データリネージは、データ アセットとそれらを変換するプロセスの関係を追跡することで、データがシステム内をどのように移動するかを把握するのに役立ちます。このリネージ情報は、 Google Cloud コンソールでグラフとリストとして表示できます。
このドキュメントでは、データリネージ情報モデルの概要、テーブルレベルと列レベルのリネージの粒度の詳細、グラフビューとリストビューを使用してデータリネージを探索する手順について説明します。
データリネージ情報モデル
リネージは、ソースからターゲットに変換されたデータのレコードです。Data Lineage API は、この情報を収集し、プロセス、実行、イベントのコンセプトを使用して階層型データモデルに整理します。
プロセス
プロセスは、特定のシステムのデータ変換オペレーションの定義です。BigQuery リネージの場合、プロセスはサポートされているジョブタイプのジョブです。同じ SQL クエリのすべての実行は単一のプロセスにリンクされるため、特定の変換ロジックが使用されるすべてのインスタンスを追跡できます。
たとえば、次の SQL クエリはプロセスです。このクエリは、2 つのソーステーブルから各ベンダーの合計乗車数をカウントしてテーブルを作成します。
CREATE TABLE `dataplex-docs.data_lineage_demo.total_green_trips_22_21`
AS
SELECT
vendor_id,
COUNT(*) AS number_of_trips
FROM
(
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2022`
UNION ALL
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2021`
)
GROUP BY
vendor_id;
プロセスの REST リソース名の形式は projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID です。
例: projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6
process リソースの詳細については、プロセス リソースのリファレンスをご覧ください。
実行
実行とは、プロセスの 1 回の実行のことです。プロセスには複数の実行を指定できます。
各実行は、startTime、endTime、最終状態(COMPLETED、FAILED、ABORTED など)で特徴付けられる一意のオペレーションです。
たとえば、午前 9 時に [プロセス] セクションから SQL クエリを実行すると、特定の実行が作成されます。午前 10 時に同じクエリを再度実行すると、新しい個別の実行が作成されます。両方の実行が同じ親プロセスにリンクされています。
