이 페이지에서는 Dataflow SQL을 사용하여 데이터를 쿼리하고 쿼리 결과를 쓰는 방법을 설명합니다.
Dataflow SQL은 다음 소스를 쿼리할 수 있습니다.
- Pub/Sub 주제의 데이터 스트리밍
- Cloud Storage 파일 세트의 스트리밍 및 일괄 데이터
- BigQuery 테이블의 일괄 데이터
Dataflow SQL은 쿼리 결과를 다음 대상에 쓸 수 있습니다.
Pub/Sub
Pub/Sub 주제 쿼리
Dataflow SQL로 Pub/Sub 주제를 쿼리하려면 다음 단계를 완료합니다.
Pub/Sub 주제에 스키마를 할당합니다.
Dataflow SQL 쿼리에서 Pub/Sub 주제를 사용합니다.
Pub/Sub 주제 추가
BigQuery 웹 UI를 사용하여 Pub/Sub 주제를 Dataflow 소스로 추가할 수 있습니다.
Google Cloud Console에서 Dataflow SQL을 사용할 수 있는 BigQuery 페이지로 이동합니다.
탐색 패널에서 데이터 추가 드롭다운 목록을 클릭하고 Cloud Dataflow 소스를 선택합니다.

Cloud Dataflow 소스 추가 패널에서 Cloud Pub/Sub 주제를 선택하고 주제를 검색합니다.
다음 스크린샷에는
transactionsPub/Sub 주제를 검색하는 방법이 나와 있습니다.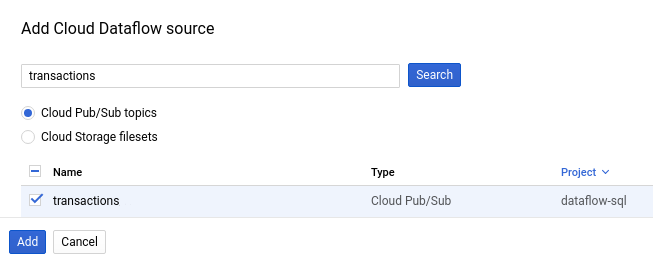
추가를 클릭합니다.
Pub/Sub 주제를 Dataflow 소스로 추가하면 탐색 메뉴의 리소스 섹션에 Pub/Sub 주제가 나타납니다.
주제를 찾으려면 Cloud Dataflow 소스 > Cloud Pub/Sub 주제를 펼칩니다.
Pub/Sub 주제 스키마 할당
Pub/Sub 주제 스키마는 다음 필드로 구성되어 있습니다.
event_timestamp필드Pub/Sub 이벤트 타임스탬프는 메일이 게시되는 시점을 식별합니다. 타임스탬프는 Pub/Sub 메시지에 자동으로 추가됩니다.
Pub/Sub 메시지의 각 키-값 쌍에 대한 필드
예를 들어
{"k1":"v1", "k2":"v2"}메시지의 스키마에는k1과k2라는 두 개의STRING필드가 있습니다.
Cloud Console 또는 Google Cloud CLI를 사용하여 Pub/Sub 주제에 스키마를 할당할 수 있습니다.
콘솔
Pub/Sub 주제에 스키마를 할당하려면 다음 단계를 완료합니다.
리소스 패널에서 주제를 선택합니다.
스키마 탭에서 스키마 수정을 클릭하여 스키마 측면 패널을 엽니다. 그러면 스키마 필드가 표시됩니다.
