Cette page explique comment interroger des données et écrire des résultats de requête avec Dataflow SQL.
Dataflow SQL permet d'interroger les sources suivantes :
- Données en streaming des sujets Pub/Sub
- Données en streaming et par lot des ensembles de fichiers Cloud Storage
- Données par lots provenant de tables BigQuery
Dataflow SQL permet d'écrire des résultats de requête sur les destinations suivantes :
Pub/Sub
Interroger des sujets Pub/Sub
Pour interroger un sujet Pub/Sub avec Dataflow SQL, procédez comme suit :
Ajoutez le sujet Pub/Sub en tant que source Dataflow.
Attribuez un schéma au sujet Pub/Sub.
Utilisez le sujet Pub/Sub dans une requête Dataflow SQL.
Ajouter un sujet Pub/Sub
Vous pouvez ajouter un sujet Pub/Sub en tant que source Dataflow à l'aide de l'UI Web de BigQuery.
Dans Google Cloud Console, accédez à la page BigQuery, où vous pouvez utiliser Dataflow SQL.
Dans le panneau de navigation, cliquez sur Add Data (Ajouter des données) dans la liste déroulante, puis sélectionnez Cloud Dataflow sources (Sources Cloud Dataflow).
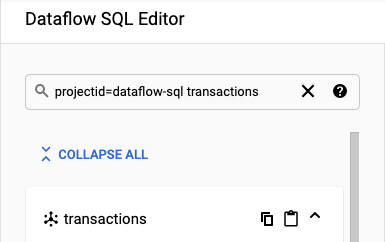
Dans le panneau Add Cloud Dataflow source (Ajouter une source Cloud Dataflow), sélectionnez Cloud Pub/Sub topics (Sujets Cloud Pub/Sub) et recherchez un sujet.
La capture d'écran suivante montre une recherche de sujet Pub/Sub
transactions: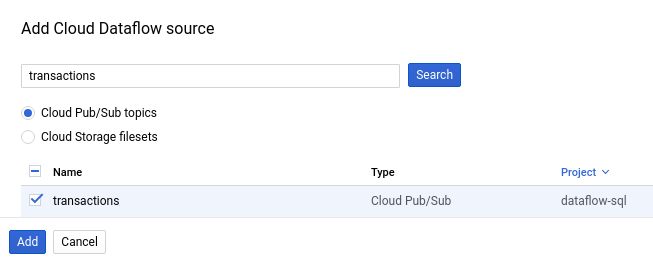
Cliquez sur Ajouter.
Après avoir ajouté le sujet Pub/Sub en tant que source Dataflow, le sujet Pub/Sub apparaît dans la section Ressources du menu de navigation.
Pour afficher le sujet, développez Sources Cloud Dataflow > Sujets Cloud Pub/Sub.
Attribuer un schéma de sujet Pub/Sub
Les schémas de sujet Pub/Sub se constituent des champs suivants :
Un champ
event_timestamp.Les horodatages d'événement Pub/Sub identifient le moment où les messages sont publiés. Les horodatages sont automatiquement ajoutés aux messages Pub/Sub.
Un champ pour chaque paire clé-valeur dans les messages Pub/Sub.
Par exemple, le schéma du message
{"k1":"v1", "k2":"v2"}comprend deux champsSTRING, nommésk1etk2.
Vous pouvez attribuer un schéma à un sujet Pub/Sub à l'aide de Cloud Console ou de la CLI Google Cloud.
Console
Pour attribuer un schéma à un sujet Pub/Sub, procédez comme suit :
Sélectionnez le sujet dans le panneau Resources (Ressources).
Dans l'onglet Schema (Schéma), cliquez sur Edit schema (Modifier le schéma) pour ouvrir le panneau latéral Schema (Schéma) qui montre les champs du schéma.