実行の REST リソース名形式は、プロセスの子であることを示しています(projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID/runs/RUN_ID)。
例: projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6/runs/83dd03a51cd2ac80f465c9e267a950b1
run リソースの詳細については、実行リソースのリファレンスをご覧ください。
イベント
イベントは、データ変換によってソースとターゲットのエンティティ間でデータが移動した時点を表します。イベントは、特定の実行のソース テーブルとターゲット テーブルを接続する特定のデータ移動の詳細なレコードです。イベントには複数のソースとターゲットを設定することもできます。
たとえば、プロセスのセクションで説明した SQL クエリが実行されると、系統イベントは、nyc_green_trips_2021 と nyc_green_trips_2022 のソーステーブルを使用して total_green_trips_22_21 のターゲット テーブルが作成されたことを記録します。
リネージ イベントには、送信元とターゲットを定義するリンクのリストが含まれます。イベントは、リネージ グラフの作成に使用されます。 Google Cloud コンソールにはこれらのリネージグラフが表示されますが、個々のイベントが直接表示されることはありません。Data Lineage API を使用して、イベントの作成、読み取り、削除を行うことができます(更新はできません)。
イベント内の各リンクは、ソース エンティティからターゲット エンティティへのデータフローの単一のパスを定義します。エンティティは、BigQuery テーブルなどのデータアセットへの参照であり、完全修飾名(FQN)で識別されます。1 つのイベントに複数のリンクを含めることができます。これは、複数のソースが 1 つのターゲットに貢献するテーブル結合などのオペレーションでよく見られます。
イベントが列レベルのリネージをサポートする方法の詳細については、列レベルのリネージをご覧ください。
リネージの粒度
データリネージを使用すると、テーブルレベルと列レベルの両方でデータの出所と変換パスを追跡できます。
テーブルレベルのリネージ
テーブルレベルのリネージでは、テーブル間の関係を示すことで、データ パイプラインの概要を確認できます。テーブルレベルのリネージは、次のようなマクロレベルのタスクに使用します。
データの検出。新しいダッシュボードを作成するアナリストは、テーブルレベルの系統を使用して、要約テーブルをそのソースまでトレースし、データが信頼できるデータベースから取得されたことを確認できます。
移行計画。コア データベースの移行を計画しているデータベース管理者は、テーブルレベルの系統を使用して、そのデータベースに依存するすべてのダウンストリーム レポートとダッシュボードを特定できます。
