Mit der Datenherkunft können Sie nachvollziehen, wie Daten durch Ihre Systeme fließen, indem Sie die Beziehungen zwischen Daten-Assets und den Prozessen, die sie transformieren, nachverfolgen. Sie können diese Informationen zur Herkunft in der Google Cloud -Konsole als Diagramme und Listen ansehen.
Dieses Dokument bietet einen Überblick über das Datenherkunftsmodell, Details zur Granularität der Herkunft auf Tabellen- und Spaltenebene sowie eine Anleitung zur Verwendung von Diagramm- und Listenansichten zum Untersuchen der Datenherkunft.
Informationsmodell für Datenherkunft
Die Herkunft ist ein Datensatz, in dem die Transformation von Daten aus Quellen in Ziele aufgezeichnet wird. Die Data Lineage API erfasst diese Informationen und organisiert sie in einem hierarchischen Datenmodell, in dem die Konzepte von Prozessen, Ausführungen und Ereignissen verwendet werden.
- Prozess: eine Definition für die Datentransformation.
- Ausführung: Eine Ausführung eines Prozesses.
- Ereignis: Ein Datensatz für die Datenverschiebung während eines Laufs.
Prozess
Ein Prozess ist die Definition eines Datentransformationsvorgangs für ein bestimmtes System. Für die BigQuery-Abstammung ist ein Prozess ein Job eines unterstützten Jobtyps. Alle Ausführungen derselben SQL-Abfrage sind mit einem einzelnen Prozess verknüpft. So können Sie jede Instanz nachverfolgen, in der eine bestimmte Transformationslogik verwendet wird.
Die folgende SQL-Abfrage ist beispielsweise ein Prozess. Mit dieser Abfrage wird eine Tabelle erstellt, in der die Gesamtzahl der Fahrten für jeden Anbieter aus zwei Quelltabellen gezählt wird.
CREATE TABLE `dataplex-docs.data_lineage_demo.total_green_trips_22_21`
AS
SELECT
vendor_id,
COUNT(*) AS number_of_trips
FROM
(
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2022`
UNION ALL
SELECT vendor_id
FROM `dataplex-docs.data_lineage_demo.nyc_green_trips_2021`
)
GROUP BY
vendor_id;
Das REST-Ressourcennamenformat für einen Prozess ist projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID.
Beispiel: projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6
Weitere Informationen zur Ressource process finden Sie in der Referenz zur Prozessressource.
Ausführen
Eine Ausführung ist eine einzelne Ausführung eines Prozesses. Prozesse können mehrmals ausgeführt werden.
Jeder Lauf ist ein eindeutiger Vorgang, der durch eine startTime, eine endTime und einen Endstatus wie COMPLETED, FAILED oder ABORTED gekennzeichnet ist.
Wenn Sie beispielsweise die SQL-Abfrage aus dem Abschnitt Prozess um 9:00 Uhr ausführen, wird ein bestimmter Lauf erstellt. Wenn Sie dieselbe Abfrage um 10:00 Uhr noch einmal ausführen, wird ein neuer, separater Lauf erstellt. Beide Läufe sind mit demselben übergeordneten Prozess verknüpft.
Das REST-Ressourcennamenformat für einen Lauf zeigt, dass er ein untergeordnetes Element eines Prozesses ist: projects/PROJECT_NUMBER/locations/LOCATION/processes/PROCESS_ID/runs/RUN_ID.
Beispiel: projects/123456789123/locations/us/processes/sh-0548bbf4ff3c8072a6c7372ba1acafb6/runs/83dd03a51cd2ac80f465c9e267a950b1
Weitere Informationen zur run-Ressource finden Sie in der Referenz zur Ausführungsressource.
Ereignis
Ein Ereignis stellt einen Zeitpunkt dar, zu dem Daten durch eine Datentransformation zwischen einer Quelle und einem Ziel verschoben werden. Ein Ereignis ist ein detaillierter Datensatz einer bestimmten Datenübertragung, der Quell- und Zieltabelle für einen bestimmten Lauf verbindet. Ein Ereignis kann auch mehrere Quellen und Ziele haben.
Wenn bei Ihrem Lauf beispielsweise die im Abschnitt Prozess beschriebene SQL-Abfrage ausgeführt wird, wird in einem Lineage-Ereignis aufgezeichnet, dass die Quelltabellen nyc_green_trips_2021 und nyc_green_trips_2022 zum Erstellen der Zieltabelle total_green_trips_22_21 verwendet werden.
Ein Lineage-Ereignis enthält eine Liste von Links, die die Quelle und das Ziel definieren. Ereignisse werden verwendet, um Herkunftsgraphen zu erstellen. In der Google Cloud -Konsole werden diese Abstammungsdiagramme angezeigt, einzelne Ereignisse werden jedoch nicht direkt dargestellt. Mit der Data Lineage API können Sie Ereignisse erstellen, lesen und löschen, aber nicht aktualisieren.
