
Tabelle interne. Dataproc Metastore elimina tutti i metadati. Vengono eliminati anche i file associati alla tabella.
Tabelle esterne. Dataproc Metastore elimina solo i metadati. Conserva i dati associati alla tabella.
Directory del magazzino Hive
Dataproc Metastore utilizza la directory del warehouse Hive per gestire le tabelle interne. La directory del warehouse Hive è la posizione in cui sono archiviati i dati effettivi.
Quando utilizzi un servizio Dataproc Metastore, la directory del warehouse Hive predefinita è un bucket Cloud Storage. Dataproc Metastore supporta solo l'utilizzo di bucket Cloud Storage per la directory del data warehouse. Al contrario, questo è diverso da un HMS on-premise, in cui la directory del warehouse Hive di solito punta a una directory locale.
Questo bucket viene creato automaticamente ogni volta che crei un servizio Dataproc Metastore. Questo valore può essere modificato impostando
un override della configurazione di Hive Metastore nella proprietà
hive.metastore.warehouse.dir.
Bucket Cloud Storage degli artefatti
Il bucket degli artefatti archivia gli artefatti Dataproc Metastore, come i metadati esportati e i dati delle tabelle interne gestite.
Quando crei un servizio Dataproc Metastore, viene creato automaticamente un bucket Cloud Storage nel tuo progetto. Per impostazione predefinita, sia il bucket degli artefatti sia la directory del warehouse puntano allo stesso bucket. Non puoi modificare la posizione del bucket degli artefatti, ma puoi modificare la posizione della directory del warehouse Hive.
Il bucket degli artefatti si trova nel seguente percorso:
gs://your-artifacts-bucket/hive-warehouse.- Ad esempio,
gs://gcs-your-project-name-0825d7b3-0627-4637-8fd0-cc6271d00eb4.
Accedere alla directory del warehouse Hive
Dopo la creazione automatica del bucket, assicurati che i tuoi account di servizio Dataproc dispongano dell'autorizzazione per accedere alla directory del warehouse Hive.
Per accedere alla directory del warehouse a livello di oggetto (ad esempio gs://mybucket/object), concedi ai service account Dataproc l'accesso in lettura e scrittura all'oggetto di archiviazione del bucket utilizzando il ruolo
roles/storage.objectAdmin. Questo ruolo deve essere impostato a livello di bucket o superiore.Per accedere alla directory del warehouse quando utilizzi una cartella di primo livello (ad esempio gs://mybucket), concedi ai service account Dataproc l'accesso in lettura e scrittura all'oggetto di archiviazione del bucket utilizzando il ruolo
roles/storage.storageAdmin.
