Questo documento descrive come utilizzare l'esplorazione del Catalogo universale Dataplex per rilevare le anomalie in un set di dati sulle transazioni di vendita al dettaglio.
Il workbench di esplorazione dei dati, o Esplora, consente ai data analyst di eseguire query ed esplorare in modo interattivo set di dati di grandi dimensioni in tempo reale. Esplora ti aiuta a ottenere informazioni dai tuoi dati e ti consente di eseguire query sui dati archiviati in Cloud Storage e BigQuery. Esplora utilizza una piattaforma Spark serverless, quindi non devi gestire e scalare l'infrastruttura di base.
Obiettivi
Questo tutorial mostra come completare le seguenti attività:
- Utilizza il workbench Spark SQL di Explore per scrivere ed eseguire query Spark SQL.
- Utilizza un notebook JupyterLab per visualizzare i risultati.
- Pianifica l'esecuzione ricorrente del notebook per monitorare i dati alla ricerca di anomalie.
Costi
In questo documento utilizzi i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il Calcolatore prezzi.
Al termine delle attività descritte in questo documento, puoi evitare la fatturazione continua eliminando le risorse che hai creato. Per ulteriori informazioni, consulta la sezione Pulizia.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
-
Install the Google Cloud CLI.
-
If you're using an external identity provider (IdP), you must first sign in to the gcloud CLI with your federated identity.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
Create or select a Google Cloud project.
-
Create a Google Cloud project:
gcloud projects create PROJECT_ID
Replace
PROJECT_IDwith a name for the Google Cloud project you are creating. -
Select the Google Cloud project that you created:
gcloud config set project PROJECT_ID
Replace
PROJECT_IDwith your Google Cloud project name.
-
-
Make sure that billing is enabled for your Google Cloud project.
Prepara i dati per l'esplorazione
Scarica il file Parquet,
retail_offline_sales_march.Crea un bucket Cloud Storage denominato
offlinesales_curatedcome segue:- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Carica il file
offlinesales_march_parquetscaricato nelofflinesales_curatedbucket Cloud Storage che hai creato, seguendo i passaggi descritti in Caricare un oggetto da un file system.Crea un lake del Catalogo universale Dataplex e assegnagli il nome
operationsseguendo i passaggi descritti in Creare un lake.Nel lake
