Dataplex は、分散データを統合し、そのデータのデータ マネジメントとガバナンスを自動化するデータ ファブリックです。
Dataplex によって、次のことができます。
- 複数の Google Cloud プロジェクトに保存されているデータにわたって、データを移動せずにドメイン固有のデータメッシュを構築します。
- 単一の権限セットで一貫してデータを管理、モニタリングできます。
- カタログ機能を使用して、さまざまなサイロにわたってメタデータを検出し、キュレートします。詳細については、Dataplex Catalog の概要をご覧ください。
- Spark SQL、Presto、HiveQL などのオープンソース ツールと BigQuery を使用して、メタデータを安全にクエリできます。
- サーバーレス Spark タスクを含む、データ品質とデータ ライフサイクルの管理タスクを実行します。
- (非推奨)ノートブックと Spark SQL クエリにアクセスして、フルマネージドのサーバーレス Spark 環境でデータを探索できます。
Dataplex を使用する理由
企業には、データレイク、データ ウェアハウス、データマートにわたって分散されたデータがあります。Dataplex を使用すると、次のことができます。
- データを検出します
- データをキュレートする
- データを移動せずに統合する
- ビジネスニーズに基づいてデータを整理する
- データを一元的に管理、モニタリング、統制する
Dataplex は、この分散データにわたり、メタデータ、セキュリティ ポリシー、ガバナンス、分類、データ ライフサイクルの管理を標準化し、統合するのに役立ちます。
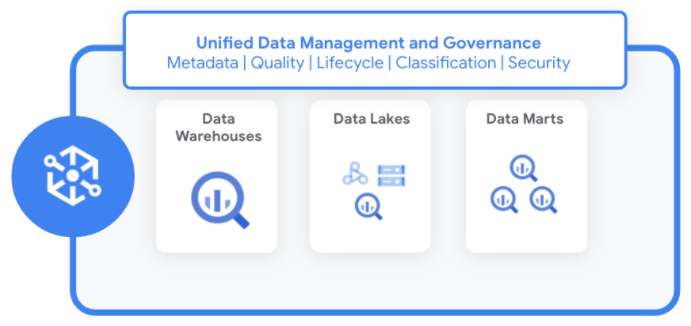
Dataplex の仕組み
Dataplex は、データの移動または重複を必要としない方法でデータを管理します。新しいデータソースが特定されると、Dataplex は組み込みのデータ品質チェックを使用して、構造化と非構造化の両方のデータのメタデータを収集し、整合性を高めます。
Dataplex は、統合されたメタストアにすべてのメタデータを自動的に登録します。次のようなさまざまなサービスやツールを使用して、データとメタデータにアクセスできます。
- BigQuery、Dataproc Metastore、Data Catalog などの Google Cloud サービス。
- Apache Spark や Presto などのオープンソース ツール。
用語
Dataplex では、次の構造を使用して、基盤となるデータ ストレージ システムを抽象化します。
レイク: データドメインまたはビジネス ユニットを表す論理的な構造。たとえば、グループの使用状況に基づいてデータを整理するために、部門(たとえば、小売、販売、財務)ごとにレイクを設定できます。
ゾーン: レイク内のサブドメイン。以下によってデータを分類するのに役立ちます。
- ステージ: たとえば、ランディング、未加工、キュレート済みデータの分析、キュレート済みデータ サイエンスなど
- 使用状況: データ契約など
- 制限事項: セキュリティ管理やユーザー アクセスレベルなど
ゾーンには次の 2 種類があります。
未加工ゾーン: 未加工フォーマットで、厳密な型チェックの対象ではないデータが含まれます。