監査とガバナンス。データ ガバナーは、テーブルレベルと列レベルのリネージを使用して、個人情報(PII)を含むテーブルのデータがパイプラインをどのように流れるかを確認できます。
列レベルのリネージ
列レベルのリネージは、個々の列間のデータの流れを追跡することで、より詳細なビューを提供します。このビューでは、リネージ イベント内のリンクは、ソース列とターゲット列の関係を表します。これらの列レベルのリンクにはそれぞれ、変換を記述する依存関係のタイプがあります。
Exact copy: 列間で値がコピーされます。Other: 列間の他の種類の依存関係。
列レベルの系統は、次のようなタスクに使用します。
根本原因の分析。データ アナリストが列に誤った値を見つけた場合、列レベルのリネージを使用してソース列まで遡り、根本原因を特定できます。
影響分析。データ エンジニアは、列を非推奨にする前に、列レベルのリネージを使用して、その列に依存するすべてのダウンストリーム列を見つけることができます。
指標のデータソースの検証。データ アナリストは、列レベルの系統を使用して、複雑な SQL クエリを解読することなく、指標の計算に使用されるソース列を特定できます。
列レベルのリネージは、次のタイプの BigQuery ジョブに対して自動的に収集されます。
Google Cloud コンソールのリネージ ビュー
Google Cloud コンソールのデータリネージでは、リネージ情報を操作する方法が 2 つあります。使用可能な複数のリージョンにわたってリネージグラフを探索するか、リネージ エクスプローラ パネルを使用して、特定のリージョン内のより詳細なビューを取得できます。グラフ表示とリスト表示を切り替えて、さまざまな詳細レベルでデータフローを分析することもできます。
リネージビューは、Dataplex Universal Catalog エントリ、BigQuery アセット、Vertex AI リソース(モデル、データセット、特徴ストア ビュー、特徴グループ)でのみ使用できます。
このページで説明するさまざまなビューについては、 Google Cloud システムでデータリネージを使用するをご覧ください。
リネージグラフ ビュー
グラフビューでは、システムとリージョン間のデータアセットのフローと関係が可視化されるため、データ アーキテクチャの把握、オリジンと宛先の追跡、パターンの特定に役立ちます。これらのリネージグラフは、特定の Dataplex Universal Catalog エントリに対して Data Lineage API サービスによって生成され、データの経時的な変換方法を示します。選択したルートエントリの上流、下流、または両方のフローが表示されます。
Data Lineage API は、サポートされているシステムおよびカスタムソースの API 呼び出しからアセット情報を自動的に受信します。