operations, aggiungi una zona e assegnale il nomeprocurementseguendo la procedura descritta in Aggiungere una zona.Nella zona
procurement, aggiungi il bucket Cloud Storageofflinesales_curatedche hai creato come asset seguendo i passaggi descritti in Aggiungi un asset.
Seleziona la tabella da esplorare
Nella Google Cloud console, vai alla pagina Esplora del Catalogo universale Dataplex.
Nel campo Lago, seleziona il lago
operations.Fai clic sul lake
operations.Vai alla zona
procuremente fai clic sulla tabella per esplorarne i metadati.Nella seguente immagine, la zona di approvvigionamento selezionata ha una tabella denominata
Offline, che contiene i metadati:orderid,product,quantityordered,unitprice,orderdateepurchaseaddress.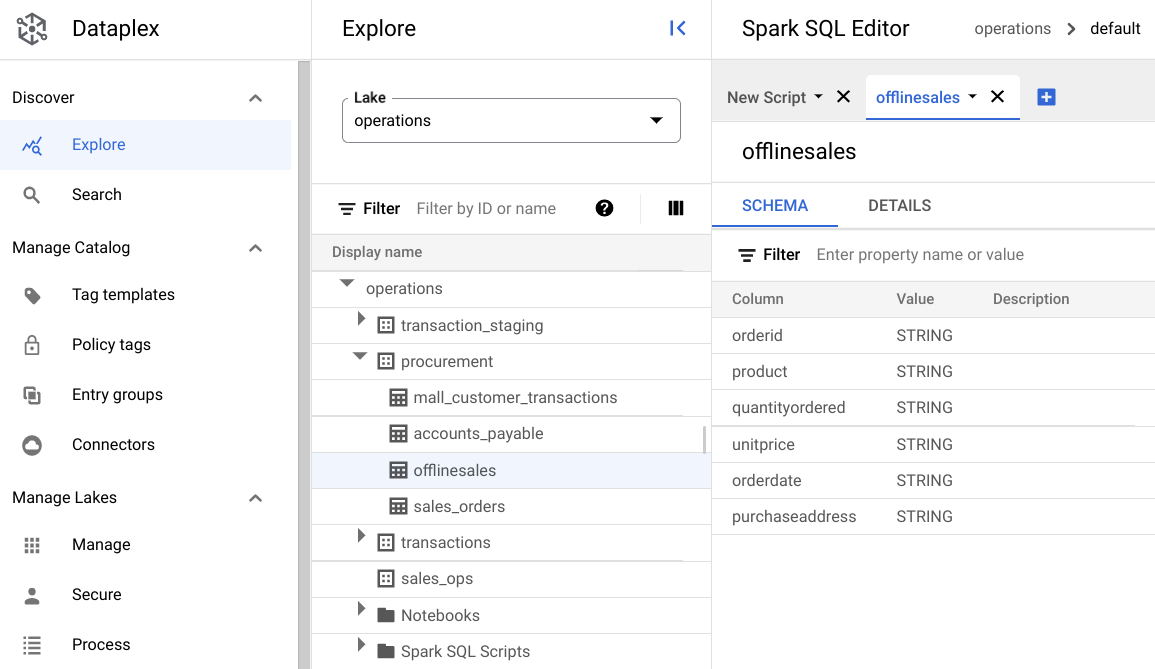
Nell'editor Spark SQL, fai clic su Aggiungi. Viene visualizzato uno script Spark SQL.
(Facoltativo) Apri lo script nella visualizzazione della scheda divisa per visualizzare i metadati e il nuovo script affiancati. Fai clic su Altro nella scheda del nuovo script e seleziona Dividi scheda a destra o Dividi scheda a sinistra.
esplora i dati
Un ambiente fornisce risorse di calcolo serverless per l'esecuzione di query e notebook Spark SQL all'interno di un lake. Prima di scrivere query Spark SQL, crea un ambiente in cui eseguire le query.
Esplora i dati utilizzando le seguenti query SparkSQL. Nell'editor SparkSQL, inserisci la query nel riquadro Nuovo script.
Esempio di 10 righe della tabella
Inserisci la seguente query:
select * from procurement.offlinesales where orderid != 'orderid' limit 10;Fai clic su Esegui.
Ottieni il numero totale di transazioni nel set di dati
Inserisci la seguente query:
select count(*) from procurement.offlinesales where orderid!='orderid';Fai clic su Esegui.
Trova il numero di diversi tipi di prodotti nel set di dati
Inserisci la seguente query:
select count(distinct product) from procurement.offlinesales where orderid!='orderid';Fai clic su Esegui.
Trovare i prodotti con un valore di transazione elevato
Fai un'idea di quali prodotti hanno un valore di transazione elevato suddividendo le vendite per tipo di prodotto e prezzo di vendita medio.
Inserisci la seguente query:
select product,avg(quantityordered * unitprice) as avg_sales_amount from procurement.offlinesales where orderid!='orderid' group by product order by avg_sales_amount desc;Fai clic su Esegui.