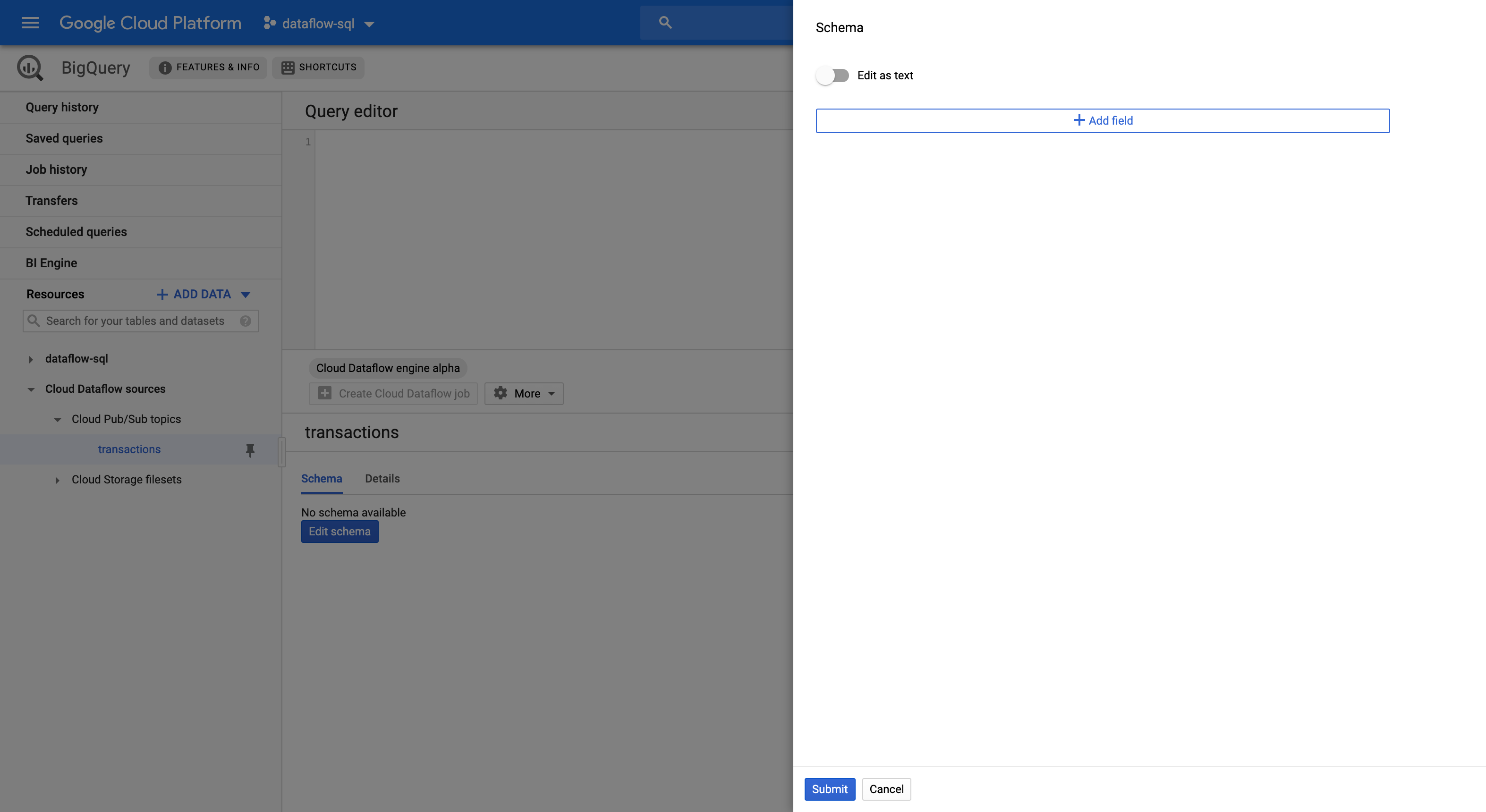
Cliquez sur Add field (Ajouter un champ) pour ajouter un champ au schéma, ou cliquez sur le bouton Edit as text (Modifier sous forme de texte) pour copier et coller l'intégralité du texte du schéma.