Jede Verknüpfung in einem Ereignis definiert einen einzelnen Datenfluss von einer Quell- zu einer Zielentität. Eine Entität ist ein Verweis auf ein Daten-Asset wie eine BigQuery-Tabelle und wird durch ihren vollständig qualifizierten Namen (Fully Qualified Name, FQN) identifiziert. Ein einzelnes Ereignis kann mehrere Links enthalten. Das ist bei Vorgängen wie Tabellenverknüpfungen üblich, bei denen mehrere Quellen zu einem Ziel beitragen.
Weitere Informationen dazu, wie Ereignisse die Herkunft auf Spaltenebene unterstützen, finden Sie unter Herkunft auf Spaltenebene.
Detaillierungsgrad der Herkunft
Mit Data Lineage können Sie den Ursprung und den Transformationspfad Ihrer Daten sowohl auf Tabellen- als auch auf Spaltenebene nachvollziehen.
Zeilen auf Tabellenebene
Die Herkunft auf Tabellenebene bietet einen allgemeinen Überblick über Ihre Datenpipelines, indem die Beziehungen zwischen ganzen Tabellen dargestellt werden. Verwenden Sie den Datenursprung auf Tabellenebene für Makroaufgaben wie die folgenden:
Datenerkennung: Ein Analyst, der ein neues Dashboard erstellt, kann die Herkunft auf Tabellenebene verwenden, um eine Zusammenfassungstabelle auf ihre Quellen zurückzuführen und zu bestätigen, dass die Daten aus einer autoritativen Datenbank stammen.
Planung der Migration. Ein Datenbankadministrator, der die Migration einer wichtigen Datenbank plant, kann die Herkunft auf Tabellenebene verwenden, um alle nachgelagerten Berichte und Dashboards zu ermitteln, die von der Datenbank abhängen.
Prüfung und Governance: Ein Data Governor kann die Herkunft auf Tabellen- und Spaltenebene verwenden, um zu prüfen, wie Daten aus einer Tabelle, die personenidentifizierbare Informationen enthält, durch eine Pipeline fließen.
Herkunft auf Spaltenebene
Die Herkunft auf Spaltenebene bietet eine detailliertere Ansicht, da der Datenfluss zwischen einzelnen Spalten nachverfolgt wird. In dieser Ansicht stellen die Links in einem Lineage-Ereignis die Beziehung zwischen einer Quellspalte und einer Zielspalte dar. Jeder dieser Links auf Spaltenebene hat einen Abhängigkeitstyp, der die Transformation beschreibt:
Exact copy: Werte werden zwischen Spalten kopiert.Other: andere Arten von Abhängigkeiten zwischen Spalten.
Sie können die Herkunft auf Spaltenebene für Aufgaben wie die folgenden verwenden:
Ursachenanalyse: Wenn eine Fachkraft für Datenanalyse einen falschen Wert in einer Spalte findet, kann sie die Herkunft auf Spaltenebene verwenden, um den Wert bis zu den Quellspalten zurückzuverfolgen und die Ursache zu ermitteln.
Wirkungsanalyse: Bevor ein Data Engineer eine Spalte einstellt, kann er mit der Herkunft auf Spaltenebene alle nachgelagerten Spalten finden, die davon abhängen.
Datenquellenbestätigung für Messwerte Mithilfe der Herkunft auf Spaltenebene kann eine Fachkraft für Datenanalyse ermitteln, welche Quellspalten zum Berechnen eines Messwerts verwendet werden, ohne eine komplexe SQL-Abfrage entschlüsseln zu müssen.
Die Herkunft auf Spaltenebene wird automatisch für die folgenden Arten von BigQuery-Jobs erfasst:
Lineage-Ansichten in der Google Cloud -Console
Mit der Datenherkunft in der Google Cloud Console können Sie auf zwei Arten mit Herkunftsinformationen interagieren: Sie können das Herkunftsgraph in mehreren verfügbaren Regionen untersuchen oder das Feld Lineage Explorer verwenden, um eine fokussiertere Ansicht in einer bestimmten Region zu erhalten. Sie können auch zwischen der Diagramm- und der Listenansicht wechseln, um den Datenfluss auf verschiedenen Detailebenen zu analysieren.
Lineage-Ansichten sind nur für Dataplex Universal Catalog-Einträge, BigQuery-Assets und Vertex AI-Ressourcen (Modelle, Datasets, Feature Store-Ansichten und Featuregruppen) verfügbar.
Informationen zu den verschiedenen Ansichten, die auf dieser Seite beschrieben werden, finden Sie unter Data Lineage mit Google Cloud -Systemen verwenden.