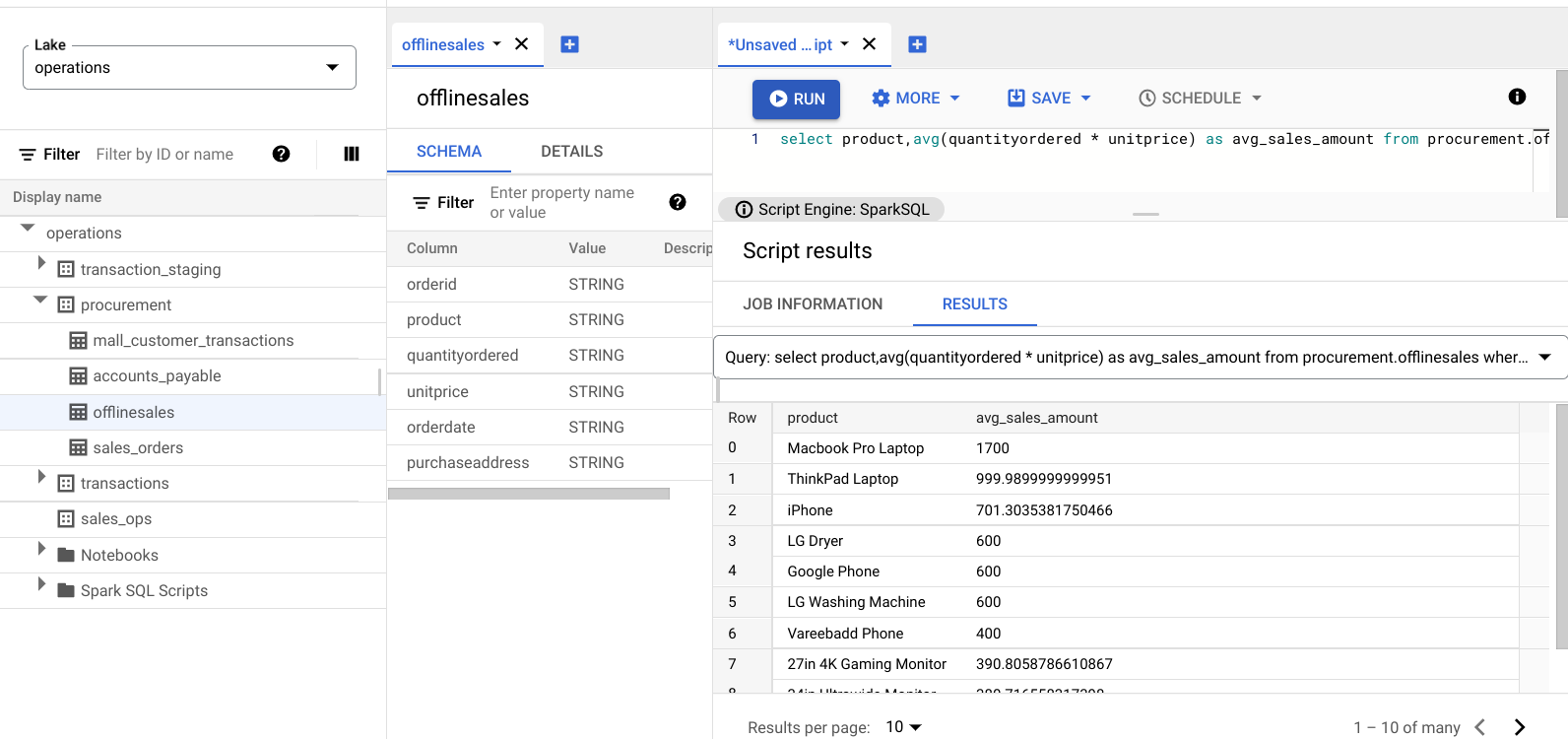
L'immagine seguente mostra un riquadro Results che utilizza una colonna denominata
product per identificare gli articoli di vendita con valori di transazione elevati, mostrati nella
colonna avg_sales_amount.
Rilevare le anomalie utilizzando il coefficiente di variazione
L'ultima query ha mostrato che i laptop hanno un importo medio di transazione elevato. La seguente query mostra come rilevare le transazioni relative ai laptop che non sono anomale nel set di dati.
La seguente query utilizza la metrica "coefficiente di variazione",rsd_value per trovare transazioni non insolite, in cui la dispersione dei valori è bassa rispetto al valore medio. Un coefficiente di variazione più basso indica un numero minore di anomalie.