キュレート済ゾーン: クリーニングされ、フォーマットされ、分析される準備ができているデータが含まれます。データは列指向の Hive パーティション分割であり、Parquet、Avro、Orc ファイル、または BigQuery のテーブルに保存されます。データには型チェックが行われます。たとえば、CSV ファイルは SQL アクセスのパフォーマンスがよくないため、使用を禁止します。
アセット: Cloud Storage または BigQuery に保存されているデータにマッピングします。別々の Google Cloud プロジェクトに保存されているデータをアセットとして単一のゾーンにマッピングできます。
エンティティ: 構造化データと半構造化データ(テーブルなど)と非構造化データ(ファイルセットなど)のメタデータを表します。
一般的なユースケース
このセクションでは、Dataplex を使用する場合の一般的なユースケースについて説明します。
ドメイン中心のデータメッシュ
この種類のデータメッシュでは、データが企業内の複数のドメイン(Sales、Customers、Products など)に整理されます。データの所有権を分散できます。異なるドメインのデータを登録できます。たとえば、データ サイエンティストとデータ アナリストは、異なるドメインから pull して、機械学習とビジネス インテリジェンスなどのビジネスの目標を達成できます。
次の図では、ドメインは Dataplex レイクで表され、個別のデータ プロデューサーが所有しています。データ プロデューサーは、ドメインでの作成、キュレーション、アクセス制御を所有します。その後、データ コンシューマは、分析のためにレイク(ドメイン)またはゾーン(サブドメイン)へのアクセスをリクエストできます。
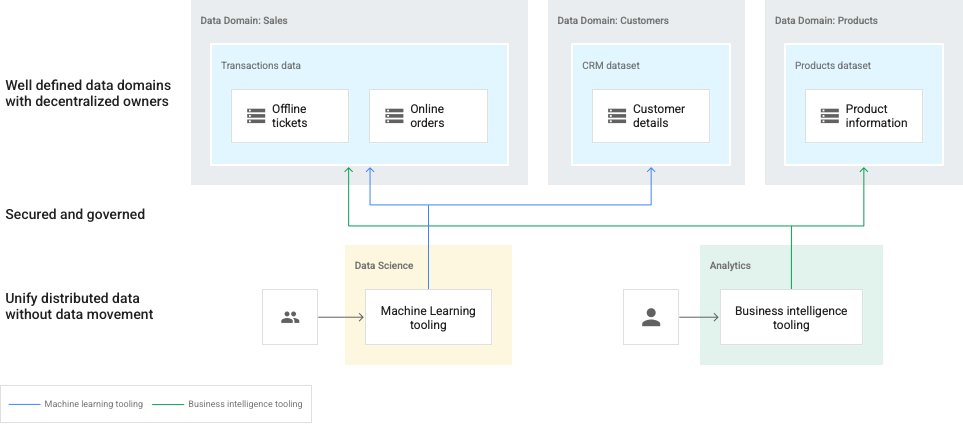
この場合、データ スチュワードは、データ ランドスケープ全体を総合的な表示を保持する必要があります。
この図には次の要素が含まれています。
- Dataplex: 複数のデータドメインのメッシュ
- ドメイン:
Sales、Customers、Productデータのレイク - ドメイン内のゾーン: 個々のチームの場合、またはマネージド データ契約を提供するため
- アセット: Cloud Storage バケットまたは BigQuery データセットに保存されたデータ。Dataplex メッシュとは別の Google Cloud プロジェクトに存在できます。
このシナリオを拡張するには、ゾーン内のデータを未加工のレイヤとキュレートされたレイヤに分割します。このアプローチを完遂するには、ドメインと未加工またはキュレート済のデータの置換ごとにゾーンを作成します。
- 未加工の販売
- キュレート済の販売
- 未加工のお客様
- キュレート済のお客様
- 未加工の製品
- キュレート済の製品
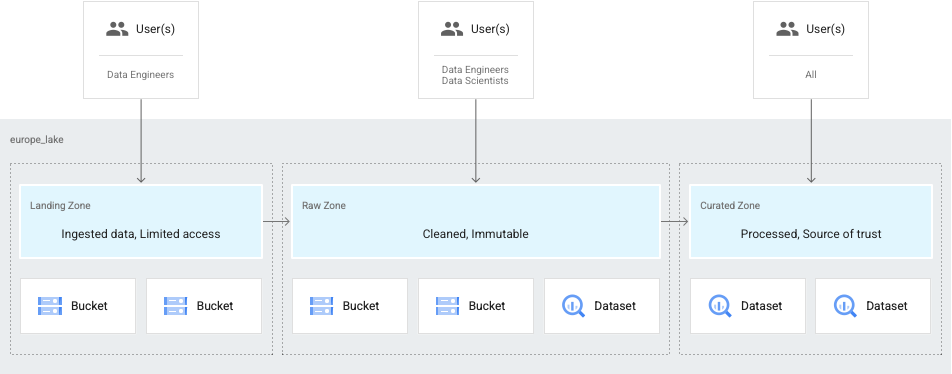
準備状況に基づくデータ階層化
別の一般的なユースケースとしては、データ エンジニアのみがデータにアクセスでき、その後、データ サイエンティストとデータ アナリストが調整して利用できる場合があります。この場合、以下のゾーンが含まれるようにレイクを設定できます。
- エンジニアがアクセスできるデータ用のランディング ゾーン。
- データ サイエンティストとアナリストが利用できるデータ用の未加工のゾーン。
次のステップ
- Dataplex の利用を開始する
- データメッシュを構築する
- レイクを作成する
- Dataplex でカタログ機能を検出する