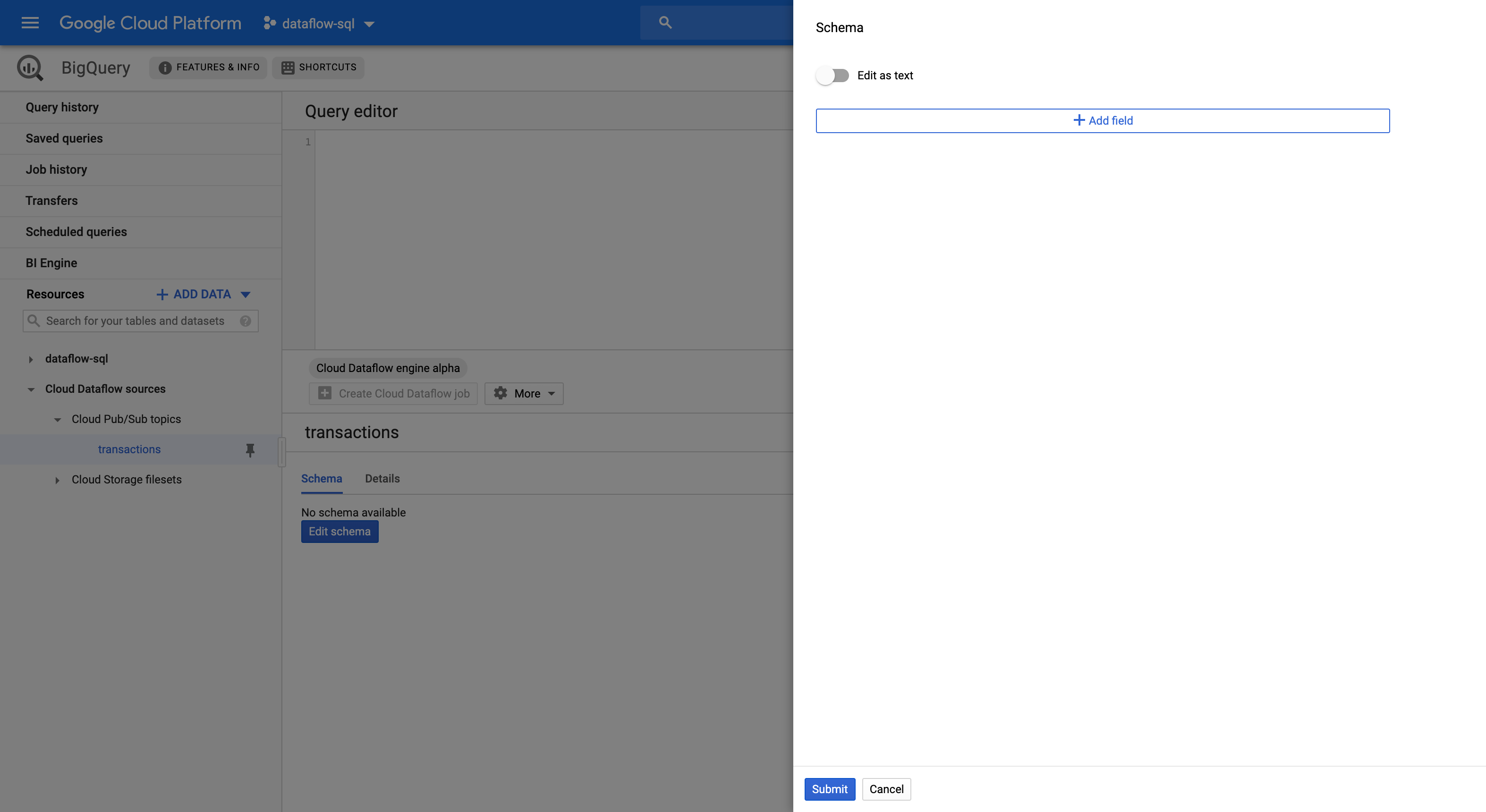
필드 추가를 클릭하여 필드를 스키마에 추가하거나 텍스트로 편집 버튼을 전환하여 전체 스키마 텍스트를 복사하여 붙여넣습니다.
예를 들어 다음은 판매 거래가 포함된 Pub/Sub 주제의 스키마 텍스트입니다.