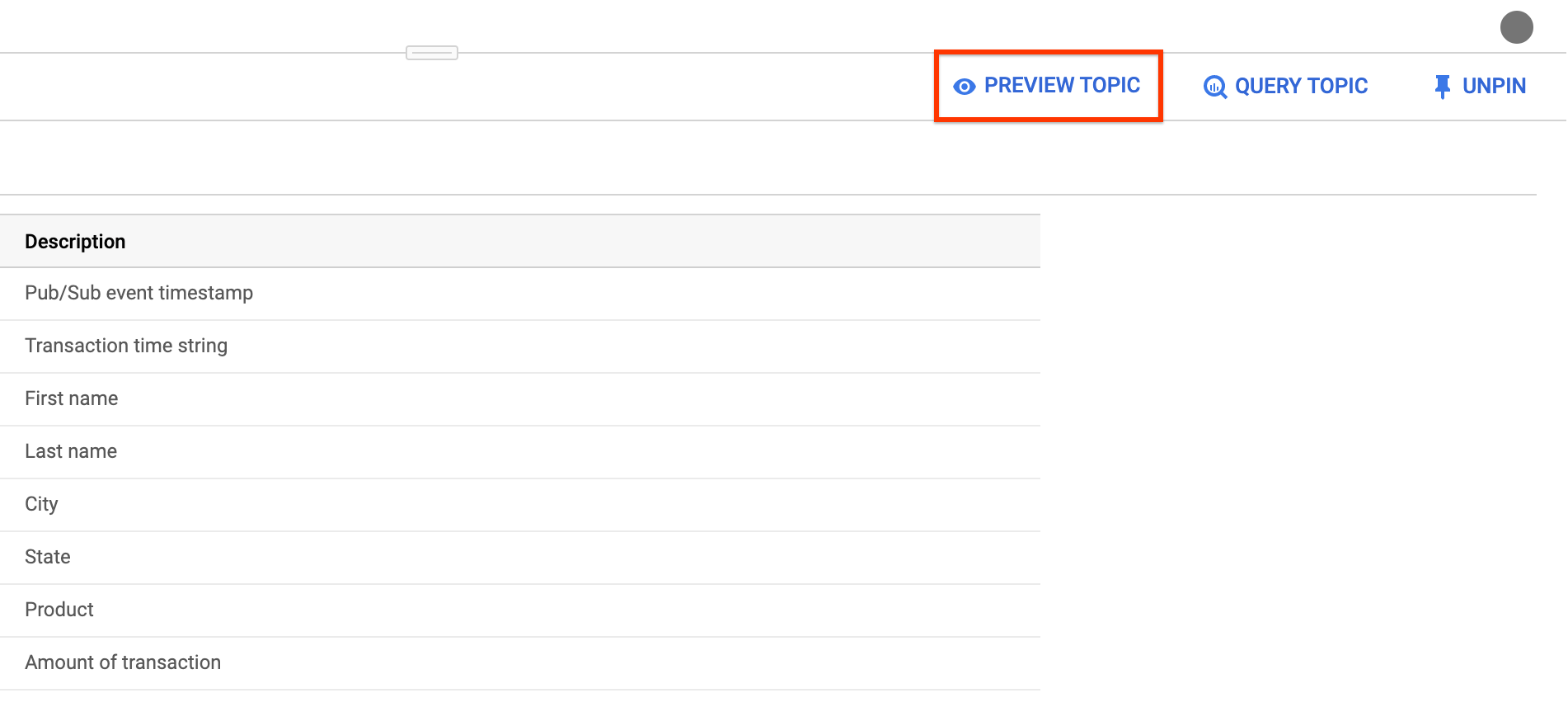
Par exemple, voici le texte du schéma d'un sujet Pub/Sub avec des transactions de vente :
[ { "description": "Pub/Sub event timestamp", "name": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "name": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "name": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "name": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "name": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "name": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "name": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "name": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]Cliquez sur Envoyer.
(Facultatif) Cliquez sur Preview topic (Aperçu du sujet) pour examiner le contenu de vos messages et vérifier qu'ils correspondent au schéma que vous avez défini.
gcloud
Pour attribuer un schéma à un sujet Pub/Sub, procédez comme suit :
Créez un fichier JSON avec le texte du schéma.