グラフの主な要素は次のとおりです。
ノード。データ エンティティを表します。テーブルレベルのビューでは、ノードにテーブル名とその列が表示されます。列レベルのビューでは、各ノードは特定のテーブルと列を表します。
エッジ。ノードを接続し、ノード間で発生するプロセスを表す線。エッジの表示は、リネージ ビューによって異なります。
- テーブルレベルのビューでは、エッジにデータ変換を示すアイコンが表示されます。
- 列レベルのビューでは、エッジにデータ変換を示すラベルが付いています。たとえば、エッジラベルに
Exact copyと表示されることがあります。これは、ソース列がターゲット列にコピーされた方法を示しています。
アイコンとラベルを処理します。変換に関する詳細情報を表示するために、エッジに表示されます。
- アイコン。変換プロセスを表します。グラフを手動で探索すると、エッジのアイコンはプロセスのソースシステム(BigQuery や Vertex AI など)を表します。複数のプロセスが関与している場合は、「複数のプロセス」アイコンが表示されます。プロセス ソース システムが不明な場合は、歯車アイコンが使用されます。フィルタを適用すると、すべてのプロセスに歯車アイコンが使用されます。
- ラベル。列レベルのリネージビューでは、ラベルは列間の依存関係のタイプ(
Exact copyまたはOther)を示します。
リネージ グラフを手動で確認する
[リネージ] タブを開くと、デフォルトの [グラフ] ビューが表示されます。デフォルトのビューには、システムとリージョン全体の概要が表示されます。グラフは手動で増分的に拡大でき、一度に 5 つのノードを読み込むことができます。エッジのプロセス アイコンは、ソースシステムを表すか、複数のプロセスを示します。
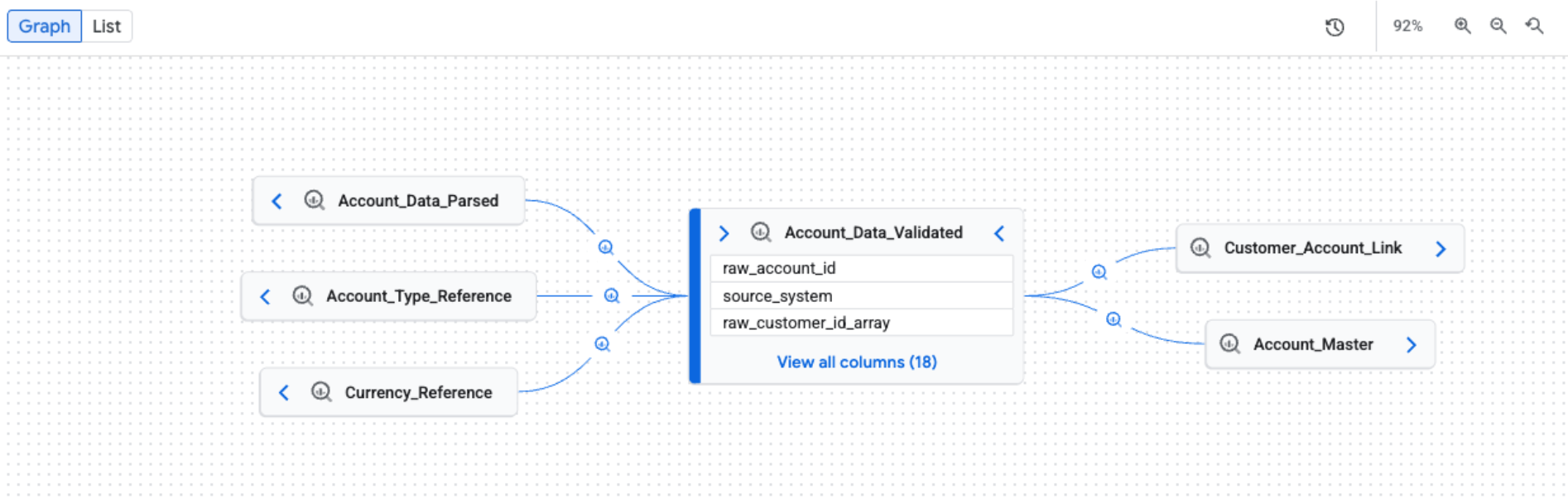
フィルタを適用してリネージ ビューを絞り込む
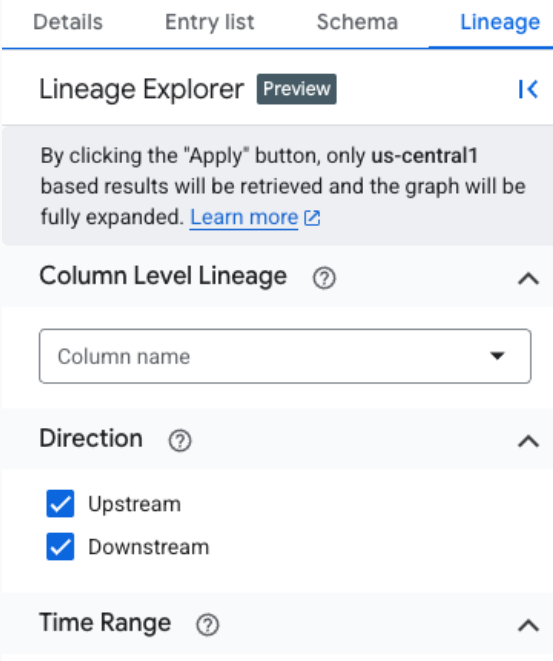
特定のリージョン内の分析に焦点を当てるためにリネージ データをフィルタするには、[リネージ エクスプローラ] パネルを使用します。フォーカス ビューに切り替えるために使用できる条件を次に示します。
- 列名: 列名でリネージをフィルタして、列レベルの詳細を表示します。
- 方向: アップストリームまたはダウンストリームのリネージ、またはその両方を表示します。
- 期間: 特定の開始時刻または終了時刻に基づいてリネージをフィルタします。
- 依存関係のタイプ: 依存関係のタイプに基づいて列レベルの系統をフィルタします。使用可能なオプションの例としては、
AllやExact copyなどがあります。