Inserisci la seguente query:
WITH stats AS ( SELECT product, AVG(quantityordered * unitprice) AS avg_value, STDDEV(quantityordered * unitprice) / AVG(quantityordered * unitprice) AS rsd_value FROM procurement.offlinesales GROUP BY product) SELECT orderid, orderdate, product, (quantityordered * unitprice) as sales_amount, ABS(1 - (quantityordered * unitprice)/ avg_value) AS distance_from_avg FROM procurement.offlinesales INNER JOIN stats USING (product) WHERE rsd_value <= 0.2 ORDER BY distance_from_avg DESC LIMIT 10Fai clic su Esegui.
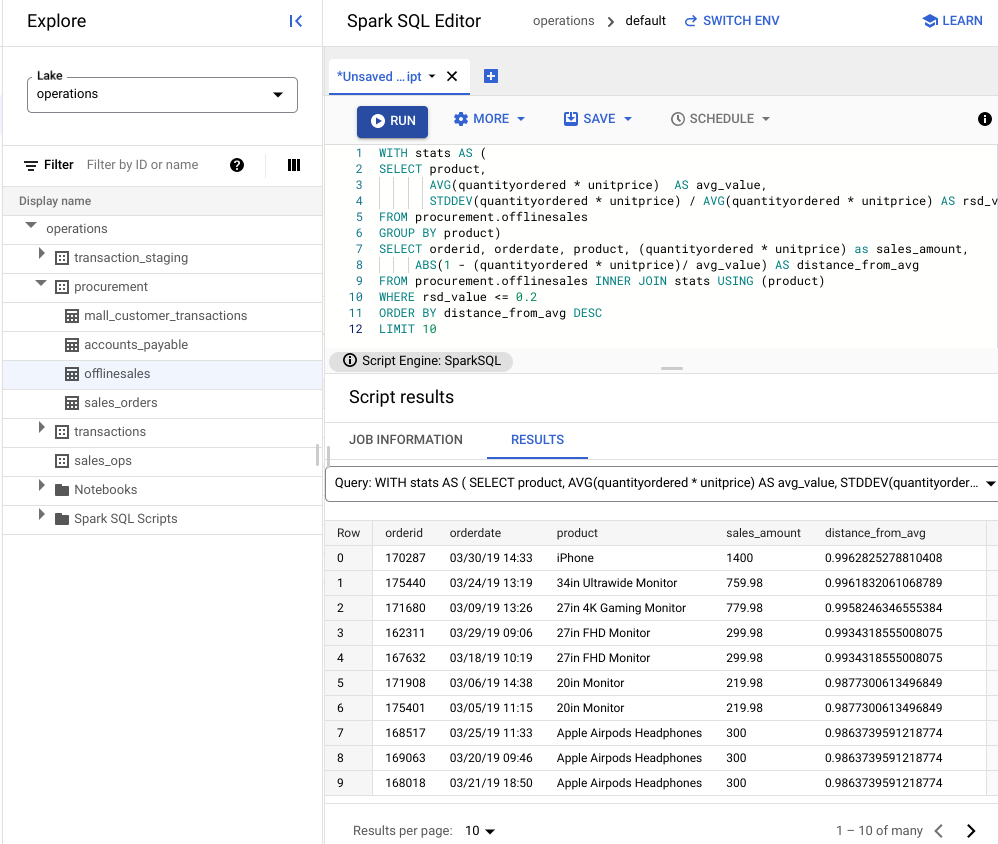
Visualizza i risultati dello script.
Nell'immagine seguente, un riquadro dei risultati utilizza una colonna denominata prodotto per identificare gli articoli di vendita con valori di transazione compresi nel coefficiente di variazione di 0,2.
Visualizzare le anomalie utilizzando un blocco note JupyterLab
Crea un modello di ML per rilevare e visualizzare le anomalie su larga scala.
Apri il notebook in una scheda separata e attendi che venga caricato. La sessione in cui hai eseguito le query Spark SQL continua.