Par exemple, voici le texte du schéma d'un sujet Pub/Sub avec des transactions de vente :
[ { "description": "Pub/Sub event timestamp", "column": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "column": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "column": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "column": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "column": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "column": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "column": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "column": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]Attribuez le schéma au sujet Pub/Sub à l'aide de la commande
gcloud data-catalog entries:gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`' \ --schema-from-file=FILE_PATH
Remplacez l'élément suivant :
PROJECT_ID: ID de votre projet.TOPIC_NAME: nom de votre sujet Pub/SubFILE_PATH: chemin d'accès au fichier JSON avec le texte du schéma
(Facultatif) Vérifiez que le schéma est bien attribué au sujet Pub/Sub en exécutant la commande suivante :
gcloud data-catalog entries lookup \ 'pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`'
Utiliser un sujet Pub/Sub
Pour faire référence à un sujet Pub/Sub dans une requête Dataflow SQL, utilisez les identifiants suivants :
pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`
Remplacez l'élément suivant :
PROJECT_ID: ID de votre projet.TOPIC_NAME: nom de votre sujet Pub/Sub
Par exemple, la requête suivante sélectionne le sujet Dataflow daily.transactions dans le projet dataflow-sql :
SELECT *
FROM pubsub.topic.`dataflow-sql`.`daily.transactions`
Écrire dans des sujets Pub/Sub
Vous pouvez écrire des résultats de requête dans un sujet Pub/Sub à l'aide de Cloud Console ou de Google Cloud CLI.
Console
Pour écrire des résultats de requête dans un sujet Pub/Sub, exécutez la requête avec Dataflow SQL :
Dans Cloud Console, accédez à la page BigQuery, où vous pouvez utiliser Dataflow SQL.
Saisissez la requête Dataflow SQL dans l'éditeur de requête.
Cliquez sur Créer une tâche Cloud Dataflow pour ouvrir un panneau d'options de tâche.
Dans la section Destination du panneau, sélectionnez Type de sortie > Sujet Cloud Pub/Sub.
Cliquez sur Sélectionner un sujet Cloud Pub/Sub et choisissez un sujet.
Cliquez sur Créer.
gcloud
Pour écrire des résultats de requête dans un sujet Pub/Sub, utilisez l'option --pubsub-topic de la commande gcloud dataflow sql query :
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --pubsub-project=PROJECT_ID \ --pubsub-topic=TOPIC_NAME \ 'QUERY'
Remplacez l'élément suivant :
JOB_NAME: nom de la tâche de votre choixREGION: point de terminaison régional (par exemple,us-west1)PROJECT_ID: ID de votre projet.TOPIC_NAME: nom de votre sujet Pub/SubQUERY: la requête Dataflow SQL
Le schéma des sujets Pub/Sub de destination doit correspondre au schéma des résultats de la requête. Si un sujet Pub/Sub de destination ne possède pas de schéma, un schéma correspondant aux résultats de la requête est automatiquement attribué.
Cloud Storage
Interroger des ensembles de fichiers Cloud Storage
Pour interroger un ensemble de fichiers Cloud Storage avec Dataflow SQL, procédez comme suit :
Créez un ensemble de fichiers Cloud Storage pour Dataflow SQL.
Ajoutez l'ensemble de fichiers Cloud Storage en tant que source Dataflow.
Utilisez l'ensemble de fichiers Cloud Storage dans une requête SQL Dataflow.
Créer des ensembles de fichiers Cloud Storage
Pour créer un ensemble de fichiers Cloud Storage, consultez la section Créer des groupes d'entrées et des ensembles de fichiers.
L'ensemble de fichiers Cloud Storage doit avoir un schéma et ne contenir que des fichiers CSV sans lignes d'en-tête.
Ajouter des ensembles de fichiers Cloud Storage
Vous pouvez ajouter un ensemble de fichiers Cloud Storage en tant que source Dataflow à l'aide de Dataflow SQL :
Dans Cloud Console, accédez à la page BigQuery, où vous pouvez utiliser Dataflow SQL.
Dans le panneau de navigation, cliquez sur Add Data (Ajouter des données) dans la liste déroulante, puis sélectionnez Cloud Dataflow sources (Sources Cloud Dataflow).
Dans le panneau Ajouter une source Cloud Dataflow, sélectionnez Ensembles de fichiers Cloud Storage et recherchez un ensemble de fichiers.
Cliquez sur Ajouter.
Après avoir ajouté l'ensemble de fichiers Cloud Storage en tant que source Dataflow, celui-ci apparaît dans la section Ressources du menu de navigation.
Pour afficher l'ensemble de fichiers, développez Sources Cloud Dataflow > Ensembles de fichiers Cloud Storage.