Ansicht des Herkunftsdiagramms
In der Graph-Ansicht werden Datenfluss und Beziehungen zwischen Systemen und Regionen visualisiert. So können Sie die Datenarchitektur nachvollziehen, Ursprünge und Ziele nachverfolgen und Muster erkennen. Diese Lineage-Diagramme, die vom Data Lineage API-Dienst für einen bestimmten Dataplex Universal Catalog-Eintrag generiert werden, zeigen, wie Daten im Laufe der Zeit transformiert werden. Sie stellen Upstream-, Downstream- oder beide Flüsse von einem ausgewählten Stamm-Eintrag dar.
Die Data Lineage API empfängt automatisch Asset-Informationen von unterstützten Systemen und über API-Aufrufe für benutzerdefinierte Quellen.
Die wichtigsten Elemente im Diagramm werden so beschrieben:
Knoten: Stellen Sie die Datenentitäten dar. In einer Ansicht auf Tabellenebene wird in einem Knoten der Tabellenname und die zugehörigen Spalten angezeigt. In einer Ansicht auf Spaltenebene stellt jeder Knoten eine bestimmte Tabelle und Spalte dar.
Kanten: Die Linien, die Knoten verbinden und die Prozesse darstellen, die zwischen ihnen stattfinden. Die Darstellung einer Kante hängt von der Lineage-Ansicht ab:
- In der Ansicht auf Tabellenebene haben Kanten Symbole, die Datentransformationen angeben.
- In der Ansicht auf Spaltenebene haben Kanten Labels, die Datentransformationen angeben. Ein Kantenlabel könnte beispielsweise
Exact copylauten, um zu beschreiben, wie eine Quellspalte in eine Zielspalte kopiert wurde.
Symbole und Labels verarbeiten: Sie werden an den Kanten angezeigt, um weitere Informationen zur Transformation zu liefern.
- Symbole: Stellen Sie den Transformationsprozess dar. Wenn Sie den Graphen manuell untersuchen, stellen Symbole auf den Kanten das Quellsystem des Prozesses dar (z. B. BigQuery oder Vertex AI). Wenn mehrere Prozesse beteiligt sind, wird das Symbol „Mehrere Prozesse“ angezeigt. Wenn das Quellsystem des Prozesses unbekannt ist, wird ein Zahnradsymbol verwendet. Wenn Sie Filter anwenden, wird für alle Prozesse ein Zahnradsymbol verwendet.
- Labels: In der Ansicht „Abstammung auf Spaltenebene“ wird die Art der Abhängigkeit zwischen Spalten mit einem Label beschrieben:
Exact copyoderOther.
Lineage-Diagramm manuell untersuchen
Wenn Sie den Tab Lineage öffnen, wird standardmäßig die Diagrammansicht angezeigt. Die Standardansicht bietet eine allgemeine Übersicht über Systeme und Regionen hinweg. Der Graph kann manuell und inkrementell erweitert werden, wobei jeweils fünf Knoten geladen werden. Prozesssymbole an Kanten stellen das Quellsystem dar oder weisen auf mehrere Prozesse hin.
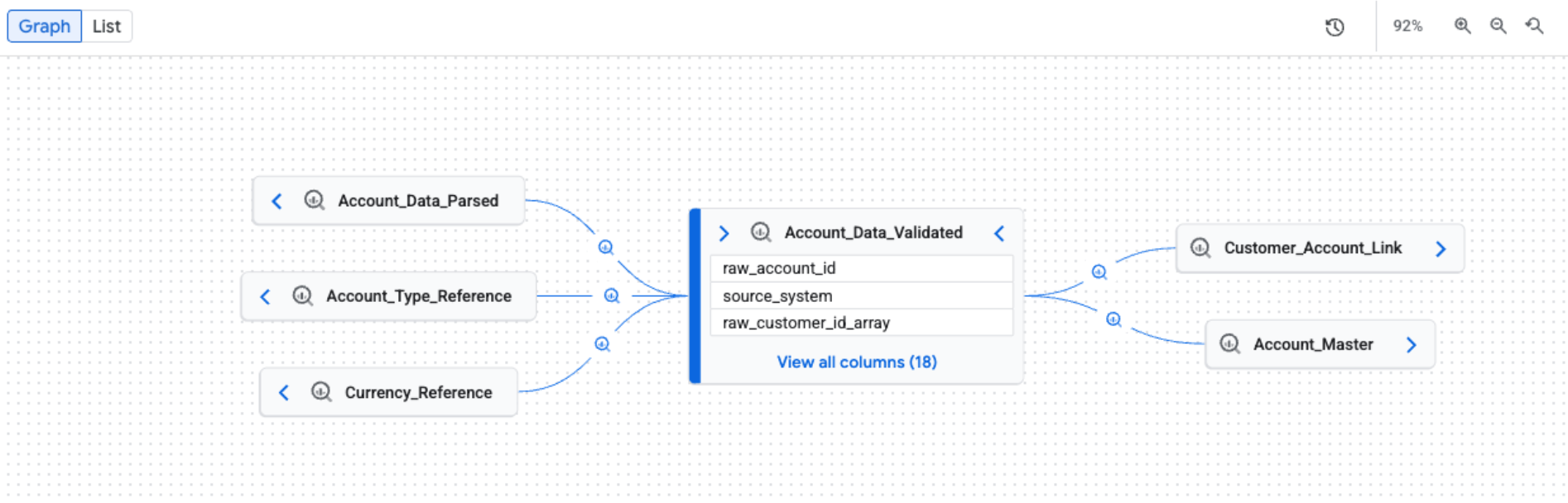
Filter für eine fokussierte Lineage-Ansicht anwenden
Wenn Sie die Herkunftsdaten für eine fokussierte Analyse in einer bestimmten Region filtern möchten, verwenden Sie den Bereich Lineage Explorer. Hier sind einige Kriterien, die Sie verwenden können, um zu einer fokussierten Ansicht zu wechseln:
- Spaltenname: Filtern Sie die Herkunft nach Spaltenname, um Details auf Spaltenebene zu sehen.