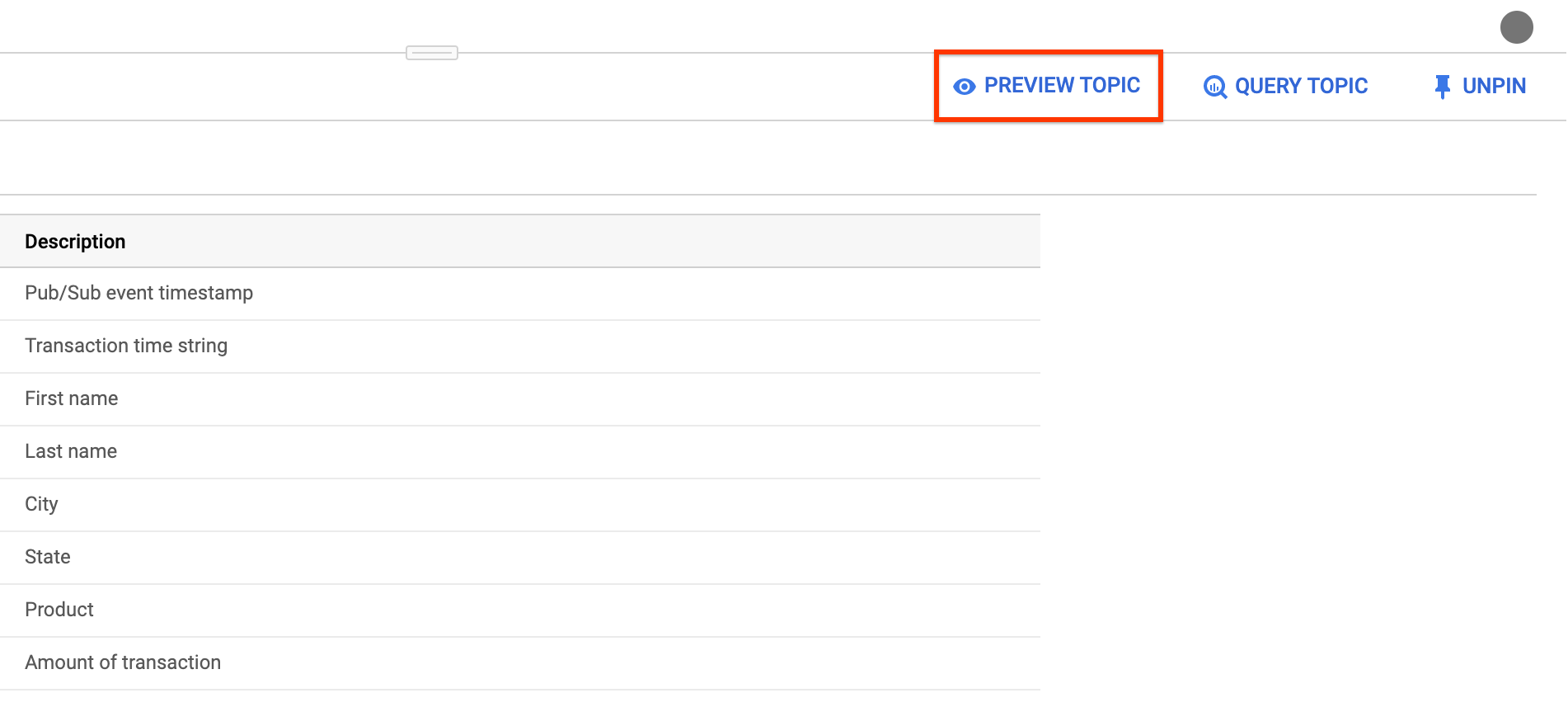
[ { "description": "Pub/Sub event timestamp", "name": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "name": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "name": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "name": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "name": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "name": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "name": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "name": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]제출을 클릭합니다.
(선택사항) 주제 미리보기을 클릭하여 메시지 콘텐츠를 검토하고 정의한 스키마와 일치하는지 확인합니다.
gcloud
Pub/Sub 주제에 스키마를 할당하려면 다음 단계를 완료합니다.
스키마 텍스트가 포함된 JSON 파일을 만듭니다.
예를 들어 다음은 판매 거래가 포함된 Pub/Sub 주제의 스키마 텍스트입니다.
[ { "description": "Pub/Sub event timestamp", "column": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "column": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "column": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "column": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "column": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "column": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "column": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "column": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]gcloud data-catalog entries명령어를 사용하여 Pub/Sub 주제에 스키마를 할당합니다.gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`' \ --schema-from-file=FILE_PATH
다음을 바꿉니다.
PROJECT_ID: 프로젝트 IDTOPIC_NAME: Pub/Sub 주제 이름FILE_PATH: 스키마 텍스트가 있는 JSON 파일의 경로
(선택 사항) 다음 명령어를 실행하여 Pub/Sub 주제에 스키마가 할당되었는지 확인합니다.
gcloud data-catalog entries lookup \ 'pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`'
Pub/Sub 주제 사용
Dataflow SQL 쿼리에서 Pub/Sub를 참조하려면 다음 식별자를 사용합니다.
pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`
다음을 바꿉니다.