フォーカス ビューでは、グラフが自動的に 3 レベルまで展開され、フィルタ条件に一致するすべてのリネージが読み込まれます。テーブルレベルと列レベルの両方のリネージをサポートしており、選択したノードからルートまでのパスの可視化も可能です。このフォーカス ビューでは、すべてのプロセスに汎用の歯車アイコンが使用されます。

列レベルのリネージを表示するには、次のいずれかの方法を使用します。
フォーカスされたグラフビューで、テーブルの列アイコンをクリックして、列レベルのリネージに切り替えます。
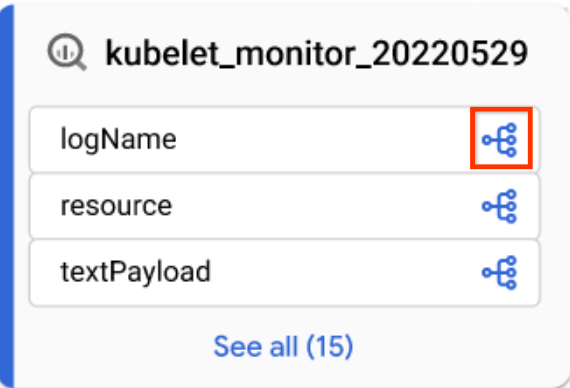
列アイコン デフォルトのグラフビューまたはフォーカスされたグラフビューで、リネージ エクスプローラ パネルの列名を適用します。

すべてのフィルタを削除してデフォルトのビューに戻るには、 リセットをクリックします。
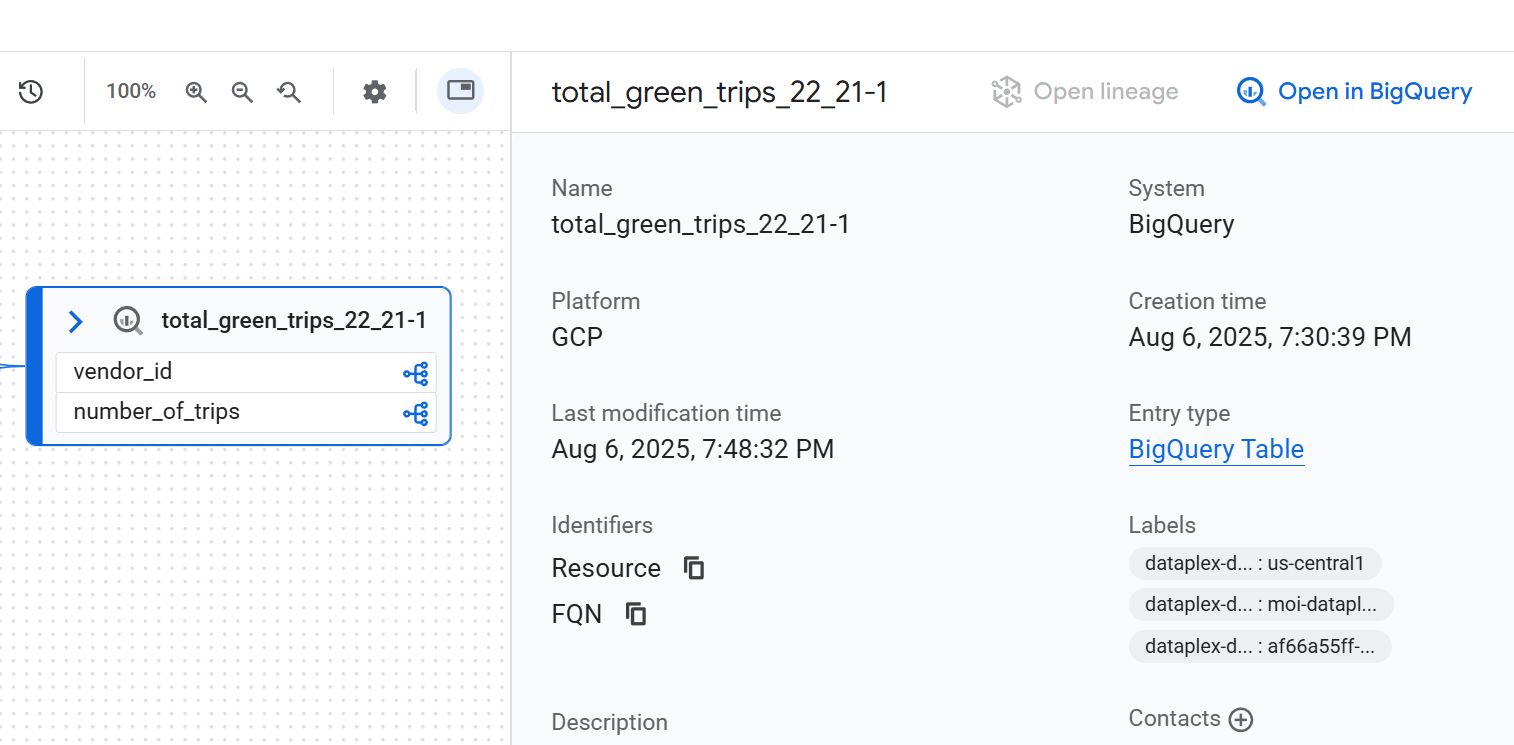
ノードの詳細
ノードの詳細を表示するには、ノードをクリックします。サイドパネルが表示され、選択したデータアセットに関する詳細情報が表示されます。たとえば、テーブルレベルの系統ビューでノードをクリックすると、アセットの完全修飾名、タイプ、その他の関連属性などの情報が表示されます。
実行の監査と履歴
完全なリネージグラフは、多くの異なるジョブの実行結果です。各ジョブは、グラフ内の特定のリンクを作成します。複数の実行は新しい実行としてログに記録されますが、グラフの静的な外観は変更されません。
個々の実行の詳細を表示するには、グラフでプロセスを含むエッジをクリックします。表示された [クエリ] パネルで、[実行] タブをクリックします。
![[詳細] タブと [実行] タブが表示されている [クエリ] パネル。](https://cloud.google.com/static/dataplex/images/query-pane.png?hl=ja)
変換ロジックを検査する
コードを検索せずに変換のビジネス ロジックを理解するには、実行された正確な SQL クエリを表示します。SQL コードを表示するには、グラフでプロセスを含むエッジをクリックします。表示されたサイドパネルで、[詳細] タブをクリックします。
リネージパスの可視化
リネージパスの可視化は、グラフ内の選択したノードからルートエントリまでのパスをトレースするのに役立ちます。ノードを選択して [パスを可視化] をクリックすると、グラフにはルート エントリへの直接リネージパスを形成するノードとプロセスのみがハイライト表示されます。
リネージパスの可視化を表示するには、[リネージ エクスプローラ] パネルでフィルタを適用して、フォーカスされたグラフビューを作成します。次に、フォーカスされた [グラフ] ビューでノードを選択します。選択したノードの詳細パネルで、[パスを可視化] をクリックします。
リネージパスの可視化は、テーブルレベルと列レベルのリネージで使用できます。リネージパスの可視化は、[リスト] ビューでも使用できます。