- Richtung: Zeigen Sie die Upstream- oder Downstream-Abstammung oder beides an.
- Zeitraum: Filtern Sie den Datenursprung anhand einer bestimmten Start- oder Endzeit.
- Abhängigkeitstyp: Filtern Sie die Lineage auf Spaltenebene nach dem Abhängigkeitstyp.
Beispiele für verfügbare Optionen sind
AllundExact copy.
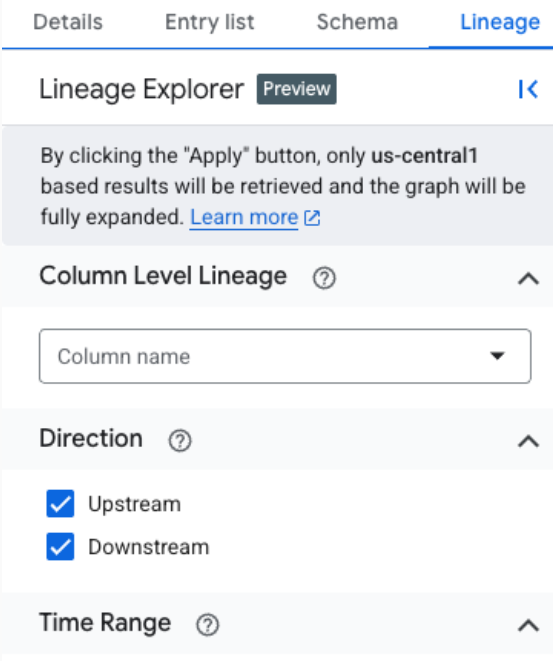
In der fokussierten Ansicht wird das Diagramm automatisch auf bis zu drei Ebenen erweitert und alle Linien geladen, die den Filterkriterien entsprechen. Sie unterstützt sowohl die Herkunft auf Tabellen- als auch auf Spaltenebene, einschließlich der Pfadvisualisierung von einem beliebigen ausgewählten Knoten zurück zum Stamm. In dieser fokussierten Ansicht wird für alle Prozesse ein generisches Zahnradsymbol verwendet.

Sie haben folgende Möglichkeiten, um die Herkunft auf Spaltenebene aufzurufen:
Klicken Sie in einer fokussierten Graph-Ansicht in einer Tabelle auf das Spaltensymbol, um zur Herkunft auf Spaltenebene zu wechseln.
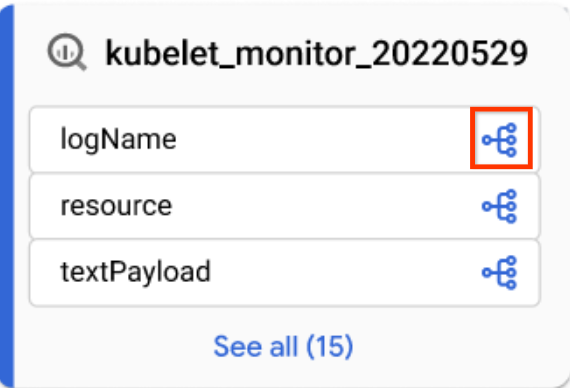
Spaltensymbol Wenden Sie in der Standardansicht Diagramm oder in der fokussierten Ansicht Diagramm einen Spaltennamen im Bereich Lineage Explorer an.

