Le attività di qualità dei dati di Dataplex Universal Catalog consentono di definire ed eseguire controlli di qualità dei dati nelle tabelle di BigQuery e Cloud Storage. Le attività di qualità dei dati di Dataplex Universal Catalog consentono anche di applicare controlli regolari dei dati negli ambienti BigQuery.
Quando creare attività di qualità dei dati di Dataplex Universal Catalog
Le attività di qualità dei dati di Dataplex Universal Catalog possono aiutarti a:
- Convalidare i dati nell'ambito di una pipeline di produzione dei dati.
- Monitora regolarmente la qualità dei set di dati in base alle tue aspettative.
- Crea report sulla qualità dei dati per i requisiti normativi.
Vantaggi
- Specifiche personalizzabili. Puoi utilizzare la sintassi YAML altamente flessibile per dichiarare le regole di qualità dei dati.
- Implementazione serverless. Dataplex Universal Catalog non richiede alcuna configurazione dell'infrastruttura.
- Copia zero e pushdown automatico. I controlli YAML vengono convertiti in SQL e trasferiti a BigQuery, senza copiare i dati.
- Controlli della qualità dei dati pianificabili. Puoi pianificare i controlli di qualità dei dati tramite lo scheduler serverless in Dataplex Universal Catalog oppure utilizzare l'API Dataplex tramite scheduler esterni come Cloud Composer per l'integrazione della pipeline.
- Esperienza gestita. Dataplex Universal Catalog utilizza un motore di qualità dei dati open source, CloudDQ, per eseguire i controlli di qualità dei dati. Tuttavia, Dataplex Universal Catalog offre un'esperienza gestita senza problemi per eseguire i controlli di qualità dei dati.
Come funzionano le attività relative alla qualità dei dati
Il seguente diagramma mostra come funzionano le attività di qualità dei dati di Dataplex Universal Catalog:
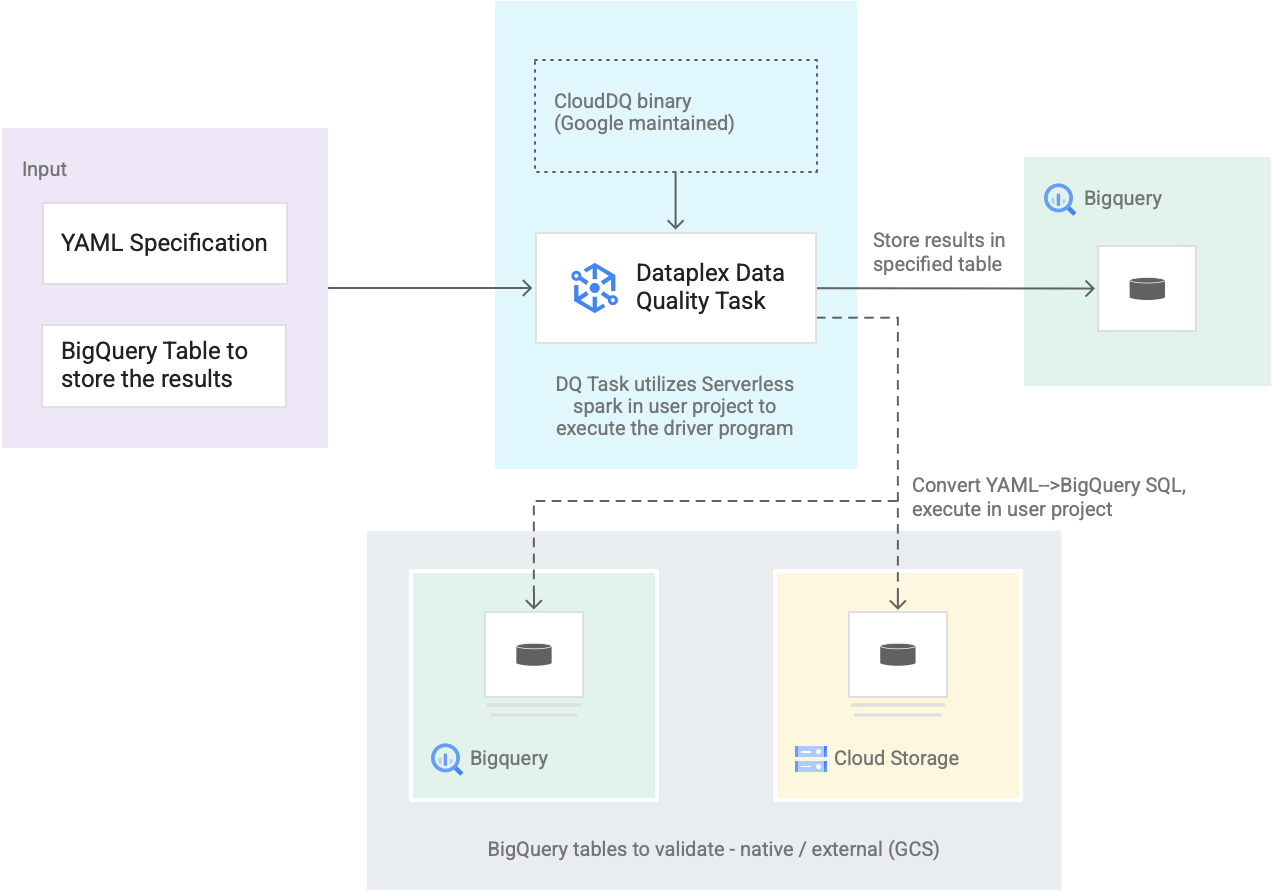
- Input degli utenti
- Specifica YAML: un insieme di uno o più file YAML che definiscono regole di qualità dei dati in base alla sintassi della specifica. Archivia i file YAML in un bucket Cloud Storage nel tuo progetto. Gli utenti possono eseguire più regole contemporaneamente e queste regole possono essere applicate a diverse tabelle BigQuery, incluse quelle di diversi set di dati o Google Cloud progetti. La specifica supporta le esecuzioni incrementali per la convalida dei nuovi dati. Per creare una specifica YAML, vedi Creare un file di specifiche.