Utiliser un ensemble de fichiers Cloud Storage
Pour faire référence à un ensemble de fichiers Cloud Storage dans une requête Dataflow SQL, utilisez les identifiants suivants :
datacatalog.entry.`PROJECT_ID`.REGION.`ENTRY_GROUP`.`FILESET_NAME`
Remplacez l'élément suivant :
PROJECT_ID: ID de votre projet.REGION: point de terminaison régional (par exemple,us-west1)ENTRY_GROUP: groupe d'entrées de l'ensemble de fichiers Cloud StorageFILESET_NAME: nom de l'ensemble de fichiers Cloud Storage
Par exemple, la requête suivante sélectionne l'ensemble de fichiers Cloud Storage daily.registrations dans le projet dataflow-sql et le groupe d'entrées my-fileset-group :
SELECT *
FROM datacatalog.entry.`dataflow-sql`.`us-central1`.`my-fileset-group`.`daily.registrations`
BigQuery
Interroger des tables BigQuery
Pour interroger une table BigQuery avec Dataflow SQL, procédez comme suit :
Créez une table BigQuery pour Dataflow SQL.
Utilisez la table BigQuery dans une requête Dataflow SQL.
Vous n'avez pas besoin d'ajouter une table BigQuery en tant que source Dataflow.
Créer une table BigQuery
Pour créer une table BigQuery pour Dataflow SQL, consultez la section Créer une table vide avec une définition de schéma.
Utiliser une table BigQuery dans une requête
Pour faire référence à une table BigQuery dans une requête Dataflow SQL, utilisez les identifiants suivants :
bigquery.table.`PROJECT_ID`.`DATASET_NAME`.`TABLE_NAME`
Les identifiants doivent respecter la structure lexicale de Dataflow SQL. Entourez les identifiants contenant des caractères autres que des lettres, des chiffres ou des traits de soulignement par des accents graves.
Par exemple, la requête suivante sélectionne la table BigQuery us_state_salesregions dans l'ensemble de données dataflow_sql_dataset et le projet dataflow-sql :
SELECT *
FROM bigquery.table.`dataflow-sql`.dataflow_sql_dataset.us_state_salesregions
Écrire dans une table BigQuery
Vous pouvez écrire des résultats de requête dans une requête Dataflow SQL à l'aide de Cloud Console ou de Google Cloud CLI.
Console
Pour écrire des résultats de requête dans une requête Dataflow SQL, exécutez la requête avec Dataflow SQL :
Dans Cloud Console, accédez à la page BigQuery, où vous pouvez utiliser Dataflow SQL.
Saisissez la requête Dataflow SQL dans l'éditeur de requête.
Cliquez sur Créer une tâche Cloud Dataflow pour ouvrir un panneau d'options de tâche.
Dans la section Destination du panneau, sélectionnez Type de sortie > BigQuery.
Cliquez sur ID de l'ensemble de données, puis sélectionnez Ensemble de données chargé ou Créer un ensemble de données.
Dans le champ Nom de la table, saisissez une table de destination.
(Facultatif) Choisissez le mode de chargement des données dans une table BigQuery :
- Écrire si la table est vide : n'écrit les données que si la table est vide (par défaut).
- Ajouter à la table : ajoute les données à la fin de la table.
- Écraser la table : efface toutes les données existantes d'une table avant d'écrire les nouvelles données.
Cliquez sur Créer.
gcloud
Pour écrire des résultats de requête dans une table BigQuery, utilisez l'option --bigquery-table de la commande gcloud dataflow sql query :
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ 'QUERY'
Remplacez l'élément suivant :
JOB_NAME: nom de la tâche de votre choixREGION: point de terminaison régional (par exemple,us-west1)DATASET_NAME: nom de votre ensemble de données BigQueryTABLE_NAME: nom de votre table BigQuery.QUERY: la requête Dataflow SQL
Pour choisir comment écrire des données dans une table BigQuery, vous pouvez utiliser l'option --bigquery-write-disposition et les valeurs suivantes :
write-empty: n'écrit les données que si la table est vide (par défaut).write-append: ajoute les données à la fin de la table.write-truncate: efface toutes les données existantes d'une table avant d'écrire les nouvelles données.
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ --bigquery-write-disposition=WRITE_MODE 'QUERY'
Remplacez WRITE_MODE par la valeur de disposition d'écriture de BigQuery.
Le schéma de la table BigQuery de destination doit correspondre au schéma des résultats de la requête. Si une table BigQuery de destination ne possède pas de schéma, un schéma correspondant aux résultats de la requête est automatiquement attribué.