Wenn Sie alle Filter entfernen und zur Standardansicht zurückkehren möchten, klicken Sie auf „Zurücksetzen“.
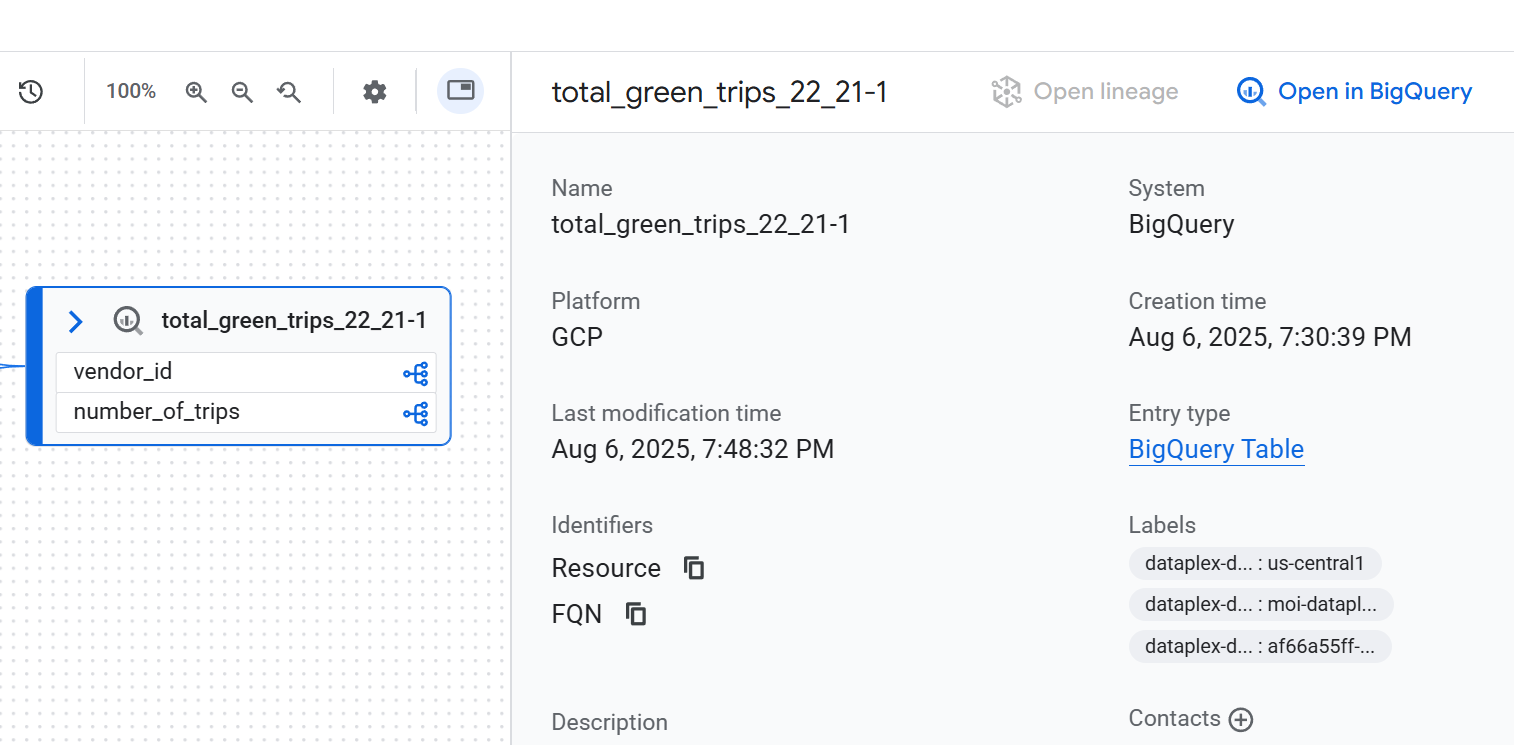
Knotendetails
Wenn Sie die Details eines Knotens aufrufen möchten, klicken Sie auf den Knoten. Eine Seitenleiste mit detaillierten Informationen zum ausgewählten Daten-Asset wird angezeigt. Wenn Sie beispielsweise in einer Lineage-Ansicht auf Tabellenebene auf einen Knoten klicken, werden Informationen wie der vollständig qualifizierte Name, der Typ und andere relevante Attribute des Assets angezeigt.
Audit und Verlauf von Ausführungen
Ein vollständiges Lineage-Diagramm ist das Ergebnis von Ausführungen vieler verschiedener Jobs, wobei jeder Job einen bestimmten Link im Diagramm erstellt. Mehrere Ausführungen werden als neue Läufe protokolliert, ändern aber nicht das statische Erscheinungsbild des Diagramms.