PROJECT_ID: 프로젝트 IDTOPIC_NAME: Pub/Sub 주제 이름
예를 들어 다음 쿼리는 dataflow-sql 프로젝트의 Dataflow 주제 daily.transactions에서 선택합니다.
SELECT *
FROM pubsub.topic.`dataflow-sql`.`daily.transactions`
Pub/Sub 주제에 쓰기
Cloud Console 또는 Google Cloud CLI를 사용하여 쿼리 결과를 Pub/Sub 주제에 쓸 수 있습니다.
콘솔
쿼리 결과를 Pub/Sub 주제에 쓰려면 Dataflow SQL을 사용하여 쿼리를 실행합니다.
Cloud Console에서 Dataflow SQL을 사용할 수 있는 BigQuery 페이지로 이동합니다.
쿼리 편집기에 Dataflow SQL 쿼리를 입력합니다.
Cloud Dataflow 작업 만들기를 클릭하여 작업 옵션이 포함된 패널을 엽니다.
패널의 대상 섹션에서 출력 유형 > Cloud Pub/Sub 주제를 선택합니다.
Cloud Pub/Sub 주제 선택을 클릭하고 주제를 선택합니다.
만들기를 클릭합니다.
gcloud
Pub/Sub 주제에 쿼리 결과를 쓰려면 gcloud dataflow sql query 명령어의 --pubsub-topic 플래그를 사용합니다.
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --pubsub-project=PROJECT_ID \ --pubsub-topic=TOPIC_NAME \ 'QUERY'
다음을 바꿉니다.
JOB_NAME: 선택한 작업 이름REGION: 리전 엔드포인트(예:us-west1)PROJECT_ID: 프로젝트 IDTOPIC_NAME: Pub/Sub 주제 이름QUERY: Dataflow SQL 쿼리
대상 Pub/Sub 주제의 스키마가 쿼리 결과의 스키마와 일치해야 합니다. 대상 Pub/Sub 주제에 스키마가 없으면 쿼리 결과와 일치하는 스키마가 자동으로 할당됩니다.
Cloud Storage
Cloud Storage 파일 세트 쿼리
Dataflow SQL로 Cloud Storage 파일 세트를 쿼리하려면 다음 단계를 완료합니다.
Dataflow SQL용 데이터 카탈로그 파일 세트 만들기
Dataflow SQL 쿼리에서 Cloud Storage 파일 세트를 사용합니다.
Cloud Storage 파일 세트 만들기
Cloud Storage 파일 세트를 만들려면 항목 그룹 및 파일 세트 만들기를 참조하세요.
Cloud Storage 파일 세트에는 스키마와, 헤더 행이 없는 CSV 파일만 있어야 합니다.
Cloud Storage 파일 세트 추가
Dataflow SQL을 사용하여 Cloud Storage 파일 세트를 Dataflow 소스로 추가할 수 있습니다.
Cloud Console에서 Dataflow SQL을 사용할 수 있는 BigQuery 페이지로 이동합니다.
탐색 패널에서 데이터 추가 드롭다운 목록을 클릭하고 Cloud Dataflow 소스를 선택합니다.
Cloud Dataflow 소스 추가 패널에서 Cloud Storage 파일 세트를 선택하고 주제를 검색합니다.
추가를 클릭합니다.
Cloud Storage 파일 세트를 Dataflow 소스로 추가하면 Cloud Storage 파일 세트가 탐색 메뉴의 리소스 섹션에 표시됩니다.
파일 세트를 찾으려면 Cloud Dataflow 소스 > Cloud Storage 주제를 펼칩니다.
Cloud Storage 파일 세트 사용
Dataflow SQL 쿼리에서 Cloud Storage 테이블을 참조하려면 다음 식별자를 사용합니다.
datacatalog.entry.`PROJECT_ID`.REGION.`ENTRY_GROUP`.`FILESET_NAME`
다음을 바꿉니다.
PROJECT_ID: 프로젝트 IDREGION: 리전 엔드포인트(예:us-west1)ENTRY_GROUP: Cloud Storage 파일 세트의 항목 그룹FILESET_NAME: Cloud Storage 파일 세트의 이름
예를 들어 다음 쿼리는 dataflow-sql 프로젝트 및 항목 그룹 my-fileset-group의 Cloud Storage 파일 세트 daily.registrations에서 선택합니다.