Se la directory del warehouse Hive non si trova nello stesso progetto di Dataproc Metastore, assicurati che l'agente di servizio Dataproc Metastore disponga dell'autorizzazione per accedere alla directory del warehouse Hive. L'agente di servizio per un progetto Dataproc Metastore è service-PROJECT_NUMBER@gcp-sa-metastore.iam.gserviceaccount.com.
Concedi all'agente di servizio l'accesso in lettura e scrittura al bucket utilizzando il ruolo
roles/storage.objectAdmin.
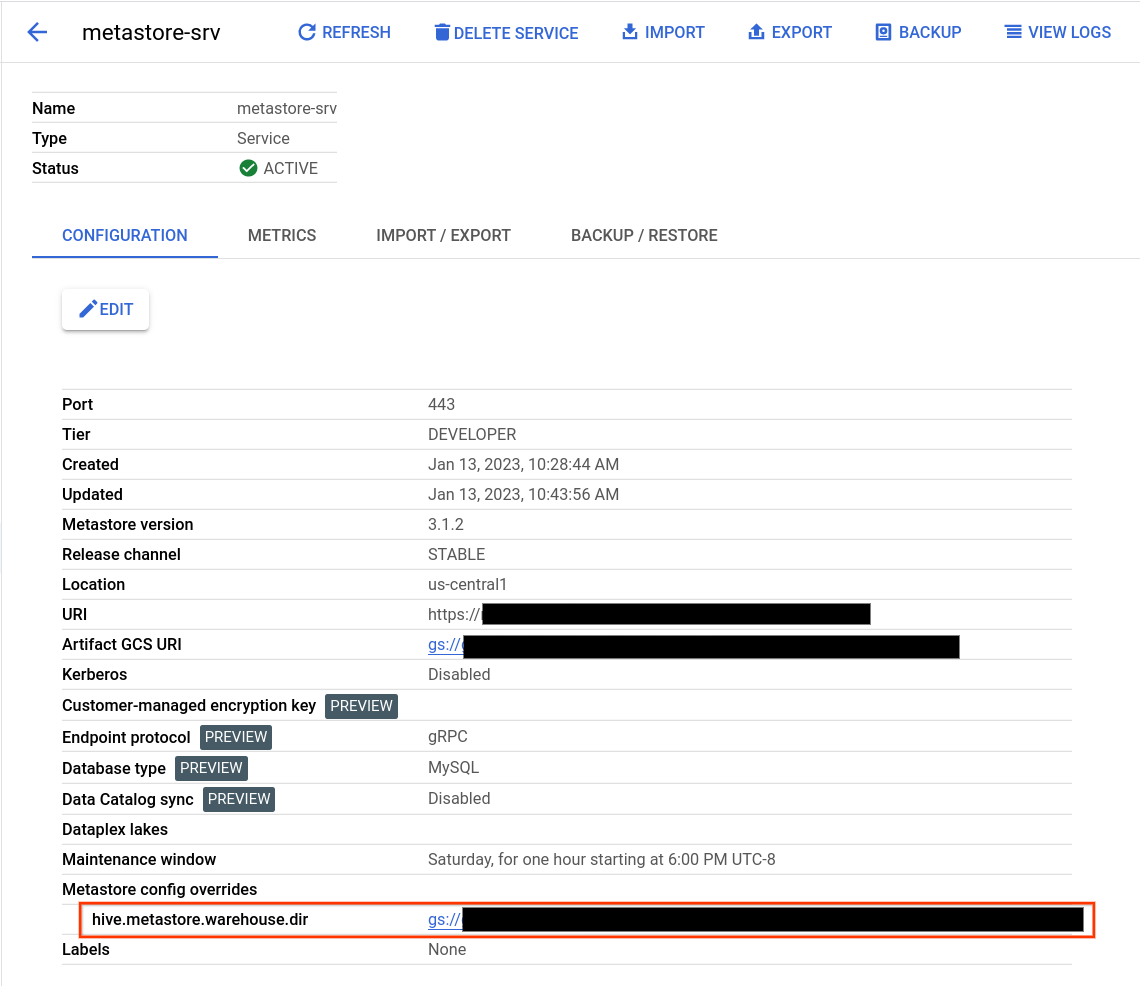
Trovare la directory del warehouse Hive
- Apri la pagina Dataproc Metastore.
Fai clic sul nome del servizio.
Viene visualizzata la pagina dei dettagli del servizio.
Nella tabella di configurazione, trova Override di configurazione metastore > hive.metastore.warehouse.dir.
Trova il valore che inizia con
gs://.Questo valore indica la posizione della directory del warehouse Hive.
Modificare la directory del warehouse Hive
Per utilizzare il tuo bucket Cloud Storage con Dataproc Metastore, imposta un override della configurazione di Hive Metastore in modo che punti alla nuova posizione del bucket.
Se modifichi la directory del magazzino predefinita, segui questi consigli.
Non utilizzare la radice del bucket Cloud Storage (
gs://mybucket) per archiviare le tabelle Hive.Assicurati che il account di servizio VM di Dataproc Metastore disponga dell'autorizzazione per accedere alla directory del warehouse Hive.
Per ottenere risultati ottimali, utilizza i bucket Cloud Storage che si trovano nella stessa regione del servizio Dataproc Metastore. Sebbene Dataproc Metastore consenta i bucket tra regioni, le risorse collocate hanno un rendimento migliore. Ad esempio, un bucket multiregionale UE non funziona bene con un servizio
us-central1. L'accesso tra regioni comporta una latenza maggiore, l'assenza di isolamento degli errori a livello regionale e addebiti per la larghezza di banda di rete tra regioni.
Per modificare la directory del warehouse Hive
- Apri la pagina Dataproc Metastore.
Fai clic sul nome del servizio.
Viene visualizzata la pagina dei dettagli del servizio.
Nella tabella di configurazione, individua la sezione Override di configurazione metastore > hive.metastore.warehouse.dir.
Modifica il valore
hive.metastore.warehouse.dircon la posizione del nuovo bucket. Ad esempio,gs://my-bucket/path/to/location.
Eliminare il bucket
L'eliminazione del servizio Dataproc Metastore non comporta l'eliminazione automatica del bucket degli artefatti di Cloud Storage. Il bucket non viene eliminato automaticamente perché potrebbe contenere dati utili post-servizio. Per eliminare il bucket, esegui un'operazione di eliminazione di Cloud Storage.