Wenn Sie die Details der einzelnen Ausführungen sehen möchten, klicken Sie im Diagramm auf eine Kante mit einem Prozess. Klicken Sie im angezeigten Bereich Abfrage auf den Tab Ausführungen.

Transformationslogik prüfen
Wenn Sie die Geschäftslogik einer Transformation nachvollziehen möchten, ohne nach dem Code suchen zu müssen, können Sie die genaue SQL-Abfrage aufrufen, die ausgeführt wurde. Wenn Sie den SQL-Code aufrufen möchten, klicken Sie im Diagramm auf eine Kante mit einem Prozess. Klicken Sie in der Seitenleiste, die angezeigt wird, auf den Tab Details.
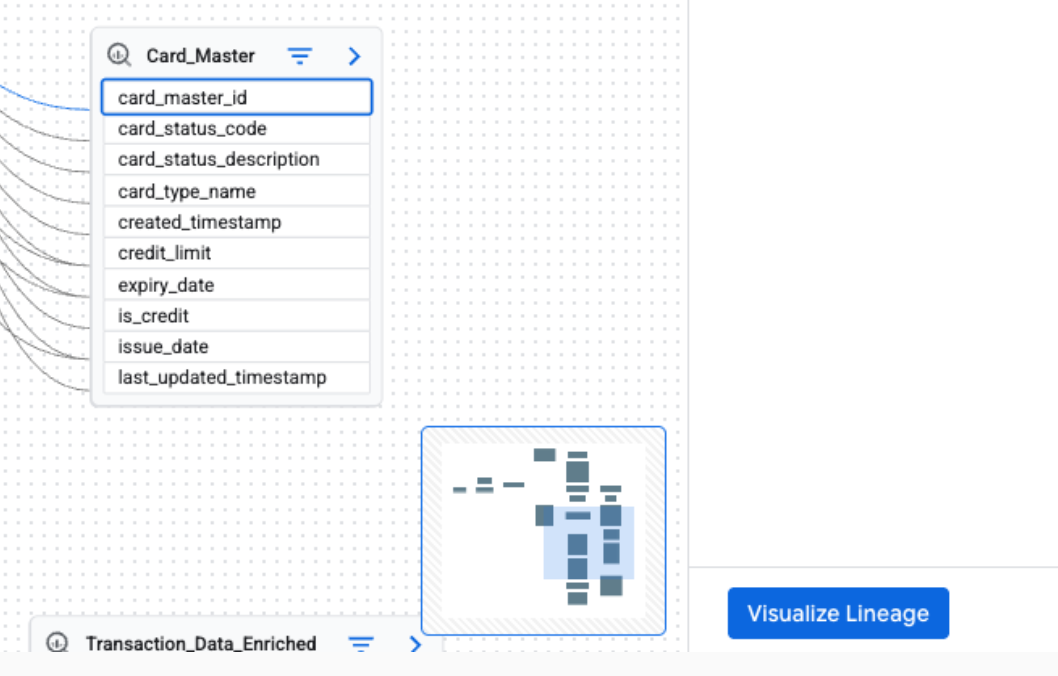
Visualisierung des Herkunftspfads
Mit der Visualisierung des Herkunftspfads können Sie den Pfad von einem beliebigen ausgewählten Knoten im Diagramm zurück zum Stammeintrag nachvollziehen. Wenn Sie einen Knoten auswählen und auf Pfad visualisieren klicken, werden im Diagramm nur die Knoten und Prozesse hervorgehoben, die den direkten Pfad zur Stammquelle bilden.
Wenn Sie die Visualisierung des Herkunftspfads sehen möchten, wenden Sie im Bereich Lineage Explorer einen Filter an, um eine fokussierte Graph-Ansicht zu erstellen. Wählen Sie dann in der fokussierten Graph-Ansicht einen Knoten aus. Klicken Sie im Detailbereich für den ausgewählten Knoten auf Pfad visualisieren.
Die Visualisierung des Herkunftspfads ist für die Herkunft auf Tabellen- und Spaltenebene verfügbar. Sie können die Visualisierung des Lineage-Pfads auch in der Listenansicht verwenden.