- Tabella dei risultati BigQuery: una tabella specificata dall'utente in cui vengono memorizzati i risultati della convalida della qualità dei dati. Il progetto Google Cloud in cui risiede questa tabella può essere diverso da quello in cui viene utilizzato il task di qualità dei dati di Dataplex Universal Catalog.
- Tabelle da convalidare
- All'interno della specifica YAML, devi specificare le tabelle che vuoi convalidare per quali regole, noto anche come associazione di regole. Le tabelle possono essere tabelle native BigQuery o tabelle esterne BigQuery in Cloud Storage. La specifica YAML consente di specificare le tabelle all'interno o all'esterno di una zona Dataplex Universal Catalog.
- Le tabelle BigQuery e Cloud Storage convalidate in una singola esecuzione possono appartenere a progetti diversi.
- Attività di qualità dei dati di Dataplex Universal Catalog: un'attività di qualità dei dati di Dataplex Universal Catalog è configurata con un binario PySpark CloudDQ predefinito e gestito e accetta le specifiche YAML e la tabella dei risultati BigQuery come input. Analogamente ad altre attività di Dataplex Universal Catalog, l'attività di qualità dei dati di Dataplex Universal Catalog viene eseguita in un ambiente Spark serverless, converte la specifica YAML in query BigQuery e poi esegue queste query sulle tabelle definite nel file di specifiche.
Prezzi
Quando esegui attività di qualità dei dati di Dataplex Universal Catalog, ti vengono addebitati i costi per l'utilizzo di BigQuery e Serverless per Apache Spark (batch).
L'attività di qualità dei dati di Dataplex Universal Catalog converte il file di specifiche in query BigQuery e le esegue nel progetto utente. Vedi Prezzi di BigQuery.
Dataplex Universal Catalog utilizza Spark per eseguire il programma driver open source CloudDQ predefinito e gestito da Google per convertire le specifiche dell'utente in query BigQuery. Consulta i prezzi di Serverless per Apache Spark.
Non sono previsti costi per l'utilizzo di Dataplex Universal Catalog per organizzare i dati o per l'utilizzo dello scheduler serverless in Dataplex Universal Catalog per pianificare i controlli della qualità dei dati. Consulta Prezzi del Catalogo universale Dataplex.