リネージのリスト表示
[リスト] ビューには、リネージの表形式の構造化された表現が表示されます。これは、[グラフ] ビューと同期されます。データアセットの並べ替え、フィルタリング、ダウンロードを容易にします。このビューは、ソースとターゲットの関係の分析、関連するアセットの詳細の表示、リネージ データの書き出しに最適です。
リストビューは、テーブルレベルと列レベルの両方のリネージで使用できます。詳細リストビューと簡略リストビューを切り替えることができます。
シンプル リストビュー: このビューは、リネージに関与するすべてのアセットの簡潔で一意のリストを取得する場合に便利です。[システム]、[プロジェクト]、[エンティティ]、[FQN](完全修飾名)、[方向]、[深さ] などの列を使用すると、リネージ内のすべてのデータアセット、その所在、元のソース、分析対象の中央アセットからの距離を確認できます。データフローに参加するすべてのエンティティの概要を把握するのに最適です。これがデフォルトのビューです。
詳細リストビュー: このビューは、個々のソースとターゲットの関係を分析するために設計されています。[ソース] 列と [ターゲット] 列を別々に指定すると、各データ変換リンクを確認できます。このビューは、個々のデータフローの監査、テーブル間の依存関係の把握、各接続の詳細なリネージ レコードのエクスポートなど、特定のアセットのペア間でデータがどのように移動するかを深く理解する必要があるタスクに最適です。
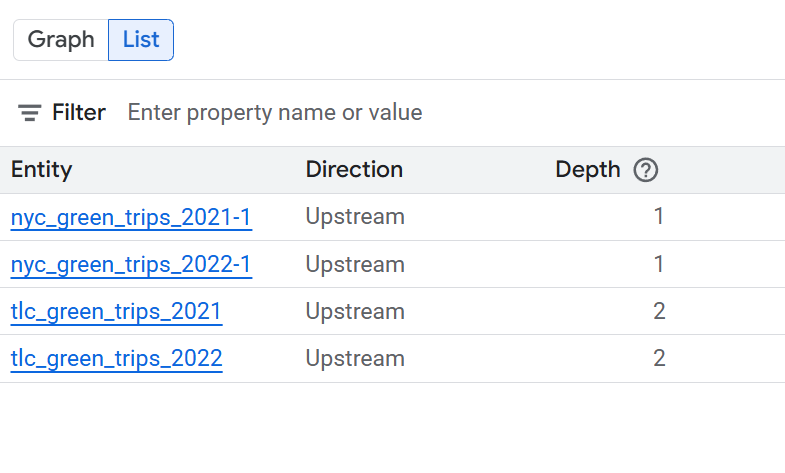
テーブルレベルのリネージのリストビュー
このビューには、テーブル間の関係が全体として表示されます。指定されたフィルタを使用して、必要な列を選択します。
以下のセクションを開くと、テーブルレベルのリストビューで使用できる列が表示されます。
簡略化されたテーブルレベルのリストビューで使用可能な列
- システム: データアセットが配置されているシステム。たとえば、BigQuery などがあります。
- プロジェクト: データアセットを含む Google Cloud プロジェクト ID。
- エンティティ: データアセットの名前。例にはテーブル名が含まれています。
- FQN: 元のソース エンティティまたは列の完全修飾名(FQN)。
- 方向: リストに表示されたアセットが、リネージフローのアップストリーム(ソース)かダウンストリーム(ターゲット)かを示します。
- 深度: 分析対象の中央アセットからのリネージ ステップの数。
詳細なテーブルレベルのリストビューで使用できる列
- ソースシステム: ソースデータ アセットが配置されているシステム。たとえば、BigQuery などがあります。
- ソース プロジェクト: ソースデータ アセットを含む Google Cloud プロジェクト ID。