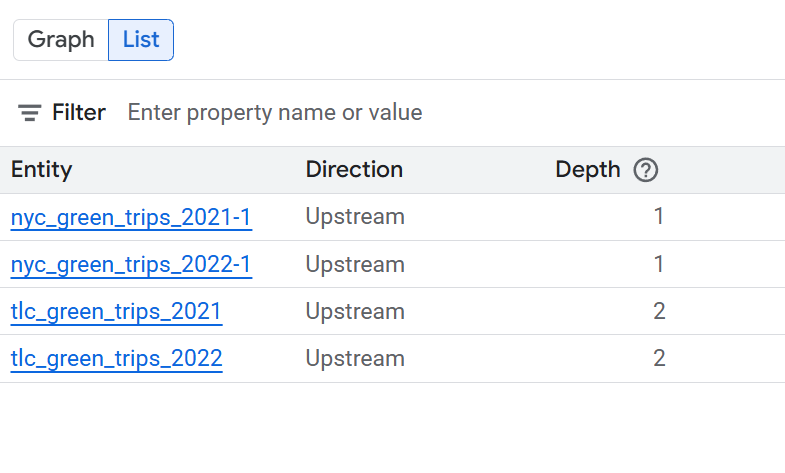
Lineage-Listenansicht
Die Listenansicht bietet eine tabellarische, strukturierte Darstellung der Herkunft, die mit der Diagrammansicht synchronisiert wird. Sie erleichtert das Sortieren, Filtern und Herunterladen von Daten-Assets. Diese Ansicht eignet sich ideal, um Quell-Ziel-Beziehungen zu analysieren, beteiligte Assets zu detaillieren und Herkunftsdaten zu exportieren.
Die Listenansicht ist sowohl für die Herkunft auf Tabellen- als auch auf Spaltenebene verfügbar. Sie können zwischen den folgenden detaillierten und vereinfachten Listenansichten wechseln.
Vereinfachte Listenansicht: Diese Ansicht ist nützlich, um eine komprimierte, eindeutige Liste aller Assets zu erhalten, die in der Herkunft enthalten sind. Die Spalten wie System, Project, Entity, FQN (Fully Qualified Name), Direction und Depth (Tiefe) geben Aufschluss über alle Datenassets in der Herkunft, ihren Speicherort, ihre ursprüngliche Quelle und ihre Entfernung vom zentralen Asset, das analysiert wird. Es eignet sich ideal für einen allgemeinen Überblick über alle am Datenfluss beteiligten Entitäten. Das ist die Standardansicht.
Detaillierte Listenansicht: Diese Ansicht ist für die Analyse einzelner Quell-Ziel-Beziehungen konzipiert. Wenn Sie separate Spalten für Quelle und Ziel angeben, sehen Sie jeden spezifischen Link zur Datentransformation. Diese Ansicht eignet sich ideal für Aufgaben, bei denen Sie genau nachvollziehen müssen, wie Daten zwischen bestimmten Asset-Paaren übertragen werden. Das kann beispielsweise beim Prüfen einzelner Datenflüsse, beim Ermitteln von Abhängigkeiten zwischen Tabellen oder beim Exportieren detaillierter Herkunftsdatensätze für jede Verbindung der Fall sein.
Listenansicht für Herkunft auf Tabellenebene
In dieser Ansicht werden Beziehungen zwischen Tabellen als Ganzes dargestellt. Wählen Sie mit den bereitgestellten Filtern die benötigten Spalten aus.
Maximieren Sie die folgenden Abschnitte, um die Spalten zu sehen, die in den Listenansichten auf Tabellenebene verfügbar sind.
In der vereinfachten Listenansicht auf Tabellenebene verfügbare Spalten
- System: Das System, in dem sich die Datenressource befindet. Beispiele: BigQuery.
- Projekt: Die Google Cloud Projekt-ID, die das Daten-Asset enthält.
- Entität: Der Name des Datenassets. Beispiele enthalten einen Tabellennamen.
- FQN: Der vollständig qualifizierte Name (Fully Qualified Name, FQN) der ursprünglichen Quellentität oder ‑spalte.
- Richtung: Gibt an, ob das aufgeführte Asset im Lineage-Ablauf Upstream (Quelle) oder Downstream (Ziel) ist.
- Tiefe: Die Anzahl der Lineage-Schritte vom zentralen Asset, das analysiert wird.
Spalten in der detaillierten Listenansicht auf Tabellenebene
- Quellsystem: Das System, in dem sich die Quelldatenressource befindet. Beispiele: BigQuery.
- Quellprojekt: Die Google Cloud Projekt-ID, die das Quelldaten-Asset enthält.
- Quelle: Der Name des Quelldaten-Assets. Beispiele sind ein Tabellenname.
- Voll qualifizierter Name der Quelle: Der FQN der Quellentität.
- Zielsystem: Das System, in dem sich die Zieldatenressource befindet. Beispiele: BigQuery.
- Zielprojekt: Die Google Cloud Projekt-ID, die das Zieldaten-Asset enthält.
- Ziel: Der Name des Zieldaten-Assets. Beispiele sind ein Tabellenname.
- Voll qualifizierter Name des Ziels: Der FQDN der Zielentität.
- Richtung: Gibt an, ob das aufgeführte Asset im Lineage-Ablauf Upstream (Quelle) oder Downstream (Ziel) ist.
- Tiefe: Die Anzahl der Lineage-Schritte vom zentralen Asset, das analysiert wird.