Importa i pacchetti necessari e connettiti alla tabella esterna BigQuery contenente i dati sulle transazioni. Esegui questo codice:
from google.cloud import bigquery from google.api_core.client_options import ClientOptions import os import warnings warnings.filterwarnings('ignore') import pandas as pd project = os.environ['GOOGLE_CLOUD_PROJECT'] options = ClientOptions(quota_project_id=project) client = bigquery.Client(client_options=options) client = bigquery.Client() #Load data into DataFrame sql = '''select * from procurement.offlinesales limit 100;''' df = client.query(sql).to_dataframe()Esegui l'algoritmo foresta di isolamento per rilevare le anomalie nel set di dati:
to_model_columns = df.columns[2:4] from sklearn.ensemble import IsolationForest clf=IsolationForest(n_estimators=100, max_samples='auto', contamination=float(.12), \ max_features=1.0, bootstrap=False, n_jobs=-1, random_state=42, verbose=0) clf.fit(df[to_model_columns]) pred = clf.predict(df[to_model_columns]) df['anomaly']=pred outliers=df.loc[df['anomaly']==-1] outlier_index=list(outliers.index) #print(outlier_index) #Find the number of anomalies and normal points here points classified -1 are anomalous print(df['anomaly'].value_counts())Grafica le anomalie previste utilizzando una visualizzazione Matplotlib:
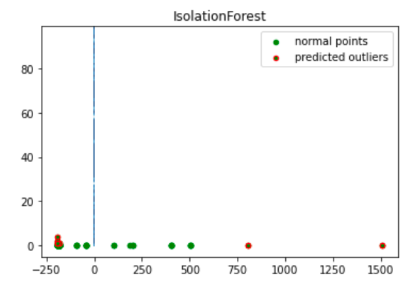
import numpy as np from sklearn.decomposition import PCA pca = PCA(2) pca.fit(df[to_model_columns]) res=pd.DataFrame(pca.transform(df[to_model_columns])) Z = np.array(res) plt.title("IsolationForest") plt.contourf( Z, cmap=plt.cm.Blues_r) b1 = plt.scatter(res[0], res[1], c='green', s=20,label="normal points") b1 =plt.scatter(res.iloc[outlier_index,0],res.iloc[outlier_index,1], c='green',s=20, edgecolor="red",label="predicted outliers") plt.legend(loc="upper right") plt.show()
Questa immagine mostra i dati sulle transazioni con le anomalie evidenziate in rosso.
Pianifica il blocco note
Esplora ti consente di pianificare l'esecuzione periodica di un notebook. Segui i passaggi per pianificare il Jupyter Notebook che hai creato.
Il Catalogo universale Dataplex crea un'attività di pianificazione per eseguire periodicamente il tuo notebook. Per monitorare l'avanzamento dell'attività, fai clic su Visualizza pianificazioni.
Condividere o esportare il notebook
Esplora ti consente di condividere un notebook con altri utenti della tua organizzazione utilizzando le autorizzazioni IAM.
Esamina i ruoli. Concedi o revoca agli utenti i ruoli Visualizzatore del Catalogo universale Dataplex
(roles/dataplex.viewer), Editor del Catalogo universale Dataplex
(roles/dataplex.editor) e Amministratore del Catalogo universale Dataplex
(roles/dataplex.admin) per questo notebook. Dopo aver condiviso un
notebook, gli utenti con i ruoli di visualizzatore o editor a livello di lake possono accedere al lake e lavorare sul notebook condiviso.
Per condividere o esportare un taccuino, consulta Condividere un taccuino o Esportare un taccuino.
Esegui la pulizia
Per evitare che al tuo Account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Elimina il progetto
Delete a Google Cloud project:
gcloud projects delete PROJECT_ID
Elimina singole risorse
-
Elimina il bucket:
gcloud storage buckets delete BUCKET_NAME
-
Elimina l'istanza:
gcloud compute instances delete INSTANCE_NAME
Passaggi successivi
- Scopri di più su Dataplex Universal Catalog Explore.
- Pianifica script e blocchi note.