SELECT *
FROM datacatalog.entry.`dataflow-sql`.`us-central1`.`my-fileset-group`.`daily.registrations`
BigQuery
BigQuery 테이블 쿼리
Dataflow SQL로 BigQuery 테이블을 쿼리하려면 다음 단계를 완료합니다.
Dataflow SQL용 BigQuery 테이블을 만듭니다.
Dataflow SQL 쿼리에서 BigQuery 테이블을 사용합니다.
BigQuery 테이블을 Dataflow 소스로 추가할 필요가 없습니다.
BigQuery 테이블 만들기
Dataflow SQL용 BigQuery 테이블을 만들려면 스키마 정의가 있는 빈 테이블 만들기를 참조하세요.
쿼리에서 BigQuery 테이블 사용
Dataflow SQL 쿼리에서 BigQuery 테이블을 참조하려면 다음 식별자를 사용합니다.
bigquery.table.`PROJECT_ID`.`DATASET_NAME`.`TABLE_NAME`
식별자는 Dataflow SQL 언어 구조를 따라야 합니다. 문자, 숫자, 밑줄이 아닌 문자로 식별자를 묶으려면 백틱을 사용하세요.
예를 들어 다음 쿼리는 dataflow_sql_dataset 데이터세트와 dataflow-sql 프로젝트의 us_state_salesregions BigQuery 테이블에서 선택합니다.
SELECT *
FROM bigquery.table.`dataflow-sql`.dataflow_sql_dataset.us_state_salesregions
BigQuery 테이블에 쓰기
Cloud Console 또는 Google Cloud CLI를 사용하여 쿼리 결과를 Dataflow SQL 쿼리에 쓸 수 있습니다.
콘솔
쿼리 결과를 Dataflow SQL 쿼리에 쓰려면 Dataflow SQL을 사용하여 쿼리를 실행합니다.
Cloud Console에서 Dataflow SQL을 사용할 수 있는 BigQuery 페이지로 이동합니다.
쿼리 편집기에 Dataflow SQL 쿼리를 입력합니다.
Cloud Dataflow 작업 만들기를 클릭하여 작업 옵션이 포함된 패널을 엽니다.
패널의 대상 섹션에서 출력 유형 > BigQuery를 선택합니다.
데이터세트 ID를 클릭하고 로드된 데이터세트 또는 새 데이터세트 만들기를 선택합니다.
테이블 이름 입력란에 대상 테이블을 입력합니다.
(선택 사항) BigQuery 테이블에 데이터를 로드하는 방법을 선택합니다.
- 비어 있으면 쓰기: (기본값) 테이블이 비어 있을 때만 데이터를 씁니다.
- 테이블에 추가: 데이터를 테이블 끝에 추가합니다.
- 테이블 덮어쓰기: 새 데이터를 쓰기 전에 테이블의 기존 데이터를 모두 지웁니다.
만들기를 클릭합니다.
gcloud
BigQuery 테이블에 쿼리 결과를 쓰려면 gcloud dataflow sql query 명령어의 --bigquery-table 플래그를 사용합니다.
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ 'QUERY'
다음을 바꿉니다.
JOB_NAME: 선택한 작업 이름REGION: 리전 엔드포인트(예:us-west1)DATASET_NAME: BigQuery 데이터 세트 이름TABLE_NAME: BigQuery 테이블 이름QUERY: Dataflow SQL 쿼리
BigQuery 테이블에 데이터를 쓸 방법을 선택하려면 --bigquery-write-disposition 플래그 및 다음 값을 사용할 수 있습니다.
write-empty: (기본값) 테이블이 비어 있을 때만 데이터를 씁니다.write-append: 데이터를 테이블 끝에 추가합니다.write-truncate: 새 데이터를 쓰기 전에 테이블의 기존 데이터를 모두 지웁니다.
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ --bigquery-write-disposition=WRITE_MODE 'QUERY'
WRITE_MODE를 BigQuery 쓰기 배열 값으로 바꿉니다.
대상 BigQuery 테이블의 스키마가 쿼리 결과의 스키마와 일치해야 합니다. 대상 BigQuery 테이블에 스키마가 없으면 쿼리 결과와 일치하는 스키마가 자동으로 할당됩니다.