Listenansicht der Herkunft auf Spaltenebene
In dieser Ansicht werden die Beziehungen zwischen einzelnen Spalten in den Quell- und Zieltabellen dargestellt. Wählen Sie mit den bereitgestellten Filtern die benötigten Spalten aus.
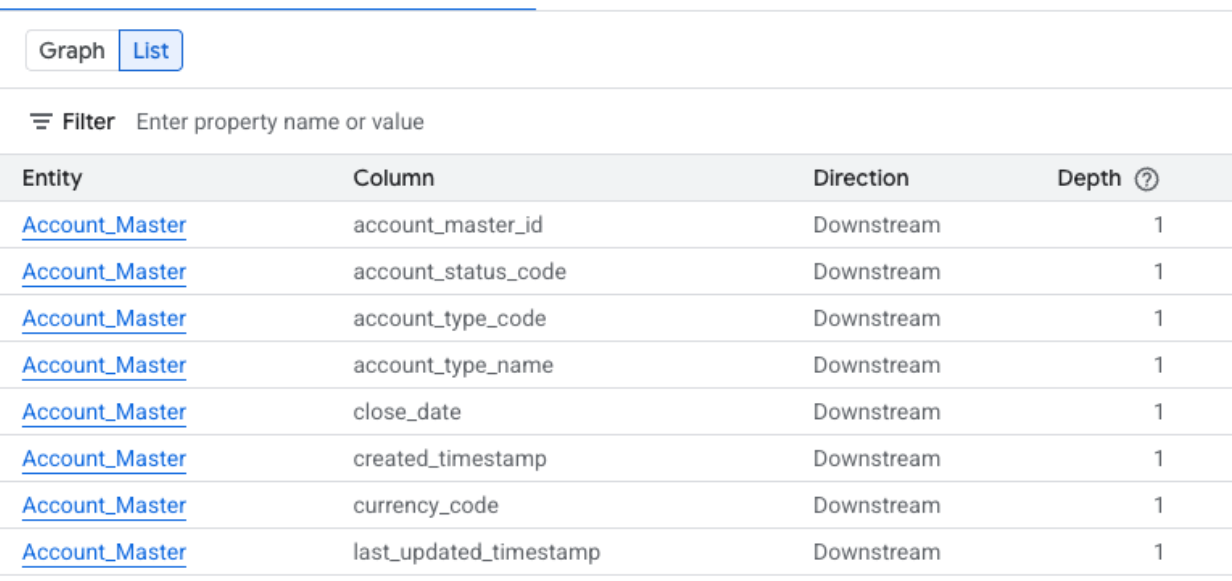
Maximieren Sie die folgenden Abschnitte, um die Spalten zu sehen, die in den Listenansichten auf Spaltenebene verfügbar sind.
Verfügbare Spalten in der vereinfachten Listenansicht auf Spaltenebene
- System: Das System, in dem sich die Datenressource befindet. Beispiele: BigQuery.
- Projekt: Die Google Cloud Projekt-ID, die das Daten-Asset enthält.
- Entität: Der Name des Datenassets. Beispiele enthalten einen Tabellennamen.
- Spalte: Die spezifische Spalte, die im Bereich Lineage Explorer innerhalb der Entität ausgewählt wurde.
- FQN: Der vollständig qualifizierte Name (Fully Qualified Name, FQN) der ursprünglichen Quellentität oder ‑spalte.
- Richtung: Gibt an, ob das aufgeführte Asset im Lineage-Ablauf Upstream (Quelle) oder Downstream (Ziel) ist.
- Tiefe: Die Anzahl der Lineage-Schritte vom zentralen Asset, das analysiert wird.
Spalten in der detaillierten Listenansicht auf Spaltenebene
- Quellsystem: Das System, in dem sich die Quelldatenressource befindet.
- Quellprojekt: Die Google Cloud Projekt-ID, die das Quelldaten-Asset enthält.
- Voll qualifizierter Name der Quelle: Der voll qualifizierte Name der Quellspalte.
- Zielsystem: Das System, in dem sich die Zieldatenressource befindet.
- Zielprojekt: Die Google Cloud Projekt-ID, die das Zieldaten-Asset enthält.
- Voll qualifizierter Name des Ziels: Der FQN der Zielspalte.
- Richtung: Gibt an, ob der Datenfluss Upstream oder Downstream ist.
- Abhängigkeitstypen: Beschreibt die Art der Beziehung zwischen den Spalten.
- Tiefe: Die Anzahl der Lineage-Schritte vom analysierten zentralen Asset.
Nächste Schritte
Datenherkunft für BigQuery-Tabellenkopien und Abfragejobs nachverfolgen
Informationen zur Verwendung der Datenherkunft mit Google Cloud -Systemen