- ソース: ソース データアセットの名前。たとえば、テーブル名などがあります。
- 送信元 FQN: 送信元エンティティの FQN。
- ターゲット システム: ターゲット データアセットが配置されているシステム。たとえば、BigQuery などがあります。
- ターゲット プロジェクト: ターゲット データアセットを含む Google Cloud プロジェクト ID。
- ターゲット: ターゲット データアセットの名前。たとえば、テーブル名などがあります。
- ターゲットの FQN: ターゲット エンティティの FQN。
- 方向: リストに表示されたアセットが、リネージフローのアップストリーム(ソース)かダウンストリーム(ターゲット)かを示します。
- 深度: 分析対象の中央アセットからのリネージ ステップの数。
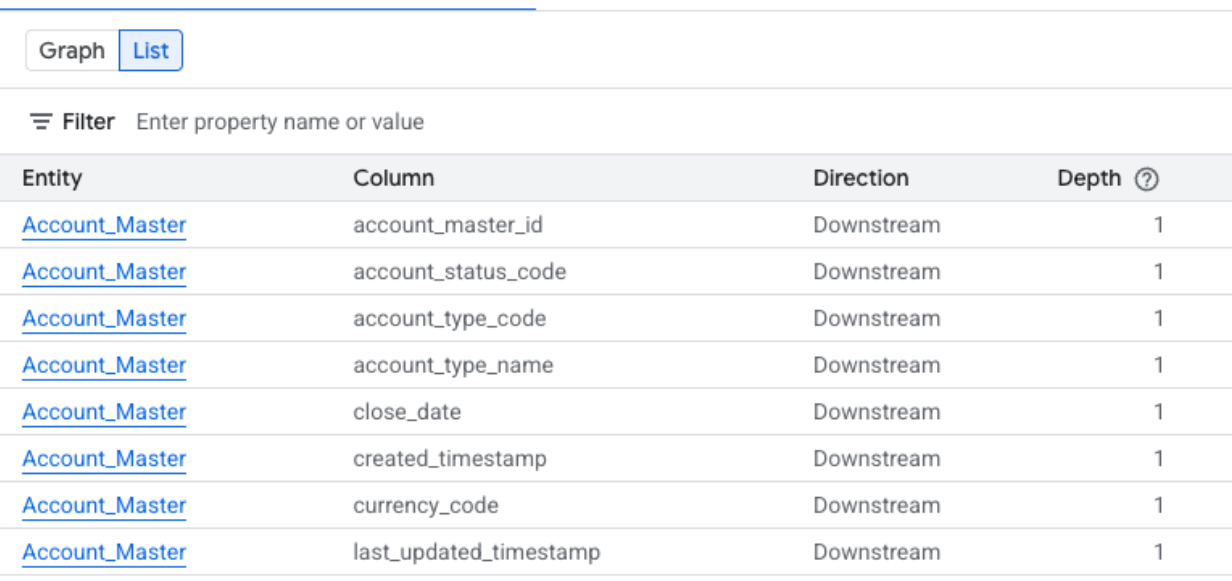
列レベルのリネージのリストビュー
このビューには、ソーステーブルとターゲット テーブルの個々の列間の関係が表示されます。指定されたフィルタを使用して、必要な列を選択します。
次のセクションを開くと、列レベルのリストビューで使用可能な列が表示されます。
簡略化された列レベルのリストビューで使用できる列
- システム: データアセットが配置されているシステム。たとえば、BigQuery などがあります。
- プロジェクト: データアセットを含む Google Cloud プロジェクト ID。
- エンティティ: データアセットの名前。例にはテーブル名が含まれています。
- 列: エンティティ内のリネージ エクスプローラ パネルで選択された特定の列。
- FQN: 元のソース エンティティまたは列の完全修飾名(FQN)。
- 方向: リストに表示されたアセットが、リネージフローのアップストリーム(ソース)かダウンストリーム(ターゲット)かを示します。
- 深度: 分析対象の中央アセットからのリネージ ステップの数。
詳細な列レベルのリストビューで使用できる列
- ソースシステム: ソースデータ アセットが配置されているシステム。
- ソース プロジェクト: ソースデータ アセットを含む Google Cloud プロジェクト ID。
- 送信元 FQN: 送信元列の FQN。
- ターゲット システム: ターゲット データアセットが配置されているシステム。
- ターゲット プロジェクト: ターゲット データアセットを含む Google Cloud プロジェクト ID。
- ターゲットの FQN: ターゲット列の FQN。
- 方向: データフローがアップストリームかダウンストリームかを示します。
- 依存関係のタイプ: 列間の関係の性質を表します。
- 深度: 分析対象の中央アセットからのリネージ ステップの数。
次のステップ
リネージ ソースについて学習する。
Google Cloud システムでデータリネージを使用する方法を学習する。